融合輕量級注意力機制的單目標(biāo)跟蹤算法研究
2024-04-16 03:24:56朱瑩瑩郭傳璽
電子制作 2024年6期
朱瑩瑩,郭傳璽
(北方工業(yè)大學(xué) 電氣與控制工程學(xué)院,北京,100144)
0 引言
單目標(biāo)跟蹤是計算機視覺領(lǐng)域的重要任務(wù)。在單目標(biāo)跟蹤中,最常見的挑戰(zhàn)之一是目標(biāo)在視頻序列中的運動、尺度變化以及外觀變化。傳統(tǒng)的方法通常基于目標(biāo)模型和特征匹配來進行跟蹤,但是面對復(fù)雜的場景時容易受到光照變化、遮擋等因素的干擾,導(dǎo)致跟蹤的不穩(wěn)定性。近年來,深度學(xué)習(xí)技術(shù)的進步顯著推動了單目標(biāo)跟蹤領(lǐng)域的發(fā)展,特別是孿生網(wǎng)絡(luò)和注意力機制等深度學(xué)習(xí)模型被廣泛運用于單目標(biāo)跟蹤任務(wù),從而提高了跟蹤的準(zhǔn)確性和魯棒性。此外,隨著Transformer 模型在自然語言處理和圖像處理領(lǐng)域的成功應(yīng)用,一些研究者開始探索將Transformer 引入單目標(biāo)跟蹤領(lǐng)域,以期望通過其優(yōu)秀的序列建模能力來解決復(fù)雜的跟蹤問題。
盡管深度卷積神經(jīng)網(wǎng)絡(luò)在計算機視覺領(lǐng)域取得了顯著的成就,但是仍然存在一些問題,其中ResNet50 模型以其深度和性能而聞名。然而,ResNet50 模型在捕捉長距離依賴和處理圖像中的全局關(guān)系方面仍然存在一定的局限性。傳統(tǒng)的ResNet 模型是通過跨層連接來提升梯度的傳播,使得深層網(wǎng)絡(luò)可以很好地學(xué)習(xí)淺層網(wǎng)絡(luò)中的細節(jié)特征。然而,這種跨層連接機制在處理長距離依賴關(guān)系時可能會受到限制。
本研究的貢獻在于設(shè)計了一種融合輕量級注意力機制的單目標(biāo)跟蹤算法,引用TransT 網(wǎng)絡(luò)作為主干網(wǎng)絡(luò),在ResNet50 模型中引入一個輕量級且高效融合兩種注意力機制的Shuffle Attention(SA)模塊,SA 模塊通過自適應(yīng)地調(diào)整通道間的相互依賴關(guān)系,使得網(wǎng)絡(luò)能夠更好地捕捉圖像中的重要空間信息和通道關(guān)系。該模塊利用了局部感知和并行計算的策略,改善ResNet50 模型在處理長距離依賴和全局關(guān)系時的性能。
1 融合輕量級注意力機制的單目標(biāo)跟蹤算法研究
■1.1 算法總體框架
本文采用特征提取加特征融合加預(yù)測頭的架構(gòu),將SA模塊引入到特征提取骨干網(wǎng)絡(luò)ResNet50 的每個Bottleneck殘差塊。融合輕量級注意力機制的單目標(biāo)跟蹤算法研究網(wǎng)絡(luò)結(jié)構(gòu)如圖1 所示。該模型的輸入是一個3×128×128 模板圖像和一個3×256×256 搜索區(qū)域圖像,首先通過骨干網(wǎng)絡(luò)進行特征提取,接著使用特征融合模塊融合模板和搜索區(qū)域的圖像特征,最后使用預(yù)測頭模塊對每個向量的前/背景分類結(jié)果進行預(yù)測[1],并對搜索區(qū)域大小的坐標(biāo)進行預(yù)測。

圖1 模型總體框架圖
■1.2 Shuffle Attention 模塊介紹
SA 模塊是一個輕量級且高效融合空間注意力機制和通道注意力機制的綜合模塊。該模塊首先將輸入特征向量分成多個組,然后經(jīng)過通道注意力和空間注意力的計算,對于每個頭的注意力計算,會得到一個注意力權(quán)重矩陣,再將注意力權(quán)重矩陣輸入到Shuffle 單元中,Shuffle 單元根據(jù)一定的策略對多頭注意力權(quán)重進行重新排列,以增強模型對序列中不同位置之間依賴關(guān)系的建模能力,經(jīng)過Shuffle 單元重新排列后的多頭注意力權(quán)重矩陣再與原始的表示向量序列相乘,并進行加權(quán)求和操作,得到最終的注意力表示結(jié)果[2]。整個SA 模塊的總體結(jié)構(gòu)如圖2 所示。

圖2 Shuffle Attention模塊示意圖
1.2.1 特征分組

1.2.2 通道注意力
通道注意力分支主要用于計算不同通道之間的相互關(guān)系。首先用全局平均池化對特征圖進行池化,以生成通道統(tǒng)計信息s ∈RC/2G×1×1,可通過空間尺寸H×W收縮Xk1來計算:
然后通過兩個全連接層對池化后的結(jié)果進行縮放和移動,得到每個通道的權(quán)重值。最后,這些權(quán)重值被用于對特征圖中的通道進行加權(quán)匯總,從而得到具有更強表達能力的特征。通道注意力分支的最終輸出為:
W1∈RC/2G×1×1,b1∈RC/2G×1×1為用于縮放和移動s 的參數(shù)。
1.2.3 空間注意力
空間注意力分支使用Xk2上的分組卷積操作(GN)來獲得空間統(tǒng)計信息,對提取出的特征進行歸一化和加權(quán),最后通過一個非線性函數(shù)激活,得到增強的特征。空間注意力的最終輸出為:
其 中W2和b2是 形 狀 為RC/2G×1×1的 參 數(shù)。 然 后將兩個支路串接,使用通道數(shù)與輸入數(shù)相同,即
1.2.4 特征聚合
與shuffleNet v2 類似,本文采用了一個channel shuffle 操作符,重新排列通道的維度,促進了不同特征之間的信息交換和整合,最后得到和輸入X 同維的注意力圖。
2 實驗結(jié)果和分析
■2.1 實驗環(huán)境
本文算法使用Pytorch 框架實現(xiàn),使用兩個公開數(shù)據(jù)集(GOT-10K、COCO17)進行訓(xùn)練,骨干網(wǎng)絡(luò)是在ImageNet 上預(yù)訓(xùn)練的引入SA 模塊的ResNet-50,模型的其他參數(shù)由Xavier init 初始化,采用AdamW 優(yōu)化器,訓(xùn)練批次大小設(shè)置為26,骨干網(wǎng)絡(luò)的學(xué)習(xí)率設(shè)置為1e-5,其他參數(shù)的學(xué)習(xí)率設(shè)置為1e-4,權(quán)重衰減設(shè)置為1e-4,在三張Nvidia TITAN XP GPU 上訓(xùn)練1000 個周期,每個周期迭代1000 次,500 個周期后學(xué)習(xí)率下降10 倍[4]。
■2.2 定量分析
為了驗證本文所提算法的有效性,將本文算法和近幾年國內(nèi)外優(yōu)秀的算法進行了對比,并詳細列出了各個算法在GOT-10K、LaSOT、OTB100、UAV123 四個通用數(shù)據(jù)集上的指標(biāo)得分,其中對比算法的評分數(shù)據(jù)來自參考文獻原文,TransT 的評分數(shù)據(jù)是在自己現(xiàn)有的環(huán)境下訓(xùn)練測試的。GOT-10K、LaSOT 的對比結(jié)果如表1 所示。

表1 GOT-10K、LaSOT在各跟蹤器上的對比結(jié)果
由表1 可以得出,在GOT-10K 數(shù)據(jù)集上,本文算法的跟蹤平均重疊率達到了69.9%,比基準(zhǔn)算法TransT 提升了1.4%。在LaSOT 數(shù)據(jù)集上,本文算法的跟蹤AUC、精確度、歸一化精確度分別達到了57.5%、59.2%、65.1%,比基準(zhǔn)算法TransT 提升了1%的AUC,提升了0.5%的精確度,提升了0.6%的歸一化精確度。說明了本文算法預(yù)測出來的目標(biāo)中心更加接近真實目標(biāo)中心,從而能夠精確地定位目標(biāo)所處的位置。
本文在一些常用的小規(guī)模數(shù)據(jù)集OTB100 和UAV123上評估了IAMTransT 跟蹤器,同時也收集了近幾年的跟蹤器進行比較,評估指標(biāo)包括精確度和成功率,結(jié)果如圖3和圖4 所示。
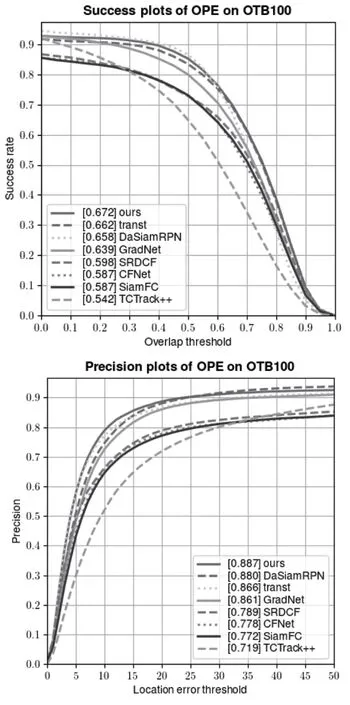
圖3 本文算法與其他算法在OTB100 測試集的實驗結(jié)果

圖4 本文算法與其他算法在UAV123測試集的實驗結(jié)果
在OTB100 數(shù)據(jù)集上,本文算法跟蹤成功率達到了67.2%,精確度上達到了88.7%,比基準(zhǔn)算法TransT 提升了1%的成功率,提升了0.7%的精確度。在UAV123 數(shù)據(jù)集上,本文算法跟蹤成功率達到了63.0%,精確度上達到了83.0%,比基準(zhǔn)算法TransT 提升了0.6%的成功率,提升了0.7%的精確度。通過定量實驗結(jié)果可以看出,本文提出的算法相較其他的算法在跟蹤的成功率和精確度上有一定優(yōu)勢。
■2.3 定性分析
為了更好地展示IAMTransT 算法與其他算法的差異性,本文在OTB100 數(shù)據(jù)集上選取了三個視頻序列,并將IAMTransT 算法和近幾年四個算法的跟蹤結(jié)果顯示在圖像上,清晰地展示了各個算法的差異性[5]。如圖5 所示,紅色代表本文的算法,綠色代表Ground-Truth,白色代表DaSiamRPN 算法,紫色代表GradNet 算法,藍色代表TransT 算法,黑色代表TCTrack++算法。

圖5 可視化對比圖
Box 視頻序列面臨的是快速移動與形變的問題,在第121 幀的時候,目標(biāo)發(fā)生了形變,本文的算法依然能夠準(zhǔn)確地跟蹤目標(biāo)。Coke 視頻序列面臨的是光照的變化,圖片中可以看出本文的算法一直穩(wěn)定地跟蹤目標(biāo)。Woman 視頻序列面臨的是遮擋的問題,在第176 幀時遭遇車輛的遮擋,本文的算法依然能夠成功跟蹤并且比其他算法更加接近真實邊界框。本文算法在目標(biāo)發(fā)生形變、光照變化、遮擋等情況下具有良好的精確性和穩(wěn)定性[6]。
3 結(jié)束語
本文引入了SA 模塊到特征提取骨干網(wǎng)絡(luò)ResNet-50的每個Bottleneck 殘差塊中,經(jīng)過大量實驗驗證,本文算法在4 個通用的數(shù)據(jù)集(GOT-10K、LaSOT、OTB100、UAV123)上均取得了優(yōu)秀的跟蹤效果,此外,本文還進行了大量的對比實驗,實驗結(jié)果表明本文的模型在目標(biāo)跟蹤成功率和精確度方面取得了顯著的提升。這證明了本文所提出的方法在解決復(fù)雜背景下的單目標(biāo)跟蹤問題上具有優(yōu)勢,具有一定的實用價值。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
山東煤炭科技(2020年1期)2020-03-06 06:43:28
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
河南科技(2014年23期)2014-02-27 14:19:15
高考金刊·理科版(2012年3期)2012-01-01 00:00:00
