基于YOLOv5的室內小物品識別定位關鍵算法研究
2024-05-19 14:36:42王映暉邱文惠劉廣臣
電腦知識與技術 2024年7期
王映暉 邱文惠 劉廣臣
摘要:對于盲人而言,室內尋找水杯、毛巾、遙控器等物品是日常生活中必不可少的技能。由于他們無法依靠視覺來定位和識別物品,因此必須依賴其他感官或工具來進行這項行動。針對盲人尋物困難的痛點, 因此主要研究YOLOv5與訓練個性化數據集、目標檢測技術對室內目標進行檢測和定位的理論和實現,輔以Kaldi技術進行語音交互,實現輔助視障人士智能化搜尋和識別室內物品。基于YOLOv5訓練個性化數據與特征提取,用于后期物體識別與定位提供數據支持。最后,基于YOLOv5目標檢測算法與單目測距進行目標物體的識別與定位。實驗結果表明該算法可以準確地識別和定位小物品,實現了室內導航的基本功能。
關鍵詞:YOLOv5;目標檢測;Kaldi;語音交互;單目測距
中圖分類號:TP312? ? ? ? 文獻標識碼:A
文章編號:1009-3044(2024)07-0015-03
開放科學(資源服務)標識碼(OSID)
0 引言
根據世界衛生組織2014年的統計數據,全球有2.17億人患有中度至重度視力障礙,3 600萬人失明[1]。到2025年,這個數字可能會超過5.5億。我國是全世界盲人最多的國家之一,中國盲人群體數量龐大,占世界盲人總數的18%。隨著國家經濟發展加快以及對殘障人士的關注支持力度加大,大多數盲人生活水平有大幅度提高。面對數量如此巨大的盲人群體,解決因視力障礙帶來的生活困難成了研究者共同關注的問題,然而各異的致盲原因和盲人群體的經濟水平,使得生物技術無法完全解決盲人問題。而室內小物品定位與識別導航技術大多需要在被定位物體上安裝標簽或者終端設備,在一些特殊環境下存在著一定的局限性。
針對盲人導盲輔助設備的外觀設計,基本分為三大類[2],分別是手杖類、穿戴類、移動類輔助工具,如斯坦福大學智能系統實驗室的博士后帕特里克·斯萊德(Patrick Slade) 研發的基于超聲波傳感器的增強型手杖[3]、宛處好等人[4]研發的基于地圖定位與卷積神經網絡的可穿戴智能導盲設備、李達等人[5]研制的導盲機器人。萬子樸等人[6]研究了一種基于RFID射頻識別的盲人尋物器;林會祺等人[7]研究了一種基于YOLOv3算法和超聲波測距的AI智能導盲眼鏡設計;洪毅[8]研究了一種基于紅外線傳感器、超聲波傳感器、激光雷達的電子導盲車和一種基于Unity3D的聽覺空間感知導盲系統;陳曉燕[9]研究了一種基于射頻識別技術來實現環境識別、局部導航以及通過SIM868模塊實現GPS定位且具有GPRS、GSM功能的導盲杖;吳濤[10]提出了一種基于邊緣的自動種子點深度圖像分割算法以通過自適應的邊緣檢測算法找到圖像中的物體輪廓邊緣的圖像處理技術和基于RGB-D的室內電子導盲系統研究。
本文提出YOLOv5及單目測距進行目標識別與定位,相比于以上幾種技術,YOLOv5及單目測距進行目標識別與定位具有結構簡單、適應能力強等優點,YOLOv5通過攝像頭來獲取視覺信息,可以獲取更為豐富的室內環境信息,且隨著圖像處理技術的深入發展,使得該項目具有更廣闊的發展平臺,該項目所提供的交互式信息輸入與輸出具有一定的創新性。
1 室內小物品定位與識別算法設計
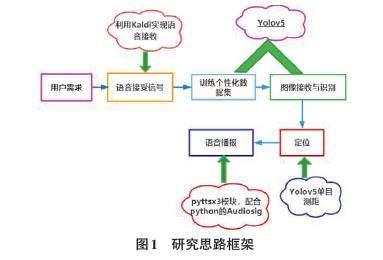
本課題圍繞在室內生活相對靜止的環境中,對多目標、小物品的識別及定位導航問題。課題內研究思路框架如圖1所示:
1.1 語音信號輸入
要想使用Kaldi對語音數據進行識別,通常需要將語音數據切割成較短的語音片段,以便于后續的特征提取和模型訓練。在Kaldi中,語音建模是語音識別的核心部分,它將特征數據進行統計建模,建立起音素、詞、句子等語音單位之間的映射關系。常用的建模方法包括隱馬爾可夫模型(HMM) 和深度神經網絡(DNN) 等。
1.2 YOLOv5模型建立
要進行模型訓練首先要進行圖像特征標定,選擇利用labelimg進行圖像特征標定,對收集好的數據集進行分類,分為訓練集與驗證集,以便進一步利用YOLOv5訓練圖像識別模型,通過對模型權重等參數的調整,進行圖像識別模型的訓練。
1.3 圖像識別與測距
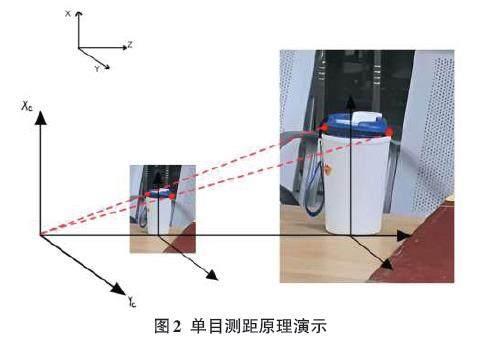
用攝像頭采集圖片,將三維場景投影到攝像機二維像平面上,主要利用小孔成像模型求解,即任意點P1 在圖像中的投影位置P1'為光心O與 P1點的連線與圖像平面的交點。F為攝像頭的焦距,C為鏡頭光心。物體發出的光經過相機的光心,然后成像于圖像傳感器或者也可以說是像平面上。如果設物體所在平面與相機平面的距離為D,目標框實際寬度P1和P2之間的寬度為W,且W是已知量,攝像頭采集到圖像內目標的P1'和P2'寬度為P,根據公式可以求得距離D。目標識別算法標出了圖像區域的范圍以及矩形框的長寬,所以圖像中的距離P可以得到。W為實際圖片中的邊長,為已知量,攝像頭焦距F也已知,故可求出距離D。已知物體尺寸的單目視覺測距是指在已知物體信息的條件下,利用攝像頭獲得的目標圖片得到深度信息[11]。
在眾多測距方式中,筆者選擇利用攝像頭進行視頻測距,與前面介紹的幾種算法相比較,視頻測距最大的不同是被動式的測距。它不需要向被測物體發射任何信號或接收信號,只需要拍攝下包含所需要目標的視頻或者圖片就可以根據需要對目標進行距離的測量。另外,由于圖像中往往包含的信息量很大,利用圖像處理技術識別并提取這些信息,能夠獲得更多的數據信息,可以提高判斷的精度。隨著圖像處理速度的提高和技術的不斷完善,視頻測距技術的應用前景也越來越廣闊[12]。
要實現單目測距[13]需要定義兩個變量:分別是焦距、待測物品高度。然后再定義一個自定義函數,用于進行單目測距。這兩個函數都有一個參數h,表示檢測到的目標高度,通過目標高度、焦距和實際高度計算目標與相機之間的距離。函數中使用英寸作為距離單位,最后將距離轉換為米作為距離單位并返回。
在圖像識別的過程中,在計算待測物品與攝像頭的距離之前,應當針對物品的置信度進行篩選,即為識別精度,如公式(1) :
[D=F×WP]? ?(1)
式中:D為目標到攝像機的距離;F為攝像機焦距;W為目標的寬度或者高度;P為目標在圖像中所占據的x方向像素(寬)或者y方向像素(高)。
確定好焦距與和待測物品高度(單位為英寸),經過轉換,最終得到單位為米的距離。
1.4 語音信號輸出
在得到攝像頭距待測物品的距離之后,通過Python的pyttsx3庫,將數據轉化為文字信息,傳遞給語音合成引擎,然后引擎將文本轉換為音頻文件,并通過操作系統的音頻設備進行播放,以此進行對距離的語音播報,并通過setProperty函數進行語速與音量的設置。
1.5 模型評價標準與回測
平均精確度(mAP) 是目標檢測中常用的評價指標之一,象征著模型的推理的準確程度。
精確度(Precision) 和召回率(Recall) 通常是一對矛盾的指標,精確度是指模型在檢測出的目標中真正正確的比例,召回率是指模型在所有正確目標中檢測到真正正確的比例。
錯誤率(Error Rate) 是指模型在目標檢測過程中的錯誤率,包括漏檢和誤檢。
定位誤差(Localization Error) 是指模型檢測到的目標位置與真實目標位置之間的誤差。通常使用IoU(Intersection over Union) 作為定位誤差的度量,IoU是指檢測到的目標框與真實目標框的交集面積與并集面積之比。
處理速度(Inference Speed) 是指模型在實際應用中的推理速度,包括模型的前向推理和后處理時間。
模型的回測(Retrospective Evaluation) 指的是在模型訓練完畢后,使用之前保留的測試集或驗證集數據對模型進行評估的過程。
當模型訓練完畢后,可以使用測試集數據對模型進行回測。通常,回測過程會使用之前保留的測試集數據輸入已經訓練好的模型中,獲取模型的檢測結果,并與真實標簽進行比較,計算模型在測試集上的性能指標,如平均精確度、精確度、召回率、錯誤率、定位誤差等。通過回測評估模型在未見過數據上的性能,可以更全面地了解模型的性能表現,并對模型進行調整和改進。
2 算法實證研究
2.1 數據集來源與預處理
本文選用自主拍攝物品圖像,利用Labelimg自主標注。
首先,需要準備包含目標檢測樣本的數據集。這個數據集應該包括目標物體(水杯、手機等)的圖像以及相應的標注信息。
其次,將整個數據集劃分為訓練集、驗證集和測試集對模型進行訓練。本文采用的文件夾劃分,將數據集中的樣本按照存儲文件夾進行劃分。比例根據數據量不同有所不同,本文按96%:2%:2%進行劃分。在進行數據集劃分時,保持訓練集和測試集的數據分布一致性。
2.2 實驗結果
對模擬結果進行分析,可以計算模型的準確率、召回率等性能指標,也可以可視化輸出結果以便觀察。如果結果不夠理想,可以通過調整模型參數或者增加數據集的大小來改進模型性能,也可以對檢測結果進行后處理,包括非極大值抑制(NMS) 等處理方式,以去除重疊的檢測框并選擇置信度較高的檢測結果。
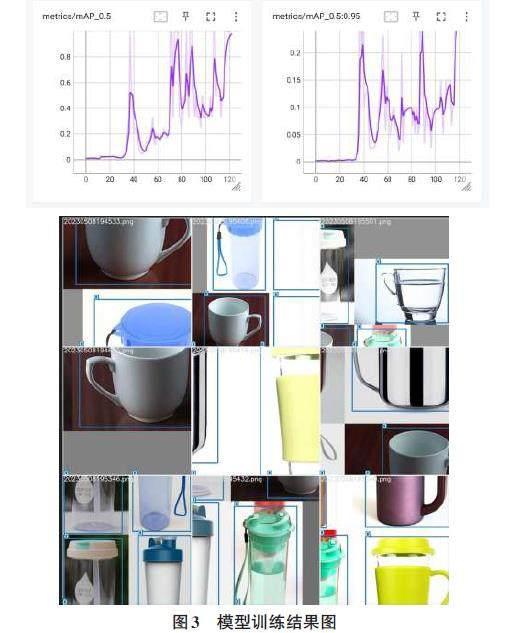
YOLOv5模型的推理速度相較于其訓練速度較快,可以在實時或近實時的應用場景中進行目標檢測和定位,在訓練完成后,檢測物品的實例如圖4所示。
3 結論
本文提出一種基于YOLOv5模型識別生活中小物品與對其進行單目測距的算法設計。由于YOLOv5深度學習模型高度的穩定性和準確性,較為適合用來進行小目標的檢測與識別。設備利用攝像頭采集圖像,YOLOv5模型配合攝像頭單目測距原理對用戶與物品之間的距離進行判斷,設備同時將距離轉化為語音信號播報出來,實現實時提醒用戶距離待尋物品的距離,從而達到在無他人協助的前提下,實時指導盲人用戶尋找室內小物品的需求,解決了傳統方式準確率低、信息滯后的問題。
參考文獻:
[1] 武曌晗,榮學文,范永.導盲機器人研究現狀綜述[J].計算機工程與應用,2020,56(14):1-13.
[2] BOURNE R R A,FLAXMAN S R,BRAITHWAITE T,et al.Magnitude,temporal trends,and projections of the global prevalence of blindness and distance and near vision impairment:a systematic review and meta-analysis[J].The Lancet Global Health,2017,5(9):e888-e897.
[3] Patrick Slade et al.Science Robotics 6[J].Issue 59,2021.
[4] 宛處好,陳雨濛,楊力川,等.一種可穿戴式智能導盲裝置:CN110623820A[P].2019-12-31.
[5] 李達,付開磊,王兵雷,等.一種導盲機器人:[P].甘肅:CN206285242U, 2017- 06-30.
[6] 萬子樸,胡宸瑞哲,周煜然,等.一種基于RFID射頻識別的盲人尋物器:CN208000669U[P].2018-10-23.
[7] 林會祺,周義濤,翁名鍵,等.AI智能導盲眼鏡的設計與實現[J].信息與電腦(理論版),2021,33(6):171-173.
[8] 洪毅.電子導盲系統研究及應用[D].廣州:廣東工業大學,2021.
[9] 陳曉燕.基于RFID、GPS實現環境識別、路徑查看的導盲杖[D].保定:河北大學,2019.
[10] 吳濤.基于RGB-D的室內電子導盲系統研究[D].西安:西安科技大學,2018.
[11] 王文勝,李繼旺,吳波,等.基于YOLOv5交通標志識別的智能車設計[J].國外電子測量技術,2021,40(10):158-164.
[12] 黎曉珊.《中國視頻社會化趨勢報告》發布[N].人民日報, 2020-11-26.
[13] 王士明.基于計算機視覺的車輛單目測距系統研究[D].天津:天津大學,2012.
【通聯編輯:唐一東】
