基于對齊原型網(wǎng)絡的小樣本異常流量分類
2024-06-29 22:43:18林同燦葛文翰王俊峰
四川大學學報(自然科學版) 2024年3期
林同燦 葛文翰 王俊峰
摘 要: 異常流量分類是應對網(wǎng)絡攻擊,制定網(wǎng)絡防御的前提. 網(wǎng)絡流量數(shù)據(jù)量大導致分析成本高,新型異常流量標記樣本數(shù)量少導致分類難度大,小樣本學習能有效應對這些問題. 但目前小樣本學習的方法仍然面對著復雜的模型或計算過程帶來的效率低下、訓練和測試樣本分布偏差導致的監(jiān)督崩潰問題. 本文提出了一種基于對齊的原型網(wǎng)絡,包含內(nèi)部對齊和外部對齊模塊. 該方法首先基于原型網(wǎng)絡在元學習框架下生成類別原型,其內(nèi)部對齊模塊通過支持集的預測損失來矯正原型在樣本分布空間中的偏差,外部對齊模塊通過對比原型和查詢集中樣本之間的相似性,將原型嵌入進查詢集的分布空間,生成動態(tài)矯正后的類別原型,從而增強了原型在不同分布下的動態(tài)適應能力. 基于對齊的原型網(wǎng)絡在沒有添加額外的參數(shù)和網(wǎng)絡結(jié)構的情況下改進了模型的訓練過程,保持快速檢測的同時提升了分類性能. 在CIC-FSIDS-2017 和CSE-FS-IDS-2018 數(shù)據(jù)集上的實驗結(jié)果表明,本文方法的F1 值為98%,相比于其他模型提高了3. 37% ~ 4. 85%,運行時間降低了89. 12%~93. 14%. 此外,該方法具有更強的魯棒性,在更多的異常類別和更少的支持樣本的情況下仍然能保持較好的性能.
關鍵詞: 異常流量; 入侵檢測; 小樣本學習
中圖分類號: TP183 文獻標志碼: A DOI: 10. 19907/j. 0490-6756. 2024. 030001
1 引言
全球網(wǎng)絡攻擊數(shù)量不斷增加,2022 年的網(wǎng)絡攻擊次數(shù)在高水平的情況下進一步增加了38%[1].隨著CHATGPT 等人工智能技術的快速進步[2],黑客可以以更快、更自動化的方式產(chǎn)生新的、更復雜的攻擊方法,開展攻擊活動,導致新的異常網(wǎng)絡流量的出現(xiàn),加劇了本已具有挑戰(zhàn)性的網(wǎng)絡安全形勢.
機器學習和深度學習方法已被廣泛應用于提高異常流量檢測和分類的自動化和智能化. 然而,其性能表現(xiàn)依賴于大量的訓練樣本,導致訓練成本高. 在如今網(wǎng)絡攻擊進化快的時代背景下,異常流量的類型不斷增多,但是能采集到的新型異常流量的標記樣本數(shù)量又很少,當訓練樣本不足時,模型性能會顯著降低[3]. 因此,如何實現(xiàn)有效、高效的小樣本異常流量分類是重要問題.
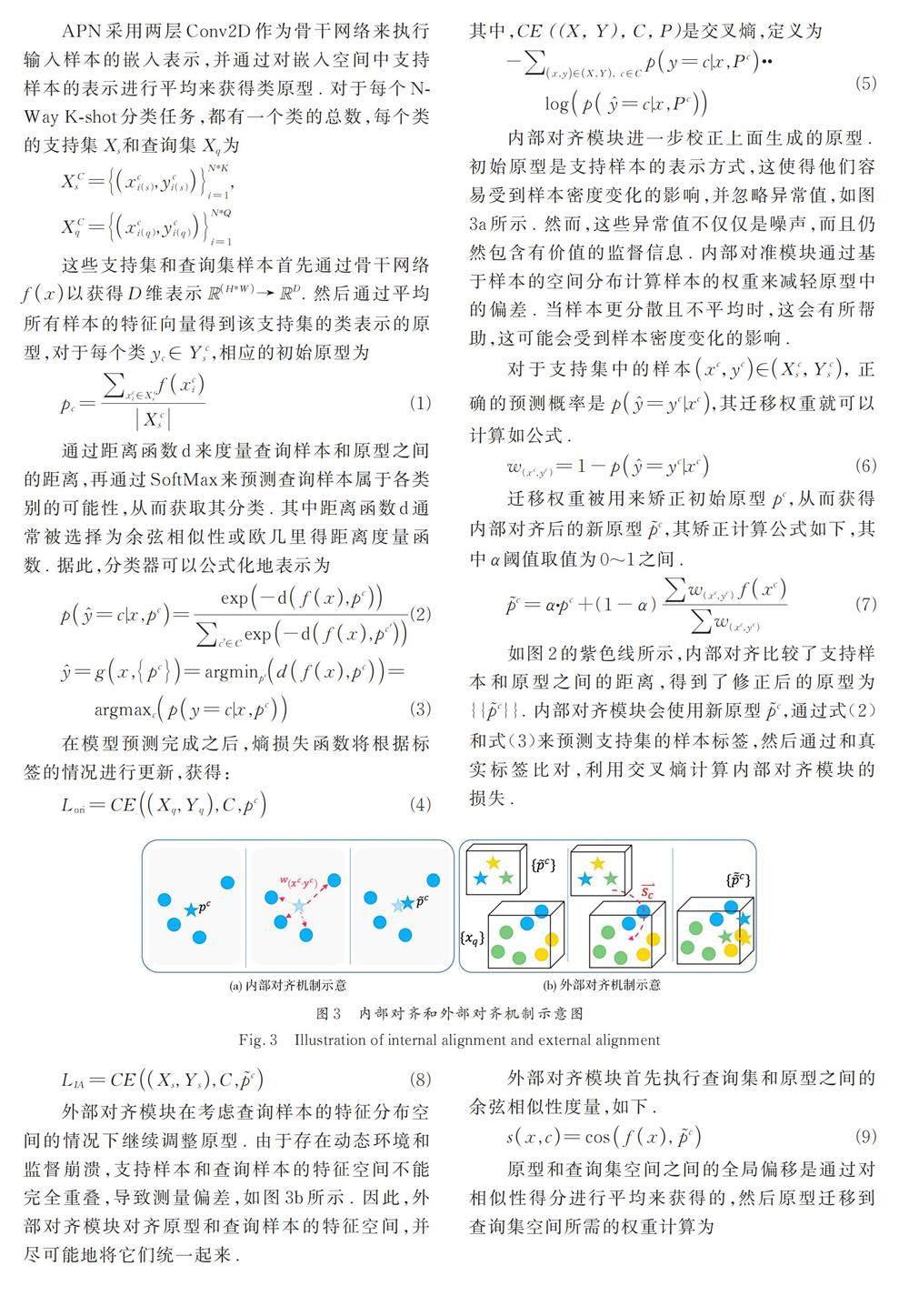
為了解決這一問題,研究人員開始關注小樣本學習[4]的方法,期望利用少量的標記數(shù)據(jù)來學習異常的模式特征,從而在減少訓練成本的同時,也提升對新型異常流量的檢測能力. 基于MAML 網(wǎng)絡的小樣本異常流量檢測方法[5]在元訓練和元測試的范式下,通過學習任務之間的通用表征,使得模型能夠滿足增量檢測的要求,這個框架已被廣泛應用,但該模型學習的通用表征,不能滿足復雜的流量環(huán)境的特征捕捉. 對流量特征的捕捉尚不充分. 基于孿生網(wǎng)絡(Siamese Network)的檢測方法[6- 8]在元學習的框架下,靈活支持多種特征提取器以在新的嵌入空間對流量進行表示,然后再通過樣本間的距離度量判斷異常流量的類別,但是其模型復雜、運行成本高,不適用于高效實時的檢測系統(tǒng). 基于原型網(wǎng)絡(Prototype Network)的檢測方法[9- 11],不再逐對比較樣本,而是先獲得一個異常流量的類別原型表征,再把待測樣本與類別原型進行比較從而實現(xiàn)分類. 原型網(wǎng)絡加快了操作速度,改進了對異常流量的抽象表示,但對原型生成有更高的要求,生成的類別原型的質(zhì)量是關鍵影響因素.
因此,現(xiàn)有的小樣本異常流量分類仍然存在不足,主要包括:(1) 監(jiān)督崩潰:網(wǎng)絡在訓練的時候會自動地挖掘各類別典型的分布特征,而忽視了特征和背景之間的關聯(lián),丟失了與其他類別相似性判斷的信息. 對于網(wǎng)絡流量而言,傳輸環(huán)境、報文格式,數(shù)據(jù)包上下文關系都存在著明顯的相似性,但是這些信息也蘊含著不同攻擊模式的特征,背景信息也就顯得更加重要. 當樣本數(shù)量很少的情況下,背景信息的偏差比較大,加劇了監(jiān)督崩潰的現(xiàn)象[12].(2) 操作效率:模型需要在特征提取和運行效率之間取得平衡,深度學習疊加模塊以及孿生網(wǎng)絡多次對比的方式會導致模型參數(shù)增多、復雜性提高、運行時間加長,不能滿足系統(tǒng)快速檢測的要求.
本文提出了一種基于對齊的原型網(wǎng)絡(AlignedPrototype Network,APN)來應對這些問題. 本模型選擇以原形網(wǎng)絡[13]為框架,充分利用其模型簡單有效的優(yōu)勢,以滿足運行效率的需要. 為了進一步解決監(jiān)督崩潰的問題,APN 引入了兩個無參數(shù)模塊:內(nèi)部對齊(Internal Alignment,IA)和外部對齊(External Alignment,EA). APN 通過加強對于已知的少量樣本的利用,考慮未知的測試樣本的特征分布,生成更加動態(tài)、精準的類別原型,使得模型能夠持續(xù)調(diào)整新型異常流量的特征抽取和類別原型刻畫. 具體而言,原形網(wǎng)絡對同一類的樣本進行聚合,生成類別原型;內(nèi)部對齊模塊校正原始原型,并通過測量支持樣本與類原型之間的距離預測損失來獲得自加權原型. 外部對齊模塊則通過測試樣本的特征分布,定位類別原型的相關特征,再通過預測的概率分布矩陣對相關特征進行加權,從而實現(xiàn)測試樣本和類別原型的特征對齊,獲得根據(jù)環(huán)境動態(tài)矯正而來的類別原型. 兩種對齊方式都以損失函數(shù)的形式添加進網(wǎng)絡中,在不增加網(wǎng)絡參數(shù)的前提下,生成更具分辨性的類別原型表征. 本文重構了兩個真實的流量數(shù)據(jù)集CIC-IDS-2017 和CSE-IDS-2018 來評估APN 在小樣本場景中的性能表現(xiàn). 實驗結(jié)果表明,模型的運行時間及內(nèi)存開銷更小、分類性能更強,在多個任務場景下的魯棒性更強.
2 相關工作
2. 1 異常流量分類
異常流量通常是由網(wǎng)絡攻擊產(chǎn)生的. 識別異常流量的類型有助于網(wǎng)絡防御和響應. 基于機器學習和深度學習的方法已經(jīng)得到應用,并取得了良好的效果[14]. 基于機器學習的方法可以自動處理網(wǎng)絡流特征,并且易于部署. 其中,支持向量機和決策樹方法是最主流的,其他常用的方法包括ANN、GA、K-NN、Na?ve Bayesian 等. 支持向量機方法使用非線性核將數(shù)據(jù)映射到高維空間,然后使用超平面將流量分類為不同的類. SVM-L[15]結(jié)合了LDA 成對公式的思想,通過優(yōu)化模型來調(diào)整分類器的超參數(shù),實驗驗證將基于統(tǒng)計規(guī)律和自然語言處理技術處理的特征輸入到SVM-L 中,可以獲得更高的精度. Hosseini 等[16]將SVM 和GA算法相結(jié)合,設計了用于特征選擇的MGA-SVM模塊,降低了計算復雜度,提高了檢測速度,以滿足大流量分析的需要. 決策樹是一種樹結(jié)構模型,將流量的特征屬性作為節(jié)點,檢測決策作為邊緣節(jié)點,其分支反映了決策過程,有助于解釋模型的決策路徑和特征的影響. Ahmim 等[17]提出了一種分層入侵檢測系統(tǒng),該系統(tǒng)采用了3 個基于樹的分類器. 該系統(tǒng)為每個分類器選擇不同的特征,在每個級別執(zhí)行分類任務,以實現(xiàn)對流量的粗略到精細分類,從而解決泛化能力有限的問題. K-NN 作為一種聚類方法,能夠提供基于實例的解釋,通過分析距離度量方法和最近鄰居,有助于了解模型對類別和樣本的理解,但是對異常點十分敏感. 樸素貝葉斯是一種基于貝葉斯定理的概率分類器,為異常流量分類提供了良好的基線. Khamaiseh等[18]將K-NN 和Naive Bayes 分類器用于SDN 中的網(wǎng)絡流量檢測,并證明了這兩種方法都能夠在SDN 的網(wǎng)絡環(huán)境中檢測異常流量. 張瑜等[19]則設計了AFSA 算法來自動適應特征的選擇來提升檢測的效果. 機器學習的成功取決于特征或規(guī)則的有效設計. 然而,識別每個獨特環(huán)境或任務的最佳細粒度流量特征可能具有挑戰(zhàn)性,特別是在小樣本異常流量場景中存在顯著噪聲干擾的情況下.
深度學習的算法主要包括以下核心骨干網(wǎng)絡CNN、RNN、LSTM、注意力機制和GAN 等,廣泛應用于異常流量分類任務[20, 21]. 這些算法在NSLKDD、KDD CUP99、CIC-IDS2017 等數(shù)據(jù)集[22]上進行了驗證,并取得了較好的成績. PBCNN[23]設計了一種分層的字節(jié)CNN,從原始流量包和網(wǎng)絡流中提取特征,并通過全連接層對其進行分類,在CIC-IDS-2017 和CSE-CIC-IDS2018 數(shù)據(jù)集上取得了顯著的結(jié)果. Elsherif [24]評估了RNN、LSTM、BRNN 和BLSTM 在NSL-KDD 上的性能,證明RNN 和LSTM 可以從歷史序列中捕獲流量特征,而BRNN 和BLSTM 具有雙向建模的特性,從而提高了召回率. 注意力機制具有更強的處理復雜輸入關系和序列關系的能力,引領了GPT、BERT等強大模型的發(fā)展. ET-BERT[25]利用BERT 強大的學習能力,在相關數(shù)據(jù)集上訓練模型來理解網(wǎng)絡流量的上下文信息,然后實現(xiàn)加密流量的分類,實現(xiàn)了良好的性能. 生成對抗性網(wǎng)絡(GenerativeAdversarial Network,GAN)可以通過生成樣本和判別樣本的競爭過程來提高生成樣本的水平.Ding 等人[26]設計了一個TACGAN 來生成更多的攻擊型數(shù)據(jù),并引入了信息損失來提高生成樣本和真實樣本之間的一致性,解決了數(shù)據(jù)樣本不平衡的問題. 深度學習方法可以自動提取特征,網(wǎng)絡模塊可以被設計用來表達和抽取不同的流量特征,本文的方法也基于深度學習對流量進行表征.但深度學習模型的性能取決于數(shù)據(jù)的豐富性. 當樣本量不足時,模型容易過擬合,導致模型性能急劇下降.
2. 2 小樣本學習及異常流量的應用
機器學習和深度學習無法應對樣本數(shù)量不足的情況,部分研究工作開始著眼于小樣本環(huán)境下對于異常流量的檢測和分類.
小樣本學習代表了一種新的機器學習范式,它利用先驗知識從有限數(shù)量的例子中有效地學習新的通用表示[4]. 目前,基于元學習的小樣本學習在計算機視覺和自然語言處理領域得到了廣泛的應用,并取得了巨大的成功. 流行的網(wǎng)絡包括MAML[27]、原型網(wǎng)絡[13]、孿生網(wǎng)絡[28]、匹配網(wǎng)絡[29]、關系網(wǎng)絡[30]等.
MAML 是基于任務粒度的小樣本學習,F(xiàn)eng等人[5]結(jié)合了MAML 算法,設計了一個用于小樣本異常流量檢測的框架. 該方法利用了33 個基于機器學習特征選擇的固定特征和LSTM 挖掘的時間特征,然后通過DNN 對其進行分類. 在元學習訓練過程中,通過多個N-way K-shot 分類任務獲得預訓練的DNN 模型參數(shù),然后在測試階段,基于新的類樣本調(diào)整模型參數(shù),以獲得適合類的分類模型. 這種方法的主要缺點是使用了固定的特征,這限制了模型的能力. 其次,MAML 算法需要在測試過程中不斷更新模型參數(shù),效率相對較低.
孿生網(wǎng)絡是簡單、有效的網(wǎng)絡模型之一,F(xiàn)CNet[7]就是一種基于孿生網(wǎng)絡的小樣本網(wǎng)絡入侵檢測框架,該方法首先排列組合所有的網(wǎng)絡流類別,構造了多個的二分類任務. 每個任務都將網(wǎng)絡流量轉(zhuǎn)換為圖像數(shù)據(jù),然后輸入到FC-Net 中,以計算每對樣本之間的相似性,從而進行分類,實現(xiàn)了95% 的平均準確率. Wang 等人[8]采用孿生膠囊網(wǎng)絡的方式進行樣本相似度的比較,利用改進的膠囊網(wǎng)絡模塊來捕捉特征之間的動態(tài)關系,提升檢測能力,同時改進了采樣方法,以解決數(shù)據(jù)不平衡的問題. 這些方法基于孿生網(wǎng)絡,具有良好的可擴展性和簡單的架構,在多個問題上都取得了良好的效果. 然而,訓練過程需要重復的成對比較步驟,效率低,運行速度慢.
原型網(wǎng)絡在多個領域也取得了不錯的表現(xiàn),Yu 等人[9]在NSL-KDD 和UNSWNB15 數(shù)據(jù)集上驗證了原型網(wǎng)絡流量分類的效果,并表明在各種分類場景下,與傳統(tǒng)的機器學習和深度學習方法相比,原型網(wǎng)絡可以實現(xiàn)優(yōu)越的性能. Wang 等人[10]從數(shù)據(jù)和特征貢獻的角度出發(fā),結(jié)合原型網(wǎng)絡的特征生成和欠采樣特性,提出了一種新的檢測方法. Guo 等人[11]提出GP-Net 中對流的全局信息和流有效載荷的字節(jié)位置關系進行了建模,提高了原型網(wǎng)絡在加密流檢測中的檢測性能. 本文選擇原型網(wǎng)絡作為基礎框架,進一步拓展其訓練方式和骨干網(wǎng)絡的設計,來解決支持集和查詢集之間的差異,防止監(jiān)督崩潰和操作效率低下的問題.
3 研究方法
3. 1 小樣本異常流量分類框架
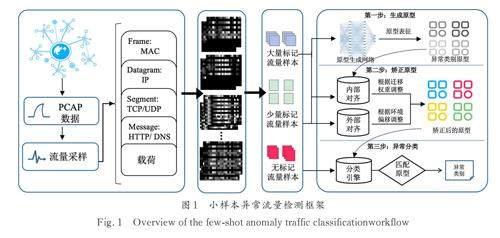
基于APN 網(wǎng)絡的小樣本異常流量分類框架如圖1 所示,包含4 個核心流程:流量收集、流量表示、任務組建和異常分類.
流量收集階段可以網(wǎng)絡流量監(jiān)控軟件來執(zhí)行,通過收集原始流量文件(如PCAP 格式)以最大限度地保留原始信息. 流量表示階段通過對網(wǎng)絡流量解析、裁剪獲得統(tǒng)一的流量尺寸,然后轉(zhuǎn)化成2D 灰度圖像. 根據(jù)標記樣本數(shù)量的情況,異常流量可以分為有大量標記樣本的類別、僅有少量標記樣本的類別. 任務組建階段基于小樣本N-wayK-shot 的分類任務設置,抽取樣本組建分類任務用于模型訓練. 在異常分類階段,每個任務會利用已標記的樣本來挖掘異常流量的類別原型,然后將未標記的樣本與生成的原型進行比較,從而實現(xiàn)分類.
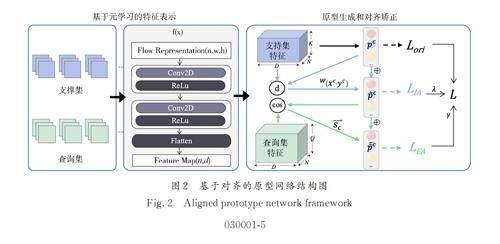
具體地,異常流量分類模塊輸入流量的表示X ∈ [ 0,256]n*W*H, 輸出分類結(jié)果 Y ∈ [ 1,…,C ]n.其中,W 和H 是處理圖像的寬度和長度,C 是異常類別的數(shù)量. 在元學習的訓練方式中,一個分類任務被看作一個樣本,在一個分類任務中,包含了支持集和查詢集兩種樣本集合. 在APN 中,模型會先將支持集的樣本使用原型網(wǎng)絡生成異常流量原型,以捕獲該類異常流量的特征空間. 初始原型在內(nèi)部對齊模塊(IA)和外部對齊模塊(EA)中得到進一步校正,其中內(nèi)部對齊通過為支持集樣本分配權重來克服支持集的密度偏差,外部對齊通過轉(zhuǎn)移到查詢集的特征空間來適應動態(tài)環(huán)境中的特征分布. 最后,將真實環(huán)境中的測試流量與對齊的原型進行匹配,并通過距離測量和相似性評估獲得流量的異常類別.
3. 2 網(wǎng)絡流量表示
網(wǎng)絡流量定義為一段時間內(nèi)的五元組< 源IP、目的地IP、源端口、目的地端口、協(xié)議>. 鑒于小樣本學習在圖像領域取得的巨大成功,網(wǎng)絡流被表征為捕捉特定內(nèi)容信息的圖像. 為了確保捕獲的信息是有效的,該過程遵循以下原則:(1) 保持生成圖像的時空結(jié)構的穩(wěn)定性,調(diào)節(jié)其大小,并為神經(jīng)網(wǎng)絡處理提供更合適的輸入數(shù)據(jù)源;(2) 保持網(wǎng)絡流量信息的真實性,并通過關注頭部信息來提取具有代表性的信息. 在網(wǎng)絡通信中,客戶端的初始數(shù)據(jù)包通常傳達更多關于其通信目的和行為信息的含義,而后續(xù)數(shù)據(jù)包主要傳輸特定數(shù)據(jù),信息量較小. 類似地,對于每個數(shù)據(jù)包,數(shù)據(jù)包的元數(shù)據(jù)和前一部分的負載信息更能描述數(shù)據(jù)包的總體含義. 具體步驟如下:
(1) 流量抽取:根據(jù)五元組格式從流量的原始記錄(如PCAP 格式)中解析包并提取、組裝成流量X.
(2) 流量采樣:對提取的流量進行采樣. 由于網(wǎng)絡流的有效載荷長度不一致,獲得的圖像大小也不一致,這對模型不友好. 雖然我們可以通過補0 的方式來保證圖像大小的一致性,但是補充過多的0 會造成表征數(shù)據(jù)的稀疏,影響模型收斂. 基于統(tǒng)計分析,確定網(wǎng)絡流的前M 個包進行保留,截斷M 之后的數(shù)據(jù)包. 特別地,為了保持流量包的時空連續(xù)性,我們將N 取平方. 對每個包的前N 2 個字節(jié)進行保留,截斷N 2 之后的字節(jié)內(nèi)容.
(3) 流量表示:采用灰度圖像來壓平通道,減少通道之間先驗關系的影響,最大限度地保留原始輸入信息的時空結(jié)構. 具體操作包括:首先對網(wǎng)絡流進行重新排列,生成大小為W 和H 的像素矩陣,滿足W*H ≥ M*N 2. 像素的每個點對應字節(jié)的值,字節(jié)的值為0~255,因此像素矩陣在視覺上是灰度圖像. 線性排列用于組織像素,當達到圖像的寬度時,像素繼續(xù)排列在下一行. 如果所有像素都排列完成,而圖像空間仍然有剩余,則用0 填充圖像.
3. 3 基于對齊的原型網(wǎng)絡(APN)
APN 的結(jié)構如圖2 所示,分為元學習的特征表示、原型生成與對齊兩部分. 原型生成和對齊可以進一步分為以下模塊:紫色線表示的內(nèi)部對齊(IA)和綠色線表示的的外部對齊(EA). 在模型訓練過程中,每個樣本是N-Way K-Shot Q-Query 的一個分類任務,命名為Episode. 其中,N 表示類的數(shù)量,K 表示每個類中包括的支持集樣本的數(shù)量,Q 表示每個類包括的查詢集樣本的數(shù)目. 每個事件中的訓練和測試數(shù)據(jù)集被命名為支持集( Xs ,Ys) 和查詢集( Xq ,Yq). 對于每次訓練,APN隨機組裝事件,然后讓模型執(zhí)行分類任務,通過損失來指導模型更新. 對于標簽較少的新類,APN 類似地構建分類任務,并提供有限的樣本作為支持集,并且模型可以基于先前學習的任務先驗知識來抽取和比較特征以執(zhí)行分類任務,從而預測查詢樣本的類.
