基于聯合編碼的煤礦綜采設備知識圖譜構建
2024-05-27 01:24:48韓一搏董立紅葉鷗
工礦自動化 2024年4期
韓一搏 董立紅 葉鷗

文章編號:1671?251X(2024)04?0084?10 ?DOI:10.13272/j.issn.1671-251x.2023100009
摘要:利用知識圖譜技術進行數據管理可實現對煤礦綜采設備的有效表示,以便獲取具有深度挖掘價值的信息。煤礦綜采設備數據不均衡、某些類別設備實體較少等問題影響實體識別精度。針對上述問題,提出了一種基于聯合編碼的煤礦綜采設備知識圖譜構建方法。首先構建綜采設備本體模型,確定概念及關系。然后設計實體識別模型:利用 Token Embedding、Position Embedding、Sentence Embedding 和 Task Embedding 4層 Embedding 結構與 Transformer?Encoder 進行煤礦綜采設備數據編碼,提取詞語間的依賴關系及上下文信息特征;引入中文漢字字庫,利用?Word2vec 模型進行編碼,提取字形間的語義規則,解決煤礦綜采設備數據中生僻字問題;使用?GRU 模型對綜采設備數據和字庫編碼后的字符向量進行聯合編碼,融合向量特征;利用?Lattice?LSTM 模型進行字符解碼,獲取實體識別結果。最后利用圖數據庫技術,將抽取的知識以圖譜的形式進行存儲和組織,完成知識圖譜構建。在煤礦綜采設備數據集上進行實驗驗證,結果表明該方法對綜采設備實體的識別準確率較現有方法提高了1.26%以上,在一定程度上緩解了在少量樣本情況下構建煤礦綜采設備知識圖譜時因數據較少導致的精度不足問題。
關鍵詞:煤礦綜采設備;知識圖譜;本體模型;聯合編碼;實體識別
中圖分類號:TD67 ?文獻標志碼:A
Construction of knowledge graph for fully mechanized coal mining equipment based on joint coding
HAN Yibo, DONG Lihong, YE Ou
(College of Computer Science and Technology, Xi'an University of Science and Technology, Xi'an 710054, China)
Abstract: Using knowledge graph technology for data management can achieve effective representation of fully mechanized coal mining equipment. The information with deep mining value can be obtained. The imbalanced data of fully mechanized coal mining equipment and the limited number of entities in certain categories of equipment affect the precision of entity recognition models. In order to solve the above problems, a knowledge graph construction method for fully mechanized coal mining equipment based on joint coding is proposed. Firstly, the fully mechanized coal mining equipment ontology model is constructed, determining the concepts and relationships. Secondly, the entity recognition model is designed. The model uses Token Embedding, Position Embedding, Sentence Embedding, and Task Embedding 4-layer Embedding structures and Transformer Encoder to encode fully mechanized coal mining equipment data, extract dependency relationships and contextual information features between words. The model introduces a Chinese character library, using the Word2vec model for encoding, extracting semantic rules between characters, and solving the problem of rare characters in fully mechanized coal mining equipment data. The model uses the GRU model to jointly encode the data of fully mechanized coal mining equipment and the character vectors encoded in the font library, and fuse vector features. The model uses the Lattice-LSTM model for character decoding to obtain entity recognitionresults. Finally, the model uses graph database technology to store and organize extracted knowledge in the form of graphs, completing the construction of knowledge graphs. Experimental verification is conducted on the dataset of fully mechanized coal mining equipment. The results show that the method improves the recognition accuracy of fully mechanized coal mining equipment entities by more than 1.26% compared to existing methods, which to some extent alleviates the low accuracy problem caused by insufficient data when constructing a knowledge graph of fully mechanized coal mining equipment in a small sample situation.
Key words: fully mechanized coal mining equipment; knowledge graph; ontology model; joint coding;entity recognition
0引言
我國煤礦行業正處于從自動化向信息化、智能化的轉型升級階段[1]。隨著煤礦信息化程度不斷提高,機電設備數量不斷增加,設備之間的關系變得愈加復雜。由于沒有相對完整的煤礦綜采設備知識管理體系,用戶無法在短時間內了解和整理有效的煤礦綜采設備知識,導致大量具有深度挖掘價值的知識難以得到有效利用。因此,煤礦綜采設備知識整合及知識管理成為煤礦數據挖掘與分析領域的重點和熱點研究內容。
目前,國內外學者針對煤礦領域知識管理問題的研究主要分為2類:①基于大數據技術的數據管理。曹現剛等[2]搭建了基于 Hadoop 的煤礦企業大數據管理平臺,實現了數據采集、多元數據融合、分布式存儲、大數據挖掘分析等一體化,提高了煤礦機電設備運行狀態數據的管理能力。高晶等[3]通過搭建適合 BP 數據集的 Hadoop 大數據框架,對企業內部已有多系統信息資源進行整理、清洗、分析、歸納,從不同角度挖掘信息之間的規律、模式等隱含知識。 QiaoWanguan 等[4]從特征分析的角度研究煤礦安全大數據模型,設計了 CMSBD(Coal Mine Safety Big Data,煤礦安全大數據)的研究范式和技術框架,以更好地管理煤礦安全數據。該類方法解決了煤礦數據管理效率低的問題,但缺少對煤礦知識的有效表示,難以獲取具有深度挖掘價值的信息。②基于知識圖譜的數據整合及挖掘分析。吳雪峰等[5]通過定義概念、關系等構建知識本體,并基于深度學習模型識別實體,在煤礦領域知識圖譜構建方面進行了初步嘗試。劉鵬等[6]構建了煤礦安全知識圖譜,并引入基于 Spark 的并行樸素貝葉斯算法的智能查詢方法,首次利用知識圖譜進行場景應用。李哲等[7]通過定義四元組本體模型,并基于?BiLSTM (Bidirectional Long?Short Term Memory,雙向長短期記憶)+CRF(Conditional Random Field,條件隨機場)模型進行知識抽取,構建了煤礦機電設備事故知識圖譜。Zhang Guozhen 等[8]通過分析煤礦設備維修知識體系的特點,構建了煤礦設備維修本體模型,并提出了?BERT(Bidirectional Encoder Representations from Transformers,雙向編碼器表示)?BiLSTM?CRF 實體識別模型,提高了實體識別精度,為知識抽取引入新的研究思路。?I. Osipova 等[9]通過分析地質、水文、地球物理和采礦等知識,提出了關于煤與瓦斯突出過程的知識結構,通過構建本體較好地解決了煤礦安全生產中的瓦斯閃爆問題。該類方法可以實現對信息的深度挖掘,但由于煤礦綜采設備類型繁雜,缺乏對綜采設備維護知識的表示能力,較難形成相對完整的綜采設備維護知識管理體系,不利于綜采設備維護知識的關聯和挖掘,導致煤礦綜采設備維護知識較難充分利用。
針對上述問題,同時考慮煤礦綜采設備數據不均衡、某些類別設備實體較少等問題,引入中文漢字字庫,將其與綜采設備數據進行特征融合,設計了一種基于聯合編碼的煤礦綜采設備知識圖譜構建方法,并通過煤礦綜采設備數據集驗證了該方法的有效性。
1煤礦綜采設備知識圖譜構建總體思路
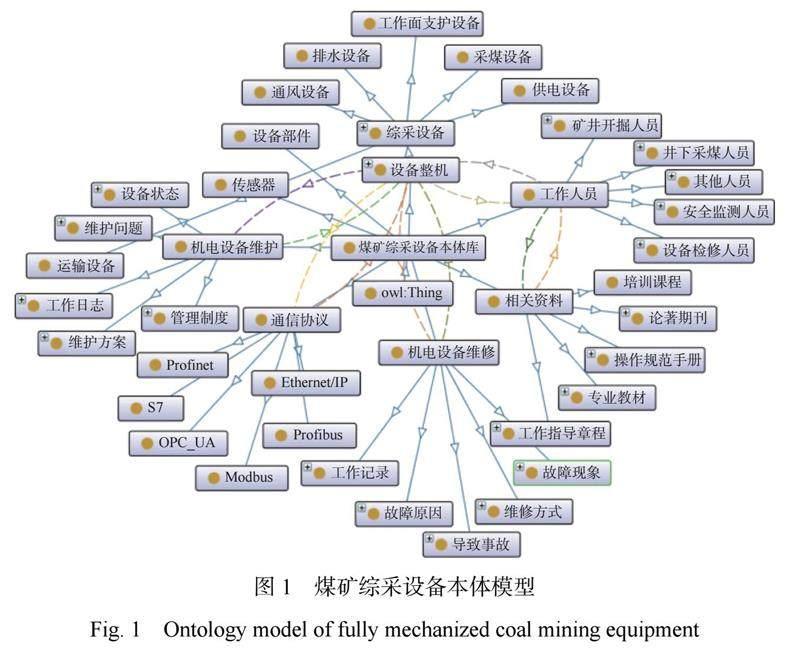
2012年 Google 首次提出“知識圖譜”概念,旨在通過利用“實體、關系和屬性”闡述客觀世界的概念、實體、事件[10]。其目的是建立一個龐大的結構化知識庫,以幫助計算機系統更好地理解和處理自然語言,并提供更智能、精確的搜索結果。知識圖譜中實體(如煤礦綜采設備、使用地點等)被表示為節點,而實體間的關系被表示為邊。每個實體可具有多個屬性來描述實體的特征。構建煤礦綜采設備知識圖譜需要對知識進行分析、歸納和標準化。本體[11]作為一種形式化的知識表示方法,用于定義領域中的概念、類別、屬性及關系,為知識圖譜提供語義框架。
本文將煤礦綜采設備核心概念分為綜采設備整機、綜采設備部件、傳感器、通信協議、設備維護、設備維修、工種、相關資料等八大類,并分析本體間的復雜關系。采用三元組本體模型Ω=
采用自頂向下和自下向上的混合方式[12]構建綜采設備知識圖譜,具體流程如圖2所示。①構建綜采設備本體模型,確定概念及關系。②基于聯合編碼識別命名實體。將收集的綜采設備數據通過 Token Embedding, Position Embedding, Sentence Embedding, Task Embedding 結構由文本轉換為連續的向量表示,并捕捉詞語之間的語義關系、位置信息、整體句子信息和任務特定信息,之后經過24層疊加的 Transformer?Encoder 捕捉詞語間的依賴關系及上下文信息。由于少量樣本訓練數據難以充分訓練模型,出現模型欠擬合問題,所以引入中文漢字字庫進行樣本擴充。考慮直接合并2份數據極易出現模型過多關注樣本中的噪聲與細節而導致模型過擬合的問題,對綜采設備數據集與字庫分別進行編碼。由于編碼生成的2種字符向量具有不同的特征分布,所以對2種字符向量進行標準化,將不同特征映射到同一尺度,并使用?GRU(Gated Recurrent Unit,門控循環單元)模型進行向量定長處理,通過橫向拼接后再次使用?GRU 模型進行特征融合。之后將融合特征向量輸入?Lattice?LSTM 進行字符解碼,完成綜采設備實體提取。③使用 Neo4j 圖數據庫進行知識存儲,實現煤礦綜采設備知識圖譜構建。
2煤礦綜采設備知識圖譜構建關鍵技術
2.1煤礦綜采設備數據預處理
盡管目前在煤礦設備管理和生產監控等系統中已存儲大量的綜采設備信息,但多源異構的綜采設備數據來源給綜采設備知識管理帶來了一定的阻礙。為了構建煤礦綜采設備知識圖譜,需在獲取綜采設備原始數據后,按照數據特性和結構化要求對數據進行預處理,步驟如下。
1)數據清洗。使用正則表達式去除煤礦綜采設備原始數據中的特殊字符和標點符號,例如:相關資料文本中“《煤礦安全規程》明確規定,井下人員必須隨身攜帶自救器”清洗為“煤礦安全規程明確規定井下人員必須隨身攜帶自救器”;檢測并去除設備維護文本中“井下電纜的連接要求如下”與“井下電纜的連接,必須符合下列要求”清洗為“井下電纜的連接要求如下”。
2)中文分詞。煤礦環境中設備數據通常呈現復雜多樣的特征,而中文語言的特別之處在于其缺乏明確的單詞邊界,使得詞與詞之間沒有空格或其他明顯的分隔符,對理解《煤礦采掘機械與設備》等非結構化文本數據的語義特征提出了更高的要求。對此,需通過分詞將連續的綜采設備數據文本語料切分成離散的詞語,從而使模型能更好理解句子的語義特征。本文采用 jieba 中文分詞組件對綜采設備數據文本語料進行分詞。通過對綜采設備數據文本語料進行細致分析,可以更好地把握設備功能、運行狀態、維護需求及可能存在的潛在風險。《煤礦采掘機械與設備》中截取的部分語料分詞效果見表1。
3)語料標注。煤礦領域目前尚缺乏公開或標準的可用于訓練的已標注數據集。考慮到煤礦環境中設備整機等數據往往具有復雜性和多樣性,為了確保訓練模型的有效性和泛化性,需通過人工標注方式為這些數據添加語義標簽。常見的標注標簽一般分為 BIO[12]和 BIOES[13]2種,本文依照 BIOES 五元標注法構建標簽表 D ={B; I; E; S ; O}。其中 B為實體起始字;I為實體中間字;E為實體結尾字;S 為單個字所構成的實體;O為除實體以外的字。從《綜采技術手冊(上下)》截選的部分語料標注結果見表2。
通過上述預處理操作,為煤礦綜采設備本體庫構建奠定了堅實的基礎,并為綜采設備知識存儲關聯映射提供了可靠的數據支持。
2.2基于聯合編碼的字符編碼器設計
2.2.1煤礦綜采設備數據編碼
Embedding 是一種常用的自然語言處理技術,用于將離散的符號(如詞語、句子、段落)映射為連續的向量表示。它通過將符號與向量空間中的點相對應,將離散的符號轉換為實數值向量。其目標是將符號的語義信息編碼到向量表示中,使得具有相似語義的符號在向量空間中更加靠近,從而為計算機模型提供更好的語義理解能力。通過 Embedding 技術可將文本數據轉換為計算機可以處理的形式,從而應用于各種自然語言處理任務。
本文使用4層 Embedding 從不同層面對煤礦綜采設備數據文本語料進行編碼。其中 Token Embedding 主要用于將煤礦綜采設備語料中的離散詞語轉換為連續的向量空間,捕捉詞語之間的語義相似性,并為每個詞提供一個基礎表示。Position Embedding 用于編碼詞語在句子或文本中的位置信息,使模型可以區分不同位置上的詞語,并捕捉詞語之間的相對距離。 Sentence Embedding 通過將詞嵌入或詞級別的表示進行組合,捕捉句子的語義和上下文信息。 Task Embedding 用于引入任務相關的嵌入向量,將模型的注意力和重點放在當前任務上,使模型學習任務特定的信息和模式。
Transformer?Encoder [14]是一種基于自注意力機制的神經網絡模型,主要將輸入序列中的每個元素映射為其向量表示,同時保留元素之間的語義和位置信息。?Transformer?Encoder 單元結構如圖3所示。通過多層?Transformer?Encoder 堆疊,模型可以提取輸入序列中的語義和結構信息,生成更豐富的向量表示。本文采用24層?Encoder,每層中有1個?Attention,頭數為12,詞向量維度為768。
煤礦綜采設備數據編碼過程如下。
1)Token Embedding。設煤礦綜采設備文本序列為x ={x1; x2;···; xn },其中n為輸入序列長度,xi 為序列中第 i個字,i=1, 2, ···, n 。通過 Token Embedding 將 xi 映射為實數向量ei 。
ei = Qtoken one_hot(xi ) ?(1)
式中:Qtoken 為固定大小的詞嵌入矩陣;one_hot(·)為?one?hot 編碼函數。
2)Position Embedding。通過 Position Embedding 為每個字 xi 的位置編碼固定大小的向量表示 pi。
式中:k為維度索引;l 為字符嵌入的維度。
3)Sentence Embedding。通過 Sentence Embedding 對 Token Embedding 和 Position Embedding 輸出進行加權平均計算,得到整個句子的向量表示 s。
式中:W1,W2分別為 Token Embedding,Position Embedding 的權重矩陣。
4)Transformer?Encoder 編碼。通過梯度下降學習到?Task Embedding 并輸入?Transformer?Encoder 中,計算輸入序列與其他位置的注意力分數αi。
式中:d 為注意力機制的維度;qi 為經過線性變換后得到的查詢向量。
對αi 進行加權平均,計算相應位置的輸入向量 zi。
式中:u 為詞向量個數;vj 為第j個詞向量線性變換結果。5)全連接計算。通過前饋神經網絡對每個位置的輸出向量 zi 進行全連接,得到最終向量維度為768的輸出向量 Ti。
式中:ReLU(·)為激活函數;w1; w2為訓練權重;b1, b2為偏置。
2.2.2基于 Word2vec模型的字庫編碼
由于煤礦數據零散,獲取相關研究數據較為困難。本文引入字庫數據以擴充數據量,使實體識別模型得到充分訓練。將原數據與字庫數據融合訓練易出現模型過多關注樣本中噪聲與細節而導致模型過擬合的問題,因此,將原數據與字庫數據分開編碼,最后對2種字符向量進行聯合編碼,達到最佳編碼效果。
Word2vec 模型是由輸入層、隱藏層和輸出層組成的神經網絡[16],能夠得到表示語義的詞向量。按照預測對象的不同,Word2vec 一般可以使用2種模型訓練向量:①以中心詞來預測上下文的?Skip? Gram 模型。②以上下文預測中心詞的?Continues Bag of Words模型。本文采用?Skip?Gram 模型,其由前饋神經網絡模型改進而來,結構如圖4所示。
本文采用的字庫輸入層 X與隱藏層 H之間的權重矩陣WVXN是需要通過訓練學習的參數,V為詞匯表大小,N為隱藏層神經元數。輸出的詞向量為 N X V維WN(、)XV 。
隱藏層節點輸入由輸入層加權求和計算得到。由于輸入為?one?hot 向量,所以只有輸入向量中的非0元素才能在計算后產生隱藏層的輸入。對隱藏層的對應節點加權求和,得到輸出層的輸出。最終得到向量維度為300的字庫字符向量。
2.2.3基于 GRU 的聯合編碼
因 Encoder模塊和 Word2vec模型訓練出的2個字符向量具有不同的維度和表示方式,進行后續解碼任務時需合并2種不同的向量,作為解碼任務的輸入。在進行拼接時需要確保2個向量的維度一致。本文基于 GRU 結構進行聯合編碼,使向量維度統一,以獲取2種編碼的字符表示。由于2種字符向量具有不同的特征分布,在進行聯合編碼前需進行特征規范化。歸一化和標準化是常用的特征規范化方式,其中歸一化會將特征縮放到一個較小范圍內而導致信息損失,因此選用標準化方式進行特征規范化。
根據下式將2種字符向量的特征值縮放到均值為0、標準差為1的正態分布中。
式中:Z'為標準化的字符向量特征值;Z為字符向量特征值;?為特征值的均值;ξ為特征值的標準差。
標準化的優點是可以處理不同特征的取值范圍不同的情況,同時可將特征值映射到同一尺度上,使不同特征對模型的貢獻權重更加平衡。本文將字庫的字符向量維度映射至768,與煤礦綜采設備原始數據字符向量維度保持一致。
GRU 是一種改進的 RNN(Recurrent Neural Network,循環神經網絡)單元,可以解決傳統 RNN 中的梯度消失和梯度爆炸問題,并具有較強的記憶能力[17]。GRU 引入門控機制,通過門控單元來控制信息的流動。其具有更新門和重置門2個門控單元。
當輸入序列為{y1;y2;···;yT }(T 為當前時刻),隱藏狀態為{h1; h2;···; hT }時,計算 GRU 的重置門:
式中:σ(·)為?sigmoid 激活函數;Wr 為重置門的權重矩陣;[hT?1;yT ]表示將前一時刻隱藏狀態?hT?1和當前時刻的輸入yT 進行拼接。
更新門為
式中Wz 為更新門的權重矩陣。
候選隱藏狀態為
式中:W為候選隱藏狀態的權重矩陣;⊙為矩陣元素相乘符號。
則更新的隱藏狀態為
在聯合編碼時,先用 GRU 對標準化的向量進行
定長處理并進行橫向拼接,再通過 GRU 對序列數據進行處理,融合關鍵特征并生成聯合編碼表示,為后續任務提供更豐富的特征表示。
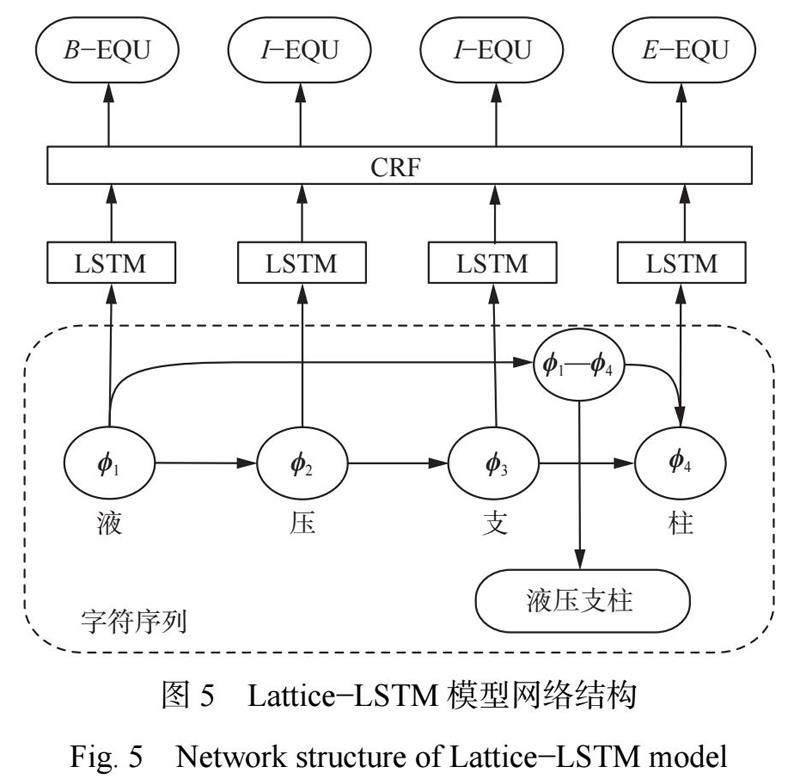
2.3 Lattice?LSTM 解碼器設計
Lattice?LSTM 模型能夠充分利用單詞和詞序信息,在字的基礎上融入詞語的編碼信息[17]。其網絡結構如圖5所示。?Lattice?LSTM 模型主干仍是?LSTM?CRF。與傳統?LSTM 模型不同,Lattice?LSTM 模型根據事先構造的詞庫表選取所需的前向詞匯信息融入字符信息中。
將?GRU 模型輸出的字符序列作為?Lattice?LSTM 模型輸入序列{φ1;φ2;···;φM },M 為字符數。句中第?J(J=1,2,…?, M)個字向量為
式中L(·)為字向量映射函數。
T 時刻 LSTM 模型隱藏狀態為
式中:Λ為 LSTM 模型訓練過程中學習到的參數;θ為 LSTM 模型的超參數。
在hT(L)STM 上使用 CRF,得到標簽序列 o 的概率為
式中:K為 CRF 模型特有參數;γ為 CRF 模型偏差。
2.4知識圖譜存儲及可視化
在知識圖譜中,常用關系型數據庫、RDF 三元組和圖數據庫存儲知識[18]。與前2種方法相比,圖數據庫只需插入節點和邊即可實現數據的高效存儲和查詢,因此采用圖數據庫 Neo4j 實現煤礦綜采設備維護知識的存儲。在 Neo4j 中,使用標簽來表示綜采設備維護知識的概念,節點和節點屬性用于表示實體及其屬性,邊和邊屬性用于表示實體之間的關系和關系屬性。基于 Neo4j 的知識存儲映射方案見表3。
利用 Cypher 語言對煤礦綜采設備知識進行存儲、查詢、更新及刪除操作。使用 CREATE 語句創建煤礦設備實體節點;使用 MATCH查詢實體節點或關系;使用 WHERE 進行條件設置。存儲部分結果如圖6所示。
3實驗及結果分析
3.1數據集建立
為了驗證本文模型在少量樣本命名識別任務中的有效性,對收集的《煤礦機電設備(第3版)》《煤礦采掘機械與設備》《綜采技術手冊》和百科網站中相關數據及字庫進行預處理,經過數據清洗、中文分詞和語料標注后,得到煤礦綜采設備領域數據集。數據集規模見表4。該數據集共有8種不同的實體類別,包含設備整機(EQU)、部件(PART)、通信協議(COM)等。字庫采用中國國家標準簡體中文字符集,共包含6620個簡體漢字、148個漢字偏旁部首。
3.2實驗設置
實驗在 CentOS7操作系統、Intel(R)Xeon(R) Silver 4210 CPU@2.20 GHz 處理器、NVIDIA GeForce PTX 2080Ti(11 GiB)GPU 處理器、python3.8環境下進行。在該實驗環境下,Word2vec 模型使用默認參數訓練,其余各模型參數設置見表5。
3.3評價指標
采用準確率 P、召回率 R 及 F1值作為評價指標。 P 衡量模型的精確性,R 衡量模型的覆蓋能力,F1分數為 P 與 R 的調和平均數,衡量模型的性能。
式中:λc 為預測正確的實體數;λt 為實體總數;λd 為數據集實體數。
3.4模型實驗
分別進行消融實驗及對比實驗。消融實驗中設計4種實驗方式:①將本文模型作為基準模型。②將煤礦綜采設備原始數據與字庫合并利用?Embedding 和?Transformer?Encoder 編碼(Encoder? Lattice?LSTM 模型)。③將編碼器?Lattice?LSTM 模型替換為?BiLSTM 模型(Encoder?Word2vec?GRU? BiLSTM 模型)。④將煤礦綜采設備原始數據與字
合并利用?Word2vec模型進行編碼(Word2vec? Lattice?LSTM 模型)。模型訓練結果如圖7—圖9所示。可看出在消融實驗中本文模型在訓練中精度更高,且收斂效果優于對比模型。
消融實驗結果見表6。可看出本文模型的準確率分別較?Encoder?Lattice?LSTM 模型、Encoder? Word2vec?GRU?BiLSTM 模型、Word2vec?Lattice? LSTM 模型高0.92%,4.93%,8.02%。主要原因:①合并數據會造成模型過多關注噪聲,進而影響模型精度。本文模型通過對煤礦綜采設備數據與中文漢字字庫分別編碼,減少噪聲影響。②?BiLSTM 未充分引入字形信息。本文模型采用?Lattice?LSTM 進行字形特征表示,從而提升識別精度。
為了更好地驗證本文模型的可行性及準確性,在所建數據集上對本文模型與?ALBERT?BIGRU? CRF 小樣本命名實體識別模型[19]、BERT?BiLSTM? CRF+BERT?CRF 分詞的聯合訓練模型[20]、傳統Lattice?LSTM 模型、BiLSTM?CRF [21]模型進行對比實驗,結果如圖10—圖12所示。可看出本文模型在前期的收斂速度較其他模型快,且最終收斂效果優于其他模型。
對比實驗結果見表7。可看出本文模型準確率較?ALBERT?BIGRU?CRF 模型、BERT?BiLSTM? CRF+BERT?CRF 模型、Lattice?LSTM 模型、BiLSTM? CRF 模型分別提高了1.26%,5.32%,11.88%,14.86%。主要原因:①?ALBERT?BIGRU?CRF 模型未考慮模型對于生僻字學習不充分的問題。本文模型通過引入中文漢字字庫,可充分學習生僻字,提高了命名實體識別精度。②?BERT?BiLSTM?CRF+BERT?CRF 模型未考慮在聯合訓練過程中易出現過度關注樣本噪聲與細節而導致模型過擬合的問題。本文模型通過對煤礦綜采設備數據與中文漢字字庫分別編碼,降低了對噪聲的關注度。③?Lattice?LSTM 模型與?BiLSTM?CRF 模型未考慮少樣本情況。本文模型利用聯合編碼技術,擴充模型訓練語料,提高了識別精度。
4結論
1)構建了煤礦綜采設備知識圖譜:通過定義概念、屬性和關系,建立了一個本體模型,用于表示煤礦綜采設備領域的語義關系;設計實體識別模型,對文本數據進行處理,從中提取出設備名稱、傳感器、通信協議等重要信息;利用圖數據庫技術,將抽取到的知識以圖譜的形式進行存儲和組織,完成知識圖譜構建。
2)引入字庫以擴充煤礦原始數據,設計聯合編碼器,融合原始數據和字庫的特征信息,解決了少量數據集實體識別中模型難以理解和區分生僻字的問題,提高了煤礦綜采設備實體識別精度。
3)實驗表明,本文模型對煤礦綜采設備實體識別準確率較現有模型提高了1.26%以上,提升了煤礦綜采設備知識圖譜構建的完整性。
4)針對煤礦少樣本知識圖譜構建問題,未來重點研究2個方面的內容:①少量樣本關系抽取;②利用知識推理進行少量樣本知識圖譜的知識補全。
參考文獻(References):
[1]王國法,任懷偉,馬宏偉,等.煤礦智能化基礎理論體系研究[J].智能礦山,2023,4(2):2-8.
WANG Guofa,REN Huaiwei,MA Hongwei,et al. Research on the basic theoretical system of coal mine inteliigence[J]. Journal of Intelligent Mine,2023,4(2):2-8.
[2]曹現剛,羅璇,張鑫媛,等.煤礦機電設備運行狀態大數據管理平臺設計[J].煤炭工程,2020,52(2):22-26.
CAO Xiangang,LUO Xuan,ZHANG Xinyuan,et al. Design of big data management platform for operation status of coal mine electromechanical equipment[J].Coal Engineering,2020,52(2):22-26.
[3]高晶,趙良君,呂旭陽.基于數據挖掘的煤礦安全管理大數據平臺[J].煤礦安全,2022,53(6):121-125.
GAO Jing,ZHAO Liangjun,LYU Xuyang. Coal mine safety management big data platform based on data mining[J]. Safety in Coal Mines,2022,53(6):121-125.
[4] QIAO ?Wanguan, CHEN ?Xue. Connotation, characteristics and framework of coal mine safety big data[J]. Heliyon,2022,8(11). DOI:10.1016/j. heliyon.2022.e11834.
[5]吳雪峰,趙志凱,王莉,等.煤礦巷道支護領域知識圖譜構建[J].工礦自動化,2019,45(6):42-46.
WU Xuefeng, ZHAO Zhikai, WANG Li, et al. Construction of knowledge graph of coal mine roadway support field[J]. Industry and Mine Automation,2019,45(6):42-46.
[6]劉鵬,葉帥,舒雅,等.煤礦安全知識圖譜構建及智能查詢方法研究[J].中文信息學報,2020,34(11):49-59.
LIU Peng,YE Shuai,SHU Ya,et al. Coalmine safety: knowledge graph construction and its QA approach[J]. Journal of Chinese Information Processing,2020,34(11):49-59.
[7]李哲,周斌,李文慧,等.煤礦機電設備事故知識圖譜構建及應用[J].工礦自動化,2022,48(1):109-112.
LI Zhe,ZHOU Bin,LI Wenhui,et al. Construction and application of mine electromechanical equipment accident knowledge graph[J]. Industry and Mine Automation,2022,48(1):109-112.
[8] ZHANG ?Guozhen, CAO ?Xiangang, ZHANG Mengyuan. A knowledge graph system for the maintenance of coal mine equipment[J]. Mathematical Problems in Engineering,2021,2021:1-13.
[9] OSIPOVA I,GOSPODINOVA V. Representation of the process of sudden outbursts of coal and gas using a knowledge graph[C]. E3S Web of Conferences,2020. DOI:10.1051/e3sconf/202019204022.
[10] ETZIONI O,BANKO M,SODERLAND S,et al. Open information extraction from the web[J]. Communications of the ACM,2008,51(12):68-74.
[11]施昭,曾鵬,于海斌.基于本體的制造知識建模方法及其應用[J].計算機集成制造系統,2018,24(11):2653-2664.
SHI Zhao,ZENG Peng,YU Haibin. Ontology-based modeling method for manufacturing knowledge and its application[J]. Computer Integrated Manufacturing Systems,2018,24(11):2653-2664.
[12]封紅旗,孫楊,楊森,等.基于 BERT 的中文電子病歷命名實體識別[J].計算機工程與設計,2023,44(4):1220-1227.
FENG Hongqi,SUN Yang,YANG Sen,et al. Chinese electronic medical record named entity recognition based on BERT methods[J]. Computer Engineering and Design,2023,44(4):1220-1227.
[13]蔡安江,張妍,任志剛.煤礦綜采設備故障知識圖譜構建[J].工礦自動化,2023,49(5):46-51.
CAI Anjiang, ZHANG Yan, REN Zhigang. Fault knowledge graph construction for coal mine fully mechanized mining equipment[J]. Journal of Mine Automation,2023,49(5):46-51.
[14] COLLARANA D,GALKIN M,TRAVERSO-RIBóN I, et al. Semantic data integration for knowledge graph construction at query time[C]. IEEE 11th International Conference on Semantic Computing,San Diego,2017:109-116.
[15] SUN Yu,WANG Shuohuan,LI Yukun,et al. Ernie 2.0: a continual pre-training framework for language understanding[C]. The AAAI Conference on Artificial Intelligence, New York,2019. DOI:10.1609/aaai. v34i05.6428.
[16] CHURCH K W. Word2Vec[J]. Natural Language Engineering,2017,23(1):155-162.
[17]丁辰暉,夏鴻斌,劉淵.融合知識圖譜與注意力機制的短文本分類模型[J].計算機工程,2021,47(1):94-100.
DING Chenhui,XIA Hongbin,LIU Yuan. Short text classification model combining knowledge graph and attention mechanism[J]. Computer Engineering,2021,47(1):94-100.
[18] ZHANG Yue,YANG Jie. Chinese NER using lattice LSTM[Z/OL].[2023-09-10]. https://doi.org/10.48550/ arXiv.1805.02023.
[19]宮法明,李翛然.基于 Neo4j 的海量石油領域本體數據存儲研究[J].計算機科學,2018,45(增刊1):549-554.
GONG Faming,LI Xiaoran. Research on ontology data storage of massive oil field based on Neo4j[J]. Computer Science,2018,45(S1):549-554.
[20]馬良荔,李陶圓,劉愛軍,等.基于遷移學習的小數據集命名實體識別研究[J].華中科技大學學報(自然科學版),2022,50(2):118-123.
MA Liangli,LI Taoyuan,LIU Aijun,et al. Research on named entity recognition method based on transfer learning for small data sets [J]. Journal of Huazhong University of Science and Technology(Natural Science Edition),2022,50(2):118-123.
[21]秦健,侯建新,謝怡寧,等.醫療文本的小樣本命名實體識別[J].哈爾濱理工大學學報,2021,26(4):94-101.
QIN Jian,HOU Jianxin,XIE Yining,et al. Few-shot named entity recognition for medical text [J]. Journal of Harbin University of Science and Technology,2021,26(4):94-101.
[22]于韜,張英,擁措.基于小樣本學習的藏文命名實體識別[J].計算機與現代化,2023(5):13-19.
YU Tao,ZHANG Ying,YONG T. Tibetan named entity recognition based on ?small sample learning[J]. Computer and Modernization,2023(5):13-19.
