基于預訓練語言模型的旅游評論文本方面級情感分析研究
2024-06-18 20:37:20謝宇欣肖克晶曹少中張寒姜丹
現代信息科技 2024年7期
謝宇欣 肖克晶 曹少中 張寒 姜丹


收稿日期:2023-08-24
基金項目:基于深度學習的虛假新聞檢測關鍵技術研究(27170123034)
DOI:10.19850/j.cnki.2096-4706.2024.07.029
摘? 要:為了促進旅游行業的消費和經濟發展,對游客在線上平臺發表的景區評論文本進行分析,深入挖掘其中的細粒度情感信息,以更好地迎合游客的偏好。在實際場景中,一個句子會涉及多個實體詞,致使難以準確識別它們對應的情感屬性關系;且旅游場景下的數據集存在稀缺和樣本不平衡問題。由此構建了基于深度學習和提示知識的預訓練語言模型,通過構建離散提示模板聯合訓練兩個子任務,并對數據集中的少數樣本進行了數據增強處理,同時在訓練階段為損失函數設置不同的權重。實驗結果顯示,模型在旅游評論文本數據集和公開數據集SemEval2014_Restaruant上取得了顯著效果,F1值分別達到了80.81%和83.71%,有助于旅游機構實現對每個城市景點的個性化分析。
關鍵詞:語言模型;提示學習;方面級情感分析;預訓練模型
中圖分類號:TP391.1;TP183 文獻標識碼:A 文章編號:2096-4706(2024)07-0141-06
Aspect-based Sentiment Analysis Research of Tourism Review Text Based on
Pre-trained Language Models
XIE Yuxin, XIAO Kejing, CAO Shaozhong, ZHANG Han, JIANG Dan
(Beijing Institute of Graphic Communication, Beijing? 102600, China)
Abstract: In order to promote consumption in the tourism industry and economic development, we analyze the scenic spot comment texts published by tourists on online platforms, and deeply explore the fine-grained emotional information in them, in order to better cater to the preferences of tourists. In actual scenarios, a sentence may involve multiple entity words, making it difficult to accurately identify their corresponding emotional attribute relationships. Moreover, there are issues of scarcity and imbalanced samples in the dataset of tourism scenarios. A pre-trained language model based on Deep Learning and prompt knowledge is constructed. Two sub tasks are jointly trained by constructing a discrete prompt template, and data augmentation is performed on a few samples in the dataset. At the same time, different weights are set for the loss function during the training phase. The experimental results show that the model has achieved significant results on the tourism review text dataset and the public dataset SemEval2014-Restarantt, with F1 values reaching 80.81% and 83.71%, respectively, which helps tourism institutions to achieve personalized analysis of each city's scenic spots.
Keywords: language model; prompt learning; aspect-based sentiment analysis; pre-trained model
0? 引? 言
隨著國內旅游市場逐步放開,國內旅游市場在短時間內已經迅速復蘇。因此,如何挖掘城市熱點并吸引游客成為各地旅游機構的首要任務。對游客在線上平臺發表的觀點和評論文本,進一步進行文本情感分析是非常必要的,這不僅可以幫助各級旅游部門和市場主體對旅游產業進行合理規劃,還能更好地推進旅游目的地建設。傳統的文本情感分析研究主要是對句子級和篇章級進行情感預測,即識別整個句子或文檔的整體情感極性。在預測過程中,通常假設在給定的文本中只對單個實體表達了唯一的情感,然而在實際應用中可能并非如此。辨別更加細致的方面級意見和情感需求,即方面級情感分析(Aspect-Based Sentiment Analysis, ABSA),在實際應用中具有更大的意義。2000年初,Hu [1]等人建立了基于規則的細粒度情感分析模型,推動了該領域技術方法的發展;2010年Thet [2]等人明確定義了方面級情感分析(ABSA)的概念,并將評論對象“方面”定義為實體的屬性或組成部分;2012年Liu [3]等人進一步明確給出了觀點的定義:“從相關文本中識別出文本項(text item)的情感元素,可以是單個或多個情感元素,它們之間存在依賴關系”,這為方面級情感分析研究指明了方向。
針對端到端的ABSA復合任務,許多研究模型通常采用并行訓練策略,在復合任務學習框架中同時訓練兩個獨立的子任務,然后將兩個子任務的輸出進行結合,以獲得最終的預測結果。然而采用單獨訓練方式并未有效地加強兩個子任務之間的關聯性,也忽視了實體識別和方面情感分類任務之間的相互影響與關系。特別是在處理句子中存在多個實體的情況下,在對本文所涉及的旅游文本數據集進行分析時,我們發現在真實場景中,一個句子往往包含多個實體,而且不同實體可能涉及相同或相關的情感屬性。面對這種情況,準確地識別句子中的多個實體及其對應的情感屬性成為一個關鍵問題,如果句子的結構復雜或存在歧義,可能會導致屬性識別變得困難,從而影響后續的情感分類過程。
由此本文提出了實體識別和方面情感分類任務聯合訓練的模型框架:將實體識別和情感屬性識別作為聯合任務來進行訓練,促使模型學習到實體和屬性之間的關聯規律,同時將實體識別的輸出內容生成離散提示模板(Discrete Prompt Template),作為提示知識融入情感屬性分類任務中,幫助模型在處理屬性關系時獲得更好的表示和推理能力。另外,由于旅游領域的評論文本具有特殊性,存在著樣本缺乏和不平衡的問題,直接使用通用數據集進行訓練時,模型會傾向于預測多數類別,模型更容易在訓練過程中學習到這些類別的特征。因此,在本文中,我們采用數據增強的方法構建句子中包含多個實體詞的數據集。在訓練過程中,為不同類別設置不同的權重,以使模型更專注于學習少數類別樣本,從而提高模型對少數類別情感分類的準確率。同時,通過數據增強技術增加少數類別樣本的數量,實現數據集中不同類別樣本的平衡,進一步改善模型在少數類別上的性能。
1? 相關技術
1.1? ATE和ATSC
假設給定一組訓練樣本中的第i個句子,,其中n是句子中B、I、O等標記的個數;方面實體提取(ATE)任務的目的是提取方面實體詞的集合 ,其中m是句子si中方面實體的個數。方面實體提取任務可以表示為Ai = PLMATE(Si),其中PLM指的是預訓練的語言模型,訓練時將第i個句子si作為輸入傳遞給模型,句子中對應的方面項Ai為輸出標簽。
1.2? Prompt機制
在本文的聯合訓練模型中,利用實體識別的輸出結果構建生成離散提示模板,將其作為提示知識融入情感屬性分類任務中,離散提示模板是一種用于文本相關任務的模板或指令,可以提供結構化的方式來引導文本的內容,以滿足特定的需求或約束。離散提示模板在生成文本時強制要求模型遵循一些指定的規則、主題或格式,這有助于控制生成的文本,使其更加符合特定的語境和目標。然后將生成的提示指令符(Instruct prompt)和句子同時作為方面實體情感分類(ATSC)任務的輸入。引導模型更好地學習實體和屬性之間的關聯信息,提示指令符作為一種特定的文本輸入,用于指導模型生成特定類型的輸出,由此通過引入提示指令符來告知模型當前需要執行的任務,即識別出提示的實體詞對應的情感屬性。
2? 模型設計
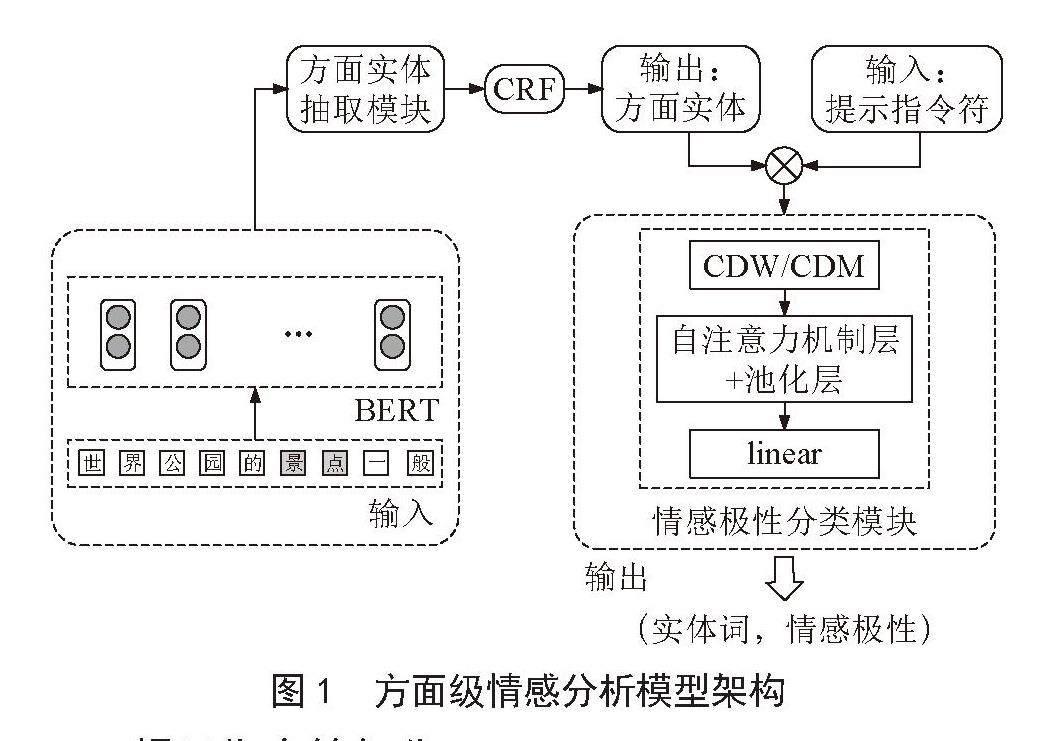
本文提出了一種新的基于深度學習和提示學習的模型,用于對旅游景點相關評論文本的句子進行方面詞抽取,將實體識別任務的結果生成提示指令符,再和原始句子一起輸入到情感分類任務中,由此達到增強對句子中方面實體的關注度的目的。如圖1所示,該模型分為三部分,分別是實體抽取部分、提示指令符部分和方面詞情感分類部分。
2.1? 提示指令符部分
BERT模型并沒有直接處理標簽序列的機制,它僅根據上下文預測每個標記的標簽。在這種情況下,BERT模型可能會在生成標簽時忽略標簽之間的順序關系。因此本文加入CRF特征[4]提高模型在BIO標注數據上的準確性,CRF模型可以利用實體之間的依賴關系和上下文信息,以全局一致性的方式進行標注,從而得到更準確地實體識別結果,避免了“I”出現在“E”之前的情況,同時也可以更好地處理BIO標注中的順序關系,并提高標注的準確性。
提示指令符的設計需要根據本文的具體任務和數據集的特點來確定,同時還需要注意避免提示指令符過于復雜或冗長,以免對模型的學習和泛化產生負面影響[5]。在本文中,模板任務是凸顯句子中的實體詞,生成提示模板:“實體是_。”。生成的文本將根據填充的內容來組成,同時保留了特定的結構。離散提示模板可以在一定程度上控制生成文本的主題等,同時減少模型輸出的不確定性。這對于本文需要確保實體詞和情感屬性的一致性的場景非常有用。在本文實體識別和情感屬性識別的聯合訓練中,加入提示指令符[6]可以引導模型更好地學習實體和屬性之間的關聯,本文的創新之處在于將實體識別的輸出結果作為特定的提示之令符,用于指導模型生成特定實體對應的情感屬性。圖2是用于ATSC子任務的Instruct ABSA模型[7]示例,輸入由指令提示和原句子組成,輸出標簽是對應方面的情感極性。
通過構建提示指令可以引導模型提取出更多信息,為了使BERT預訓練模型能夠獲取語義信息,本文設計了“aspect is [MASK]”樣式的提示指令模板作為輸出,構建了由具體詞匯組成的離散模板,適用于小樣本的文本情感分類任務,使用預先定義的模板將需要預測的每個輸入進行轉換,轉換成一個新的token序列。每個token表示一個文本單元或[MASK]等補充符號。式(1)可以將原始句子x和提示指令模板Tn結合在一起得到新的輸入 :
(1)
在一個句子中,可能存在多個實體和情感屬性,而它們之間的關系可能是復雜的。還可以為模型提供一些先驗知識和指導信息,幫助模型更好地學習實體和屬性之間的關聯信息。通過加入提示指令符,可以明確指定當前要處理的實體和屬性,從而減少歧義,增強模型對于兩個子任務的專注度和準確性,避免模糊的任務定義和錯誤的關聯,提高模型的學習效率和準確性。
2.2? 情感分類部分
給定訓練樣本中第i個句子,用? 表示訓練樣本中第i個句子的情感極性,其中m表示句子中方面實體項的個數,從文本中識別和提取到方面實體后,要對與每個方面相關的情感極性進行分類。基于指令的訓練會將明確的提示指令符合并到訓練數據中,如圖1所示,將實體識別任務的輸出和定義好的提示指令符模板輸入情感分類模型,即指示了模型要預測的方面實體,模型從這些指令中學習。
本文模型使用BERT編碼器對語義向量進行語義特征編碼,采用全連接層和自注意力機制對情感向量進行情感特征編碼,并計算聯合損失函數。通過兩種文本表示方法:CDW(Contextual Document Window)和CDM(Contextual Document Matrix),捕捉文本的語義信息,以便更好地表示文本內容。對于圖4中的示例句子,首先定義一個上下文窗口,這是一個固定大小的窗口,包含目標詞語及其周圍的詞語,假設目標詞語的向量表示為vtarget,上下文窗口中的詞語向量分別為v1、v2、v3(按照順序)。那么,CDW方法生成的文本向量可以表示為:
(2)
其中,n表示上下文窗口中詞語的數量。這個公式表示將目標詞語與上下文詞語的向量進行加權平均,得到最終的文本向量表示。CDM文本表示方法通過考慮文本之間的語義相似性和相關性,生成文本的表示矩陣。假設有兩個文檔矩陣A和B,其中A表示文檔A的詞向量矩陣,B表示文檔B的詞向量矩陣。可以使用余弦相似度來計算文檔之間的語義相似度,如式(3)所示:
(3)
其中,A和B分別表示文檔A和文檔B的詞向量矩陣。然后,通過設置一個閾值θ,判斷文檔之間是否相關,根據相關性判斷,可以生成一個文本表示矩陣,其中矩陣元素為1表示相關,為0表示不相關。由于BERT模型[8]沒有顯式的位置信息,可以添加自注意力機制幫助模型關注重要的上下文信息,從而更好地捕捉實體和情感屬性之間的語義關系[9]。假設全連接層的輸出為gt,其中包含了編碼后的情感信息,自注意力機制允許模型關注不同詞語之間的關系,并為每個詞語分配一個注意力權重,以反映其重要性。通過tanh激活函數,計算每個gt的隱含狀態ut,隱含狀態將用于計算每個詞語的自注意力權重,使用自注意力算式(4)計算每個詞語的注意力權重αt:
(4)
其中,ut表示詞語t的隱含狀態,αw表示權重參數,n表示詞語的總數。通過將每個詞語的自注意力權重αt與全連接網絡的輸出gt進行加權求和,得到特征向量E。這個特征向量E將捕捉詞語之間的上下文語義關系,能夠更好地捕捉情感信息的關聯性,提高情感分析的效果。
3? 結果分析
3.1? 實驗數據集
本文在公開數據集SemEval2014 Task4 [10]和基于社交媒體的北京旅游景區評論數據集上分別進行對比實驗。SemEval2014 Task4數據集包含Restaurant、Laptop和Car幾個領域的評論數據,其中原始的樣本格式由評論語句、語句中的方面實體詞以及對應的情感類別數值組成,經過預處理后,剔除了異常數據且將原始文本合并成單行格式。基于社交媒體的北京旅游景區評論數據集(PTS)是針對中文旅游方面的評論文本,但此數據集是對網頁文本的簡單爬取,無法直接用于實驗,因此對5 000條數據進行重復和無效文本剔除,對其中的表情符號、評價標簽、顏文字、時間信息、標點符號等內容進行數據清洗,得到的數據集按照8:1:1的比例隨機切分為訓練集、驗證集和測試集。訓練過程中,需要提前試驗以確定Epoch的大小,以免造成分類準確率低或者過擬合的現象。因此本文選取了10%的訓練集數據進行Epoch實驗,并記錄了每次訓練的Accuracy值和損失函數值,如圖3所示。
3.2? 實驗設置和評價指標
本文的實驗用的是Huggingface開源社區發布的預訓練模型,Transformer是一個通用接口,支持PyTorch框架,相當于加載預訓練模型的基座,使用Bert-Base-Chinese語言模型實現。實驗超參數如表1所示。
本文用測試集數據對模型進行評估,在前面的實驗中分別預測了實體標簽和某個實體對應的情感分類,并且計算了聯合損失,需要根據實體的預測值解析出對應的實體位置,并預測實體對應的情感分類,再跟真實實體對進行對比,計算出準確率A(Accuracy)、召回率R(Recall)和F1值(F-score)這幾個評價指標,計算式為:
(5)
(6)
(7)
其中,TP、TN分別表示預測正確的正向類別數和負向類別數;FP、FN分別表示預測錯誤的正向類別數和負向類別數;A和R分別表示精確率和召回率,P表示Precision,加上EPS這樣一個很小的值來避免分母為零的情況。
3.3? 分類模型對比實驗
為了評估本文的模型性能,本研究與幾個其他相關研究的方面級情感分析模型進行了對比實驗,表2展示了本文模型在特定旅游評論數據集上與其他預訓練模型的準確率、召回率和F1值的對比,實驗結果表明,本文模型取得了比其他模型更好的分類效果,對于旅游領域的評論數據集文本,本文模型的準確率和F1值分別達到了81.01%和80.81%,相較于Bert-LSTM [11]模型提升了4.89%和5.2%,驗證了本文提出方法的有效性。
由表2可以看出,與BERT的其他基準模型相比,本文提出的結合指令提示符的改進模型在旅游領域的數據集上取得了較好的效果,但在實驗中遇到了幾個問題:一是在初始調試階段將BERT模型中的參數“requires_grad”屬性設置為“False”,保持預訓練的BERT權重固定,可以加快訓練過程并防止模型過度擬合特定任務的有限數據。但凍結BERT模型的參數時,模型無法根據特定任務的數據進行微調和更新,這樣會限制模型適應任務特定的特征和模式,從而導致了模型性能下降。二是實驗的輸出結果差異變小,這是因為在線性層(linear層)加了一個Sigmoid函數,可以對輸出結果進行歸一化,并將輸出范圍限制在0到1之間,這樣得到較小的輸出差異意味著可以提高模型在情感分類任務上的準確性、可解釋性和置信度,使得模型的分類結果更穩定、一致且易于理解,有助于更好地應用于文本情感分析場景。總的來說,本文提出的模型在旅游評論文本數據集上取得了更好的效果,證明了此方法的可行性。
表3展示了在公開數據集SemEval2014的Restaurant領域上,本文模型與其他幾個基準模型的性能對比。由表3可以看出,單一的結合注意力機制來捕捉文本中信息的IAN模型效果一般;Bert-CNN模型結合了BERT預訓練模型和卷積神經網絡(CNN),對輸入文本進行編碼后傳遞給卷積層進行特征提取,其模型準確率有了一定的提升;針對句對任務的模型Bert-pair是對輸入進行編碼后,通過額外的任務特定層來處理,但在文本的情感分類任務上效果不如Bert-LSTM模型,Bert-LSTM模型將文本編碼信息傳遞給LSTM層,以建立上下文信息和序列建模;本文提出的模型在輸入中結合了提示指令符,模型先對句子進行方面詞抽取,將該子任務的結果作為提示指令符,再和原句子一起輸入進方面詞情感分類任務中,由此達到增強對句子中方面實體的關注度的目的,由準確率來看可以有效地說明該模型在文本情感分類任務上的性能良好。
3.4? 降采樣對比實驗
為了驗證本文模型在訓練樣本較少的旅游評論數據集上效果仍然優于其他模型,通過降采樣方法,分別取PTS數據集數量的80%(PTS0.8)、50%(PTS0.5)、20%(PTS0.2)作為降采樣后的數據集進行對比。降采樣后的標簽分布與原數據集保持一致,選擇分類模型對比實驗中效果較好的模型進行對比。
降采樣實驗的對比結果如表4所示。由對比結果可以看出,面對特定領域的小樣本數據,本文提出的通過構建特定領域的離散提示模板,聯合訓練兩個子任務的訓練模型準確率比Bert-LSTM模型的準確率高了2.07%,且本文的模型受數據量驟減的影響最小,分類準確率波動幅度更小,說明本文提出的方法面對旅游評論文本的使用效果最好,驗證了本文方法的有效性。
4? 結? 論
本文提出了基于預訓練模型和提示學習的方面級情感分類模型,使其更好的應用于真實應用場景,并提升模型面對多實體句子的分類性能。綜合利用提示指令符和聯合訓練技術,可以幫助模型更好地學習實體和屬性之間的關聯,從而提高方面級文本情感分析的性能。針對此應用場景下的數據集句子出現多實體屬性難以對應的問題,本文提出的融入提示指令符方法和聯合訓練框架可以幫助模型在處理屬性關系時獲得更好的表示和推理能力,達到精準提取文本中的多個實體的情感信息的目的;針對缺乏樣本和樣本不平衡問題,本文通過數據增強,可以增加少數類別的樣本數量,使得數據集中不同類別的樣本更加均衡,從而改善模型在少數類別上的性能。經實驗驗證,本文所提出的模型在文本情感分析的準確率、召回率以及F1值等評價指標上都優于其他四種方法,由此論證了本文模型的有效性。本文的主要貢獻如下:一是構建了一個新的文本情感分析的深度學習模型架構,加強了兩個子任務之間的聯系,比較所提出的模型與其他四種情感分析模型的性能。二是模型針對句子中包含多個方面實體的文本情感分析具有可用性,可以為不同城市的旅游機構和企業提供啟發性的建議,使其能夠抓住機遇快速發展。三是為未來的研究提供了一些方向。
參考文獻:
[1] HU M Q,LIU B. Mining and Summarizing Customer Reviews [C]//Proceedings of the tenth ACM SIGKDD international conference on Knowledge discovery and data mining.Seattle:Association for Computing Machinery,2004:168-177.
[2] THET T T,NA J C,KHOO C S G. Aspect-Based Sentiment Analysis of Movie Reviews on Discussion Boards.Journal of Information Science,2010,36(6),823-848.
[3] LIU B. Sentiment Analysis and Opinion Mining [M].[S.I.]:Morgan & Claypool Publishers,2012.
[4] 劉斐,文中,吳藝.基于BERT-BILSTM-CRF模型的電力行業事故文本智能分析 [J].中國安全生產科學技術,2023,19(1):209-215.
[5] 王昱婷,劉一伊,張儒清,等.基于提示學習的文本隱式情感分類 [J].山西大學學報:自然科學版,2023,46(3):509-517.
[6] 張心月,劉蓉,魏馳宇,等.融合提示知識的方面級情感分析方法 [J].計算機應用,2023,43(9):2753-2759.
[7] WANG Y Z,MISHRA S,ALIPOORMOLABASHI P. Super-NaturalInstructions: Generalization via Declarative Instructions on 1600+ NLP Tasks [J/OL].arXiv:2204.07705 [cs.CL].[2023-07-20].https://doi.org/10.48550/arXiv.2204.07705.
[8] ZHANG J W,QI H. Data Mining and Spatial Analysis of Social Media Text Based on the BERT-CNN Model to Achieve Situational Awareness: a Case Study of COVID-19 [J].Journal of Geodesy and Geoinformation Science,2022,5(2):38-48.
[9] 高佳希,黃海燕.基于TF-IDF和多頭注意力Transformer模型的文本情感分析 [J].華東理工大學學報:自然科學版,2024,50(1):129-136.
[10] dIGO999. SemEval-2014 Task 4: Aspect Based Sentiment Analysis [EB/OL].[2023-07-21].https://github.com/Diego999/SemEval-2014-Task-4-ABSA.
[11] SONG Y W,WANG J H,LIANG Z W,et al. Utilizing BERT Intermediate Layers for Aspect Based Sentiment Analysis and Natural Language Inference [J].arXiv:2002.04815 [cs.CL].[2023-07-26].https://arxiv.org/abs/2002.04815.
作者簡介:謝宇欣(1999—),女,漢族,湖北襄陽人,碩士研究生在讀,研究方向:自然語言處理;通訊作者:肖克晶(1991—),女,漢族,河南信陽人,講師,博士研究生,研究方向:自然語言處理。
