基于申威SIMD指令的H.264編碼優化
2024-09-14 00:00:00黃樸劉世巍張昊王聰
現代電子技術 2024年6期




摘 "要: 國產化申威處理器出現較晚,其在多媒體領域中的性能還不突出,同時通用處理器中的單指令流多數據流(SIMD)因能有效提升并行處理能力而受到處理器廠商的青睞。為提高國產化自主平臺申威架構的多媒體處理能力,結合申威架構Core3B體系的SIMD指令系統,提出一種基于申威架構的SIMD指令集H.264編碼優化方法。結合申威處理器的并行結構特點,利用申威適配的Perf、Top指令等系統性能分析工具,采集兩種主流視頻分辨率下與編碼性能強相關的高頻熱點函數,詳細分析其程序并行化可行性,采用手工嵌入申威SIMD和訪存擴展等匯編指令進行細粒度優化。實驗結果表明,該方法在申威架構下的H.264平均編碼性能提升了約30%。相應工作成果已推送到申威社區,增強了基于申威處理器的國產計算機在桌面多媒體應用領域的工作體驗。
關鍵詞: 單指令流多數據流; H.264標準; 申威處理器; 熱點函數; 程序并行化; 細粒度
中圖分類號: TN911?34; TP3 " " " " " " " " " " " 文獻標識碼: A " " " " " " " " " " 文章編號: 1004?373X(2024)06?0049?06
H.264 encoding optimization based on SW SIMD instruction
HUANG Pu, LIU Shiwei, ZHANG Hao, WANG Cong
(CETC Suntai Information Technology Co., Ltd., Wuxi 214000, China)
Abstract: Domestic Shenwei processors emerged relatively late, and their performance in the multimedia field is not yet outstanding. At the same time, single instruction multiple data (SIMD) in general?purpose processors are favored by processor manufacturers for effectively improving parallel processing capabilities. In order to improve the multimedia processing capability of the domestic independent platform Shenwei architecture, a SIMD instruction set H.264 encoding optimization method based on the Shenwei architecture is proposed by combining with the SIMD instruction system of the Core3B system of the Shenwei architecture. Based on the parallel structure characteristics of the Shenwei processor, high?frequency hotspot functions strongly related to encoding performance under two mainstream video resolutions are collected by means of system performance analysis tools such as Perf and Top instructions adapted by Shenwei. The experimental results show that this method can improve the average encoding performance of H.264 under the Shenwei architecture by about 30%, and the corresponding work results have been pushed to the Shenwei community, enhancing the work experience of domestic computers based on Shenwei processors in the field of desktop multimedia applications.
Keywords: SIMD; H.264 standard; Shenwei processor; hotspot function; program parallelization; fine grained
0 "引 "言
單指令流多數據流(Single Instruction Multiple Data, SIMD)是計算機處理器中的一種指令集架構,主要用于執行并行計算[1]。為提升CPU的圖形圖像數據處理能力,SIMD架構被廣泛應用于各種類型的計算機處理器中,包括常見的桌面和移動設備處理器[2?3]。
申威是我國自主設計、具有完全自主知識產權的64位字長Load/Store型RISC架構多核處理器[4]。經過多年發展,申威形成了Core3B核心處理器指令系統,包括基本指令系統和SIMD擴展指令系統。所有指令均采用定長的32位格式,支持32位單精度和64位雙精度浮點運算,支持256位單指令流多數據流(SIMD)的短向量運算,通過指令集適配優化,可以大幅度提升系統性能。
盡管H.265已發布多年,但H.264仍是目前市場應用最廣泛的視頻編解碼標準[5]。對該編解碼算法的結構并行性研究,主要集中在X86和ARM平臺上[6?7],而在國產化CPU平臺上的相關研究還不多見[2],大部分為針對解碼器或濾波模塊的優化工作。文獻[8]介紹了基于開源編碼器匯編優化幀內預測的率失真代價計算過程。文獻[9]設計了一種基于4×4基本塊復用的18路預測模式并行的高吞吐量全流水線硬件架構。文獻[10]完成了視差估計算法的并行映射。文獻[11]設計了一種新的幀內率失真優化預測模式的并行流水線硬件架構。
本文針對申威威焱831平臺特點,基于Core3B SIMD指令優化了H.264視頻編碼器的處理效率,工作成果已推送到申威開源社區,為加快國產申威計算機的圖形化應用發揮了積極作用。
1 "申威SIMD技術
目前,程序向量化通常由兩種途徑來實現:其一是利用編譯器自身的功能實現程序的自動向量化,即編譯器經過對程序的依賴分析、對齊分析等自動把標量代碼轉變成相應的向量化指令,從而實現程序的并行計算;其二是手工向量化,開發人員利用SIMD程序接口或使用內嵌匯編的方法,通過SIMD擴展的體系結構和指令集,對串行程序重新進行向量化程序的編寫,在一定程度上省去編譯器進行向量化分析查找后端指令等工作,并且對性能提升有明顯效果。本次研究主要基于威焱831處理器,使用手工嵌入式匯編的方式將普通程序替換為申威SIMD指令來提升多媒體程序性能。
1.1 "申威SIMD概述
申威處理器提供了200多條指令來實現 SIMD的功能,支持浮點雙256位SIMD流水線和整數單256位SIMD流水線。
1.2 "數據類型、寄存器與指令擴展
C3B核心擴展指令系統設置有32個256位向量寄存器,與浮點寄存器文件共用地址,其低64位即是浮點寄存器;向量寄存器與浮點寄存器在硬件實現上不同,但是在匯編代碼中的表示格式是相同的。此外所有寄存器均以字符$開頭,所以在匯編代碼中向量寄存器和浮點寄存器均以$f0~$f31表示。
C3B核心支持短向量數據類型,包括長度為8的字整數向量(8×32位)、長度為4的單精度浮點向量(4×32位)與雙精度浮點向量(4×64位),還有限支持長度為32的字節整數向量(32×8位)、長度為16的半字整數向量(16×16位)、長度為4的長字整數向量(4×64位)以及256位的8倍字整數數據。
C3B的擴展指令系統較為全面,在多媒體優化中經常用到的指令包括加法減法指令、可重構邏輯運算指令、位移指令、條件判斷選擇指令以及裝入和存儲指令等。
1.3 "向量化限制
理論上來說,對于完全SIMD向量化的程序,32×8 的向量運算性能可以達到標量的8倍,64×4的向量運算性能可以達到標量的4倍。但是,程序向量化通常存在以下限制,因此很難做到完全SIMD向量化。
首先是硬件限制:向量化受限于硬件的限制。在 SIMD擴展中,向量化訪存操作必須是地址連續的,且要求32字節對界。因此,雖然有些循環是可向量化的,但具體針對威焱831體系結構,需要進行程序變換后才能向量化。
1) 循環結構的限制:循環必須是只有一個入口和一個出口時才能被向量化。
2) 更有效的使用Cache:高效地使用各級Cache對于性能的提高是極為重要的,一級Cache中訪問數據的速度比主存儲器中訪問數據快數十倍。為了更好地使用Cache,程序需要盡量使用同一個Cache行的所有數據而不是各不同Cache行的部分數據,而且程序最好能在數據被替換出Cache以前盡量多地重用這些數據。當然,為了從SIMD部件中獲得性能的提升,也要求程序最好訪問連續的內存區域,這一點來講,Cache與SIMD 部件對程序的要求是一樣的。
3) 對界問題:大部分情況下,申威架構下使用擴展存儲與裝入指令進行變量映射的時候,需要保證標準類型變量為32字節對界。若進行了不對界訪存,程序運行時,系統需要不斷處理該訪存引起的異常,這將極大拖慢程序與系統的運行速度。數據Cache中跨32字節的不對界訪存如圖1所示。
上述三個問題的處理,1)關系到能否實施向量化,2)、3)則是向量化后能否發揮預期性能的關鍵。
2 "FFmpeg的H.264編碼優化
2.1 "H.264視頻編碼標準
H.264(AVC)視頻編碼標準作為目前應用最廣的標準意義非凡,其既能帶來較高的壓縮率,又能保證編碼質量,在安防、直播等視頻領域都有很廣泛的應用。
從編碼途徑上分類,視頻編碼可分為硬件編碼和軟件編碼。硬件編碼依靠專門的解碼芯片,編碼效率高;軟件編碼則可以支持不同的視頻編解碼標準,系統兼容性好,當然軟件編碼對CPU的性能要求也較高。目前基于H.264標準的媒體應用最廣泛,因此從實用性角度看,優化H.264的軟件編碼效率,性價比最高。
2.2 "H.264編碼器優化實現
FFmpeg是一套完善的開源的音視頻處理軟件框架[12],編譯時可集成x264庫。在申威處理器上,其H.264編碼流程由通用分支基于高級語言實現,雖然具有格式兼容性好和算法升級靈活的優勢,但單純依靠CPU性能,編碼效率較低。
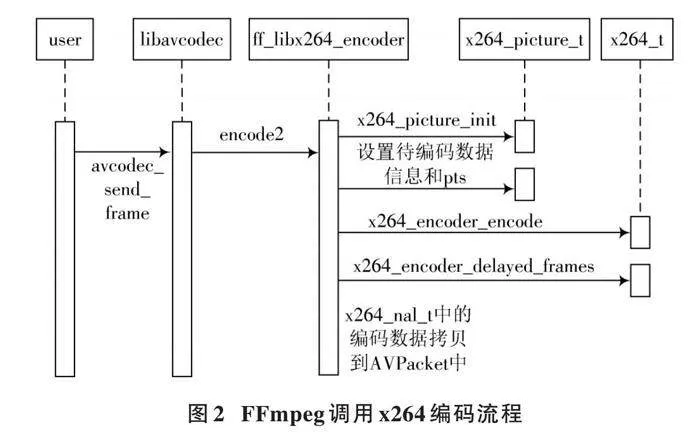
FFmpeg調用x264的流程如圖2所示。圖中,用戶傳入命令參數后,解析指令、進行查找編碼器等操作,由avcodec_open2打開編碼器接口進入編解碼器部分,隨后初始化x264編碼器并進行相關配置;其次是編碼階段,由avcodec_alloc_frame()函數為編碼幀分配內存,av_read_frame()函數從碼流中讀取幀數據,判斷幀類型后調用avcodec_encode_video()函數編碼;最后是收尾階段,釋放數據內存、編碼器和關閉輸入文件。
2.2.1 "性能瓶頸分析
x264的編碼運算主要集中在x264_encoder_encode()函數,可細分成: 幀間和幀內預測、變換與量化、濾波、熵編碼四部分。H.264碼流的基本單位是NALU(碼流單元),分為多種類型,比如:圖像數據分片(Slice)、增強信息(SEI)、序列參數集(SPS)、圖像參數集(PPS)。一個Slice分片通常由多個宏塊(MB)組成,宏塊是編碼運算處理的基本單位。
1) 幀間和幀內預測:幀間預測指利用視頻時間域相關性,使用鄰近已編碼圖像像素預測當前圖像的像素,以達到有效去除視頻時間域冗余的目的。由于視頻序列通常包括較強的時間域相關性,因此預測殘差值接近于0。將殘差信號作為后續模塊的輸入進行變換、量化、掃描及熵編碼,可實現對視頻信號的高效壓縮,核心函數是x264_mb_analyse_inter_*()。
幀內預測則是利用圖像內空間域相關性,使用已編碼像素預測圖像鄰近像素,以達到有效去除圖像空間域冗余的目的,其核心函數是x264_mb_analyse_intra()。
2) 變換與量化:變換編碼將圖像時域信號變換成頻域信號,在頻域中圖像信號能量大部分集中在低頻區域,相對時域信號,碼率有較大的下降。H.264對圖像或預測殘差采用4×4整數離散余弦(DCT)變換技術。
量化過程就是根據圖像的動態范圍大小確定量化參數,既保留圖像必要的細節,又可以減少碼流。在圖像編碼中,變換編碼和量化從原理上講是兩個獨立的過程;但在H.264中,將兩個過程中的乘法合二為一,并進一步采用整數運算,減少編解碼的運算量,提高圖像壓縮的實時性,這些措施對峰值信噪比(PSNR)的影響很小,一般低于0.02 dB,可不計。
宏塊編碼函數x264_macroblock_encode是完成變換與量化的主要函數。
3) 濾波:H.264視頻編碼標準中,在編解碼器反變換量化后,圖像會出現方塊效應,盡管H.264采用較小的4×4變換尺寸,可以降低這種不連續現象,但仍需要一個去方塊濾波器,以最大程度提高編碼性能。在x264中,x264_slice_write()函數中調用x264_fdec_filter_row()的源代碼,x264_fdec_filter_row()對應著x264中的濾波模塊。
4) 熵編碼:熵編碼函數x264_macroblock_write_cabac()或x264_macroblock_write_cavlc()讀取碼流數據,進行CABAC或CAVLC熵編碼。
在申威平臺上,通過性能分析發現,編碼過程絕大多數CPU性能消耗在幀內預測、運動補償、DCT變換、濾波等過程運算上。另外,在視頻輸出方面,大量的數據拷貝操作同樣消耗了不少的CPU時間。
表1統計了CPU占比的熱點函數,并刪掉了其中不滿足向量化限制性條件的內容。
針對上述分析,在申威平臺上進行編碼器優化的流程如圖3所示。首先,使用性能分析工具perf記錄編碼全程的高頻熱點函數;其次,逐項分析熱點函數,在滿足向量化限制條件的基礎上研究并行化方法;然后采用SIMD指令以嵌入式匯編手段重構熱點函數,包括循環展開、數據分組打包、并行運算等步驟;最后結合申威流水線特點,考慮指令延遲及循環間隔等因素,進一步調整指令流,減少因數據相關而引入的不必要延遲,使用更高效的指令進行替換。如果性能結果不滿意,則繼續查找新的優化點,重復上述過程。
2.2.2 "優化實現
1) SIMD優化。利用微處理器的并行部件,SIMD技術通過一條指令對一組數據進行相同的操作,從而完成之前需要多條指令才能完成的處理任務。以方塊濾波函數x264_pixel_sad_16×16為例,其通用分支代碼實現和采用SIMD擴展指令將內層循環進行并行優化后的代碼如下:
//C代碼節選
for( int y = 0; y lt; ly; y++ )
{
for( int x = 0; x lt; lx; x++ )
{
i_sum+=abs(pix1[x]?pix2[x]);
}}
//并行化改造
for(int y = 0; y lt; ly; y++) {
for(int i = 0,x = 0;i lt; idx ; i++,x+=8){
_asm_ _volatile_(
\"VLDD $f2,0(%0)\n\t\"
\"VLDD $f3,0(%1)\n\t\"
\"VSUBW $f3,$f2,$f4\n\t\"
\"VSUBW $f2,$f3,$f5\n\t\"
\"VSELLTW $f4,$f5,$f4,$f6\n\t\"
\"VSTD $f6,0(%2)\n\t\"
:
:\"r\"(amp;v_pix1[x]),\"r\"(amp;v_pix2[x]),\"r\"(amp;v_result)
:);}}
其中v_pix1、v_pix2為源代碼中像素數據pix1及pix2轉換并進行對齊操作的向量數組。使用VLDD指令加載到向量寄存器$f2、$f3后,使用VSUBW指令進行v_pix1-v_pix2、vpix2-v_pix1減法操作。將二者的差值分別存儲到$f4、$f5,通過指令VSELLTW判斷$f4向量中每個元素的值,如果小于0則選取$f5中相應元素的值;否則,將$f4相應元素的值存儲至$f6。最終使用VSTD指令將結果$f6儲存至對齊數組v_result中,該數組的各元素之和即為源代碼中的i_sum。內層循環一次可操作8個數據,整體來看循環次數減少為原來的[18],有效提升了性能。
又如子函數x264_clip_pixel()被2的整數倍次調用,改造時需先展開再進行并行化改造,同時其運算完全由位運算、加減法及條件判斷組成,是比較理想的可改寫函數。其代碼如下:
//簡化C代碼
for( int y = 0; y lt; i_h; y++, dst += i_dst, src += i_src)
for( int x = 0; x lt; i_w; x++ )
dst[x] = x264_clip_pixel(x);
// x264_clip_pixel()
x264_clip_pixel(x){
return ((xamp;~A)?(?x)gt;gt;31amp;A;x;
}
其中x = src[x]*A + B;
for( y = 0; y lt; i_height; y++, dst += i_dst_stride, src += i_src_stride ){
for( x = 0; x lt; j; x++ ){
for( i = 0; i lt; 8; i++){
tmp_res[i] = src[i+off] * scale;}
_asm_ _volatile_(
\"VLDD $f10,0(%0)\n\t\"
\"VLDD $f11,0(%1)\n\t\"
\"VADDW $f10,$f11,$f12\n\t\"
\"VSTD $f12,0(%2)\n\t\"
:
:\"r\"(amp;tmp_res),\"r\"(amp;tmp_offset),\"r\"(amp;tmp_dst)
:);
_asm_ _volatile_(
\"VLDD $f10,0(%0)\n\t\" " " " " " " " " " " " " " " " " " "http://tmp_dst
\"VLDD $f11,0(%1)\n\t\" " " " " " " " " " " " " " " "http://PIXEL_MAX
\"VLDD $f12,0(%2)\n\t\" " " " " " " " " " " " " " " " "http://tmp_const0
\"VADDW $f11,1,$f13\n\t\" " " " " " " " " " " " " " "http://tmp_max+1
\"VSUBW $f12,$f13,$f13\n\t\" " //?(tmp_max+1)=~PIXEL_MAX
\"VLOG08 $f12,$f10,$f13,$f14\n\t\" " //tmp_dstamp;~PIXEL_MAX
\"VSUBW $f12,$f10,$f15\n\t\" " " " " " " " " " " " " " "http://?tmp_dst
\"VSRAW $f15,31,$f15\n\t\" " " " " " " " " " " " " " " //gt;gt;31算術
\"VLOG08 $f12,$f15,$f11,$f15\n\t\" " " " " " " " " " " " " " " "http://amp;
\"VSELEQW $f14,$f10,$f15,$f16\n\t\" " " " " " " " " " " " " " "http://?
\"VSTD $f16,0(%3)\n\t\" " " " " " " " " " " " " " " " " " " " " " " //
:
:\"r\"(amp;tmp_dst),\"r\"(amp;tmp_max),\"r\"(amp;tmp_const0),\"r\" (amp;tmp_
return)
:);
首先改造最內層數據變量x,由于缺少乘法指令,因此src[x]*A保留,將其8次循環的值賦給對齊向量數組tmp_res;然后B值賦給向量tmp_offset,通過指令VADDW相加存儲到tmp_dst,即完成變量x的向量化;其次改造x264_clip_pixel(x):x向量值tmp_dst加載到$f10,常量A對齊轉換為tmp_max后加載$f11,0對齊轉換為tmp_const0加載到$f12;由于缺少向量取反指令, tmp_max首先加1存儲至$f13,隨后通過VSUBW進行tmp_const0?tmp_max間接實現取反操作;最后通過可重構指令VLOG08實現tmp_dstamp;~PIXEL_MAX的邏輯與操作,其中數據8通過與操作的真值表求出,剩余部分可查看注釋釋義。
2) 對界問題的處理。申威架構中,一般情況下可采用兩種方式來處理對界問題:一是采用SIMD整理指令對數組b進行拼接;二是使用不對界訪存接口直接處理。理論上,方法2比方法1性能要好。但實際使用中,不對界仿存指令依舊會帶來不可接受的巨大開銷。因此申請許多新內存空間,并利用_attribute_((aligned(n)))強制對界,配合內存拷貝優化方式來初始化能有效提升性能。
3) 內存拷貝優化。幀拷貝大量使用memcpy()函數。該部分通過SW平臺下優化的mem庫直接鏈接使用。
上述三種優化手段里面,SIMD向量優化主要集中在運動補償和去塊濾波方面,效果明顯;而幀拷貝優化屬于通用優化方法,在編碼的各個階段都可以獲益,尤其是在編碼后的視頻輸出階段。
3 "實 "驗
3.1 "實驗平臺
實驗的硬件平臺采用威焱831臺式計算機。威焱831為64位字長的國產高性能8核通用處理器,該處理器集成了8個64位RISC結構的申威處理器核心,采用Core3B核心指令系統,主頻2.5 GHz,配置16 GB DDR3內存,搭載UOS 20操作系統,采用Linux 4.19?sw內核。視頻編碼器x264版本為0.164.x,測試視頻片段為h264格式視頻文件通過FFmpeg軟件解碼出來的YUV文件,包括1 080P、4K兩種主流分辨率。
3.2 "實驗數據
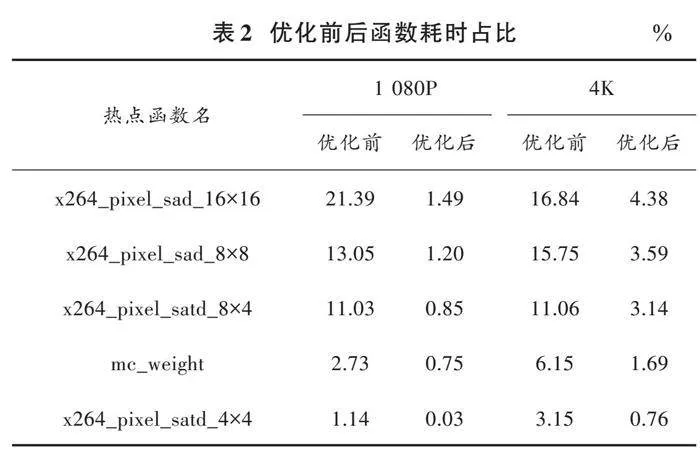
表2統計了上述主要耗時函數在兩種分辨率的YUV文件編碼H.264格式視頻過程中的CPU耗時占比,以10億個CPU周期(G Cycles)為單位。從表2可以看出,經過SIMD向量化優化后,去塊效應濾波模塊和運動補償模塊計算效率明顯改善,結合表1可發現性能改善主要集中在去塊效應濾波模塊。SIMD向量化充分利用了各種系統資源和程序的計算并行性特征,編碼過程中的計算效率明顯提升。在保證了幀率和圖像質量的前提下,各主要熱點函數經過SIMD優化后,在整個編碼過程中的耗時占比大幅下降。其中,在1 080P分辨率下耗時均下降到2%以下,相對于4K分辨率的編碼情景,改善效果感性上更為顯著。
表3統計了優化前后兩種分辨率視頻的整體編碼性能,主要以編碼時的FPS作為性能比較基準單位。
從表3可以看出:與表2占比耗時提升推測相對應,1 080P分辨率的編碼性能效果提升更為顯著,整體編碼性能由4.9提升到7.4,平均提升幅度達到50%以上;4K分辨率提升效果則達到近20%,不過CPU占用率基本達到飽和。
4 "結 "語
本文對申威處理器上使用FFmpeg編碼H.264標準視頻的性能瓶頸進行了較詳細的分析,針對其中比較耗時的操作,提出了在申威架構下適用SIMD進行優化的具體方法。各項數據表明,在保證圖像視頻質量下,編碼器在主流分辨率下的性能提升了15%以上,平均性能提升了30%以上。這種基于申威SIMD技術的優化方法充分利用了總線、數據通道資源,并且沒有改變處理算法的基本結構,在基于軟件編碼的國產處理器多媒體領域中有著廣泛應用。
參考文獻
[1] 劉浩浩.面向SIMD超長向量加速部件的向量化方法研究[D].鄭州:中原工學院,2022.
[2] 陽飛.基于龍芯2K1000B的H.264視頻解碼系統軟件適配與優化[D].南京:東南大學,2020.
[3] 裴航.基于申威421處理器的視頻解碼SIMD優化技術研究[D].鄭州:中原工學院,2021.
[4] 張振東,王彤,劉鵬.面向申威眾核處理器的規則處理優化技術[J/OL].計算機研究與發展:1?19[2023?09?13]. http://kns.cnki.net/kcms/detail/11.1777.TP.20230720.0940.004.html.
[5] 馮德邦.支持超高清的H.264熵解碼器的設計與驗證[D].哈爾濱:哈爾濱工業大學,2022.
[6] 谷一鑫.面向ARM架構的圖像高性能計算庫研究與移植優化[D].西安:西安電子科技大學,2022.
[7] 馬浩.基于Tilera多核處理器的HEVC解碼主要模塊并行處理方案設計與實現[D].南京:南京郵電大學,2021.
[8] 佘成龍.“魂芯”DSP H.265幀內預測實現及預測模式并行化設計[D].合肥:合肥工業大學,2019.
[9] 熊啟金,丁永強,林志堅.高效視頻編碼幀內預測算法優化與硬件架構設計[J].無線電通信技術,2023,49(5):953?959.
[10] 蔣林,馮茹.基于視頻陣列處理器的3D?HEVC視差估計算法并行設計與實現[J].計算機應用與軟件,2023,40(7):260?265.
[11] 林志堅,丁永強,楊秀芝,等.HEVC幀內率失真優化預測模式的并行流水線硬件設計[J].華南理工大學學報(自然科學版),2023,51(5):95?103.
[12] FFmpeg documentation. FFmpeg source code [EB/OL]. [2022?04?30]. http://www.ffmpeg.org/download.html#get?sources/.
[13] 屠要峰,陳河堆.面向GoldenX軟硬協同優化的異構加速列式存儲引擎研究[J].計算機學報,2022(1):207?223.
猜你喜歡
科普童話·神秘大偵探(2023年1期)2023-05-30 12:48:10
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
測控技術(2018年5期)2018-12-09 09:04:26
電子測試(2018年18期)2018-11-14 02:30:34
電信科學(2016年10期)2016-11-23 05:11:56
現代企業(2015年2期)2015-02-28 18:45:09
