基于生成對抗網(wǎng)絡的超聲數(shù)據(jù)壓縮方法研究?
2024-04-15 09:24:38李澤宇王黎明聶鵬飛韓星程武國強
艦船電子工程 2024年1期
李澤宇 王黎明 聶鵬飛 韓星程 武國強 馬 文
(中北大學信息與通信工程學院 太原 030051)
1 引言
隨著社會的不斷發(fā)展,無損檢測技術(shù)在現(xiàn)代工業(yè)等領(lǐng)域起到了至關(guān)重要的作用。超聲檢測是常用的無損檢測方法,具有較高穿透性等優(yōu)勢[1]。在超聲檢測中,由于探頭數(shù)量多、采樣頻率高,大量的超聲數(shù)據(jù)被存儲下來。由于數(shù)據(jù)量龐大,存儲下來需要大量的空間,因此研究合適的超聲數(shù)據(jù)壓縮方法已成為急切需求。關(guān)于超聲數(shù)據(jù)的壓縮算法早已有研究,如哈夫曼編碼、LZW 算法、游程編碼等,這些壓縮算法雖然能夠壓縮數(shù)據(jù),使其能夠便于存儲和傳輸,但面對當今數(shù)量巨大的數(shù)據(jù),越來越顯得力不從心。
近年以來深度學習技術(shù)取得迅速發(fā)展,尤其是生成對抗網(wǎng)絡(GAN)[2]的出現(xiàn),因其優(yōu)秀的性能,該網(wǎng)絡一經(jīng)提出就成為熱點研究領(lǐng)域。為了進一步提高數(shù)據(jù)的壓縮比,本文研究了基于生成對抗網(wǎng)絡的超聲數(shù)據(jù)壓縮的方法。實現(xiàn)了更高壓縮比的超聲數(shù)據(jù)壓縮。最后進行仿真實驗,展示了本文方法在提高超聲數(shù)據(jù)壓縮能力方面優(yōu)越的性能。
2 生成對抗網(wǎng)絡模型
本文以GAN、CNN 和LSTM 模型為基礎(chǔ),建立模型。此模型主要由兩部分組成,分別是生成器和鑒別器組成。網(wǎng)絡模型如圖1所示。
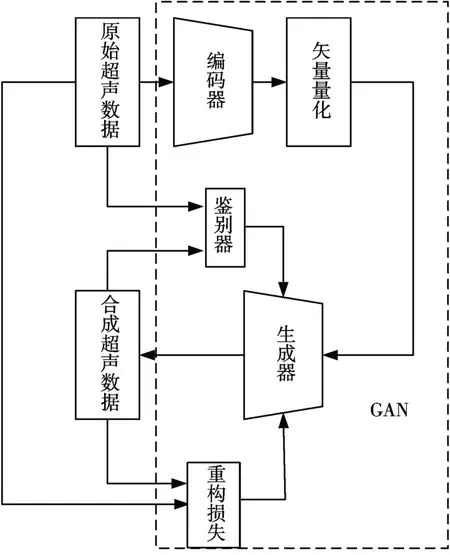
圖1 生成對抗網(wǎng)絡模型
2.1 生成器
生成器的網(wǎng)絡主要由CNN 和LSTM 網(wǎng)絡構(gòu)成。由于生成器網(wǎng)絡和編碼器互為鏡像,因此以介紹編碼器為主。編碼器網(wǎng)絡結(jié)構(gòu)如圖2所示。
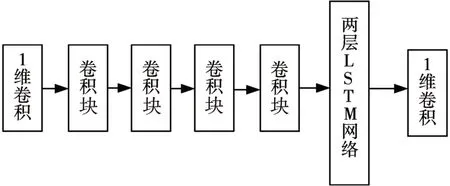
圖2 編碼器結(jié)構(gòu)
編碼器由兩個一維卷積層、4 個卷積塊和LSTM 模塊組成,其中每個卷積塊由1個卷積層和1個下采樣層組成。通過多層的卷積和下采樣,可以達到將數(shù)據(jù)降維的效果[3]。
卷積層通過卷積核,從輸入中抽取重要特征,形成特征向量。其運算表達式為
式中,Yk,Yk-1為第k層,第k-1層的特征向量;Mk為卷積核;bl為偏置。
通過卷積操作,從輸入的數(shù)據(jù)中提取出具有代表性的特征,通過激活操作進行非線性變換,得到更適用于壓縮的特性。本文使用常見的ELU函數(shù)。
由于數(shù)據(jù)特征的維度比較高,會造成訓練網(wǎng)絡出現(xiàn)過度擬合的情況,因此常常通過加入下采樣層來提高網(wǎng)絡運算速度,減少訓練時間并能有效防止訓練過擬合[4],下采樣層輸出為
其中S 為下采樣的規(guī)則,本文使用平均池化。平均池化的表達式為
由于LSTM 網(wǎng)絡能夠從每組序列中提取出數(shù)據(jù)的特點,常被用來處理序列數(shù)據(jù),其能夠很好地存儲遠程時間依賴性信息,建模數(shù)據(jù)之間的短時依賴或者是長時依賴[5]。
LSTM 網(wǎng)絡結(jié)構(gòu)包含一個細胞存儲單元和3 個控制信息增減的門(遺忘門、輸入門、輸出門)[6]。LSTM結(jié)構(gòu)如圖3所示。
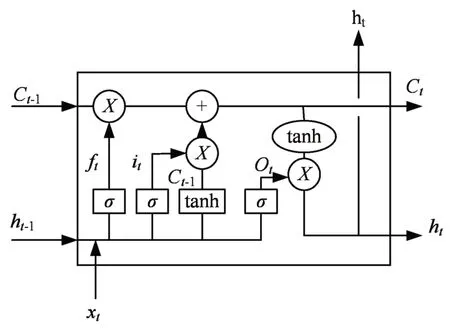
圖3 LSTM結(jié)構(gòu)
LSTM 結(jié)構(gòu)中的“遺忘門”ft決定要從細胞存儲單元中舍棄哪些信息。舍棄多少由sigmoid 函數(shù)的輸出決定,1 表示“全保留”,0 表示“全舍棄”。“輸入門”it:決定要往細胞存儲單元中存儲哪些新的信息,“輸入門”中的sigmoid 網(wǎng)絡決定需要保留哪些新的信息,tanh 網(wǎng)絡決定了需要更新多少隱藏狀態(tài)信息;結(jié)合“遺忘門”和“輸入門”的輸出,可以對細胞存儲單元中的信息進行更新,“輸出門”O(jiān)t決定了要從細胞存儲單元中輸出哪些信息,與之前的門類似,會先由sigmoid 函數(shù)產(chǎn)生一個介于0~1 之間的數(shù)值來確定輸出哪些細胞存儲單元中的信息。
生成器網(wǎng)絡具體參數(shù)如表1所示。
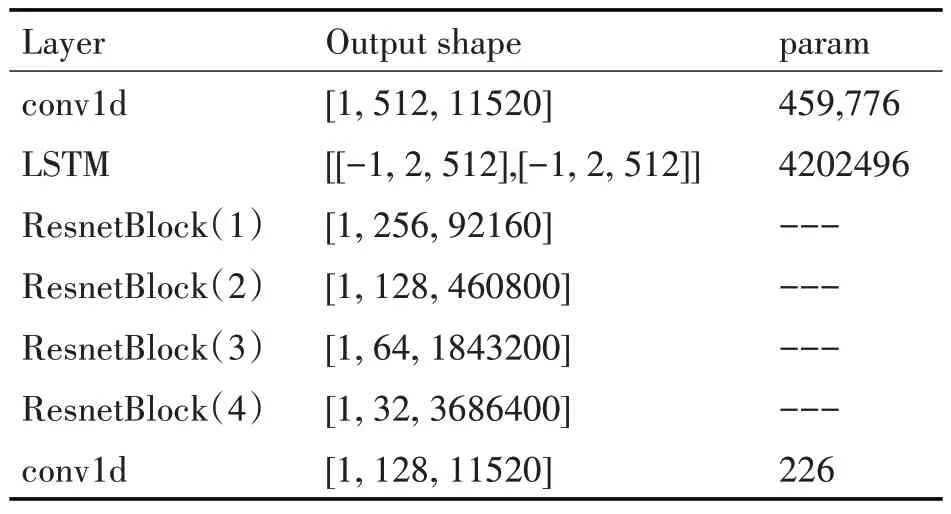
表1 生成器網(wǎng)絡具體參數(shù)
2.2 鑒別器
鑒別器是同一時間下對生成的數(shù)據(jù)和真實的數(shù)據(jù)進行鑒別,鑒別器的網(wǎng)絡結(jié)構(gòu)如圖4所示。
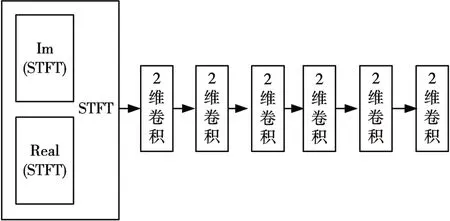
圖4 鑒別器網(wǎng)絡結(jié)構(gòu)
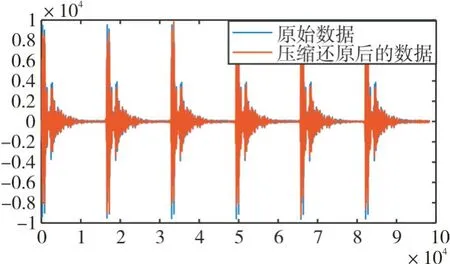
圖5 原始信號和壓縮還原后信號對比圖
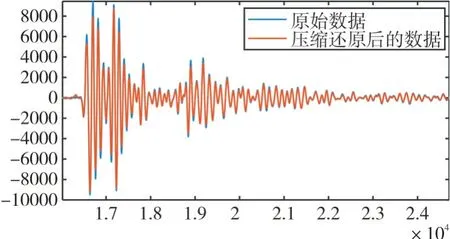
圖6 有效信號部分
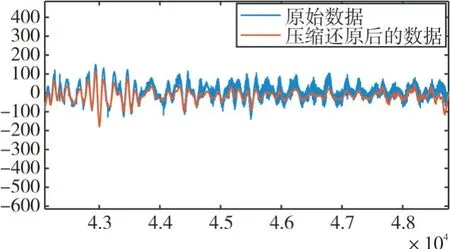
圖7 噪聲部分
MS-STFT 鑒別器網(wǎng)絡的輸入是一個實部和虛部連接的復值STFT。每個鑒別器都有一個二維卷積層(內(nèi)核大小為3×8),然后是隨著膨脹率不斷增加的二維卷積(1,2和4),步長為2。膨脹二維卷積后是一個卷積核大小為3×3 的二維卷積。最終的二維卷積核大小為3×3和步長為1提供了最終的預測。
鑒別器的采用Leaky ReLU作為激活函數(shù)。
3 模型訓練
模型的訓練分成兩個部分,一部分介紹模型中的損失函數(shù),另一部分介紹整個模型的訓練過程。
3.1 損失函數(shù)
重構(gòu)損失包含了時域損失和頻域損失。時域損失函數(shù)如下:
對于頻域上的損失,本文采用多時間尺度的mel 頻譜圖上L1 和L2 損失之間的線性組合。頻域損失函數(shù)如下:
其中Si是64-bins的梅爾頻譜圖,e=5,…,11,α表示L1和L2之間的平衡標量系數(shù)集,αi=1。
生成器的對抗損失函數(shù)如下:
其中,K為鑒別器數(shù)量。
生成器的相關(guān)特征匹配損失函數(shù)如下:
其中,Dk是鑒別器,L 是鑒別器層數(shù),K 是鑒別器數(shù)量。
鑒別器損失函數(shù)如下:
其中,K是鑒別器數(shù)量
整個模型的訓練,就是為了將生成器訓練為優(yōu)化以下?lián)p失。
其中,λt,λf,λg,λfeat為各項的平衡系數(shù)。
3.2 訓練過程
一次模型訓練分為兩部分,分別訓練鑒別器和生成器。
在對鑒別器和生成器訓練的過程中,需要先對鑒別器進行訓練,讓其學會分辨真假,此時從生成器接收到的數(shù)據(jù)標簽都為假,以此計算損失函數(shù)并更新鑒別器中的參數(shù)。然后開始訓練生成器,鑒別器接收來自生成器的假數(shù)據(jù)來計算損失函數(shù),此時標簽全為真,目的是希望生成器的數(shù)據(jù)能夠向真實數(shù)據(jù)不斷靠攏。
訓練中整個參數(shù)更新的方法采用Adam算法。
4 實驗結(jié)果分析
4.1 數(shù)據(jù)集
本文使用超聲數(shù)據(jù)來自于實驗室自制的數(shù)據(jù)集。將數(shù)據(jù)集中的數(shù)據(jù)分割為長度一致的數(shù)據(jù),得到共21065條數(shù)據(jù)。
4.2 性能評估
本文方法的性能評估主要是與傳統(tǒng)壓縮方法進行比較和一些壓縮評價指標。
從表2 中可以看出與傳統(tǒng)方法相比,本文方法有著良好的壓縮率。

表2 各類方法壓縮比比較
本文方法屬于有損壓縮方法,因此需要對解壓后的數(shù)據(jù)進行評估,本文采用了以下幾種評估方法,對該壓縮方法進行評估。
1)相對均方根誤差(R2MSE);2)信噪比(SNR);3)相關(guān)系數(shù)(R);4)均方誤差(RMSE);5)平均絕對誤差百分比(MAPE)。
根據(jù)表3,得出用本文方法對超聲信號進行壓縮并還原后的效果還比較好,經(jīng)分析造成R2MSE較大的原因為超聲信號中的噪聲還原時產(chǎn)生的誤差較大。

表3 本文方法的評價指數(shù)
5 結(jié)語
為了研究出高保真的超聲數(shù)據(jù)壓縮方法,本文提出了生成對抗網(wǎng)絡和LSTM,卷積網(wǎng)絡結(jié)合的模型,通過三種網(wǎng)絡結(jié)合的方式來提高壓縮比和還原度。
經(jīng)過試驗,本文的方法能夠合成出與真實數(shù)據(jù)近似度較高的數(shù)據(jù),在模型合成數(shù)據(jù)誤差等方面都有著良好的性能。
本文的不足之處在于使用的數(shù)據(jù)集過于單調(diào)和網(wǎng)絡結(jié)構(gòu)較為復雜。改進的思路是通過擴大數(shù)據(jù)集,訓練優(yōu)化網(wǎng)絡參數(shù)。同時還需不斷試驗改進網(wǎng)絡結(jié)構(gòu)。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
