決策中心戰制勝機理仿真實驗分析?
2024-04-15 09:24:32李立偉侯立志趙擎天陳秋麗
艦船電子工程 2024年1期
陳 鑫 李立偉 侯立志 趙擎天 陳秋麗 孫 贇
(軍事科學院系統工程研究院 北京 100020)
1 引言
2019 年美國戰略與預算評估中心發布《重奪制海權―美國海軍水面艦隊向決策中心戰轉型》報告,首次提出“決策中心戰”作戰概念,建議美國海軍通過“決策中心戰”重塑指揮架構、調整兵力部署、保持決策優勢,為美國國防戰略提供支持[1]。2020 年戰略與預算評估中心發布《“馬賽克戰”:利用人工智能和自主系統實施決策中心戰》報告,指出“馬賽克戰”即是一種“決策中心戰”,軍事競爭的下一主要領域將是信息和決策,通過利用新興人工智能和自主系統技術有望建立新的長期優勢[2]。決策中心戰概念著眼大國對抗的作戰需求,旨在推動美軍從信息為中心作戰向決策為中心作戰轉變,從掌控信息優勢向掌控決策優勢轉變。這一作戰概念具有重大的理論和實踐價值。如果說網絡中心戰概念開啟了美軍向信息化軍隊轉型之路,決策中心戰概念則標志著美軍信息化建設進入了更高階段,也將成為美軍智能化轉型的重要牽引。對決策中心戰進行仿真實驗,對于剖析其制勝機理具有十分重要的意義。
2 問題的提出
決策中心戰的制勝機理是使敵方陷入“決策困境”,實質是以智能化輔助決策為支撐,創新作戰樣式,快速形成殺傷鏈的閉合。當前的研究多是在理論層面對這一作戰概念進行宏觀描述、對人工智能賦能的新型作戰體系功能特點進行總結,但對于它的內在機理缺乏量化的科學分析和研究。平臺分解的粒度對作戰體系的能力有什么樣的影響?是不是分解程度越高,體系能力就越大、越穩定呢?小型平臺在戰斗空間異構組合快速形成能力的關鍵是什么?諸如此類的問題尚未得到解決。但這些問題都是汲取決策中心戰的經驗、科學布局智能化作戰體系的關鍵問題。
3 基于MAS 抽象建模的決策中心戰仿真實驗分析
3.1 仿真實驗系統總體設計
決策中心戰機理仿真實驗系統總體設計思想,是設置一個決策中心戰典型作戰場景,仿真以人工智能、物聯網、大數據、云計算等科技支撐環境下的分布式自主并行作戰樣式,通過量化分析找到制勝機理。本實驗選取了馬賽克作戰體系,作戰主體是將多能平臺分解后的動態組成的專業化系統集合,即將體系中具有智能特征的各作戰實體抽象為多智能體,這樣馬賽克作戰體系即被抽象建模成一個MAS(Multi-agents System,多智能體系統),系統中的多智能體被賦予殺傷鏈中的發現、定位、跟蹤、瞄準、打擊與評估六種能力包[3~4],在一定的作戰想定背景下,通過設計多智能體異構規則,預設不同的變量,觀察系統運行后自主決策、自主行動等行為方式,統計關鍵變量對MAS 效能產生的影響,從實驗結果中找到決策中心戰的制勝要素。決策中心戰機理仿真實驗總體設計思路如圖1所示。
3.2 決策中心戰MAS實驗與機理分析
3.2.1 實驗基本想定
1)基本想定內容
本實驗按照實驗目的屬于假設檢驗實驗,模型在不考慮藍方干擾的情況下,在范在互聯[5]的網信環境中,以紅方某型無人機群打擊藍方對象為作戰場景,紅方無人機具有發現能力、定位能力、跟蹤能力、瞄準能力、打擊能力及評估能力六種可能能力的架構,應對藍方的殺傷網需要這六種能力中的隨機幾種能力,將作戰雙方分別定義為兩類Agent,即紅方平臺Agent 和藍方目標Agent。作戰開始后雙方皆可實時獲取對方的位置和能力信息,當藍方對象全部能力被紅方鎖定后,該對象將消失同時隨機產生一個新的需要隨機能力的目標。
2)想定空間
本實驗系統采取概念級抽象仿真,對戰場環境進行簡化,構造可實現馬賽克戰典型戰場的降階模型。利用多主體仿真工具NetLogo,將戰場基本環境抽象為無邊界網絡,紅、藍多智能體在一個環面曲面(圖2(a))的作戰空間中互相作用。在系統平面圖(圖2(b))中,如果一個智能體從左邊消失,就會在右邊出現;如果在下方消失,就會在上方相應的位置出現,即多智能體在水平方向和豎直方向回繞[6]。為了簡明洞察多智能體在虛擬戰場中的適應、協作、異構等特性,模型中沒有納入敵方干擾及指揮控制復雜性的影響,同時假設所有智能體都以相同的速度移動,且沒有納入損耗作為平臺的特征。
圖2 戰場空間示意圖、系統平面圖
3)關注范圍
一是檢驗馬賽克戰是否比傳統的多能平臺系統作戰效率高。決策中心戰主張的是能力分解按需組合,因此本實驗的重點在于:對馬賽克化的即不同能力分解度下的程序運行結果進行比較,分析得出平臺分解度是否比傳統的平臺作戰效能高。二是判定在決策中心中制勝的關鍵是什么。最優方案是不存在的,因為這與數圖論中的旅行推銷員問題相似,同屬于計算機科學中的NP-hard 問題,即無法用一定數量的運算來解決多項式時間內可解決的問題。通過為多智能體賦予行為規則,啟發式探索智能體異構的較優方案和沖突消除方法,探索一定的規律和要點。三是考慮復雜度對模型的影響。本實驗規定攻擊目標一旦被消滅,即在隨機位置被取代,從而在整個運行過程中保持目標的總體密度。在密度一定的情況下,如在具有六種能力類型的120 個能力目標中,全部是一體化平臺,模型有20 個平臺;在完全分解的的情況下,最多有120 個平臺。所需要能力越多,復雜度越高,對規則的邏輯編排要求就越高,實驗將會關注復雜度對結果的影響。
4)實驗粒度
本實驗采用基于多智能體抽象仿真方法,屬于粗粒度實驗,將馬賽克戰中最核心的參數進行抽象。被簡化的內容主要有戰場環境和作戰單元。將殺傷鏈的能力分散抽象為具有或需要隨機能力的智能體,通過人為制定行為規則,觀察運行結果,分析研究馬賽克戰的運行機理。建模涉及六個變量,一是紅方無人機數量;二是藍方攻擊目標數量;三是紅方無人機可支配的能力數量;四是藍方攻擊目標所需要的能力數量;五是平臺分解度;六是效能指數MoE(Measrue of Effectiveness)(本實驗中設定為每分鐘產生的能力數)。仿真結果的有效性通過效能指數來計算。
3.2.2 實驗運行
1)初始化
紅藍雙方智能體坐標隨機地布撒于作戰空間,紅方智能體為紅色飛機,藍方智能體為藍色方塊,通過滑塊可以選擇紅方無人機數量num_guns,藍方攻擊目標數量num_goals,紅方無人機可支配的能力數量capacity_gun,藍方攻擊目標所需要的能力數量capacity_goal。如圖3 所示為一個初始化界面,滑塊從上到下依次表示紅方無人機40 架,藍方目標40 個,紅方每臺無人機具備3 種能力,藍方每個目標需要3 種能力。能力以不放回的方式分配給各平臺,將發現、定位、跟蹤、瞄準、打擊與評估6種能力設置為列表(0 1 2 3 4 5),不同平臺分別具有列表中的任意3 種能力,例如某平臺可能具有能力0、2 和4,另一個平臺可能具有能力1、2 和3。每個平臺能力不重復,例如不會配備能力1、1和2,但在整個部隊中可以重疊,比如藍方中的任意幾個平臺可能都需要能力2。拖動滑塊可實現對參數在范圍內的任意調節,即可生成任意想要的初始化界面。

圖3 初始化界面
2)規則設置
本實驗采取啟發式設計,將能力隨機分配給攻擊對象,但這并不是為了解決最優的問題,而是通過規則設計后在運行中發現的問題,來找到在最低限度的復雜環境中,啟發式算法帶來的某些困難。最基本的啟發式規則是純貪婪算法,且有兩個可以選擇的規則。圖4是部分規則代碼。

圖4 部分規則代碼
基本規則:在每個時間步,所有平臺都試圖按照圖4 中概述的過程,來選擇一個要應對的攻擊對象,所有具有與紅方飛機的能力1 個或者多個能力的藍方目標都是該飛機的潛在目標,那些已經有歸屬平臺來提供其所需要能力的攻擊對象將被忽略。首要的決策為取捷徑,即紅方Agent 將選擇距離自己最近的藍方Agent目標,向目標前進,抵達該目標所在位置,等待仍然需要的其他能力的平臺趕來,當全部能力被滿足,就認為藍方該目標已經得到應對。它將在從仿真中移除,并用另一個隨機生成的攻擊對象代替。所有已經分配給正在尋找目標的平臺開始再次行動,并進行能力匹配來應對。
遞歸瞄準規則:如果離一個需要應對的藍方平臺最近的紅方攻擊對象已經被距離該攻擊對象更近的另一個平臺所覆蓋,則第一個平臺檢查下一個最近的目標,對所有攻擊對象進行探測,以確定是否有一個攻擊對象可以使用其進行應對,并且還沒有被更近的某個平臺所覆蓋。
需求檢查規則:當各平臺最初觀察到潛在攻擊對象時,所有平臺已經分配的能力都從最初的攻擊對象需求中扣除,這減少了分配給同一攻擊對象的冗余平臺。
圖5 中第五、六張展示了攻擊對象分配和沖突消除的規則,包括“卡住”的目標,即一個正在進行中但尚未得到完全應對的攻擊對象。在代碼編寫過程中,對“卡住“的目標采取的調整方法是:先記住“卡住”的目標,運行中讓平臺在此目標以外的目標群中進行選擇,選擇的原則是決策最快(但不一定是距離最短的)能夠解決的目標。

圖5 攻擊對象分配和沖突消除的方法
3)運行結果
實驗運行了平臺從簡單到復雜(能力從單一到全部6 種)、攻擊對象從簡單到復雜(需要單一能力到需要全部6 種能力)的各情形,平臺和目標在不同分解度下的結果統計如表1。
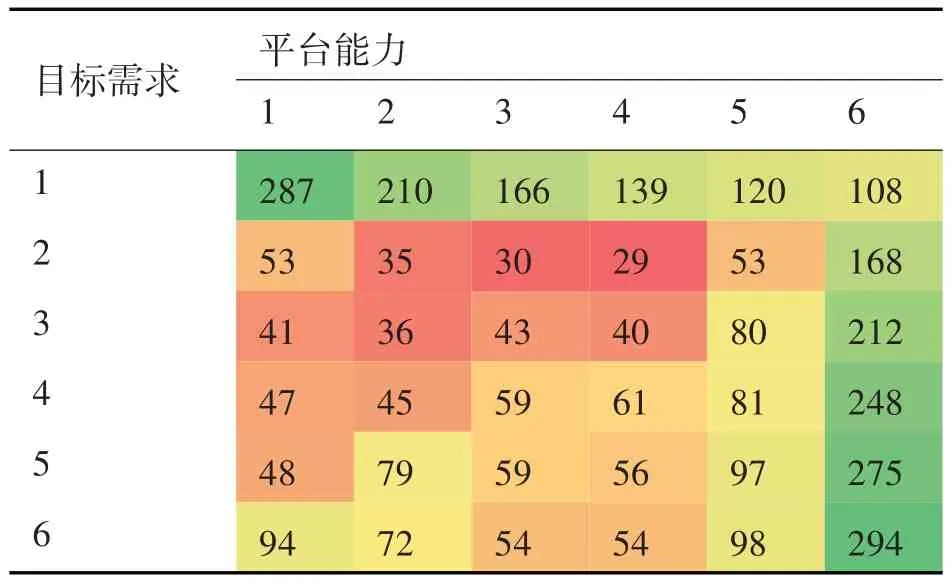
表1 不同馬賽克配置下模型的MoE
這一統計結果與蘭德公司對馬賽克戰仿真實驗結果不同,但從中得出的結論相似[6]。對于紅藍雙方的能力復雜度,呈現為表中的目標需求和平臺能力,在匹配情況不同時每分鐘產生的能力數MoE形成了一定的規律,紅色越深,效能越差;綠色越深,效能越好。
4 結論及分析
由表1可以看出:
1)按行看,目標需求為1,即目標完全馬賽克化時,平臺的作戰效能最好。
此時當平臺越復雜時,MoE 值越低,因為平臺越復雜,對于單個的目標,平臺能力浪費越多;當目標需求為6,即目標最復雜時,使用簡單的平臺或復雜的平臺效果較好,而平臺能力為3 或4 時效果較差。
2)按列看,平臺能力為6時,表現較好,因為此時平臺可以任意選擇目標,但是如果目標需求為1,則造成平臺能力的浪費,此時效率偏低;當平臺能力為1,即完全馬賽克化時,對簡單和復雜的目標表現較好(決策都更簡單),對于中間目標(需求為2,3,4,5)則表現較差。
3)當平臺能力為2,3,4,5時,對簡單的目標能取得較好的結果,對復雜的目標則結果較差。
綜上可得出,在知己知彼、使用恰當規則的前提下,智能化作戰體系的戰斗力會有好的表現,這些是體系中涌現新質戰斗力的必要條件。本實驗默認在作戰空間的理想態勢感知,在實踐中,通信、態勢感知是決策的前提,利用智能科技可以擴大戰場偵察感知的范圍[7],輔助態勢感知與態勢評估快速準確開展;規則的設計在本實驗中占據了很大比例,在復雜的戰場環境中還需更靈巧、更貼切的任務規則、任務分配和編組優化等設計。
5 結語
本實驗分析了雙方實力相當時的理想情況,通過MAS 抽象建模的方式,對典型決策中心戰進行了啟發式仿真實驗,結果表明分布作戰在一定情況下較傳統的平臺作戰具有優勢,但并不是所能力分解的情況都具有好的戰斗力,這與雙方平臺分解程度有很大的關聯。實驗結果推翻了當前分布式作戰具有絕對優勢的臆斷認知,人工智能與相關技術的融合發展將戰爭形態推向高級階段[8~9],制勝機理發生了一定變化[10]。可以得出,智能化指揮信息系統獲取決策優勢的前提是全維態勢感[11],要想讓決策中心戰發揮積極作用,須以智能賦能態勢感知、任務規劃和編排規則,營造決策優勢。從信息化作戰向智能化作戰的轉變過程中,智能裝備的發展須能接入體系殺傷網,且注重裝備互聯互通互操作功能,以便其功能隨時被調用,邊緣指控[12]、人機結合是發展的過程性選擇。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
發明與創新(2022年30期)2022-10-03 08:40:56
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
人大建設(2018年6期)2018-08-16 07:23:10
文理導航·科普童話(2017年5期)2018-02-10 19:42:14
發明與創新(2016年38期)2016-08-22 03:02:52
