基于圖像自適應(yīng)增強(qiáng)與特征融合的目標(biāo)檢測方法
2024-04-15 09:03:52朱海紅李思宇李林峰胡倫庭
測繪工程 2024年1期
于 璐,朱海紅,李思宇,李 霖,李林峰,胡倫庭,龍 雪
(1.武漢大學(xué) 資源與環(huán)境科學(xué)學(xué)院,武漢 430000; 2. 武漢海微科技有限公司, 武漢 430000; 3. 北京強(qiáng)度環(huán)境研究所, 北京 100000)
近年來隨著硬件的不斷迭代升級和深度學(xué)習(xí)技術(shù)的發(fā)展,目標(biāo)檢測算法被廣泛應(yīng)用于自動駕駛、智慧交通、人臉識別等各個領(lǐng)域[1]。目標(biāo)檢測算法可以根據(jù)采集圖像的特征,自動提取感興趣目標(biāo)的位置并識別出目標(biāo)類別,不需要過多的人工干預(yù)且占用空間小、方便部署,在測繪地理信息領(lǐng)域也有較為成熟的應(yīng)用[2],如攝影測量、遙感目標(biāo)檢測以及交通標(biāo)志和信號燈檢測等。
早期的深度學(xué)習(xí)神經(jīng)網(wǎng)絡(luò)模型大多應(yīng)用于圖像分類,通常需要借助其它算法才能同時完成目標(biāo)定位和分類識別任務(wù)。目標(biāo)檢測算法則將特征提取、目標(biāo)定位和分類任務(wù)都整合在了一個網(wǎng)絡(luò)中,省去了繁瑣復(fù)雜的特征設(shè)計(jì)過程,模型訓(xùn)練更加簡潔方便,在檢測與識別效果方面顯著優(yōu)于傳統(tǒng)的基于顏色、形狀等簡單特征的算法,檢測準(zhǔn)確度與速度也高于常用的手工特征算法。其中,以目標(biāo)的定位和分類是否同時進(jìn)行為區(qū)分標(biāo)準(zhǔn),目標(biāo)檢測算法被分為單階段網(wǎng)絡(luò)和兩階段網(wǎng)絡(luò)兩種類型。兩階段網(wǎng)絡(luò)以Faster R-CNN[3]為代表,先生成目標(biāo)所在候選區(qū)域,再獲取該區(qū)域特征圖用于判定目標(biāo)類別,這種方式的檢測精度較高,但相對于單階段網(wǎng)絡(luò)占用空間大、檢測速度慢。單階段網(wǎng)絡(luò)沒有用于生成候選框的階段,直接對目標(biāo)的位置和類別進(jìn)行回歸,節(jié)約計(jì)算成本并提高了檢測速度,常用的單階段網(wǎng)絡(luò)包括SSD[4](single shot multi-box detector)、YOLO[5](you only look once)系列等。
在目標(biāo)檢測算法中,網(wǎng)絡(luò)的不同層級包含的信息不盡相同,無論是單階段網(wǎng)絡(luò)還是兩階段網(wǎng)絡(luò),都依賴于深層的網(wǎng)絡(luò)結(jié)構(gòu)來提取高維語義信息。而在實(shí)際的目標(biāo)檢測應(yīng)用中,不同目標(biāo)的尺度變化較大,當(dāng)算法的網(wǎng)絡(luò)較深則易丟失淺層的細(xì)節(jié)特征信息,不利于小目標(biāo)檢測,因此常用的目標(biāo)檢測算法都存在對小目標(biāo)檢測能力不足的問題,從而引起了算法整體的檢測精度下降,對此許多學(xué)者對小目標(biāo)檢測困難的問題做出了不同方向的改進(jìn)。Yang等[6]在SSD算法中引入了空洞卷積和注意力殘差模塊,將低分辨率高語義特征層和高分辨率低語義特征層進(jìn)行融合,使得算法更注重底層特征,在應(yīng)用于微小目標(biāo)檢測時降低了18.01%的誤檢率和18.36%的漏檢率。Fu等[7]提出了DSSD(deconvolutional single shot detector)算法,在SSD算法的擴(kuò)展特征層后加入了反卷積模塊,通過自上而下的結(jié)構(gòu)實(shí)現(xiàn)了不同層特征的融合,除此之外還優(yōu)化了用于分類和定位的預(yù)測模塊。Li等[8]對YOLOv3算法的3個輸出層的有效感受野進(jìn)行分析,根據(jù)有效感受野分配候選框,并增加了上下文信息,顯著改善了小目標(biāo)的檢測困難問題。Zhao等[9]為提升航空遙感影像的小目標(biāo)檢測準(zhǔn)確率,構(gòu)建了并行高分辨率網(wǎng)絡(luò),將多個子網(wǎng)絡(luò)并行連接,對不同分辨率的特征層反復(fù)融合,增強(qiáng)了小目標(biāo)特征。
在不同環(huán)境下,采集圖像的質(zhì)量也會產(chǎn)生差異,進(jìn)而對提取目標(biāo)特征造成較大影響,因此除了改進(jìn)網(wǎng)絡(luò)結(jié)構(gòu)這一方法外,數(shù)據(jù)增強(qiáng)也是一種提高算法對各尺度目標(biāo)檢測能力的有效方法,通過各種圖像增強(qiáng)算法能夠提升圖像質(zhì)量并豐富監(jiān)督信息,從而獲取更可靠的特征空間[10]。這種方式不會占用太多內(nèi)存空間,不需要增加硬件成本,但可以有效提升檢測算法的準(zhǔn)確度和泛化能力[11]。Lv等[12]使用基于Retinex理論的圖像增強(qiáng)算法進(jìn)行原始低照度圖像的增強(qiáng), 聯(lián)合利用原始圖像與增強(qiáng)圖像之間特征差異性,設(shè)計(jì)了雙分支SSD結(jié)構(gòu)。Huan等[13]構(gòu)建基于雙邊濾波的高斯金字塔變換Retinex圖像增強(qiáng)算法融入模型,有效解決了在復(fù)雜場景下由于光照不均、事務(wù)遮擋下檢測精度差、實(shí)時性低的問題。
基于以上背景,文中提出了一種自適應(yīng)圖像增強(qiáng)、引入注意力機(jī)制的特征融合的改進(jìn)SSD算法。首先,根據(jù)圖像的全局特征預(yù)測圖像預(yù)處理算法的超參數(shù),實(shí)現(xiàn)檢測圖像的自適應(yīng)增強(qiáng),減輕由于檢測環(huán)境差異導(dǎo)致的采集圖像質(zhì)量不一,進(jìn)而引起的目標(biāo)特征丟失問題;其次,將特征提取的主干網(wǎng)絡(luò)替換為ResNet50,優(yōu)化特征金字塔結(jié)構(gòu),使其更適用于小目標(biāo)圖像的特征提取;最后,將特征金字塔中的淺層特征和深層信息進(jìn)行特征融合,并引入SENet結(jié)構(gòu)獲取通道間權(quán)重,用于抑制融合后的特征對于原有細(xì)節(jié)特征的干擾,實(shí)現(xiàn)了語義信息和細(xì)節(jié)信息的有效融合,提高了算法對于各尺度目標(biāo)的檢測性能。
1 算法介紹
1.1 SSD算法
SSD是一種單階段(one-stage)目標(biāo)檢測網(wǎng)絡(luò),在多尺度特征圖上以回歸的方式同時得到目標(biāo)的類別和位置。相較于位置回歸與類別預(yù)測需要分階段進(jìn)行的兩階段(two-stage)網(wǎng)絡(luò),SSD的速度更快、占用內(nèi)存更小。SSD算法框架如圖1所示,主要包含4個部分,即輸入(input)、主干網(wǎng)絡(luò)(backbone)、頸部(neck)和頭部(head)[14]。輸入部分用于訓(xùn)練圖像預(yù)處理與增強(qiáng),如隨機(jī)旋轉(zhuǎn)、裁剪和放大等;主干網(wǎng)絡(luò)用于提取圖像特征,SSD算法的主干網(wǎng)絡(luò)為修改后的VGG16[15]網(wǎng)絡(luò);頸部為特征金字塔即多尺度特征圖部分,將主干網(wǎng)絡(luò)提取出的特征通過一系列的額外卷積層構(gòu)建不同尺度的特征圖;在頭部對特征金字塔中各個特征圖的不同位置進(jìn)行密集抽樣,抽樣時采用不同的定位框尺度和長寬比,同時進(jìn)行物體分類和先驗(yàn)框(anchor box)的回歸。

圖1 SSD算法框架
文中主要對輸入、主干網(wǎng)絡(luò)和頸部3個部分進(jìn)行了改進(jìn)。輸入部分,在原有的隨機(jī)裁剪、旋轉(zhuǎn)、放大等操作的基礎(chǔ)上,增加了改善圖像亮度和細(xì)節(jié)特征的自適應(yīng)增強(qiáng)模塊。在主干部分,使用ResNet50網(wǎng)絡(luò)替換VGG16網(wǎng)絡(luò),提取更深層的信息用于分類。在頸部部分,加入了帶有注意力機(jī)制的特征融合模塊,在淺層特征圖中融合了上下文信息和深層的語義信息。
1.2 基于圖像自適應(yīng)增強(qiáng)的預(yù)處理方法
由于采集環(huán)境差異會對圖像造成不同程度的影響,因此在目標(biāo)檢測任務(wù)中圖像增強(qiáng)是一項(xiàng)重要環(huán)節(jié),可以通過圖像增強(qiáng)有目的的強(qiáng)調(diào)局部或整體特征,擴(kuò)大圖像中不同物體特征的區(qū)別,提高圖像質(zhì)量并豐富信息量[16]。除了對訓(xùn)練圖像進(jìn)行隨機(jī)裁剪、旋轉(zhuǎn)和縮放外,根據(jù)圖像本身的特征進(jìn)行針對性的圖像處理可以進(jìn)一步提高圖像的質(zhì)量。在本文算法中,選取改善圖像亮度和對比度的圖像增強(qiáng)算法,有助于改善灰度畸變現(xiàn)象,增強(qiáng)圖像細(xì)節(jié)特征,有利于擁有豐富細(xì)節(jié)特征的小目標(biāo)檢測。本文參考IA-YOLO[17]中的圖像自適應(yīng)增強(qiáng)框架,通過構(gòu)建一個弱監(jiān)督的CNN網(wǎng)絡(luò)來預(yù)測圖像增強(qiáng)模塊的超參數(shù),根據(jù)預(yù)測的超參數(shù)在可微圖像處理模塊對訓(xùn)練圖像進(jìn)行自適應(yīng)增強(qiáng),并根據(jù)檢測的損失值反向傳播來優(yōu)化這些參數(shù)。與常規(guī)圖像預(yù)處理方法不同的是,該方法并不局限于提高整幅圖像質(zhì)量,而是對提升模型檢測性能有用的特征進(jìn)行針對性增強(qiáng)。圖像自適應(yīng)增強(qiáng)模塊由兩部分組成,一個是CNN參數(shù)預(yù)測模塊(CNN predict module),一個是可微圖像處理模塊(DIP module),整體結(jié)構(gòu)如圖2所示。
用于預(yù)測參數(shù)的CNN網(wǎng)絡(luò)主要包括5個卷積層和兩個全連接層,每個卷積層包括一個步長為2的3×3卷積層和一個Leaky Relu層,最終全連接層輸出可微圖像處理模塊需要的超參數(shù)。CNN參數(shù)預(yù)測網(wǎng)絡(luò)是根據(jù)全局的圖像特征,例如色調(diào)、亮度等,去預(yù)測圖像濾波處理的參數(shù),將原本需要手動調(diào)整的超參數(shù),交給CNN網(wǎng)絡(luò)預(yù)測,并根據(jù)檢測的損失函數(shù)反向傳播從而不斷進(jìn)行優(yōu)化和學(xué)習(xí),使得圖像能夠自適應(yīng)地朝著有利于檢測的方向進(jìn)行增強(qiáng)。因此,該模塊只需要輸入下采樣后低分辨率的圖像,經(jīng)過一個簡單的CNN網(wǎng)絡(luò)即可得出預(yù)測參數(shù),并隨檢測的損失值不斷更新預(yù)測參數(shù)。
針對不同環(huán)境對采集圖像屬性的影響,在圖像增強(qiáng)算法上選取了能夠改善圖像整體亮度、對比度和色調(diào)的Gamma校正、對比度變換和白平衡的變換算法,以及增強(qiáng)圖像邊緣和細(xì)節(jié)特征的USM銳化算法,各個濾波器算法如表1所示。
其中,Pt為圖片的像素值;ri、gi和bi為各通道對應(yīng)位置的像素值;Gamma用于校正圖像的明暗;參數(shù)γ可以通過反向傳播不斷學(xué)習(xí),調(diào)整圖像的明暗。白平衡用于解決不同的光源條件下,同一個物體反射的光線有所差別的問題,通過三通道各個像素值乘以一個用于學(xué)習(xí)的參數(shù),來調(diào)整圖像的色彩比例。圖像的對比度是一幅圖像中最亮和最暗的像素值之間的反差大小,反差越大代表圖像對比度越大,反差越小代表圖像像素更接近、對比度越小。圖像銳化采用USM算法[18],這種銳化的方法就是對原圖像先做一個高斯模糊,然后用原來的圖像減去一個系數(shù)乘以高斯模糊之后的圖像,該方法可以去除一些細(xì)小的干擾細(xì)節(jié)和噪聲,比一般直接使用卷積銳化算子得到的圖像銳化結(jié)果更加真實(shí)可信。
1.3 特征提取網(wǎng)絡(luò)改進(jìn)
SSD算法采用的VGG16網(wǎng)絡(luò)雖然在增加CNN網(wǎng)絡(luò)深度方面做出了貢獻(xiàn),但當(dāng)網(wǎng)絡(luò)深度到達(dá)一定限度時,易出現(xiàn)梯度消失和退化現(xiàn)象。隨著網(wǎng)絡(luò)深度的不斷增大,用于非線性轉(zhuǎn)換的激活函數(shù)也不斷增多,高維信息更加離散,導(dǎo)致網(wǎng)絡(luò)難以實(shí)現(xiàn)恒等映射(identity mapping)。VGG16中采用的激活函數(shù)為ReLU非線性激活函數(shù),ReLU計(jì)算式如式(1)所示。
f(x)=max(0,x).
(1)
當(dāng)輸入值為負(fù)值的情況下輸出值被設(shè)置為0,代表當(dāng)前神經(jīng)元不會被激活,從而保證網(wǎng)絡(luò)中神經(jīng)元的稀疏激活性,加快網(wǎng)絡(luò)的收斂速度。但這種激活方式存在輸入與輸出的不可逆性,然而在網(wǎng)絡(luò)的低維空間中信息通常較為集中,ReLU激活函數(shù)會造成較多不可逆的信息損失,因此難以實(shí)現(xiàn)輸入與輸出的恒等映射,進(jìn)而導(dǎo)致網(wǎng)絡(luò)過深時出現(xiàn)退化現(xiàn)象。ResNet[19](deep residual network, ResNet)網(wǎng)絡(luò)通過引入殘差學(xué)習(xí)的方式,在網(wǎng)絡(luò)層間加入了如圖3 (a)所示的殘差模塊,將網(wǎng)絡(luò)的不同特征層進(jìn)行快捷連接(shortcut connection),使網(wǎng)絡(luò)深度達(dá)到成百上千層時仍然保持良好的分類效果。如圖3所示的殘差模塊,通過在不同層間加入快捷連接,將輸入x傳入輸出層中與之相加,輸出結(jié)果可用式(2)表示。

圖3 殘差模塊與BottleNeck結(jié)構(gòu)
H(x)=F(x)+x.
(2)
通過以上算式,可以將網(wǎng)絡(luò)轉(zhuǎn)化為學(xué)習(xí)殘差的過程,當(dāng)F(x)=0時,就構(gòu)成了恒等映射H(x)=x,使得網(wǎng)絡(luò)可以自主選擇跳過冗余層,并且減小了計(jì)算參數(shù)量。為進(jìn)一步獲取網(wǎng)絡(luò)深層信息、提升檢測效果,文中將特征提取網(wǎng)絡(luò)由VGG16替換為深度殘差網(wǎng)絡(luò)ResNet50,可以有效緩解隨深度增加帶來的退化現(xiàn)象,從而獲取到更深層的有助于分類的信息。ResNet50網(wǎng)絡(luò)主要包含4個部分,每部分分別包含3、4、6、3個BottleNeck結(jié)構(gòu)。BottleNeck結(jié)構(gòu)如圖3 (b)所示,遵守尺寸不變通道數(shù)不變、尺寸減半通道數(shù)翻倍[20]的設(shè)計(jì)原則,由兩個1×1步長為1的卷積層和一個3×3步長為2的卷積層以及殘差連接構(gòu)成,1×1的卷積層用于特征降維,3×3的卷積層用于提取深層特征。每個部分輸出的特征層記為{C1,C2,C3,C4},假設(shè)輸入的圖像大小為300×300,則每部分輸出的特征層尺寸分別為{75, 38, 19, 10}。
在SSD算法中使用的特征金字塔結(jié)構(gòu)主要用于提取不同尺度的特征,保障了算法對于多尺度目標(biāo)的檢測能力,但其中用于小目標(biāo)檢測的淺層特征僅有一層,缺乏足夠的細(xì)節(jié)特征表達(dá),因此SSD算法存在小目標(biāo)不敏感的缺陷。由于本文實(shí)驗(yàn)數(shù)據(jù)集中以中小目標(biāo)為主,且需要微小細(xì)節(jié)信息來判定目標(biāo)類別,因此文中選取ResNet50網(wǎng)絡(luò)輸出的淺層特征層C2作為特征金字塔的初始特征圖,并根據(jù)以下算式構(gòu)建特征金字塔。
Pi+1=F(f3×3(F(f1×1(Pi)))),
(3)
F(xi)=ReLU(BN(xi)).
(4)
其中,i∈{0, 1, 2, 3, 4},P0=C2,f3×3和f1×1分別為卷積核大小為3、1的卷積層,f3×3卷積層的步長為2。BN為批標(biāo)準(zhǔn)化處理(batch normalization),批標(biāo)準(zhǔn)化處理用于消除網(wǎng)絡(luò)訓(xùn)練過程中數(shù)據(jù)分布發(fā)生變化導(dǎo)致學(xué)習(xí)速度降低的問題[21]。ReLU表示ReLU激活函數(shù),可以緩解由于網(wǎng)絡(luò)過深產(chǎn)生的梯度消失現(xiàn)象。最終輸出特征圖集合表示為{P0,P1,P2,P3,P4,P5},特征圖尺寸分別為{38, 19, 10, 5, 3, 1}。
1.4 引入SENet的特征融合模塊
在特征金字塔輸出的特征圖中,特征隨網(wǎng)絡(luò)加深逐漸抽象[22],深層輸出的特征通常包含更豐富的語義信息,但同時也會丟失部分細(xì)節(jié)特征信息。因此,將淺層特征與深層特征以特定的方式融合,添加上下文信息,可以有效提高小目標(biāo)的檢測能力,文中參考FSSD算法[20]和文獻(xiàn)[23]中的特征融合結(jié)構(gòu),將淺層的特征與深層的語義信息進(jìn)行融合,使得用于小尺度目標(biāo)檢測和定位的淺層特征圖能夠同時包含細(xì)節(jié)和深層語義信息。特征融合結(jié)構(gòu)可以由以下算式表示。
Tf=Concat(f{Xp},f{Up{Xq}}),
(5)
f(xi)=ReLU(L2(xi)),
(6)
Up(xi)=ReLU(BN(f1×1(Bilinear(xi)))).
(7)
其中,Billinear表示雙線性插值法,對于與目標(biāo)尺寸不同的待融合特征圖,先通過1×1的卷積層降維后,使用雙線性插值法將尺寸較小的深層特征圖上采樣處理。f表示所有待融合特征圖通過L2正則化將數(shù)據(jù)歸一化至同一范圍內(nèi),便于后續(xù)的拼接。拼接方式選取串聯(lián)(concatenation)操作,將未經(jīng)上采樣的特征圖Xp和經(jīng)過插值后的特征圖Xq在通道維度拼接,再通過一個3×3的卷積層消除拼接后的混疊效應(yīng)。
由于直接融合的方式容易導(dǎo)致原有信息被干擾,可能會造成小尺度目標(biāo)信息的丟失,本文在特征融合模塊中引入SENet,使網(wǎng)絡(luò)在訓(xùn)練的過程中更專注于融合通道間有效的特征。SENet[24](squeeze and excitation) 結(jié)構(gòu)如圖4所示,是一種能夠?qū)矸e特征的通道間相互依賴關(guān)系進(jìn)行顯式建模的結(jié)構(gòu),輸入SENet的特征層首先通過一個全局平均池化層得到全局空間信息,再通過兩個全連接層和兩個激活函數(shù)對全局信息進(jìn)行壓縮再升維,最終獲取各個通道的權(quán)重并與對應(yīng)的特征圖相乘,從而獲取各通道間的關(guān)聯(lián)關(guān)系。將SENet插入到L2正則化和ReLU激活函數(shù)之后、串聯(lián)操作之前,獲取拼接前各通道的權(quán)重,以取得更有效的特征融合結(jié)果。

圖4 SENet結(jié)構(gòu)
文中采取了如圖5所示的特征融合結(jié)構(gòu),將特征金字塔輸出的P0與主干網(wǎng)絡(luò)輸出的C3融合,替換用于檢測與定位的尺寸為38的特征圖P0,記為T0;將P1與{C3,C4}融合替換尺寸為19的特征圖P1,記為T1。最終,用于定位和檢測的特征圖集合為{T0,T1,P2,P4,P5},特征圖尺寸分別為{38, 19, 10, 5, 3, 1},每層生成的候選框個數(shù)分別為{4, 6, 6, 4, 4},將特征圖尺寸與每層生成的候選框個數(shù)對應(yīng)相乘后,共輸出8 732個候選框。并將以上候選框進(jìn)行NMS篩選,NMS(non-maximum suppression)為非極大值抑制篩選,用于選取得分最高的候選框并抑制多余的候選框。
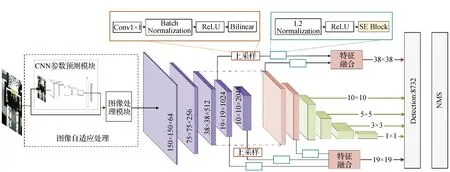
圖5 改進(jìn)SSD算法結(jié)構(gòu)
1.5 損失函數(shù)
SSD算法的損失函數(shù)主要包含兩部分,即置信度損失Lconf和定位損失Lloc,計(jì)算式如式(8)所示。
(8)
其中,N表示匹配的候選框個數(shù),當(dāng)N為0時損失值設(shè)置為0;α為權(quán)重系數(shù),當(dāng)交叉驗(yàn)證時設(shè)置為1;c為置信度得分,l表示候選框參數(shù),g為真實(shí)標(biāo)注框參數(shù)。
定位損失,是候選框與真實(shí)標(biāo)注框的SmoothL1損失。如式(9)所示:
(9)
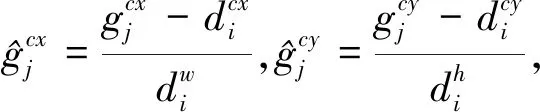
(10)

(11)
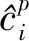
(12)
(13)
2 實(shí)驗(yàn)結(jié)果與分析
2.1 數(shù)據(jù)集
文中的實(shí)驗(yàn)數(shù)據(jù)集為以中小目標(biāo)為主的車載屏幕部件數(shù)據(jù)集,由部署在工業(yè)生產(chǎn)線的工業(yè)相機(jī)采集。數(shù)據(jù)集為未經(jīng)處理的車載屏幕背板圖像,類別包含導(dǎo)電泡棉正常、導(dǎo)熱泡棉正常、排線正常、排線缺失、排線歪斜、排線未扣緊和排線翻轉(zhuǎn)7個類別,圖6、圖7分別為車載屏幕背板圖像和各類別圖像。

圖6 車載屏幕部件數(shù)據(jù)集圖像

圖7 各類別圖像
文中提出的算法可以對采集圖像數(shù)據(jù)進(jìn)行自適應(yīng)的圖像增強(qiáng),為驗(yàn)證算法對采集圖像質(zhì)量差異的處理能力,數(shù)據(jù)集中包含的圖像是未經(jīng)過圖像增強(qiáng)處理的原始圖像。數(shù)據(jù)集共包括訓(xùn)練集數(shù)據(jù)2 251張,測試集數(shù)據(jù)214張,驗(yàn)證集數(shù)據(jù)563張,圖像分辨率為2 448像素×2 048像素,各類別具體數(shù)目如表2所示。

表2 訓(xùn)練集各檢測類別數(shù)目
通常測試集的劃分方式是從已標(biāo)注圖像中隨機(jī)劃分出一定比例數(shù)量的圖像作為測試集,但文中研究對象的檢測受環(huán)境光照影響較大,因此從已采集圖像中挑選了214張環(huán)境光照有差異的圖像來測試模型對光照條件的適應(yīng)能力。
2.2 模型訓(xùn)練信息與評價指標(biāo)
使用在ImageNet數(shù)據(jù)集[25]上預(yù)訓(xùn)練的ResNet50模型對主干網(wǎng)絡(luò)部分進(jìn)行預(yù)訓(xùn)練,將前50輪訓(xùn)練的主干網(wǎng)絡(luò)權(quán)重進(jìn)行凍結(jié),共迭代300輪。優(yōu)化器選擇SGD(stochastic gradient descent)優(yōu)化器,初始學(xué)習(xí)率定為0.002,學(xué)習(xí)率衰減采用余弦退火策略進(jìn)行周期性衰減。實(shí)驗(yàn)的操作系統(tǒng)為Windows,使用Pytorch1.5框架開發(fā),實(shí)驗(yàn)的硬件環(huán)境CPU為Intel i7-9700 CPU@3.00 GHz,內(nèi)存為16G,GPU為NVDIA GTX 1650 super。
評價指標(biāo)有平均精度和平均精度均值等[26],其中平均精度就是Precision-recall曲線下方的面積,按模型給出的置信度由高到低對候選框進(jìn)行排序,得到一組包含精度、召回率的有序數(shù)組。平均精度由以下算式得出:

(14)
平均精度均值(mAP)指所有類別平均精度(AP)的平均值。
(15)
其中,N為類別的總數(shù);AP(i)為各類別的平均精度。
2.3 消融實(shí)驗(yàn)
為驗(yàn)證各個模塊對于檢測精度提升的有效性,進(jìn)行了圖像自適應(yīng)增強(qiáng)模塊、特征融合模塊和注意力模塊的消融實(shí)驗(yàn)。在表3消融實(shí)驗(yàn)中,Feature_Fusion和Fusion指的是特征融合模塊,Fusion_Layers表示進(jìn)行特征融合的結(jié)構(gòu),即圖8中(a)、(b)結(jié)構(gòu),SE Block表示SENet結(jié)構(gòu)的注意力模塊,IADA指圖像自適應(yīng)增強(qiáng)模塊。從表3中的結(jié)果可以看出,各模塊都對檢測精度有一定的提升。其中特征融合模塊,在未加入注意力模塊前,結(jié)構(gòu)(a)相較于原始SSD算法提高了4.6%,高于結(jié)構(gòu)(b)的2.04%。說明結(jié)構(gòu)(b)的淺層特征加入了更深層的語義特征后,原有的細(xì)節(jié)特征被干擾。注意力機(jī)制可以使模型通過訓(xùn)練不斷調(diào)整特征融合后各通道的權(quán)重,選擇有利于模型檢測的信息,因此加入注意力模塊之后,結(jié)構(gòu)(b)提升了4.97%,高于結(jié)構(gòu)(a)。圖像自適應(yīng)增強(qiáng)模塊對于模型檢測性能也有較大幅度的提升,在主干網(wǎng)絡(luò)為VGG16和ResNet50的實(shí)驗(yàn)中,分別提升了4.05%和1.86%。最終,采用圖8(b)的特征融合結(jié)構(gòu),加入注意力模塊和圖像自適應(yīng)增強(qiáng)模塊后,模型的檢測精度得到較大幅度提升,相較于原始SSD算法提升了5.2%。

表3 消融實(shí)驗(yàn)

圖8 Fusion Layers 結(jié)構(gòu)
2.4 檢測結(jié)果對比與分析
2.4.1 檢測結(jié)果
文中算法能夠精準(zhǔn)地檢測出實(shí)驗(yàn)數(shù)據(jù)集中的中小目標(biāo)部件,并實(shí)現(xiàn)了較高的定位精度。在圖9的檢測結(jié)果示例中,為了驗(yàn)證模型在不同光照環(huán)境下的檢測性能,挑選了不同環(huán)境的檢測圖片,并與原SSD算法的檢測結(jié)果作對比。從圖10可以看出,在明暗度不同的環(huán)境下,SSD算法出現(xiàn)了漏檢和誤檢的現(xiàn)象,改進(jìn)后的SSD算法則可以在昏暗和明亮的情況下檢測出正確的類別并精準(zhǔn)定位。

圖9 檢測結(jié)果示例

圖10 不同光照條件下的檢測結(jié)果
2.4.2 改進(jìn)算法與其他算法對比結(jié)果
將不同的目標(biāo)檢測模型與文中改進(jìn)SSD算法作對比,實(shí)驗(yàn)結(jié)果如表4所示,其中Param代表參數(shù)量,即算法的參數(shù)所占內(nèi)存大小;FLOPs(floating point operations)表示浮點(diǎn)運(yùn)算次數(shù),表示每次檢測時運(yùn)行浮點(diǎn)操作的次數(shù),用于衡量算法的計(jì)算復(fù)雜度。文中算法相較于經(jīng)典目標(biāo)檢測網(wǎng)絡(luò)Faster R-CNN精度提升了7.25%,參數(shù)量與浮點(diǎn)運(yùn)算次數(shù)都大幅度降低。相比YOLO系列網(wǎng)絡(luò),文中算法在多尺度缺陷目標(biāo)的表現(xiàn)更好,在檢測精度上高于經(jīng)典的YOLO-v3和YOLO-v5網(wǎng)絡(luò)。在SSD系列網(wǎng)絡(luò)中,文中改進(jìn)算法較原始SSD算法精度提升了5.2%,同時也高于其他的改進(jìn)SSD網(wǎng)絡(luò)如DSSD、FSSD等,且參數(shù)量和計(jì)算量較小,適合在移動端進(jìn)行部署。
3 結(jié) 論
文中通過引入圖像自適應(yīng)增強(qiáng)和融入注意力機(jī)制的特征融合,提升了SSD算法的檢測能力,實(shí)現(xiàn)了對中小目標(biāo)準(zhǔn)確、有效的定位。改進(jìn)算法通過在圖像預(yù)處理階段加入自適應(yīng)圖像增強(qiáng)模塊,提升了在不同光照條件下算法的檢測性能,對于真實(shí)場景下的各種檢測環(huán)境具有良好的適應(yīng)性;通過引入SENet結(jié)構(gòu)的特征融合模塊有效提升了對小尺度目標(biāo)的檢測能力,從而實(shí)現(xiàn)對多種尺度目標(biāo)的精準(zhǔn)檢測。基于車載屏幕背板數(shù)據(jù)集的對比實(shí)驗(yàn)以及消融實(shí)驗(yàn)證明了改進(jìn)算法對中小目標(biāo)的檢測總體精度高于經(jīng)典的目標(biāo)檢測算法和部分常用的SSD改進(jìn)算法,且具有較低的內(nèi)存占用和計(jì)算復(fù)雜度,對于不同環(huán)境的適應(yīng)能力更強(qiáng),為解決目標(biāo)檢測算法的實(shí)際應(yīng)用中的難題提供了可行的改進(jìn)方式。
猜你喜歡
今日農(nóng)業(yè)(2021年19期)2022-01-12 06:16:36
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中老年保健(2021年11期)2021-08-22 03:15:44
中學(xué)生數(shù)理化(高中版.高考數(shù)學(xué))(2021年1期)2021-03-19 08:28:38
現(xiàn)代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
