基于多尺度判別模塊的細粒度圖像分類
2024-09-19 00:00:00陳冰冰
現(xiàn)代信息科技 2024年13期


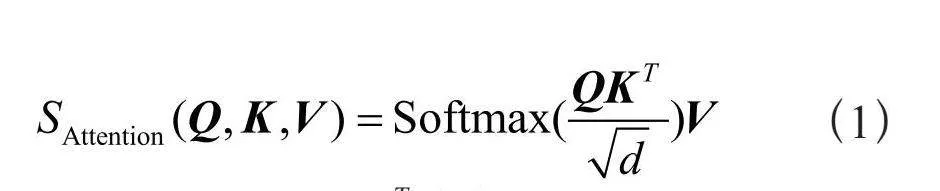


摘 要:為了提高混合架構(gòu)在細粒度圖像分類領(lǐng)域的性能,設(shè)計提出了一個判別模塊(DM),該模塊包括兩個部分:判別性特征選擇(DFS)和多尺度特征聚合(MFA)。DFS模塊通過選取Vision Transformer(ViT)中不同注意力頭中Top-K個鳥類物種的代表性特征以關(guān)注不同區(qū)域特征,促進不同判別區(qū)域的協(xié)同效應,同時減少特征冗余。MFA模塊聚合不同尺度的鳥類判別性特征信息。在開源的鳥類細粒度數(shù)據(jù)集上進行了實驗證明,并與現(xiàn)有方法進行了比較。實驗結(jié)果表明,所提出的模塊在鳥類細粒度圖像識別方面取得了一定的改進。
關(guān)鍵詞:細粒度圖像分類;判別性特征選擇;協(xié)同效應
中圖分類號:TP183 文獻標識碼:A 文章編號:2096-4706(2024)13-0040-07
Fine-grained Image Classification Based on Multi-scale Discrimination Module
CHEN Bingbing
(School of Computer Science and Mathematics, Fujian University of Technology, Fuzhou 350118, China)
Abstract: In order to improve the performance of hybrid architecture in the field of fine-grained image classification, a Discriminant Module (DM) is proposed, which consists of two parts: Discriminant Feature Selection (DFS) and Multi-scale Feature Aggregation (MFA). By selecting the representative features of Top-K bird species in different attentional heads in Vision Transformer (ViT), the DFS module pays attention to the characteristics of different regions, promotes the synergistic effect of different discriminating regions, and reduces the feature redundancy. The MFA module aggregates discriminant characteristics information of birds at different scales. The experimental proof is carried out on an open source bird fine-grained dataset and compared with existing methods. The experimental results show that the proposed module has achieved some improvement in bird fine-grained image recognition.
Keywords: fine-grained image classification; discriminant feature selection; synergistic effect
0 引 言
鳥類細粒度圖像識別是計算機視覺領(lǐng)域的重要任務(wù)。同時,該任務(wù)對于瀕危鳥類的保護和研究具有重要意義。然而,背景干擾和鳥類姿勢的任意性等因素增加了鳥類細粒度圖像識別的挑戰(zhàn)。為了解決該問題,本文提出了建立在混合架構(gòu)的基礎(chǔ)上的判別模塊(DM),該模塊可以更準確地刻畫鳥類物種之間的差異,同時避免特征冗余和過擬合問題。
1 細粒度圖像分類
鳥類作為自然界的重要家庭成員,在全球生態(tài)系統(tǒng)中發(fā)揮著至關(guān)重要的作用。有效可行的細粒度鳥類圖像分類可以實現(xiàn)鳥類物種的準確識別,便于鳥類種群分布的檢測,從而更好地了解鳥類生態(tài)和保護需求。然而,鳥類物種之間的外觀差異往往很小,并且一些亞種之間的差異是細微的。因此,準確的鳥類識別通常需要詳細的特征比較,如顏色、形狀和紋理,這使得鳥類細粒度圖像分類成為一項具有挑戰(zhàn)性的任務(wù)。由于細粒度圖像類間差異小,類內(nèi)差異大,不能簡單地應用粗粒度圖像識別的方法來進行細粒度圖像識別。為了解決這個問題,研究人員傾向于在圖像中識別具有判別性特征的信息區(qū)域,利用部件標注信息,或利用額外的輔助數(shù)據(jù)。總體上可分為定位分類子網(wǎng)絡(luò)、外部信息輔助、端到端特征編碼三類方法[1]。
早期的定位分類子網(wǎng)絡(luò)方法利用部件標注、邊界框[1]等輔助信息幫助網(wǎng)絡(luò)快速定位圖像中的關(guān)鍵區(qū)域,如圖1所示。近年來,大多數(shù)研究轉(zhuǎn)向采用區(qū)域建議網(wǎng)絡(luò)作為區(qū)域提取器[2]。一旦選擇了圖像區(qū)域,它們就會被調(diào)整為預定義的大小,并輸入到骨干網(wǎng)絡(luò)中,以學習更多信息豐富的局部特征。然而,這種機制忽略了所提出區(qū)域的子部分之間的關(guān)系,并且容易生成覆蓋大部分對象的邊界框,這使得難以捕獲有效的細粒度特征以用于最終的對象識別。此外,兩階段網(wǎng)絡(luò)會使整個訓練過程復雜化,并傾向于提供次優(yōu)性能。
圖1 CUB-200-2011數(shù)據(jù)集示例
基于外部信息的方法中常用的輔助信息包括網(wǎng)絡(luò)圖像數(shù)據(jù)和多模態(tài)數(shù)據(jù)[3]。眾所周知,人工采集和標注圖像的成本很高,因此利用互聯(lián)網(wǎng)上海量的圖像資源進行數(shù)據(jù)擴充是很自然的事情。此外,圖像的文本描述,如地理位置信息,也有助于細粒度圖像分類。值得注意的是,這些外部來源提供的信息質(zhì)量是未知和不可控的,有些信息可能與任務(wù)無關(guān)甚至有害。因此,需要額外的工作和成本來處理這些負面影響。
近年來,Vision Transformer(ViT)[4]因其在圖像分類等任務(wù)中的出色表現(xiàn)而受到廣泛關(guān)注。ViT通過以相對較大的固定尺寸表示特征,可以在粗粒度圖像識別中獲得較高的精度。然而,對于本文所考慮的鳥類細粒度識別等任務(wù),期望能夠準確地檢測局部區(qū)域信息并適當?shù)乇硎酒渲邪呐袆e性特征。Li等人通過精心設(shè)計的金字塔結(jié)構(gòu)取得了令人鼓舞的進展,有效地實現(xiàn)了局部到全局的注意力機制[5]。它是一種“CNN+ViT”的隱式混合架構(gòu),能夠捕捉局部特征,同時建模局部圖像區(qū)域之間的遠程關(guān)系,特別適合細粒度圖像任務(wù)。在局部和全局特征協(xié)同提取成功的基礎(chǔ)上,本文進一步嘗試自適應地檢測和表示與最終分類相關(guān)的關(guān)鍵局部區(qū)域。具體來說,該研究構(gòu)建了一個判別模塊DM來識別多個尺度上的判別區(qū)域,使用三個開源的鳥類細粒度基準數(shù)據(jù)集來驗證所提出的方法。
2 多尺度混合架構(gòu)與判別性特征提取
2.1 多尺度混合架構(gòu)
CNN基于局部感知的歸納偏置和平移不變性,通過卷積和池化操作,在實現(xiàn)局部特征提取、降維的同時,很好地保留了圖像的空間結(jié)構(gòu)信息。相比之下,ViT通過自注意力機制提取和整合全局信息,可以更好地提供圖像中的全局語義信息。在ViT中,全局視圖非常重要,而一些重要的局部細節(jié)可能會被忽略。為了充分發(fā)揮兩種網(wǎng)絡(luò)結(jié)構(gòu)的優(yōu)勢,CNN與ViT相結(jié)合的想法應運而生。例如,Liu等人提出了Swin Transformer [6],它具有分層設(shè)計和滑動窗口。通過計算窗口內(nèi)的注意力,增強了ViT對相關(guān)圖E37R5Ir+VohmSTYCpHkZjg==像局部性的表征能力,降低了計算成本。Peng等人開發(fā)了Conformer [7],其中包括并行的CNN和Transformer分
支,并利用特征耦合模塊集成局部和全局特征,同時保留圖像細節(jié)。與這種并行架構(gòu)不同的是,CvT [8]首
先用卷積token embedding取代了原始ViT的position embedding位置嵌入,卷積token embedding本質(zhì)上是一個卷積層,然后用卷積投影代替線性投影得到自注意力機制所需的Q、K和V。為了增強局部區(qū)域信息特征的表示和提取能力,CMT [9]特別設(shè)計了兩個模塊,即局部感知單元(local Perception Unit, LPU)和逆殘差前饋網(wǎng)絡(luò)(Inverse Residual Feedforward Network, IRFFN)。最近,Diao等人提出了MetaFormer [3],它提供了一種簡單而有效的方法來聯(lián)合學習視覺和各種元信息。其中,MetaFormer [3]包括五個階段,前三個階段通過CNN引入歸納偏置對視覺信息進行編碼,后兩個階段通過ViT將視覺信息與元信息融合。這里的元信息是指涉及圖像的文本描述或時空信息等。由于其簡單性和SOTA性能,我們將使用MetaFormer作為主干,但不使用額外的元信息。
2.2 判別性特征提取
Zhang [10]等人在經(jīng)典的R-CNN(Regions with CNN features)框架的基礎(chǔ)上,提出了一種基于部件的R-CNN(Part R-CNN),用于細粒度的類別檢測。具體來說,Part R-CNN首先通過選擇性搜索算法生成大量的多尺度物體或物體部位的候選框,然后利用部位標注和邊界框分別訓練身體、頭部和軀干的三種檢測模型。最后,該模型通過從檢測到的物體和單個部位提取特征來進行分類。類似的工作,如Branson [11]或Huang [12]等人通過使用部件注釋和邊界框來快速定位關(guān)鍵部件,以便進行最終分類。與上述依賴人工標記信息來尋找圖像中判別部分的方法不同,Yang [13]等人提出了一種自監(jiān)督模型,具體地說,構(gòu)建了包含Navigator Agent、Teacher Agent和Censorship Agent的Navigator-Teacher-Censorship Network(NTS-Net)。Navigator可以在Teacher的指導下檢測出信息量最大的判別區(qū)域,而prospeczer則對Navigator生成的區(qū)域進行檢查并做出最終的預測。Fu [14]等人設(shè)計了一種循環(huán)注意力卷積神經(jīng)網(wǎng)絡(luò)(Recurrent Attention Convolution Neural Network, RA-CNN),在迭代過程中迭代搜索關(guān)鍵區(qū)域并逐漸縮小焦點區(qū)域,使模型聚焦于判別部分,最后從整個迭代過程中產(chǎn)生的所有尺度的焦點區(qū)域中提取特征并融合進行預測。其中,Zheng [15]等人提出了一種多注意卷積神經(jīng)網(wǎng)絡(luò)(MA-CNN),通過聚類具有相似響應區(qū)域的通道來獲得判別區(qū)域。
3 方法設(shè)計
3.1 MetaFormer模型
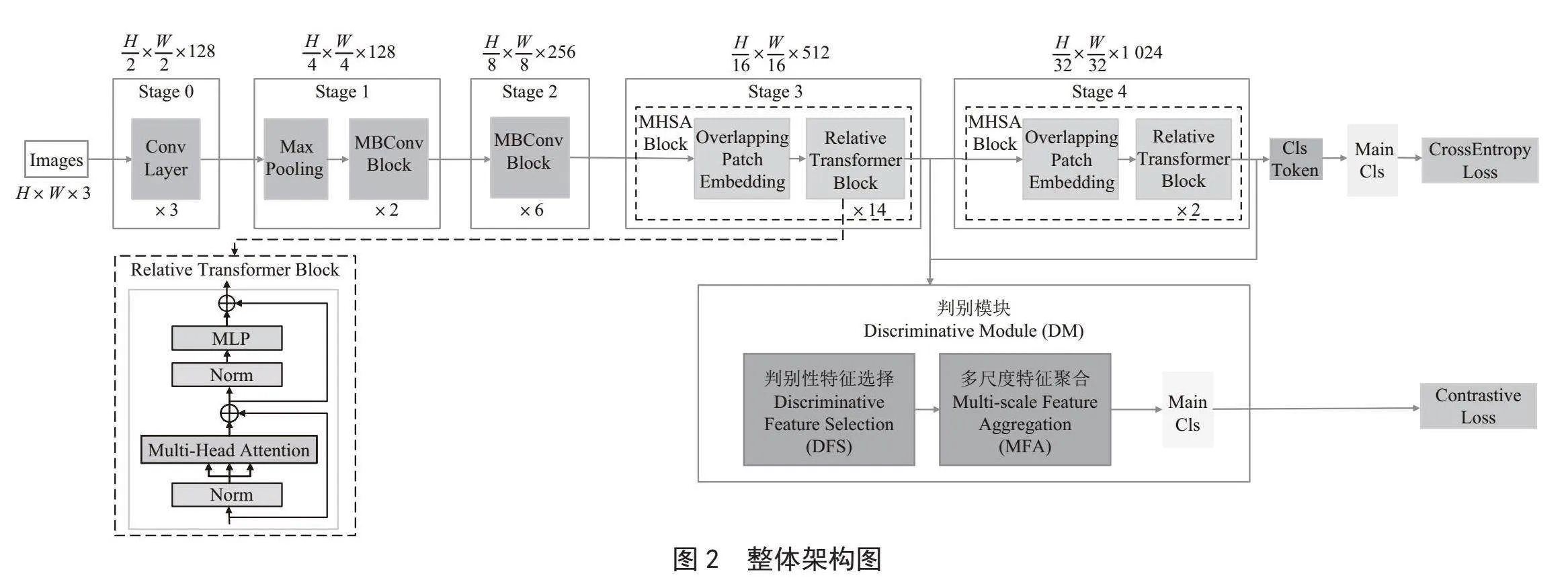
如圖2所示,MetaFormer模型由5階段{S0,S1,S2,S3,S4}組成。在每個階段的開始,減少圖片的輸入尺寸并增加通道數(shù)量以實現(xiàn)多尺度布局。第一階段S0是一個簡單的3層卷積,S1和S2是具有squeeze-excitation模塊的MBConv塊。S3和S4是ViT-based的MHSA塊,包括Overlapping Patch Embedding和Relative Transformer Block。
ViT首先將圖片分割成一個個小的圖像patch塊,并將這些patch塊通過token embedding進行tokenization得到image token。除了這些image token之外,還插入一個特殊的類token(簡稱cls token)來聚合用于最終分類的全局圖像信息。cls token和image token通過concat操作連接在一起。每個圖像塊的位置信息通過位置嵌入進行疊加。然后將這些tokens輸入到由多個編碼器塊組成的transformer encoder中,每個編碼器塊包括多頭自注意力(MSA)和多層感知器(MLP)。在MSA中,每個token被線性映射到一個維度為d的嵌入空間,并進一步打包成三個矩陣,即Q、K和V。注意力計算操作如下所示:
注意力圖 表示輸入的tokens之間的關(guān)系。特別地,注意力圖的第一行對應于cls token相對于所有其他token的注意力,這反映了每個token對最終分類的重要性。然后將多個自注意頭的輸出送入到MLP中。MLP由兩個全連接層組成,中間有一個GELU激活函數(shù)。在一系列堆疊的transformer塊之后,提取cls token并將其用于最終分類。
3.2 判別模塊DM
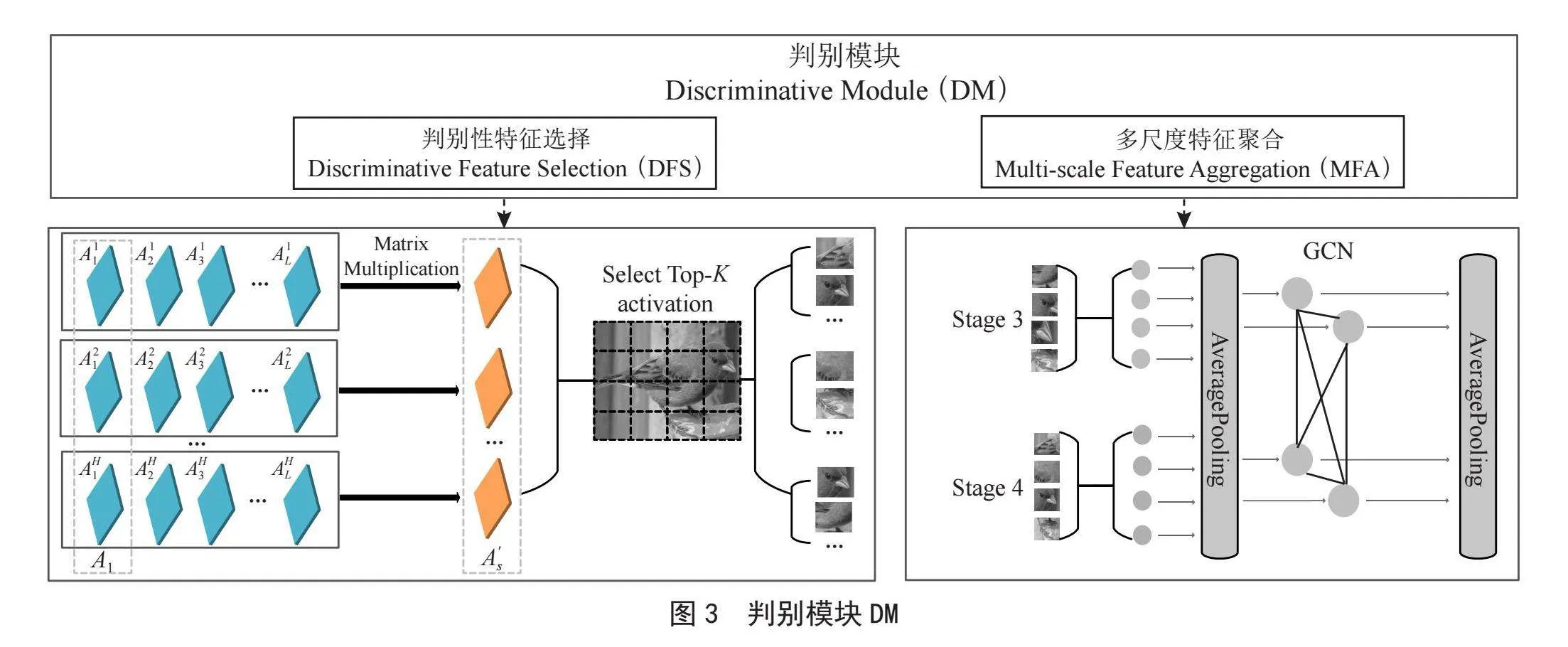
圖3展示了判別模塊DM的整體設(shè)計,DM包括判別性特征選擇DFS和多尺度特征聚合MFA。
3.2.1 判別性特征選擇(DFS)
在細粒度圖像分類中,最具挑戰(zhàn)性的問題是如何識別細微特征,為最終分類提供關(guān)鍵的判別性信息。實際上,多頭注意力機制提供了有價值的線索,每個注意頭集中在不同的圖像區(qū)域,為最終任務(wù)進行特征提取。在本文中,我們充分利用了注意力圖在多階段設(shè)置中的潛力。
具體來說,S3和S4階段分別有L = 14、2層Transformer encoder,每層Transformer encoder有H = 8個自注意力頭。為簡潔起見,我們省略了階段或?qū)拥木唧w索引。特別地,讓z = [z0;z1,…,zN]表示輸入特征,其中N表示token的總數(shù)量,z0表示cls token。第l層的特征表示可以寫成如下:
其中 表示層歸一化操作。式(2)中MSA的注意力權(quán)值可以表示為:
(3)
其中 表示第l層中第i個頭的cls token所對應的注意力權(quán)重, 表示第l層中第i個頭的第j個token所對應的注意力權(quán)重。
如我們所知,cls token的注意力圖表示每個token對最終分類的重要性。基于cls token的注意力權(quán)值來表示判別性信息是很自然的,即:
然而,使用單個層(例如最后一層)提供的注意力權(quán)重可能無法很好地表示token之間的相對重要性。因此,這里我們利用同一階段多個層的注意力權(quán)值遞歸相乘得到的權(quán)重,即:
考慮到不同token之間的判別性特征的協(xié)同效應,選擇多個token對應的判別性特征是合理的,而不是只選擇信息量最大的特征。具體來說,根據(jù)cls token的權(quán)重值,即 中的 ,我們選擇得分中的top-K個token,令I(lǐng) (ik)表示第k塊信息token在第i個頭中的索引,即:[I (i1),…,I (ik),…,I (iK)]。因此,所選擇的特征表示可以寫成:
在每個階段,按照這種方式,可以選擇最重要的top-K個特征,這可以確保過濾掉混亂的背景,同時保留可以為細粒度任務(wù)提供細微差異的局部特征。
3.2.2 多尺度特征聚合(MFA)
當從不同階段選擇了判別性特征后,需要融合這些多尺度特征來完成最終任務(wù)。眾所周知,圖卷積網(wǎng)絡(luò)(GCN)[16]可以對圖數(shù)據(jù)進行有效的表示學習,并且可以很好地處理缺失或有噪聲的數(shù)據(jù)。在這里,我們利用GCN的優(yōu)勢,將從多個階段選擇的每個patch作為一個節(jié)點,考慮多個patch之間的關(guān)系來學習特征表示。為了自動捕獲節(jié)點之間的相關(guān)性,我們使用了基于可學習自適應鄰接矩陣的GCN。具體來說,我們將從每個階段選擇的特征進行連接和池化以獲得 ,并分別使用卷積層從 中提取節(jié)點特征qGCN和kGCN:
然后,我們初始化一個可學習的自適應鄰接矩陣 ,用較小的值表示每對節(jié)點之間的初始相似度,并引入注意力機制。具體來說,我們對 和 進行維度擴展,得到 和 。每個 和每個 之間的相似度是通過 與 之間的差值并通過Tanh()激活函數(shù)得到的,從而得到注意力權(quán)值 :
同時,引入了一個權(quán)重系數(shù) 來調(diào)節(jié)權(quán)重。最終自適應鄰接矩陣 的表示如下:
將 送入使用自適應鄰接矩陣 的單層GCN后,得到新的節(jié)點特征:
最后,將所得到的特征送入分類頭用于最終的分類。在損失計算時,將原始的特征用于交叉熵損失計算,將經(jīng)過DM模塊后的特征用于對比損失。最終的損失由交叉熵損失和對比損失共同構(gòu)成。
4 實驗設(shè)置與結(jié)果
為了驗證該方法的有效性,我們在三個開源的鳥類基準數(shù)據(jù)集上進行了一系列實驗。我們首先介紹了數(shù)據(jù)集和訓練超參數(shù)的設(shè)置,然后介紹和討論了所提出的模型和相關(guān)基線模型的實驗結(jié)果。
4.1 數(shù)據(jù)集和實驗設(shè)置
我們使用三個開源鳥類細粒度數(shù)據(jù)集NABirds [17]、CUB-200-2011 [18]和Ningxia-Birds [19]數(shù)據(jù)集作為基準進行實驗。NABirds總共包含555個鳥類類別,每個類別分別有大約40~60個訓練樣本和測試樣本。CUB-200-2011總共包含200個鳥類類別,每個類別平均分別有30個左右的訓練和測試樣本。Ningxia-Birds是一個細粒度的寧夏野生鳥類分類數(shù)據(jù)集,在過去兩年中以開源的方式發(fā)布。Ningxia-Birds共收錄了206個鳥類分類,每個分類平均有60個左右的樣本。所有圖像都調(diào)整為384×384以適應模型。
MetaFormer及其在iNaturalist 2021上預訓練的權(quán)重被用作我們模型的主干。訓練超參數(shù)和優(yōu)化器設(shè)置為與MetaFormer相同。即我們使用AdamW作為優(yōu)化器,并采用cosine decay learning rate scheduler余弦衰減學習率,其中學習率初始化為5×10-5,權(quán)值衰減為0.05。我們還使用了MetaFormer使用的數(shù)據(jù)增強和正則化策略。在挑選判別性特征時其中Top-K激活區(qū)域的K值對于CUB-200-2011分別設(shè)置為2,對于NABirds和Ningxia-Birds分別設(shè)置為3。我們進行300 epoch的訓練迭代微調(diào)。所有實驗均使用Nvidia GeForce RTX3090進行,并使用PyTorch作為工具。
4.2 實驗結(jié)果
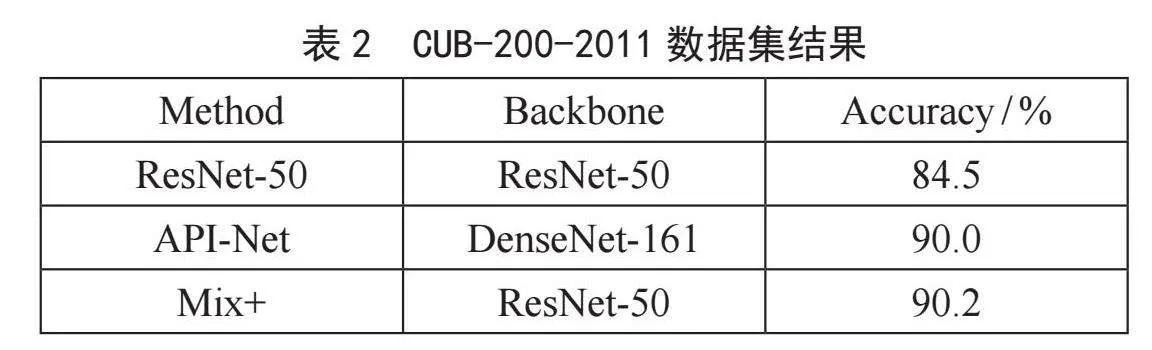
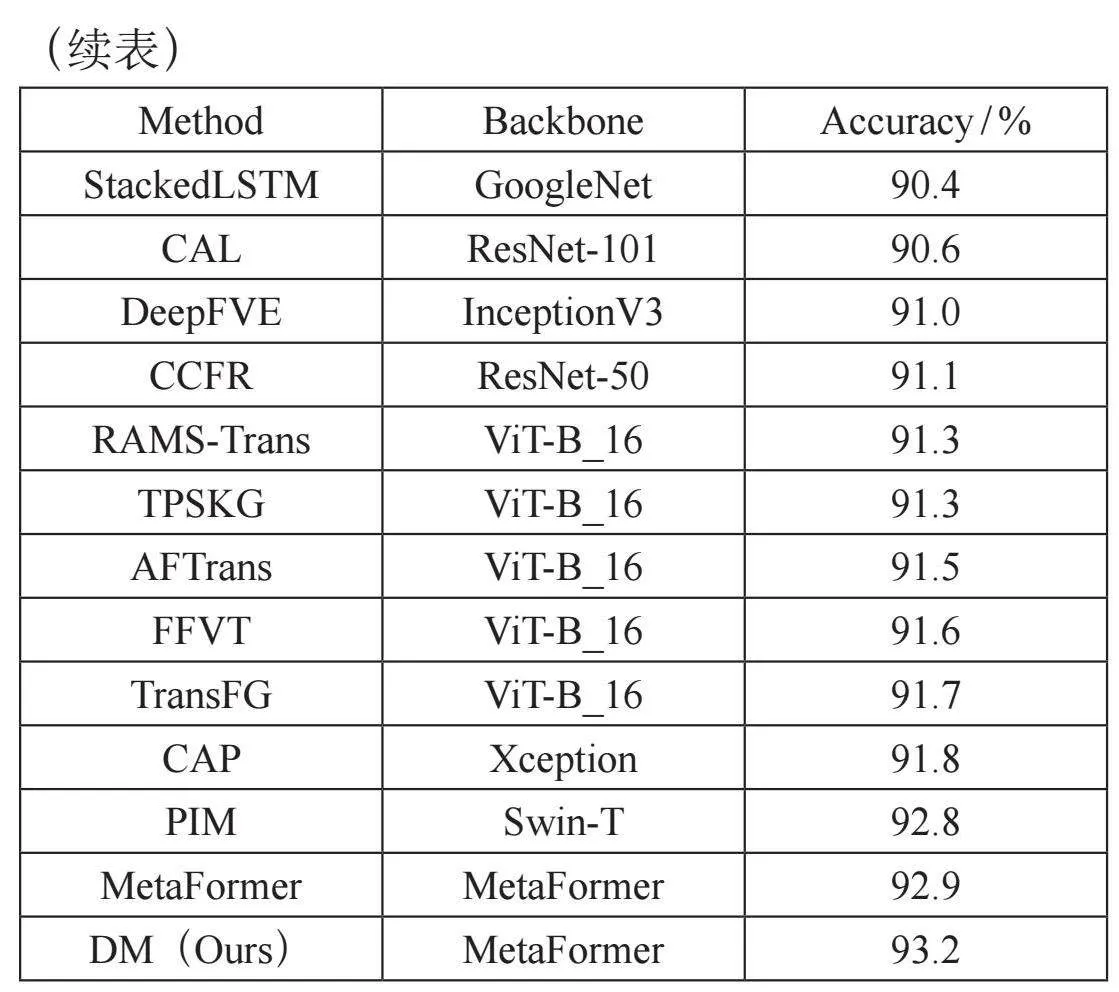
表1給出了所提出的模型和相關(guān)SOTA模型在NABirds上的分類精度,其中可以發(fā)現(xiàn),我們的模型DM達到了93.5%的精度,比MetaFormer提供的最后一個SOTA額外提高了0.5%。表2顯示了在CUB-200-2011上的實驗結(jié)果。我們的模型在其他基線上也可以觀察到類似的改進:DM達到了93.2%的精度,比最新的SOTA高0.3%。表3顯示,所提出的DM在Ningxia-Birds上可以達到96.7%,比MetaFormer高0.2%。結(jié)果表明,本文提出的DM可以進一步提高混合架構(gòu)MetaFormer的性能。
4.3 消融實驗
4.3.1 Top-K的設(shè)置
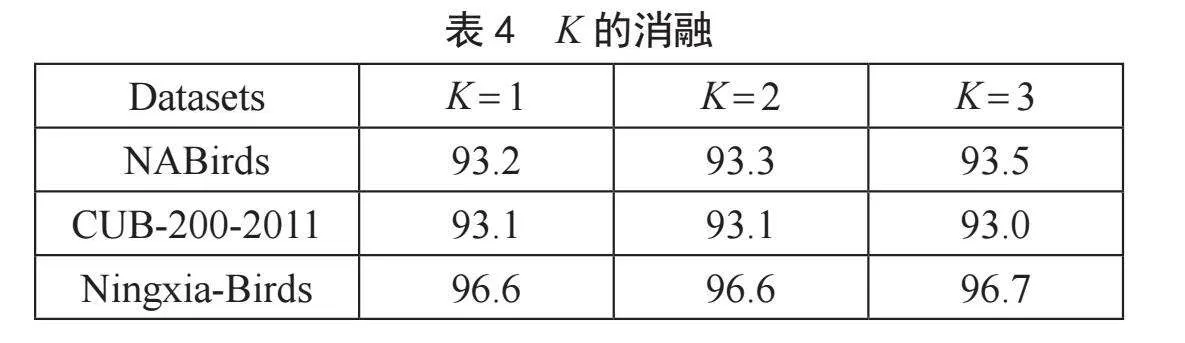
為了研究Top-K的最優(yōu)值,我們討論了不同的設(shè)置(即K = 1,2,3),并在三個數(shù)據(jù)集上進行了消融實驗。實驗結(jié)果如表4所示。從表4可以看出,不同的K值對不同的數(shù)據(jù)集有不同的影響。在NABirds數(shù)據(jù)集中,當K = 3時獲得最佳結(jié)果。在CUB-200-2011數(shù)據(jù)集中,當K = 1或K = 2時獲得了可比的結(jié)果。而在寧夏鳥類數(shù)據(jù)集中,當K = 3時,獲得的結(jié)果略好。從這些結(jié)果可以得出,使用大于1的K值可以帶來一定的改善,這也證明了我們提出的方法的有效性。在區(qū)分細微差異時,僅使用判別能力最強的patch往往是不夠的,需要使用判別能力較弱的K的輔助協(xié)同效應。
4.3.2 DM的影響
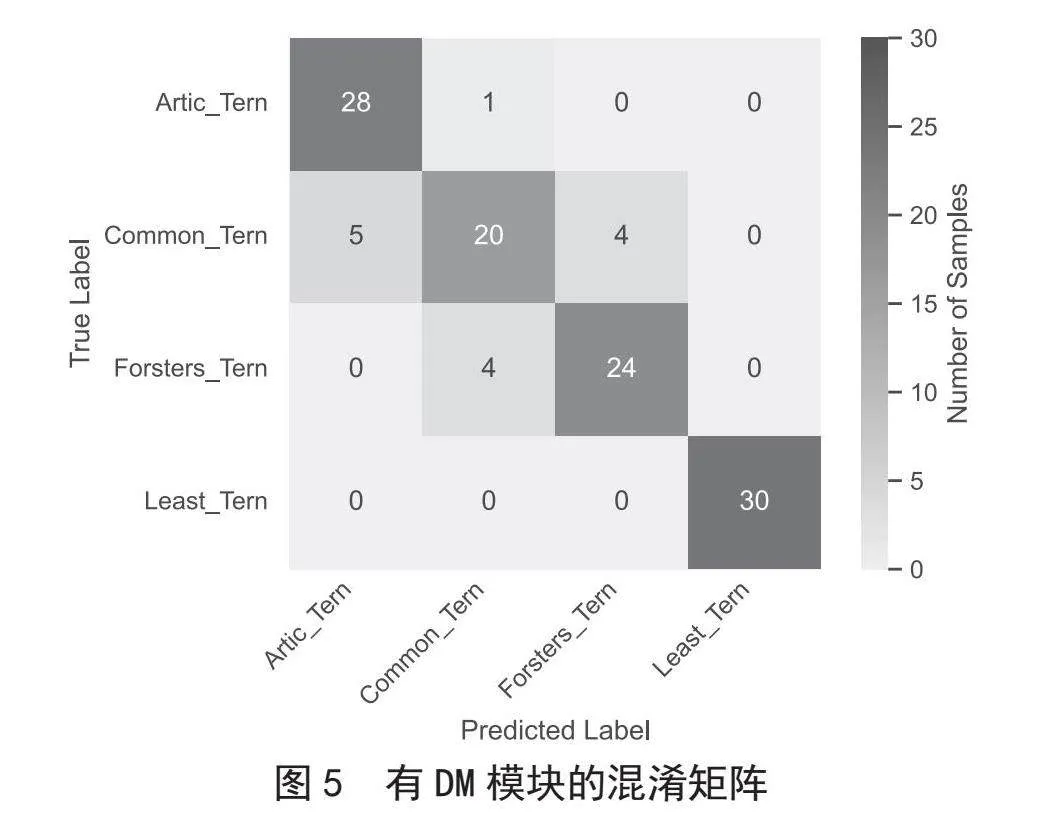
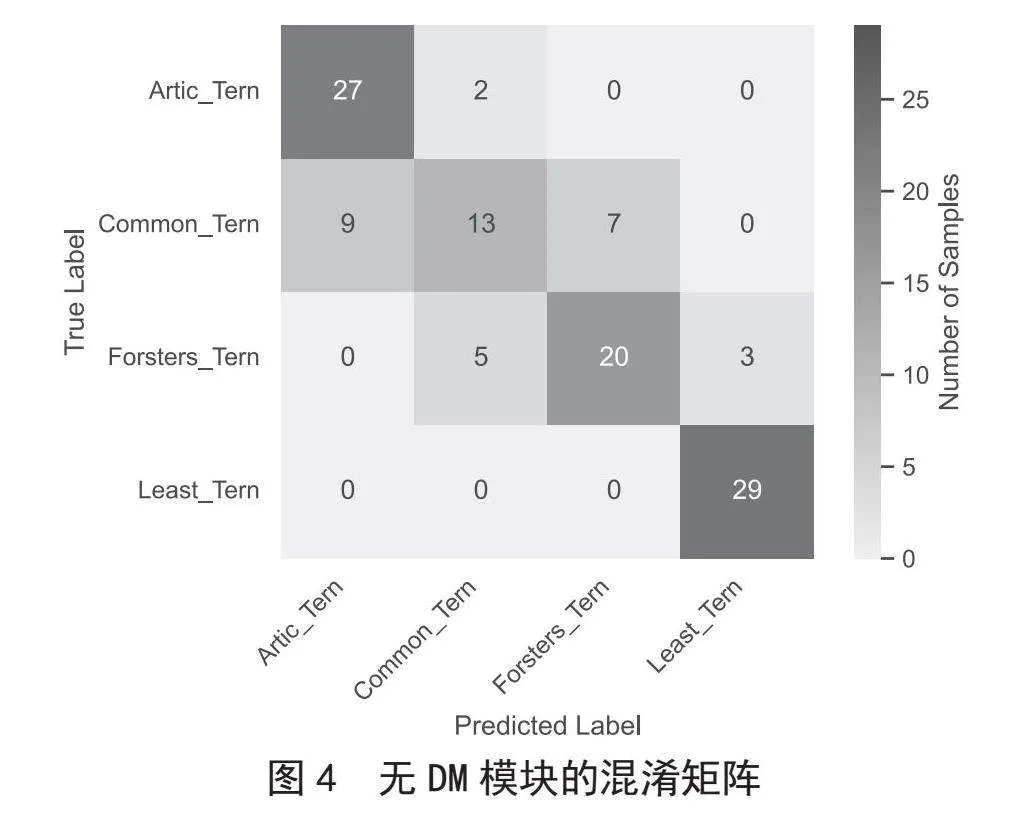
為了更好地證明所提出的DM模塊的有效性,我們繪制了混淆矩陣來顯示DM模塊帶來的改進。我們在CUB-200-2011數(shù)據(jù)集上進行了消融實驗。圖4顯示了無DM模塊的原始MetaFormer模型對四個極其相似的子類別的混淆矩陣,而圖5顯示了有DM模塊的MetaFormer模型對相同的四個子類別的混淆矩陣。混淆矩陣對角線上的數(shù)字表示正確分類的樣本數(shù)量,其他數(shù)字表示錯誤分類的樣本數(shù)量。對角線區(qū)域的顏色越深,模型正確分類的樣本越多。從圖4和圖5中我們可以看到,帶有DM模塊的MetaFormer可以提高區(qū)分細微差異的能力。雖然DM并沒有完全糾正錯誤分類,但它仍然在一定程度上減少了模型錯誤的數(shù)量。我們認為DM不能完全糾正錯誤分類的原因是圖所示的四個子類別具有非常相似的特征,需要很高的分辨率才能發(fā)現(xiàn)一些細微的差異,甚至有些人可能很難用肉眼區(qū)分。
5 結(jié) 論
在混合架構(gòu)的細粒度圖像分類任務(wù)中,我們設(shè)計的判別模塊DM在三個開源的鳥類細粒度圖像分類數(shù)據(jù)集上取得了一定的提升。通過選取注意力頭中Top-K個鳥類代表性特征,有效地提高了對不同區(qū)域的關(guān)注度,促使不同判別區(qū)域協(xié)同工作。同時聚合不同尺度的特征信息,增強了鳥類判別性特征的多樣性。總體而言,我們的方法讓混合架構(gòu)在細粒度圖像分類任務(wù)上向前又邁了一步。在未來,我們也希望尋找并設(shè)計更好的方案來解決該任務(wù)。
參考文獻:
[1]WEI X-S,WU J X,CUI Q. Deep Learning for Fine-grained Image Analysis: A Survey [J/OL].arXiv:1907.03069 [cs.CV].(2019-07-06).https://arxiv.org/abs/1907.03069.
[2] REN S Q ,HE K M,GIRSHICK R,et al. Faster R-CNN: Towards Real-time Object Detection with Region Proposal Networks [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,39(6):1137-1149.
[3] DIAO Q S,JIANG Y,WEN B,et al. MetaFormer: A Unified Meta Framework for Fine-grained Recognition [J/OL].arXiv:2203.02751 [cs.CV].(2022-03-05).http://arxiv.org/abs/2203.02751.
[4] DOSOVITSKIY A,BEYERL L,KOLESNIKOV A,et al. An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale [J/OL].arXiv:2010.11929 [cs.CV].(2020-10-22).https://arxiv.org/abs/2010.11929.
[5] LI J P,YAN Y C,LIAO S C,et al. Local-to-global Self-attention in Vision Transformers [J/OL].arXiv:2107.04735 [cs.CV].(2021-07-10).https://arxiv.org/abs/2107.04735.
[6] LIU Z,LIN Y T,CAO Y,et al. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows [C]//2021 IEEE/CVF International Conference on Computer Vision(ICCV).Montreal:IEEE,2021:9992-10002.
[7] PENG Z L,HUANG W,GU S Z,et al. Conformer: Local Features Coupling Global Representations for Visual Recognition [J/OL].arXiv:2105.03889 [cs.CV].(2021-05-09).http://arxiv.org/abs/2105.03889.
[8] WU H P,XIAO B,CODELLA N,et al. CvT: Introducing Convolutions to Vision Transformers [C]//2021 IEEE/CVF International Conference on Computer Vision (ICCV).Montreal:IEEE,2021:22-31.
[9] GUO J Y,HAN K,WU H,et al. CMT: Convolutional Neural Networks Meet Vision Transformers [C]//2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).New Orleans:IEEE,2022:12165-12175.
[10] ZHANG N,DONAHUE J,GIRSHICK R,et al. Part-based R-CNNs for Fine-grained Category Detection [C]//Computer Vision-ECCV 2014.Zurich:Springer,2014:834-849.
[11] BRANSON S,HORN G V,BELONGIE S,et al. Bird Species Categorization Using Pose Normalized Deep Convolutional nets [J/OL].arXiv:1406.2952 [cs.CV].(2014-06-11).https://arxiv.org/abs/1406.2952.
[12] HUANG S L,XU Z,TAO D C,et al. Part-stacked CNN for Fine-grained Visual Categorization [C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Las Vegas:IEEE,2016:1173-1182.
[13] YANG Z,LUO T G,WANG D,et al. Learning to Navigate for Fine-grained Classification [J/OL].arXiv:1809.00287 [cs.CV].(2018-09-02).https://arxiv.org/abs/1809.00287v1.
[14] FU J L,ZHENG H L,MEI T. Look Closer to See Better: Recurrent Attention Convolutional Neural Network for Fine-grained Image Recognition [C]//2017 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Honolulu:IEEE,2017:4476-4484.
[15] ZHENG H L,F(xiàn)U J L,MEI T,et al. Learning Multi-attention Convolutional Neural Network for Fine-grained Image Recognition [C]//2017 IEEE International Conference on Computer Vision(ICCV).Venice:IEEE,2017:5219-5227.
[16] KIPF T N,WELLING M. Semi-supervised Classification with Graph Convolutional Networks [J/OL].arXiv:1609.02907 [cs.LG].(2016-09-09).https://arxiv.org/abs/1609.02907.
[17] HORN G V,BRANSON S,F(xiàn)ARRELL R,et al. Building a Bird Recognition APP and Large Scale Dataset with Citizen Scientists: The Fine Print in Fine-grained Dataset Collection [C]//2015 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Boston:IEEE,2015:595-604.
[18] WAH C,BRANSON S,WELINDER P,et al. The Caltech-UCSD Birds-200-2011 Dataset [DB/OL].(2011-07-01).https://www.vision.caltech.edu/datasets/cub_200_2011/.
[19] 魏銘辰,劉立波,王曉麗.2020—2021年寧夏野生鳥類細粒度分類研究圖像數(shù)據(jù)集 [J].中國科學數(shù)據(jù):中英文網(wǎng)絡(luò)版,2022,7(3):142-148.
作者簡介:陳冰冰(1999—),女,漢族,福建莆田人,碩士在讀,研究方向:細粒度圖像識別、自監(jiān)督學習。
