基于內在好奇心與自模仿學習的探索算法
2024-09-21 00:00:00呂相霖臧兆祥李思博鄒耀斌
現代電子技術 2024年16期
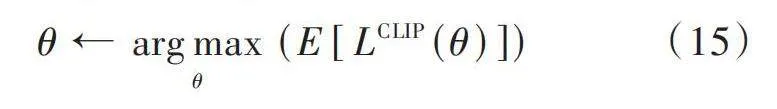

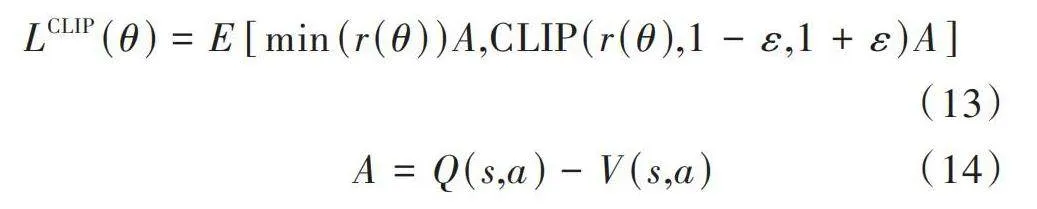

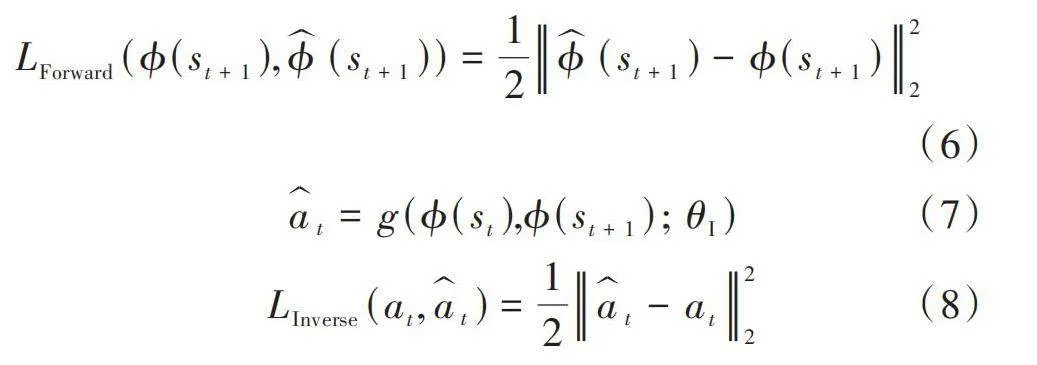

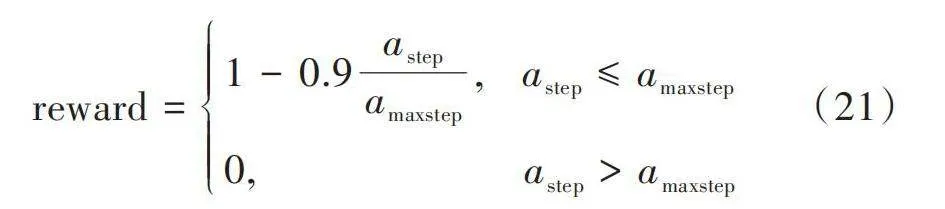
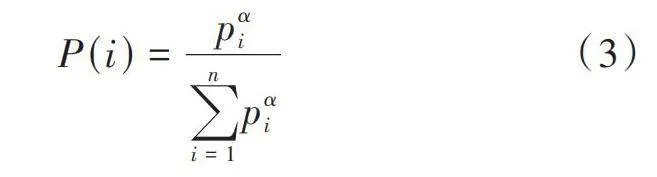



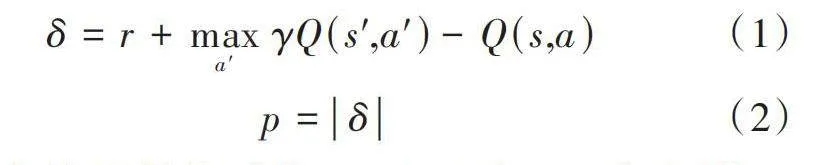
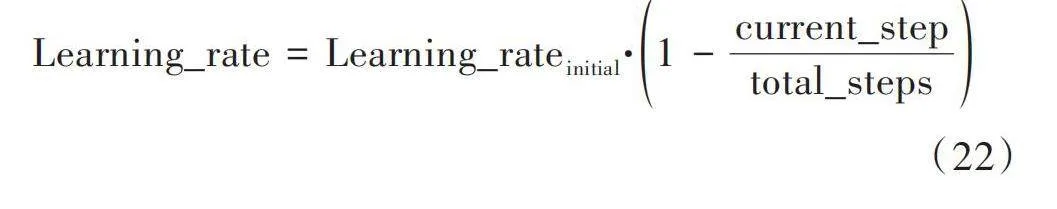
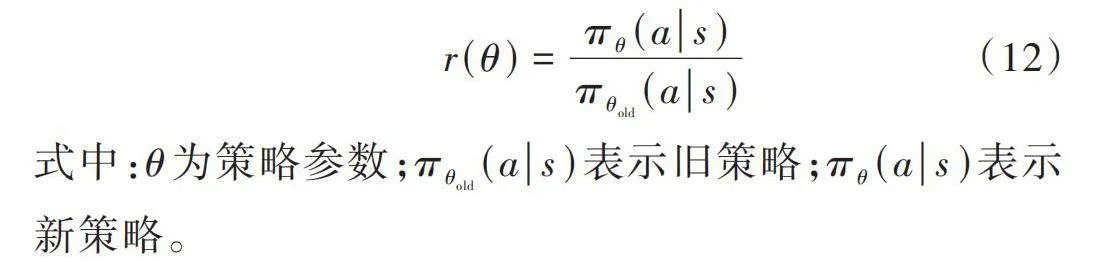
摘" 要: 針對深度強化學習算法在部分可觀測環境中面臨的稀疏獎勵、信息缺失等問題,提出一種結合好奇心模塊與自模仿學習的近端策略優化算法。該算法利用隨機網絡來生成探索過程中的經驗樣本數據,然后利用優先經驗回放技術選取高質量樣本,通過自模仿學習對優秀的序列軌跡進行模仿,并更新一個新的策略網絡用于指導探索行為。在Minigrid環境中設置了消融與對比實驗,實驗結果表明,所提算法在收斂速度上具有明顯優勢,并且能夠完成更為復雜的部分可觀測環境探索任務。
關鍵詞: 好奇心模塊; 自模仿學習; 深度強化學習; 近端策略優化; 隨機網絡; 優先經驗回放
中圖分類號: TN911?34; TP242.6" " " " " " " " " "文獻標識碼: A" " " " " " " " " " 文章編號: 1004?373X(2024)16?0137?08
Exploration algorithm based on intrinsic curiosity and SIL
Lü Xianglin1, 2, ZANG Zhaoxiang1, 2, LI Sibo1, 2, ZOU Yaobin1, 2
(1. Hubei Key Laboratory of Intelligent Vision Monitoring for Hydropower Engineering, China Three Gorges University, Yichang 443002, China;
2. School of Computer and Information, China Three Gorges University, Yichang 443002, China)
Abstract: In allusion to the problems of sparse rewards and missing information faced by deep reinforcement learning algorithm in partially observable environments, a proximal policy optimization algorithm combining curiosity module and self?imitation learning (SIL) is proposed. In this algorithm, the random network is used to generate empirical sample data during the exploration process, and then the priority experience replay technology is used to select high?quality samples. The excellent sequence trajectories are imitated by means of SIL, and a new policy network is updated to guide the exploration behavior. The ablation and comparison experiments were performed in the Minigrid environment. The experimental results show that the proposed algorithm has a significant advantage in convergence speed and can complete more complex exploration tasks of partially observable environments.
Keywords: curiosity module; self?imitation learning; deep reinforcement learning; proximal policy optimization; random network; priority experience replay
0" 引" 言
部分可觀測馬爾科夫過程(POMDP)是指智能體在探索過程的視野受限,僅能通過掌握局部環境的觀測信息進行問題分析與建模,并智能化地做出后續決策。近年來,深度強化學習算法已在多智能體對抗游戲[1?3]、機器人控制[4?6]、自動駕駛[7?10]和兵棋推演[11?12]等諸多非完全信息的任務中取得了巨大的成功。
POMDP任務存在信息缺失與稀疏獎勵等問題,目前學者們主要采用回放歷史信息、循環神經網絡以及好奇心探索機制等方法來解決信息缺失和稀疏獎勵問題。文獻[13]按照所收集的經驗樣本的時序誤差不同,賦予每個樣本不同的優先概率,有效地利用過去的探索經驗優化了訓練效果。文獻[14]結合強化學習算法與優先經驗回放加速了POMDP任務的收斂,能夠處理更復雜的對話管理場景。基于最大熵思想,文獻[15]還提出了自模仿學習(Self?Imitation Learning, SIL)算法,通過模仿過去表現良好的樣本軌跡進行學習,極大地提升了探索效率。文獻[16]通過將記憶引入TD3算法,提出了基于長短期記憶的雙延遲深度確定性策略梯度算法(LSTM?TD3)。文獻[17]通過將長短期記憶與深度Q網絡相結合,修改DQN以處理噪聲觀測特征。但是探索環境通常呈現動態變化性或具有基于回合(episode)產生變化的特征,這使得融合了循環神經網絡的深度強化學習算法在解決這些環境中面臨的稀疏獎勵問題時變得困難。而基于回放歷史信息的方法依賴于過去表現良好的經驗數據,一旦空間狀態變得復雜,智能體就很難獲取到有價值的數據樣本。為解決上述問題,文獻[18]利用人類內在的好奇心這一概念,提出了好奇心探索機制,依據智能體所采集的空間信息給予相應的內在獎勵。ICM(Intrinsic Curiosity Module)算法[19]和RND(Random Network Distillation)算法[20]主要計算不同網絡之間的特征差異,可用于激發智能體探索不同場景。但上述好奇心算法也存在過度探索的問題,智能體在環境中容易忽視已經學到的有效策略,從而導致學習過程的低效性和不穩定性。本文在好奇心算法基礎上,引入自模仿學習算法來增強對已有經驗數據的利用,以此提出了一種融合好奇心與自模仿學習的近端策略優化算法(Proximal Policy Optimization Algorithm with Curiosity Module and Self?Imitation Learning, PPO?CI),進而達到解決POMDP探索任務中的稀疏獎勵與信息缺失等問題的目的。
1" 相關技術
1.1" 優先經驗回放
由文獻[21]中DeepMind提出的經驗回放機制通過將過去的探索經驗存儲至經驗池,然后隨機抽取批次大小的經驗進行訓練,打破訓練數據之間的相關性,從而提高算法的穩定性與泛化能力。優先經驗回放機制[13]通過賦予各樣本數據不同的優先級,改變樣本數據的被采樣概率。樣本數據優先級[p]通過時序差分誤差[δ]來衡量,其計算公式如下:
[δ=r+maxa′γQ(s',a')-Q(s,a)] (1)
[p=δ] (2)
式中:[r]表示當前所得獎勵值;[Q(s',a')]表示目標網絡[Q]值,由下一狀態[s']在采取動作[a']時所得;[Q(s,a)]表示當前[s]狀態采取動作[a]計算所得的[Q]值。根據所得的優先級[p]進行概率采樣,經驗樣本采樣的概率公式為:
[P(i)=pαii=1npαi] (3)
式中:[α]表示優先級調節參數;[n]表示采樣的樣本數量。
優先經驗回放會將TD誤差和經驗數據一同存進經驗池,并為每個經驗數據賦予一個與其TD誤差大小成正比的采樣概率[P(i)]。
1.2" ICM算法
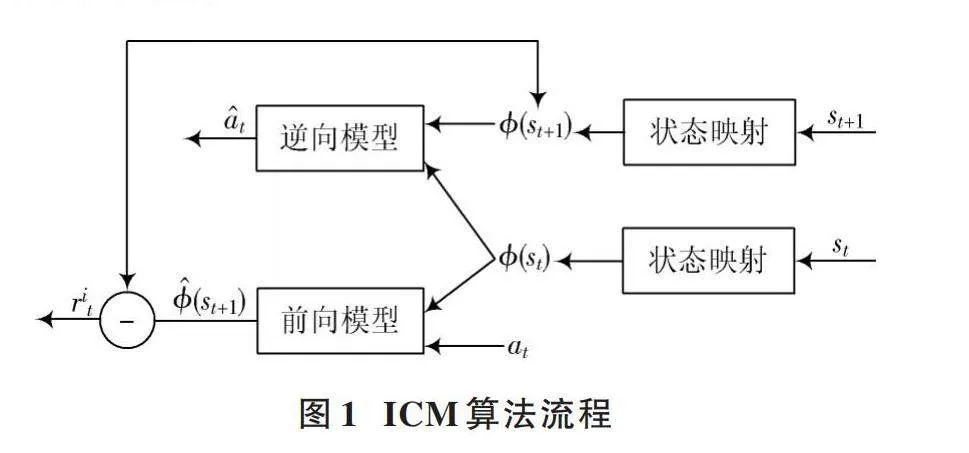
好奇心機制通過給予智能體內在獎勵激發探索的動力,其中具有代表性的為D. Pathak等人提出的內在好奇心模塊(ICM)[19],其算法模型如圖1所示。ICM算法利用逆向動力學模型和前向動力學模型來學習一個新的特征空間,通過策略網絡預測的下一狀態信息與ICM動力學模型所預測的下一狀態信息差異計算出對應的內在獎勵值。
圖1中,算法輸入為決策模型所得當前狀態值[st]、當前采取動作[at]和下一狀態信息[st+1]。[?(st)]為狀態[st]的特征編碼;而[?(st+1)]是[?(st+1)]的預測估計,由[?(st)]與動作[at]計算所得。[at]為由狀態映射信息[?(st)]和[?(st+1)]計算所得的動作預測值;[rit]為經動力學模型計算所得的內在獎勵值。而[?(st+1)]和[rit]計算公式為:
[?(st+1)=f(?(st),at;θF)] (4)
[rit=η2?(st+1)-?(st+1)22] (5)
ICM算法的損失函數如下:
[LForward(?(st+1),?(st+1))=12?(st+1)-?(st+1)22] (6)
[at=g(?(st),?(st+1);θI)] (7)
[LInverse(at,at)=12at-at22] (8)
式中:[f]是前向模型的網絡函數;[θF]為前向模型的網絡參數;[η]是縮放因子;[LForward]為前向模型的計算損失值;[θF]為通過最小化損失函數[LForward]來優化前向模型的網絡參數;[g]是逆向模型的網絡函數;[θI]為逆向模型的網絡參數;[LInverse]為逆向模型的計算損失值,用于優化逆向模型的網絡參數[θI]。
1.3" 自模仿學習
自模仿學習是一種無監督學習方法,它通過自主探索和學習來生成和改進策略,以達到優化目標的目的。首先,智能體使用當前策略網絡與環境互動產生探索經驗與累計獎勵并存入經驗池;然后,自模仿學習算法從經驗池中選擇具有高獎勵或優質性能的軌跡片段作為模仿的目標,從選定的優質軌跡中提取子軌跡,并基于選定的子軌跡構建一個新的策略網絡,用于模仿優質軌跡中的行為;接著,使用選定的子軌跡訓練智能體的策略網絡,通過反復迭代訓練和更新智能體的策略網絡,使其不斷逼近或模仿新策略網絡中的行為選擇。SIL算法的損失函數計算公式如下:
[LSILvalue=12(R-Vθ(s))+2] (9)
[LSILpolicy=-logπθ(as)(R-Vθ(s))+] (10)
[LSIL=Es,a,R∈DLSILpolicy+βSILLSILvalue] (11)
式中:[LSILvalue]為對應的價值損失函數;[R]為累計獎勵值;[Vθ(s)]代表對應狀態[s]的價值函數;[(?)+]表示為[max(?,0)],以此鼓勵智能體模仿自己的決定,只有當這些決定所獲得的回報比預期更大時才選擇更新[LSILvalue];[LSILpolicy]為SIL算法的策略損失函數;[πθ(as)]是根據參數[θ]的策略函數在狀態[s]下選取動作[a]的概率估計值;[D]代表經驗池;[βSIL]為價值損失函數對應的超參數。
1.4" 近端策略優化算法
深度強化學習算法分為值函數算法和策略梯度算法[22]。近端策略優化算法(Proximal Policy Optimization Algorithm, PPO)屬于策略梯度算法的一種,其原理是將策略參數化,通過參數化的線性函數或神經網絡表示策略[23]。
PPO算法的核心之一是重要性采樣,它的主要目的是評估新舊策略之間的差異程度,通過計算比值來衡量差異大小。重要性采樣公式如下:
[r(θ)=πθ(as)πθold(as)] (12)
式中:[θ]為策略參數;[πθold(as)]表示舊策略;[πθ(as)]表示新策略。
PPO算法的另一個核心是梯度裁剪,其策略損失函數表達式如下:
[LCLIP(θ)=E[min(r(θ))A,CLIP(r(θ),1-ε,1+ε)A]] (13)
[A=Q(s,a)-V(s,a)] (14)
式中:[r(θ)]為重要性采樣比;[CLIP]為裁剪函數;[ε]為超參數;[A]為優勢函數;[Q(s,a)]代表在狀態[s]下采取動作[a]后產生的累計獎勵值;[V(s,a)]為狀態價值估計值。
PPO算法的策略參數更新公式為:
[θ←argmaxθ(E[LCLIP(θ)])] (15)
2" 結合ICM與自模仿學習的近端策略優化算法
本文提出了一種結合好奇心與自模仿學習的近端策略優化算法,即PPO?CI算法,以解決POMDP探索任務。首先通過ICM與PPO算法結合鼓勵智能體的探索行為,并將探索經驗數據存入優先經驗池;然后通過優先經驗回放選取好的樣本數據,SIL算法模仿好的樣本軌跡,同時更新一個新的策略網絡,用于指導智能體行為選擇,最終使得智能體完成探索任務。
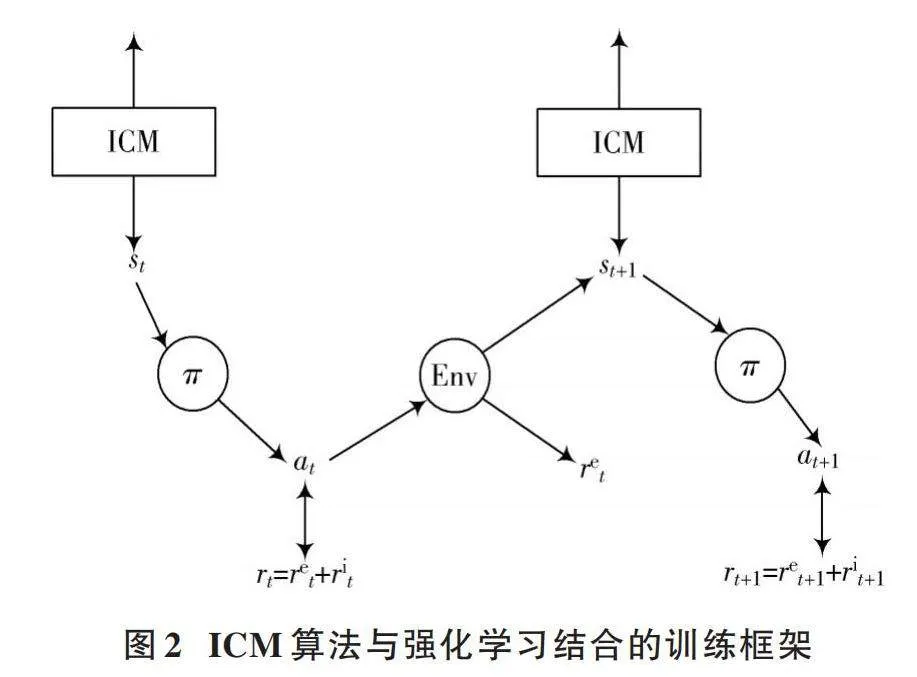
本文采用強化學習與ICM算法結合的工作機制,訓練框架如圖2所示。
結合計算所得的內在獎勵與環境反饋的外在獎勵指引智能體進行探索任務,其總獎勵計算公式如下:
[rt=mrit+ret] (16)
式中:[rt]為時刻[t]獲得的總獎勵值;[m]為內在獎勵對應權重系數;[rit]為經過ICM動力學模型計算所得的內在獎勵值;[ret]為與環境互動所獲得的外在獎勵值,在稀疏獎勵任務中大部分情況為0。
PPO?CI算法分為兩個訓練模塊,即PPO?ICM算法模塊與SIL算法模塊。其中涉及到的PPO與ICM結合算法的訓練損失函數公式如下:
[LCLIP+VF+St(θ)=Et[LCLIPt(θ)]-c1LVFt(θ)+c2S(st)] (17)
[LVFt(θ)=(Vθ(st)-Vtargt)2] (18)
[LICM=LForward(?(st+1),?(st+1))+LInverse(at,at)] (19)
[LPPO+ICM=LCLIP+VF+St(θ)+LICM] (20)
式中:[LCLIP+VF+St(θ)]為PPO算法的損失函數;[LCLIPt(θ)]為PPO算法的策略梯度的損失;[LVFt(θ)]為PPO算法的價值函數的損失;[S(st)]為交叉熵的損失;[c1]和[c2]為其對應系數;[Vθ(st)]為基于狀態[st]的預測價值函數值;[Vtargt]為目標網絡的value值;[LForward(?(st+1),?(st+1))]為ICM算法的前向模型損失值;[LInverse(at,at)]為其逆向模型的損失值。
PPO?CI算法的具體偽代碼實現過程如下。
1) 初始化網絡參數、算法的超參數。
2) 初始化普通經驗池[D]與優先經驗池[D']。
3) 將當前時間步的狀態信息[st]輸入到設計的基于Actor?Critic框架的網絡模型,獲取各項動作及其概率分布;依概率選擇動作[at],并將動作反饋給環境,獲取下一狀態信息[donet]、當前外在獎勵值[ret]與完成情況[donet]。
4) 將步驟3)所獲取的數據[(st,at,st+1)]輸入至ICM算法模型,計算預測狀態[s't+1]與預測動作[at],通過評估[st+1]與[s't+1]的差異獲取內在獎勵值[rit],并與環境反饋的外在獎勵[ret]結合,獲得總獎勵值[rt];同時通過評估[st+1]與[s't+1]的差異、[at]與實際動作[at]的差異計算出ICM算法的損失函數值,然后將數據[(st,at,rt,donet)]存入普通經驗池[D]與優先經驗池[D']。在優先經驗池[D']中,根據計算出的誤差為數據賦予不同的優先級,供后續訓練調用。
5) 從普通經驗池[D]中抽取batch_size大小的數據樣本,然后將這些樣本分成多個小批量(minibatch),使用每個小批量的數據來計算PPO?ICM算法的損失函數,并更新策略網絡的參數。
6) 從優先經驗池[D']抽取batch_size大小的樣本數據,使用SIL算法對高質量的軌跡序列進行模仿,并提取出對應的狀態動作對用于訓練一個新的策略網絡;同時更新樣本優先級,采用訓練好的新策略網絡來進行策略改進。
7) 不斷重復步驟3)~步驟6)直至算法收斂。
3" 實驗設計
3.1" 實驗環境
本文采用文獻[24]中由Open AI提出的Gym?Minigrid網格環境對所提出的PPO?CI算法表現進行測試與評估。Minigrid環境是基于回合(episode)產生變化的環境,該環境每回合開始時,智能體在某一區域初始位置與朝向,在探索時僅能獲取局部視野信息,并且無法感知墻壁后方與門另一側信息,需要根據僅掌握的部分信息完成探索任務。本文基于Minigrid已注冊的環境進行改動,設計了四種不同探索難度的地圖環境,旨在驗證PPO?CI算法面臨各類基于回合變化環境的性能與表現。
圖3a)為改進的環境MultiRoom?N6S6,每一回合地圖上隨機生成6個大小隨機的房間,且各房間門的顏色隨機,智能體在最左下方位置的房間內的隨機位置出現,該地圖中智能體需要學會開門動作并且需要連續通過多個房間找到最右上方房間的出口。
圖3b)為改進的環境Empty?15×15?v1,在這個環境中,智能體起始點位于最左側房間某個隨機位置,而目標出口在最右側房間內的隨機位置。不同的挑戰在于:該環境擴大了房間內的空間,并且三扇門的位置隨機,這為智能體進行探索帶來了麻煩。圖3c)為改進的環境FourRooms?v1,該環境擴大了房間的大小,且探索任務不再僅限于從左側向右側進行探索;另外,環境中設置了相同顏色的門,這會一定程度上影響智能體對于自身位置的判斷。對于該環境,智能體隨機出現在左上側房間的某個位置,目標點隨即出現在右下側房間的某個位置,智能體需要在位置判斷受影響的情況下完成任務。圖3d)為改進的環境LockedRoom?v1,該環境設置了一扇帶鎖的門,智能體需要打開另一扇未上鎖的門,去到房間內拿到鑰匙,然后去開另一側帶鎖的門,最終找到出口。該探索任務難度在于:智能體需要學會拾取鑰匙的動作,并學會持有鑰匙在鎖住的門前學會激活門的動作。
3.2" 獎勵設計
獎勵是智能體與環境每回合交互所得到的回報。本文設計了一種隨步數變化而變化的獎勵函數,其目的是引導智能體在每個episode內盡可能地用更少的步數獲取更高的獎勵,從而避免智能體陷入局部最優解并停止探索任務的情況。
具體獎勵函數如下:
[reward=1-0.9astepamaxstep," " astep≤amaxstep0," " " " " " " " " " " " " " "astepgt;amaxstep] (21)
3.3" 模型結構與參數
本文為處理環境中多維復雜的特征信息,設計一種基于Actor?Critic架構的網絡模型,具體結構如圖4所示。
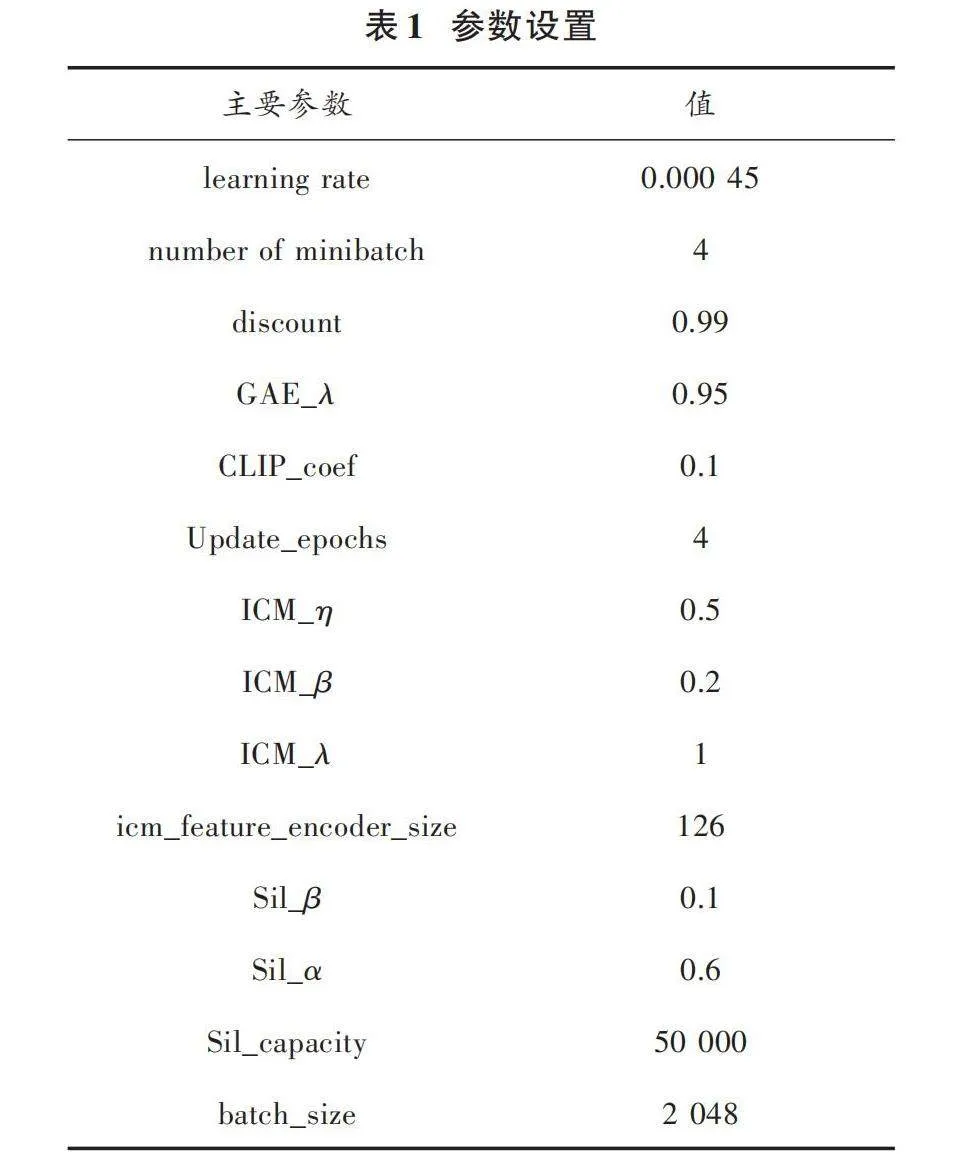
由圖4可知:從環境中所獲取的狀態信息首先經歷兩層卷積網絡層,將輸入的狀態數據信息抽象成更高層次的特征表示;然后將卷積層的輸出結果通過展平層,將多維特征數據展開成一維向量;接著輸入到全連接層捕捉特征之間的復雜關系,并對特征進行組合;最后將組合特征分別輸入Actor網絡的全連接層,獲取各項動作及其概率分布,用于指導智能體的行為決策,并輸入到Critic網絡的全連接層評估當前狀態的價值。本文實驗所采用的PPO?CI算法涉及到PPO?CLIP算法模塊、ICM算法模塊以及自模仿學習算法模塊的各項參數,具體的超參數如表1所示。
為加快模型的收斂速度,以及訓練后期對細化參數的調整,本文采用線性退火算法來提高模型在更接近最優解時的精度。學習率的線性退火算法公式為:
[Learning_rate=Learning_rateinitial·1-current_steptotal_steps] (22)
式中:[Learning_rate]表示當前的學習率;[Learning_rateinitial]表示初始設置的學習率;[current_step]表示當前與環境交互的步數;[total_steps]表示訓練的總步數。
3.4" 實驗結果與分析
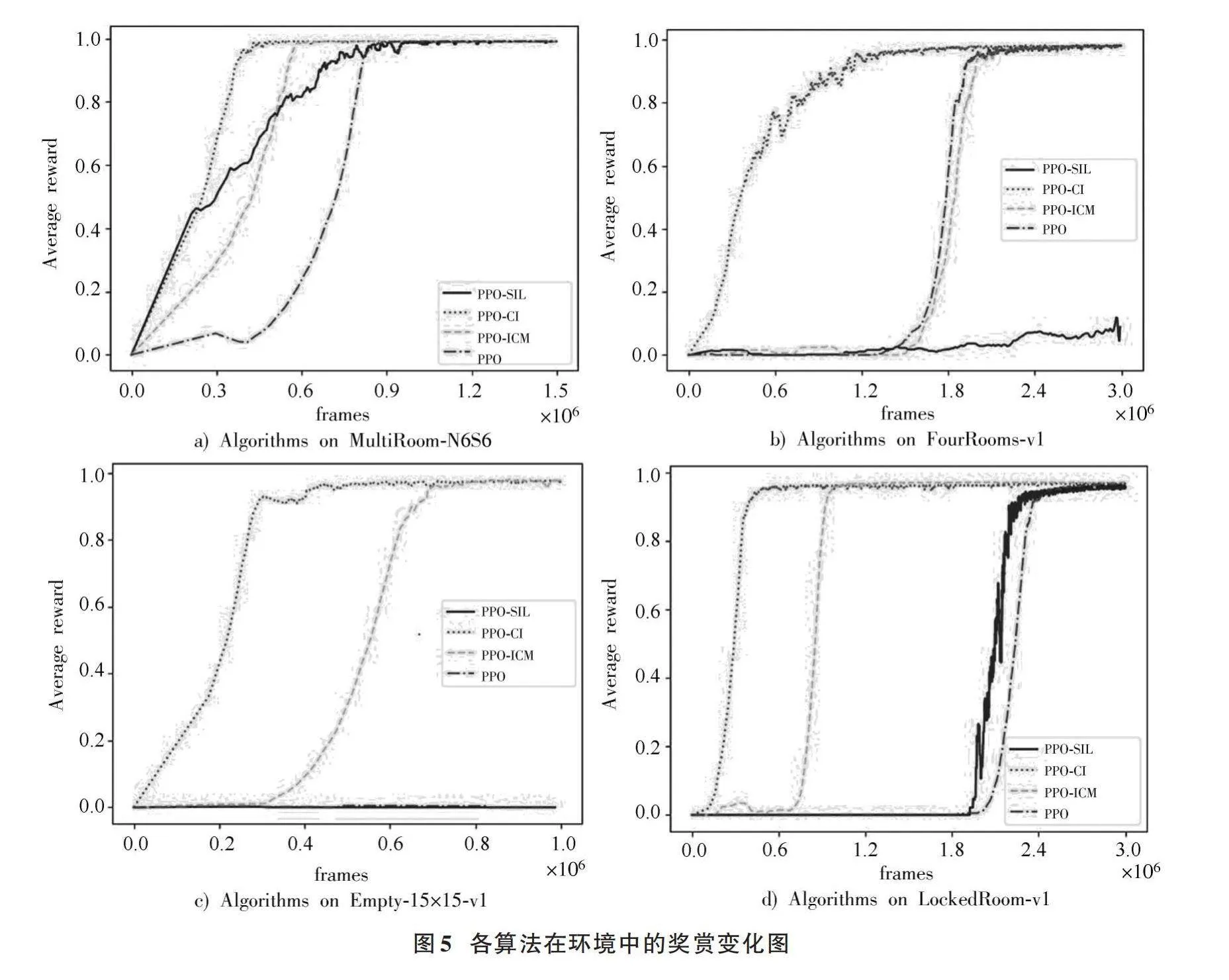
實驗采用的操作系統為Ubuntu 18.04,Python版本為3.9,基于Torch 1.13搭建深度強化學習框架。實驗設備選用含有2張內存大小為8 GB的GTX 1080顯卡的服務器。為測試與評估所提出的PPO?CI算法在POMDP任務中的性能表現,設置了消融實驗,將提出的PPO?CI算法與PPO算法、PPO?ICM算法、PPO?SIL算法進行比較。
各算法在MultiRoom?N6S6環境下的訓練獎勵值變化如圖5a)所示,橫坐標的frames表示智能體與環境交互的總步數,縱坐標表示智能體與各不同隨機種子環境交互產生的平均獎勵值信息。在該環境中,4種基于PPO算法的改進算法均能完成任務。四類完成探索任務的算法中,PPO?CI算法以最快的速度達到收斂狀態,因為PPO?CI算法通過綜合利用ICM的自主探索和SIL的軌跡模仿,提高了有效樣本的利用率。通過綜合利用這些樣本,PPO?CI算法可以更好地優化智能體的策略,提高學習效果,這一優勢在Empty?15×15?v1環境的探索中更加突出。Empty?15×15?v1環境中設置了三面墻來阻礙智能體的探索,并且墻上門位置的變化幅度較大,使得環境具有較強的隨機性。如圖5c)所示,僅在好奇心驅使下進行探索的PPO?ICM算法與PPO?CI算法能夠完成該探索任務,這說明僅憑環境反饋的獎勵信息很難進行下一步探索。在FourRooms?v1環境中,智能體受限于自身的位置判斷,且門的顏色也混淆了智能體的判斷。PPO?CI算法在該環境中仍以最快的速度達到收斂,在好奇心的推動下,通過有效利用優先經驗池的軌跡回放進行高效地學習,準確地判斷自身位置以及各房間門的位置,并成功找到出口。如圖5d)所示,在設置了門鎖與鑰匙的LockedRoom?v1環境中,智能體首先需要找到鑰匙,然后學會開門動作,最終找到出口。
在這種多任務環境中,PPO?CI算法仍表現出高效的學習能力與適應能力。本文提出的PPO?CI算法綜合利用了ICM和SIL的優點,既能夠對智能體與環境交互產生的經驗數據進行有效利用,又能夠在好奇心的驅動下進行自主探索,從而在探索能力和學習效果方面取得更好的平衡。
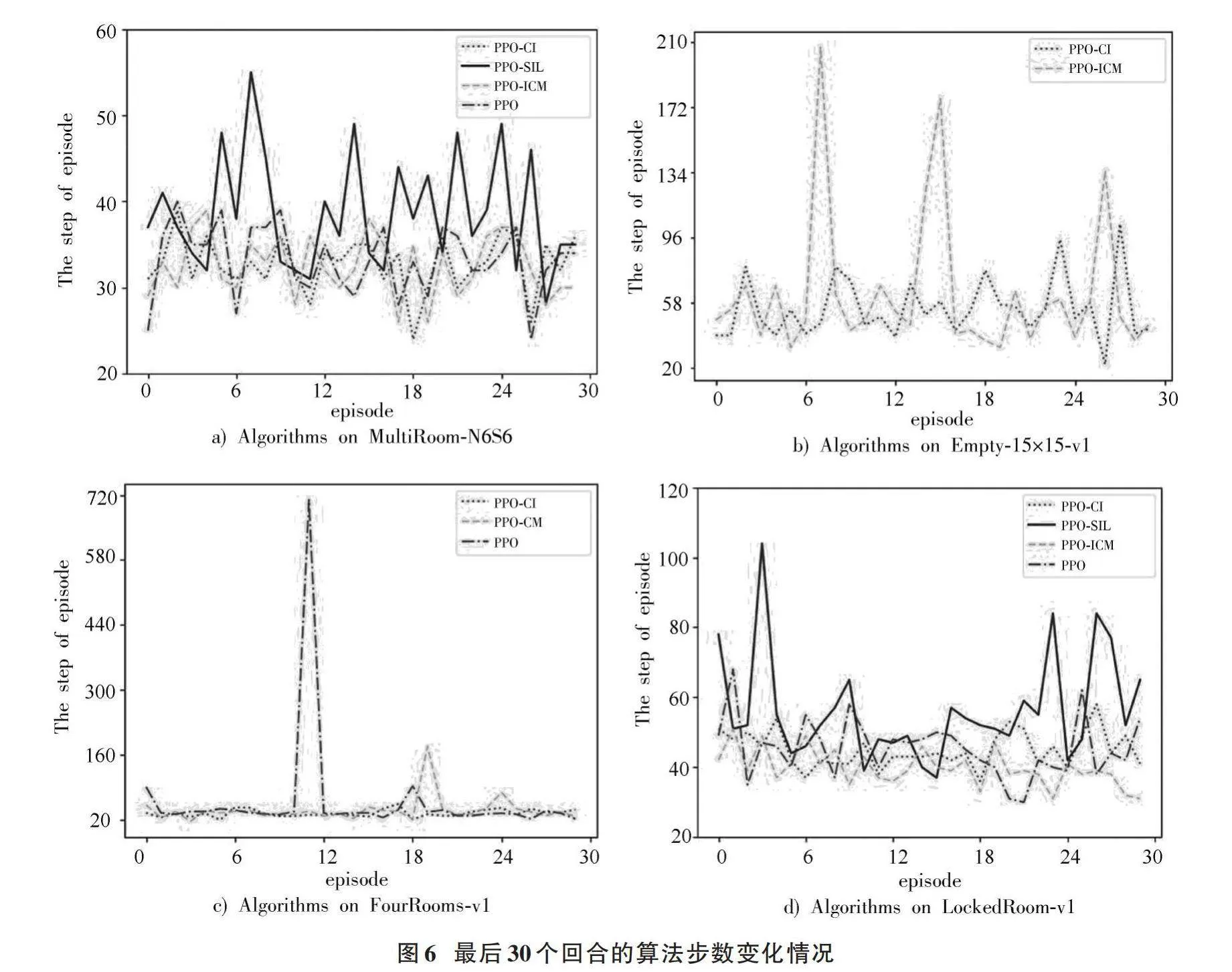
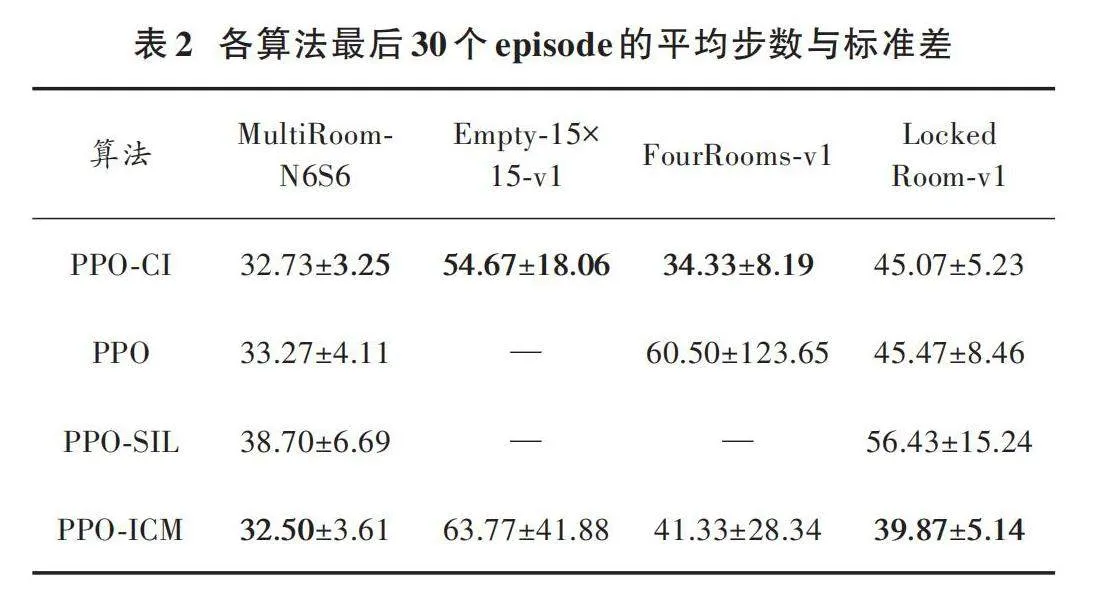
在驗證了PPO?CI算法的快速收斂性后,進一步對算法收斂后的穩定性進行分析。本文選取各算法在收斂之后的最后30個episode的訓練情況作為參考,從具體步數來探究算法收斂后的穩定性。各類算法在四類環境中的訓練情況如圖6所示。
由圖6中使用PPO?CI算法訓練的結果顯示,其使用步數的波動幅度較小且所使用的步數也是較少的。但是由于各個環境是基于回合產生改變,導致各回合初始位置離目標點的距離不確定,故僅平均步數并不能客觀地體現出各算法的穩定性,故還選取了30個episode的步數標準差作為評估對象。表2中數據前項為平均步數,后項為標準差。綜合數據體現出PPO?CI算法在快速收斂的同時也具有很強的穩定性,每回合都能采取更優的探索路徑完成探索任務。
4" 結" 論
本文為解決POMDP探索任務中的稀疏獎勵與信息缺失等問題,提出一種融合好奇心與自模仿學習的深度強化學習算法,利用好奇心鼓勵智能體探索未知場景,并將產生的探索數據存入設計的優先經驗池,然后利用自模仿學習從優先經驗池中選取具有優秀探索表現的歷史經驗數據進行學習與更新策略。
為驗證所提出的PPO?CI算法在POMDP任務的表現,設計了四項不同難度的Minigrid環境的探索任務。經實驗驗證,該算法平衡了探索過度與利用不足的問題,同時具有較快達到收斂效果的優勢,較已有的ICM、SIL等算法速度更快。并且該算法具有更強的泛化性,對基于回合變化的環境仍有著很強的適應能力,能夠有效解決多種不同難度的POMDP探索任務。
本文為解決部分可觀測環境探索中的稀疏獎勵、信息缺失等問題提供了一種有效的方法。未來的研究將致力于進一步優化好奇心與探索算法的融合,比如在更為復雜或具有更多動態變化因素的環境中對PPO?CI算法進行測試與改進,并且嘗試使用其他的好奇心模型或者與其他的探索算法相結合來進一步提升算法的性能。
注:本文通訊作者為臧兆祥。
參考文獻
[1] JADERBERG M, CZARNECKI W M, DUNNING I, et al. Human?level performance in 3D multiplayer games with population?based reinforcement learning [J]. Science, 2019, 364: 859?865.
[2] YE D, LIU Z, SUN M, et al. Mastering complex control in MOBA games with deep reinforcement learning [J]. Proceeding of the AAAI Conference on Artificial Intelligence, 2020, 34(4): 6672?6679.
[3] VINYALS O, BABUSCHKIN I, CZARNECKI W M, et al. Grandmaster level in StarCraft II using multi?agent reinforcement learning [J]. Nature, 2019, 575: 350?354.
[4] CARLUCHO I, PAULA D M, WANG S, et al. Adaptive low?level control of autonomous underwater vehicles using deep reinforcement learning [J]. Robotics and autonomous system, 2018, 107: 71?86.
[5] CARLUCHO I, PAULA D M, ACOSTA G G. An adaptive deep reinforcement learning approach for MIMO PID control of mobile robots [J]. ISA transactions, 2020, 102: 280?294.
[6] WANG D, DENG H. Multirobot coordination with deep reinforcement learning in complex environments [J]. Expert systems with applications, 2021, 180: 115128.
[7] XIONG H, MA T, ZHANG L, et al. Comparison of end?to?end and hybrid deep reinforcement learning strategies for controlling cable?driven parallel robots [J]. Neurocomputing, 2020, 377: 73?84.
[8] JIN Y, LIU Q, SHEN L, et al. Deep deterministic policy gradient algorithm based on convolutional block attention for autonomous driving [J]. Symmetry, 2021, 13: 1061.
[9] YANG T K, LI L K, NGIAP T K, et al. Deep Q?network implementation for simulated autonomous vehicle control [J]. IET intelligent transport systems, 2021, 15: 875?885.
[10] LI J X, YAO L, XU X, et al. Deep reinforcement learning for pedestrian collision avoidance and human?machine cooperative driving [J]. Information sciences, 2020, 532: 110?124.
[11] 崔文華,李東,唐宇波,等.基于深度強化學習的兵棋推演決策方法框架[J].國防科技,2020,41(2):113?121.
[12] ESPEHOLT L, SOYER H, MUNOS R, et al. IMPALA: scalable distributed deep?RL with importance weighted actor?learner architectures [C]// Proceedings of the 35th International Conference on Machine Learning. Stockholm, Sweden: PMLR, 2018: 1407?1416.
[13] SCHAUL T, QUAN J, ANTONOGLOU I, et al. Prioritized experience replay [C]// International Conference on Learning Representations. Vancouver, Canada: IMLS, 2016: 1312?1320.
[14] HENDERSON M, THOMSON B, YOUNG S. Word?based dialog state tracking with recurrent neural networks [C]// Proceedings of the 15th Annual Meeting of the Special Interest Group on Discourse and Dialogue (SIGDIAL). Philadelphia, PA, USA: ACL, 2014: 292?299.
[15] OH J, GUO Y, SINGH S, et al. Self?imitation learning [C]// Proceedings of the International Conference on Machine Learning. Stockholm, Sweden: IMLS, 2018: 3878?3887.
[16] MENG L, GORBET R, KULI? D. Memory?based deep reinforcement learning for POMDPs [C]// IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway, USA: IEEE, 2021: 5619?5626.
[17] HAUSKNECHT M, STONE P. Deep recurrent Q?learning for partially observable MDPs [C]// 2015 Association for the Advancement of Artificial Intelligence Fall Symposium Series. Palo Alto, California, USA: AAAI, 2015: 1?8.
[18] OUDEYER P Y, KAPLAN F. How can we define intrinsic motivation [C]// Proceedings of eighth International Conference on Epigenetic Robotics: Modeling Cognitive Development in Robotic Systems. Lund: Brighton, 2008: 93?101.
[19] PATHAK D, AGRAWAL P, EFROS A A, et al. Curiosity?driven exploration by self?supervised prediction [C]// Proceedings of the 2017 International Conference on Machine Learning. San Diego, CA: JMLR, 2017: 2778?2787.
[20] BURDA Y, EDWARDS H,STORKEY A J, et al. Exploration by random network distillation [C]// Proceeding of the 7th International Conference on Learning Representations. New Orleans, USA: ICLR, 2019: 1?17.
[21] MNIH V, KAVUKCUOGLU K, SILVER D, et al. Playing Atari with deep reinforcement learning [J]. Nature, 2013, 518: 529?533.
[22] 張峻偉,呂帥,張正昊,等.基于樣本效率優化的深度強化學習方法綜述[J].軟件學報,2022,33(11):4217?4238.
[23] 劉國名,李彩虹,李永迪,等.基于改進PPO算法的機器人局部路徑規劃[J].計算機工程,2023,49(2):119?126.
[24] CHEVALIER?BOISVERT M, WILLEMS L, PAL S. widesp?read attention and research [EB/OL]. [2023?01?12]. https://github.com/maximec/gym?minigrid, 2018.
