高效的一次性弱間隙序列模式挖掘算法
2024-03-21 08:15:38楊鴻茜武優西耿萌劉靖宇李艷
計算機工程 2024年3期
楊鴻茜,武優西*,耿萌,劉靖宇,李艷
(1.河北工業大學人工智能與數據科學學院,天津 300401;2.河北工業大學經濟管理學院,天津 300401)
0 引言
隨著大數據的發展和應用,如何高效地挖掘出數據背后的潛在信息并將這些信息整合利用到更深層次的研究中變得尤為重要。序列模式挖掘(SPM)[1-2]作為數據挖掘[3-4]領域的一個重要子課題,被廣泛應用于脫氧核糖核酸(DNA)檢測[5-6]、生物遺傳學[7-8]、文本檢索[8-9]、股票預測[9-10]等領域。
傳統的SPM 方法[11-12]只考慮模式在序列中是否出現,而忽略了模式的重復性。因此,為了更加靈活地應對用戶的挖掘需求,發現更有價值的模式,帶間隙約束的可重復SPM 方法應運而生。根據模式的出現形式可以將其分為4 種情況,即無特殊條件[13]、無重疊條件[14-15]、不相交條件[16-17]和一次性條件[18-19]。其中,一次性條件[20-21]是指序列中的任何項目只能被模式匹配一次,這種約束條件既規避了結果集爆炸的問題,又盡可能地避免遺漏重要的信息。
在傳統的間隙約束序列模式挖掘中,模式的每一項都被認為具有相同意義,這與實際情況是不符的。比如,商人會更關注高利潤的商品,股民會更關注波動較大的股票市場信息。因此,弱間隙約束的概念被提出并用于序列模式挖掘領域,即僅挖掘那些用戶更感興趣的項,而忽略其他不重要的項。文獻[22]提出了一次性弱間隙強模式挖掘(OWSP-Miner)算法,可以實現在單項序列中挖掘一次性自適應弱間隙強模式。
但是上述算法只能在一種特殊序列中進行挖掘,即單項序列。實際生活中的通用序列由若干項集組成,每個項集都包含許多有序的項,即項集序列。在項集序列中研究此問題更有價值和實用性。本文提出一次性弱間隙序列模式挖掘(OWP)算法,該算法在更具通用性的項集序列上高效挖掘一次性弱間隙強模式。首先區別于單項序列上的一次性定義,重新定義一次性條件以適用于項集序列的情況,在支持度計算方面,提出SupII 算法,采用倒排索引的數據結構避免重復掃描數據庫,提高算法的匹配效率。然后在候選模式生成部分,采用模式連接策略,減少冗余候選模式數量。
1 相關工作
自序列模式挖掘的概念被提出以來,其廣泛應用于大數據挖掘、文本分析、生物信息學等諸多領域[23-24]。近年來,由于帶間隙[25]的模式更具靈活性并且能夠考慮模式在序列上的重復性,相關研究的重點不斷向間隙約束序列模式挖掘靠攏。文獻[26]提出一種有效的方法來挖掘具有間隙約束的完整閉合序列模式;文獻[27]提出基于通配符約束的生物序列模式挖掘算法,使用單向掃描和雙向掃描相結合的方式在生物序列中挖掘帶有通配符的頻繁模式;文獻[28]提出一個挖掘框架,可以在物聯網設備產生的不確定數據集中挖掘潛在的高平均效用模式;文獻[29]將具有特定間隙數的序列模式挖掘方法應用于DNA 序列。
然而,在上述算法中,所使用的數據集的每一項都被認為是具有相同意義的。而在實際應用中,用戶對于不同的項目感興趣程度也是不同的。因此,文獻[30]提出一種基于弱間隙的模式挖掘算法,根據影響程度將項目集劃分為強項集合和弱項集合,僅挖掘那些用戶更感興趣的強模式。雖然該算法的效率很高,但它沒有關注到序列項目使用的重復性,并且可能造成結果集爆炸的問題。為了避免該問題,文獻[22]提出OWSP-Miner 算法,該算法挖掘一次性條件下自適應弱間隙強模式,一次性條件既可以有效減少冗余模式的產生,又充分考慮到了模式在序列上的重復性。
然而,OWSP-Miner 只能在單項序列上進行挖掘,并不適用于通用的項集序列。因此,本文提出OWP 算法來挖掘頻繁的一次性弱間隙強模式。
2 相關定義
定義1(序列數據庫)序列數據庫是一個包含k條序列的集合,表示為D={s1,s2,…,s}k。T={t1,t2,…,t}c是數據庫D中所有項的集合,其中,c是T的大小。D中的每條序列都是一個包含若干個項集的列表,表示為si=si1,si2,…,sin,其中,n為序列si的大小,表示為size(si)=n。每個項集sij都是集合T的一個有序子集,用lij=len(si)j表示項集的長度,序列的長度是它所包含項集長度的總和,即
定義2(強項集合和弱項集合)所有的項根據用戶感興趣程度分為強項集合(τ)和弱項集合(ω),并且τ∩ω=?,τ∪ω=T。
例1給定一個項集序列數據庫D如表1 所示,其 中,s1=(bc)(bef)(abce)(abd)(abd)(cf)(adf),可知,T={a,b,c,d,e,f},size(s1)=7,len(s1)=20。如果強項集合為τ={a,b,d,e},那么弱項集合就為ω={c,f}。

表1 項集序列數據庫DTable 1 Itemset sequence dataset D
定義3(弱間隙強模式)大小為r的弱間隙強模式可表示為p=p1*p2*…*pr,其中,pi?τ(1 ≤i≤r),*表示任意數量的弱項集。
定義4(出現和一次性出現)給定序列s=s1,s2,…,sn和一個模式p=p1*p2*…*pr。如果存在r個整數o=
定義5(支持度)弱間隙強模式p在序列si上滿足一次性條件的出現次數就稱作模式p在序列si上的支持度,表示為sup(p,si)。模式p在序列數據庫D上的支持度是模式p在D中各條序列上的支持度之和,即
例2給定序列s1=(bc)(bef)(abce)(abd)(abd)(cf)(adf)和一個弱間隙強模式p=(b)*(b)*(ad)。如果忽略弱間隙約束,那么因為p1=(b)?s1=(bc),p2=(b)?s2=(bef),p3=(ad)?s4=(abd),則<1,2,4>是模式p在s1上的一個出現。然而,當τ={a,b,d,e},ω={c,f}時,<1,2,4>就不是一個出現,因為s3=(abce)中存在強項,所以<1,2,4>不滿足弱間隙約束。顯然,<2,3,4>、<3,4,5>和<4,5,7>是模式p滿足弱間隙約束的全部出現。其中,<2,3,4>和<3,4,5>不滿足一次性條件,因為p1∩p2=b≠?并且索引3 在兩次出現中被重復使用,即項集(abce)中的項'b'在出現<2,3,4>中與p2匹配,在出現<3,4,5>中又重復與p1匹配。盡管<2,3,4>和<4,5,7>也重復使用了s4,但是在<2,3,4>中,使用的是s4=(abd)中的項'd',而在出現<4,5,7>中,使用的是s4=(abd)中的項'b',因此它們是滿足一次性條件的兩個出現。綜上所述,一次性弱間隙條件下p的所有出現為<2,3,4>和<4,5,7>,即p在序列s1上的支持度為sup(p,s1)=2。同理,sup(p,s2)=1,sup(p,s3)=0。根據定義5,模式p在序列數據庫D中的支持度為
定義6(頻繁模式)給定一個最小支持度閾值minsup,如果一個弱間隙強模式p在序列數據庫D上的支持度不小于minsup,那么模式p就被稱為一個頻繁的一次性弱間隙強模式。
例3在例2 中,若給定minsup 為3,則模式p=(b)*(b)*(ad)是一個頻繁的一次性弱間隙強模式,因為其在表1 所示的項集序列數據庫中的支持度sup(p,D)=3≥minsup。
定義7(一次性弱間隙序列模式挖掘)給定項集序列數據庫D、弱項集合和最小支持度閾值minsup,一次性弱間隙序列模式挖掘的研究目標是挖掘序列數據庫D中所有頻繁的一次性弱間隙強模式。
3 算法描述
3.1 準備階段
為了在后續計算支持度的過程中減少對原始數據的遍歷次數以及無用候選模式的生成,準備階段主要有2 個步驟:創建倒排索引和剪枝不頻繁的項以獲得1 長度的頻繁模式集合。
步驟1掃描序列數據庫以獲得所有項的集合,并為每個序列創建各自的倒排索引。
定義8(倒排索引)對包含k條序列的序列數據庫D,創建k個倒排索引I={i1,i2,…,ik}。倒排索引ij對應序列sj,如果sj有h個不同的項,那么倒排索引ij={k1∶v1,k2∶v2,…,kh∶vh},其中,鍵k(a1≤a≤h)存儲的是項,而值va存儲的是項ka出現位置的列表。
例4給定序列s1=s1s2s3s4s5s6s7=(bc)(bef)(abce)(abd)(abd)(cf)(adf)。以 項'a'為 例,不難發 現'a'出現在序列中的第3 個項集、第4 個項集、第5 個項集以及第7 個項集中,因此,項'a'的倒排索引為[3,4,5,7]。同理,可以得到該序列相應的倒排索引為:i1={'a':[3,4,5,7],'b':[1,2,3,4,5],'c':[1,3,6],'d':[4,5,7],'e':[2,3],'f':[2,6,7]}。
步驟2依次計算每個強項的支持度,如果該項的支持度小于minsup,則對其進行剪枝。此外,剪枝所有弱項,因為弱間隙約束規定弱項只允許出現在間隙中,而不可以構成模式。
例5在例4 中,假設在s1中挖掘1 長度的頻繁模式,若minsup 為3,τ={a,b,d,e},ω={c,f},則強項'e'被剪枝,因為它的支持度為2。盡管項'c'和'f'的支持度都為3,但它們依然要被剪枝,因為它們是弱項。
3.2 支持度計算
在第3.1 節中,通過創建倒排索引和剪枝得到了長度為1 的頻繁模式集合。關鍵問題是計算長度為m(m≥2)的模式p在序列s中的支持度。基于模式中各項的出現位置,提出SupII算法來計算長度為m(m≥2)的模式的支持度。SupII 算法主要分為5 個步驟。
步驟1給定長度為m(m≥2)的模式p=e1,e2,…,ej,…,em(1≤j≤m,ej?τ)。首先為模式p所使用的倒排索引創建m層節點。
例6給定一 個弱間 隙強模式p=(b)*(b)*(ad),由例4 可知,模式p中包含的項'a'、'b'和'd'的倒排索引分別為'a':[3,4,5,7]、'b':[1,2,3,4,5]、'd':[4,5,7],則創建4 層節點如圖1 所示。
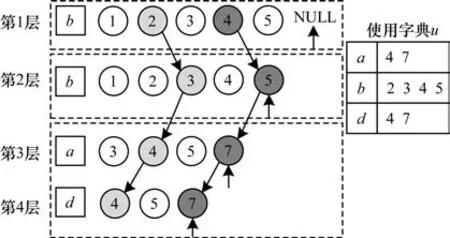
圖1 模式p 在序列s1中的所有出現Fig.1 The supports pattern p in sequence s1
步驟2為了保證一次性條件,創建并初始化使用字典u以記錄不同項被使用過的位置。使用字典中的每個元素都由兩個部分組成:鍵和值。鍵存儲項,值存儲對應項被使用過的位置索引。
比如,當計算模式p=(b)*(b)*(ad)的支持度時,初始化使用字典u為{'a':[],'b':[],'d':[]}。
步驟3按照p=e1,e2,…,ej,…,em(1≤j≤m,ej?τ)從左往右的順序,從第1 層的每一個未被使用過的位置開始,自上而下尋找模式p所有滿足一次性弱間隙約束的出現。對于所有的eu…e(v1≤u≤v≤m)可分為以下2 種情況:
1)若eu…ev在同一個項集內,則對于所有的ej(u≤j≤v),出現位置相同。
2)若eu…ev在不同項集內,則根據項集的先后順序,出現位置也保持相應的先后順序,并且不同項集間滿足弱間隙約束。
例如,在圖1 中,1 是第1 層中第1 個沒有被使用過的位置,于是在第2 層中尋找大于1 且未被使用過的位置,即2。繼續在第3 層尋找大于2 且未被使用過的位置,得到位置3。但是,在同一個項集內的第4 層中沒有找到位置3。因此,位置3 被舍棄,回溯到第3 層的下一個位置4。然而,在位置2、4 中,即s2和s4之間存在強項s3=(abce),不滿足弱間隙約束,因此,需要回溯到第2 層,尋找第2 層中下一個未被使用的位置3。此時,位置1、3 也不滿足弱間隙約束,于是繼續回溯到第1 層找到下一個位置2。按照同樣的方法向下迭代,可以找到模式p的一次出現<2>、<3>、<4,4>,即<2,3,4>。
步驟4得到模式p的一次出現后,需要在使用字典u中更新當前已使用過的位置。
例如,在獲得模式p的第1 個出現<2,3,4>后,更新使用字典為u={'a':[4],'b':[2,3],'d':[4]},因為(b)、(b)和(ad)分別對應<2>、<3>、<4,4>。
步驟5重復步驟3 和步驟4,直到任一倒排索引指向NULL。
繼續計算模式p的支持度,當獲得第1 層的下一個位置3 時,因為3 已經存在于使用字典u中,即'b':[2,3],所以不滿足一次性條件,因此,選擇下一個位置4。重復上述步驟,可以得到模式p在s1中的第2 次出現<4>、<5>、<7,7>,即<4,5,7>。同時,更新使 用字典為u={'a':[3,7],'b':[2,3,4,5],'d':[4,7]}。當尋找下一個出現時,第1 層的倒排索引指向NULL,算法結束。
SupII 算法的偽代碼如算法1 所示。
算法1SupII 算法
3.3 候選模式生成
傳統的序列模式挖掘方法通常采用I-Connection和S-Connection 來生成候選模式,這種方法的本質是枚舉策略,雖然可以避免遺漏有希望的候選模式,但同時也會產生大量冗余的模式而極大地增加運行時間。為了解決這個問題,本文采用模式連接策略來生成候選模式。
定義9(前綴和后綴模式,子模式和超模式)如果一個長度為m的模式p=e1,e2,…,em,那么模式r=e1,e2,…,em-1和q=e2,e3,…,em分別為模式p的前綴和后綴,表示為r=prefix(p)和q=suffer(p)。此外,模式r和q被稱為模式p的子模式,模式p又被稱為模式r和q的超模式。
定義10(I-Join,S-Join)給 定2 個長度為m的弱間隙強模式q和r,其中,模式r表示為r=e1,e2,…,em-1,em。如果suffer(q)=prefix(r),根據em-1,em可 分為以下2 種情況:
1)em-1和em存在于同一個項集中。在這種情況下,使用I-Join 的方法生成超模式t,即添加項em到模式q的最后一個項集中,表示為t=q⊕r。
2)em-1和em存在于2 個不同項集中。在這種情況下,使用S-Join 的方法生成超模式t,即將項集(em)附加到模式q的末尾,表示為t=q?r。
例7給定3 個4 長度的弱間隙強模式p=(b)*(ab)*(d),q=(ab)*(de)和r=(ab)*(d)*(e),可 知,suffer(p)=prefix(q)=prefix(r)=(ab)*(d),因此,模式p和q可以通過I-Join 生成超模式t1=(b)*(ab)*(de),模式p和r可以通過S-Join 生成超模式t2=(b)*(ab)*(d)*(e)。
定義11(模式連接)用2 個長度為m的頻繁模式通過I-Join 和S-Join 生成長度為m+1 的候選模式,這個方法被稱為模式連接。需要注意的是,在使用I-Join 方法時,同一項集內的項要按字典順序排序。
例8給定1 長度的頻繁模式集:{(a),(b),(d)},可以通過I-Join 生成超模式(ab)、(ad)和(bd),但是模式(da)不合規則,因為它沒有按照字典順序排序。
下面通過例9 來闡述模式連接策略的優越性。
例9給定2 長度的頻繁模式集{(ad),(b)*(a),(d)*(b)}和1 長度的頻繁模式集{(a),(b),(d)}。如果采用傳統的I-Connection 和S-Connection方法生成候選模式的話,將得到12 個3 長度的候選模式。但是如果采用模式連接策略,只生成(ad)*(b)、(d)*(b)*(a)和(b)*(ad)3 個候選模式。顯然,模式連接策略大幅減少了候選模式的數量。因此,模式連接策略優于I-Connection 和S-Connection 方法,能夠有效縮減候選模式數量,達到提高挖掘效率的目的。
模式連接策略的偽代碼如算法2 所示。
算法2PatternJoin 算法
3.4 OWP 算法
本節通過OWP 算法來挖掘序列數據庫中所有頻繁的一次性弱間隙強模式,具體步驟如下:
步驟1遍歷序列數據庫D,創建倒排索引I。
步驟2計算各項的支持度,剪枝不頻繁的強項并將頻繁的強項存入FP1與FPItem。
步驟3在FPm-1(m≥2)基礎上,使用模式連接策略生成長度為m的候選模式Candim。
步驟4通過SupII 算法計算Candim中每個候選模式的支持度,并將頻繁的模式存入FPm與FPItem。
步驟5重復步驟3 和步驟4,直到沒有新的候選模式生成,算法結束。
OWP 算法的偽代碼如算法3 所示。
算法3OWP 算法
OWP 算法主要有以下2 個優點:1)OWP 采用倒排索引結構,避免了對原始序列數據庫的重復掃描,并且使用項的出現位置計算模式支持度,提高了搜索與計算效率;2)OWP 采用模式連接策略生成候選模式,減少了冗余候選模式的生成,其效率遠遠優于經典的I-Connection 和S-Connection 方法。
3.5 時空復雜度分析
3.5.1 時間復雜度
OWP 算法的時間復雜度為O(k×N/r+L×logaL),其中,k、r、N和L分別為模式最大長度、1 長度模式的數量、序列總長度和候選模式數量。
OWP 算法的時間復雜度主要由準備階段、支持度計算和候選模式生成3 個部分構成。在準備階段,創建倒排索引,其時間復雜度為O(N/r);在支持度計算階段,SupII 算法的時間復雜度為O(k×N/r);在候選模式生成階段,模式連接策略的時間復雜度為O(L×logaL)。因此,OWP 算法的時間復雜度為O(N/r+k×N/r+L×logaL)=O(k×N/r+L×logaL)。
3.5.2 空間復雜度
OWP 算法的空間復雜度為O(k×N/r+L),其中,k、r、N和L分別為模式最大長度、1 長度模式的數量、序列總長度和候選模式數量。
OWP 算法的空間復雜度由準備階段創建的倒排索引、支持度計算時占用的內存空間和生成的候選模式3 個部分組成。其中,準備階段創建的倒排索引的空間復雜度為O(N/r);在支持度計算階段,SupII 算法的空間復雜度為O(k×N/r);在候選模式生成階段的空間復雜度為O(L)。因此,OWP 算法的空間復雜度為O(N/r+k×N/r+L)=O(k×N/r+L)。
4 實驗分析
4.1 實驗數據集
本文采用6 個真實數據集來驗證OWP 算法的運行效率,其中,D1 是項集序列數據集,D2、D3 是序列數據集,D4、D5 和D6 是氨基酸數據集,都是單項序列數據集。
實驗運行環境:操作系統為64 位Windows 10,處理器為Inter?CoreTMi5-9300U,主頻為2.20 GHz,內存為8 GB,開發語言為Python,開發環境為PyCharm。
表2 所示為所選用數據集。
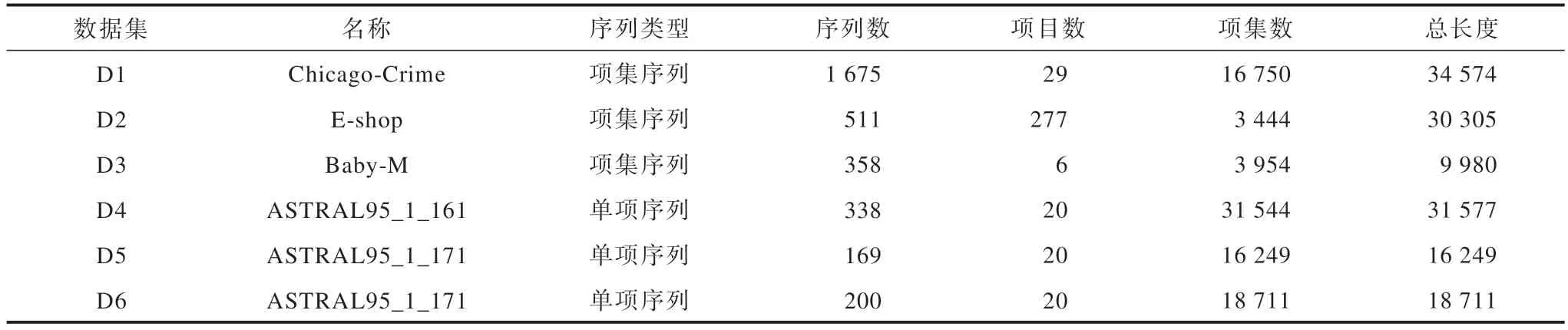
表2 實驗數據集Table 2 Experimental datasets 單位:個
4.2 對比算法
本文主要采用以下對比算法:
1)OWP-p:為驗證準備階段剪枝策略的有效性,本文設計了OWP-p 算法,與OWP 算法相比,該算法沒有使用此剪枝策略。
2)Ows-OWP:為了驗證SupII 算法在計算支持度方面的優越性,采用Ows-OWP 算法作為對比,該算法采用文獻[27]提出的one-way scan 算法計算模式的支持度。
3)OWP-e:為了驗證模式連接策略的有效性,使用OWP-e 算法作為對比算法,該算法在候選模式生成時采用以廣度優先為基礎的枚舉法。
4.3 挖掘效果
本文采 用3 個對比算法OWP-p、Ows-OWP 和OWP-e 在D1~D6 這6 個數據集上進行實驗,設置不同數據集上的minsup 分別為450、500、600、35、24 和20。其中,D1~D3 為項集序列數據集,隨機設置其10%的項為弱項,D4~D6 為氨基酸序列,設置非必要氨基酸為弱項,即弱項集合為ω={A,D,E,U,O,X}。圖2、圖3 和表3 分別為運行時間、內存消耗以及候選模式數量的對比結果。
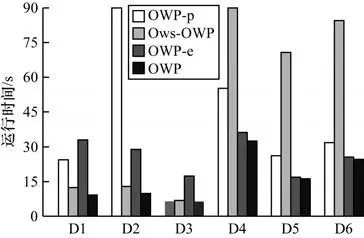
圖2 D1~D6 運行時間對比Fig.2 Comparison of D1~D6 running time
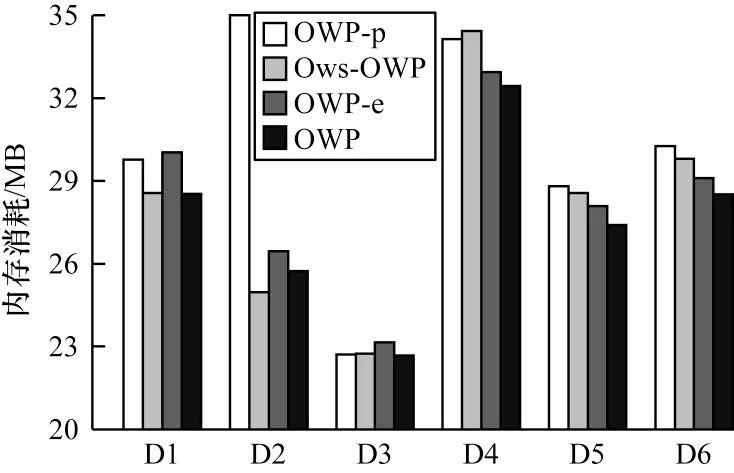
圖3 D1~D6 內存消耗對比Fig.3 Comparison of D1~ D6 memory consumption
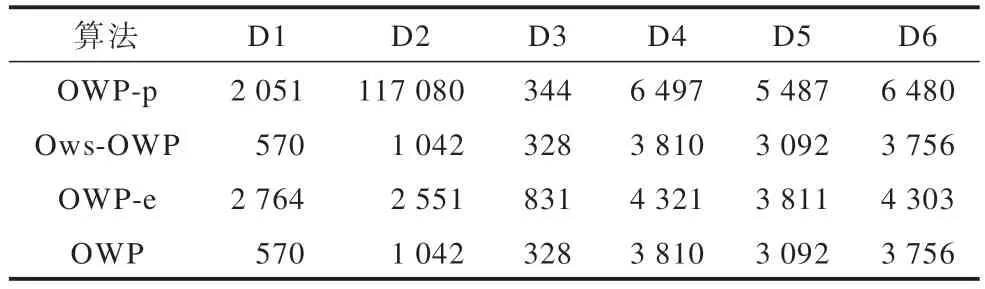
表3 生成的候選模式數量Table 3 The number of candidate patterns generated 單位:個
根據上述實驗結果,可以得出如下結論:
1)剪枝策略可以有效提高算法效率。OWP 的效率優于OWP-p。以D1 為例,觀察圖2、圖3 和表3可知,OWP 和OWP-p 的運行時間分別是9.20 s 和24.41 s,內存消耗分別是28.53 MB 和29.76 MB,生成的候選模式數量分別為570 個和2 051 個。運行時間增長了24.41/9.20=2.653 倍,內存消耗減少了3.51%。類似情況出現在每個數據集上,主要原因是:對非頻繁強項和所有弱項進行剪枝,即縮減了FP1的大小,在生成2 長度的候選模式時,可以大大地減少在I-Join 和S-Join 過程中產生的冗余模式,同時減少了計算冗余候選模式支持度而造成的時間和空間的浪費。因此,剪枝策略可以有效提高算法的運行效率。
2)無論在項集序列數據集上還是在單項序列數據集上,OWP 的表現優于Ows-OWP。在運行時間方面,OWP 的運行時間少于Ows-OWP。以D1 為例,由表3 可知,在OWP 和Ows-OWP 都生成570 個候選模式的情況下,通過圖2 可以看出它們的運行時間分別為9.20 s 和12.40 s。類似的情況也出現在其他數據集上,出現這種情況的主要原因是:SupII算法采用倒排索引結構,利用項目出現的位置索引計算模式支持度,避免了重復掃描數據庫造成的時間浪費,因此運行時間大大縮短。在內存消耗方面,觀察圖3 可知,除了在D2 中,OWP 比Ows-OWP 的內存消耗高,分別是25.73 MB 和24.96 MB,在其他數據集中OWP 算法的內存消耗都低于Ows-OWP 算法,造成這種情況的原因是:由于SupII 算法需要提前申請額外空間來構建倒排索引,這產生了一定的內存消耗。當數據集的項數較多時,如D2 有277 個,這就使得OWP 占用的空間略微增加。根據表2 可知,其他數據集的項目數較少,所以OWP 用于創建倒排索引產生的空間消耗較低。因此,在內存消耗方面,OWP 算法在項數較多的數據集上內存消耗略高,在項數較少的數據集上內存消耗略低。根據圖2、圖3 可知,以D1 為例,OWP 比Ows-OWP的運行時間增長了12.40/9.20=1.348 倍,內存消耗減少了0.07%。綜上所述,OWP 算法優于Ows-OWP算法。
3)模式連接策略可以有效減少候選模式的數量。無論在項集序列數據集上還是在單項序列數據集上,OWP-e 的運行時間、內存消耗和候選模式的生成數量均大于OWP。以D1 為例,由圖2、圖3 和表3可知,OWP 和OWP-e 的運行時間分別是9.20 s 和33.05 s,內存消耗分別是28.53 MB 和30.02 MB,生成的候選模式數量分別是570 個和2 764 個,運行時間增長了33.05/9.20=3.592 倍,內存消耗減少了5%。這種情況也普遍出現在其他數據集上,出現這一情況的原因如下:OWP 采用模式連接策略,可以減少冗余候選模式的生成數量,也減少了用于計算它們支持度的時間和內存消耗。因此,OWP 算法優于OWP-e 算法。
綜上所述,OWP 算法可以比其他對比算法更高效地挖掘一次性弱間隙強模式。
4.4 可擴展性
為了驗證OWP 算法的可擴展性,分別選取3 個對比算 法OWP-p、Ows-OWP 和OWP-e,在 以D1 為基礎的數據集D1_1、D1_2、D1_3、D1_4、D1_5、D1_6上進行實驗。這些數據集分別是D1 大小的1~6 倍。設置不同數據集上的minsup 分別為450、900、1 350、1 800、2 250 和2 700。圖4、圖5 分別為挖掘結果的運行時間和內存消耗對比。
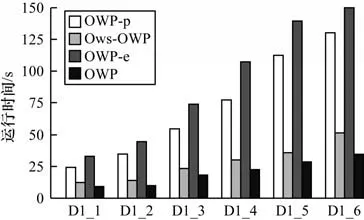
圖4 不同大小數據集上的運行時間對比Fig.4 Comparison of running time on different size datasets
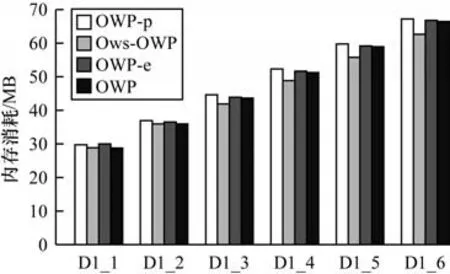
圖5 在不同大小數據集上的內存消耗對比Fig.5 Comparison of memory consumption on different sizes datasets
觀察圖4 和圖5 可以得出以下結論:
OWP 算法在運行時間和內存消耗方面都隨著數據集的增大呈線性增加。比如,OWP 算法在D1_1上的運行時間為9.20 s,內存消耗為28.73 MB,在D1_6 上運行時間為34.62 s,內存消耗為66.39 MB,即運行時間增長了34.62/9.20=3.763 倍,內存消耗增加了66.39/28.73=2.310 倍。由此可見,OWP 的運行時間和內存消耗增長的倍數遠低于數據集大小增長的倍數,證明OWP 具有良好的可擴展性。此外,OWP-p 的運行時間增長了130.26/24.41=5.336 倍,內存消耗 增加了67.20/29.76=2.258 倍;Ows-OWP 的 運行時間增長了51.54/12.40=4.156 倍,內存消耗增加了62.62/28.87=2.169 倍;OWP-e 的運行時間增長了163.87/33.05=4.958 倍,內存消耗增加了66.39/30.02=2.212 倍。分析可知,在運行時間上,其他3 種對比算法增加的倍數要高于OWP,但是在內存消耗上其他3 種對比算法的表現要略微優于OWP。出現這種情況的原因是:OWP 采用的剪枝策略、SupII 算法和模式連接策略有效提高了算法的運行效率,但同時OWP 由于采用SupII 算法計算支持度,當數據集變大時,創建倒排索引所占據的空間也會變大,因此比Ows-OWP 消耗了更多內存空間。然而,OWP-p 和OWP-e 生成的冗余候選模式雖然會造成一定的內存占用,但是由于數據集項數較少且不隨著數據集變大而增加,因此它們內存消耗增加的倍數要略微低于OWP。
綜上所述,OWP 的挖掘性能不會隨著數據集的增大而降低,因此,OWP 在大數據集上也可以高效地挖掘出用戶感興趣的模式。
5 結束語
本文提出在更具通用性的項集序列數據集上挖掘一次性弱間隙強模式的OWP 算法。在準備階段,通過掃描數據庫對序列中的各項創建對應的倒排索引,并采用剪枝策略剪枝弱項和非頻繁強項,精簡1長度的頻繁模式集合。在支持度計算方面,采用倒排索引結構,根據模式出現位置索引計算候選模式支持度,避免重復掃描數據庫帶來的時間消耗,從而大幅提高了運行效率。在候選模式生成方面,采用基于Apriori 屬性的模式連接策略,有效減少候選模式的生成數量。在真實數據集上的實驗結果驗證了OWP 算法的高效性與可擴展性。下一步將對如何解決弱間隙約束條件重復判斷的問題進行研究,以達到在序列、模式增長或者出現次數增加時,可以高效計算模式支持度。
