基于深度學習的目標檢測研究
2024-09-19 00:00:00朱克佳
現代信息科技 2024年13期





摘 要:目標檢測是機器視覺領域的核心問題。經過多年的發展,以深度學習技術為基礎的目標檢測方法已成為研究熱點。根據檢測的原理和過程,目標檢測可分為一階段目標檢測和二階段目標檢測。首先,在進行廣泛文獻調研的基礎上,對比目前主流目標檢測方法的原理、思路,其次,使用mAP和FPS兩個參數對比各方法的檢測效果,分析常見目標檢測方法的優缺點;最后,對目標檢測的發展做出預測和展望。
關鍵詞:目標檢測;深度學習;圖像處理;卷積神經網絡
中圖分類號:TP391.4;TP18 文獻標識碼:A 文章編號:2096-4706(2024)13-0076-08
Research on Object Detection Based on Deep Learning
ZHU Kejia
(School of Electronics, Software Engineering Institute of Guangzhou, Guangzhou 510990, China)
Abstract: Object detection is a core issue in the field of Machine Vision. After years of development, object detection methods based on Deep Learning technology have become a research hotspot. According to the principle and process of detection, object detection can be divided into one-stage object detection and two-stage object detection. Firstly, based on extensive literature research, the principles and ideas of mainstream object detection methods are compared. Then, the detection effects of various methods are compared using two parameters, the mAP and the FPS, and the advantages and disadvantages of common object detection methods are analyzed. Finally, predictions and prospects are made for the development of object detection.
Keywords: object detection; Deep Learning; image processing; Convolutional Neural Networks
0 引 言
目標檢測是對視頻圖像中感興趣的對象進行研究,并在圖像中標注出來。通常對象為可移動的人、物或者人操作的某些設備裝置等。被檢測的對象目標又稱作前景,圖像中周圍環境稱作背景。因此,視頻圖像目標檢測的一個任務就是,將滿足條件的前景從背景中標注、分割出來,為目標提取、分類識別、動作行為判斷、危險識別等更深層次含義的應用研究做基礎。目前,目標檢測在視頻監控、智能交通、無人駕駛、工業機器人、無人機等領域都有著越來越深入的應用。
經典目標檢測根據前景與背景的相對關系,使用前幀的若干特征或者前后幀的關系,用某特征來表示該目標,通過固定大小窗口在后幀圖像滑動,將候選區域與原模板區域特征對比,實現目標分類、檢測、跟蹤。常用方法主要包括背景差法、幀差法、光流法等。這種算法常遍歷窗口,甚至需手動提取特征,智能程度低,所獲取的特征通常都是圖像的低級特征,同時遍歷窗口算法中很多計算都是冗余,較為耗時,且魯棒性較差,難以準確實時檢測多個目標。
1 檢測原理與階段
近年來,在神經網絡技術發展的基礎上,深度學習得到了快速發展,它引入了能學習深層次特征的工具來優化傳統體系結構,使所得模型的網絡架構、訓練策略、功能性能均得以提升。
2012年Krizhevsky等[1]首次嘗試用深層卷積神經網絡。AlexNetd [2]用大規模圖像數據集ImageNet對圖像中目標檢測加以分類,獲得第一名的佳績。自此,人們更多的使用深度學習來研究目標檢測,用卷積神經網絡(CNN)來自動學習目標特征,代替半自動手動選擇和提取特征,通過比較區域候選框或回歸計算來進行目標檢測。
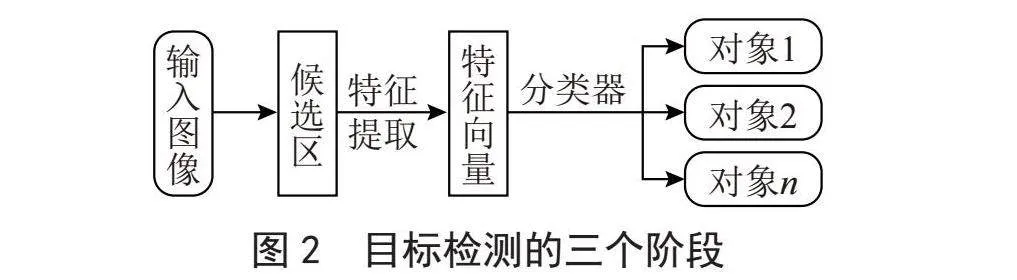
隨著深度卷積神經網絡獲得重大研究進展,目標檢測效率大幅提升,檢測的準確度和實時性方面也積累了越來越多的研究成果,深度學習逐漸成為人們關注的焦點,目標檢測成為深度學習新的研究方向。基于深度學習的目標檢測思想如圖1所示。通常先設定模型框架,使用數據集對其訓練得到訓練網絡,再對測試數據檢測得出測試結果。如果從輸入圖像至目標標注的過程角度來說,基于深度學習目標檢測的三個階段即是:輸入圖像得到候選區域;在候選區提取特征;使用分類器對特征進行分類,完成對目標的分類標注,從而完成目標檢測。其流程圖如圖2所示。
經過數據訓練的框架生成訓練網絡,對待檢測的圖像即測試數據檢測,以錨框標注識別結果。這里有兩大類思路。第一大類:直接通過網絡計算,用概率預測輸出目標預選框和標簽,稱為一階段檢測(One Stage),又稱作回歸檢測;第二大類:將目標檢測分成兩階段,在網絡中使用候選區域,提取特征圖后,通過網絡提取感興趣區域(Region of Interest, RoI),最后使用某種規則對特征圖的RoI區域內的內容進行分類,這個方法稱為而二階段檢測(Two Stage)或者基于區域生成的檢測[3]。
2 二階段目標檢測
2.1 二階段主要檢測方法介紹
2.1.1 R-CNN算法檢測
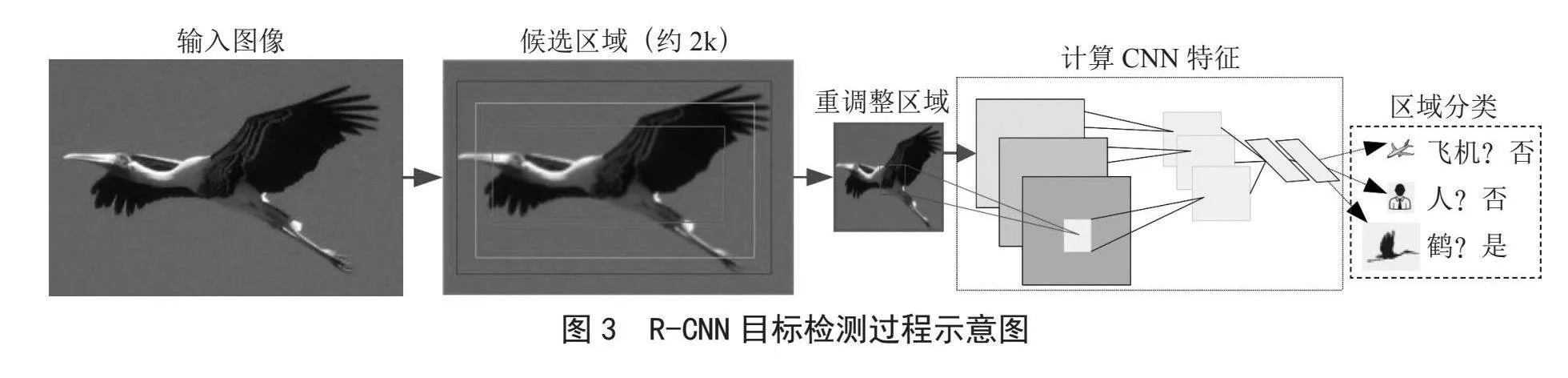
傳統手動或者半手動提取圖像特征的方法,智能化程度過低。2014年Girshick等[4]采用AlexNet作為骨干網絡,利用Selective Search算法[5]提取一系列較可能是物體的候選區域,再用CNN提取圖像特征,完成目標檢測。其關鍵步驟主要有:
1)使用Selective Search從輸入圖像上提取可能的區域,總計共約2 000個候選區域。
2)將所選區域統一為相同227×227維度。
3)使用CNN提取統一后區域特征。
4)將所提取特征輸出至兩個相鄰的連接層。
5)使用支持向量機SVM對特征進行分類。
6)使用極大值抑制法去除多余的標注框。
7)對邊界框的位置微調、修改,將其作為目標檢測的標記框,使對目標的外圍框標注更加準確。R-CNN目標檢測過程圖如圖3所示。
與經典目標檢測相比,R-CNN目標檢測取得了巨大突破,其使用選擇性搜索取代滑動窗口生成候選框,大幅降低了計算量。原來由人工來選取SIFT等特征,改為由CNN計算疊加獲得特征,提升了目標特征的表達能力,將由特征表示的目標區分轉化為通過計算相似度自動完成對目標的分類標記。經實驗,在PASCAL 2007 VOC 2011/2012數據集上,目標的mAP為53.3%;在PASCAL VOC 2010數據集上,目標的mAP為53.7%。但是,R-CNN的選擇性搜索使用的是圖像的低級特征,目標背景較復雜時,易受干擾,候選框難以選擇。而且由于特征提取時,對圖像做出圖像固定尺寸的處理,可能導致圖像的信息發生改變,對每個感興趣區域進行運算,去除2 000左右冗余框,將耗費大量的時間,R-CNN各個步驟之間關聯不夠緊密,多處運算對已有的運算結果使用不夠充分[6]。
2.1.2 SPP-net算法檢測
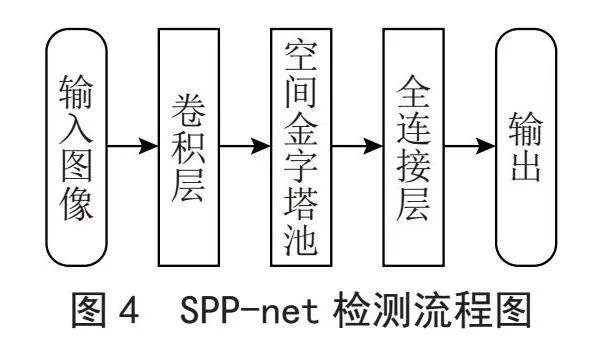
R-CNN人為的對采集圖像大小要求固定一致,會降低待檢測圖像或子圖像的識別精度。He等[7]設計了SPP-net(Spatial Pyramid Pooling Network)算法,其主要思想為:首先,對任意大小的輸入圖像,卷積運算求取目標特征,這些特征具有固定的維數,對于多個目標重疊的區域,不需要重復運算;其次,使用空間金字塔池化策略,對特征加以篩選;最后,將池化篩選結果送到全連接層,對目標加以區分標注,實現目標檢測。在2014年的ImageNet大尺度視覺識別挑戰賽(LSVRC)中,文獻[7]作者團隊在目標檢測和圖像分類方面排名第2和第3優異成績。SPP-net檢測流程圖如圖4所示。
SPP-net使用ZF5作為骨干網絡,與使用AlexNet作為骨干網絡的R-CNN相比,具有稍好的目標檢測精度和更優秀的檢測實時性。他們在VOC 2007數據集上進行測試,SPP-net最好的目標檢測的mAP達到60.9%。使用ZF5作為骨干網絡,每幀圖片目標檢測時間為0.142~0.382 s,處理速度是R-CNN的24~102倍。顯然,SPP-net未對SPP層之前的網絡進行改進,與R-CNN訓練過程相同,訓練過程分為多步且單獨運行,對各個階段運行結果需要獨立保存,耗費巨大的存儲空間;不同大小圖像特征提取后特征具有相同固定的維數,因此,候選框的感受野不同。
2.1.3 Fast R-CNN算法檢測
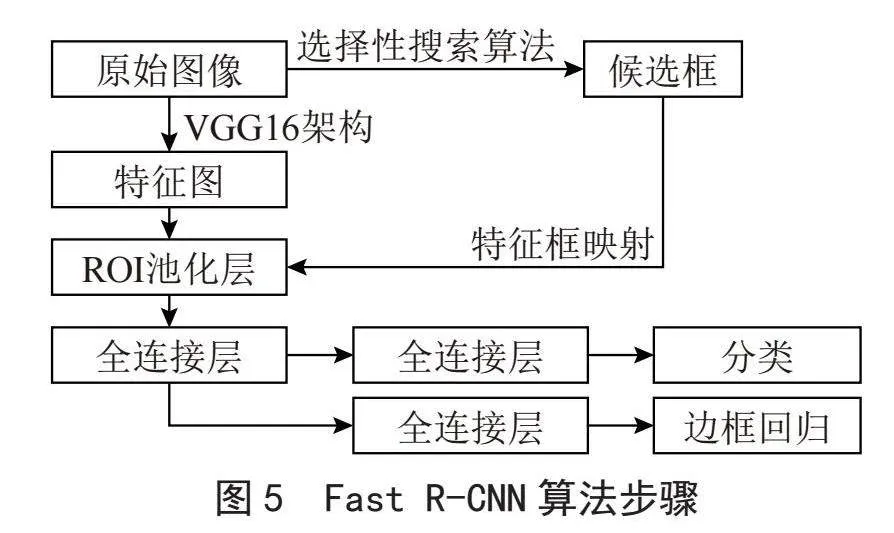
由于SPP-net使用金字塔池化層,使得獲取圖像特征變得更加方便,文獻[8]提出Fast R-CNN算法,其主要思想是:構建VGG16架構,先直接對原圖做一次卷積運算得到特征圖,用Selective Search(選擇性搜索算法)的方法挑選候選區域,用RoI(感興趣區域、感興趣池化層)取代空間金字塔池化層;直接用網格將每個候選區域均勻分成若干個區域塊,對每個塊進行最大值池化,轉變為大小統一的特征向量;然后,放入全連接層中做處理,使用Softmax層代替SVM進行分類,全連接層同時也做回歸任務。其算法步驟如圖5所示。
在VOC 2007數據集上,目標檢測的mAP可達70.0%,每秒可以檢測2幅圖片,FPS為0.5幀。但Fast R-CNN由于使用Selective Search的方法篩選候選區域,花費較多時間,訓練和預測仍需較長時間,實時性檢測受到嚴峻的挑戰。
2.1.4 Faster R-CNN算法檢測
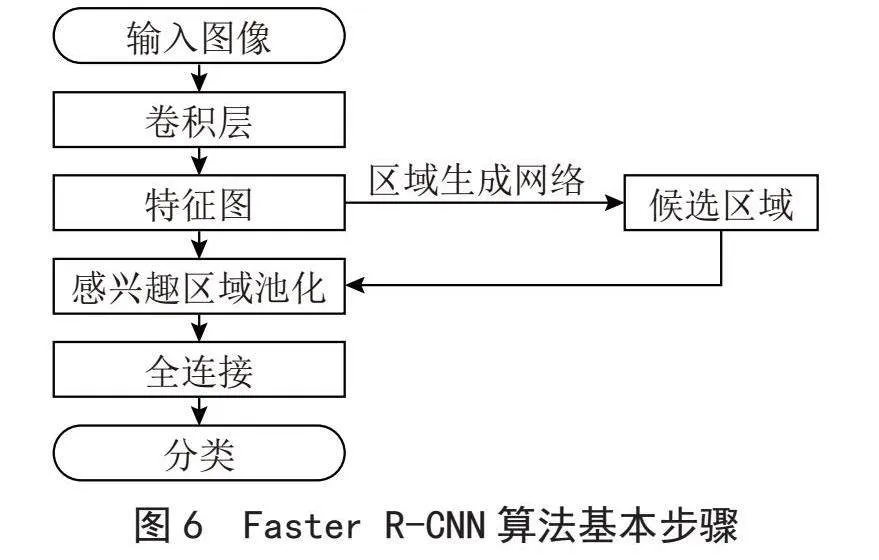
Ren等[9]在Fast R-CNN的基礎上做出改進,提出Faster R-CNN算法,其主要思想是在原圖卷積層后添加區域提取網絡RPN(Region Proposal Network),代替Fast R-CNN的選擇性區域搜索。Faster R-CNN [10]算法基本步驟為:首先,對原始圖像做卷積運算特征提取;其次,在其中的RPN層得到候選區域;最后,共用候選區域與目標監測區域,使用RoI以及全連接輸出最終分類結果。Faster R-CNN算法基本步驟如圖6所示。實驗證明在使用VOC 2007+VOC 2012作為訓練數據集、VOC 2007和VOC 2012作為測試數據集時,Faster R-CNN目標檢測的mAP可達73.2%和70.4%,檢測每幀圖像耗時198 ms,FPS達到5.05幀/秒。
Faster R-CNN比R-CNN提高了目標檢測的mAP和FPS,但仍有不足,主要表現在:使用卷積網絡獲取候選區域,運算量仍然較大;雖然目標檢測速度有提升,但由于正常視頻播放速度為每秒24幀以上,對于實時性檢測仍然有較大的進步空間。
文獻[11]將邊緣檢測分支融入Faster R-CNN當中,并在損失函數中加入物體邊緣損失函數,在RoI Align模塊中使用注意力機制過濾和增強特征,目標檢測的mAP達到98.42%。
2.1.5 Mask R-CNN算法檢測
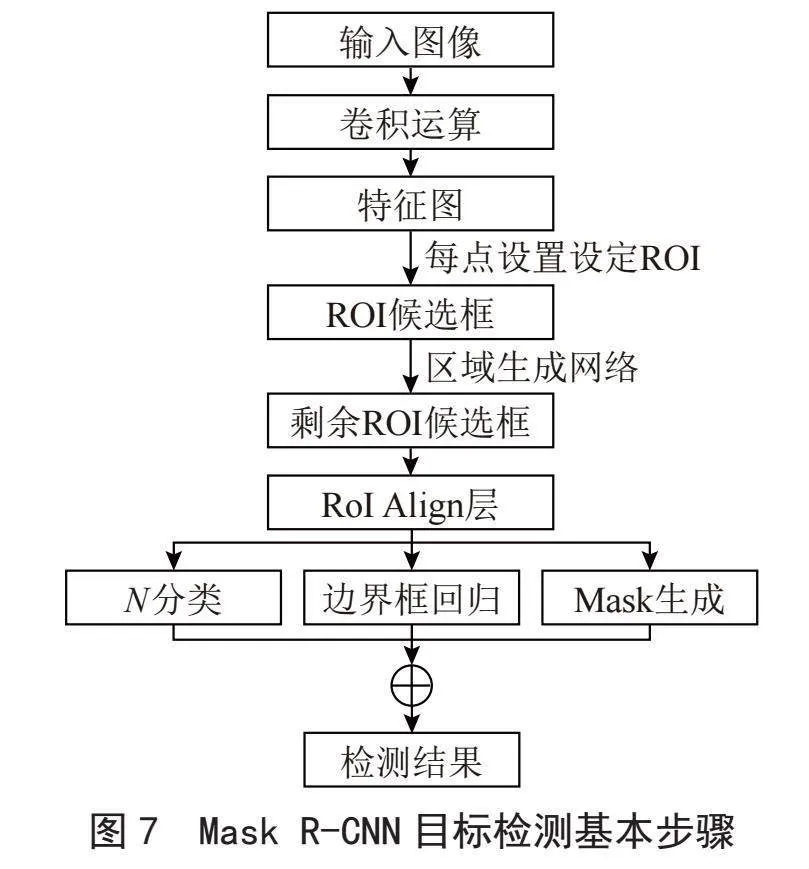
He等[11]對Faster R-CNN進行了擴展,在既有邊界框識別分支的基礎上,增加了一個用于預測物體掩碼的分支,只增加了一個小的開銷更快的R-CNN,很容易推廣到其他目標檢測任務。Mask R-CNN檢測目標基本思想為:Mask R-CNN是在Faster R-CNN的基礎上添加一個預測分割Mask的分支,添加了并列的FCN層(Mask層),目標檢測基本步驟如圖7所示。
通過RoI Align層替換RoI Pooling層,使用雙線性插值來確定非整數位置的像素,從RPN網絡確定的RoI中生成相同大小的較小的特征圖,使得每個感受野取得的特征能更好對齊原圖感受野區域[11]。由于Mask R-CNN網絡通過掩碼對某幀圖像進行空間布局編碼控制,使得目標在空間布局更加準確精細[11],實際上完成了某幀圖像中目標的分割,因此它比Faster R-CNN目標檢測的mAP更好。實驗證明,在COCO數據集上,Mask R-CNN的目標檢測的mAP為39.8%,比Faster R-CNN高了20.1%。但是,Mask R-CNN檢測使用分割分支,致使Mask R-CNN比Faster R-CNN檢測速度慢一些,可完成5幀/秒的圖像檢測。
2.2 二階段目標檢測對比分析
通過以上算法改進過程,可以發現二階段目標檢測mAP提升方法主要有:優化必要的環節,使全范圍內遍歷目標檢測提升為主要特征區域搜索;實現若干環節數據共享,避免重復運算,可大幅度提升算法運行速度;使用新的訓練策略,使算法從各個獨立步驟運算逐步向端到端運算;引進注意力機制以及更接近真實目標的模型進行大量訓練。二階段目標檢測對比如表1所示。
3 一階段目標檢測
二階段目標檢測雖然mAP較高,但算法通常較為復雜,目標檢測耗費時間較長。本節主要分析一階段目標檢測方法,其使用區域目標預測法檢測目標,通過回歸法對目標框計算并加以標注。目前,使用較多的算法主要包括以下幾種。
3.1 一階段主要檢測方法介紹
3.1.1 OverFeat算法檢測
Sermanet等[12]在2014年提出OverFeat算法,將任務分解為分類、定位、檢測三步;首先,他們借鑒AlexNet模型,設計了以快速模型(Fast Model)和準確模型(Accurate Model)為特征的提取器OverFeat。網絡訓練輸入時,每張原圖片大小為256×256,隨機裁剪為221×221作為CNN輸入進行訓練。在測試階段,可使用大小都不相同的圖片進行多尺度輸入預測。對于特征圖,經過重復多次使用非重疊的池化offset pooling后,將其送入分類器。將輸出向量在后面把它們拉成一維向量。在分類任務中,特征提取網絡5層(池化后的)后面接一個回歸網絡來做定位,可在定位的基礎上訓練一個背景區分圖像中有沒有被檢測物體。OverFeat算法在網絡結構方面基本上和AlexNet相同,使用同一卷積神經網絡作為共享的骨架網絡,大幅降低了計算量,是ImageNet大規模視覺識別挑戰賽2013(ILSVRC2013)本地化任務的獲勝者。ILSVRC13測試集檢測結果為:目標檢測的mAP達到24.3%,而檢測速度比R-CNN的快了9倍。
3.1.2 YOLO算法檢測
Redmon等[13-14]提出YOLO(You Only Look Once)算法,使用一次卷積神經網絡完成候選區選取與對象識別,其基本思想為:將被檢測圖像等分分割為S×S個網格塊圖像,每個網格預測K個包圍框。對網格塊內的圖像所屬類別進行概率估算,具有最大概率的類被選擇并分配給特定的網格單元。剔除非最大值的概率類別,實行非最大值抑制算法,完成一個類別的最高概率包圍框。再繼續找到具有下一個最高類別概率的包圍框,直至完成所有類別的分類。YOLO檢測示意圖如圖8所示。
YOLO算法對全圖分割成小塊檢測目標,基本模型使用VOC 2007/2012復合數據集訓練時,目標檢測的mAP為63.4% [14],可完成每秒45幀的圖像處理速度,實現了端到端的目標檢測,基本滿足實時性的要求。
YOLO算法目標檢測的mAP比Fast R-CNN以及Faster R-CNN要低,YOLO算法背景的誤判率為4.75%,而Fast R-CNN誤判率為13.6%,可見YOLO誤判率更優秀。
3.1.3 YOLOv2和YOLO9000算法檢測
Redmon等[15]對YOLO進行改進,在2016年提出YOLOv2和YOLO9000,其主要思想為:他們首先將YOLO的模型改進為YOLOv2,使用DarkNet-19作為基礎網絡,拋棄了全連接,在網絡中做卷積運算后,增加Batch Normalization使網絡更易收斂,使用了跨層連接,網絡訓練變得更容易,YOLOv2模型可以在不同的尺寸下運行。YOLOv2在VOC和COCO數據集上獲得了當時最好的結果,在VOC 2007數據集上,YOLOv2的目標檢測的mAP為76.8%,目標檢測的FPS為67幀/秒;而當目標檢測的FPS為40幀/秒時,目標檢測的mAP為78.6%,在速度和準確性之間輕松實現了折中。
同時文獻[15]分別在COCO目標檢測數據集和ImageNet分類數據集上訓練了YOLO9000,ImageNet驗證集(200類)上目標檢測的mAP為19.7%,可實時檢測超過9 000類別的目標類別。
3.1.4 YOLOv3算法檢測
2018年,Redmon等[15]在YOLOv2和YOLO9000基礎上對原目標檢測算法加以改進,主要體現在:YOLOv3借鑒了ResNet的殘差結構,進一步加深網絡為53個卷積層,即Darknet-53網絡;使用特征金字塔FPN(Feature Pyramid Networks),獲得3層最深層特征,預測各尺度下目標;YOLOv3損失舍棄Softmax函數,而使用Sigmoid函數作為邏輯回歸層判斷函數,進而對每個類別做二分類。
YOLOv3在COCO數據集測試中,測試圖片大小為608×608,當交并比為0.5時,YOLOv3目標檢測的mAP可達57.9%,檢測速度約為20幀/秒。而相同交并比時,RetinaNet算法目標檢測的mAP為57.5%,檢測速度約為5.1幀/秒。YOLOv3可實現一定程度的速度和精度的均衡。
3.1.5 YOLOv4算法檢測
2020年Bochkovskiy等[16]等人提出YOLOv4算法,他們在原有YOLO目標檢測架構上,采用了近些年CNN領域中最優秀的優化策略,在數據處理、主干網絡、網絡訓練、激活函數、損失函數等各個方面都進行了不同程度的優化。算法采用CSPDarkNet-53網絡,并采用PAN(Path Aggregation Network)結構將特征上下融合兩次,核心是采用Cross Stage Partial Network結構,選擇Mish(A Self Regularized Non-Monotonic Neural Activation Function)激活函數,對目標的中心點回歸公式加以微調,定位損失采用的是CIoU損失函數,訓練時采用數據增強Mosaic、cmBN、SAT自對抗訓練等技術。
實驗證明,YOLOv4算法模型檢測速度快且準確率高:在MS COCO數據集上測試的目標檢測的mAP為43.5%,當交并比為0.5時,YOLOv4目標檢測的mAP可達65.7%,且圖像檢測速度可達65幀/秒,實現了速度與精度的較好平衡,其主要缺點是目標檢測預測框誤檢率較高。
3.1.6 SSD算法檢測
考慮到YOLO目標檢測速度較快但精度不高,尤其是小目標檢測精度更不高,Liu等[17]在2015年提出SSD(Single Shot MultiBox Detector)算法,SSD算法借鑒了YOLO將圖像分格的核心思想,具體如下:
1)采用VGG16作為基礎模型,然后在VGG16的基礎上新增了卷積層來獲得更多的特征,不同層的網絡檢測不同尺度的對象,使用大特征圖來檢測小目標,小的特征圖檢測大目標。
2)舍棄YOLO的全連接,直接對不同的特征圖卷積運算進行提取特征,來進行目標檢測。
3)為每個網格設定多個先驗邊界框。
4)訓練時使用了數據增強技術。
5)SSD算法的損失函數由包括位置損失(loc)與類別置信度損失(conf)的加權和構成。
SSD網絡結構如圖9所示。
實驗證明,在VOC、COCO和ILSVRC數據集上,SSD比YOLO具有更高準確性,速度更快,對于300×300輸入,SSD在VOC 2007測試中目標檢測的FPS為59幀/秒,在Nvidia Titan X上實現了74.3%的mAP,對于512×512輸入,SSD實現了76.9%的mAP,高于YOLO的63.4%,高于Fast YOLO的52.7%。但是圖片檢測的FPS為22幀/秒,低于YOLO的45幀/秒,更是遠低于Fast YOLO的155幀/秒,優于可比的最先進的Faster R-CNN模型。與其他單級方法相比,SSD即使在較小的輸入圖像尺寸下也具有更好的精度。
3.1.7 DSSD與FSSD算法檢測
針對SSD對小目標檢測精度不高的問題,Fu等[18]在2017年提出DSSD算法,將Residual-101與快速檢測框架SSD結合,來增強圖像的特征提取能力,用反卷積層增加SSD+Residual-101將低層特征與高層特征融和,提高了目標,尤其是小目標的檢測精度。實驗證明,在VOC和COCO數據集檢測中,513×513輸入DSSD在VOC 2007、VOC 2012、COCO數據集的測試中,DSSD算法目標檢測的mAP分別為81.5%、80.0%、33.2%,在Titan X GPU上目標檢測的FPS為6.6幀/秒,低于SSD檢測速度。
考慮到SSD的特征金字塔檢測方法,使得不同尺度的特征難以融合,Li等[19]將SSD和FPN結合提出FSSD算法,他們設計出一種輕量級的特征融合模塊,將不同層次如低層細節特征與高層的語義特征,以及不同尺度的特征拼接在一起,然后通過一些下采樣塊生成新的特征金字塔,再將其饋送給多盒檢測器,預測最終的檢測結果。輸入圖片大小為300×300時,在VOC 2007測試中,使用單個Nvidia 1080 Ti GPU,FSSD算法可以在65.8幀/秒的速度下實現82.7%的mAP,在小目標上檢測效果優于Faster R-CNN。
3.1.8 DenseBox算法檢測
目前,大多數目標檢測方法都是基于錨框進行目標檢測,但是,越來越多的學者認為該策略存在天然缺陷[20],主要體現在:
1)對錨框信息標注需要過多的參數標注,引進的參數過多,致使目標檢測的向量維數過多。
2)根據目標和錨點的交并比所確定錨框尺寸,以及錨框的回歸坐標都是根據經驗得來,通常不一定是最優的。
3)三是足夠高召回率需要大量的錨點,致使運算量大幅度增加,而大部分錨點對檢測結果都是無用的。
4)錨框導致正負樣本不均衡,正樣本數量會遠遠小于負樣本。
早在2015年,Huang等[21]就提出一種無錨框的DenseBox算法,算法不再預設錨框,直接預測物體的邊界框,即對輸入圖像的每一個像素,計算像素點到所在的物體四周邊界的距離,以及隸屬不同目標物體類別的概率,最后取最大值,篩選最優邊框,實驗證明算法,在公共基準數據集MALF人臉檢測和KITTI汽車檢測中,對中檔車的平均檢測精度可達85.74%。
3.1.9 CornerNet算法檢測
Law等[22]于2020年提出CornerNet算法,使用單一卷積神經網絡將物體邊界框作為一對關鍵點(左上角和右下角)進行檢測,即將對象作為成對的關鍵點進行檢測。CornerNet算法架構包含3部分:環面網絡、右下角和左上角的熱圖、預測模塊。實驗證明,在MS COCO數據集上目標檢測的mAP達到42.2%。
3.1.10 CenterNet算法檢測
CornerNet算法角點精度以及準確性直接影響標記目標的邊界框的質量,在CornerNet的目標檢測中,常遇到大量不正確的對象邊界框的情況,考慮到角點生成的區域內部仍包含重要信息,Duan等[23]提出CenterNet算法,設計出3種Backbone的網絡結構,CenterNet算法將左上角、右下角和中心點綜合考慮,對物體框進行預測判斷,同時預測角點和中心點,他們認為角點定義的預測框內應包含中心點,否則舍棄該預測框。實驗證明在MS-COCO數據集上,CenterNet目標檢測的mAP達到47.0%。
3.2 一階段目標檢測對比分析
隨著目標檢測研究的不斷深入,使用無錨框目標檢測[24-29]的研究也越來越多。一階段目標檢測算法對比如表2所示。
4 結 論
目前,目標檢測從傳統的通過研究少量圖像中背景與對象的區別與聯系加以分割檢測,逐漸轉向通過人工智能設計框架,使用大量數據集訓練,得到訓練網絡,進而對目標進行檢測。
提高目標檢測的mAP與FPS,是目標檢測中是兩個相對矛盾的參數,這也與應用場景需求有關。如在無人駕駛中,檢測速度要求放在第一位,而在文字檢測、橋梁裂痕及信號燈檢測等方面,目標檢測精度放在首位。綜合眾多參考文獻,提高目標檢測精度與提高目標檢測速度的思路主要包括:
1)構建高質量的目標檢測數據集。提高數據集質量、數量,建立更適合目標檢測場景的數據集;增強已有數據集的利用效率、深度。
2)設計更優秀骨干網絡,甚至在輕人工干預下,實現骨干網絡設計。將VGG、GoogleNet以及ResNet等網絡結構應用于目標檢測中,使得系統的特征提取能力大幅提升,可見,骨干網絡性能的好壞,直接影響特征提取能力。注意到Transformer自注意力機制較強,Facebook AI的研究者便把Transformer用到了目標檢測任務中,形成DETR(Detection Transformer),其效檢測效果與Faster R-CNN相比擬。
3)可通過錨點、交并比閾值、動態卷積、邊界框損失函數等更細節的層面來提升目標檢測的精度、速度。
4)基于GAN的目標檢測為目標檢測提供新的思路。
目標檢測除了精度、速度之外,主要還有以下難點:
1)當前目標檢測對小目標的檢測還不夠理想。無人機航拍、衛星遙感、紅外目標識別、高空拋物、自動駕駛等領域對小目標檢測有很強的需求。小目標圖像往往面臨著分辨率低、像素少、訓練數據難以標記,尤其在數據處理過程中,信息容易弱化甚至丟失等問題,都亟待解決。
2)目前的目標檢測基本都是在封閉數據集內對目標檢測。如何對未知物體在開放環境進行目標檢測也是一個難點。
3)多場景、領域目標檢測。目前,目標算法基本只針對特定領域、一定場景下對特定目標物進行檢測,應用場景單一,多領域目標檢測是一個極具挑戰的應用。
相信在不久的將來,隨著人們對基于深度學習技術的不斷深入研究,對目標檢測技術的不斷探索,其應用領域會更加廣泛,為人類的生產生活發展帶來更大的價值。
參考文獻:
[1] KRIZHEVSKY A,SUTSKEVER I,HINTON G E. ImageNet Classification with Deep Convolutional Neural Networks [J].Communications of the ACM,2017,60(6):84-90.
[2] DING L,LI H Y,HU C739a3b51819e8ad18c9003821139b507 M,et al. AlexNet Feature Extraction and Multi-Kernel Learning for Objectoriented Classification [C]//The ISPRS Technical CommissionⅢ Midterm Symposium on “Developments, Technologies and Applications in Remote Sensing”.Beijing:[s.n.],2018,42:277-281.
[3] 劉宇昊.基于Faster R-CNN的水下小目標檢測識別技術研究 [D].大連:大連理工大學,2021.
[4] GIRSHICK R,DONAHUE J,DARRELL T,et al. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation [C]//2014 IEEE Conference on Computer Vision and Pattern Recognition.Columbus:IEEE,2014:580-587.
[5] 孟祥澤.基于深度卷積神經網絡的圖像目標檢測算法現狀研究綜述 [J].數字技術與應用,2021,39(1):112-116.
[6] 李柯泉,陳燕,劉佳晨,等.基于深度學習的目標檢測算法綜述 [J].計算機工程,2022,48(7):1-12.
[7] HE K M,ZHANG X Y,REN S Q,et al. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2015,37(9):1904-1916.
[8] GIRSHICK R. Fast R-CNN [C]//2015 IEEE International Conference on Computer Vision (ICCV).Santiago:IEEE,2015:1440-1448.
[9] REN S Q,HE K M,GIRSHICK R,et al. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,39(6):113-1149.
[10] ZHAO K,WANG Y N,ZHU Q,et al. Intelligent Detection of Parcels Based on Improved Faster R-CNN [J/OL]. Applied Sciences,2022,12(14):7158(2022-07-15).https://doi.org/10.3390/app12147158.
[11] HE K M,GKIOXARI G,DOLLáR P,et al. Mask R-CNN [C]//2017 IEEE International Conference on Computer Vision (ICCV).Venice:IEEE,2017:2980-2988.
[12] SERMANET P,EIGEN D,ZHANG X,et al. OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks [J/OL].arXiv:1312.6229 [cs.CV].[2023-11-20].https://doi.org/10.48550/arXiv.1312.6229.
[13] JOSEPH R,DIVVALA S,GIRSHICK R. You Only Look Once: Unified,Real-Time Object Detection [C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Las Vegas:IEEE,2016:779-788.
[14] REDMON J,FARHADI A. YOLO9000: Better, Faster, Stronger [C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Honolulu:IEEE,2017:6517-6525.
[15] REDMON J,FARHADI A. YOLOv3: An Incremental Improvement [J/OL].arXiv:1804.02767 [cs.CV].(2018-04-08).https://arxiv.org/abs/1804.02767.
[16] BOCHKOVSKIY A,WANG Q-C,LIAO H-Y M. YOLOv4: Optimal Speed and Accuracy of Object Detection [J/OL].arXiv:2004.10934 [cs.CV].(2020-04-23).https://arxiv.org/abs/2004.10934.
[17] LIU W,ANGUELOV D,ERHAN D,et al. SSD: Single Shot MultiBox Detector [J/OL].arXiv:1512.02325 [cs.CV].[2023-11-08].https://arxiv.org/abs/1512.02325.
[18] FU C-Y,LIU W,RANGA A,et al. DSSD: Deconvolutional Single Shot Detector [J/OL].arXiv:1701.06659 [cs.CV].[2023-11-18].https://arxiv.org/abs/1701.06659.
[19] LI Z X,YANG L,ZHOU F Q.FSSD: Feature Fusion Single Shot Multibox Detector [J/OL].arXiv:1712.00960 [cs.CV].[2023-11-18].https://arxiv.org/abs/1712.00960.
[20] ZHU C C,HE Y H,SAVVIDES M. Feature Selective Anchor-Free Module for Single-Shot Object Detection [J/OL].arXiv:1903.00621 [cs.CV].[2023-11-16].https://arxiv.org/abs/1903.00621.
[21] HUANG L C,YANG Y,DENG Y F,et al. DenseBox: Unifying Landmark Localization with End to End Object Detection [J/OL].arXiv:1509.04874 [cs.CV].[2023-11-16].https://arxiv.org/abs/1509.04874.
[22] LAW H,DENG J. CornerNet: Detecting Objects as Paired Keypoints [J].International Journal of Computer Vision ,2020,128:642-656.
[23] DUAN K W,BAI S ,XIE L X,et al. CenterNet: Keypoint Triplets for Object Detection [J/OL].arXiv:1904.08189 [cs.CV].[2023-11-16].https://arxiv.org/abs/1904.08189.
[24] PIAO Z Q,WANG J B,TANG L B,et al. Anchor-Free Object Detection with Scale-Aware Networks for Autonomous Driving [J/OL].Electronics,2022,11(20):3303[2023-11-17].https://doi.org/10.3390/electronics11203303.
[25] LI Q M,BI Y Q,CAI R S,et al. Occluded Pedestrian Detection Through Bi-Center Prediction in Anchor-Free Network [J].Neurocomputing,2022,507:199-207.
[26] XIANG Y,ZHAO B X,ZHAO K,et al. Improved Dual Attention for Anchor-Free Object Detection [J].Sensors,2022,22(13):4971-4971.
[27] LIU Y,ZHANG Y,WANG Y X,et al. A Survey of Visual Transformers [J].IEEE Transactions on Neural Networks and Learning Systems,2023:1-21.
[28] 王迪聰,白晨帥,鄔開俊.基于深度學習的視頻目標檢測綜述 [J].計算機科學與探索,2021,15(9):1563-1577.
[29] WU X W,SAHOO D,HOI S C H. Recent Advances in Deep Learning for Object Detection [J].Neurocomputing,2020,396:39-64.
作者簡介:朱克佳(1982—),男,漢族,安徽阜陽人,講師,碩士研究生,研究方向:圖像處理、智能控制、機器視覺、人工智能。
