基于雙注意力機制的可見光-紅外行人重識別
2024-06-17 13:41:57魏克銘韓星宇王輝范自柱
華東交通大學學報 2024年2期
魏克銘 韓星宇 王輝 范自柱


摘要:【目的】由于可見光圖像和紅外圖像之間的巨大模態差異,導致可見光-紅外行人重識別是一項非常具有挑戰性的圖像檢索問題。【方法】為了進一步減小兩種模態之間的差異,重點關注行人信息,提出一種基于雙注意力機制的網絡結構用于可見光-紅外行人重識別。一方面通過雙注意力機制挖掘不同尺度的行人空間信息和增強局部特征的通道交互能力,另一方面利用全局分支和局部分支,學習多粒度的特征信息,使不同粒度信息可以相互補充,形成一個更具辨別性的特征。【結果】在兩個公共數據集上的實驗結果表明,該方法相較于基線有明顯的提升,在RegDB數據集和SYSU-MM01數據集上均表現出理想的性能。【結論】該方法可為以后解決可見光-紅外行人重識別的模態差異問題提供有效的參考。
關鍵詞:可見光-紅外行人重識別;注意力機制;緩解模態差異
中圖分類號:TP391;[U-9] 文獻標志碼:A
文章編號:1005-0523(2024)02-0087-08
Visible-Infrared Person Re-Identification Based
on Dual Attention Mechanism
Wei Keming1, Han Xingyu2, Wang Hui2, Fan Zizhu1,2
(1. School of Science, East China Jiaotong University, Nanchang 330013, China; 2. Key Laboratory of Advanced Control
and Optimization of Jiangxi Province, East China Jiaotong University, Nanchang 330013, China)
Abstract: 【Objective】Visible-infrared person re-identification is a very challenging image retrieval problem due to the huge modal difference between visible and infrared images.【Method】In order to further reduce the difference between the two modalities and focus on pedestrian information, a network structure based on dual attention mechanism is proposed for visible-infrared person re-identification. On the one hand, through the dual attention mechanism to mine personal spatial information of different scales and enhance the channel interaction ability of local features. On the other hand, through learning multi-granular feature information through using global and local branches, different granular information can complement with each other to form a more discriminating feature. 【Result】Experimental results on two public datasets show that the proposed method has a significant improvement compared with the baseline, and shows ideal performance on both the RegDB dataset and the SYSU-MM01 dataset. 【Conclusion】The proposed method can provide an effective reference for solving the problem of modal difference of visible-infrared person re-identification in the future.
Key words: visible-infrared person re-identification; attention mechanism; mitigate modal differences
Citation format: WEI K M, HAN X Y, WANG H, et al. Visible-infrared person re-identification based on dual attention mechanism[J]. Journal of East China Jiaotong University, 2024, 41(2): 87-94.
【研究意義】行人重識別主要任務是在多個不重疊的攝像機視圖中匹配特定的人,在安全領域有著不可或缺的作用,近年來行人重識別一直受到廣泛的關注。它的挑戰主要集中在視圖、姿態、光照、遮擋、背景變化等方面,為了解決這些問題,眾多學者提取出了許多解決方法,取得不錯的效果。這些方法主要集中在單模態的可見光行人重識別問題上,但在實際應用中,往往需要捕捉不同場景下的行人圖像,特別是在夜晚光照極弱的情況下,可見光相機很難捕捉到有效的行人信息,因此可見光-紅外行人重識別就引起了眾多學者的注意。該領域主要研究可見光圖像和紅外圖像之間的跨模態度量問題,以從不同模態的圖像中匹配出相同的行人圖像,目的是克服在復雜環境下傳統行人重識別的局限性。紅外圖像相比于可見光圖像,信息量更少、視覺效果模糊、分辨率差、對比度低,巨大的模態差異,導致很難提取到有效的特征信息,常規的單模態行人重識別也不能夠發揮同等的效用。
【研究進展】不同模態間的巨大差異導致可見光-紅外行人重識別非常具有挑戰性,針對模態差異,眾多學者提出了一系列解決方法。為緩解模態差異,一些方法通過設計模態生成器[1-4],從而生成中間模態或實現模態轉換,例如Zhang等[2]提出特征級模態補償網絡,直接從其他模態的現有模態共享特征中生成缺失模態特定特征,但由于紅外到可見光變換的不穩定性,導致生成的模態難以優化,而且不可避免地會引入噪聲數據。另外一些方法采用單流、雙流或多流網絡[5-10],通過設計不同的損失函數、注意力機制等提取不同模態共享特征,例如Wu等[10]提出聯合模態和模式對齊網絡,以發現不同模態的細微差別,減輕模態差異,并且提出了一個中心聚類損失函數,進一步約束增強學習效果。然而,基于這些學習方法訓練通用的網絡模型,缺乏對特異性模態信息的關注度,導致關鍵信息丟失。
【關鍵問題】為了避免噪聲數據的影響,充分利用有價值的行人信息,減小模態間的差異,從以下幾個方面出發來解決此問題:【創新特色】首先,為了減小背景、光線等噪聲數據的影響,受到交叉注意力和空洞卷積的啟發,本文提出多尺度交叉注意力機制(multi-scale cross attention, MCA),同時利用不同尺度的空洞卷積和最大池化,擴大模塊的感受野,關注更多的邊緣信息。其次考慮到不同通道之間的信息交互和不同層次行人特征之間的差異性,本文提出局部通道交互注意力機制(part channel-interaction attention, PCA),在兼顧局部特征的同時,增強不同通道間的特征交互能力。最后,考慮到數據集規模有限,缺乏多樣性,如果僅學習全局特征,容易導致信息丟失,而不同粒度的特征可以更有效的提取行人信息,因此本文結合局部特征和全局特征,共同優化網絡模型。本文的模型在兩個公開數據集RegDB和SYSU-MM01上均取得最優的識別效果。
1 方法
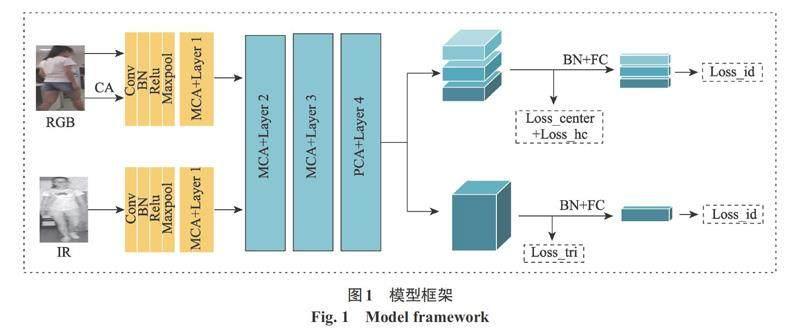
為了減小模態差異、背景噪聲影響、增強模型的魯棒性,基于隨機通道交換[9]提出了一種兼顧局部與全局特征的雙注意力機制的網絡結構用于可見光-紅外行人重識別。這一部分主要介紹網絡結構的模型框架,其整體結構如圖1所示。主要包括以下幾個部分組成:① 由ResNet50組成的雙流骨干網絡;② 多尺度交叉注意力機制(MCA);③ 局部通道交互注意力機制(PCA);④ 全局特征分支及其對應損失函數;⑤ 局部特征分支及其對應損失函數。在測試階段,使用全局特征分支的輸出結果進行預測,局部特征分支僅在訓練過程中發揮效用。
1.1 模型框架
雙流網絡是用于可見光紅外行人重識別特征提取的典型方法,而且它的有效性在眾多文獻中得到了有力的證明。本文利用在ImageNet上預訓練的ResNet50作為骨干網絡提取特征,為保證不同模態特征的特異性,網絡在第二個殘差塊前不共享參數;為避免噪聲的影響,本文同時設計兩個注意力模塊,注意力模塊在保持特征圖身份識別能力的同時,減輕模態差異以及背景噪聲的影響。其次,為了同時獲得全局特征和局部特征,學習到細微的、具有鑒別性的特征,本文結合PCB[11]特征分塊機制,旨在學習不同行人圖像之間的細微差別,以達到更好的效果。
1.2 多尺度交叉注意力機制(MCA)
受到交叉注意力和多尺度特征融合[12]的啟發,本文提出了MCA。考慮到最大池化可以加強網絡對顯著性區域的關注度,去除背景冗余信息,但容易丟失空間分辨率,因此引入空洞卷積彌補池化的不足。同時考慮到利用不同尺度最大池化和空洞卷積可以擴大感受野,關注行人的邊緣特征,獲取多尺度的上下文信息,從而增強像素級的表征能力。具體流程如圖2左側所示,圖2右側展示了MCA中最大池化模塊和空洞卷積模塊的具體結構。
給定特征[x∈RC×W×H,]該模塊首先在[x]上應用兩個具有[1×1]濾波器的卷積層,分別生成兩個特征映射[Q]和[K],其中[Q,K∈RC′×W×H]。[C′]為通道數,由于降維,通道數小于C。然后[Q]和[K]分別經過一個多尺度最大池化塊,再經過[1×1]濾波器的卷積層得到[Q1]和[K1],用數學公式表示如下
[Q1=conv12(max(conv11(Q)))] (1)
[K1=conv22(max(conv21(K)))] (2)
另外給定的輸入特征[x∈RC×W×H]分別經過不同大小濾波器的空洞卷積塊得到V,而后輸入[1×1]濾波器的卷積塊和平均池化塊得到[V1]為
[V1=avg(conv(Dilated(x)))] (3)
[Q1]和[K1]經過仿射變換后,與[V1]進行聚合變換,最終與輸入特征x求和得
[output=x+Agg(Aff(Q1,K1),V1)] (4)
式中:Aff為仿射變換;Agg為聚合變換。
1.3 局部通道交互注意力機制(PCA)
不同通道的特征圖受到的關注度理應是不相同的,且特征圖的不同層次也是如此,因此為了增強不同層次之間的通道交互能力,引入了PCA,如圖3所示。首先給定一個輸入特征[x∈RC×W×H],x在水平方向被均勻地分割成若干塊,得到[xi,i=1,2,3],然后分別經過池化和[1×1]卷積塊,進行縮放變換,隨后對拼接的特征利用正切激活函數激活,具體過程用公式表示如下
[xi′=max(relu(convi1(xi))),i=1,2,3] (5)
[xi′=tanh(avg(convi1(xi′))),i=1,2,3] (6)
[x′=concat(x1′,x2′,x3′)] (7)
[output=x+tanh(x′)] (8)
1.4 損失函數
本節主要介紹本文的框架中使用的損失函數,包括交叉熵損失、三元損失、聚類中心損失和中心三元損失。利用交叉熵損失和三元損失結合起來監督全局特征,利用交叉熵損失、聚類中心損失和中心三元損失作為局部分支的學習目標。
1) 交叉熵損失函數。交叉熵損失的目標是提取特定行人身份的信息進行分類。此方法被廣泛應用于行人重識別任務中,以促進模型對樣本進行有效的分類。在本文中,依舊采用交叉熵損失分別優化全局特征和局部特征,以捕獲每個行人不同模態的身份鑒別信息。交叉熵損失的表達式如下
[Lid=-i=1NlogeWTyixik=1DeWTkxi] (9)
式中:[Wk]為第[k]類的權重向量;[yi]為特征[xi]的真實身份標簽;N為批次大小;D為訓練集中的類數。
2) 三元損失函數。對于全局特征,利用三元損失優化不同模態下不同行人圖像的特征,它可以拉近不同模態相同身份的行人特征間的距離,擴大不同身份的行人間的距離,本文沿用Ye等[9]提出的三元損失,公式定義如下
[Ltri=i=1Pa=1K[ρ+maxxia-xip2-mini≠jxia-xjn2]+](10)
式中:K為模態數量;[P]為行人的數量;[xa]為錨點樣本;[xp]為正樣本對;[xn]為負樣本對;[ρ]為閥值參數,用以約束正負樣本間的距離。
3) 中心三元損失函數。三元損失通過錨點與所有其他樣本的比較計算損失。但由于圖像本身存在的一些噪聲,造成局部特征可能與全局特征有很大的差異,如果存在一些異常值,可能會過于嚴格地約束成對距離,三元損失將不能很好地優化類內類間距離。因此,利用中心三元損失函數優化局部特征的類內與類間距離,采用每個身份的中心作為身份代理,將錨點與所有其他樣本的比較替換為錨點中心與所有其他中心的比較,具體計算公式如下
[Lcenter=i=1P[ρ+civ-cit2-mini≠jciv-cjn2]++i=1P[ρ+cit-civ2-mini≠jcit-cjn2]++i=1P[ρ+cim-cit2-mini≠jcim-cjn2]+] (11)
式中:[civ]為可見光圖像特征的聚類中心;[cit]為紅外圖像的聚類中心;[cim]為隨機通道交換后得到的模態的聚類中心;[cin]為其他模態聚類中心。
4) 聚類中心損失函數。聚類中心損失通過懲罰不同模態分布的中心,優化不同模態的類內相似度,公式定義如下
[Lhc=i=1Pciv-cit2] (12)
式中:[civ]和[cit]分別表示可見光和紅外圖像的聚類中心。
5) 均方差損失函數。為進一步縮小相同身份不同模態的行人圖像之間的距離,簡單地應用均方差損失進行約束,公式如下
[Lmse=i=1Pxiv-xit2] (13)
式中:[P]為行人的數量。
綜上所述,損失函數分為全局損失和局部損失,全局損失函數定義如下
[Lglobal=Lid+Ltri+Lmse] (14)
局部損失函數定義如下
[Llocal=λ1Lid+λ2Lcenter+λ3Lhc] (15)
總損失函數定義如下
[L=Lglobal+αLlocal] (16)
式中:[α],[λ1],[λ2],[λ3]均為超參數,用以平衡各個損失函數之間的權重。
2 實驗
2.1 數據集
為了評估本文提出方法的有效性,在兩個公開的數據集(SYSU-MM01和RegDB)上做了充分的實驗,數據集參數如下。
SYSU-MM01數據集由4個可見光相機和2個紅外攝像機在室內和室外拍攝而成,涉及491個身份。其中訓練集包括22 258張可見光圖像和11 909張紅外圖像,涉及395個身份。測試集包含3 803張用于被檢索紅外圖像和301張用于檢索的可見光圖像,共96個身份。此數據集包含全局搜索和室內搜索兩種測試模式。
RegDB數據集由一對對齊的可見光和熱成像相機拍攝而成,包括412個身份的4 120張圖片,每個身份對應10張可見光圖像和10張熱成像圖像。此數據集被隨機劃分為兩部分,206個身份用于訓練,其余206個身份用于測試。訓練和測試均需基于數據集的隨機劃分重復進行10次實驗。
2.2 參數設置
采用雙注意力機制增強的雙流網絡,引入PCB模塊,以ResNet50作為骨干提取特征,共享后3個殘差塊的參數。采用隨機梯度下降(SGD)優化器進行訓練。訓練階段,所有的可見光和紅外圖像的大小調整為[288×144],通過隨機通道交換、擦除、翻轉增強數據集。初始學習率設置為0.1,在前10個訓練周期采用預熱策略,在第20個訓練周期衰減為0.01,在第50個訓練周期衰減為0.001。訓練周期總數設置為100。在每一個訓練批次中,隨機抽取4個行人,其中每個行人分別抽取4張可見光圖像和4張紅外圖像,共32張行人圖像。超參數的取值區間為[[0,1]],根據實驗結果的優劣,不斷微調參數值,以取得更好的實驗效果,最終總損失函數[L]的參數值在RegDB數據集上分別設置為[α=1],[λ1=1],[λ2=][0.6],[λ3=0.6];在SYSU-MM01數據集上設置[α=1],[λ1=0.5],[λ2=0.1],[λ3=2]。
2.3 對比現有方法
對比了近些年來提出的可見光-紅外行人重識別方法,表1和表2分別展示了在RegDB數據集和SYSU-MM01數據集上與不同方法比較的結果。在RegDB數據集中,可見光到紅外模式下達到了95.22%的Rank1,87.70%的mAP和74.48%的mINP;紅外到可見光模式下達到了93.67%的Rank1,86.43%的mAP和71.68%的mINP。在SYSU-MM01數據集中,全局搜索模式下達到了74.18%的Rank1,70.04%的mAP和56.97%的mINP;室內搜索模式下達到了79.69%的Rank1,83.08%的mAP和79.65%的mINP。基于所有這些評估和比較的結果,可以確認本文方法的優越性及有效性。
2.4 消融實驗
以RegDB數據集為例,評估模型的有效性。
1) 不同模塊的效果。首先從模型中刪除兩個注意力模塊、PCB模塊及其對應的損失函數,以此作為基線方法Base進行比較。P表示結合局部特征及其對應的損失函數,MCA表示采用注意力模塊MCA,PCA表示采用注意力模塊PCA。具體結果如表3所示,從中可以清晰地看出,在采用MCA時效果比Base增加2.77%,比Base+P增加1.02%;在采用PCA時效果比Base增加2.72%,比Base+P增加0.68%;同時加上兩個注意力機制時效果比Base增加4.56%,比Base+P增加1.87%。
2) 利用全局特征進行預測的有效性。為了驗證僅使用全局特征分支進行預測的效果,在此以RegDB數據集為例,對比利用全局特征和局部特征的預測結果,其中Local表示僅利用局部特征進行預測,Global表示僅利用全局特征進行預測,Global+Local表示聯合使用全局特征和局部特征進行預測。具體結果如表4所示,從中可以觀察到利用全局特征分支進行預測的效果最好。
3) 層次劃分的效果。不同的層次劃分數量決定了行人局部特征通道交互的粒度。以RegDB數據集為例,圖4展示了不同層次劃分的效果,其中橫軸Part表示分塊的數量。為了保證Part的有效性,避免出現垂直方向上特征無法均分導致信息丟失的情況,所以Part在此可以取1,2,3,6,其中[Part=1]表示不做分塊。可以觀察到[Part=3]是分層提取局部行人特征的最佳設置。
3 結論
基于注意力機制,本文提出了一種端到端可見光-紅外行人重識別模型。重點針對可見光圖像和紅外圖像之間的模態差異,提出兩種注意力機制,能夠有效的提取判別性行人特征,主要結論如下。
1) 提出多尺度交叉注意力機制MCA,結合不同尺度的最大池化和空洞卷積,擴大感受野,獲取多尺度的上下文信息。
2) 提出局部通道交互注意力機制PCA,增強了局部特征的通道交互能力,對不同背景和遮擋等噪聲具有更強的魯棒性。
3) 通過設計網絡結構,結合全局特征和局部特征,在RegDB數據集和SYSU-MM01數據集上均取得最優的效果。
參考文獻:
[1]? ?WANG G, ZHANG T, CHENG J, et al. RGB-infrared cross-modality person re-identification via joint pixel and feature alignment[C]//Seoul: Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019.
[2]? ?ZHANG Q, LAI C, LIU J, et al. Fmcnet: Feature-level modality compensation for visible-infrared person re-identification[C]//New Orleans: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022.
[3]? ?LI D, WEI X, HONG X, et al. Infrared-visible cross-modal person re-identification with an X modality[C]//New York: Proceedings of the AAAI Conference on Artificial Intelligence, 2020.
[4]? ?ZHANG Y, YAN Y, LU Y, et al. Towards a unified middle modality learning for visible-infrared person re-identification[C]//Chengdu: Proceedings of the 29th ACM International Conference on Multimedia, 2021.
[5]? ?WU A, ZHENG W S, GONG S, et al. RGB-IR person re-identification by cross-modality similarity preservation[J]. International Journal of Computer Vision, 2020, 128: 1765-1785.
[6]? ?HAO Y, WANG N, LI J, et al. HSME: Hypersphere manifold embedding for visible thermal person re-identification[C]//Honolulu: Proceedings of the AAAI Conference on Artificial Intelligence, 2019.
[7]? ?YE M, SHEN J B, CRANDALL D J, et al. Dynamic dual-attentive aggregation learning for visible-infrared person re-identification[C]//Glasgow: European Conference on Computer Vision - ECCV 2020, 2020.
[8]? ?YE M, SHEN J B, LIN G, et al. Deep learning for person re-identification: A survey and outlook[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021, 44(6): 2872-2893.
[9]? ?YE M, RUAN W, DU B, et al. Channel augmented joint learning for visible-infrared recognition[C]//Montreal: Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021.
[10] WU Q, DAI P, CHEN J, et al. Discover cross-modality nuances for visible-infrared person re-identification[C]//Nashville: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021.
[11] SUN Y, ZHENG L, YANG Y, et al. Beyond part models: Person retrieval with refined part pooling[C]//Munich: Proceedings of the European Conference on Computer Vision (ECCV), 2018.
[12] 張泓,范自柱,石林瑞,等. 一種基于多尺度特征融合的人頭計數檢測方法研究[J]. 華東交通大學學報,2021,38(2): 115-121.
ZHANG H, FAN Z Z, SHI L R, et al. A head detection method based on multi-scale feature fusion[J]. Journal of East China Jiaotong University,2021,38(2): 115-121.
[13] HAO X, ZHAO S, YE M, et al. Cross-modality person re-identification via modality confusion and center aggregation[C]//Montreal: Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021.
[14] ZHANG L Y, DU G D, LIU F, et al. Global-local multiple granularity learning for cross-modality visible-infrared person reidentification[J]. IEEE Transactions on Neural Networks and Learning Systems, 2021: 34138719.
[15] HUANG Z, LIU J, LI L, et al. Modality-adaptive mixup and invariant decomposition for RGB-infrared person re-identification[C]//Vancouver: Proceedings of the AAAI Conference on Artificial Intelligence, 2022.
[16] CHEN C, YE M, QI M, et al. Structure-aware positional? transformer for visible-infrared person re-identification[J]. IEEE Transactions on Image Processing, 2022, 31: 2352-2364.
[17] JIANG K, ZHANG T, LIU X, et al. Cross-modality transformer for visible-infrared person re-identification[C]//Tel-Aviv: European Conference on Computer Vision, 2022.
[18] LIU J, SUN Y, ZHU F, et al. Learning memory-augmented unidirectional metrics for cross-modality person re-identification[C]//New Orleans: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022.
第一作者:魏克銘(1998—),男,碩士研究生,研究方向為深度學習、模式識別。E-mail: wkmqyr@163.com。
通信作者:范自柱(1975—),男,博士,教授,博士生導師,研究方向為模式識別、機器學習。E-mail: zzfan3@163.com。
