基于文檔順序與多模態模型的金融票據信息抽取?
2024-04-17 07:27:36林宇亭
計算機與數字工程 2024年1期
覃 俊 林宇亭 劉 晶,3 葉 正 劉 洲
(1.中南民族大學計算機科學學院 武漢 430074)(2.湖北省制造企業智能管理工程技術研究中心 武漢 430074)(3.農業區塊鏈與智能管理湖北省工程研究中心 武漢 430074)
1 引言
在當今數字化的趨勢下,各行各業都利用文檔存儲信息,尤其是金融領域。如何將電子文檔中的信息自動提取出來,是企業化轉型的重要步驟[1]。預訓練模型BERT[2]誕生后,文字抽取任務取得了巨大進展。而文檔是多模態表示的,有多種模態數據需要學習,包括文本位置和視覺信息等。在2019 年,微軟提出了文檔智能的預訓練模型LayoutLM[9],該模型在BERT 的基礎上添加了2-D Position Embedding 和Image Embedding,使模型可以聯合學習文本信息和布局信息之間的關系,但是該模型沒有將視覺模態和文本模態結合。所以LayoutLMv2[2]將圖像信息也進行編碼,并提出了空間感知的自我注意機制。最新的LayoutLMv3[3]舍棄了利用CNN[6]獲取視覺特征的方式,直接將圖像扁平化分塊。另外,百度提出的ERNIE-Layout[7]首次在預訓練過程中對文檔布局進行了排序。
雖然通過計算機視覺和自然語言處理的結合已經可以有效提取文檔關鍵信息[8]。但是金融文檔存在信息混亂、背景復雜等問題。現有的模型并不能有效處理金融文檔。所以,本文以金融票據為研究對象,提出一種針對票據文檔的序列化方法,結合LayoutLMv3 模型與GRU 網絡,使模型的泛化能力和識別準確率得到顯著提升。
文章的主要貢獻如下:1)構建了一個含有復雜背景的金融票據數據集,驗證了模型的泛化性。2)針對含有復雜背景的金融票據,提出一種解決金融票據無結構化的方法。3)文章結合了LayoutLMv3模型與GRU 網絡,并與多個模型進行對比實驗,以此來表明文章方法在處理復雜金融票據的優越性。
2 金融票據信息抽取
金融票據的信息抽取是從非結構化的數據中抽取實體以及實體關系的任務。圖1 展示的是本文所構建的真實票據數據集示例。

圖1 含有復雜背景金融票據實例
為了提取出文本和布局模態信息,文獻[10]通過先進性光學字符識別(OCR)。通過OCR 識別出文檔中的文本和位置信息,然后通過NLP模型抽取實體。而LayoutLM 的出現,將文本模態和圖像結合起來,通過大規模數據的預訓練以達到很好的效果。其過程如圖2 所示,訓練完畢后,就可以利用模型提取文檔中的信息[11]。在數據標注階段,通常會利用序列標注(BIO)的辦法。但是金融票據中的信息往往是無序的,所以僅使用序列標注是很難提取到正確的關系。例如“名稱、數量、價格、西瓜、2、10$”,在這樣的文字順序中“名稱”和“西瓜”是存在邏輯關系的。需要人工標注,但是利用序列標注需要大量的人力。本文受ERNIE- Layout 模型在預訓練中結構排序的啟發,提出一種針對金融票據的文本序列化方式。首先對OCR 的識別信息進行實體標注,然后利用Layout-Parser 工具包將OCR識別的結果進行排序,并且將“名稱、數量、價格”標注為“問題”,將“西瓜、2、10$”標注為答案,將有邏輯關系的數據進行實體鏈接,沒有實體關系的數據如“標題、地址等”,將其放在序列的最前方。以此更好地識別實體之間的關系。

圖2 文檔信息抽取流程圖
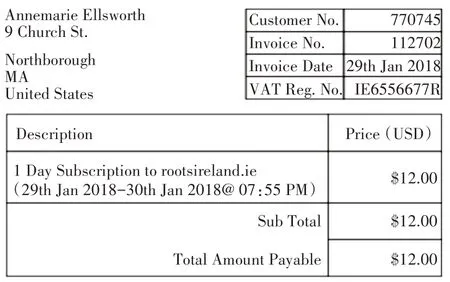
圖3 復雜結構金融文檔實例
3 方法
本文主要結構遵循LayoutLMv3,并引入兩種方法:1)構建順序重構模塊,使用Layout-Parser 將文檔中的文字數據進行序列化,構建文本之間的上下文關系和空間關系。2)使用單詞級別的編碼規則,并在模型中增加GRU[12]捕捉空間依賴關系。圖4是本文改進后的模型。
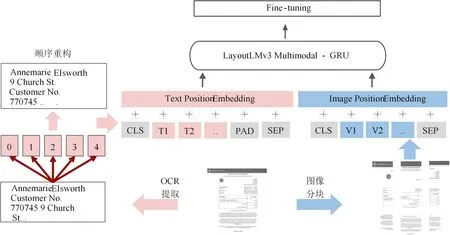
圖4 文檔信息抽取模型圖
3.1 LayoutLMv3
LayoutLMv3 模型在模型設計上,舍棄了CNN和Faster R-CNN 來表征圖像,直接利用文檔圖像的圖像塊,大大節省了參數并避免了復雜的文檔預處理(如人工標注目標區域框和文檔目標檢測)。簡單的統一架構和訓練目標使LayoutLMv3 成為通用的預訓練模型。該模型大大超越了此前的SOTA結果。
3.2 構建有序的文本序列
首先需要利用OCR 技術將文本和文本位置識別出來。但傳統的OCR 是利用多尺度掃描進行識別,這樣的方法使OCR 關注的順序都是從左到右和從上到下的順序。但是在金融文檔中,兩個有關聯的數據往往是上下相關或者并不在同一行上面。
如圖3 所示,傳統OCR 識別出的順序是“Annemarie EIsworth Customsr No.770745 9 Church St。”,該順序與人類閱讀順序不符。所以本文采用Layout-Parser 將票據信息進行有序排列。并將實體分為“標題、地址、商品名稱、數量、價格”,票據中帶有表格型的數據將被檢測為空間布局,而普通的文本通過Layout-Parser 中的檢測模型和標記邊界框檢測其中的文本信息并獲取上下文關系。然后通過文檔重組算法,將識別到的文本按照“名稱、數量、價格”的順序重新排列組合,以獲得正確的閱讀順序。
由于金融票據背景信息繁雜,如圖3 所示,所以本文使用Layout-Parser 中基于主動學習的注釋工具[13]構建訓練集,然后根據半自動預測校正算法,會將重復項和錯誤的預測,根據較少的監督去糾正。若預測的框和真實的結果產生巨大差異,為了消除該差異會將第j 個對象位置不一致的Dp類別不一致的Dc公式化為式(1)~(2):其中IOU計算輸入的并集分數的交集,b?j,c?j表示原始預測框,pjk表示第k個擾動框,vjk表示擾動后的預測。
3.3 將序列化信息編碼到LayoutLMv3
金融票據中的文本和位置信息需要編碼進LayoutLMv3進行訓練,其中文本嵌入包括單詞嵌入和位置嵌入。文本嵌入T如式(3)所示:
其中Emb(T)、Emb1D(T)、Emb2D(T)表示文本嵌入、順序嵌入、坐標嵌入。文本嵌入利用RoBERTa[14]的文本矩陣初始化,并在文本序列的開頭和結尾處附加兩個特殊標記[CLS]和[SEP],表示一段文字的開始和結束。最后在文本序列的末尾附加[PAD]標記,利用此標記填充較短的序列,使所有的序列長度保持一致。
由于對文本進行了重新排序,所以把單詞的順序作為一維位置嵌入。將排序好的索引值利用和文本相同的方式進行編碼,并將其拼接在一起。為防止其過擬合在編碼過程中加入了Dropout,并通過實驗找到最優取值。
二維位置嵌入也叫做布局嵌入,對于每個文本,使用OCR 工具來獲取其二維坐標,邊界框的坐標由(x0,y0,x1,y1,w,h)所表示,其中(x0,y0)表示邊界框左上角坐標,(x1,y1) 表示右下角坐標,w,h表示邊界框的寬度和高度。為了規范化所有坐標的范圍,本文所有的坐標都在[0,1400]范圍內進行取值。
對于圖像嵌入,本文按照LayoutLMv3 的編碼規則。首先把圖像分辨率大小調整為224×224×3。然后將圖像分割成均勻的圖像塊,并線性投影到一維,如式(4)所示:
其中H、W 表示為圖像的高度和寬度,P2表示為圖像塊的個數。
3.4 結合LayoutLMv3與GRU
由于在金融票據中具有相關性的文本,其實際空間距離相隔較遠,導致文本在序列中的位置很遠。所以本文加入GRU 來解決這樣的問題,由于原始的注意力機制只能計算文本與絕對位置的關系,為了有效的利用文檔中的相對空間,使用空間感知自注意力機制把一維和二維位置信息設置為偏置項,如式(5)~(6)所示:
其中αij表示的是傳統注意力機制xi和xj之間的注意力分數。b(1D)、b(2D)是一維、二維信息的偏置項。(xi,xj)是第i個邊界框的左上角坐標,α'ij表示的是空間注意力分數。處理完的數據送到GRU中,每個GRU 單元包括一個重置門和一個更新門,重置門決定前一時刻的信息與現在的信息結合,更新門判斷前一時刻的保留程度,并作為現在時刻輸出。在處理完整個序列之后,將輸出的含有上下文關系的信息利用LayoutLMv3的分類器進行預測。
4 實驗
4.1 實驗數據
本文的實驗數據分為兩部分,包括真實的金融類票據數據集和現有的公開表單數據集。利用OCR工具對每張圖像的關鍵信息打上對應的標簽,并把實體做了鏈接。例如,商品名稱鏈接到對應的價格、數量。實驗所用數據一共有524 張圖像。本文按照8∶2 的比例,將數據劃分為420 張訓練集,104張測試集。
本文使用FUNSD 數據集[15]進行驗證有效性。包含199張、9707個實體。其中每個實體都包含一個ID、一個標簽、一個邊界框、一個與其他實體的鏈接表,被劃分為149 張訓練集,50 張測試集。詳情見表1。

表1 數據集統計
4.2 實驗設置
本文實驗采用LayoutLMv3-Base 和LayoutLMv3-Large 模型權重進行微調。 LayoutLMv3-base 模型采用12 層Transformer 編碼器,其時間復雜度為O(12N^2),LayoutLMv3-Large 模型采用24 層Transformer 編碼器。針對模型訓練時的超參數,本文通過超參數實驗取最優參數。如圖5 所示。該圖以Dropout 為例展示了取值不同時的準確率曲線,可以直觀看出在Dropout取值為0.1的時候效果最好。
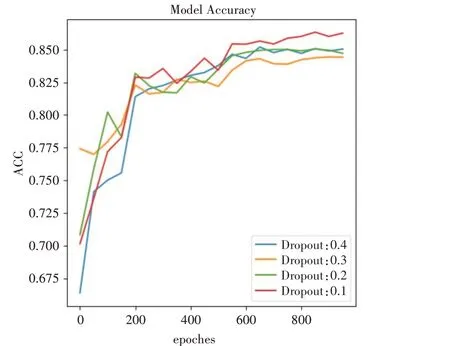
圖5 Dropout-準確率曲線圖
4.3 實驗結果
本文采用精確率(Precision)、召回率(Recall)和綜合評價指標(F1)作為模型性能的衡量標準。將收集的英文金融票據數據集與原模型進行對比,實驗結果如表2所示。
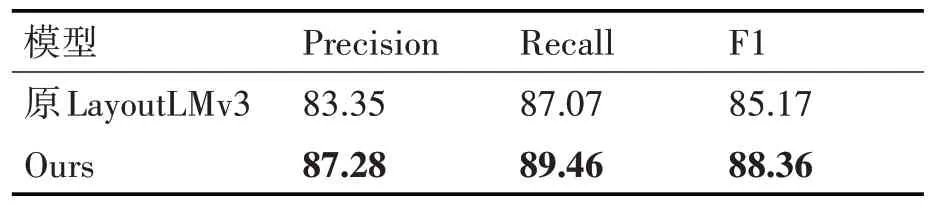
表2 金融文檔數據集實驗
含有復雜背景的數據在原模型的F1 指標是85.17%,而通過本文方法的改進之后達到88.36%。所以本文的方法在處理復雜背景的金融類票據的抽取的任務中是更有優勢的。
本文還對現有模型與公共數據集做對比。如表3所示,在BASE模型中,本文使用的方法與改進之前的LayoutLMv3 對比,Precision 提高了1.47%、Recall 提高了2.15%、F1 提高了2.37%。在Large 模型中,F1 提高1.65%。由此可見,本文的方法在處理表單類的數據時也是有顯著提升的。表明了本文方法的通用性。
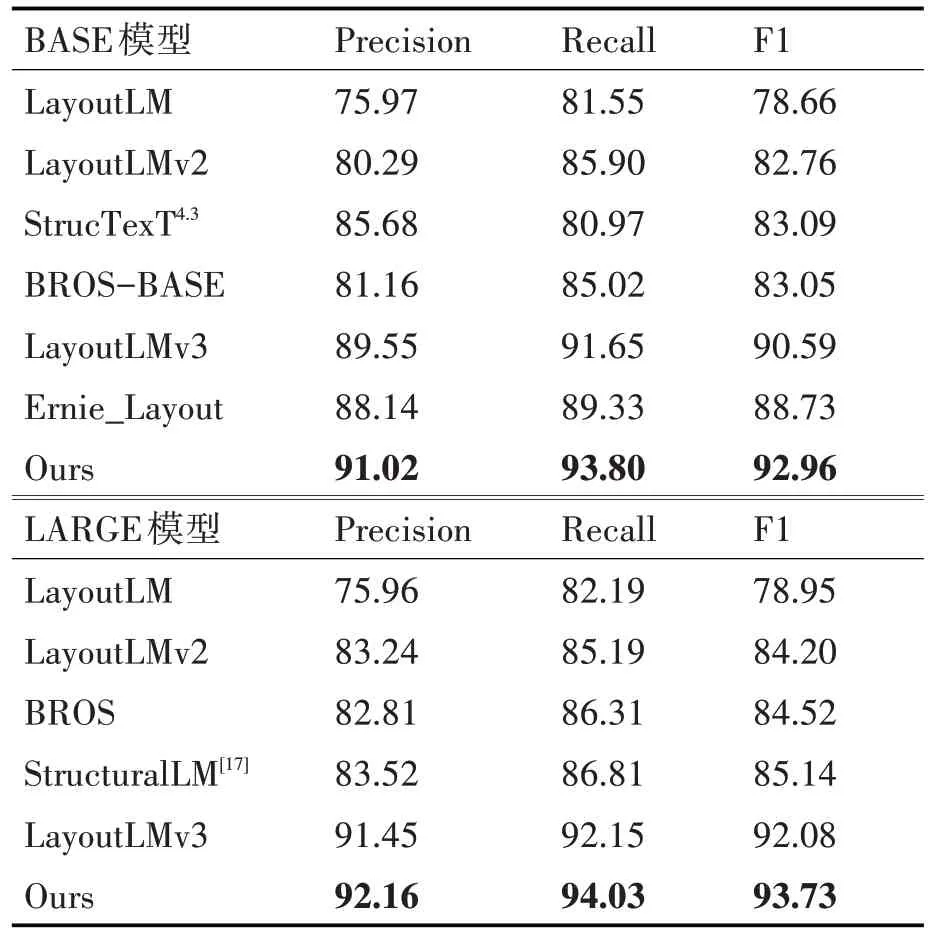
表3 FUNSD數據集對比實驗
除此之外,文章還在FUNSD 和文章構建的數據集進行了消融實驗,具體效果如表4 所示,其中第一行是FUNSD 的結果,第二行是文檔構建的金融數據集的結果。可以看出在加入序列化編碼和GRU 網絡后,F1 分數均有明顯提升。而金融票據數據集比普通表單數據集效果更加顯著。所以,文章提出的方法更加適用于金融票據領域,并且在文檔信息抽卻任務中具有通用性。
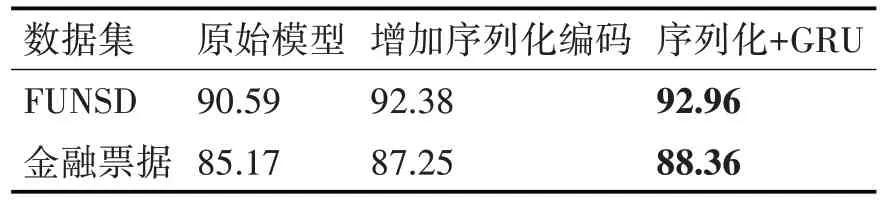
表4 不同數據集消融實驗的F1分數
5 結語
在本文中,針對復雜金融票據結構化信息少、冗余信息多的特點,結合文本、布局、圖像多個模態,提出順序重構進行復雜金融票據信息抽取的辦法。最終通過實驗,驗證了文章方法在抽取金融票據文檔時是高效的,可以達到88.26%的F1值,并且在文檔信息抽取任務中具有通用性。對于文檔信息抽取任務,需要對其包含的所有信息進行抽取,而不是僅僅通過實體標注抽取一部分信息。所以在之后,研究使用提示學習的方法來引導模型抽取不同的信息。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
制造技術與機床(2019年10期)2019-10-26 02:48:08
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
金橋(2018年12期)2019-01-29 02:47:36
知識經濟·中國直銷(2018年12期)2018-12-29 12:22:40
電子制作(2018年18期)2018-11-14 01:48:06
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
中國工程咨詢(2016年10期)2016-01-31 03:12:10
小學教學參考(2015年20期)2016-01-15 08:44:38
