基于LightGBM模型的中國成人吸煙行為研究
2024-06-18 05:07:10劉忠華盧鑫梅文強趙旻胡彬彬張軻殷紅慧
現代信息科技 2024年7期
劉忠華 盧鑫 梅文強 趙旻 胡彬彬 張軻 殷紅慧
收稿日期:2023-07-13
基金項目:云南省煙草公司文山州公司科技計劃一般項目(20235326002)
DOI:10.19850/j.cnki.2096-4706.2024.07.027
摘? 要:采用2018年世界衛生組織在中國開展的成人煙草調查數據,對成人吸煙行為影響因素進行探究。首先對原始數據做數據清洗,包括剔除無關變量、組合新變量等步驟。其次結合卡方檢驗、方差分析以及最大互信息數對處理后的數據集進行特征選擇。再次基于XGBoost、LightGBM算法進行建模,對影響成人吸煙行為的因素進行排序和分析。最后基于表現較好的LightGBM模型進行變量組合建模,進一步挖掘吸煙者特征。經建模分析,識別得出成人性別、煙草環境、增稅態度、低焦油煙認知、學歷、年齡重要性由強至弱對吸煙行為產生影響。
關鍵詞:LightGBM;XGBoost;吸煙行為
中圖分類號:TP399 文獻標識碼:A 文章編號:2096-4706(2024)07-0128-09
Study of Adult Smoking Behavior in China Based on the LightGBM Model
LIU Zhonghua1, LU Xin1, MEI Wenqiang4, ZHAO Min1, HU Binbin2, ZHANG Ke3, YIN Honghui4
(1.China National Tobacca Corporation Yunnan Company, Kunming? 650011, China; 2.Yunnan Academy of Tobacco Agricultural Sciences, Kunming? 650031, China; 3.Yunnan Tobacco Quality Inspection & Supervision Station, Kunming? 650032, China;
4. Yunnan Tobacco Company Wenshan Prefecture Company, Wenshan? 663099, China)
Abstract: Using the adult tobacco survey data conducted by the World Health Organization in China in 2018, this study explores the influencing factors of adult smoking behavior. Firstly, perform data cleaning on the original data, including removing irrelevant variables, combining new variables, and other steps. Secondly, feature selection is performed on the processed dataset by combining Chi-square test, analysis of variance, and Maximal Information Coefficient (MIC). Then, it conducts modeling based on XGBoost and LightGBM algorithms, sorting and analyzing the factors affecting adult smoking behavior. Finally, based on the well performing LightGBM model, variable combination modeling is performed to further explore the characteristics of smokers. Through modeling and analysis, it is identified that adult gender, tobacco environment, attitude towards value-added tax, low tar smoke awareness, educational background, and age importance have a varying impact from strong to weak on smoking behavior.
Keywords: LightGBM; XGBoost; smoking behavior
0? 引? 言
煙草作為一種嗜好品,長期吸食會對人體健康產生一定影響。煙草煙霧中含有數百種有毒有害物質,其中包括至少69種致癌物質。吸煙不僅對吸煙者自身健康有害,而且對周圍不吸煙者也產生危害。在過去的50年里,越來越多無可爭辯的科學證據表明,使用煙草制品或接觸二手煙會導致死亡、疾病和殘疾。根據《世界衛生報告》,在全球8個主要死因中,有6個與吸煙有關,而吸煙每年導致多達700萬人死亡。為了遏制煙草流行,減少煙草對健康和經濟的破壞性影響,世衛組織制定了煙草控制框架公約(FCTC),這是第一個國際公共衛生條約,也是最廣泛接受和最迅速實施的條約之一。到目前為止,已有181個國家簽署了《煙草控制框架公約》,中國是早期簽署國之一。該公約要求簽署國應建立煙草監測系統,提供準確的國家和全球煙草使用數據,以估算煙草使用對公共衛生和經濟的影響,并進一步評估煙草控制政策的有效性。
根據國家衛生委員會的工作計劃,在世界衛生組織的支持下,中國疾病預防控制中心在2018年7月至12月期間,按照全球成人煙草調查標準,在中國開展了2018年成人煙草調查。該調查是一項針對15歲及以上非集體中國居民的家庭調查,調查內容包括背景資料、煙草使用、電子煙使用、戒煙、二手煙、煙草價格、煙草控制運動、煙草廣告、宣傳和贊助、煙草使用知識、態度和看法等。本次調查采用分層多階段整群隨機抽樣的方法,最終得到19 376份有效問卷。對于收集到的問卷,WHO研究人員進行統計分析后,用于了解該國總體煙草流行情況,以及城市和農村地區、性別的煙草流行情況等問題。近年來,基于梯度提升決策樹(Light Gradient Boosting Machine, LightGBM)的算法快速發展[1,2],已被廣泛用于交通[3,4]、醫學[5,6]、金融[7-9]、防災[10]、警務[11]等領域。本文基于WHO組織調查數據,借助集成機器學習模型XGBoost、LightGBM進行數據挖掘,探究影響中國成人吸煙行為的主要因素,并通過對部分因素進行組合,進一步刻畫出吸煙者和非吸煙者畫像。最終,借助研究結果,針對不同特征的人群,提出更為準確的控煙建議。同時,也可根據建立得出的最優模型對中國成人吸煙行為進行預測。
1? 數據預處理
1.1? 處理目的
在進行建模分析之前,為得到表現較好的模型,需要對數據進行預處理[12]。收集數據采用的抽樣方法為WHO制定的多階段隨機整群抽樣方法,得到的樣本代表性良好。數據清洗的目的是讓數據更加規整,主要包括剔除無關變量、組合新變量等步驟。特征選擇則是幫助保留對模型結果有顯著性影響的特征,化繁為簡,增強模型的可解釋性。
1.2? 抽樣方法
調查采用分層多階段隨機整群抽樣方法[13]。在設計過程中,充分考慮了與以往調查數據進行縱向可比性的需要,以客觀反映煙草使用和煙草控制政策的現狀。抽樣過程如下:首先,全國按地理區域(中北部、東北部、中東部、中南部、西南部和西北部)和城鄉(區縣)劃分為12個地層。
第一階段抽樣:在2010年保留的100個監測點的基礎上,再選擇100個監測點。在12個地層中,主要采樣級別為縣/區級別。每個階層的原始樣本規模與該地區的總戶數成正比。根據每個縣/區的戶籍數量,采用概率比例抽樣法(PPS)選擇每個階層的縣/區。在2018年的調查中,新選出了50個縣和50個區;因此,最終選定的主要樣本單元總數為200個。
第二階段抽樣:首先,在第一階段選擇的縣/區中,采用PPS法選擇了2個村或居委會。因此,全國共選出400個村或居委會。如果選定的村或居委會的戶籍人口在1 000戶至2 000戶之間,則該村或居委會被視為第二階段的最終樣本單元;如果選定的村或居委會的戶籍人口超過2 000人,則將村或居委會分成若干部分,每個部分約有1 000戶。采用簡單隨機抽樣法選擇一個斷面作為第二階段的最終樣本單元。
第三階段抽樣:采用簡單隨機抽樣方法,從每個選定部門/村/居委會的住戶名單中選擇55戶,全國共有22 000戶。由于部分路段的空置住戶相對較多,抽樣時樣本量有所擴大,全國共選擇24 370戶。
第四階段抽樣:根據選定的住戶名單進行住戶調查,根據調查問卷記錄住戶成員的信息,并從每戶中隨機選擇一名成員作為受訪者,最終,總共有19 376人完成了個人調查。
1.3? 數據清洗
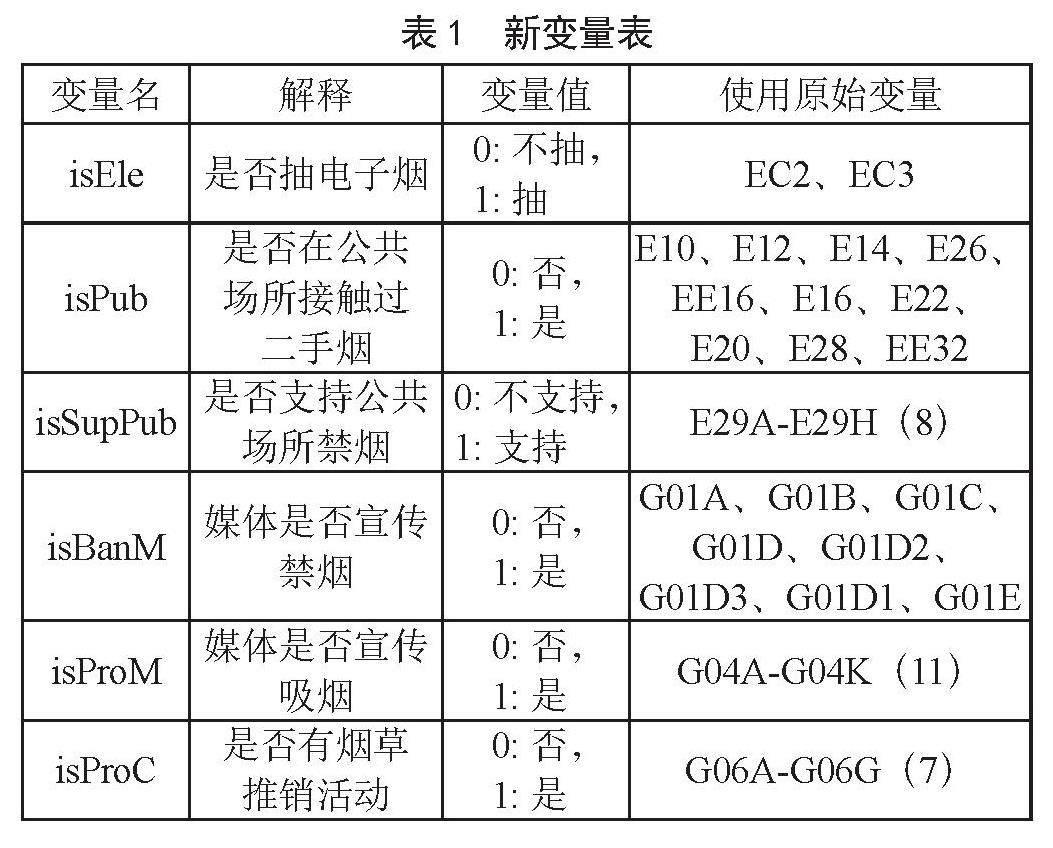
使用數據中的樣本權重變量(gatsweight),經過計算調整樣本數量,最終得到60 350條樣本數據,代表中國15歲及以上的男性及女性的整體情況。數據中一共包含339個變量,包含個人背景資料、煙草使用、電子煙使用、戒煙、二手煙、煙草價格、煙草控制運動、煙草廣告、宣傳和贊助、煙草使用知識、態度和看法等方面內容。針對研究問題對數據做如下清洗:一是剔除無關變量。剔除與研究問題——是否抽煙無關的變量,以及只針對部分人群(如吸煙者)提問而產生的變量,保留82個變量做后續研究。二是組合部分變量,得到新變量。結合問卷信息,對類型一致或相似的變量進行組合,經過組合,得到6個新變量,如表1所示。
1.4? 變量值的處理
問卷中變量值7、77含義為:Don't know,9、99含義為:Refuse to answer,將其用缺失值替換,由于集成機器學習模型對缺失值兼容,不需要進行缺失值填充;涉及是非問題的變量值1含義為:Yes,2含義為:No,將2替換為0,后續建模時即可將該類型變量作為0~1變量來處理;對于部分有序離散型變量,根據變量值含義調整數值大小;對于多分類的無序離散型變量(假設含有n個類別),結合其變量值分布,進行獨熱編碼,最終處理為n個0~1變量。表2為多分類無序離散型變量處理表。
1.5? 剔除類別分布不平衡變量
對于無序離散型變量,部分變量的類別分布過于極端,某類別樣本達到總樣本的90%以上,此變量很難對模型擬合效果的提升產生貢獻,考慮將其進行剔除處理。經過上述清洗過程后得到29個變量,其中因變量為是否吸煙(isSmoke),自變量28個,包含連續型變量、有序離散型變量及無序離散型變量。相關變量說明如表3所示。
2? 特征選擇
2.1? 離散型變量特征選擇
對于本文研究的問題來說,如果一個離散型特征取值在吸煙組和不吸煙組占比是相同的,就認為這個變量對成人吸煙與否是沒有影響的;如果該離散型特征取值在吸煙組和不吸煙組占比相差非常大,就認為該變量對成人吸煙與否影響非常大,即通過分析對比離散型變量不同取值在不同組之間分布有無顯著差異,進行離散型變量的特征選擇。由于考慮的是兩個屬性變量之間是否有聯系,采用列聯表分析的方法,列聯表分析使用的是卡方統計量[14]。下面先介紹列聯表分析的統計量卡方檢驗,以變量Male說明列聯表篩選變量的原理與步驟。卡方檢驗方式如下:
若用f0表示觀測值頻數,用fe表示期望值頻數,χ2統計量可寫為:
如果在一定顯著性水平下,χ2統計量大于所對應的χ2(n),那么我們認為拒絕原假設,我們就認為檢測的兩屬性之間是不獨立的,反之。下面以變量Male這一變量舉例說明。表4是性別在不同組內的實際人數分布和期望人數分布,對應的卡方統計量計算為:
在α = 0.05的顯著性水平下,,可見18 095 ? 3.84,作出拒絕原假設的判斷,即認為性別與是否吸煙是顯著相關的。
同樣的,對其他的離散型變量依次進行卡方檢驗,進行變量篩選。
2.2? 連續型變量特征選擇
在這一節中,采用單因素方差分析方法進行變量選擇。需要說明,將有序離散型變量煙草環境(TobaccoEnv)、低焦油煙認知(LowtarAware)當作連續型變量進行處理。方差分析的一般步驟如下:
1)提出原假設與備擇假設。此問題原假設為是否吸煙對受訪者特征沒有影響。
2)構造檢驗統計量。計算組間平方和SSA、組內平方和SSE,構造F統計量:
其中,k為因素水平個數,n為樣本總數。SSA與SSE定義為:
3)統計決策。根據計算出來的F統計量在一定顯著性水平下判斷是否拒絕原假設。下面以年齡這一變量舉例說明方差分析的步驟,如表5所示。即這里分別計算不同組的組內、組間平方和。由于這里數據量過大,不展示詳細的計算步驟。由上述計算得出拒絕原假設,保留年齡變量。同樣的,對剩余的連續型變量依次進行方差分析,進行變量篩選。
2.3? 依據變量相關性進行特征選擇
在最后建模之前,我們考慮變量間可能會存在一定程度相關性,這會影響建模結果。用衡量兩變量間相關關系的最大互信息數(MIC)作為判斷標準,最大互信息數不局限于線性關系,也可以衡量變量間的非線性關系。MIC的計算公式為:
MIC計算的時候會a×b的網格劃分數據空間。經計算得到兩變量間MIC值結果,如表6所示。
本文對存在相關性的變量處理如下:若兩變量之間MIC值大于0.7,結合卡方檢驗以方差分析結果進行判斷,只將其中一個變量納入建模的數據集中。經過上述特征選擇,最終選取的16個變量用于后續建模,具體說明如表7所示。文中使用的模型XGBoost、LightGBM均是在梯度提升決策樹模型(GBDT)的基礎上改進而來,由于運算速度快、效果好的優點,在目前各個研究領域內被廣泛使用。
3? 模型方法
3.1? XGBoost模型
XGBoost(eXtreme Gradient Boosting)相較于傳統GBDT在效率與準確率上有較大提升。它本質上是一種通過組合弱學習器來產生強學習的Boosting算法,相比于較早的Adaboost通過調整每一輪訓練樣本的權重,XGBoost是通過擬合上一輪學習器的殘差來訓練模型。
上式是XGBoost的目標函數,第一部分是訓練誤差,第二部分是每棵樹的復雜度的和。主要有以下優點:一是高度靈活性。支持線性分類器,對代價函數進行二階泰勒展開。二是正則化。在代價函數加入了正則項,用于控制模型復雜度,防止過擬合。三是自動缺失值處理。對于存在缺失值的特征,可以自動學習出它的分裂方向。四是列抽樣。借鑒了Randomforest對列隨機抽樣的做法,不僅能降低過擬合,還能減少計算量。
3.2? LightGBM模型
LightGBM算法是2017年由微軟團隊提出的GBDT算法的改進版,是基于梯度的單面采樣算法(GOSS)和特征捆綁算法(EFB)的結合。GOSS采樣認為梯度大的樣本點會貢獻貢多的信息增益,因此GOSS進行下采樣的時候保留大梯度的數據,按比例隨機采樣梯度小的樣本點。EFB算法通過綁定互斥的特征來減少互斥特征的數量從而實現降維的目的。LighGBM采用了Histogram算法,將連續特征離散化固定到固定數量的bins上。主要有以下優點:一是時間復雜度低。采用直方圖算法將遍歷樣本轉變為遍歷直方圖;二是計算量小。采用了基于Leaf-wise算法的增長策略構建樹;三是內存占用少。采用互斥特征捆綁算法減少了特征數量;四是支持并行學習。采用優化后的特征并行、數據并行方法加速計算,當數據量特別大的時候還可以采用投票并行的策略。
4? 模型構建與評估
數據預處理完成后,分別建立XGBoost、LightGBM模型,用AUC值作為模型主要評價指標。依據模型繪制出決策樹,并進行特征重要性排序,從而得出結論。
4.1? 模型評價指標
對于二分類模型,其閾值可能設定的高或低,通過設定不同的閾值得到不同的假正類率(FPR)和真正類率(TPR),ROC曲線就是將同一模型每個閾值的FPR作為橫坐標,TPR作為縱坐標所形成的曲線。
由于ROC曲線的形狀不好量化比較,因此需要結合ROC曲線與坐標系所圍成的面積(AUC)來評價模型的預測性能。AUC評價指標相對于其他指標而言,更能衡量模型對于不平衡數據的預測能力,不關注具體得分,只關注排序結果,不需要設定閾值,評估效果更好。因此,本文選用AUC值作為模型評價指標。
4.2? 模型建立——XGBoost
建模過程分為以下步驟:
1)訓練集與測試集劃分。按照8:2的比例劃分訓練集與測試集,在訓練集進行模型訓練,在測試集上用AUC值進行模型評價。
2)網格搜索調參。網格搜索算法是一種最簡單也是最常用的超參數搜索算法,給定參數搜索范圍,輸出最優化的參數,如表8所示。
3)最優模型訓練。給定最優化的參數,在訓練集上進行訓練,在測試集上的AUC值為0.872,模型泛化能力強,圖1為ROC曲線。
4)獲得模型結果。依據建立出的模型,可以繪制出決策樹,如圖2所示。
由圖2可得出以下結論:
用特征分裂后帶來的平均增益作為特征重要性評估標準,得到如圖3所示的排序,其中,性別、煙草環境、是否支持增稅為判斷吸煙者的主要特征。可見,改善煙草環境能夠有效降低成人的吸煙率,國家可出臺相關政策進行管控。
重要性排前5的特征對AUC值的提升如表9所示。
4.3? 模型建立——LightGBM
建模過程分為以下步驟:
1)訓練集與測試集劃分。按照8:2的比例劃分訓練集與測試集,在訓練集進行模型訓練,在測試集上用AUC值進行模型評價。
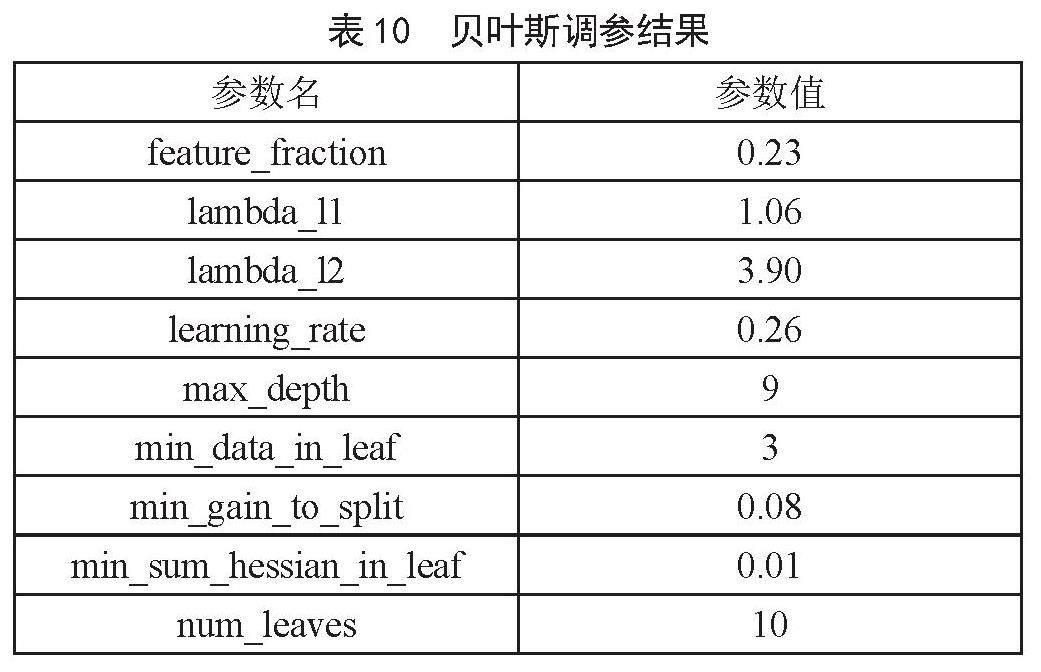
2)貝葉斯全局優化調參。貝葉斯優化是一個很有效的全局優化算法,目標是為了找到全局最優解。模型主要參數的選擇如表10所示。
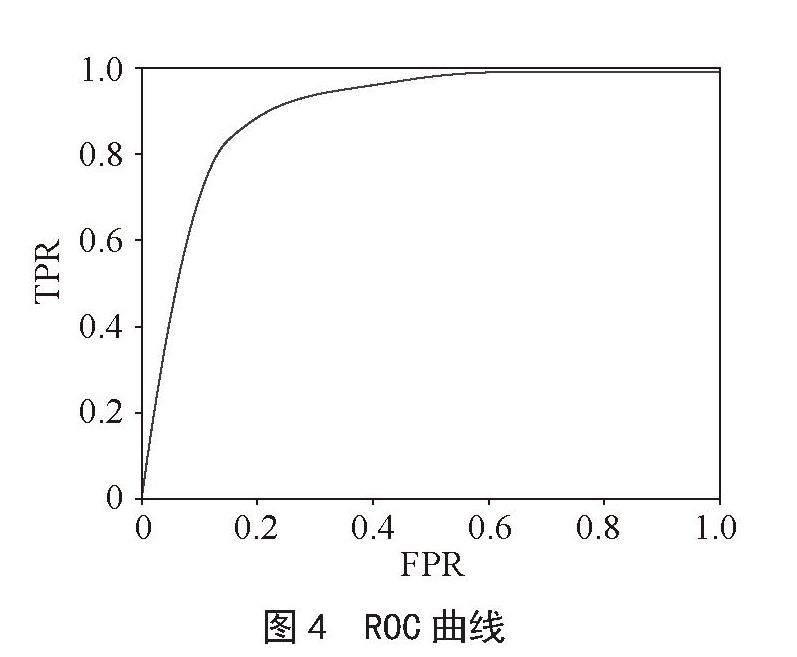
3)最優模型訓練。給定最優化的參數,在訓練集上進行訓練,在測試集上的AUC值為0.874,模型泛化能力強,圖4為ROC曲線。
4)獲得模型結果。用全部變量進行建模,繪制出決策樹,如圖5所示。
依據該圖的不同分支,可得出結論:
1)吸煙者畫像:高中以下學歷、在媒體上見過吸煙場景的男性。
2)不吸煙者畫像:高中以上學歷、未在媒體上見過吸煙場景的男性。
用特征分裂后帶來的平均增益作為特征重要性評估標準,得到如圖6所示的排序。
由圖6可知,與XGBoost模型相同,性別、煙草環境、是否支持增稅為判斷吸煙者的主要特征。重要性排前5的特征對AUC值的提升如表11所示。
為進一步刻畫出吸煙者畫像,詳細了解其特征,對部分變量進行組合建模,對繪制出的決策樹圖像進行分析,得出結論。
依據圖7,可得出吸煙者畫像為:支持增稅、不認同低焦油煙危害以及吸煙引起心臟病;不支持增稅、認同低焦油煙危害、18.5歲以上;在公共場所接觸過二手煙、初中學歷以下、18.5歲以上;未在公共場所接觸過二手煙、年齡37.5歲以下;家里7口人以上、高中以下學歷、農民工;家里6口人以下、小學以下學歷、非農民工。
5? 結? 論
本文基于WHO組織2018年在中國開展的成人煙草調查數據,采用多階段隨機整群抽樣方法,對其進行數據清洗、特征選擇后,將XGBoost、LightGBM算法運用到成人吸煙行為預測模型中。研究表明,在算法上,LightGBM運行速度和模型分類能力均優于XGBoost;影響因素分析上,XGBoost和LightGBM算法均給出了影響因素重要性排序圖,主要因素有:性別、煙草環境、增稅態度、低焦油煙認知、學歷、年齡等。通過對組合變量進行建模,由繪制出的決策樹可以進一步刻畫出吸煙者畫,便于相關管理部門和控煙組織針對不同特征人群制定個性化控煙政策提供決策依據。
參考文獻:
[1] 尹超英,邵春福,黃兆國,等.基于梯度提升決策樹的多尺度建成環境對小汽車擁有的影響 [J].吉林大學學報:工學版,2022,52(3):572-577.
[2] 生紅瑩,趙偉國,陳揚,等.基于深度數據挖掘的電力系統短期負荷預測 [J].吉林大學學報:信息科學版,2023,41(1):131-137.
[3] 常碩,張彥春.基于袋外預測和擴展空間的隨機森林改進算法 [J].計算機工程,2022,48(3):1-9.
[4] 甘紅楠,張凱.參數自適應下基于近鄰圖的近似最近鄰搜索 [J].計算機工程,2022,48(9):28-36.
[5] 彭俊,項薇,謝勇,等.基于LightGBM多階段醫療服務等待時間的預測研究 [J].計算機應用與軟件,2022,39(12):119-124.
[6] 閆瑞平,王習亮,姚粉霞,等.決策樹模型與Logistic回歸分析模型識別高血壓危險因素的效果比較 [J].中華疾病控制雜志,2022,26(2):218-222.
[7] 胡嘉麟.基于LightGBM模型的車輛保險購買興趣預測研究 [D].大連:大連理工大學,2021.
[8] 張漢平.基于LightGBM模型的個人貸款違約預測的研究 [D].武漢:華中師范大學,2021.
[9] 郭長東.基于XGBoost模型的股票預測研究 [D].延吉:延邊大學,2021.
[10] 范桂英,湯軍,高賢君,等.基于LightGBM的南陽市西部地區山洪災害風險評價 [J].中國農村水利水電,2023(8):135-141+156.
[11] 錢芳慧,蔡競.基于LightGBM的犯罪類型預測模型研究 [J].計算機仿真,2023,40(1):25-30.
[12] 吳照明,胡西川.基于LightGBM信貸風控模型的算法優化 [J].計算機應用與軟件,2022,39(6):342-349.
[13] 郭長帥,卓建偉.基于數據挖掘算法的流動人口定居意愿研究 [J].管理現代化,2019,39(3):81-86.
[14] 馮斌,張又文,唐昕,等.基于BiLSTM-Attention神經網絡的電力設備缺陷文本挖掘 [J].中國電機工程學報,2020,40(S1):1-10.
作者簡介:劉忠華(1982—),男,漢族,云南楚雄人,統計師,農藝師,碩士研究生,主要研究方向:應用統計和數字農業;通訊作者:殷紅慧(1977—),女,漢族,云南玉溪人,高級農藝師,碩士,主要研究方向:煙草農業研究。
