大模型倫理失范的理論解構與治理創新
2024-07-24 00:00:00肖紅軍張麗麗
財經問題研究 2024年5期

摘 要:ChatGPT系列和Sora等大模型作為人工智能技術的發展前沿,在助力人類生產生活的數字化和智能化轉型提速的同時,也引發一系列倫理失范現象,成為全球性治理難題。本文對大模型倫理失范進行理論解構發現:大模型倫理失范的緣起是其區別于傳統生產力和生產工具的技術非中性、內嵌人類倫理和將人類倫理與機器倫理糅合其中等屬性特征,技術起點是算法,關鍵中介是數據,行為主體是人類。大模型所引發的諸如模型黑箱、數據版權侵害且主體責任難確定、沖擊人類主體資格等倫理失范現象對現行倫理治理模式提出挑戰。因此,本文以大模型生命周期為時間維度,以關鍵要素為核心,構建了基于大模型關鍵要素的全生命周期倫理治理框架。同時,為推動新倫理治理框架的有效運行,本文構建了包含兩層行為主體的自我治理、兩級守門人和全球性合作治理網絡等子體系的大模型倫理治理生態體系。
關鍵詞:大模型;倫理失范;倫理治理
中圖分類號:F49;B82-057 文獻標識碼:A 文章編號:1000-176X(2024)05-0015-18
一、引 言
人工智能技術創新日新月異,不斷實現新突破。以OpenAI的ChatGPT系列和Sora、谷歌的Gemini、百度ERNIE 3. 0、華為盤古等為代表的語言大模型和視頻大模型是人工智能技術的發展前沿,其在海量數據、強算力和算法三個關鍵因素共同推動下,模擬人類思維鏈運行。自2022年底ChatGPT問世以來,大模型領域逐漸形成國際上以OpenAI和谷歌為代表,國內以百度、華為和阿里巴巴等為代表的技術研發和應用終端布局體系。其中,2024年2月,OpenAI推出的Sora將大模型技術從文字式智能涌現躍遷至視頻式智能涌現,從靜態式呈現躍遷至動態式呈現,Sora成為鏈接物理世界和數字世界的“通用模擬器”。與其他人工智能應用相比,大模型實現了突破性技術創新和顛覆性技術創新[1],且依靠其通用性、多模態和智能涌現能力與千行百業深度融合,引發生產方式、技術創新范式、內容生成方式和人機關系等領域的變革。例如,科學研究、生物醫藥和軟件開發等領域從分散個體化的“慢工出細活”式生產演變為平臺集成化的“短平快”式智能涌現。然而,大模型應用也會引發一系列倫理失范現象。例如,2023年3月31日,ChatGPT就因為用戶隱私泄露等問題在意大利被禁止使用,并因涉嫌違反數據收集規則被調查。2024年1月29日,意大利數據保護局稱OpenAI違反歐盟《一般數據保護條例》,可能會對其處以全球營業額4%的罰款。此外,大模型倫理失范現象還包括算法黑箱、數字鴻溝和隱私泄露等,并衍生出新型倫理失范現象。例如,模型黑箱、數據版權侵害、深度偽造加深、沖擊人類主體資格和加劇社會階層分化等。
如何有效防范與治理大模型等生成式人工智能應用所引發的倫理失范成為全球性重要議題,“科技向善”“負責任研究與創新”“科技倫理”等理念被提出并付諸實踐,國際組織、各國家或地區紛紛出臺相關倫理監管政策以實現倫理失范治理與技術創新之間的平衡[2]。其中,國際組織中具有代表性的監管政策包括,聯合國教科文組織發布的《人工智能倫理問題建議書》、G20發布的《G20人工智能原則》、電氣與電子工程師協會發布的《人工智能設計倫理準則》、G7發布的《開發先進人工智能系統組織的國際行為準則》、歐盟發布的《人工智能法案》和配套的《人工智能責任指令》、28個國家和歐盟共同簽署的《布萊切利宣言》,以及英國、美國等18個國家聯合發布的《安全人工智能系統開發指南》等,從正式制度和非正式制度兩個層面加強人工智能倫理治理。具體到單個國家或地區層面,美國的倫理監管模式逐漸從相對寬松轉向趨緊監管,且以總統拜登簽署的《關于安全、可靠和可信的人工智能》行政命令為分水嶺;中國高度重視大模型相關倫理治理,出臺了《新一代人工智能倫理規范》《科技倫理審查辦法(試行)》《生成式人工智能服務管理暫行辦法》等一系列政策文件,逐漸加強倫理治理的制度建設,并新設國家科技倫理委員會以推進科技倫理治理。其中,《生成式人工智能服務管理暫行辦法》提出,對生成式人工智能服務實行包容審慎和分類分級監管,且明確服務提供者和應用者等主體的責任。為提高大模型倫理治理的法治化水平,《國務院2023年度立法工作計劃》將人工智能和網絡數據安全管理相關立法提上日程。英國、新加坡等國家也出臺了相應的監管政策以防范和治理大模型等生成式人工智能的倫理失范。另外,為加強大模型倫理治理,各國家或地區還設置了專門監管機構。例如,歐盟《人工智能法案》提出,設立歐盟人工智能辦公室(European AI Office) 以提高通用型人工智能模型的透明性,以及控制系統性風險等。同樣,日本提出要成立一個全國性的機構對人工智能倫理失范進行研究與監管。然而,現行的單要素和單環節、自上而下和以結果為導向的倫理治理模式無法有效防范和治理大模型等生成式人工智能應用所引發的算法偏見、隱私泄露、數據版權侵害等倫理失范現象。為加強大模型倫理治理,亟須對大模型倫理失范的緣起進行探究,對倫理失范現象進行歸納,對相關倫理治理范式進行梳理,進而針對現行理論研究薄弱之處、治理制度體系待完善之域和治理實踐待創新之區等,探尋更加適宜和有效的倫理治理范式。
鑒于此,本文對大模型的屬性和倫理失范緣起進行分析,解構大模型倫理失范的關鍵要素,歸納大模型倫理失范的主要表現及其對現行治理體系提出的挑戰。在此基礎上,構建大模型倫理治理的新框架和相應治理生態體系。從理論上對大模型倫理失范緣起給予回答,從治理框架上進行創新,從治理生態上進行構建,以期實現大模型倫理治理秩序重構的目標。
本文的邊際貢獻主要包括:一是對大模型的屬性和關鍵要素進行解構,是對大模型等生成式人工智能本質的再認識。二是對大模型倫理失范的緣起進行理論解構,進一步揭示算法、數據和人類等關鍵要素在大模型倫理失范中所發揮的作用。三是對大模型倫理失范現象進行歸納和總結,在人工智能倫理失范現象或風險的基礎上進行了拓展。四是以大模型生命周期為時間維度,以關鍵要素為核心,構建基于大模型關鍵要素的全生命周期倫理治理框架,并構建相應的大模型倫理治理生態體系,以有效防范與治理大模型倫理失范現象。
二、文獻回顧
人工智能倫理相關研究最早可以追溯至1940—1950年關于倫理和數字技術的探討,此后,緊密貼合科學技術發展脈絡,倫理治理相關研究脈絡的演變從科技倫理到人工智能倫理,再到大模型等生成式人工智能倫理治理。大模型倫理治理的相關研究主要涌現于2022年底ChatGPT問世之后。與本文相關的文獻主要集中于以下三類:一是大模型對社會、經濟的影響及其倫理失范的相關研究。二是大模型倫理治理的相關研究,主要集中于治理模式、治理目標和實現路徑等。三是大模型關鍵要素倫理治理的相關研究,以算法、數據和深度合成技術等為主。
(一) 大模型對社會、經濟的影響及其倫理失范的相關研究
隨著人工智能技術的演進,大模型等生成式人工智能對經濟增長、生產效率和要素分配等方面產生深刻影響[3],起到提質增效和深化供給側結構性改革等作用,與此同時也引發隱私泄露、數字鴻溝、輸出帶有歧視性或偏見性結果、知識產權歸屬不清晰等倫理問題,可歸納為技術內生型倫理風險和技術應用型倫理風險兩大類[4]。具體到不同領域,大模型會引發不同倫理失范現象。例如,大模型廣泛應用于醫學、經濟和金融等研究領域會引發科研范式變革,能夠自主進行科研假設、科學實驗和驗證假設合理性等全流程[5],從低效率的作坊模式轉變為平臺模式[6],對創新寬度產生影響[7]。此外,大模型還可以為科研人員提供文獻回顧、數據訪問[8]等輔助性研究便利,但也會導致數據版權侵害且主體責任難確定[9]、知識產權侵害和科研不端等倫理失范現象。其中,主體責任難確定將進一步引發社會信任體系的混亂。大模型還適用于工業設計、藥物研發和材料科學等領域,其對簡單重復性勞動所產生的替代作用將引發社會分化或歧視等倫理失范現象。
(二) 大模型倫理治理的相關研究
為應對大模型倫理失范及其對現行倫理治理體系提出的新挑戰,學術界對大模型倫理治理開展了相關研究。一是對大模型進行道德倫理設計,從技術上降低倫理失范發生的概率。基于前期所習得知識和輸入信息,大模型通過所構建的思維框架生成內容,具有思維價值[10]并體現倫理內涵。對大模型倫理進行有效治理,可以通過在研發階段引入倫理專家團隊[11]、構建倫理數據庫或倫理知識庫、價值觀嵌入、敏感價值設計、提示工程[12]和內置糾偏機制等方式,使大模型等生成式人工智能習得人類的道德倫理知識體系,以降低倫理失范現象發生的概率。二是大模型倫理治理體系或框架的相關研究。關于大模型倫理治理體系或框架的直接研究對象為生成式人工智能、通用人工智能或通用模型[13] 等。目前,較成熟的人工智能倫理治理模式包括規制型治理、創新型治理、自治型治理、市場導向型治理、集中式治理、敏捷治理[14]、復合型系統性治理和面向產業鏈的韌性治理[15]等。張凌寒[6]提出,針對生成式人工智能要構建“基礎模型—專業模型—服務應用”的分層治理體系,形成復合型系統性治理。王沛然[16]提出,針對大模型的特征應遵從控制主義轉向訓導主義的治理范式,其包含大模型的開發訓練動機、訓練數據的內容生態建設、具體場景和用戶的規制等三個基本法學命題。三是對大模型倫理治理的目標、實現路徑和不同主體的法律定位等進行研究。結合《生成式人工智能服務管理暫行辦法》等監管政策對大模型服務提供者侵權責任的界定,進一步從生成和移除兩個維度進行判定,強調責任判斷標準的適時可調整性[17]。考慮到現有的倫理治理政策存在可操作性不強、剛性約束不足和效力層級較低等問題,應堅持法治先行,加快構建科技倫理規范體系[18]。當然,也有學者提出,大模型技術處于尚未完全落地的階段,不適宜在早期就開展專門的倫理治理立法工作,過早的干預或治理將影響技術創新,可能導致法律偏離原本的功能定位,應該從技術標準、安全風險評估和信息審核技術等方面進行治理[19]。
(三) 大模型關鍵要素倫理治理的相關研究
大模型關鍵要素倫理治理的相關研究主要集中于數據、算法等。一是關于大模型訓練數據倫理治理的相關研究。大模型訓練需要海量數據作支撐,數據規模越大,大模型能夠學習和提取的人類道德倫理知識就越多[20],但存在訓練數據的誤導性、偏見和歧視等倫理風險[21]。為加強數據倫理治理,Someh等[22]提出,要構建個人、組織和社會互動的數據倫理治理框架,包括正式治理和非正式治理,從而合乎道德地使用大數據。續繼和王于鶴[23]提出,要構建以綜合推進數據要素市場的高效、公平和安全為目標的“個人—企業—社會”的三維共建數據治理體系框架。張欣[24]針對數據的質量、安全和時效等問題,提出構建精準多元的數據主體責任矩陣,打造靈活高效的數據治理監管工具體系。二是對算法倫理治理的相關研究。針對算法黑箱、算法偏見和算法歧視等倫理問題,有研究提出分場景的算法規制方式,構建算法公開、數據賦權和反算法歧視等算法規制的具體制度,以實現算法負責任的目標[25];針對算法倫理風險問題,有研究提出構建自動化、生態化和全流程的動態監管體系,以實現敏捷治理[26]。肖紅軍[27]從人、算法和社會三個治理要素的九個維度構建了算法責任綜合治理范式的九宮格模型。然而,不同主體算法責任的分配原則和用戶的算法責任等問題仍待進一步廓清[28]。此外,張凌寒[29]從深度合成技術倫理治理的視角切入,提出對大模型實施全鏈條治理,在全球形成更具影響力的治理法律制度體系。
通過以上分析可以發現,現有研究仍然存在以下不足之處:一是數據、算法等關鍵要素倫理治理的研究自成獨立體系,對大模型關鍵要素的倫理治理缺乏針對性和適用性。二是未對大模型生命周期的不同階段和關鍵要素進行拆解,未對關鍵要素的倫理失范緣起進行系統分析,目前也未有相應的倫理治理框架。大模型的技術復雜性、結果的不確定性和應用的廣泛性所引發的倫理風險呈現出影響范圍廣、傳播速度快和乘數效應強等特征,現有的倫理治理模式已經無法應對,亟須提出新的倫理治理框架。
三、大模型倫理失范的理論解構
相較于其他人工智能技術和應用,大模型存在倫理失范現象的根源是什么,要從分析其本質屬性開始。本文運用馬克思關于生產力和生產工具的相關理論對大模型的屬性進行解構,并結合大模型生命周期的主要階段,對大模型屬性及倫理失范緣起進行探究,為進一步防范和治理大模型倫理失范現象尋求路徑。
(一) 大模型屬性及倫理失范緣起
⒈生產力屬性:技術非中性
大模型是人工智能技術的發展前沿,是深度神經網絡(DNN) 在強算力基礎設施和海量數據支撐下,算法及框架的疊加與演進而成的集成性技術系統。在Transformer架構的基礎上,神經網絡模型逐漸演進為三類大模型典型架構,即掩碼語言模型、自回歸語言模型和序列到序列模型。作為一項人工智能技術,大模型隸屬于生產力的范疇,且屬于以科技創新為核心的新質生產力,是推動社會進步最活躍的要素[30],是社會生產力的一次躍升[31]。進一步深入分析,馬克思從兩個維度對生產力進行闡釋和分類:生產力是人類進行物質資料生產的客觀力量,即物質生產力;生產力是人類生產精神財富的能力,即精神生產力。兩者的統一性體現為物質生產力和精神生產力均形成了使用價值。從這一意義看,大模型的生成內容以滿足人類的精神需求為主,其屬于精神生產力的范疇。
大模型的核心技術要素為算法,其也屬于生產力的范疇,具有黑箱特征。算法是從數據輸入至結果輸出的一項計算機計算規則或步驟,即算法=邏輯+控制[32]。算法黑箱可劃分為主觀算法黑箱和客觀算法黑箱[33],并進一步衍生出算法偏見、算法歧視等倫理失范現象。算法黑箱產生的緣由可歸納為三點:一是從知識產權的角度看,算法具有商業秘密性和經濟價值性,無法向公眾公開。例如,大模型GPT?4是可以復制的,但OpenAI不會將其公之于眾。二是算法作為技術,其本身具有不透明性和不可解釋性,人類無法預知其產生的結果。三是算法黑箱體現為不同人群對算法的運算機制和決策程序等信息存在認知偏差,這種偏差尤其存在于專業人員與非專業人員之間。算法黑箱在大模型倫理風險中體現為應用者無法觀察或驗證算法的數據處理過程,導致結果不確定性和不可解釋性等倫理風險。因此,從生產力范疇的角度分析,大模型不再具有“價值中立性”,存在算法黑箱及其衍生的倫理失范現象。
從所作用的勞動對象來看,大模型內嵌人類的倫理傾向或偏好,不再保持“價值中立性”。與其他生產力相比,大模型所作用的勞動對象是數據,其具有虛擬性、可重復應用且包含人類的道德倫理內容等特征。一是數據作為一種新型生產要素,其存儲或管理需要依托于網絡等載體,與傳統要素相比具有虛擬化的特征。二是一旦數據脫離所有者,數據可以被重復使用和處理,并且控制其未來流向和使用途徑等具有一定困難,即存在數據倫理風險敞口。三是數據要素包含人類的價值觀等倫理傾向或偏好,尤其是個人數據,具有“人格化”特征。正是由于大模型所作用的數據要素包含人類的倫理傾向或偏好,且自身存在倫理風險敞口,數據參與大模型的運行,并內嵌到生成內容中,倫理偏好或傾向、倫理風險也將進一步傳遞。
⒉生產工具屬性:內嵌人類倫理
大模型作為一種應用系統,是人類作用于輸入內容的中介,使輸入內容發生一定變化,是人腦的延伸,因而大模型屬于生產工具的范疇。人類在大模型的研發過程中融入了自身的倫理傾向或偏好;在大模型的使用過程中產生包含倫理傾向的內容,并對人類產生倫理影響。
在大模型的研發階段,研發者的倫理傾向或偏好注入其中,因而算法黑箱不可避免。人工智能技術不斷演進,大模型在盡力模擬人類大腦的運行方式,參數規模力求接近于大腦神經突觸數量。例如,大模型GPT?4由8個混合模型組成,每個模型約2 200億個參數,總共約1. 8萬億個參數,是大模型GPT?3的10倍以上。其中,算法模型的選擇和參數規模的確定均取決于研發者的主觀意愿。因此,隨著大模型研發技術的不斷演進,大模型的運行模式將越來越接近人類大腦,研發者及所模擬人類思維中所包含的倫理傾向或偏好會滲透其中,算法的黑箱特征在大模型整個生命周期中如影隨形。
在大模型的訓練階段,訓練數據、訓練人員和數據處理者的倫理傾向或偏好會融入其中。一是訓練數據的來源和質量本身包含倫理傾向或偏好。按照是否經過處理或加工,可以將訓練數據劃分為原始數據和合成數據。大模型的訓練數據大多來源于公開數據庫,未進行加工或合成。由于來源確定或屬于公開數據庫,原始數據應重視其內容的正當性。為提高大模型訓練數據質量,降低對訓練數據規模的依賴性,需要對訓練數據進行質量過濾、冗余去除、隱私消除等處理,在該過程中就會將人類的倫理傾向或偏好內嵌其中,且可能因訓練數據規模的龐大和內容的復雜性等因素而無法進行精確處理,即存在倫理風險敞口。合成數據與原始數據的根本區別在于除數據本身所包含的倫理傾向或偏好之外,數據合成過程中摻入了數據處理者的倫理傾向或偏好,影響其內容的正當性。二是訓練數據的處理和標注方法等包含著人類的倫理傾向或偏好。大模型預訓練數據以原始數據為主,合成數據為輔,調優數據以標注數據為主。大模型調優數據主要包括代碼類數據和對話類數據。其中,代碼類數據主要來源于GitHub上的公共代碼庫,且以Python文件為主;對話類數據以人工標注數據為主,數據標注者主要包括專業標注工和大模型應用者。因此,大模型訓練數據會受數據處理者、數據標注者和應用者等群體的倫理傾向或偏好的影響,且存在“漏網之魚”的倫理風險敞口和“以偏概全”的局限性。
大模型作為生產工具,不僅是人類體力勞動的延伸和替代,還是人類大腦和神經系統的延伸和替代。一是大模型是人類體力勞動的延伸和替代,其帶來生產工具供給的范式變革。人類具有先天生理上的限制。例如,人類無法在極高或極低溫度下進行生產勞動。為克服人類自身的生理性局限,生產工具作為勞動者和勞動對象的中介應運而生。生產工具是人類作用于勞動對象的物件,是人類社會時代劃分的重要標志。機器是工業社會的重要體現,而以人工智能技術支持的機器人等智能化機器是數字經濟時代的重要體現。區別于其他生產工具,大模型在應用過程中主要作用于數據要素,其生成內容也具有一定的虛擬性和數字化特征,擁有智能涌現且與人類思維相似等特征,帶來了生產工具供給的范式變革。二是大模型是人類大腦和神經系統的延伸和替代,大模型應用過程中將人類的倫理傾向或偏好融入其中。大模型作為智能化生產工具引發了“代具性”“技術附庸”問題,嚴重沖擊人類主體資格。機器大生產代替傳統手工生產,人類的勞動不斷趨向重復性和機械性,加劇了人的物化和異化[34],即在以機器為中心的生產體系中,人被嵌入機械化生產線中,勞動強度被不斷提升,引發精神和體力的雙重壓力,制約了人類的全面發展。與此類似,數字經濟時代,大模型高度滲透到人類生產生活中,人與機器不斷互嵌互構,從機器服務于人、人機協作、人機共生,進一步演變為人機一體,人與機器的邊界不斷模糊,久而久之人類會對大模型產生過度依賴,形成“代具性”,甚至淪為“技術附庸”[34]。這會引起人的主體性消解和決策自主權喪失[35]等現象,嚴重沖擊人類主體資格。三是大模型在訓練過程中會學習訓練數據的特征、結構、知識和倫理內容等,并延伸至其所生成內容的倫理傾向,對人類社會產生倫理影響。
⒊雙重屬性:人類倫理與機器倫理糅合
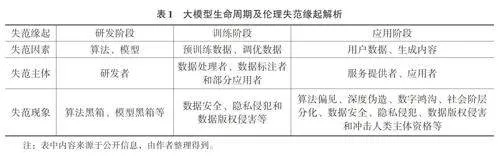
大模型是算法和模型等人工智能技術的集成系統,與應用端緊密聯系在一起,是一種新型生產力工具[36],又被稱為數字化生產力工具。以OpenAI的ChatGPT系列和Sora為例,其底層技術是Transformer架構和Diffusion Transformer架構,應用端是大模型GPT?4和Sora。大模型是生產力與生產工具的集合體,兼具兩者的屬性特征,從研發階段到應用階段均將人類的倫理傾向或偏好內嵌其中,且生成帶有倫理傾向或偏好的內容。波普爾認為,科學實踐的特點是不斷地根據經驗檢驗理論,并根據檢驗的結果進行修正。由該理論可知,大模型是科學技術與科學實踐的融合,是人類思想或意識在機器上的延伸。與馬斯克的腦機接口直接讀取人類思想不同,大模型通過對人類思想或意識進行學習之后形成涌現能力,是人機一體化不斷演進的一種表現,更是機器與人類倫理道德體系不斷糅合之后的外在展現。因此,大模型作為一種數字化生產力工具,兼具生產力與生產工具的雙重屬性,倫理失范的緣起或底層邏輯是兩者的綜合,并貫穿于大模型生命周期(如表1所示),倫理失范現象更加復雜且難治理。
(二) 大模型倫理失范的關鍵要素解構
大模型是人工智能技術的發展前沿,通過生產力、生產工具及二者集合體這三個層面進行解構可以發現,算法、數據和人類是引起大模型倫理失范的關鍵要素。算法是大模型倫理失范的技術起點,數據是大模型倫理失范的關鍵中介,人類則是大模型倫理失范的行為主體。大模型生命周期、關鍵要素與倫理失范現象的關系如圖1所示。
⒈大模型倫理失范的技術起點:算法
算法是大模型運行的內在邏輯,依靠運行規則和學習能力對“投喂”其中的訓練數據進行學習,生成人類滿意的內容,其“黑箱”問題也隨之延伸至生成內容,并體現為生成內容的不可追溯性和不確定性。另外,算法通過對數據進行學習,并部署于不同的應用場景中,嵌入人類的社會生活中,其“價值中立性”不復存在,成為局部人類道德倫理體系的習得者、反映者和影響者。如果算法黑箱變為算法透明箱,其內在運行邏輯顯而易見,大模型的生成內容就可預測,倫理失范的緣由則可追溯、可修正。因此,算法是大模型倫理失范的技術起點,也是算法黑箱、算法歧視和算法偏見,以及所衍生的模型黑箱、模型歧視和模型偏見等倫理失范現象的根源。
⒉大模型倫理失范的關鍵中介:數據
大模型的出現將傳統的知識生成模式轉變為機器生成模式,且以類人腦的方式在短期內實現生成內容的智能涌現。大模型的訓練和運行依賴于數據,且學習和傳承了內嵌其中的人類道德倫理體系,通過“鏡像效應”[13]使其生成內容表征局部人類道德倫理體系,并對人類道德倫理體系產生影響。按照大模型數據“投喂”目的的不同和所形成的道德倫理體系的先后順序,將倫理道德體系劃分為原生道德倫理體系和衍生道德倫理體系。訓練數據的“投喂”形成大模型的原生道德倫理體系,是研發者、訓練者、數據標注者等相關主體,以及訓練數據中所包含的道德倫理體系在進行模型研發、訓練和優化過程中形成的初始道德倫理體系。衍生道德倫理體系指大模型進入應用階段,應用者將自身道德倫理或輸入內容所包含的道德倫理等輸入大模型,在智能交互中對原生道德倫理體系產生一定影響,并在其基礎上所形成的新道德倫理體系或引起原生道德倫理體系的變化。大模型的道德倫理體系將研發者、訓練者、數據標注者及其輸入內容的道德倫理體系進行糅合。其中,輸入內容作為客觀主體體現了前述相關主體的道德倫理,因而大模型所習得的道德倫理體系是人類道德倫理體系經過算法等人工智能技術進行處理之后形成的多個人類主體的道德倫理融合體系。
⒊大模型倫理失范的行為主體:人類
大模型的研發者、訓練者、服務提供者和應用者是人類,訓練數據的產生者、處理者和輸入者也是人類,因而引起大模型倫理失范的行為主體是人類,受影響的主體是人類,承擔責任的主體也是人類自身。算法是人類的代理者[27,37],大模型同樣充當著人類代理者的角色,區別在于所代理內容多少和程度大小。數據是人類的產物和資源,是人類道德倫理體系的反映物,從這個意義上講,數據具有“價值中立性”的特征,是否產生倫理失范現象取決于人類的生產方式、應用方式和具體場景。綜上,盡管人類的主體資格受到大模型的沖擊,但人類依然是大模型的控制者和其生成內容的決策者。大模型體現的是人類的意志,大模型等生成式人工智能與人類不論承擔交互式倫理責任,或完全式倫理責任[38],或無需承擔倫理責任[39],大模型倫理失范行為主體、受影響主體和責任主體最終是人類自身。
(三) 大模型倫理失范的主要表現
對大模型倫理失范的緣起進行分析與解構后發現,大模型具有算法疊加、參數規模增加、訓練數據來源多元化和規模龐大、智能涌現能力更強等特征,這引起了新型倫理失范現象的發生和原有倫理失范現象的深化或擴散。例如,模型黑箱、數據版權侵害且主體責任難確定、沖擊人類主體資格和對人類社會道德倫理秩序的漠視和擾亂等。
第一,模型黑箱。在關于人工智能倫理、算法倫理的分析和研究中,算法黑箱是倫理治理的焦點和難點,包括由此衍生出的算法歧視和算法偏見、結果不確定性和誤導性[40]等倫理失范現象。在算法黑箱的基礎上,依賴深度神經網絡和集成技術的大模型所產生的黑箱現象演變為模型黑箱[41]。算法是從數據輸入至結果輸出的一項計算機計算規則或步驟,即算法=邏輯+控制[32],深入滲透到社會生活中的算法已經成為社會價值判斷的一部分,不再具有“價值中立性”[25];參數是模型中需要訓練和優化的變量,將影響模型的生成內容,參數越多,模型的生成內容越符合預期;模型是算法使用數據進行訓練后輸出的文件,是具有特定流程或結構的計算機程序[16],算法和參數均包含其中。模型黑箱比算法黑箱更加復雜,是算法黑箱的疊加,是算法、模型和參數等要素糅合之后的“黑箱”。模型黑箱進一步加劇了大模型生成內容的不可解釋性和不確定性,甚至其生成內容是錯誤的、虛假的、有害的、具有誤導性且缺乏因果推斷的[42],加之存在“機器幻覺”現象,會對人類行為產生不良誘導。與專用人工智能模型相較而言,大模型的智能涌現能力強,內容生成效率高,易于在短期內形成劣質內容且能快速傳播,在一對多的連鎖反應下將對人類社會道德倫理秩序帶來系統性沖擊。
第二,數據版權侵害且主體責任難確定。數據和文本挖掘技術為公開數據的獲取與使用提供了便利。大模型的智能涌現能力依賴于海量數據的“投喂”,然而大模型所使用數據的獲取途徑和使用方式是否正當、合法仍需進一步加以監管。其中,歐盟理事會通過的《數字化單一市場版權指令》對獲取、使用數據和文本進行了規范,提出僅不受版權保護的事實或數據無需授權,即數據獲取和使用的主體授權原則,但仍需注意是否存在復制權侵害。大模型的部分訓練數據直接來源于網絡爬取,且未對數據的合法性和安全性等進行評價和驗證,如果爬取數據超出了數據主體的授權范圍或包含敏感信息等,將會侵害數據主體權利,又由于人機邊界模糊、數據來源模糊和數據主體權利模糊等延伸出主體責任難確定等倫理問題。大模型訓練使用合成數據同樣存在上述問題。其中,Sora視頻大模型的出現將數據版權侵害問題擴展至視頻生成領域。
第三,人機邊界模糊,物理世界與虛擬世界界限模糊,這將會沖擊人類主體資格和社會信任體系。政治經濟學關于生產關系的相關理論認為,人與生產工具、人與生產力之間均是彼此獨立的二元結構。數字經濟時代,大模型與人的關系打破了上述二元結構,加劇了人的物化和異化[34]。從語言大模型ChatGPT到視頻大模型Sora,大模型技術的演進體現為人與機器不斷互嵌互構,人機邊界不斷模糊,引起人的主體性消解和決策自主權喪失[35]等現象,嚴重沖擊人類主體資格。此外,視頻大模型Sora的問世使深度偽造進一步加深。深度偽造是基于生成對抗網絡模型,廣泛應用于視頻換臉的人工智能技術,憑借其高度真實性、泛在普適性和快速演化性等特征,其應用不當會產生侵犯公民人身財產權利、消解社會信任體系等倫理問題。與深度偽造技術相比,視頻大模型取得了實質性的超越,加深了偽造的深度,從對人臉的“偽造”演變為對物理世界的“偽造”,進而影響人類社會信任體系。
第四,對人類社會道德倫理秩序的漠視和擾亂。一是大模型的生成內容對人類道德倫理秩序的漠視和擾亂。具體到應用場景的大模型,攜帶著所習得的局部人類道德倫理體系,生成應用者所需要的內容,并將原生道德倫理體系和衍生道德倫理體系糅合其中。大模型的研發者、服務提供者和應用者漠視生成內容是否存在對人類社會道德倫理秩序的擾亂,大模型生成內容處于人類道德倫理體系的真空區,未被“觸及”或“約束”。例如,用人工智能生成欺騙性內容干擾選舉被認為是全球面臨的重要挑戰。二是大模型濫用對人類社會道德倫理秩序的漠視和擾亂。大模型充當著“人類大腦”或“世界模擬器”的角色,改變了知識的生產方式,縮短了知識生產的社會必要勞動時間,降低了人類獲得所需文字、視頻等生成內容的成本。大模型應用者從輸入需求到輸出結果,以及輸出結果的未來用途等,全過程沒有適用且有效的治理措施,這無疑是對人類社會道德倫理秩序的漠視和擾亂。
(四) 大模型倫理失范所提出的治理挑戰
大模型引起了技術海嘯和秩序重構,對現有倫理治理體系提出了一系列挑戰。現有的單要素和單環節的倫理治理模式、自上而下的倫理治理模式和以結果為導向的倫理治理模式已經無法有效防范和應對大模型倫理失范,體現為倫理治理的缺失或失效。
第一,單要素和單環節的倫理治理模式不能有效防范和應對大模型倫理失范。人機邊界模糊與人機關系重構導致倫理治理主體范疇的擴張。人機智能交互和反饋式學習機制不斷演進,模糊了人機邊界,引起人機關系的重構,并產生“飛輪效應”,導致倫理治理范疇發生變化。一是大模型倫理治理對象發生變化。傳統倫理治理范疇中的治理對象主要包括生成內容和服務提供者,大模型所引發的倫理風險則超越了以上治理對象,需將大模型研發者、訓練者和應用者,訓練數據的提供者、處理者和標注者等納入倫理治理對象的范疇。二是大模型倫理治理主體尚未清晰界定,主體間責任則無法明確劃分。以生成內容為例,大模型的生成內容是否存在倫理風險,取決于大模型在研發過程中是否存在倫理缺陷。因此,大模型研發者、服務提供者和應用者均在其中發揮了作用,對結果的輸出負有責任,如果出現倫理失范,參與者均需要承擔相應的責任,然而由于算法的不透明性和結果的不確定性,無法清晰界定不同主體的責任歸屬。綜上所述,單要素和單環節的倫理治理模式呈現出一定程度的不適用性,無法有效防范和應對大模型倫理失范。
第二,自上而下的倫理治理模式不能及時防范和應對大模型技術迭代更新所引發的倫理風險。一是自上而下的倫理治理模式主要采用法律法規等方式治理倫理問題,與大模型技術迭代更新的速度相比具有一定的遲滯性和固定性,只能應對已經出現或可預見的倫理問題,卻無法及時防范大模型技術迭代更新所產生的倫理風險。二是大模型具有技術不確定性所引發的生成內容及其社會影響的不確定性,自上而下的倫理治理模式具有一定的線性僵化特征,不能及時防范大模型對人類社會道德倫理秩序的沖擊。三是以政府監管政策為主基調的自上而下的倫理治理模式,容易引起倫理準則抽象性與倫理實踐之間的脫節,需要從倫理描述轉向倫理應用[40],探索新型倫理治理模式以避免大模型“野蠻生長”。
第三,以結果為導向的倫理治理模式不能有效防范和應對大模型生命周期的倫理問題。以《生成式人工智能服務管理暫行辦法》為代表的監管政策體系,針對大模型及其相關應用的倫理治理注重對生成內容或信息的監管,責任主體的歸屬主要聚焦于生成式人工智能服務提供者。與其他人工智能技術相比,大模型技術的演進范式及其應用模式的轉變引發的倫理失范現象不再局限于最終的生成內容,以結果為導向的倫理治理模式不能有效防范其倫理失范。一是大模型的技術創新范式發生變革,體現為開源式創新、過程式創新和不確定性創新。以結果為導向的倫理治理模式重心是大模型的生成內容或最終結果,不能有效應對大模型技術創新過程中存在的倫理風險。二是大模型的應用場景日趨多元化和開放化,導致倫理失范現象發生的潛在邊界擴大,具有多點多發等特征。因此,以結果為導向的倫理治理模式已無法全面防范和應對大模型倫理失范。
四、大模型倫理治理框架的再構建
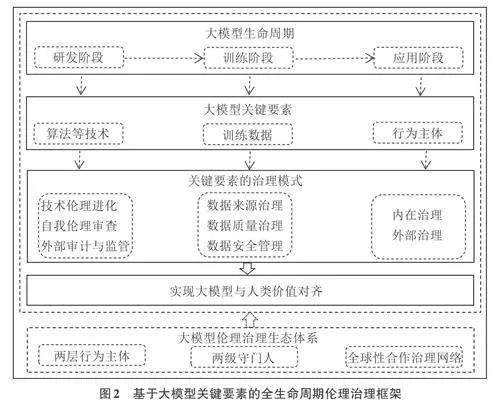
大模型在算法黑箱、數字鴻溝等倫理問題之上,衍生出了模型黑箱、數據版權侵害且主體責任難確定、沖擊人類主體資格等倫理失范現象,對現行倫理治理體系提出了挑戰,單要素和單環節、自上而下和以結果為導向的倫理治理模式已經呈現出治理上的缺位性、滯后性、固化性,以及政策與實踐脫節等不足,亟須提出新的倫理治理框架以對大模型倫理失范進行防范和應對。在對大模型的屬性、倫理失范緣起、關鍵要素解構和主要表現等進行分析,且對大模型倫理失范所提出的治理挑戰進行闡述的基礎上,本文以大模型生命周期為時間維度,以關鍵要素為核心,構建基于大模型關鍵要素的全生命周期倫理治理框架,如圖2所示。
(一) 基本思路
基于大模型關鍵要素的全生命周期倫理治理框架的基本思路是:一是覆蓋大模型生命周期,強調倫理治理環節的完整性。大模型倫理治理應該覆蓋其研發階段、訓練階段和應用階段,甚至延伸至退出階段。二是重點關注大模型關鍵要素的倫理治理。算法、數據和人類這一行為主體是大模型的關鍵要素,也是倫理治理的重點。將大模型關鍵要素置于具體應用場景中,且強調倫理素養的內在提升和自我治理,有助于提高倫理治理的整體性、適用性和自下而上性。三是倫理治理目標是在人工道德代理(Artificial Moral Agent) 的基礎上,實現大模型與人類價值對齊或倫理對齊。與人類價值對齊,即通過人類的價值引導,大模型應與人類的價值觀和社會道德倫理秩序相一致,《生成式人工智能服務管理暫行辦法》中明確提出“堅持社會主義核心價值觀”的具體要求。人類的價值觀包括生存價值觀、社會價值觀和政治價值觀。人類的社會道德倫理秩序主要指社會道德領域的正式制度和非正式制度。大模型與人類價值對齊體現為符合文化、符合社會和符合法規三個層次。符合文化體現為符合大模型所使用國家或地區的ykb/n+QYZs7YY96X6VNS1xgf0n1rrZod2gPtzW8E1N0=文化環境。符合社會體現為符合大模型所使用國家或地區的社會環境。例如,意識形態及政治傾向等。符合法規體現為對使用國家或地區的法律法規等制度的遵守與執行。前兩項更多體現為對非正式制度的遵守,后一項體現為對正式制度的遵守。四是重視大模型倫理治理的系統性與完整性。為配合基于大模型關鍵要素的全生命周期治理框架的有效實施,構建相應的倫理治理生態體系,也是該倫理治理框架的進一步細化與重要延伸。其中,大模型倫理治理生態體系中兩層行為主體和兩級守門人是對大模型關鍵要素的進一步細化,全球性合作治理網絡是關鍵要素治理模式的延伸。例如,以大模型相關技術創新實現對大模型算法等技術的治理;發揮國際組織和各國政府的全局性及跨區域性倫理治理作用;社會輿論體系的倫理監督則是正式倫理治理制度的有效補充。
(二) 大模型倫理治理的關鍵要素倫理治理
⒈對技術的倫理治理
大模型是算法、模型、數據處理和標注、模型訓練等技術的集合體。綜合考慮大模型中算法、模型和參數之間的關聯性和可分割性,將三者統一稱為大模型技術。其中,算法倫理治理是重點。對大模型技術進行倫理治理,可以從三個維度展開:一是大模型技術的倫理進化。加強算法、模型、模型訓練和調優、數據處理和標記等大模型技術創新。例如,以人類反饋強化學習(RLHF)、模型可解釋性和OpenAI正在研發的模型審計等技術提高模型黑箱透明度、生成內容可解釋性和倫理導向正確性等;在大模型中增加倫理數據訓練模塊、內置倫理自查或審計模型等倫理設計,減少倫理失范現象的出現和擴散。二是大模型技術的倫理自我審查、測試和評估。考慮到大模型技術具有商業秘密性和知識產權價值,且力求覆蓋大模型技術的重要倫理風險敞口,可以采取模型卡制度,由大模型研發者創建模型卡,對大模型的參數、算法、訓練數據、預期應用領域和用戶群體等關鍵性信息進行登記和備案,以提高大模型的透明度和倫理規范性等。三是大模型技術倫理外部審計與監管。人工智能技術的備案、審查和安全評估等倫理治理措施已經推行,為加強大模型倫理外部審查的約束剛性,可對大模型技術采用全鏈條倫理審計制,針對不同技術可選擇代碼審計、非侵入式審計、眾包審計、代理審計和抓取審計等方式[33],以保證審計過程中的權責匹配性、機構獨立性和知識產權保護等。
⒉對數據的倫理治理
數據是大模型運行的驅動力,主要包括訓練數據和用戶數據兩類。其中,大模型訓練數據主要包括文本、圖片、視頻和(文本,視頻) 對等形式,在大模型預訓練和調優階段發揮作用。數據的來源、質量、合成技術和所含倫理內容等均會影響大模型所習得的倫理規則,并隨著大模型應用場景的拓展體現出延伸性和擴散性。加強數據的倫理治理是大模型倫理治理的關鍵部分。
綜合考慮大模型數據倫理風險敞口,可以從以下三個維度加強大模型數據的倫理治理:一是數據來源治理。對來源于公開數據、專門數據庫等未經過相關處理的原始數據,應提高數據來源的可追溯性、正當性和規范性,避免出現數據版權侵害等倫理失范現象。此外,數據來源在一定程度上對數據質量和所包含的倫理理念等具有“隱性”保證作用,即來源正當的數據質量和倫理健康性更高。二是數據質量治理。大模型所使用數據的質量體現在是否存在誤導性、歧視性等,對大模型、生成內容和應用者的道德倫理體系產生影響。加強對訓練數據質量的檢測與評估,并針對異常數據有相應的處理流程和辦法,保證訓練數據合乎倫理秩序和道德規范,避免低質量數據對生成內容和應用者的道德倫理體系產生負面影響。三是數據安全管理。數據安全和隱私保護是大模型運行的基石,以技術創新加強數據安全和隱私保護。數據存儲和使用過程中均存在安全性要求,應加強隱私計算關鍵技術的突破。例如,聯邦學習、多方安全計算、差分隱私和同態加密等,并加強關聯領域的互聯互通等,為數據安全和隱私保護提供一項新的技術選擇,加上一把安全鎖。從數據安全治理方式上,可引入專業型數據托管機構,將數據存儲、管理和使用等職責分離,對數據處理和使用進行有效監督,提高數據安全性,也有利于政府對大模型訓練數據進行監管。
⒊對大模型行為主體的倫理治理
人類是影響大模型道德倫理體系的行為主體,是其倫理治理的關鍵要素。一是人類在人工智能大模型的研發、訓練、部署和應用等環節均發揮主體作用,且貫穿始終。二是大模型的倫理風險觸發和受影響主體是人類。三是大模型倫理治理的根本在于治人。按照大模型生命周期的不同階段,將人類這一行為主體劃分為大模型研發者、大模型訓練者、數據提供者、數據處理者(主要包括數據預處理者、合成者和標記者)、大模型服務提供者和大模型應用者,針對以上行為主體進行倫理治理需綜合考慮共性和差異性,即不同行為主體的倫理風險敞口存在差異。
其一,對大模型行為主體的內在倫理治理。其根本在于提升其倫理認知水平、倫理素質和專業技能。為從根源上實現倫理治理的目標,需要對大模型行為主體進行分層分類治理,切實提升倫理認知水平,且增強倫理風險防范能力。遵循倫理認知—倫理判斷—倫理意圖—倫理行為的倫理決策四階段理論[43],通過學校教育、公共宣傳和在職培訓等方式提高大模型行為主體的倫理認知層次和價值判斷能力,正確引導倫理判斷和倫理意圖,降低倫理失范發生的概率,減輕倫理失范對人類社會道德倫理體系的消極影響。提升大模型研發者與訓練者、訓練數據提供者與處理者、大模型服務提供者等行為主體的倫理素質和專業技能,降低倫理失范發生的概率。大模型專業型行為主體是直接與大模型的算法、模型、參數和訓練數據等接觸的群體,擁有相對信息優勢和空間優勢,對大模型所習得的“道德倫理規則”有更深刻的影響,因而提升其倫理素質和專業技能更具迫切性且倫理治理成效更顯著。專業型行為主體倫理素質的提升更多落腳于在職培訓、職業道德準則學習等形式;專業技能的提升主要體現于模型黑箱的克服、倫理嵌入和倫理設計等領域,且將人類社會道德倫理規則貫穿于大模型研發、訓練和服務提供整個過程,減輕大模型對人類社會道德倫理秩序體系的沖擊。
其二,對大模型行為主體的外部倫理治理。推行許可證制、市場黑名單制和倫理失范問責制,以加強大模型行為主體的外部倫理治理。許可證制是在大模型推入市場之前,監管機構對大模型進行倫理評估或性能測試之后,允許符合標準的大模型進入應用市場;市場黑名單制根據大模型在應用中出現倫理失范的頻率、影響范圍和造成損失或傷害程度高等維度確定是否將大模型行為主體列入市場黑名單;倫理失范問責制主要從懲罰大模型相關行為主體、補救受影響主體損失并防范潛在倫理風險等層面對行為主體進行治理。
⒋大模型應用場景、風險等級與倫理治理方式的匹配
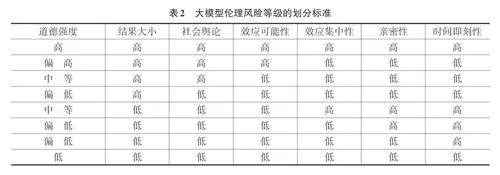
歐盟《人工智能法案》提出,按照人工智能風險等級采取差異化治理方式。根據問題權變模型中道德強度的概念和維度,并分析了道德強度對倫理決策產生影響的路徑。將風險等級、道德強度與場景理論融合,重點考慮大模型在不同應用場景中若發生倫理失范所造成社會影響的大小。大模型倫理風險等級的劃分充分考慮道德強度的六個維度。其中,結果大小、社會輿論和效應可能性這三個維度的重要性高于其他維度,具體風險等級劃分標準如表2所示。
在借鑒歐盟分級分類治理模式、日本風險鏈模型、德國VCIO模型的基礎上,將大模型主要應用場景劃分為公共事業和商業服務兩個類別,本文構建了基于應用場景的大模型倫理治理方式的匹配矩陣。①
五、大模型倫理治理生態體系的構建
為加強大模型倫理治理,實現大模型與人類價值對齊或倫理對齊的目標,在基于大模型關鍵要素的全生命周期倫理治理框架下,需要多元主體的共同參與,構建全方位的治理生態體系,主要包括推動大模型關鍵群體和企業兩層行為主體的自我治理,發揮大型平臺企業和政府兩級守門人作用,形成以國際組織為核心、以技術治理為工具和以社會輿論為監督的全球性合作治理網絡等子體系,加快大模型倫理治理“赤字”的綠化進程。大模型倫理治理生態體系包含大模型關鍵群體、大模型企業、數字守門人、國際組織和各國政府等多元主體的自治理、他治理和外部監管,能夠實現對大模型道德倫理體系的影響因素相對全面的覆蓋,不再局限于單要素和單環節,且關鍵群體、大模型企業等主體的自我治理和數字守門人的監管式守門人角色等是對以政府為主導的自上而下的倫理治理的有效補充。其中,重視發揮大模型研發者、大模型企業和數字守門人等主體的治理作用,實現從大模型研發、訓練和服務提供等階段均有相應的倫理自律或治理,既可以實現大模型生命周期的覆蓋,又是倫理先行理念對以結果為導向的倫理治理模式的擴充和延伸,包括政府作為終極守門人在監管政策制定中應提高監管制度的全局性,力求將大模型生命周期統籌在內。
(一) 推動兩層行為主體的自我治理
大模型的行為主體可劃分為關鍵群體和企業主體兩個層級。其中,關鍵群體主要是大模型研發者,企業主體則是以企業形式存在的與大模型相關的經濟組織。
第一,加強大模型關鍵群體倫理素養和專業技能的提升。人是產生倫理風險的根源,是大模型倫理治理的最終落腳點,大模型研發者是其中的關鍵群體,其擁有一定的信息優勢和空間優勢,倫理素養和專業技能對大模型原生道德倫理體系產生直接影響,是大模型倫理治理的第一線。大模型研發者的倫理自我治理可以從以下途徑展開:一是提升自身倫理素養。以公共部門的公益性倫理教育或宣傳為基礎,以高等院校教育或繼續教育的倫理課程為核心,以所從事具體領域的大模型倫理規范等制度文件的學習或培訓為補充,強化大模型倫理教育和學習。二是提升自身專業技能。專業技能的提升具有長期積累性,且需要緊跟技術發展腳步進行迭代更新,大模型相關專業技能的提升可以從以下途徑展開。首先,短期應以在職培訓為重點,以實際工作需求為導向,注重理論知識與實踐技能的結合,緊密結合技術發展前沿,提升大模型技術人員的專業技能。其次,中長期應以高等院校教育為重要途徑,發揮個體自主性學習,以勞動力市場需求和個體職業發展為最終落腳點,培養專業型人才隊伍。
第二,加強大模型企業的自我倫理治理。大模型企業主要包括大模型研發企業、大模型部署企業和服務提供企業,其自我倫理治理主要通過以下途徑展開:一是強化倫理意識。倫理先行,將科技向善、負責任研究和技術創新等理念貫穿于企業文化與實踐之中。發揮企業文化等非正式制度的引導作用,對企業倫理價值觀具有正向影響。大模型的多模態、通用性特征和模型即服務(MaaS) 的產業鏈模式等,要求加強企業間倫理倡議或公約等非正式倫理制度建設。二是完善自我治理的倫理制度體系建設,強化制度約束力且擴大覆蓋面。大模型企業自我治理的倫理制度建設具有局部性特征,體現為集中于數據安全、隱私保護和用戶個人信息安全領域,且以落實國家倫理監管政策和促進企業發展為主。大模型企業自我治理的倫理制度可從三個層面加以完善。首先,大模型技術規范、路線圖和工具箱等技術倫理規范性制度建設。其次,大模型訓練數據的相關倫理制度建設。最后,整體性大模型倫理風險防范和管理等制度建設。前兩個層面強調制度的約束力和適用性,最后一個層面強調制度的約束力和覆蓋面。正式制度是非正式制度的基礎,對非正式制度具有補充作用,非正式制度是正式制度的延伸。三是變革組織架構。大模型企業加強自我倫理治理,且推動大模型倫理自律性制度有效施行,應進行相應的組織架構變革。首先,設置相對獨立的大模型技術顧問委員會,其對企業大模型技術和應用是否符合倫理監管政策和自律性倫理制度進行監督,并就相關倫理問題提出建議和解決措施。其次,設置大模型倫理委員會,統籌不同部門以落實倫理治理戰略,將企業已分散設置的數據隱私保護委員會、信息安全委員會、網絡安全委員會等進行有機整合,保證大模型企業倫理治理的統一性和全局性;或者,保留現有倫理委員會,但需根據大模型關鍵要素、生命周期不同階段和主要倫理失范現象等調整倫理審查、監督等方向和內容。最后,在業務部門設置大模型倫理專員或工作小組等,負責企業大模型倫理戰略、自律性制度和非正式制度在大模型技術研發、產品設計和生產過程的具體執行和引導等。四是創新自我倫理治理實踐,主要包括加強對外披露自我倫理治理相關內容,以及加強大模型倫理自治技術或工具的應用及創新。目前,大模型企業主要以企業社會責任報告、ESG報告和道德準則等專項報告為載體,需進一步將倫理自治相關披露內容從負責任算法、負責任人工智能延伸至負責任大模型。大模型倫理審查、測試、評估和補救等技術或工具有助于降低倫理失范現象的出現,提高大模型的安全性、可靠性和穩健性等。
(二) 發揮兩級守門人作用
第一,發揮數字守門人的倫理治理作用,不斷邁向平臺中立。歐盟《數字市場法》對數字守門人進行了詳細界定,其主要指超級平臺企業和大型平臺企業。數字守門人可以憑借其數據、算法和市場等優勢或權力獲取一定的倫理治理影響力,且以強大的網絡效應形成以平臺為中心的聯合企業體系,對這一體系的倫理治理發揮一定作用。因此,數字守門人兼具自律式守門人[44]和監管式守門人[45]的雙重角色,介于政府與其他企業主體之間。從平臺企業加重義務和社會責任履行的角度出發,進一步發揮數字守門人作用可從以下途徑展開:一是發揮超級平臺企業和大型平臺企業的自律式守門人作用。數字守門人在履行政府倫理監管政策并承擔相應違規責任的基礎上與用戶之間建立良好的信任關系且延伸至社會信任體系。首先,形成用戶數據的權屬清晰、數據安全和隱私保護等基礎性信任關系。在現行用戶隱私設置或信息收集等基礎上,明確用戶對數據的所有權、攜帶權和被遺忘權等,在用戶數據的存儲、使用和銷毀等過程中保護數據安全和用戶隱私等,尤其是杜絕用戶數據濫用和非法交易等。其次,在默認設置、訪問渠道和用戶推薦等平臺應用中形成透明、非歧視性和破除“信息繭房”等過程性信任關系。例如,部分用戶隱私聲明存在一定的形式性,將數據使用權和實際控制權一并讓渡的同時,也將隱私侵犯、數據濫用等倫理風險敞口暴露,過程性信任關系不可或缺。最后,在生成內容等服務提供或輸出結果中形成結果性信任關系。二是發揮超級平臺企業和大型平臺企業的監管式守門人作用。發揮平臺企業對用戶的部署領域、輸入內容和生成內容等方面的倫理“準監管”作用,憑借其控制力對用戶違背社會倫理規則、監管政策和平臺自制監管規則的行為或結果等采取干預措施或自行裁罰等,在聯合企業體系中產生威懾力和警示性。
第二,發揮政府終極守門人作用,加快倫理監管制度供給和監管機構設置步伐,創新監管工具和方式。政府是大模型倫理監管政策的主要供給主體,需逐步完善倫理監管制度體系。為應對大模型倫理失范對現行倫理監管制度提出的挑戰,應提高制度的前瞻性、全局性、靈活性和適用性。一是提高倫理監管制度的前瞻性。緊跟大模型技術發展前沿,政府所屬科研機構應加強對大模型倫理的相關研究,發揮其建言獻策的作用,力求以潛在倫理風險為導向,提前布局倫理監管制度建設。二是提高倫理監管制度的全局性,力求覆蓋大模型關鍵要素及生命周期。以大模型為監管對象,以關鍵要素為監管核心,以生命周期為監管跨度,改變數據、算法和服務提供者三者相分離的監管局面,形成系統性的倫理監管制度體系。三是提高倫理監管制度的靈活性和適用性。以大模型應用場景、風險等級與倫理治理方式相匹配為原則,在“分領域監管”理念的基礎上,引入“分場景監管”理念,實行重點場景、高風險等級重點監管,實現倫理監管制度制定的靈活性和適用性。其中,將法律法規等形式的硬性監管制度布局于重點場景、高風險領域,明確大模型關鍵要素和行為主體的倫理責任,劃出清晰的法律紅線和底線,提高制度約束的剛性。相反,對于非重點場景、低風險領域,則主要布局意見和辦法等形式的軟性倫理監管制度。
另外,政府應設置相應的大模型倫理監管機構,并注重不同層級監管機構之間合作與交流機制的形成和優化。一是設置雙層的倫理監管機構。考慮到單一制國家、復合制國家和聯盟等國家或聯合體結構的差異,在中央(聯邦) 政府、聯盟總部層面設置一個綜合性大模型倫理監管機構,以執行倫理審計、審查、評估、調查、救濟和監測倫理監管制度的實施等相關監管職能為主。其中,倫理審計是在現行“備案制”基礎上的延伸,是倫理監管約束力增強的體現。在地方政府(州)、成員國層面設置相應的倫理監管機構,與上述倫理監管機構之間存在一定行政隸屬關系,職能配置上相似。二是形成或優化雙層倫理監管機構的運行機制,核心為統一協調與合作交流,以保障倫理監管制度的執行、防范倫理失范的發生和相關倫理失范事件的處理等。此外,探索在監管機構內部設置一名首席大模型倫理治理官,對該機構的倫理監管事宜進行統籌和規劃,形成上下統一且專一的倫理監管機構體系。優化大模型倫理監管隊伍,創新監管工具。大模型等生成式人工智能應用屬于科技范疇,倫理監管屬于社會科學范疇,大模型倫理監管屬于兩者交叉領域,單純依靠其中一個學科領域的人員難以實現兼顧全面性和適用性的倫理監管。因此,在大模型倫理監管人才隊伍中應吸納專業技術人員,包含實際操作技術人員和行業技術專家。此外,在監管沙盒、工具包“A. I. Verify”等基礎上,政府仍需加快大模型倫理監管工具的創新。
(三) 形成全球性合作治理網絡
大模型倫理治理是全球性治理難題,需加強全球及區域間倫理治理合作與交流,以全球性或區域性國際組織為引領,以政府間合作與交流為重要形式,以制度建設和治理技術創新為具體表現,同時,社會輿論體系應把好倫理監督關,共同形成且織密全球性合作治理網絡。形成全球性合作治理網絡,推進大模型倫理治理“赤字”的綠化進程。一是全球性國際組織對倫理治理網絡進行整體性布局,多邊或雙邊等區域性國際組織進行符合當地需求的布局,以倡議書、規范和標準等不具有強制性的制度為主。除制度建設外,充分發揮國際組織的號召力和組織協調能力,以大模型技術發展和倫理治理為主題開展研究和交流,為制定倫理治理制度等提供智力支持,增強不同國家和區域的合作與交流,且逐漸形成倫理治理合力等目標。二是加強政府間及區域間倫理治理合作與交流。以訓練數據、用戶數據和算法等大模型關鍵要素跨境流動、國際數字貿易等現實需求為抓手,以貿易合作、技術合作合同等為切入點,以增強數據安全、技術保密性等為短期目標,將大模型倫理治理相關內容內嵌其中,不斷推動倫理治理從雙邊互認互信、多邊互認互信至全球性互認互信。三是創新倫理治理技術,實現以技術治理技術。增強全球性和多邊性技術組織的創新能力,大模型底層支撐是人工智能技術,模型黑箱、數據版權侵害等倫理失范現象的根源在于現行技術存在人類未解之謎或未涉足領域。首先,加強大模型技術自身的創新。聯合全球性、區域性或各國技術組織,以關鍵性算法、數據處理技術和隱私計算等為主要攻關領域,克服大模型生成內容不確定性對社會倫理體系的沖擊。其次,在大模型技術中添加倫理訓練和優化部分,使大模型原生道德倫理體系和衍生道德倫理體系均與人類價值對齊。四是發揮社會輿論體系的倫理監督作用。社會公眾是大模型應用者,是受益者也是受損害者,是大模型倫理監督最廣大的群體,是在倫理治理制度體系、治理機構和治理技術等措施之外的有效補充,具有柔性化、靈活性、及時性和覆蓋面廣等特征。
六、總結與展望
大模型的問世將人工智能技術從專用性、單一模態演進至通用性、多模態,助力人類生產生活數字化和智能化轉型提速,與此同時引發倫理失范及治理難題。本文在對現有研究進行梳理和分析基礎上,從生產力、生產工具相關理論對大模型屬性及倫理失范緣起進行探究,發現作為生產力的大模型存在技術非中性,作為生產工具的大模型內嵌人類倫理,生產力和生產工具雙重屬性的大模型將人類倫理與機器倫理糅合其中,大模型區別于傳統生產力和生產工具,其自身和生成內容均內嵌倫理。繼而從技術和生命周期角度對大模型倫理失范的關鍵要素進行解構,發現大模型倫理失范的技術起點是算法,關鍵中介是數據,行為主體是人類。針對大模型諸如模型黑箱、數據版權侵害且主體責任難確定、沖擊人類主體資格等倫理失范現象,對單要素和單環節、自上而下和以結果為導向的倫理治理模式提出挑戰,以大模型生命周期為時間維度,以關鍵要素為核心,本文構建了基于大模型關鍵要素的全生命周期倫理治理框架,以有效防范與治理大模型倫理失范。為推動大模型倫理治理新框架的有效運行,本文構建了包含兩層行為主體的自我治理、兩級守門人和全球性合作治理網絡等子體系的倫理治理生態體系,加快大模型倫理治理“赤字”的綠化進程。
綜合考慮大模型的技術演進、倫理失范特征、倫理治理進程等相關研究現狀,未來可在以下領域進行深入研究:一是以大模型應用場景為研究切入點,細化大模型應用場景分類,針對不同應用場景采取不同的倫理治理模式,實現大模型精細化治理、精準化治理。二是從大模型技術創新、迭代更新的視角,以算法黑箱、模型黑箱等關鍵倫理問題為核心,從技術和理論兩個層面開展如何實現以算法治理算法、以模型治理模型等相關研究。三是從法律層面,針對大模型倫理失范中不同行為主體的責任歸屬、責任界定和處罰措施等,開展系統性研究。
參考文獻:
[1] 張輝,劉鵬,姜鈞譯,等.ChatGPT:從技術創新到范式革命[J].科學學研究,2023,41(12):2113-2121.
[2] FOFFANO F, SCANTAMBURLO T, CORTES A.Investing in AI for social good: an analysis of European national strategies[J]. AI & society: the journal of human?centered systems and machine intelligence,2023,38(2):479-500.
[3] ROBERTE H,COWLS J,MORLEY J,et al.The Chinese approach to artificial intelligence: an analysis of policy,ethics, and regulation[J]. AI & society: the journal of human?centered systems and machine intelligence,2021,36
(1):59-77.
[4] 趙志耘,徐峰,高芳.關于人工智能倫理風險的若干認識[J].中國軟科學,2021(6):1-12.
[5] 孫蒙鴿,韓濤,王燕鵬,等.GPT技術變革對基礎科學研究的影響分析[J].中國科學院院刊,2023(8):1212-1224.
[6] 張凌寒.生成式人工智能的法律定位與分層治理[J].當代法學,2023(7):126-141.
[7] 王鈺,唐要家.人工智能應用如何影響企業創新寬度?[J].財經問題研究,2024(2):38-50.
[8] FAWAZ Q.ChatGPT in scientific and academic research:future fears and reassurances[J].Library hi tech news,2023,40(3):30-32.
[9] 陳兵.促進生成式人工智能規范發展的法治考量及實踐架構——兼評《生成式人工智能服務管理暫行辦法》相關條款[J].中國應用法學,2023(4):108-125.
[10] WEI J,WANG X,SCHUURMANS D,et al.Chain?of?thought prompting elicits reasoning in large language models[EB/OL](. 2022-01-28)[2024-02-26].https://arxiv.org/abs/2201.11903.
[11] MCLENNAN S,FISKE A,TIGARD D,et al. Embedded ethics: a proposal for integrating ethics into the development of medical AI[J]. BMC medical ethics,2022,23(1):1-10.
[12] JULES W,QUCHEN F,SAM H,et al.A prompt pattern catalog to enhance prompt engineering with ChatGPT[EB/OL].(2023-02-21)[2024-02-24].https://arxiv.org/pdf/2302.11382.pdf.
[13] 滕妍,王國豫,王迎春.通用模型的倫理與治理:挑戰及對策[J].中國科學院院刊,2022,37(9):1290-1299.
[14] 鄧悅,許弘楷,王詩菲.人工智能風險治理:模式、工具與策略[J].改革,2024(1):144-158.
[15] 張欣.面向產業鏈的治理:人工智能生成內容的技術機理與治理邏輯[J].行政法學研究,2023(6):43-60.
[16] 王沛然.從控制走向訓導:通用人工智能的“直覺”與治理路徑[J].東方法學,2023(6):188-198.
[17] 徐偉.論生成式人工智能服務提供者的法律地位及其責任——以ChatGPT為例[J].法律科學(西北政法大學學報),2023,41(4):69-80.
[18] 李石勇,卜傳丞.科技倫理治理中法治不能缺位[N].中國社會科學報,2022-06-14(2).
[19] 趙精武,王鑫,李大偉,等.ChatGPT:挑戰、發展與治理[J].北京航空航天大學學報(社會科學版),2023(3):188-192.
[20] LEANDRO M.Editorial:ChatGPT and the ethical aspects of artificial intelligence[J]. Revista de gest?o,2023,30(2):110-112.
[21] OZKAYA I.Application of large language models to software engineering tasks:opportunitier,risks,and implications[J]. IEEE software,2023,40(3):4-8.
[22] SOMEH I A,DAVERN M,BREIDBACH C F,et al.Ethical issues in big data analytics:a stake?holder perspective[J]. Communications of the association for information systems,2019,44(34):718-747.
[23] 續繼,王于鶴.數據治理體系的框架構建與全球市場展望——基于“數據二十條”的數據治理路徑探索[J].經濟學家,2024(1):25-35.
[24] 張欣.生成式人工智能的數據風險與治理路徑[J].法律科學(西北政法大學學報),2023,41(5):42-54.
[25] 丁曉東.論算法的法律規制[J].中國社會科學,2020(12):138-159+203.
[26] 劉艷紅.生成式人工智能的三大安全風險及法律規制——以ChatGPT為例[J].東方法學,2023(4):29-43.
[27] 肖紅軍.算法責任:理論證成、全景畫像與治理范式[J].管理世界,2022,38(4):200-226.
[28] 蘇宇.算法規制的譜系[J].中國法學,2020(3):165-184.
[29] 張凌寒.深度合成治理的邏輯更新與體系迭代——ChatGPT等生成型人工智能治理的中國路徑[J].法律科學(西北政法大學學報),2023,41(3):38-51.
[30] 周文,許凌云.論新質生產力:內涵特征與重要著力點[J].改革,2023(10):1-13.
[31] 周文,何雨晴.新質生產力:中國式現代化的新動能與新路徑[J].財經問題研究,2024(4):3-15.
[32] ROBERT,K.Algorithm= Logic + Control[J]. Communications of the ACM,1979,22(7):424-436.
[33] 陳雄燊. 人工智能倫理風險及其治理——基于算法審計制度的路徑[J]. 自然辯證法通訊,2023(10):138-141.
[34] 孫偉平.人工智能與人的“新異化”[J].中國社會科學,2020(12):119-137.
[35] 楊雙彪.人工智能的倫理困境及其規避進路——基于馬克思主義科技觀分析[J].理論觀察,2023(6):52-56.
[36] EDEN R,BURTON?JONES A,CASEY V,et al.Digital transformation requires workforce transformation[J]. MIS quarterly executive,2019,18(1):1-17.
[37] KIM E S.Deep learning and principal?agent problems of algorithmic governance:the new materialism perspective[J]. Technology in society,2020,63(11):101378.
[38] CRNKOVIC G D,?üRüKLü B.Robots:ethical by design[J]. Ethics and information technology,2012,14(1):61-71.
[39] MILLER K W.Moral responsibility for computing artifacts:the rules[J]. IT professional,2011,13(3):57-59.
[40] 孫保學.人工智能算法倫理及其風險[J].哲學動態,2019(10):93-99.
[41] JUNAID Q.Toward accountable humancentered AI: rationale and promising directions[J]. Communication and ethics in society,2022,22(2):329-342.
[42] PEARL J.The seven tools of causal inference,with reflections on machine learning[J]. Communications of the ACM,2019,62(3):54-60.
[43] REST J R.Moral development,advances in research and theory[M]. New York:Prager,1986:23.
[44] 候利陽.論互聯網平臺的法律主體地位[J].中外法學,2022,34(2):346-365.
[45] 解正山.約束數字守門人:超大型數字平臺加重義務研究[J].比較法研究,2023(4):166-184.
(責任編輯:尚培培)
