基于近紅外光譜技術建立棉籽蛋白質含量快速無損測定方法
2024-05-08 08:25:14黃義文周大云黃龍雨吳玉珍付守陽
中國糧油學報 2024年3期
楊 碩, 黃義文, 周大云, 黃龍雨, 吳玉珍,付守陽, 徐 青, 彭 軍,3, 匡 猛,3
(中國農業科學院棉花研究所;棉花生物育種與綜合利用全國重點實驗室1,安陽 455000)
(鄭州大學農學院2,鄭州 450000)
(三亞中國農業科學院國家南繁研究院3,三亞 572024)
我國是世界第一產棉大國,長期以來棉花的利用價值主要集中于棉纖維,而棉纖維外的其他部分則利用尚不充分。棉籽是棉花生產過程中重要的副產物,主產品棉纖維分離后,每年能得到約750萬t的棉籽[1]。棉籽處理后蛋白質質量分數30%~70%,且氨基酸組成良好,營養價值豐富,還具有防脹氣、抗氧化和提高免疫力等功能[2]。可以作為極佳的飼用蛋白或食用蛋白資源,是潛在的植物蛋白來源[5]。目前我國蛋白質資源十分短缺,豆粕作為主要的飼料蛋白源,長期依賴國外進口,嚴重影響我國的糧食安全。棉籽中含有豐富的棉籽蛋白,是重要的非糧蛋白來源,提高非糧蛋白的利用率是保障我國糧食安全的重要途經[9]。因此開發利用好棉籽蛋白資源,可以有效緩解我國蛋白源短缺問題,保障國家糧食安全。
棉籽蛋白質的含量是評價棉籽營養品質的重要指標,明確不同材料間蛋白質含量對棉花的綜合利用以及高蛋白品種選育具有重要意義,快速無損棉籽蛋白質含量檢測方法在其中發揮到重要作用。目前棉籽蛋白質含量測定主要依賴于各種化學方法,例如凱氏定氮法[10]、雙縮脲法[11]、Folin-酚試劑法[12]、紫外吸收法等[13],雖然化學方法具有檢測靈敏度高等優點,但是依然存在著如檢測時操作步驟復雜,效率低下;需依賴各種精密儀器,使用大量化學試劑,造成環境污染;檢測時不可逆,破壞種子狀態等缺點[14],已無法滿足現代棉花綜合利用產業及棉籽優質蛋白育種中快速無損檢測的需求。
近紅外光譜(NIRS)檢測技術是一種集現代電子技術、光譜分析技術、計算機技術及化學計量技術于一體的現代光譜分析檢測技術[15]。根據有機化合物中的含氫基團(C-H、N-H、O-H、S-H和P-H等)在近紅外光區域內的振動吸收特性,可定性或定量地測定樣品的化學成分,具有無損、快速、環保和低成本等特點[17,18]。近紅外光譜檢測技術在花生[19]、玉米[20]、大豆[21]、油菜[22]等經濟作物蛋白質含量檢測中已得到廣泛應用。使用傳統化學法對棉籽營養品質進行檢測成本高、效率低且具有破壞性,用于檢測的種子不能再用于繁殖,不利于育種研究需求。所以建立一種快速、精準且無損的棉籽蛋白質含量檢測方法是開展棉籽營養品質改良及棉籽綜合利用的關鍵。
雖然目前關于棉籽蛋白質含量的近紅外檢測技術已有報道[23,24],但是這些研究對象主要集中在光籽或種仁上,難以對毛籽樣品進行快速檢測,隨著棉花綜合利用產業的發展以及對棉籽優質營養品質育種的重視,亟需一種快速無損棉籽蛋白質含量檢測的方法。研究利用凱氏定氮法對187份棉籽樣品的蛋白質含量進行檢測,分別采集了供試樣品的毛籽、光籽和種仁3種不同棉籽形態的近紅外光譜信息,結合改進的偏最小二乘法 (MPLS),通過不同散射處理和數學算法組合對光譜信息及化學值進行擬合,從而建立一種適應不同棉籽形態的快速、無損、高效的棉籽蛋白質檢測技術,為棉籽綜合利用以及高品質育種提供技術支撐。
1 材料與方法
1.1 實驗材料
研究所用材料為187份棉花品種,由來自黃河流域棉區、長江流域棉區、西北內陸棉區的棉種及國外品種構成,于2020年棉花生長季種植在中國農業科學院棉花研究所東場實驗站(36°10′N, 114°38′E)。每個材料5 m行長種植,行距0.8 m,所有田間管理按當地大田生產管理進行。其中158份樣品作為定標集用于近紅外模型建立,29份樣品作為驗證集用于定標模型的外部驗證。
1.2 樣品處理
待測棉籽樣品在成熟后收取20鈴發育正常棉鈴。晾曬軋花后獲得帶有短毛絨的毛籽樣品,毛籽樣品經濃硫酸脫絨處理得到棉花光籽樣品,對光籽樣品進行手工剝殼后獲得棉仁樣品,樣品使用前皆放置在45 ℃烘箱中烘干至恒重待用。
1.3 成分測定
剝殼粉碎后得到的棉仁粉采用凱氏定氮法測定棉籽仁蛋白質含量,方法參照國家標準[25]。每個樣品采取3次重復,相對誤差控制在2%以內,采用平均值作為此樣品蛋白質含量的化學測定值。凱氏定氮使用儀器為8400KjeltecTM凱氏定氮儀。
1.4 近紅外光譜掃描
采用XDS型近紅外快速成分分析儀采集樣品的光譜信息。所有樣品掃描前均放置于溫度為25 ℃、相對濕度為60%的環境中進行水分平衡處理。掃描前將近紅外掃描儀開機預熱30 min,并需通過儀器自檢,消除外部噪聲干擾,減少實驗誤差。分別掃描毛籽、光籽和棉仁3種不同棉籽形態樣品,每份樣品重復掃描3次,掃描采用直徑為35 mm,高10 mm的圓形樣品杯。將棉籽樣品裝于圓形樣品杯中,用力壓實至于樣品杯高度齊平。光譜掃描波長范圍為400~2 500 nm,掃描頻率32 scan/s,每2 nm數據點間隔采集樣品的反射強度(R),取平均值并轉化為log(1/R),得到原始光譜數據儲存于計算機中。
1.5 近紅外光譜模型建立
利用WinISIⅢ軟件對采集的光譜數據進行分析,對原始樣品集合進行聚類分析計算,統計出與其他樣品的掃描光譜在光譜數據上有著顯著差別的樣品,剔除掉異常數據樣品。根據馬氏距離以任意一個樣品為中心,半徑為0.8以內的樣品定義為相似樣品進行剔除,一定范圍只保留一個樣品,挑選得出的這些樣品能夠代表一定范圍光譜之間的差異,保證樣品的代表性。最終獲得一組既具有相似性,又能夠代表光譜間最大差異的定標樣品集進行建模,以158份不同棉花品種作為建立模型的定標樣品。采用無散射處理 (NONE)、標準正常化處理 (SNV)、去散射處理 (DET)、標準化聯合去散射處理(SNV+DET)、標準化多元散射校正 (SMSC)、加權多元離散校正(WMSC)、反向多元離散校正(IMSC)7種光譜散射處理方法及16種數學處理方法對定標集樣品進行數據處理。光譜數據經過不同處理后得到定標模型,通過WinISIⅢ軟件給出的定標相關系數(RSQ)、交叉驗證相關系數 (1-VR)、標準誤差 (SEC) 及交叉檢驗標準誤差(SECV) 來判別定標模型對其他未知樣品的預測能力。定標模型建立后,用驗證樣品集的相關系數(R2)和預測標準誤差(SEP)對定標模型的預測性能進行評價。
1.6 數據處理
利用Microsoft Excel 2021數據分析工具對3種NIRS模型所用的定標集和驗證集的棉籽蛋白質含量進行數據分析,SPSS16.0軟件對驗證集的化學真值和預測值進行統計分析。
2 結果與分析
2.1 棉籽蛋白質含量化學值分析
所有供試材料利用凱氏定氮法測定棉籽蛋白質含量,其中定標集158份樣品的棉籽蛋白質質量分數變異范圍為35.54%~53.34%,平均值為43.65%,標準差為4.59%。驗證集29份樣品的棉籽蛋白質質量分數變異范圍為34.55%~48.25%,平均值為41.97%,標準差為3.79%。建立模型的關鍵因素是建模所用的定標集化學值是否覆蓋廣泛,一個覆蓋范圍廣的定標集能夠提高檢測模型的精度和穩定性[26]。本研究中定標集樣品的棉籽蛋白質質量分數范圍為35.54%~53.34%,覆蓋廣泛,能夠較好滿足模型構建的需求,基于此建立的近紅外光譜模型更具有普適性。此外,本研究篩選到了9份棉籽蛋白質質量分數高于50%的材料(表1),可為棉花高蛋白品質育種和相關基因發掘提供種質資源。本實驗的棉籽材料包含黃河流域、長江流域、西北內陸等三大棉區的品種資源,品種來源較為豐富,但棉籽蛋白質含量在平均值附近的材料較少,后續可以繼續補充模型樣品,提高適用性及穩定性。
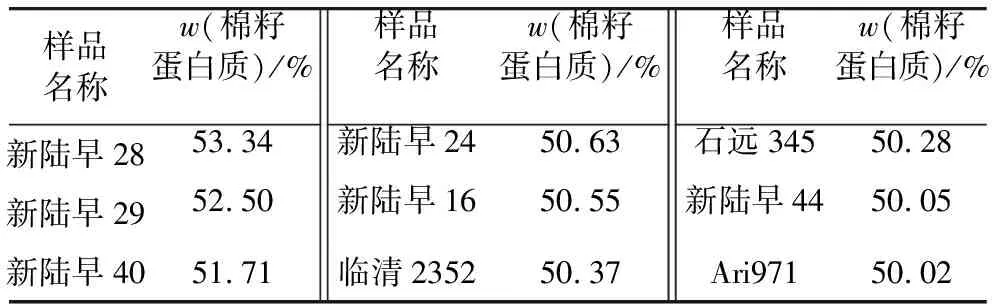
表1 供試樣品中棉籽蛋白質質量分數超過50%的樣品信息
2.2 近紅外光譜的采集
利用XDS Rapid ContentTM分析儀采集毛籽、光籽和棉仁的近紅外光譜信息,獲得了3種不同棉籽形態的原始光譜 (圖1)。3種不同棉籽形態的原始光譜在不同波長下變化趨勢一致,同一棉籽形態不同樣品的光譜信息變化趨勢也是一致的,且不完全重合,表明近紅外光譜儀設備工作狀態良好,掃描的光譜信息質量較高。進一步對3種棉籽模型的原始光譜進行一階導數處理來消除外部影響,處理后光譜 (圖2)減弱了基線偏移等影響,有效提高了光譜的精細度,更加明顯地展現了樣品所反映的光譜特征。
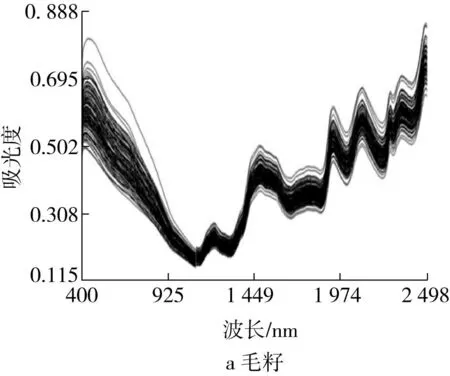
圖1 3種棉籽形態的原始光譜圖
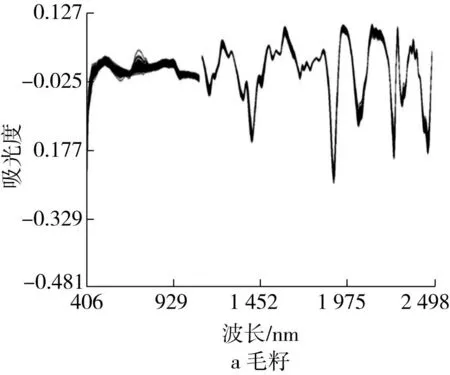
圖2 3種棉籽形態預處理后的光譜圖
2.3 不同數學處理對定標方程的影響
對光譜數據進行一些合適的處理可以消除外界因素的干擾,提高校正模型的預測性及穩定性,常用求導數學處理消除基線漂移、降低顆粒度變化的影響及提高光譜的分辨率[27]。在全光譜范圍內,對原始光譜進行標準化聯合去散射處理(SNV+DET),并獲得不同數學處理下的定標模型(表2)。未進行導數處理(0,0,1,1)時,毛籽、光籽和棉仁定標模型的定標相關系數RSQ及交叉驗證相關系數1-VR較小,且SEC和SECV誤差值均較大。對3種近紅外模型進一步利用16種數學處理,其中毛籽模型以(4,4,4,1)數學處理效果最好,最佳數學處理后的RSQ為0.955、SEC為0.957、SECV為1.388、1-VR為0.907;光籽模型以(4,6,6,1)數學處理模型效果最好,數學處理后RSQ為0.970、SEC為0.785、SECV為0.952、1-VR為0.957;棉仁模型以(1,4,4,1)數學處理模型效果最好,RSQ為0.989、SEC為0.475、SECV為0.589、1-VR為0.984。
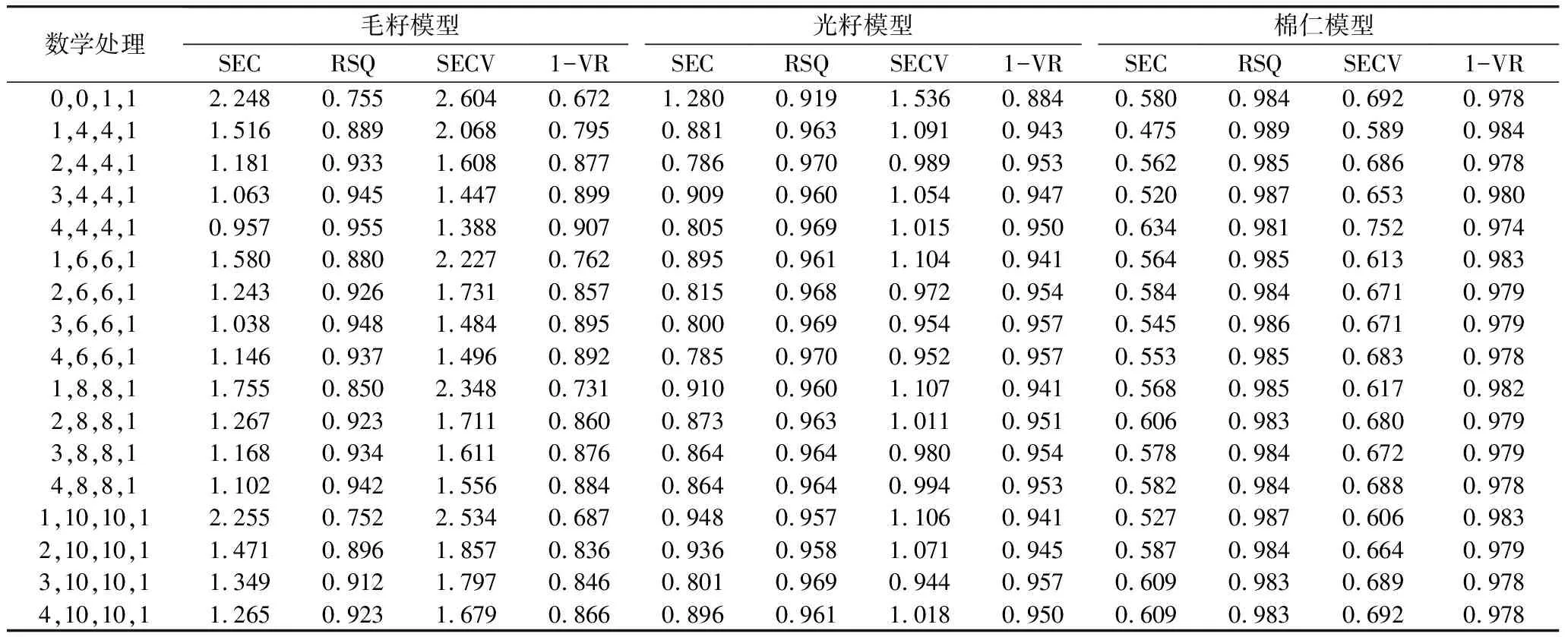
表2 不同數學處理對3種棉籽形態校正模型的影響
2.4 不同散射處理對定標方程的影響
對近紅外光譜信息進行散射校正可以糾正化學值與近紅外吸光度之間的非線性扭曲,消除光譜中的樣品誤差,提高模型質量[28]。在確定3種近紅外模型最佳數學處理的基礎上,對樣品光譜進行7種散射處理(表3)。毛籽模型中,進行IMSC處理時定標模型效果較好,RSQ為0.957、SEC為0.946、SECV為1.370、1-VR為0.909;光籽模型中,進行WMSC處理時定標模型效果較好,RSQ為0.971、SEC為0.777、SECV為0.940、1-VR為0.958;棉仁模型中,進行SNV+DET處理時定標模型效果較好,RSQ為0.989、SEC為0.475、SECV為0.589、1-VR為0.984。
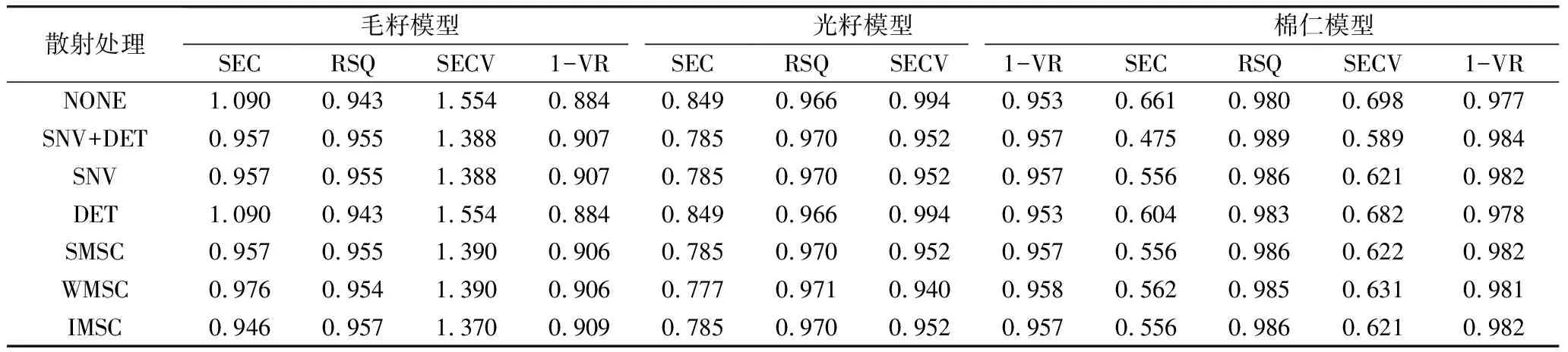
表3 不同散射處理對3種棉籽形態校正模型的影響
2.5 棉籽蛋白質含量近紅外模型的驗證
選取了建模樣品集以外的29個樣品對定標的蛋白質含量近紅外檢測模型進一步驗證。外部驗證結果如表4所示,毛籽、光籽及棉仁模型的外部驗證相關系數R2分別為0.947、0.962和0.980,SEP分別為0.885、0.787和0.530,3種模型的定標相關系數均大于0.90,相關性較高,說明預測模型質量較好。3種不同棉籽形態的近紅外檢測模型均可以快速準確地測定棉籽中的蛋白質含量,其中棉仁模型預測相對更精準。
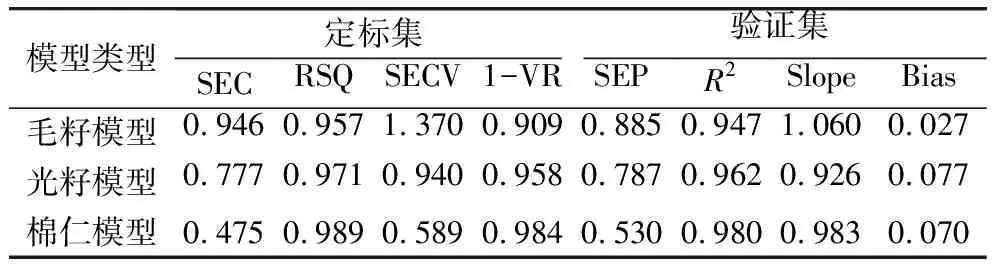
表4 3種棉籽形態下蛋白質含量測定模型的性能指標
將驗證集樣品通過凱氏定氮法測得的化學值與構建的近紅外光譜模型所得的預測值進行比較,如圖3所示。化學值與預測值的差值范圍較小,各模型的預測效果較好。化 學值及預測值差異顯著性t檢驗結果顯示差異不顯著,棉籽蛋白質含量測定的毛籽、光籽及棉仁3種近紅外光譜模型驗證集的化學值及預測值間均沒有顯著性差異,模型預測的準確度較高。
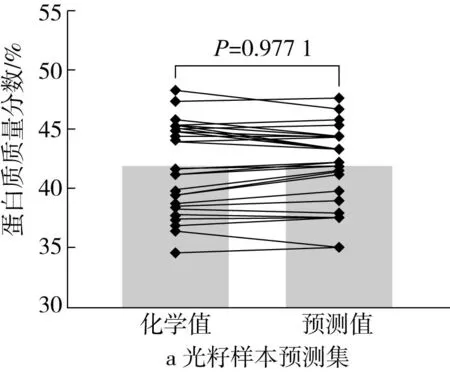
圖3 驗證集棉籽蛋白質含量的化學值及預測值
本研究通過對3種不同形態的棉籽進行近紅外光譜的采集及數據處理,建立了毛籽、光籽及棉仁3種近紅外棉籽蛋白質含量測定的定標模型,毛籽、光籽和棉仁蛋白質含量檢測模型的定標決定系數分別為0.957、0.971和0.989,說明建立的棉籽蛋白質含量檢測模型準確度高、實用性強,預測結果的準確性及可靠性與化學法相似,可以代替化學方法對棉籽中的蛋白質含量進行測定。近紅外分析模型的結果準確性與樣品、儀器及數據處理建模過程密切相關,樣品狀態對于模型的影響主要體現在樣品的粒度、顏色、光滑度和所含雜質等,樣品粒度的差異影響樣品對近紅外光的吸收和散射,進而導致光譜的變異[29]。樣品粒度大時,光學表面粗糙,對反射光譜及傳感系統造成影響,進而影響感受系統對樣品的反應,使得靈敏度及準確度出現變化[30]。在本研究中構建的3種棉籽蛋白質含量近紅外檢測模型中,毛籽、光籽和棉仁定標模型的相關系數RSQ依次遞增,由此可以表明蛋白質大部分在集中在棉仁中,棉籽所帶的棉短絨及棉籽殼影響了樣品對近紅外光的散射和吸收。
3 結論
在目前我國蛋白質資源短缺的情況下,棉籽蛋白質作為非糧蛋白的重要來源,具有廣闊的市場前景和利用價值,快速無損環保的棉籽蛋白質含量檢測方法在棉花綜合利用產業和棉籽營養品質改良過程中將發揮重要作用。本研究通過采集毛籽、光籽和種仁3種不同棉籽形態的近紅外光譜信息和測定樣品中蛋白質含量的化學值,通過不同數學處理、散射處理以及改良的偏最小二乘法構建模型,并進行外部樣品驗證,3種模型的定標相關系數均大于0.90,表明本研究建立的棉籽蛋白質含量檢測模型能夠對未知樣品進行精準預測。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
