基于高級語義特征蒸餾的增量式連續目標檢測方法 *
2024-03-18 07:22:12康夢雪張金鵬馬喆黃旭輝劉雅婷宋子壯
現代防御技術 2024年1期
康夢雪,張金鵬,馬喆*,黃旭輝,劉雅婷,宋子壯
(1. 中國航天科工集團智能科技研究院有限公司,北京 100043;2. 航天防務智能系統與技術科研重點實驗室,北京 100043)
0 引言
現代防御環境錯綜復雜,呈現出高動態強開放的特點,對防御體系的目標感知和檢測能力提出嚴峻挑戰。威脅目標種類多更新快,高價值信息隱蔽難獲取,導致歷史數據無法涵蓋所有潛在威脅目標,不能動態反映實時環境狀況。因此,基于大規模歷史數據和傳統深度學習方法所訓練的智能系統存在動態開放環境適應能力差的局限性。這要求新型智能系統應能夠在動態開放場景下進行增量式持續自主學習,將歷史數據與實況數據進行增量式融合,持續提升環境生存能力和對抗能力,從而自主應對環境態勢變化,形成高水平智能化防御能力。
傳統目標感知算法不具備對未知新類型目標的持續感知能力,當應用場景從靜態封閉擴展到動態開放時,感知性能發生顯著退化。因此,對新類型威脅目標進行增量式連續學習,迅速確定其數量、種類與威脅程度,是防御場景下持續自主感知能力的關鍵。近年來,增量式連續學習被提出用于動態開放場景下的目標感知,通常根據是否呈現任務標簽,將增量式連續學習分為3 種類型:任務增量、域增量和類增量。本文關注類增量連續學習與目標檢測任務的結合,即增量式連續目標檢測任務。
現有的增量式連續學習方法在分類任務上取得了較好的進展[1-5],但在檢測識別任務上難度較大進展較少。分類任務中單幀圖像一般只包含單一類別的單個目標物體,因此只需要確定該物體的類別信息,也即分類模型只預測輸出一個類別標簽。檢測任務中單幀圖像上可能出現若干類別不同、且數量可變的目標物體,因此需要同時確定多個物體的類別信息和位置信息,即檢測模型預測輸出數量不定的類別標簽和位置坐標。因此,增量式連續分類任務只需避免分類知識的遺忘,而增量式連續檢測任務需要同時避免分類知識和定位知識的知識遺忘,因此增量式連續檢測任務往往難度更大。但防御場景下必然面對多目標情形,因此準確檢出來襲目標的數量、類別、方位是基本要求,因此必須開展增量式連續檢測方法的研究。
傳統目標檢測模型通過已知數據進行訓練。微調模型以適應新加入的數據,會導致模型在舊數據上的性能急劇下降,該現象被稱為災難性遺忘,是增量式連續學習的關鍵挑戰。
在分類任務的增量式連續學習方面,研究人員已經提出較多方法以緩解災難性遺忘,例如參數隔離[6]、正則化[7]和樣本回放[8]。文獻[1]闡述了增量式連續分類算法的最新進展。
在目標檢測任務的增量式連續學習方面,有基于樣本回放[9]、元學習[10]、知識蒸餾[11]、關系建模[12]等眾多方法,其中知識蒸餾被證明是減少災難性遺忘的有效方法之一[11,13-15]。該方法的基本思路是通過知識蒸餾將舊數據的知識從教師模型傳遞給學生模型,知識的來源可以是關鍵樣本、重要特征、分類響應或定位響應等。在知識蒸餾框架下,舊類別目標的監督信息由教師模型的預測提供,而新類別目標的監督信息由新增數據的標注基準來提供,從而能夠有效應對增量學習過程中舊類別標注信息缺失的問題。
但現有特征蒸餾方法大都在較低層或較淺層的特征層進行方法設計而忽略了對高級語義特征的開發利用。高級語義特征具有更好的語義抽象性和變換穩定性,是對圖片類別信息的魯棒表示[1]。而知識蒸餾的目的也在于向學生模型傳遞各個類別的特征魯棒性和語義不變性。因此,高級語義特征可用以更好指導基于特征蒸餾的知識傳遞。
受此啟發,本文提出一種全新的基于高級語義特征的知識蒸餾方法,以更好選擇重要知識進行傳遞,從而緩解災難遺忘,并提升增量式連續目標檢測算法的性能。本文將首先簡述增量式連續目標檢測識別,接著詳述本文所提出的基于高級語義特征蒸餾的增量式連續目標檢測方法,然后基于公開數據集MSCOCO2017 進行算法驗證,并結合分離實驗分析蒸餾不同特征區域對算法性能的影響,最后對增量式連續目標檢測進行總結和展望。
1 增量式連續目標檢測
1.1 增量式連續目標檢測任務及模型
原始數據集包含多類別樣本,根據增量式連續學習的一般設定,需要將數據依照不同場景設定分為舊類別數據與新類別數據。圖1 為知識蒸餾框架下增量式連續目標檢測模型的示意圖。
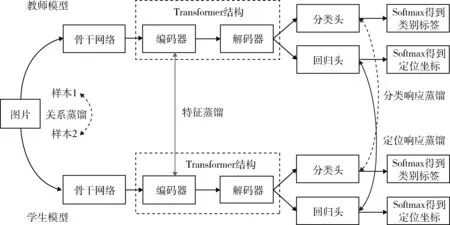
圖1 增量式連續目標檢測模型(本方法僅使用特征蒸餾,其他蒸餾方法以虛線示意作為對比)Fig. 1 Incremental continuous target detection model (only feature distillation is used in this method,other distillation methods are shown as dashed lines for comparison)
如圖1 所示,首先進行舊類別數據訓練。模型基于舊類別訓練圖像數據集與舊類別標簽,訓練神經網絡得到教師模型。其中,訓練、驗證與測試部分數據集均為舊類別目標的標注數據。模型包括利用骨干網絡提取圖像特征,將深層特征和淺層特征拼接生成多尺度特征圖。特征圖通過包含編碼器和解碼器的特征提取網絡得到最終特征向量。通過分類輸出層與回歸輸出層得到分類軟標簽與回歸軟標簽。最終經過Softmax 等激活函數得到類別標簽與回歸坐標。
其次進行新類別數據訓練。模型基于新類別訓練圖像數據集與新類別標簽,再次訓練神經網絡得到學生模型。其中,訓練和驗證數據集僅包含新類別標簽,測試數據集包含新類別標簽與舊類別標簽。學生模型需要在僅學習新類別標簽的情況下,在測試數據集上同時識別出新類別與舊類別目標。
為緩解學生模型對于舊類別知識的遺忘,提高學生模型在測試數據集上舊類別目標識別準確率,學生模型應接受教師模型輸出信息,以保存相應的舊類別知識。教師模型輸出信息可包含類別標簽信息,類別軟標簽,以及特征信息等。該模型信息傳遞過程被稱為知識蒸餾。
1.2 增量式連續目標檢測中的知識蒸餾
現有應用于增量式目標檢測的知識蒸餾方法主要包含3 種類型,包括基于特征的知識蒸餾[11]、基于響應的知識蒸餾[15]和基于關系的知識蒸餾[14]。圖1 示意了不同知識蒸餾在模型中的出現位置。
基于特征的知識蒸餾方法都是通過精心選擇特定網絡層特征來實現舊知識提取和傳遞。文獻[16]提出細粒度特征蒸餾法和多視圖相關蒸餾法選擇性地利用模型中間層來保留舊類別的模式。文獻[13]提出保留教師和學生特征圖之間的通道式、點式和實例式關聯。文獻[11]根據圖片底層特征的統計信息彈性選擇蒸餾區域。文獻[14,16-17]提出了其他提取模型中間層特征并加以蒸餾的方法。
基于響應的蒸餾方法直接對教師模型與學生模型的分類輸出和定位輸出進行蒸餾,去掉了待蒸餾特征的選擇與設計。例如,LwF(learning without forgetting)是首個利用知識蒸餾方法的增量式連續檢測模型,它將教師模型產生的舊類別預測標簽與新類別標簽混合進行訓練,以保存模型對于舊類別的記憶能力[13]。文獻[18]提出了一種完全基于響應的蒸餾方法,根據教師模型輸出響應的均值與方差進行知識的自適應選擇與過濾,從而提升知識傳遞的質量。文獻[11]將檢測模型的最終輸出響應與RPN(region proposal network)輸出響應相結合進行知識蒸餾。
基于關系的蒸餾方法通過度量學習等方式挖掘樣本之間的關系實現知識的傳遞。文獻[14]通過對于輸出層、中間層和不同實例之間關系的相關蒸餾,討論模型蒸餾的合適位置。
因為響應知識的形成依賴于特征知識,而樣本關系挖掘又效率較低。因此在上述3 種蒸餾類型中,基于特征蒸餾的增量式連續目標檢測方法得到更為廣泛的研究。然而,目前特征蒸餾方法在很大程度上依賴于底層細節特征的選擇,而對高級語義特征的重要性探索不足。
2 基于高級語義特征蒸餾的連續目標檢測
在深度神經網絡模型中,特征向量包括高層語義特征與底層細節特征。高層語義特征位于深層網絡,富含深層抽象信息,例如目標類別語義信息與邊界框定位信息等。底層細節特征位于淺層網絡,富含空間細節信息,例如輪廓、邊緣、顏色、紋理和形狀等。高級語義特征與底層細節特征均在教師模型的目標信息與背景信息中進行表達。新類別目標在教師模型中被錯誤地表達為背景信息,而學生模型需要將其重新識別為有效目標。因此區分有效目標、正確背景、錯誤背景是正確利用高層語義特征與底層細節特征的關鍵。本文提出一種注意力掩碼方法來區分3 種信息:①教師模型中的目標信息;②學生模型中的目標信息;③教師模型中的正確背景信息。
教師模型中的目標信息中包含了舊任務所有的前景信息。以往的工作通常直接使用前景信息中的所有特征,并平等地對待每個位置。但是實際情況是,即使在每個前景框中,特征也是不完全一致的。因此本文提出,在分離出前景背景信息之后,仍然需要對前景框提取里面的有價值區域進行蒸餾。為了解決這個問題,需要模型首先通過計算教師模型經過解碼器之后所生成的語義信息與學生模型經過解碼器之后所生成的語義信息差異,選出差異大的區域作為需要重點關注的重要特征位置。將重要特征位置信息以掩碼的形式加到對應的特征圖上,之后再進行相應位置的特征蒸餾損失。將待檢測的圖像(包括新類別目標與舊類別目標)輸入到訓練好的學生模型進行目標檢測。
根據上述描述這里提出了一種結構化特征提取方案,包括3 個步驟:首先,計算教師和學生之間高層語義表示的差異,如式(1)所示。然后,計算低層特征表示的差異,如式(2)所示。接著,在高層語義差異的指導下最小化底層特征差異,如式(3)所示。由于前景與背景包含信息不同,因此需要使用注意力掩碼分離前景與背景。語義引導的特征提取僅添加到前景,因為前景具有更為重要的語義信息。最后,計算各項差異之和作為最終的蒸餾損失,如式(4)所示。
將本文方法的詳細步驟整理如下:
step 1:計算高級語義特征的差異
式中:Steacher為老師模型高級語義特征;Sstudent為學生模型高級語義特征。
step 2:計算淺層特征的差異
式中:Fteacher為老師模型淺層(或底層)特征圖;Fstudent為學生模型淺層(或底層)特征圖。
step 3:計算前背景分離掩碼
式中:Hold和Wold為老師模型檢測框的長和寬。
step 4:計算整體蒸餾損失
式中:Lossdist為教師與學生模型蒸餾損失函數。
本方法無需對原始檢測器進行“侵入式”的結構改進和設計,因此對各類具體的Query-based Transformer 檢測器都有好的適配能力。此外,本方法還具有簡化增量式連續目標檢測方法設計復雜性的優點,主要體現在以下2 個方面:(1)本方法采用Transformer 檢測器構建;其高級語義特征采用查詢特征(query feature,QF)的方式生成,查詢特征的數量一般在100~300 之間。但傳統CNN 檢測器,其高級語義特征大多采用錨點特征(anchor feature,AF)的方式生成,且錨點數量一般不少于2 000 個。每個QF 或AF 對應一個潛在目標物體,但事實上單張圖像上的有效目標數量一般不超過20 個,因此QF 比AF 提供了更有效率的高級語義特征生成方式。基于此,Transformer 檢測器無需對輸出結果使用非極大值抑制(non-maximum suppression,NMS),在輸出篩選上更加簡潔。所以Transformer 檢測器有效簡化了高級語義特征的生成和篩選方式,進而為基于高級語義特征的知識蒸餾帶來便利。
最后,現有方法基本都組合使用多種知識蒸餾以緩解災難遺忘,圖1 示意了不同知識蒸餾在神經網絡模型中的位置。例如近期的最優模型ERD[11]同時使用了分類和定位2 種知識蒸餾。而本文方法僅使用了特征蒸餾,進而無需在教師和學生之間設置多組蒸餾損失函數。這一優勢進一步簡化了增量式連續檢測方法的設計復雜性。
3 增量式連續目標檢測實驗結果
3.1 增量式連續目標檢測實驗設置及評估方法
為驗證所提出的算法性能,本文進行了2 個實驗:一個是在不同連續學習場景對于算法進行連續學習能力驗證,另一個通過對于不同有價值區域進行蒸餾討論語義特征引導的意義。
實驗1 的設置包括基于公開數據集MS COCO的單步連續學習場景(40 類+40 類、50 類+30 類、60類+20 類和70 類+10 類)與多步連續學習場景(40 類+20 類+20 類)。其中40 類+40 類場景是指模型首先學習前40 類數據作為舊樣本,在此基礎上再學習后40 類數據作為新樣本。其余場景設置同理。實驗2的設置為40 類+40 類連續學習場景。通過比較不同有價值區域的蒸餾結果,討論語義特征引導的意義。
增量式連續目標檢測的評價一般通過與相對應的整體學習方法進行比較來確定[13]。具體的評價指標包括絕對差異(absolute gap,AbsGap)與相對差異(relative gap,RelGap),其定義分別如式(5)和式(6)所示:
式中:mAPcontinual為增量式連續學習下的目標檢測精度;mAPoverall為對應數據類別下整體學習的目標檢測精度,后者一般被認為是前者的上界。AbsGap和RelGap都衡量增量連續學習與整體學習之間的性能差距,進而反映出各自的增量式連續學習能力。特別地,RelGap去除不同檢測器基線的影響,衡量增量連續學習與整體學習之間的相對性能差距。
3.2 不同特征蒸餾區域的比較實驗
本文首先討論不同有價值區域的蒸餾結果。如表1 所示,添加完整特征蒸餾與基線模型差異較小。但是如果將特征拆分為前景與背景信息,則性能有所提升。之后將高級語義特征用于引導前景信息蒸餾,則最終性能得到顯著提升。
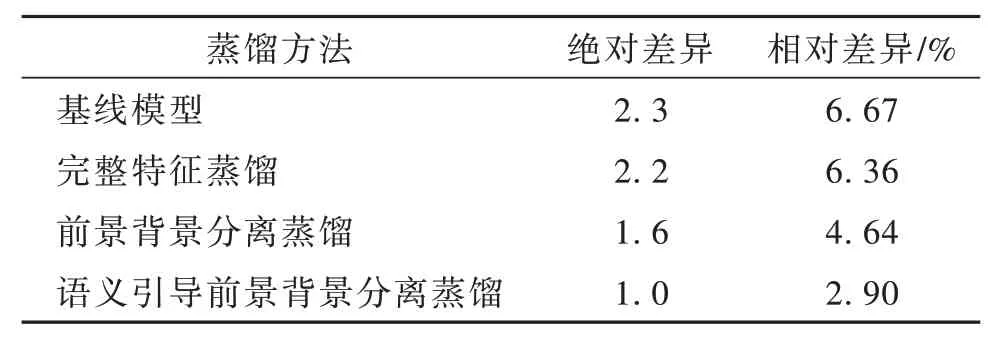
表1 分離實驗結果Table 1 Separation experiment results
如表1 所示,通過在基線模型上添加不同類型的特征蒸餾方法,逐步證明了完整特征蒸餾、前背景分離特征蒸餾、語義引導前景背景分離蒸餾的性能提升效果,進而綜合性說明了不同蒸餾區域的選擇在特征蒸餾中的重要性。表1 的實驗證明,前景信息與背景信息存在顯著信息差,以及高級語義信息對于關鍵信息選取有重要作用。
3.3 增量式連續目標檢測實驗結果
表2 顯示了本文方法與先前典型方法的增量學習性能比較結果。其中,LwF[13]是基于分類響應的的蒸餾方法,RILOD[15]是基于特征和分類響應相結合的蒸餾方法,SID[14]是基于特征和關系相結合的蒸餾方法,ERD[11]是基于分類響應和定位響應相結合的蒸餾方法。本文方法為基于特征的蒸餾方法,通過對比多種不同蒸餾方式下的增量學習方法,從而充分揭示其在緩解災難性知識遺忘、提升增量式連續目標檢測性能方面的顯著性。
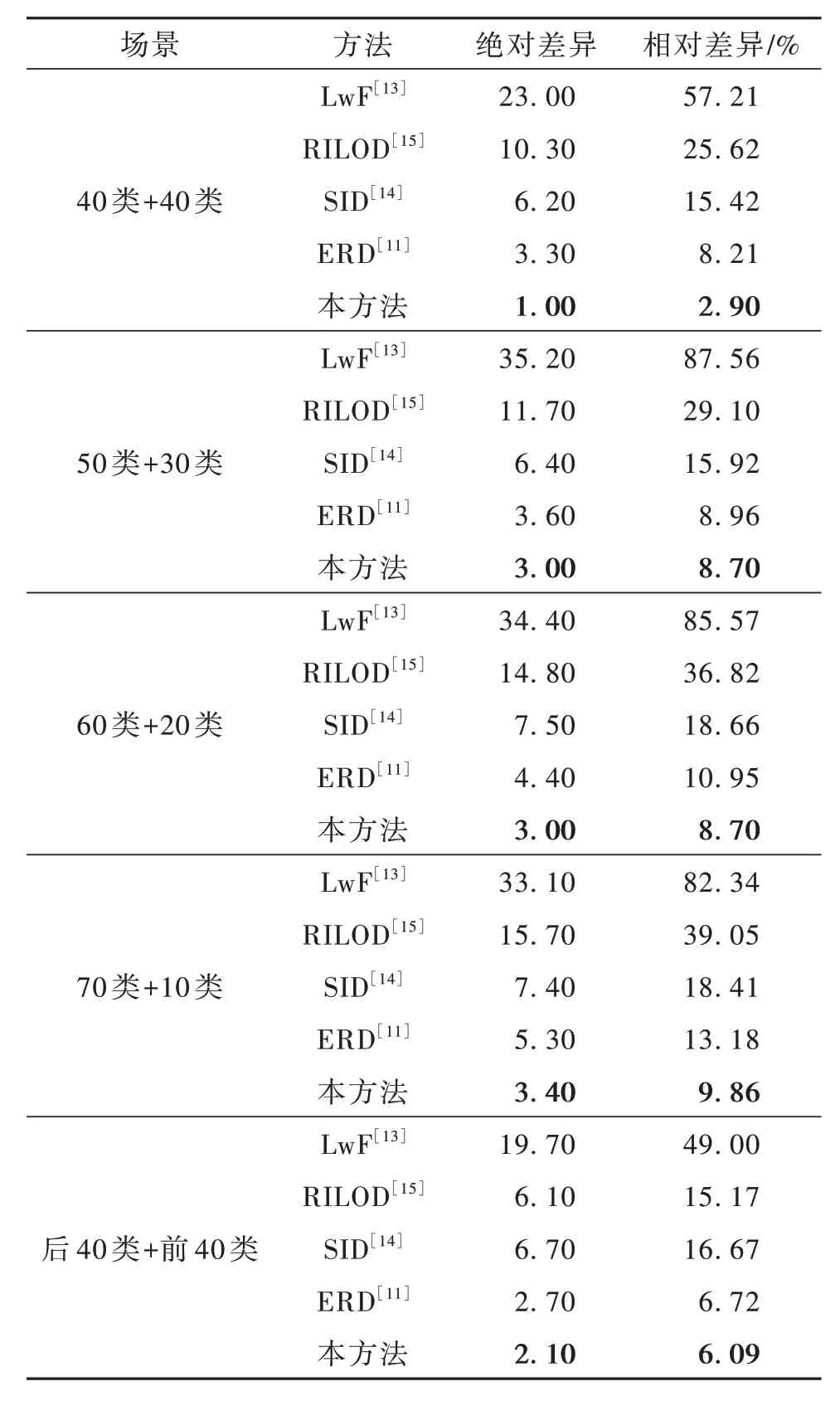
表2 單步連續學習目標檢測實驗結果Table 2 Results for one-step IOD
表2 中顯示40 類+40 類、50 類+30 類、60 類+20類和70 類+10 類場景下的連續學習性能。如40 類+40 類任務所示,與先前方法LwF,RILOD,SID 和ERD 相比,本方法與基于整體學習的上限差距更小,證明本方法的有效性。同時,在后40 類+前40類場景下性能也有顯著提高,這表明該方法可以在不受類別順序影響的情況下緩解災難性遺忘。對于所有其他場景(50 類+30 類、60 類+20 類和70 類+10 類),該方法也超越了當前最好水平。
本文還討論了多步連續學習目標檢測場景下不同方法的性能差異,實驗結果如表3 所示。表3中A 代表在首批數據下的整體式正常學習階段,B 代表在后續增量數據下的連續學習階段。A(第1 類~第40 類)表示首批數據包括第1 類到第40 類。B(第41 類~第60 類)表示增量數據包括第41 類到第60類。從A 到B,模型需要連續學習多個步驟,以適應多步增量數據劃分。表3 顯示本方法與完整訓練的差距顯著小于其他模型,這表明了它在多步場景下緩解災難性遺忘的出色能力。
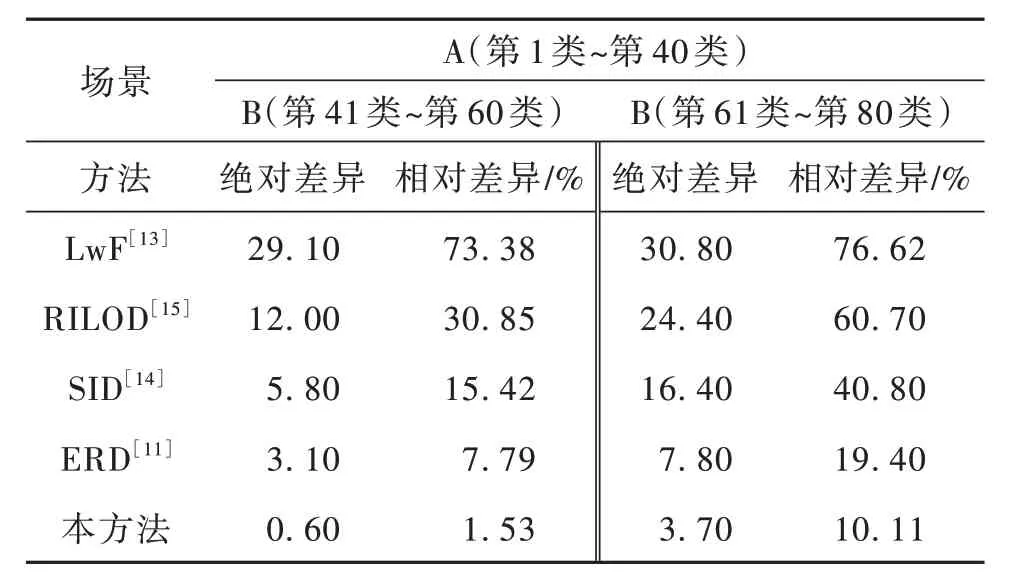
表3 多步連續學習目標檢測實驗結果Table 3 Results for multi-step IOD
綜合表2,3 結果可見,本文所提出方法具有更好的增量式連續目標檢測識別能力,其性能提升有以下3 個方面的內在原因。
(1)傳統特征蒸餾方法直接計算淺層特征差異進行知識傳遞,其工作原理如式(2)所示。由于淺層特征往往強于對圖像物理層面的細節信息(如邊緣、輪廓、紋理等)進行表達而缺乏更強的魯棒性,因此在此層面的學習使得學生模型更傾向于擬合和模仿教師模型中舊類別的欠魯棒特征。這些欠魯棒特征易于受到新類別知識的沖擊而劣化,從而導致舊類別知識的遺忘。
(2)本文的知識蒸餾方法額外計算了高層語義特征之間的差異,其工作原理如式(1)所示。由于高層語義特征存在于檢測器頭部網絡之中,是最接近分類輸出端和定位輸出端的特征,因而具有更強的變換不變性和穩定的語義表示能力。因此,在此層面的學習使得學生模型更傾向于擬合和模仿教師模型中舊類別的穩定語義表示,從而提升新類別學習過程中舊類別知識的穩定性。
(3)本文還計算了高級語義與淺層特征之間的交互作用,其工作原理如式(4)所示,這使得魯棒特征學習與穩定語義學習產生有效交互,實現語義引導下的特征學習,從而進一步緩解災難遺忘,提升增量式連續目標檢測能力。
4 結束語
針對基于深度學習方法的目標檢測器采用整體學習范式,在新類別數據增量出現時無法有效進行連續學習的問題,本文創新性地提出一種基于高級語義特征蒸餾的增量式連續目標檢測方法。不同于現有方法僅依賴淺層特征蒸餾,該方法首次引入高級語義特征蒸餾,并通過高級語義特征動態選擇淺層特征,實現高價值特征知識的傳遞,有效提升了增量式連續目標檢測任務的性能。同時,該方法充分利用了Transformer 檢測器的優勢,簡化了現有增量學習方法中組合式知識蒸餾的復雜設計,創新性地僅使用特征蒸餾即實現了更好的增量式連續目標檢測性能。
本研究在目標感知領域具有廣泛的應用前景,可促進檢測識別方法從靜態封閉的有限應用場景向動態開放場景發展,同時可推廣至紅外以及多模態場景下的各類增量式連續目標識別任務中。本研究有助于增強各類智能系統的持續自主學習能力,提升在高動態強開放場景下的任務遂行能力,推動智能感認知技術和智能感認知系統的深入發展。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現代語文(2016年21期)2016-05-25 13:13:44
海峽科技與產業(2016年3期)2016-05-17 04:32:12
大連民族大學學報(2015年2期)2015-02-27 08:28:11
