基于圖像融合與深度學(xué)習(xí)的人臉表情識(shí)別
2024-03-23 07:31:04焦陽陽黃潤(rùn)才萬文桐
傳感器與微系統(tǒng) 2024年3期
焦陽陽,黃潤(rùn)才,萬文桐,張 雨
(上海工程技術(shù)大學(xué)電子電氣工程學(xué)院,上海 201600)
0 引 言
在面對(duì)面交流中,面部表情的變化往往反映了一個(gè)人內(nèi)心情感變化情況。隨著計(jì)算機(jī)技術(shù)的發(fā)展,人臉表情識(shí)別被廣泛運(yùn)用在智慧課堂、智能駕駛[1]、醫(yī)療保障等領(lǐng)域。
人臉表情識(shí)別可分為3個(gè)步驟:圖像預(yù)處理、特征提取與表情識(shí)別。特征提取是其中最關(guān)鍵的環(huán)節(jié),分為傳統(tǒng)特征提取和深度學(xué)習(xí)特征提取方法,傳統(tǒng)方法通過特征描述符來提取表情特征,深度學(xué)習(xí)特征提取方法是指使用卷積神經(jīng)網(wǎng)絡(luò)進(jìn)行特征提取。最近幾年大量研究人員投入了對(duì)表情識(shí)別的研究中,Chen J 等人[2]使用方向梯度直方圖(histogram of oriented gradient,HOG)提取人臉表情特征,然后使用支持向量機(jī)(support vector machine,SVM)進(jìn)行表情識(shí)別。Boughida A等人[3]使用Gabor濾波器進(jìn)行表情特征的提取。但傳統(tǒng)方法提取的信息單一,并且缺乏高級(jí)語義信息,不能很好地滿足人臉表情識(shí)別任務(wù)。
因此眾多研究人員開始嘗試使用深度學(xué)習(xí)方法來提取特征。馮楊等人[4]采用小尺度卷積核提取面部表情特征,提高了表情識(shí)別的準(zhǔn)確率。Zhang S等人[5]設(shè)計(jì)了一種混合深度分離殘差網(wǎng)絡(luò)用于表情特征提取。但深度學(xué)習(xí)無法利用圖像的局部特征信息,并且無法區(qū)分表情圖像中重要的部分。因此,張翔等人[6]通過在神經(jīng)網(wǎng)絡(luò)中加入注意力模塊來提高表情識(shí)別準(zhǔn)確率。Wang H等人[7]使用MO-HOG與深度學(xué)習(xí)特征進(jìn)行融合。
針對(duì)上文中提到的單一特征描述符提取信息有限,而深度學(xué)習(xí)無法關(guān)注有效圖像信息等問題,本文提出了一種基于圖像融合與深度學(xué)習(xí)的表情識(shí)別方法,對(duì)不同紋理特征圖像進(jìn)行融合,隨后構(gòu)建改進(jìn)后的神經(jīng)網(wǎng)絡(luò)模型,將融合后的圖像輸入模型中進(jìn)行高級(jí)特征提取,最后使用SoftMax進(jìn)行表情分類。
1 人臉表情識(shí)別模型
本文提出的人臉表情識(shí)別模型流程:首先對(duì)圖像進(jìn)行預(yù)處理,隨后使用局部二值與差分激勵(lì)算子分別提取局部二值模式(local binary pattern,LBP)與韋伯局部描述符(Weber local descriptor,WLD)圖像,差分激勵(lì)描述了圖像的局部強(qiáng)度信息,但忽略了邊緣的方向信息,而局部二值描述了圖像的邊緣方向信息,卻忽略了強(qiáng)度信息。將兩種圖像進(jìn)行融合得到新的圖像作為神經(jīng)網(wǎng)絡(luò)的輸入圖像。下一步構(gòu)建改進(jìn)后的殘差神經(jīng)網(wǎng)絡(luò)(residual neural network,Res-Net),加入改進(jìn)后的注意力機(jī)制與空洞卷積,使模型在擴(kuò)大感受野的同時(shí)關(guān)注到有用的信息,減少對(duì)無用特征的關(guān)注,最后對(duì)表情進(jìn)行識(shí)別。
2 表情識(shí)別模型具體設(shè)計(jì)
2.1 圖像預(yù)處理
在原始圖像中存在著許多對(duì)表情特征提取無關(guān)的信息,因此需要對(duì)表情圖像進(jìn)行預(yù)處理,包括人臉檢測(cè)、灰度及尺寸歸一化等。首先檢測(cè)并裁剪出人臉部位,然后將三通道三原色(RGB)圖像轉(zhuǎn)換為灰度圖,統(tǒng)一縮放成相同規(guī)格的尺寸大小,得到模型所需要的輸入圖像。
2.2 圖像融合
2.2.1 LBP特征
LBP算子由Ojala 等人在1994 年提出,被廣泛運(yùn)用于人臉識(shí)別等領(lǐng)域。原始的LBP 算子計(jì)算中心像素與周圍8個(gè)像素之間的關(guān)系,從中心像素的左上角位置開始,依次將鄰域像素與中心像素進(jìn)行比較,小于取0,大于取1。最后得到8個(gè)二進(jìn)制數(shù),將其按照順時(shí)針的順序排列,轉(zhuǎn)換為一個(gè)十進(jìn)制數(shù),就得到了該中心像素的LBP值
其中,(xc,yc)為中心像素,p為鄰域點(diǎn)的個(gè)數(shù),ip為相鄰像素灰度值,ic為中心像素灰度值,s為符號(hào)函數(shù)
2.2.2 WLD特征
WLD 特征是根據(jù)韋伯定律所提出的一種紋理特征描述符[8]。韋伯定律是反映心理量和物理量之間關(guān)系的定律,它表明能夠引起感覺差異的差別閾值與原始刺激的強(qiáng)度之比是一個(gè)常量,即
式中k為常量,ΔI為差別閾值,I為原始刺激的強(qiáng)度。WLD包含2 個(gè)算子:差分激勵(lì)算子和方向算子,方向算子通過計(jì)算中心像素垂直與水平像素差之比得到方向信息,本文僅使用差分激勵(lì)算子。差分激勵(lì)描述了窗口內(nèi)圖像像素的強(qiáng)度變化,通過計(jì)算中心像素與周圍8 個(gè)點(diǎn)的像素差值和,將和與中心像素點(diǎn)灰度值進(jìn)行比值計(jì)算,再利用反正切變換將比值映射到(π/2,-π/2)之間,其計(jì)算公式為
式中xc為中心像素值,xi為鄰域像素值,P為鄰域像素點(diǎn)個(gè)數(shù)。
2.2.3 圖像融合
WLD中的差分激勵(lì)算子描述了圖像的局部強(qiáng)度信息變化,但其原始方向算子計(jì)算比較簡(jiǎn)單,故使用局部二值算子計(jì)算圖像的方向信息。通過設(shè)置加權(quán)融合系數(shù)α,根據(jù)式(5)得到融合后的圖像
式中XL為L(zhǎng)BP圖像,Xw為WLD圖像,X為融合后圖像。
2.3 改進(jìn)ResNet
本文以ResNet18 為骨干網(wǎng)絡(luò)進(jìn)行神經(jīng)網(wǎng)絡(luò)模型的搭建,通過將前2個(gè)Block的卷積核替換為空洞卷積,擴(kuò)大感受野范圍。并在殘差結(jié)構(gòu)中加入改進(jìn)后的注意力機(jī)制,有效提高特征的表征能力。
2.3.1 Dil-Block模塊
原始的ResNet18是以殘差塊構(gòu)成的神經(jīng)網(wǎng)絡(luò),殘差塊的原理為輸入特征圖通過兩個(gè)卷積層進(jìn)行特征提取,最后與輸入特征進(jìn)行相加,得到輸出。其中的卷積核大小均為3 ×3,但由于前后特征圖尺寸均不同,因此需要對(duì)前面殘差塊擴(kuò)大卷積核的采樣范圍,使模型獲得更大的感受野。本文將前2個(gè)殘差塊的卷積核替換為空洞卷積。空洞卷積在與傳統(tǒng)卷積一樣的計(jì)算量情況下,可以擴(kuò)大感受野的范圍。圖1為Dil-Block的示意,輸入特征圖首先經(jīng)過2 個(gè)空洞卷積層進(jìn)行特征提取,然后經(jīng)過注意力層提取注意力,再與輸入特征圖進(jìn)行相加,最后通過ReLU 激活函數(shù)得到輸出特征。

圖1 Dil-Block示意
2.3.2 改進(jìn)注意力模塊
在Dil-Block中添加注意力模塊,旨在加強(qiáng)重要特征的權(quán)重。Wang Q等人[9]提出了ECA-Net注意力模塊,使用一維卷積進(jìn)行注意力權(quán)重的提取。ECA-Net 在進(jìn)行通道注意力的提取時(shí),僅使用全局平均池化,本文使用2 種不同池化方式來計(jì)算通道注意力。ECA-Net 僅計(jì)算了通道注意力,本文則在通道注意力后添加空間注意力的計(jì)算,得到完整的注意力權(quán)重,圖2為改進(jìn)注意力示意。

圖2 改進(jìn)注意力示意
圖2 中的通道注意力部分將輸入按照空間方向進(jìn)行全局平均與最大池化,然后分別使用卷積核大小為k的一維卷積來計(jì)算相鄰?fù)ǖ乐g的相關(guān)性。k決定了通道之間交互的范圍,本文采用以下公式計(jì)算k的大小
式中c為通道數(shù)量,Odd 為選擇最近的奇數(shù),γ和b分別設(shè)置為2和1。將2個(gè)注意力矩陣相加并通過Sigmoid函數(shù)得到注意力權(quán)重,與輸入圖像進(jìn)行相乘,得到通道注意力特征圖,接著按照通道方向進(jìn)行全局平均和最大池化,得到一個(gè)二維特征圖,使用7 ×7的二維卷積進(jìn)行空間注意力的提取,最后通過Sigmoid 函數(shù)與特征圖相乘得到最終的特征圖。
2.4 表情分類
將上文中進(jìn)行融合后的圖像輸入到改進(jìn)后的神經(jīng)網(wǎng)絡(luò)中,經(jīng)過一系列殘差塊的特征提取后得到最終的特征向量,再經(jīng)過全連接層后通過SoftMax 進(jìn)行表情分類。在本文模型訓(xùn)練過程中,使用了交叉熵?fù)p失函數(shù)作為優(yōu)化函數(shù)
式中為真實(shí)值,為預(yù)測(cè)值,N為樣本數(shù)。通過反向傳播不斷降低損失值來更新神經(jīng)網(wǎng)絡(luò)的權(quán)重參數(shù),提高模型預(yù)測(cè)的準(zhǔn)確率。
3 實(shí)驗(yàn)與結(jié)果分析
模型由Pytorch框架搭建,操作系統(tǒng)為Ubuntu 18.04,硬件配置如下:CPU 為Xeon?E5-2678,GPU 為NVIDIA Tesla K80,內(nèi)存為8 GB。Python 版本為3.8,其中神經(jīng)網(wǎng)絡(luò)參數(shù)設(shè)置如下:優(yōu)化器使用Adam,batch_size 為64,epoch 設(shè)置為20。
3.1 實(shí)驗(yàn)數(shù)據(jù)集
實(shí)驗(yàn)使用JAFFE和CK +數(shù)據(jù)集。由于2 個(gè)數(shù)據(jù)集中樣本數(shù)據(jù)均較少,采用仿射變換的方式來進(jìn)行數(shù)據(jù)增強(qiáng)。JAFFE數(shù)據(jù)集經(jīng)過擴(kuò)充后為4 540 張樣本,CK +數(shù)據(jù)集為6 564張樣本,并將兩者按照9∶1 的比例劃分出訓(xùn)練集和測(cè)試集。
3.2 融合系數(shù)α實(shí)驗(yàn)
在進(jìn)行圖像融合時(shí),使用系數(shù)α進(jìn)行融合比例的控制,分別選用不同的融合系數(shù)進(jìn)行實(shí)驗(yàn)。圖3為實(shí)驗(yàn)結(jié)果。
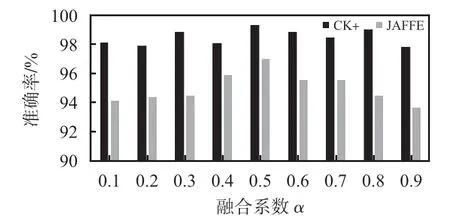
圖3 融合系數(shù)α結(jié)果
從圖3中可以看出,當(dāng)融合系數(shù)取0.5 時(shí),識(shí)別準(zhǔn)確率最高,證明此時(shí)的融合圖像既包含局部強(qiáng)度信息也包含方向信息。因此,本文后續(xù)實(shí)驗(yàn)均將融合系數(shù)設(shè)置為0.5。
3.3 消融實(shí)驗(yàn)
為了驗(yàn)證本文提出的表情識(shí)別模型的有效性,進(jìn)行了模型消融實(shí)驗(yàn),共設(shè)置了4 組對(duì)照實(shí)驗(yàn)。實(shí)驗(yàn)一的輸入圖像為L(zhǎng)BP圖像;實(shí)驗(yàn)二的輸入圖像為WLD圖像;實(shí)驗(yàn)三的輸入圖像為融合圖像,但將模型的前2個(gè)Block換為原始卷積核;實(shí)驗(yàn)四則將注意力機(jī)制去除。分別在JAFFE與CK +數(shù)據(jù)集上進(jìn)行實(shí)驗(yàn),與本文模型進(jìn)行對(duì)比。消融實(shí)驗(yàn)結(jié)果如表1所示。

表1 消融實(shí)驗(yàn)結(jié)果%
從表1中的實(shí)驗(yàn)一與實(shí)驗(yàn)二的結(jié)果可以看出,2個(gè)數(shù)據(jù)集的準(zhǔn)確率均不高,證明單個(gè)紋理特征所包含的信息有限。實(shí)驗(yàn)三的結(jié)果表示,對(duì)ResNet18 中的前2 個(gè)Block 進(jìn)行卷積核的替換,有效增加了感受野的范圍,使得模型能夠在前期關(guān)注到更多的信息。在實(shí)驗(yàn)四中,添加注意力后,2 個(gè)數(shù)據(jù)集的準(zhǔn)確率有了3%的提升,證明了注意力機(jī)制能有效提高模型對(duì)于重要特征的關(guān)注。
3.4 注意力對(duì)比實(shí)驗(yàn)
本文對(duì)ECA注意力機(jī)制進(jìn)行了改進(jìn)。為了驗(yàn)證改進(jìn)注意力機(jī)制的有效性,與其他注意力算法進(jìn)行對(duì)比,分別設(shè)置3組對(duì)照實(shí)驗(yàn),第一組使用SE-Net,第二組使用CBAM注意力,第三組使用ECA-Net,最后為本文模型。實(shí)驗(yàn)結(jié)果如表2所示。

表2 注意力對(duì)比實(shí)驗(yàn)結(jié)果%
從表2中可知,本文模型取得了最高的識(shí)別準(zhǔn)確率,分別為97.0%與99.3%。SE-Net使用全連接層來提取注意力權(quán)重,ECA-Net通過一維卷積進(jìn)行通道注意力的提取,CBAM則對(duì)通道與空間注意力均進(jìn)行了計(jì)算,通道注意力采用了與SE-Net相似的結(jié)構(gòu),空間注意力使用二維卷積進(jìn)行計(jì)算。本文提出的改進(jìn)注意力算法對(duì)上述算法的缺點(diǎn)進(jìn)行了改進(jìn),使模型能夠?qū)⒆⒁饬Ψ诺綄?duì)表情識(shí)別有用的特征上。
3.5 與其他算法對(duì)比
表3為本文提出的方法與其他主流表情識(shí)別算法的識(shí)別率對(duì)比。通過表3 可知,無論傳統(tǒng)方法還是深度學(xué)習(xí)方法,本文均取得了最高的識(shí)別準(zhǔn)確率,證明了本文方法的有效性。

表3 本文算法與其他算法識(shí)別率對(duì)比%
4 結(jié)束語
本文提出了一種基于紋理圖像融合與改進(jìn)ResNet的人臉表情識(shí)別算法。通過WLD與LBP圖像融合的方式進(jìn)行局部紋理特征的融合,彌補(bǔ)了單一紋理特征無法有效表達(dá)圖像信息的不足。同時(shí)對(duì)ResNet 進(jìn)行改進(jìn),通過空洞卷積解決了感受野較小的問題,改進(jìn)后的注意力模塊則有利于模型關(guān)注重要特征。將融合后的圖像輸入到改進(jìn)后的神經(jīng)網(wǎng)絡(luò)中進(jìn)行表情識(shí)別,在JAFFE 與CK +數(shù)據(jù)集上進(jìn)行驗(yàn)證,取得了不錯(cuò)的識(shí)別率。但模型對(duì)某些表情的識(shí)別率較低,后續(xù)將繼續(xù)研究如何改進(jìn)部分表情的識(shí)別率。
猜你喜歡
今日農(nóng)業(yè)(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學(xué)生數(shù)理化(高中版.高考數(shù)學(xué))(2021年1期)2021-03-19 08:28:38
現(xiàn)代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
中國(guó)生物醫(yī)學(xué)工程學(xué)報(bào)(2017年6期)2017-02-10 05:11:45
噪聲與振動(dòng)控制(2015年4期)2015-01-01 07:08:21
