基于深度殘差網絡和近紅外光譜的煤矸石智能識別
2024-04-23 17:14:34王亞棟賈俊偉譚韋君
分析測試學報 2024年4期
關鍵詞:模型
王亞棟,賈俊偉,譚韋君,雷 萌
(1.山西天地王坡煤業有限公司,山西 晉城 048000;2.天地(常州)自動化有限公司,江蘇 常州 213125;3.中國礦業大學 信息與控制工程學院,江蘇 徐州 221116)
煤矸石作為煤炭開采和加工過程中產生的副產品,其含碳量較低,燃燒性能不佳。當煤矸石混入煤炭中時,會顯著降低煤炭的發熱效率[1]。因此,在煤炭被輸送至市場前,對煤矸石進行有效的識別和分選至關重要[2-3]。目前,煤矸石的分選主要依賴人工揀選、濕選和干選等方法[4]。人工揀選雖具有一定的靈活性,但在追求高效率的現代生產環境下,其效率和準確性均顯不足,同時高強度的勞動也可能引起工人的健康問題。濕法分選雖然在一定程度上提高了效率,但其復雜的工藝流程和大量的水資源消耗可能導致嚴重的環境污染。干選法主要包括破碎法、射線法和圖像識別法[5-7],其中破碎法成本較低,但普適性較差;射線法輻射性較強,需要加裝隔離設備,設備成本較高;圖像識別法易受光照和粉塵的影響,難以達到生產要求。
近紅外光譜分析(NIRS)技術憑借快速、實時、無需化學試劑和對環境無害的特性,在煤炭的定性和定量分析領域得到了廣泛的認可和應用[8]。楊恩等[9]將光譜探頭安裝于采煤機上,通過分析煤巖界面的近紅外反射光譜曲線,實現了煤巖界面分布的快速精確探測。Yu 等[10]通過改進線性判別分析算法,并結合近紅外光譜技術對煤產地進行檢測,識別準確率達97.21%。Zou 等[11]基于近紅外光譜技術和改進的U 型網絡,挖掘多個煤質工業參數的關聯特性,實現了多煤質參數的協同預測。宋亮等[12]通過建立標準化差異煤炭指數模型分析可見光-近紅外光譜,實現了煙煤與褐煤的分類。Xiao等[13]將局部感受野與極限學習機結合,基于可見-近紅外光譜,實現了煙煤、無煙煤、褐煤等煤種的分類。也有部分研究人員將近紅外光譜應用于煤矸石識別領域。李廉潔等[14]采用特征波長篩選策略,基于可見-近紅外光譜高光譜成像,實現了黑色背景下塊狀煤與矸石的識別。但針對煤與矸石的近紅外光譜智能識別研究尚處于起步階段。
以卷積神經網絡(CNN)為核心的深度學習技術能夠高效、自主地挖掘數據內蘊藏的潛在特征,應用范圍廣泛,覆蓋計算機視覺、自然語言處理、醫學信號處理和語音識別等領域[15-16]。
基于上述背景,本文從河南、河北、山東3個煤礦產區采集了不同煤種的430組煤和矸石樣本,構建了國內首個開源的煤炭與矸石近紅外光譜數據集,通過迭代計算歐氏距離以識別并剔除異常光譜,確保數據集的質量和代表性。同時通過融合深度學習和近紅外光譜分析技術,構建了基于一維殘差網絡(1D-ResNet)的分類模型,用于煤與矸石的快速識別(相關數據和代碼開源于:https://github.com/usefulbbs/Coal-Gangue)。
1 數據與方法
1.1 光譜數據采集
煤炭作為一種天然形成的化石燃料,其化學組成和物理性質受到地質成因和成礦環境的顯著影響。由于不同地區的地質條件差異,煤炭展現出多樣的性質特征[17]。為豐富實驗樣本、增加樣本的多樣性,實驗分別從河南、河北和山東3 個省份采集了430 組煤炭和矸石樣本,每個產地的樣本數量如表1 所示。在河南與河北境內所采集的主要是無煙煤,其含碳量與燃點較高,密度、硬度較大,燃燒時無煙產生,廣泛用作化工業重要原料和民用生活燃料;在山東省內所采集的煤炭主要為焦煤,屬于中等變質煙煤,發熱量高、粘結性強,是煉焦的重要原料。

表1 不同產地的煤和矸石樣本數量Table 1 Number of coal and gangue samples from different regions
根據我國煤炭開采的相關標準和規定,并結合對我國礦井的實地調研,確定本實驗的環境條件為:采集溫度(20±10)℃,相對濕度50%±20%,并在正常大氣壓強下進行實驗。實驗使用VIAVI公司生產的高性能便攜式近紅外光譜儀MicroNIRTMPro采集樣本的光譜數據。為了確保測量的準確性和重復性,對每個樣本進行5 次掃描,以掃描結果的均值作為最終測量數據。鑒于煤與矸石均屬于固體樣本,采集時將儀器設置為漫反射模式,并固定儀器與樣品的距離為20 mm,以獲得最佳的光譜反射效果。光譜波長范圍為908.1~1676.2 nm,涵蓋了125 個不同的波長點,可為分析提供豐富的光譜信息。為保持數據的一致性和可靠性,每隔10 min 進行一次背景校正,確保光譜數據的穩定性和準確性。樣本的近紅外光譜是典型的一維數據,圖1給出了煤和矸石各25個樣品的近紅外光譜圖。
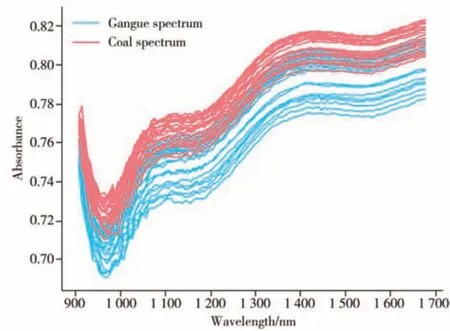
圖1 部分樣本的近紅外光譜圖Fig.1 Near infrared spectra of a few samples
1.2 異常光譜剔除
在樣本光譜采集的過程中,環境的變化或不恰當的操作均可能會導致數據集中出現與正常光譜顯著不同的異常值。這些異常值的存在不僅會干擾數據分析,還可能誤導模型的訓練過程,從而影響最終的測試結果。因此,建模之前需對光譜數據進行細致的異常值檢測和剔除。
歐幾里得距離(ED),即歐氏距離,是歐幾里得空間中兩點間的直線距離,常用于衡量數據間的相異度。 光譜數據集Xm×n=[x1,x2,...,xm]中樣本間的歐氏距離可表示為:
式中,xi為第i個樣本的光譜,包含n個特征點,i= 1,2,...,m;xj為第j個樣本的光譜,包含n個特征點,j= 1,2,...,m;xik為第i個樣本光譜的第k個特征點,k= 1,2,...,n;xjk為第j個樣本光譜的第k個特征點,k= 1,2,...,n。
對于采集到的樣本,其分布近似遵循正態分布。實驗通過采用迭代方法和3-sigma 準則,逐步剔除樣本光譜數據集中的異常值,具體步驟如下:
Step1:計算數據集Xm×n的平均光譜xˉ,平均光譜代表了光譜數據集的綜合屬性,能反映數據的總體趨勢;
Step2:根據公式(1)計算各樣本光譜到xˉ的歐氏距離{D(xi,xˉ)|i= 1,2,...,m};
Step3:按照99.7%的置信度檢測異常值,利用3σ準則將檢測閾值設置為D標準差的3倍(3σ)。其中,平均值:
標準差:
Step4:當|D(xi,) -μ| ≥3σ時,即判定xi為異常值并剔除。當有異常值被剔除時,須重新計算新數據集的。重復以上步驟,直至無異常值出現。
通過上述過程從數據集中移除可能導致模型訓練偏差的異常光譜,從而保證模型的泛化能力和測試結果的可靠性。
1.3 1D-ResNet
殘差網絡(ResNet)是一種高效的深度學習結構。在其訓練過程中,網絡各層的參數和非線性映射函數會逐步調整優化,以最小化網絡輸出與實際標簽之間的損失函數。這一優化過程確保了近紅外光譜輸入在經ResNet處理后提取的特征與目標標簽之間的對應性。具體而言,網絡通過賦予對最終預測結果有正向影響的特征更高的權重,同時降低可能引入誤差的噪聲成分的權重,以此提高模型的準確性和魯棒性。
殘差網絡構建在殘差模塊之上,通過加入“短路連接”實現恒等映射。典型的殘差模塊如圖2 所示。恒等映射可通過跨越兩個卷積層的直接連接,實現模塊的輸入與主路徑輸出的疊加。這樣的設計允許梯度在訓練過程中直接傳遞,無需經過多層非線性變換,極大地減輕了梯度消失的問題。此外,這種短路連接還有助于網絡更有效地學習恒等映射,從而使更深層次的網絡訓練變得更加穩定和高效。
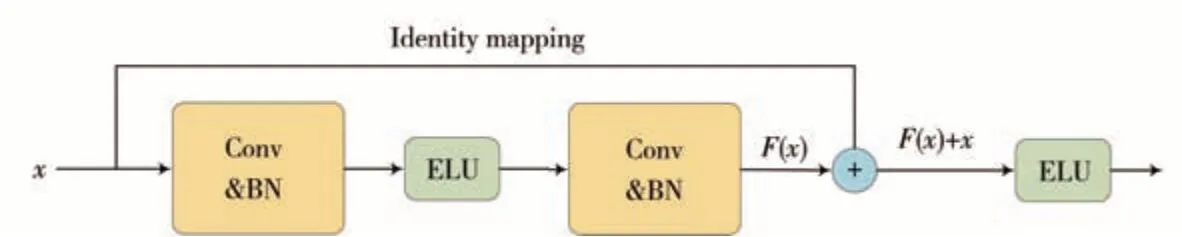
圖2 殘差模塊結構圖Fig.2 Structure of the residual module
原始的ResNet結構主要是為二維圖像數據設計的。近紅外光譜是一種一維數據,需要在網絡設計上進行調整以適應其特性[18]。首先,將常規的二維卷積層替換為一維卷積層,使卷積核可在光譜數據上沿一個維度進行卷積操作。其次,在考慮光譜數據特性和處理需求的基礎上,將網絡的超參數設置如下:殘差模塊中卷積層的數量為2,卷積核大小為3,滑動步長和填充數量均為1,其中的激活函數采用指數線性單元(ELU):
式中,s為ELU單元的輸入值;α為可調節參數。
ELU 可以避免神經網絡在變得更深時出現梯度消失問題。與線性整流函數(ReLU)不同,ELU 會在輸入為正時直接輸出該值,而在輸入為負時輸出一個小的負數。這種設計既避免了ReLU 的“死區”問題,又可以減少噪聲的影響。
殘差模塊的輸出維度(卷積核數量)需要根據模塊所在的位置進行調整,1D-ResNet 的結構和數據維度變化如表2 所示。初始單個樣本的光譜維度為(1,125),以其作為網絡的輸入數據。在輸出維度中,第一維表示輸入數據的批大小( Batch size),第二維表示特征維度,第三維表示網絡通道數。

表2 1D-ResNet網絡參數Table 2 Parameters of the 1D-ResNet network
1D-ResNet 的網絡結構如圖3 所示。批歸一化層(BN)用于加快和穩定訓練過程,最大池化層用于壓縮特征圖大小,保留顯著信息[18-20]。殘差模塊保存了原始輸入信息,有效緩解了梯度消失問題。Flatten用于將多維的輸入一維化。全連接層作為分類器,輸出的兩個數值經Softmax函數處理后作為每個類別的條件概率。

圖3 1D-ResNet的結構圖Fig.3 Structure diagram of 1D-ResNet
針對煤和矸石的二分類任務,在模型訓練時采用交叉熵損失函數(Loss)進行分類:
式中,y為真實的標簽值(0或1);p為預測標簽為1的概率值。
1.4 模型評價方法
模型預測的準確率A按照下式進行計算:
式中PT為正確分類為煤的樣本個數;PF為錯誤分類為煤的樣本個數;NT為正確分類為矸石的個數;NF為錯誤分類為矸石的個數。
實驗采用五折交叉驗證對模型進行評估,將樣本隨機均分成5 份,每次選擇其中1 份作為測試集,其余4份作為訓練集,共進行5次實驗。為了避免樣本不平衡對實驗結果的影響,在樣本劃分時,每一份樣本中煤和矸石的數量大致相當。最后,取5次預測準確率的平均值用于衡量模型的性能。該方法能夠全面評估模型在不同數據集上的泛化能力和穩定性,從而確保得出的結論基于全面和均衡的數據分析。
2 結果與討論
2.1 異常值剔除
為避免異常值的干擾,本實驗按照樣本來源地和類別,基于歐氏距離對異常樣本進行迭代剔除。異常值的判定過程如圖4 所示,在對河南矸石樣本集進行第1次迭代時,2#樣本與平均光譜的歐氏距離超出了閾值,因此被作為異常值剔除,在第2 次迭代時未發現異常值,迭代終止。類似地,山東煤炭中的46#樣本被當作異常值剔除,其余樣本集中未發現異常值。

圖4 河南矸石數據異常值第1輪迭代(A)和第2輪迭代(B)剔除過程,以及山東煤數據異常值第1輪迭代(C)和第2輪迭代(D)剔除過程Fig.4 The exclusion process of outliers in the first iteration(A) and the second iteration(B) for abnormal values in Henan gangue data,as well as the exclusion process in the first iteration(C) and the second iteration(D)for abnormal values in Shandong coal data
圖5 展示了河南矸石和山東煤中異常樣本光譜與正常樣本光譜的對比。圖中實線表示正常光譜,虛線表示異常光譜。盡管正常樣本和異常樣本的光譜在整體趨勢上相似,但在吸光度值上存在顯著差異。這種差異可能源于測量設備的偏差或操作人員引入的誤差,這些因素會對模型的最終預測結果帶來不利影響。

圖5 河南矸石光譜數據集(A)和山東煤光譜數據集(B)中異常樣本與正常樣本光譜對比示意圖Fig. 5 Comparison schematic of spectral data between abnormal samples and normal samples for the Henan gangue spectral dataset(A) and the Shandong coal spectral dataset(B)
2.2 建模分析
圖6 展示了1D-ResNet 在訓練過程中損失變化的曲線圖。在該圖中,實線代表訓練集的五折平均損失變化,虛線則表示測試集的五折平均損失變化。在訓練的初期階段(0~約400輪),訓練集和測試集對應的損失迅速下降,表明1D-ResNet 具有良好的學習和擬合能力,能在標簽的引導下快速、準確地調整模型參數實現模型的有效訓練。之后,損失曲線趨于平穩并維持在一個較低的水平,表明模型在經過充分訓練后,已達到較好的收斂狀態。此時,模型的性能在訓練集和測試集上表現出一致性,說明1D-ResNet 在處理此類數據時具有較好的泛化能力。這種穩定的損失趨勢也表明了模型對于捕捉煤矸石光譜特征的有效性,同時避免了過擬合的問題,確保了模型在實際應用中的可靠性和預測準確性。

圖6 五折交叉驗證平均損失變化曲線Fig.6 Five-fold cross-validation average loss change curve
為客觀評價1D-ResNet 的性能,本實驗將其與近紅外光譜領域中常用的分類模型進行了對比,包括支持向量機(SVM)、決策樹(DT)、隨機森林(RF)和K近鄰(KNN)。使用五折交叉驗證對每種方法進行評估,得到對應的模型參數量、每一百個樣本的平均推理時間和分類準確率,結果如表3所示。

表3 不同模型實驗結果對比Table 3 Comparison of experimental results of different models
在傳統方法中,SVM 的性能較好,五折交叉驗證準確率為93.92%。1D-ResNet 的預測準確率高達96.26%,明顯優于其它方法,表明由殘差模塊構成的網絡模型,能較好地分析樣本光譜特征,學習煤與矸石光譜間的差異。雖然1D-ResNet每一百個樣本的平均推理時間為16.230 ms,長于其它模型,但已滿足實際應用需求,這一時間上的輕微犧牲并不會對其有效性產生顯著影響。
3 結 論
在傳統的煤矸石識別方法中,人工分選和機械濕選存在效率低、消耗大量水資源等問題。為解決此問題,本文融合近紅外光譜分析技術和深度學習方法,實現了快速、有效的煤矸石識別。通過采集不同產地不同煤種的430 組煤和矸石樣本,增強了實驗結果的普適性和可靠性,并提供了更具代表性的數據基礎。采集樣本的近紅外光譜后,利用歐氏距離剔除了數據集中的異常值,并構建了基于1DResNet 的識別模型,該模型能夠自動學習光譜的內在特征。五折交叉驗證結果表明,模型的分類準確率達96.26%,優于傳統的機器學習方法(SVM 和隨機森林等)。該文為煤矸石識別提供了一種快速實用、簡潔高效的分析方法。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
