異策略模仿-強化學習序列推薦算法
2024-06-01 23:56:36劉珈麟賀澤宇李俊
計算機應用研究
2024年5期
劉珈麟 賀澤宇 李俊
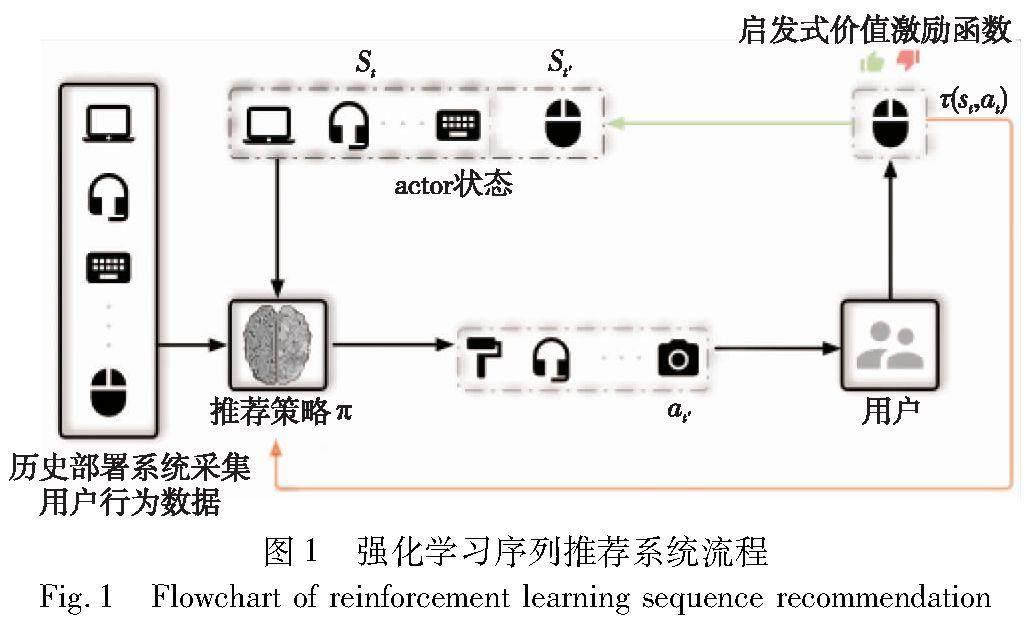
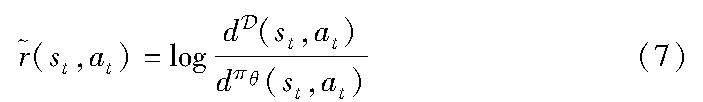
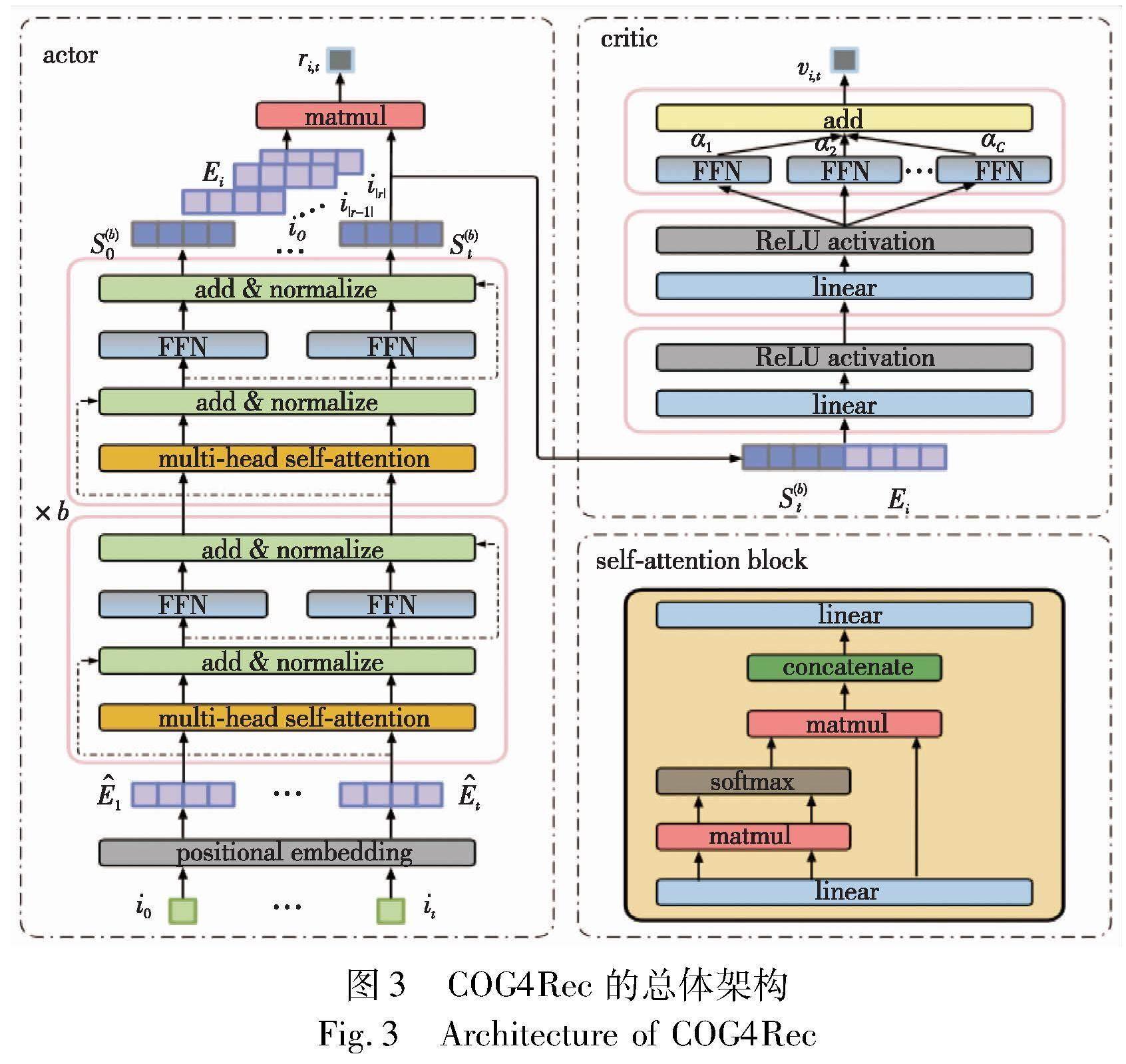
摘 要:最近,強化學習序列推薦系統受到研究者們的廣泛關注,這得益于它能更好地聯合建模用戶感興趣的內動態和外傾向。然而,現有方法面臨同策略評估方法數據利用率低,導致模型依賴大量的專家標注數據,以及啟發式價值激勵函數設計依賴反復人工調試兩個主要挑戰。因此,提出了一種新穎的異策略模仿-強化學習的序列推薦算法COG4Rec,以提高數據利用效率和實現可學習的價值函數。首先,它通過異策略方式更新分布匹配目標函數,來避免同策略更新密集在線交互限制;其次,COG4Rec采用可學習的價值函數設計,通過對數衰減狀態分布比,模仿用戶外傾向的價值激勵函數;最后,為了避免模仿學習分布漂移問題,COG4Rec通過累積衰減分布比,強化用戶行為記錄中高價值軌跡片段重組推薦策略。一系列基準數據集上的性能對比實驗和消融實驗結果表明:COG4Rec比自回歸模型提升了17.60%,它比啟發式強化學習方法提升了3.25%。這證明了所提模型結構和優化算法的有效性。這也證明可學習的價值函數是可行的,并且異策略方式能有效提高數據利用效率。
關鍵詞:異策略評估; 模仿學習; 逆強化學習; 序列推薦
中圖分類號:TP391 文獻標志碼:A?文章編號:1001-3695(2024)05-010-1349-07
doi:10.19734/j.issn.1001-3695.2023.10.0447
Off-policy imitation-reinforcement learning for sequential recommendation
Abstract:Recently, reinforcement learning sequence recommender systems have received widespread attention because they can better model the internal dynamics and external tendencies of user interests. However, existing methods face two major challenges: low utilization of same-strategy evaluation data causes the model to rely on a large amount of expert annotation data and heuristic value incentive functions rely on costly repeated manual debugging. This paper proposed a new hetero-strategic imitation-reinforcement learning method to improve data utilization efficiency and achieve a learnable value function. Firstly, it updated the distribution matching objective function through different strategies to avoid the intensive online interaction limitations of same-strategy updates. Secondly, COG4Rec adopted a learnable value function design and imitated the value incentive function of outdoor tendencies through the logarithmic decay state distribution ratio. Finally, in order to avoid the problem of imitation learning distribution drift, COG4Rec strengthened the recommendation strategy for recombining high-value trajectory segments in user behavior records through the cumulative attenuation distribution ratio. The results of performance comparison experiments and ablation experiments on a series of benchmark data sets show that COG4Rec is 17.60% better than the autoregressive model and 3.25% better than the heuristic reinforcement learning method. This proves the effectiveness of the proposed COG4Rec model structure and optimization algorithm. This also proves that the design of a learnable value function is feasible, and the heterogeneous strategy approach can effectively improve data utilization efficiency.
Key words:off-policy evaluation; imitation learning; inverse reinforcement learning; sequential recommendation
0 引言
推薦系統對探索如何感知用戶真實興趣和解決信息爆炸問題具有重要意義[1]。在推薦任務中,用戶與系統的交互過程可以被表示為一個動態序列,該序列包含了用戶的反饋信息。……
登錄APP查看全文
