
基于Hadoop和Spark的可擴展性化工類大數據分析系統設計
2021-08-09 19:52:27尹旭熙
粘接 2021年6期
摘 要:針對易制毒化學品數據的海量增長問題,如何對這些數據進行分析,進而為易制毒化學品交易提供參考,是當前思考的重點。對此基于易制毒化學品海量增長的數據,結合Hadoop和Spark各自的優缺點,提出一種基于Hadoop+Spark的易制毒化學品數據分析系統。為實現該系統,首先采用Hadoop+Spark的框架對系統進行搭建;將系統功能模塊分為數據分析模塊、ETL模塊、可視化模塊3個主要模塊,并對上述功能模塊進行詳細設計與實現;提出用于易制毒化學品價格預測的保序回歸模型。最后搭建集群服務器和系統運行環境,運行上述預測模型,得到價格預測的誤差值較小,能較準確預測易制毒化學品價格。
關鍵詞:Hadoop框架;易制毒化學品;大數據分析;保序回歸模型
中圖分類號:TP311.13 文獻標識碼:A 文章編號:1001-5922(2021)06-0081-03
Abstract:In view of the massive growth of precursor chemicals data, how to analyze these data and provide reference for precursor chemicals trading is the focus of current thinking. Based on the huge growth data of precursor chemicals, combined with the advantages and disadvantages of Hadoop and Spark, a data analysis system of precursor chemicals based on Hadoop + Spark is proposed. In order to realize the system, Hadoop + Spark framework is used to build the system; the system function module is divided into three main modules: data analysis module, ETL module and visualization module, and the above functional modules are designed and implemented in detail; the ordinal regression model for price prediction of precursor chemicals is proposed. Finally, the cluster server and system operating environment are built, and the above prediction model is run. The error value of price prediction is small, which can accurately predict the price of precursor chemicals.
Key words:Hadoop framework; precursor chemicals; big data analysis; ordinal regression model
要想對易制毒化學品交易過程進行多角度、全方位的監控,就必須對相關數據進行實時分析處理,包括實時采集、數據流緩存、數據處理等環節,可是,現有研究主要關注于數據采集和數據處理等工作,反而忽略了數據清洗、數據緩存、數據布局等內容,這在一定程度上影響了實時數據的分析處理效率及效果。對此,一是基于Hadoop平臺進行實時數據的分析處理。在實操中,利用HDFS系統進行數據儲存,利用Map Reduce工具對實時數據進行快速處理,這為數據流的高效處置提供了技術支持。但HDFS對于實時數據流的適應性差,Map Reduce在分析實時數據流的過程中可能出現數據丟失、分析延遲等問題,導致Hadoop系統對于實時數據的處理效能不佳。二是構建統一的云計算平臺,它集成了Hadoop和Spark的應用優勢,即Hadoop能夠進行數據批量操作,Spark善于進行數據收集。因此,本研究結合兩種并行處理框架的優勢,對海量的化工類交易數據進行處理。
1 系統整體架構設計
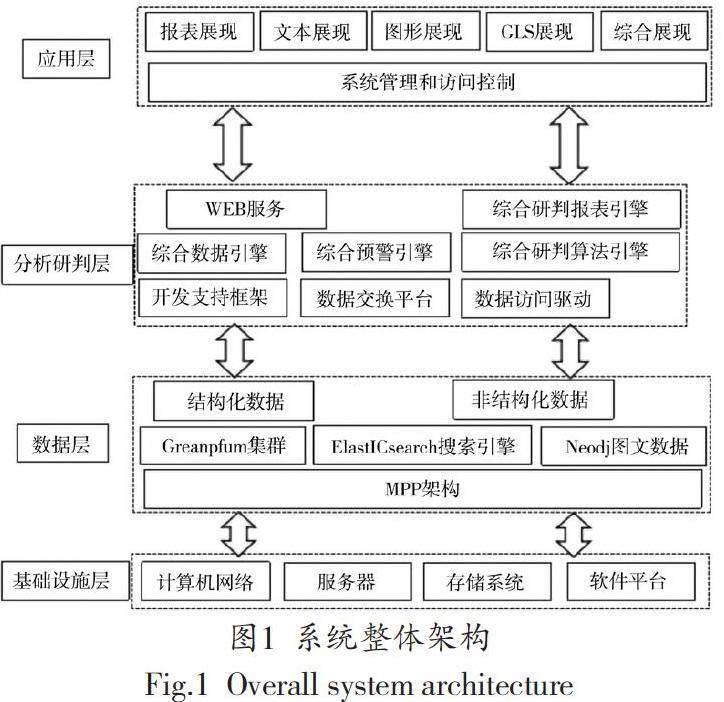
本文系統選用Spark和HBase框架,引用Flume、Kafka等技術進行數據傳輸,能夠對易制毒化學品交易數據進行采集及分析,并利用可視化工具來展示數據分析結果。系統整體架構展示,如圖1所示。
2 系統功能模塊設計
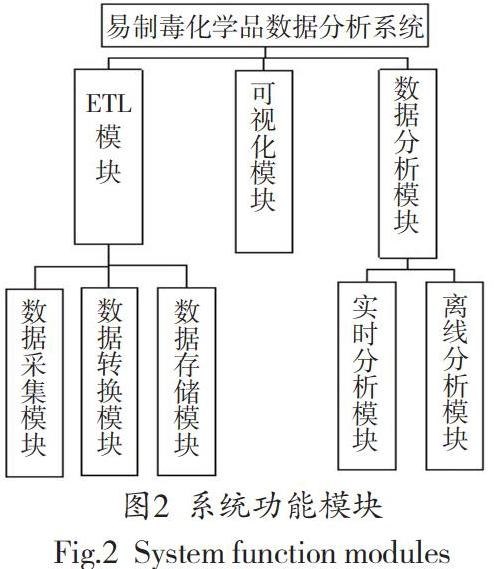
本文開發的易制毒化學品數據分析系統包含數據分析模塊,ETL模塊,可視化模塊,等3個功能模塊,這3個功能能夠對易制毒化學品交易數據進行提取、存儲及分析,從而為用戶提供信息支持,包括化學品價格走勢、化學品交易現狀等。具體如圖2所示。
在圖2的模塊中,ETL模塊是由數據采集子模塊、數據轉換子模塊、數據存儲子模塊構成的,它整合了Spark Streaming、Kafka、Flume等多個組件,圍繞用戶的業務需求,利用Spark Streaming組件對交易數據進行篩選、轉化等處理,最后將處理結果轉存至HBase內。數據分析模塊是由離線分析模塊和實時分析模塊構成的,前者從HBase中提取出歷史交易數據,然后利用Spark ML對其進行模型訓練,最終實現了價格預測的功能;后者遵循面向場景的原則,對ETL模塊的處理數據進行更深層次的數據分析。
3 功能模塊詳細設計
3.1 ETL模塊設計
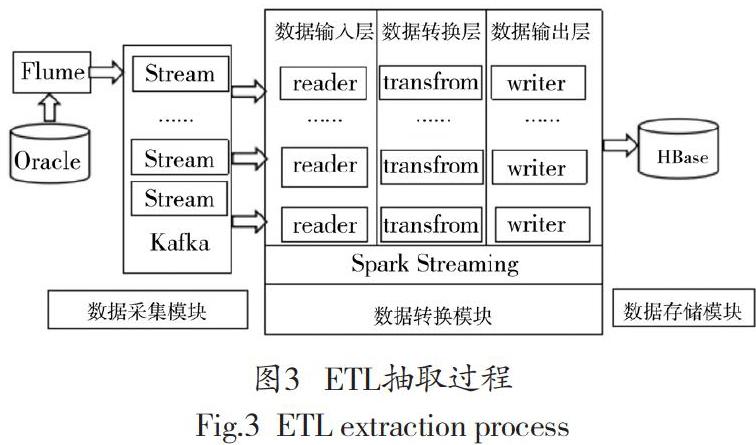
易制毒化學品數據分析系統不僅要處理傳統事務性數據,而且對接于多種類型的數據源,在系統運作過程中面向大量的數據流。另外,出于現實應用的考慮,用戶對于ETL模塊的數據分析速度提出了更高要求,“準實時服務”已然成為ETL模塊的設計目標。因此,將ETL模塊分為數據采集,數據轉換,數據存儲,等3個子模塊,具體技術架構如圖3所示。
在抽取過程中,由數據采集模塊對Oracle存儲的易制毒化學品交易數據進行處理,Flume與Kafka對接,Spark Streaming直接對接于Kafka。Spark內置了針對不同數據源的reader,用于對接收到的數據流進行連接和采集,然后將它們發送至數據轉換層,Spark內置了多樣化的數據轉換操作算子,尤其在Scala庫的配合下,可以實現數據清洗、數據轉換等功能。在完成數據格式轉換以后,數據輸出層內置的writer將轉換后的數據傳輸至HBase。
3.2 數據分析模塊設計
數據分析模塊的主要功能是對ETL模塊輸出的數據信息進行分析和統計,這一過程并不會影響系統整體的運算效率,也不會對系統穩定性造成干擾。因此,本文在設計中,首先設定了實時數據統計分析的時間間隔,從而為用戶提供具有時效性的當期統計結果。Spark Streaming是實時分析模塊的內核,它集成了基于Scala語言的數據清洗、統計、轉換等代碼,能夠對Kafka輸出的實時數據流進行處理分析,并將分析結果經由maven傳輸給集群服務器,相關信息被存儲于HBase內,可以為用戶提供查詢服務。具體步驟如圖4所示。
3.3 回歸預測模型構建
3.3.1 預測流程
易制毒化學品數據分析系統具備短期預測和結果展示的功能。圍繞價格預測的目標,首先調用ETL模塊數據進行訓練,然后將訓練得到的結果存儲在非結構化數據庫中,以此為后續的查詢等奠定基礎。具體預測訓練流程如圖5所示。
3.3.2 基于保序回歸的預測模型構建
保序回歸指的是對單調函數空間內給定數據的回歸分析過程,其優勢在于擬合誤差最小化。保序回歸算法是:
4 實驗驗證
4.1 環境搭建與參數設置
為驗證回歸預測算法的應用成效,通過試驗的方式進行驗證。在本次實驗中,首先采集某市在2018.03.01~2018.12.31期間的丙酮交易數據,然后按照交易時間對原始數據集進行劃分,包括3~12月、5~12月、7~12月、9~12月、10~12月、11~12月等6個批次,然后分批進行測試。另外,依據“80/20法則”,將前80%的數據集選做訓練集,將后20%的數據集充當測試集。
考慮到丙酮價格的整體走勢是遞減的,據此對保序回歸模型進行參數設定,如表1所示。
實驗步驟如表2所示。
本次實驗是在3節點的分布式Spark集群環境下進行的,集群節點配置條件如表3所示。
系統開發環境:Javal.8.0-172+Scala2.11.8+Spark2.2.0。
4.2 仿真結果
實驗結果展示如圖6所示。
根據圖6可知,相較于基于線性回歸的價格預測模型和基于邏輯回歸的價格預測模型,本文提出的基于保序回歸的價格預測模型的評估結果MSE值更小,尤其在數據集數量不足的情況下,保序回歸算法仍然能夠實現較小的均方誤差,這充分證明了本文模型的應用優勢。
5 結語
通過上述的研究,文章搭建的大數據算法能很好的運行和利用當前的易制毒化學品數據,并能較好的預測易制毒化學品的價格,從而為更好的利用這些易制毒化學品交易數據提供了參考和建議。但本研究的設計還只是初步構建,更多系統功能還有待進一步完善。
參考文獻
[1]劉昕林,鄧巍,黃萍,等.基于Hadoop和Spark的可擴展性大數據分析系統設計[J].自動化與儀器儀表,2020(03):132-136.
[2]陳彬.基于Hadoop框架的海量數據運營系統研究[J].自動化技術與應用,2020,39(03):178-181.
[3]陳家宇,胡建軍.MobiWay應用中基于Hadoop的多目標多任務調度算法[J].計算機應用與軟件,2020,37(02):240-247.
[4]韓德志,陳旭光,雷雨馨,等.基于Spark Streaming的實時數據分析系統及其應用[J]. 計算機應用,2017,37(05):1263-1269.
[5]袁泉,常偉鵬.基于Hadoop平臺的圖書推薦服務Apriori優化算法[J].現代電子技術,2019,42(01):180-182.
[6]李爽,陳瑞瑞,林楠.面向大數據挖掘的Hadoop框架K均值聚類算法[J].計算機工程與設計,2018,39(12):3734-3738.
[7]晏依,徐蘇.Hadoop環境下基于并行熵的FIUT算法挖掘[J].計算機工程與設計,2019,40(03):685-690+787.
[8]華幸成.面向大數據處理的應用性能優化方法研究[D].杭州:浙江大學,2019.
[9]尹旭熙.基于大數據分析技術的多源監控信息挖掘方法研究[J].電子設計工程,2020,28(17):52-55+60.
[10]孫嘯,李雙琴,謝銳,等.基于大數據管理架構的油氣管道數據監測分析模型[J].現代電子技術,2020,43(17):102-105.
