申威26010 眾核處理器上Winograd 卷積算法的研究與優化
2024-04-29 05:35:42武錚金旭安虹
計算機研究與發展 2024年4期
關鍵詞:指令
武 錚 金 旭 安 虹
(中國科學技術大學計算機科學與技術學院 合肥 230026)
(zhengwu@mail.ustc.edu.cn)
隨著深度學習的快速發展,卷積神經網絡(convolutional neural networks,CNNs)作為其最成熟的網絡模型之一,被廣泛應用于計算機視覺[1]、語音識別[2]、自動駕駛[3]、智能醫療健康[4]等領域,以獲取更高的產業效率和更好的用戶體驗.而當前CNNs 高準確率的背后是巨大的計算代價,隨著數據集變大、網絡參數變多以及模型結構變得更加的復雜,CNNs 對運行效率的要求越來越高.對于整個CNNs 來說,90%以上的計算量都集中在卷積層中[5],這也使得眾核處理器上高性能并行卷積算法的研究成為了當前學術界和工業界的熱門話題之一.
當前最受歡迎的卷積算法有4 種[6],分別是直接卷積算法、GEMM 卷積算法、FFT 卷積算法和Winograd卷積算法.直接卷積算法是基于7 層循環做卷積,雖然實現簡單,但是因為數據局部性差而導致性能不高.GEMM 卷積算法的核心是高效的矩陣乘實現,因為許多硬件平臺上有可以直接使用的高效矩陣乘庫,所以GEMM 卷積算法成為了加速卷積計算算法中非常受歡迎的算法,該算法可以分為顯式的GEMM 卷積算法[7]和隱式的GEMM 卷積算法[8].相比于直接卷積算法,GEMM 卷積算法并不會改變整體的計算量,只是將離散的計算操作集中并連續執行,從而提高數據的局部性以實現卷積的高效執行.而FFT 卷積算法[9]和Winograd 卷積算法[10]則不同,兩者都是通過將輸入數據和卷積核數據線性變換,然后進行對應位相乘,中間結果再進行逆線性變換得到最終的輸出數據.通過這種“變換—運算—逆變換”的過程,大大降低了卷積的計算復雜度.FFT 卷積算法將直接卷積算法的計算復雜度從O(OH2×FH2)降到了O(OH2×logOH)[6],Winograd 卷積算法則進一步將卷積的計算復雜度降到了O((OH+FH-1)2)[10].
Winograd 卷積算法因其較低的計算復雜度,受到了廣泛的關注與研究.Park 等人[11]針對卷積中大量的零權重和Winograd 變換中額外的加運算限制,提出了ZeroSkip 硬件機制和AddOpt 數據重用優化,增強后的算法能夠取得51.8%的性能提升.Jia 等人[12]在?ntel Xeon Phi 上進行了任意卷積核維度的Wingorad卷積算法的優化與實現,對比最優的GPU 實現,在2D CNNs 上取得了旗鼓相當的性能,在3D CNNs 上性能更佳.武錚等人[13]利用?ntel KNL 的MCDRAM、多Memory/SNC 模式等微架構特性優化Winograd 卷積算法實現.測試VGG16,對比MKL-DNN 有2 倍多的性能加速.Mazaheri 等人[14]提出了一種基于符號計算的Winograd 卷積算法,利用元編程和自動調諧引入了能夠為GPU 自動生成高效可移植Wingorad 卷積實現的系統.Jia 等人[15]提出了一種基于MegaKernel的Winograd 卷積實現,通過映射算法將不同的計算任務分配給GPU 線程塊,并構建1 個按照依賴關系來獲取和執行任務的調度器.結果表明,與cuDNN 的2 種Winograd 卷積實現相比,基于MegaKernel 的Winograd 卷積實現有1.25 倍和1.7 倍的性能加速.Castro 等人[16]通過匯編代碼實現性能熱點部分的方法,提出了一種優化的Wingorad 卷積算法OpenCNN,相比于cuDNN 的Winograd 卷積實現,在Turing RTX 2080Ti 和Ampere RTX 3090 上分別加速了1.76 倍和1.85 倍.王慶林等人[17]在融合數據scatter 和矩陣乘數據打包的基礎上,針對飛騰多核處理器設計了一種不依賴矩陣乘庫函數的Winograd 卷積實現,使得Mxnet 中VGG16 的前向計算獲得了3.01~6.79 倍的性能加速.總的來說,近些年Winograd 卷積算法在通用處理器?ntel Xeon/Xeon Phi 和NV?D?A GPU 上得到了快速發展.與此同時,許多其他硬件平臺的Winograd卷積加速也在不斷吸引著研究人員投身其中,如國產多核處理器[17]、ARM CPU[18]、FPGA[19]等.
申威26010 眾核處理器作為世界一流超算系統“神威·太湖之光”的核心算力來源,其低功耗高性能的特性使得其在人工智能領域擁有巨大潛力,8×8的從核陣列、軟件控制的存儲器層次結構、硬件支持的寄存器通信、從核的雙流水指令運行等獨特的架構特征既給了研究人員充足的可控空間,又提出了巨大的技術挑戰.然而,該處理器上有關卷積算法的研究一直處于初級階段,僅有的一些研究工作[5,8,20]也只是針對GEMM 卷積算法在該處理器上的高效并行實現.
綜上所述,為了進一步探索申威26010 處理器上卷積算法的潛力,本文詳細討論了單精度Winograd 卷積算法在該處理器上的高性能并行設計,主要貢獻有3 點:
1)提出了一種并行卷積算法—融合Winograd卷積算法,并為該算法設計了匹配的定制矩陣乘,使得該算法避免了傳統Winograd 卷積算法對官方GEMM庫接口的依賴.
2)提出的融合Winograd 卷積算法具有可視的執行過程,能夠結合申威處理器典型架構特征進行更細粒度的計算訪存優化.同時,通過設計合并的Winograd 變換模式、DMA 雙緩沖、片上存儲的強化使用、輸出數據塊的彈性處理以及指令重排等優化方案,在提升算法性能的同時,也為未來處理器上的并行研究工作提供了有意義的參考借鑒.
3)從優化效果、卷積性能和卷積神經網絡性能3 個方面進行了實驗.實驗結果表明,在VGG 網絡模型的測試中,融合Winograd 卷積算法性能高達傳統Winograd 卷積算法性能的7.8 倍.通過對典型CNNs中常見卷積的收集測試,融合Winograd 卷積算法最高可以發揮申威處理器峰值性能的116.21%,平均可以達到93.14%.同時,通過測試對比定制矩陣乘和該處理器的通用GEMM,表明定制矩陣乘更有利于融合Winograd 卷積算法性能的發揮.
1 相關背景
1.1 Winograd 卷積算法
CNNs 主要包括卷積層、下采樣層和全連接層等,其中卷積層和下采樣層進行特征提取,全連接層在提取的最終特征上進行識別.綜合來看,卷積層是CNNs 的關鍵動力,也是整個網絡執行過程中最耗時的部分.考慮到卷積層的本質是卷積運算,因而,如何高效地設計卷積算法已經成為了一個熱門研究話題.本文選擇計算復雜度最低的Winograd 卷積算法作為研究對象,主要研究工作為該算法在國產申威26010 眾核處理器上的高效并行.
對于通常的卷積運算,可以將輸入數據標記為in[B][IC][IH][IW],表示B個IC通道的樣本,每個通道可以看作一個大小為IH×IW的輸入特征映射;將卷積核數據標記為f tl[OC][IC][FH][FW],表示OC組卷積核,每組IC個卷積核中每個卷積核的高度和寬度分別為FH和FW;將輸出數據標記為out[B][OC][OH][OW],表示B個OC通道的樣本中每個通道可以看作一個大小為OH×OW的輸出特征映射.除此之外,不同的填充大小和不同的跨步大小相互組合形成了不同的卷積形式,可以把高和寬的填充大小分別標記為padH和padW,類似地,高和寬的跨步大小則為stdH和stdW.卷積的執行過程為IC個輸入特征映射和IC個卷積核一一對應卷積,然后累加IC個局部卷積結果,從而得到一個輸出特征映射,因此一個完整的卷積需要OC×IC個卷積核.上述卷積過程可以簡化為式(1)中關于in,flt,out的張量乘法和累加.
其中 0 ≤b<B,0 ≤oc<OC,0 ≤oh<OH,0 ≤ow<OW.
Winograd 卷積起源于有限脈沖響應(finite impulse response,F?R)濾波的最小濾波算法[10],該最小濾波算法由r拍的F?R 濾波器生成m個輸出,也就是F(m,r).此時,算法運算需要 μ(F(m,r))=m+r-1次乘法操作.對于1 維的Winograd 最小濾波算法可以表示為矩陣的形式:
通過嵌套1 維的Winograd 最小濾波算法可以得到2 維的Wingorad 最小濾波算法F(m×m,r×r):
其中x表示輸入,w表示過濾器,y表示輸出;AT,G,BT表示該算法的系數矩陣;⊙表示矩陣的對應位相乘,即Hadamard 乘積.如果把x替換為卷積中的輸入數據in,w替換為卷積中的卷積核數據flt,y替換為卷積中的輸出數據out,參考文獻[10]則可以得到Winograd 卷積算法,如算法1 所示.
算法1.Winograd 卷積算法.
對于Wingorad 卷積算法,系數矩陣AT,G,BT是由m和r決定的,以F(2×2,3×3)為例,此時有
1.2 申威26010 眾核處理器
申威26010 眾核處理器[21-22]是由上海高性能集成電路設計中心自主研發的一款國產異構眾核處理器,支持64 b 自主神威指令級系統,采用分布式共享存儲和片上計算陣列.如圖1 所示,該處理器單芯片由4 個等價的核組(core group,CG)構成,核組間通過片上網絡(network on chip,NoC)互連.每個核組由1個主核(management processing element,MPE)和64 個從核(computing processing element,CPE)組成,共計260 個計算核心.每個核組私有1 個4 路128 b 的DDR3主存控制器(memory controller,MC)和1 個協議處理單元(protocol processing unit,PPU),并通過MC 直連1 塊8 GB 的DDR3 主存.
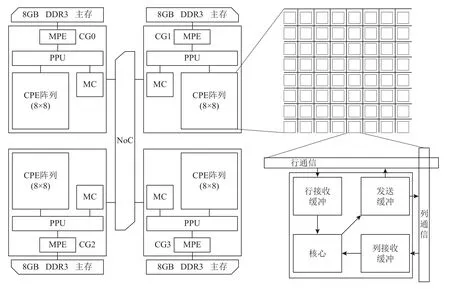
Fig.1 The architecture of ShenWei-26010 processor圖1 申威26010 的處理器架構
主核和從核的工作頻率都是1.45 GHz,兩者都支持256 b 的浮點向量乘加指令,不同的是主核有2 條浮點運算流水,從核僅有1 條浮點運算流水.同時,雙精度數據運算和單精度數據運算共用雙精度浮點運算單元的微體系結構特征,使得該處理器上浮點數據的向量長度都為4.基于此,單核組從核陣列的理論單精度浮點峰值是742.4 GFLOPS,主核是23.2 GFLOPS.其中計算性能約97%來源于從核陣列,可見在該處理器上進行性能優化最為關鍵的任務就是如何高效地組織利用從核陣列的各種資源,以充分發揮從核陣列的計算性能.每個主核擁有2 級私有緩存,包括1 個32 KB 的L1 指令緩存、1 個32 KB 的L1數據緩存以及1 個256 KB 的L2 緩存.每個從核都有1 個16 KB 的L1 指令緩存和1 個64 KB 本地設備內存(local device memory,LDM).從核陣列上的64 個從核共享一個大小為64 KB 的直接映射的L2 指令緩存.
該處理器為了盡可能緩解片外訪存的壓力,提供了2 個核心技術.一個是不同的主從核間的數據訪問方式:1)gld/gst 離散訪主存,即是從核直接對主存進行讀寫操作,這種方式的好處是簡單易用,缺陷就是速度很慢,訪存延遲高達278 個時鐘周期;2)DMA(direct memory access)批量式訪主存,即是從核先通過DMA 操作將主存數據提取到LDM,然后再對LDM 內的數據進行相關操作,整個過程的訪存延遲較低,大約29 個時鐘周期.其中,DMA 支持多種訪存模式,應用最為廣泛的有PE_MODE,ROW_MODE,BROW_MODE.另一個是寄存器通信實現同一核組內64 個從核的片上數據共享,為了有效支持這一機制,每個從核上配備了發送緩沖區、行接收緩沖區和列接收緩沖區,發送緩沖區可以緩沖6 個寄存器消息,2 個接收緩沖區可以分別緩沖4 個寄存器消息.寄存器通信機制需要注意3 點:1)通信時數據的大小固定為256 b;2)行和列都不同的2 個從核之間不能直接進行通信,需要借助同行或者同列上的從核作為中間轉折點;3)通信的過程是匿名的,當多個從核發送消息到某個從核時,該從核基于先到先得的策略接收消息.Benchmarking[23]顯示每個從核陣列上寄存器通信的帶寬在P2P 模式和廣播模式下分別可以達到637.25 GBps 和1 115.25 GBps.
申威26010 處理器每個從核支持2 條硬件流水線P0 和P1.其中,P0 支持浮點和整數的標量/向量操作,P1 支持數據遷移、比較、跳轉和整數標量操作.2條流水線共享1 個指令解碼器(instruction decoder,?D)和1 個指令隊列,每個時鐘周期?D 對隊列中前2 條指令進行檢測,當滿足3 種情況時2 條指令可以同時被加載到2 條流水中:1)2 條指令同已發射未完成的指令不存在沖突;2)2 條指令間不存在寫后讀和寫后寫沖突;3)2 條指令可以分別被2 條流水處理.不難看出,如何混合交差程序中2 種類型的指令,使P0和P1 能夠并行運行,對于該處理器性能的發揮起著重要的作用.
2 Winograd 卷積算法的并行優化
首先介紹提出的并行Winograd 卷積算法的整體設計思路.然后以F(2×2,3×3)為例,結合申威26010處理器架構特征,詳細闡述該算法的各種計算和訪存的優化方案.最后,對研究工作的通用性進行了分析,以期望能夠對其他眾核處理器上卷積研究提供有益的參考借鑒.
2.1 融合Winograd 卷積算法
如算法1 所示,Winograd 卷積算法的基本運算流程可以分為4 個部分:
現代處理器存在的普遍問題就是訪存速度無法跟上計算能力,申威26010 處理器在這方面尤為嚴重,其每字節浮點計算率高達33.84[23].而通用處理器?ntel KNL 7290 和NV?D?A Tesla V100 分別為7.05[24]和7.78[25],可見申威26010 處理器每字節的片外主存數據訪問需要匹配遠高于通用處理器的計算量.對于許多工作來說,要想充分發揮該處理器的性能,訪存受限無疑是一個巨大的挑戰.在上述Winograd 卷積算法的基本運算流程中,scatter 和gather 過程中的維度變化都是大量的離散訪存操作,這將造成難以忍受的高額訪存開銷.為了解決上述問題,設置了新的數據格式—in[IH][IW][IC][B],flt[FH][FW][IC][OC],out[OH][OW][OC][B].這些數據格式的核心便是通過直接使用卷積過程中天然的矩陣乘關系(對應矩陣乘參數M,N,K分別為OC,B,IC),在避 免scatter 和gather 過程中的維度變化造成的高額訪存開銷的同時,也省去了存儲中間數據而需要的額外內存資源.另一方面,將矩陣乘關系放到低維度中可以盡可能地提高整個算法執行過程中訪存的連續性.
如圖2(a)所示,Winograd 卷積最直接的實現方法就是在步驟3 中調用官方GEMM 庫接口,而步驟1、步驟2 和步驟4 利用從核陣列并行執行Winograd 變換和Winograd 逆變換,這是一種傳統的Winograd 卷積算法.該算法的優點是實現簡單方便,缺點是中間數據需要消耗大量片外存儲資源,極低的數據重用導致頻繁的片外訪存,高額的訪存開銷導致即便有著高性能的GEMM 庫接口也難以實現卷積的高效運行.

Fig.2 Basic framework of the fused Winograd convolution algorithm圖2 融合Wingorad 卷積算法的基本框架
為了充分挖掘Winograd 卷積算法在申威26010處理器上的潛力,本文提出了一種不依賴官方GEMM庫接口的算法.該算法能夠將原本獨立執行的Winograd變換、核心運算和Winograd 逆變換融合到一起,以充分發揮Winograd 卷積算法本身潛在的數據重用,從而盡可能降低訪存對算法執行效率的影響,將其稱之為“融合Winograd 卷積算法”.如圖2(b)所示,將原卷積數據中的最后2 維看成1 個元素,那么in,flt,out則分別可以看成IH×IW,FH×FW,OH×OW的2維數組,且三者的單元素大小分別為IC×B,IC×OC,OC×B.在融合Winograd 算法中,步驟1 是通過DMA讀取主存上r×r的卷積核數據塊fltTileM到LDM 空間中的fltTileL,再通過Winograd 變換得到 α×α的步驟2 與步驟1 類似,先是讀取 α×α的輸入數據塊inTileM到LDM 空間中的inTileL,然后通過Winograd 變換得到 α×α 的為了能夠更好地適應融合Winograd 卷積算法中核心運算的實際情況,定制了高效的矩陣乘實現,并提供了便于該算法調用的從核函數接口wgdGEMM.步驟3 則是通過一一對應的方式調用 α×α 次的wgdGEMM,從而得到α×α的步驟4 執行Winograd 逆變換得到outTileL,并DMA 寫回到主存中的對應位置outTileM.考慮整個過程中fltTileM是固定的,而inTileM和outTileM則是通過移動滑窗獲取的,所以fltTileM將會被反復使用次.為了最大化fltTileM的時間局部性,設計算法僅且只執行1 次步驟1,并將變換后的結果長期駐留在片上存儲LDM 中,直到卷積結束.步驟2、步驟3和步驟4則會隨著滑窗的移動獲取不同的inTileM和outTileM,繼而執行次得到最終的輸出數據out.
2.2 算法優化方案
后續內容將以F(2×2,3×3)為例進行詳細闡述,即m=2,r=3,α=4.在2.1 節融合Winograd 卷積算法的基礎上,結合申威26010 處理器的架構特征以及卷積運算的實際情況,進一步探索細粒度的訪存和計算的優化方案.
2.2.1 合并的Winograd 變換模式
考慮到申威26010 處理器在進行矩陣乘的計算kernel 設計時,需要進行向量加載和寄存器通信.而該處理器僅支持雙精度數據情況下單條指令完成向量加載和寄存器通信.如果是單精度數據的話,則需要分2 條指令進行,且這2 條指令之間存在寫后讀關系,將極大地降低計算kernel 的指令級并行度.因此,選擇在片上存儲LDM 中提前進行單精度數據和雙精度數據的類型轉換,從而保證送入wgdGEMM中的源數據都是雙精度數據,以最大化卷積算法的指令級并行度.為此,可以設置融合Winograd 卷積算法中inTileL,fltTileL,outTileL用于存儲LDM 上的單精度數據,則用于存儲LDM 上的雙精度數據.此時,對于輸入數據塊和卷積核數據塊的Winograd 變換,以及輸出數據塊的Winograd 逆變換可以表示為:
在F(2×2,3×3) 中,BT,G,AT為確定的常數矩陣,具體值可以參見1.1 節.此時,i nTileL的維度為4 ×4×IC×B,可以將其簡單視為 16×IC×B.相應的,維度也可以表示為 16×IC×B.那么對于輸入數據塊的Winograd 變換直觀上可以分為二次矩陣乘運算,稱之為“分離的Winograd 變換模式”,如圖3 所示.其中i=0,1,…,IC×B-1,整個過程需要 224×IC×B次浮點運算.這種Winograd 變換方式雖然簡單直觀,但是不僅浮點運算量大,而且中間數據tmp會增大片上存儲資源LDM 的開銷,如果引入向量化則更會使這種額外的LDM 開銷成倍增加.

Fig.3 Separated Winograd-transformed mode圖3 分離的Winograd 變換模式
為了解決上述問題,設計了合并的Winograd 變換模式,通過將BTinTileLB的二次矩陣乘運算合并到一次,直接獲取中每個元素關于inTileL中16個元素的線性關系,結果如圖4 所示.

Fig.4 Merged Winograd-transformed mode圖4 合并的Winograd 變換模式
通過合并的Winograd 變換模式,將浮點運算次數降低到了 48×IC×B,僅為原計算量的21.4%.同時,消除了中間數據帶來的額外LDM 開銷,使得向量化的使用不再受限制.因為申威26010 處理器的浮點向量長度為4,如果在合并的Winograd 變換模式中加入向量化,計算量將進一步降低至原計算量的5.35%.
類似地,對于fltTileL和通過合并的Winograd 變換模式,整個變換過程中計算量降為原計算量的11.43%;對于outTileL和通過合并的Winograd 變換模式,整個變換過程中計算量降為原計算量的9.52%.
2.2.2 DMA 雙緩沖
申威26010 處理器支持異步的DMA 訪存,因此有可能通過精心設計算法,從而盡可能地將DMA 訪存開銷分攤到核心運算上,緩解該處理器的片外訪存壓力,提高并行算法性能.
算法2.基于DMA 雙緩沖的融合Winograd 卷積算法.
如算法2 所示,DMA 雙緩沖的核心思想是通過預先執行1 次循環的DMA 操作,以消耗部分雙倍的LDM 片上存儲為代價,使得相鄰2 次循環間的DMA操作和核心運算能夠無依賴并行,從而掩藏掉部分訪存時間.其中,ldst表示存儲DMA 操作所需數據的LDM 空間,cmpt表示存儲當前核心運算所需數據的LDM 空間.其中fltTileL用于DMA 讀取卷積核數據塊,并將fltTileL在Winograd 變換后的數據以雙精度的形式放入考慮到Winograd 卷積中卷積核數據的反復使用,中數據將會常駐LDM 空間,直至卷積結束.同時,設置i nTileL[cmpt]和inTileL[ldst]用于雙緩沖輸入數據塊inTileM的DMA 讀取,設置outTileL[cmpt]和outTileL[ldst]用于雙緩沖輸出數據塊outTileM的DMA 寫回.相應地,分配和用于存儲當前核心運算所需要的對應雙精度數據.在算法2 中,實現了下一次inTileM的DMA讀取和上一次outTileM的DMA 寫回同當前核心運算的并行執行,理論最優情況下將會實現大約2 倍的性能提升.
2.2.3 片上存儲的強化使用
申威26010 處理器提供了用戶可控的片上存儲LDM,但是單個從核的LDM 僅有64 KB,有限的LDM容量要求研究人員不得不精心設計算法,以盡可能提高片上存儲資源的使用效率.在算法2 中,雙緩沖雖然能夠很好地實現核心運算和DMA 訪存的并行,但是也會使部分使用中的LDM 空間翻倍,同時考慮到存儲雙精度數據帶來的額外LDM 消耗,這些都給本就有限的LDM 帶來了巨大壓力.為了緩解算法2中片上存儲的使用壓力,設計了2 種優化方案:展開的LDM 強化使用和交錯的LDM 強化使用.兩者都是從算法設計的角度,通過重新組織算法的執行流程,尋找能夠節省的LDM 空間.
假設B=IC=OC,如圖5 所示,算法2 中初始使用的LDM 空間大小為580B2字節.在展開的LDM 強化使用中,將核心運算的整體展開并拆分成16 次獨立的wgdGEMM,依次標識為wgdGEMM[0]~[15].同時,結合2.2.1 節中合并的Winograd 變換模式下的線性關系,如式(5)所示.
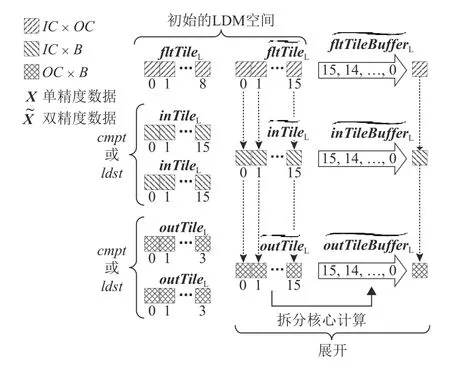
Fig.5 Unfolding LDM enhanced usage圖5 展開的LDM 強化使用

Fig.6 ?nterleaving LDM enhanced usage圖6 交錯的LDM 強化使用
2.2.4 輸出數據塊的彈性處理
在融合Winograd 算法的優化中,都是以單個輸出數據塊為計算粒度設計算法,對于片上存儲LDM的使用由B,IC,OC決定.但是并非任何情況下LDM都能夠得到充分使用,當B,IC,OC三者較小時,會出現大量LDM 空間閑置的情況.針對上述問題,設計了輸出數據塊的彈性處理方案:通過增大算法基于輸出數據塊的計算粒度,使閑置的LDM 空間能夠被使用起來,從而進一步探索融合Winograd 算法中潛在的數據局部性.
在進行Winograd 卷積時,移動輸入數據的滑窗獲取輸入數據塊時,2 個相鄰的輸入數據塊之間會產生r-1的重疊.因此,對于以單個輸出數據塊為計算粒度的融合Winograd 算法,輸入數據會出現反復被讀取的情況.如圖7 所示的卷積中,對于優化前的算法,輸入數據將會被平均反復讀取2.56 次.通過引入輸出數據塊的彈性處理,假設算法的計算粒度由單個輸出數據塊變為2 個輸出數據塊,那么每次只需要讀取 4×6的inTileM相當于之前讀取2 次 4×4的inTileM.因此,優化后的算法中輸入數據的平均反復讀取降為了1.92 次,相應地,輸入數據的訪存開銷降低了25%.在不考慮LDM容量的情況下,可以設置單次計算輸出數據塊的數量為,此時將完全消除輸入數據的不必要訪存,使其訪存局部性達到最大.
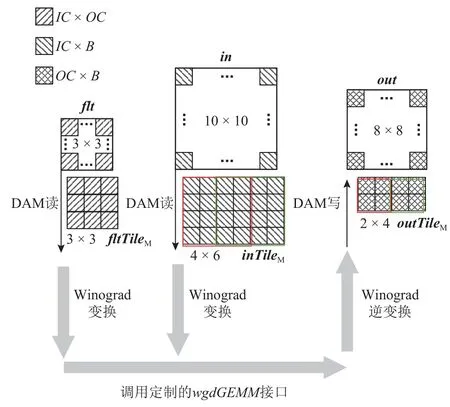
Fig.7 Processing two output data blocks in a single run圖7 單次處理2 個輸出數據塊
2.2.5 定制的矩陣乘
融合Winograd 卷積算法相比傳統Winograd 卷積算法的一大優勢就在于其不依賴于GEMM 庫接口,這使得整個Winograd 卷積的執行過程不再是透明的,從而讓更細粒度的計算訪存優化成為可能.為此,參考申威26010 處理器上的通用GEMM[26],定制了匹配該算法的矩陣乘實現.為了方便后續說明,將算法中的卷積參數映射到對應的矩陣乘參數.其中,矩陣A,B,C分別對應每次DMA 訪存的fltTileM,inTileM,outTileM數據塊,矩陣乘參數M,N,K分別對應卷積中的OC,B,IC.
如圖8 所示,整個定制矩陣乘實現可以分為2 部分:一部分為原始矩陣數據到單核組的任務映射;一部分為融合Winograd 卷積算法執行過程中調用的wgdGEMM.首先,前者由Winograd 變換、Winograd逆變換和核組級分塊構成,對于Winograd 變換和Winograd 逆變換過程,在2.1 節中已經進行了詳細的介紹,而核組級分塊直接采用文獻[26]中的分塊原理,詳細過程可以參考文獻[26]中的研究工作.其次,需要注意Winograd 轉換和Winograd 逆變換的線程級并行同wgdGEMM的線程級并行間是相對應的.以fltTileM為例,其在wgdGEMM中的對應矩陣A在進行線程級任務劃分時,是通過對Kcg×Mcg矩陣塊進行 8×8網格劃分從而實現單個從核的任務映射.同理,fltTileM也將通過對 3×3個ICcg×OCcg(ICcg=Kcg,OCcg=Mcg)數據塊的 8×8網格劃分以實現卷積核的Winograd 變換過程的線程級并行.類似地,inTileM需要通對 4×4個ICcg×Bcg(ICcg=Kcg,Bcg=Ncg)數據塊的 8×8網格劃分以實現輸入的Winograd 變換過程的線程級并行,outTileM需要通過對 2×2個OCcg×Bcg(OCcg=Mcg,Bcg=Ncg)數據塊的 8×8網格劃分以實現輸出的Winograd 逆變換過程的線程級并行.最后,將結合融合Winograd 卷積算法中矩陣乘與文獻[26]的2 點關鍵不同之處對wgdGEMM的實現進行詳細介紹:1)不同一.矩陣乘不再是非轉置的矩陣乘,而是矩陣A轉置的矩陣乘;2)不同二.M,N,K通常情況下小于1 000[27].
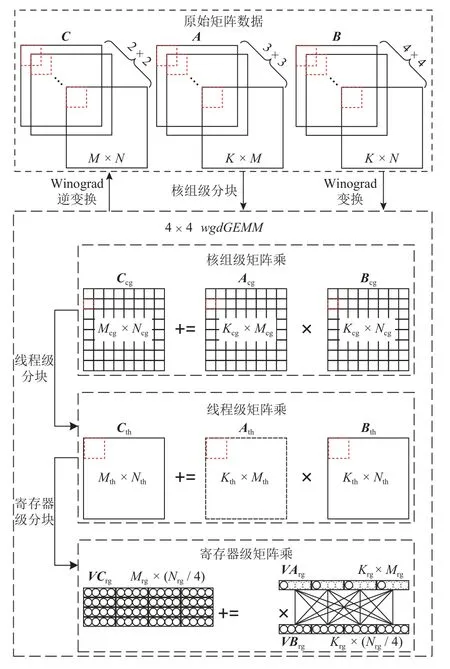
Fig.8 Customized matrix multiplication implementation圖8 定制的矩陣乘實現
將16 個wgdGEMM綁定到一起作為融合Winograd卷積算法的單位計算粒度.其中,單個wgdGEMM可以分為3 個層次,分別為核組級矩陣乘、線程級矩陣乘和寄存器級矩陣乘.對于核組級矩陣乘,Acg,Bcg,Ccg分別對應算法中存儲雙精度數據的LDM 緩沖區當LDM 空間足夠的情況下,Mcg,Ncg,Kcg分別與M,N,K相等.然后,基于單個核組上的 8×8從核陣列,對Acg,Bcg,Ccg進行 8×8網格形式的線程級分塊,從而將單核組的矩陣乘映射到單線程的矩陣乘.為了滿足Cth的計算需求,需要通過廣播-廣播的寄存器通信方案[26],分別對Ath和Bth進行廣播.在對從核進行Ath,Bth,Cth數據分配時,考慮到“不同一”,定制矩陣乘不再采用單一的行對行映射,而是按照行對行映射的方式為每個從核分配Bth和Cth,按照行對列映射的方式為每個從核分配Ath.由此,可得第i行第j列的從核將分配到Acg[j][i],Bcg[i][j],Ccg[i][j].通過這種混合映射方法,使得在廣播-廣播的寄存器通信中,分別對Ath進行行廣播,對Bth進行列廣播,從而使得每個從核上寄存器通信緩沖區資源能夠得到充分利用.為了能夠盡可能發揮wgdGEMM的指令級并行效率,通過寄存器級分塊進一步將線程級矩陣乘劃分為更細粒度的寄存器級矩陣乘,從而方便最底層核心指令序列的手動重排.考慮到“不同一”中可以先對Ath進行轉置,將其維度從Kth×Mth變為Mth×Kth,再直接運用文獻[26]中的方法.但是我們更希望能夠避免這一轉置帶來的額外訪存開銷,為此,基于申威26010 處理器單精度向量長度為4 這一特性,設計了如圖8 所示的寄存器級矩陣乘映射方案:1)通過vldd 指令依次裝入Cth中元素,每次4 個元素,得到一個VCrg[Mrg][Nrg/4]的向量數組;2)通過ldder 指令依次裝入Ath的單個元素進行向量擴展,得到一個VArg[Krg][Mrg]的向量數組,并行廣播;3)通過vldc 指令依次裝入Bth中元素,每次4 個元素,得到一個VBrg[Krg][Nrg/4]的向量數組,并列廣播;4)通過vmad 指令對VArg和VBrg的所有向量數據進行全相連的乘法運算,并同VCrg中對應向量元素進行累加運算5)通過vstd 指令將計算結果寫入Cth的對應位置.其中,每執行一次方案1和方案5,相應的方案2~4將會被執行次,不難看出方案2~4 組成了寄存器級矩陣乘的核心指令序列.為了保證寄存器級矩陣乘的運算效率,取Krg=1使得累加運算過程不存在數據依賴.同時,考慮到申威26010 處理器除去零寄存器和棧指針(stack pointer,SP)寄存器能夠自由使用的向量寄存器數為30,所以有
再考慮整個線程級矩陣乘的計算訪存比,所以有
在保證涉及到的每個向量元素能夠匹配1 個獨立向量寄存器的情況下,為了最大化計算訪存比,減少不必要的訪存開銷,結合式(6)(7),可得因此,對于寄存器級矩陣乘,分配4 個向量寄存器存儲VArg、4 個向量寄存器存儲VBrg和16 個向量寄存器存儲VCrg.
申威26010 處理器每個從核支持2 條不同的流水線P0 和P1,其中P0 支持浮點和整數的標量/向量操作,而P1 支持數據遷移、比較、跳轉和整數標量操作.為了能夠獲得高性能的wgdGEMM,可以通過手寫匯編保證寄存器級矩陣乘核心指令序列盡可能精簡,同時手動重排指令序列以充分發揮從核的雙流水指令運行機制.通過對上述寄存器級矩陣乘的描述,可以得到理想情況下向量寄存器的分配.其中,4個向量寄存器用于載入VArg數據,標記為AR0~AR3;4 個向量寄存器用于載入VBrg數據,標記為BR0~BR3;16 個向量寄存器用于存儲VCrg數據,標記為CR00~CR33.由此,可以得出寄存器級矩陣乘最內層循環核心指令序列如圖9(a)左側所示,執行時間為25 個時鐘周期,此時整個執行過程幾乎處于單流水狀態.為了能夠真正啟動從核的雙流水模式,對初始指令序列手動重排,重排后如圖9(a)右側所示.在最內層循環開始前,首先預取第1 次計算所需的AR0,AR1,BR0,BR1,然后在最內層循環指令序列中實現當前循環的計算前部分和訪存后部分的雙流水,以及當前循環的計算后部分和下一輪循環的訪存前部分的雙流水,最終優化后的指令序列的執行時間為16 個時鐘周期,性能提升約56.25%.此時,雖然從核雙流水的性能得以充分發揮,但是Mrg=4且Nrg=16,卻要求矩陣乘中M是32 的倍數且N是128 的倍數.雖然當M和N不滿足此要求時可以使用填充的方式先滿足倍數要求再進行運算,但是考慮到“不同二”,這種開銷往往是不可忽視的.例如,當M=64,N=64,K=128時,依照圖9(a)中實現,需要額外1 倍的計算和訪存,這些不必要的計算和訪存將極大地降低算法的性能.

Fig.9 ?nstruction reordering圖9 指令重排
為了盡可能緩解這一問題,依照Mrg=4且Nrg=16 時指令重排的思想,對Mrg∈{1,2,3,4}和Nrg∈{4,8,12,16}組成的16 種情況中余下的15 種情況的實現分別進行了指令重排,如圖9(b)所示Mrg=4且Nrg=8時的情況.為了配合這一實現,將Mth分為2 部分[0,Mthmod(Mth,4)) 和[Mth-mod(Mth,4),Mth).類似地,Nth也 被分為 [0,Nth-mod(Nth,16)) 和 [Nth-mod(Nth,16),Nth).通過Mth的2 部分和Nth的2 部分的一一對應關系可以將寄存器級矩陣乘分為4 個部分.此時,對于M=64,N=64,K=128的情況則可以直接運算,不需要任何多余的計算和訪存開銷.
2.3 通用性分析
本文研究工作雖然是面向國產申威26010 處理器探索并行卷積算法的高性能實現,但是仍然對其他眾核處理器硬件平臺具有一定的借鑒意義.如2.1節中Winograd 變換、核心運算和Winograd 逆變換融合執行以盡可能減少分離執行造成的高額訪存開銷的思想,2.2.1 節中合并Winograd 變換過程并向量化以避免存儲中間數據帶來的額外片上存儲資源的開銷并降低變換過程中的計算量,以及2.2.4 節中彈性處理輸出數據塊的數量以充分利用片上存儲資源,這些優化方案都是脫離硬件平臺特征的,可以直接應用于其他眾核處理器.除此之外,其他的優化方案,比如DMA 雙緩沖、片上存儲的強化使用、定制矩陣乘實現這些工作則是同申威26010 處理器架構特征緊密聯系的,雖然無法直接應用于其他眾核處理器平臺,但是對于某些類似架構特征的硬件平臺仍然可以提供一些參考價值.
如上所述,Winograd 融合卷積算法可以分為與架構無關的優化方案和與架構相關的優化方案2 個部分,對于新一代的申威26010Pro 處理器[28-29],主要關注于架構相關的優化方案的適用性.而架構相關的優化方案主要是DMA 雙緩沖、片上存儲的強化使用、定制矩陣乘實現,其中申威26010Pro 處理器對于DMA 雙緩沖是依舊支持的;片上存儲LDM 則由原來的64 KB 增加到了256 KB,更多的片上存儲資源更有利于降低主存的訪問頻率;定制矩陣乘的實現中,最大變化來自于寄存器通信機制的取消和S?MD 指令向量長度的增加,但是仍然具備對單核組從核間的數據通信的支持,也就是新的RMA(remote memory access),向量長度的增加則更有利于浮點性能的發揮.因此,綜合上述分析不難看出,融合Winograd 卷積算法對于申威26010Pro 處理器同樣適用.
3 實驗結果與分析
申威26010 處理器的配置如表1 所示.
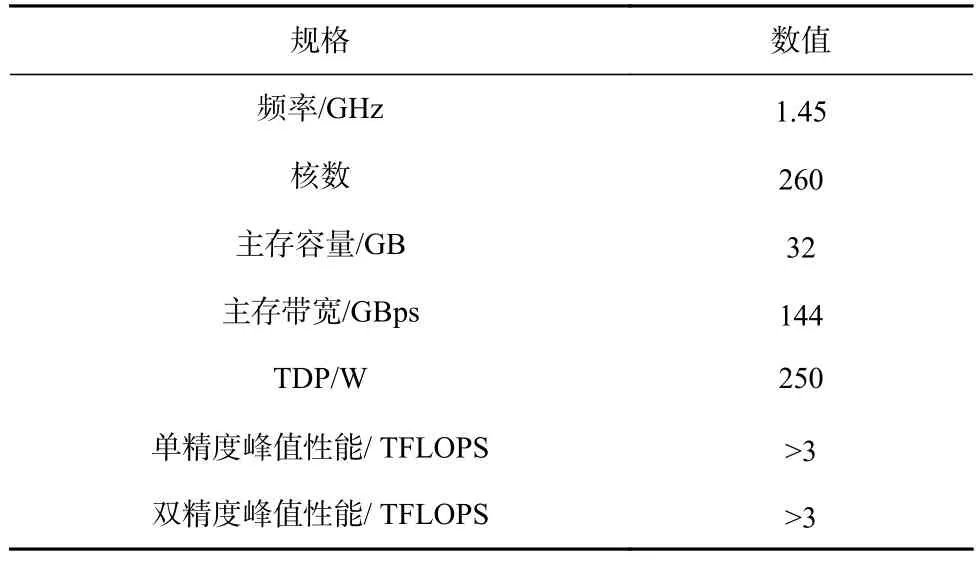
Table 1 Configure Parameters for ShenWei-26010 Processor表1 申威 26010 處理器配置參數
本次實驗全部在申威26010 處理器單核組上進行,因為跨不同核組的并行通常由更高編程級別的用戶自己處理[26,30].實驗中將本文提出的不依賴官方GEMM 庫接口的融合Winograd 卷積算法標記為fusedWgdConv,類似地,將依賴官方GEMM 庫接口的傳統Winograd 卷積算法作為基準測試對象,并標記為simpleWgdConv.從4 個不同的角度設計實驗,從而充分展示研究工作的成果和價值.1)通過對不同優化方案的累加設計實驗,測試各個優化方案的效果;2)抽取典型卷積神經網絡模型AlexNet,GoogleNet,ResNet,VGG 中的常見卷積層,測試評估fusedWgdConv在實際應用場景中的性能;3)基于fusedWgdConv,在深度學習框架Caffe 中測試不同批大小下VGG 網絡模型的卷積性能提升.4)對fusedWgdConv 調用的wgdGEMM的效果進行了測試.為了保證測試結果的精確性,所有測試均迭代10 次,去掉1 個最優值和1個最差值,取剩余8 個測試結果的平均值.
3.1 優化效果測試
選取VGG 中的卷積作為測試實例,并以simpleWgd-Conv 作為測試基準,測試并記錄fusedWgdConv 在不同優化方案累加下相比于simpleWgdConv 的性能加速.
通過對不同優化方法的累加,可以得到7 個版本的fusedWgdConv,分別為:1)?N?T,融合Winograd 變換、核心運算和Winograd 逆變換的執行過程,初步實現fusedWgdConv;2)MERGE,在?N?T 版本的基礎上引入合并的Winograd 變換模式;3)DB_?N,在MERGE版本的基礎上,雙緩沖實現in的DMA 訪存和核心運算的并行;4)DB_OUT,在DB_?N 版本的基礎上,雙緩沖實現out的DMA 訪存和核心運算的并行;5)LDM_OPT,在DB_OUT 的基礎上,引入展開的LDM 強化使用和交錯的LDM 強化使用,緩解有限片上存儲資源的使用壓力,降低算法的片外訪存開銷;6)MULT?_OUT,在LDM_OPT 的基礎上,考慮小規模卷積時LDM 大量閑置的情況,引入輸出數據塊的彈性處理機制,使得任何情況下算法都能充分利用片上存儲資源;7)ADD_F43,通過添加F(4×4,3×3)的實現,探索不同輸出數據塊大小的影響.
如圖10 所示,初步實現了fusedWgdConv 的?N?T版本相比simpleWgdConv 有67%的性能提升,可見?N?T 的基本設計思路能夠明顯降低simpleWgdConv依賴官方GEMM 庫接口造成的高額訪存開銷.依據Winograd 變換系數能夠提前確定這一特征,將原本分離的Winograd 變換模式替換為合并的Winograd變換模式,同時引入向量化,不僅消除了額外的LDM使用,而且大大降低了Winograd 變換過程中的計算量,基于此的MERGE 版本性能是simpleWgdConv 的2.9 倍.申威26010 處理器支持DMA 的異步執行,通過對fusedWgdConv 的精心設計實現了in和out的DMA訪存同核心運算的并行運行,使得大部分的片外訪存開銷得以被計算掩藏.基于此的DB_?N 版本相比MERGE 版本性能提升了52.76%.進一步優化后的DB_OUT 版本相比MERGE 版本性能提升了74.14%.最終雙緩沖使得fusedWgdConv 運行性能達到了simpleWgdConv 的5.05 倍.有限的片上存儲資源限制了fusedWgdConv 的性能提升,為了能夠盡可能提升片上存儲的使用效率,設計了展開的LDM 強化使用以減少數據類型變換帶來的額外LDM 消耗,以及交錯的LDM 強化使用降低inTileL雙緩沖的LDM 需求,由此LDM_OPT 版本性能相比DB_OUT 版本進一步提升了48.51%.MULT?_OUT 版本中的輸出數據塊彈性處理僅對小規模卷積有作用,因此對算法性能提升并不明顯,其最終性能是simpleWgdConv 的7.75 倍.ADD_F43 版本相比于MULT?_OUT 版本的性能提升非常微弱,主要原因在于fusedWgdConv 單核組每次至少要處理1 個輸出數據塊所涉及到的Winograd變換、Winograd 逆變換和核心運算,造成片上存儲資源的開銷很高.當算法由F(2×2,3×3)擴展到F(4×4,3×3)時,單個輸出數據塊的規模增加了4 倍,大大增加了對片上存儲資源的需求,而申威26010處理器有限的片上存儲資源不足以很好地支撐fused-WgdConv 的進一步擴展.
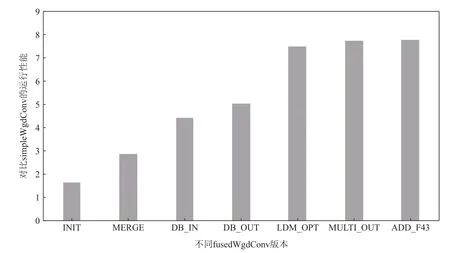
Fig.10 Performance comparison of different fusedWgdConv versions and simpleWgdConv圖10 不同fusedWgdConv 版本和simpleWgdConv 的性能對比
綜合來看,fusedWgdConv 相比simpleWgdConv 對于申威26010 處理器上的卷積有顯著的性能提升.
3.2 卷積性能測試
為了能夠進一步驗證fusedWgdConv 對常用卷積是否具有現實意義,抽取典型卷積神經網絡模型AlexNet,GoogleNet,RestNet,VGG 中卷積層的卷積參數,并測試對比fusedWgdConv 和simpleWgdConv 的卷積性能.一般來說,卷積性能測試時的測試標準是運行時的性能,但是為了能夠更好地觀察算法對硬件處理器的使用效果,實驗選擇運行時相對理論峰值性能的百分比作為測試標準,計算公式為硬件效率=.
如圖11 所示,將抽取的卷積按照計算量由小到大排列,同時對2 種常見的卷積形式進行測試分析:1)填充為0 且跨步為1;2)填充為1 且跨步為1.從總體卷積測試來看,fusedWgdConv 在無填充和有填充的情況下平均硬件效率分別為95.08%和91.2%,分別是simpleWgdConv 下卷積性能的14.54 倍和14.52 倍.可以看出,fusedWgdConv 的卷積能夠很好地適應現實中的卷積場景.從單個卷積測試來看,無填充時,fusedWgdConv 性能最小時是simpleWgdConv 性能的3.02 倍,最大時可以達到62.81 倍;有填充時,fusedWgd-Conv 相比simpleWgdConv,卷積性能與無填充時差不多,在3.01~62.72 倍不等.其中,無填充和有填充情況下,fusedWgdConv 的最高硬件效率可以分別達到116.21%和111.41%.可以看出,fusedWgdConv 能夠很好地發揮申威26010 處理器的硬件性能,且相比simpleWgdConv有明顯的性能提升.
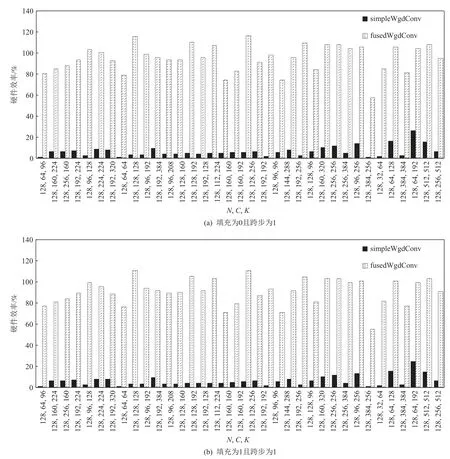
Fig.11 Hardware efficiency of ShenWei-26010 processor for different convoltuions圖11 不同卷積下申威26010 處理器的硬件效率
3.3 卷積神經網絡性能測試
為了測試評估本文工作在實際使用中的效果,以原始版本的Caffe 為基準,基于fusedWgdConv 測試不同批大小下VGG 模型的卷積性能提升.同時,考慮到Caffe 中卷積的數據格式為N-C-H-W,fused-WgdConv 的數據格式為H-W-C-N,標記Caffe-FWC和Caffe-FWC-DFT 這 2 個版本的Caffe,分別表示基于fusedWgdConv 的Caffe 和基于fusedWgdConv 且進行數據格式轉換的Caffe.
如圖12 所示,Caffe-FWC 的性能加速比在3.4~9.8之間.而Caffe-FWC-DFT 雖然仍能帶來可觀的性能提升,但是數據格式轉換大約占了整個卷積執行過程的40.5%,因此是不容忽視的.但是數據轉換過程完全是可以避免的,只需要將卷積神經網絡模型中的所有網絡層格式設計成H-W-C-N即可.此時在實際使用中僅需對樣本數據進行 1 次的N-C-H-W到H-W-C-N的數據格式轉換即可,其代價相對于后續成千上萬次的網絡模型的循環迭代是非常微小的.這也是我們目前正在致力于的整個DNN 庫的研究工作,具體內容會在以后的文章中進行詳細闡述.
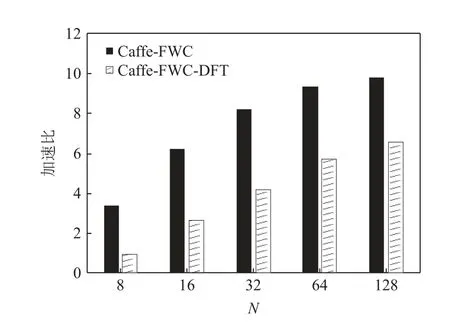
Fig.12 Performance speedup of Caffe with different versions圖12 不同版本Caffe 的性能加速比
3.4 定制矩陣乘效果測試
fusedWgdConv 的關鍵點之一就是與其匹配的定制矩陣乘,如2.2.5 節所示,wgdGEMM在申威26010處理器現有的通用GEMM[26]的基礎上,針對2 點不同進行了設計.針對“不同一”,設計了混合映射的廣播-廣播的寄存器通信以及避免轉置開銷的寄存器級矩陣乘.相應的,針對”不同二”,對Mrg∈{1,2,3,4}和Nrg∈{4,8,12,16}組成的16 種情況下寄存器級矩陣乘的核心指令序列都進行了手寫匯編和指令重排,而文獻[26]只考慮了Mrg=4且Nrg=16的情況.
實驗選擇8 組矩陣乘場景作為測試對象,其中每組矩陣乘滿足2 點:一是矩陣A轉置;二矩陣的維度不同時滿足Mrg=4和Nrg=16.同時,選取申 威26010 處理器現有的GEMM[26]作為基準,對比測試wgdGEMM的效果.假設GEMM 同wgdGEMM一 樣所需數據已存在于LDM 中,如表2 所示為兩者的運行時間.其中,wgdGEMM相對GEMM 性能加速比為0.202 3~0.278 8 不等,平均性能加速比約為0.239 9.由此可見,針對fusedWgdConv 定制矩陣乘是有必要的,且wgdGEMM相比GEMM 有明顯的性能提升.
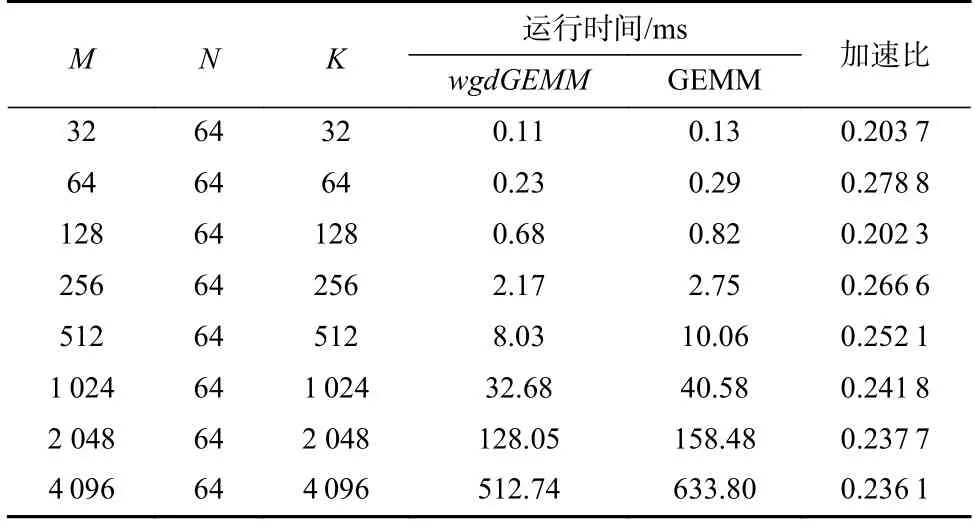
Table 2 Running Time for wgdGEMM and GEMM表2 wgdGEMM 和GEMM 的運行時間
4 總結展望
隨著我國自主研發的申威26010 眾核處理器在人工智能領域的快速發展,對該處理器上高性能卷積算法的實現也提出了更高的要求.而該處理器上卷積算法現有的研究尚處于初級階段,本文針對這一問題,結合申威26010 處理器的架構特征,提出并實現了一種高性能并行的融合Winograd 卷積算法.該算法有2 個主要特點:1)不依賴于官方GEMM庫接口,設計了匹配該算法的定制矩陣乘,并結合現實卷積計算特征和通用矩陣乘算法,在零開銷情況下完成了矩陣轉置,并對其寄存器級矩陣乘的核心指令序列進行了各種情況的指令重排;2)Winograd變換、核心運算和Winograd 逆變換過程的融合優化避免了三者分開執行時造成的反復讀取主存數據帶來的高額訪存開銷.此外,還設計了合并的Winograd變換模式加速Winograd 變換過程;DMA 雙緩沖實現從核陣列上計算和訪存的并行;展開和交錯的LDM強化使用方法以提高有限片上存儲資源的使用效率;輸出數據塊的彈性處理避免小規模卷積下片上存儲資源的浪費,通過這些優化保證了融合Winograd 卷積算法在申威26010 處理器上的高性能并行.在實驗分析中,以依賴官方GEMM 庫接口的傳統Winograd卷積算法為基準,從優化效果和卷積性能2 個方面進行測試分析,證明了融合Winograd 卷積算法不僅有遠高于傳統Winograd 卷積算法的性能,而且能夠很好地應用于現實卷積場景.
未來將對本文工作進行擴展,結合其他網絡層優化設計以及主流深度學習框架,進一步探索申威26010 眾核處理器上深度學習的并行優化.
作者貢獻聲明:武錚提出算法思路,設計并實現具體的優化方案,撰寫并修改論文;金旭參與算法實現、實驗設計以及數據分析;安虹負責指導論文撰寫.
猜你喜歡
科普童話·神秘大偵探(2023年1期)2023-05-30 12:48:10
測控技術(2018年5期)2018-12-09 09:04:26
電子測試(2018年18期)2018-11-14 02:30:34
電信科學(2016年10期)2016-11-23 05:11:56
時代農機(2015年3期)2015-11-14 01:14:29
科技傳播(2015年20期)2015-03-25 08:20:30
信息安全研究(2015年3期)2015-02-28 20:18:12
西安航空學院學報(2014年5期)2014-07-13 01:27:52
家電科技(2014年5期)2014-04-16 03:11:28
汽車零部件(2014年2期)2014-03-11 17:46:27
