基于特征變量擴(kuò)展的含氣飽和度隨機(jī)森林預(yù)測(cè)方法
2024-03-16 03:24:18桂金詠李勝軍高建虎劉炳楊
巖性油氣藏 2024年2期
關(guān)鍵詞:特征
桂金詠,李勝軍,高建虎,劉炳楊,郭 欣
(中國(guó)石油勘探開(kāi)發(fā)研究院西北分院,蘭州 730020)
0 引言
含氣飽和度是天然氣藏商業(yè)價(jià)值評(píng)估、儲(chǔ)量提交、井位優(yōu)選、剩余氣描述等定量化分析工作的重要物性參數(shù),可以直接通過(guò)試氣數(shù)據(jù)或使用測(cè)井曲線(xiàn)解釋得到。目前,在地球物理勘探領(lǐng)域已經(jīng)提出了大量含氣飽和度測(cè)井解釋方法,但有關(guān)含氣飽和度的地震解釋方法卻較少[1-3]。利用地震數(shù)據(jù)預(yù)測(cè)天然氣藏的含氣飽和度是一種復(fù)雜的、多解性的以及高度非線(xiàn)性的地震反演問(wèn)題,現(xiàn)有的試圖從地震信息中解譯出含氣飽和度信息的方法,大多都是借助疊前地震反演技術(shù)先從疊前地震數(shù)據(jù)中反演出彈性參數(shù)數(shù)據(jù),繼而重點(diǎn)研究如何更高精度地將彈性參數(shù)數(shù)據(jù)進(jìn)一步反演為含氣飽和度等物性參數(shù),而物性參數(shù)與彈性參數(shù)間的巖石物理模型則起到一種正、反演基本準(zhǔn)則的作用。Bachrach[4]以經(jīng)典的Gassmann 方程為基礎(chǔ),建立了縱波阻抗、橫波阻抗及密度與孔隙度、飽和度等物性參數(shù)間的統(tǒng)計(jì)巖石物理模型,實(shí)現(xiàn)了孔隙度和飽和度的聯(lián)合反演。胡華鋒[5]結(jié)合統(tǒng)計(jì)巖石物理模型與貝葉斯分類(lèi)器,對(duì)儲(chǔ)層物性參數(shù)進(jìn)行了反演。De Figueiredo 等[6]利用混合高斯模型獲取物性參數(shù)的先驗(yàn)分布概率密度函數(shù),提出了貝葉斯線(xiàn)性解析化物性參數(shù)反演方法。劉興業(yè)等[7]針對(duì)統(tǒng)計(jì)巖石物理反演中似然函數(shù)難以表征的問(wèn)題,采用核估計(jì)的方法得到了條件概率密度函數(shù),基于核貝葉斯判別法預(yù)測(cè)物性參數(shù)。李紅兵等[8]提出了一種基于彈性阻抗的、適用于復(fù)雜孔隙儲(chǔ)層孔隙結(jié)構(gòu)的飽和度反演方法。另外,為了避免地震數(shù)據(jù)到彈性參數(shù)數(shù)據(jù),再到物性參數(shù)數(shù)據(jù)這種“兩步”反演方法誤差傳遞的問(wèn)題,也有學(xué)者嘗試將巖石物理模型與Zoeppritze 地震反射方程或其簡(jiǎn)化方程相融合,提出了物性參數(shù)地震直接反演方法,直接將疊前地震數(shù)據(jù)反演為含氣飽和度、孔隙度等物性參數(shù)數(shù)據(jù)。桂金詠等[9]結(jié)合包裹體巖石物理模型將雙相介質(zhì)地震反射系數(shù)推導(dǎo)成含氣飽和度、孔隙度和泥質(zhì)含量的函數(shù),并對(duì)其應(yīng)用差分進(jìn)化算法求解。Lang 等[10]在Gassmann 方程的基礎(chǔ)上,結(jié)合臨界孔隙度模型,推導(dǎo)了流體體積模量、剪切模量及密度隨巖石基質(zhì)、流體參數(shù)的偏導(dǎo)數(shù),發(fā)展了基于貝葉斯線(xiàn)性反演的疊前地震AVO 物性預(yù)測(cè)。Liu 等[11]基于Kuster-Toks?z 巖石物理模型推導(dǎo)了飽和巖石模量的線(xiàn)性近似式,采用基于柯西約束的貝葉斯最大后驗(yàn)概率解,開(kāi)展了疊前地震確定性物性參數(shù)反演。李坤等[12]推導(dǎo)了利用KT 巖石物理模型高階近似和Gray 地震反射模型表征的疊前地震AVO 反射系數(shù)方程,假設(shè)在待反演物性參數(shù)服從混合概率先驗(yàn)?zāi)P偷那疤嵯拢苯臃囱莩隹紫抖取柡投燃澳噘|(zhì)含量。Fjeldstad 等[13]利用高斯混合模型表示含氣飽和度等物性參數(shù)的先驗(yàn)分布特征,結(jié)合地質(zhì)統(tǒng)計(jì)學(xué)空間模擬技術(shù),提出了含氣飽和度的“一步法”地質(zhì)統(tǒng)計(jì)學(xué)反演。
實(shí)際上,無(wú)論是“兩步法”還是“一步法”都離不開(kāi)巖石物理建模過(guò)程。對(duì)于地質(zhì)條件日趨復(fù)雜的天然氣探區(qū),彈性參數(shù)與物性參數(shù)間的巖石物理關(guān)系往往具備極強(qiáng)的非線(xiàn)性,極易受到實(shí)際研究區(qū)巖性、孔隙結(jié)構(gòu)、壓力、溫度等多種因素的影響,導(dǎo)致在大多數(shù)情況下難以建立起精確的巖石物理模型[14-17]。機(jī)器學(xué)習(xí)方法的出現(xiàn)為這類(lèi)非線(xiàn)性建模問(wèn)題提供了一種新的途徑。機(jī)器學(xué)習(xí)方法可以通過(guò)機(jī)器自主學(xué)習(xí)得到一種非線(xiàn)性映射關(guān)系,實(shí)現(xiàn)高度復(fù)雜的非線(xiàn)性函數(shù)逼近,具有強(qiáng)大的學(xué)習(xí)數(shù)據(jù)集本質(zhì)和高度抽象化特征的能力。通常根據(jù)訓(xùn)練是無(wú)監(jiān)督的還是有監(jiān)督的進(jìn)行分類(lèi)。無(wú)監(jiān)督學(xué)習(xí)無(wú)須訓(xùn)練數(shù)據(jù)集,直接基于輸入數(shù)據(jù)的分布或結(jié)構(gòu)來(lái)對(duì)信息相似的數(shù)據(jù)進(jìn)行分組和映射;監(jiān)督學(xué)習(xí)則需要訓(xùn)練數(shù)據(jù)集,包括輸入數(shù)據(jù)和標(biāo)簽,標(biāo)簽是輸入的響應(yīng)值。監(jiān)督學(xué)習(xí)的主要目標(biāo)是從標(biāo)記的訓(xùn)練數(shù)據(jù)中學(xué)習(xí)出一個(gè)最優(yōu)的映射模型,將已知領(lǐng)域知識(shí)與數(shù)據(jù)本身進(jìn)行結(jié)合,能夠有效減少預(yù)測(cè)的多解性。在眾多的監(jiān)督機(jī)器學(xué)習(xí)算法中,隨機(jī)森林(Random Forests,簡(jiǎn)稱(chēng)RF)近年來(lái)在地球物理學(xué)領(lǐng)域取得了較好的應(yīng)用效果[18]。Breiman[19]提出的RF 是一種集合學(xué)習(xí)算法,結(jié)合了bagging 集合和隨機(jī)特征選擇的思想,預(yù)測(cè)結(jié)果由多個(gè)決策樹(shù)分類(lèi)器投票決定。多個(gè)決策樹(shù)的作用相當(dāng)于組合很多非線(xiàn)性關(guān)系形成更復(fù)雜的非線(xiàn)性關(guān)系,具有預(yù)測(cè)精度高、對(duì)異常值和噪聲數(shù)據(jù)容忍度高等優(yōu)點(diǎn),已廣泛應(yīng)用于金融、生物、遺傳、圖像識(shí)別、醫(yī)學(xué)等領(lǐng)域。在地球物理領(lǐng)域,Harris 等[20]將隨機(jī)森林算法應(yīng)用于地球物理和地球化學(xué)數(shù)據(jù)聯(lián)合巖性分類(lèi)。宋建國(guó)等[21]針對(duì)儲(chǔ)層預(yù)測(cè)的復(fù)雜非線(xiàn)性及穩(wěn)定性問(wèn)題,將隨機(jī)森林回歸算法引入到地震儲(chǔ)層預(yù)測(cè)中,建立地震屬性與自然伽馬之間的非線(xiàn)性關(guān)系。王光宇等[22]考慮了不平衡樣本對(duì)隨機(jī)森林巖性分類(lèi)問(wèn)題的影響。Kuhn 等[23]利用地球物理和遙感數(shù)據(jù)對(duì)金礦附近未開(kāi)采區(qū)域的巖性進(jìn)行了分類(lèi)研究。Cracknell 等[24]將RF 與SVM、樸素貝葉斯、K 近鄰和人工神經(jīng)網(wǎng)絡(luò)進(jìn)行了巖性預(yù)測(cè)效果比較,認(rèn)為RF 優(yōu)于其他機(jī)器學(xué)習(xí)算法,并且證明了RF 能夠以更簡(jiǎn)單的輸入?yún)?shù)和更少的計(jì)算成本產(chǎn)生準(zhǔn)確的結(jié)果。
以往研究結(jié)果表明,對(duì)于巖性和流體識(shí)別等離散數(shù)據(jù)的分類(lèi)問(wèn)題,利用若干個(gè)對(duì)目標(biāo)敏感的地震衍生屬性,如振幅、頻率以及彈性參數(shù)等作為輸入特征變量,即可獲得較好的分類(lèi)結(jié)果[25-27],而對(duì)于含氣飽和度這類(lèi)連續(xù)數(shù)值的回歸問(wèn)題,特征變量的數(shù)量對(duì)預(yù)測(cè)結(jié)果的影響尚未明確。離散分類(lèi)問(wèn)題和連續(xù)值回歸問(wèn)題在算法本質(zhì)上差別不大,但對(duì)參與訓(xùn)練的特征變量的數(shù)量依賴(lài)程度不同。連續(xù)值回歸問(wèn)題可以看作是將連續(xù)值按極小的間隔離散化的分類(lèi)問(wèn)題,只是所分類(lèi)別較多,對(duì)參與訓(xùn)練的特征變量的數(shù)量要求也更大。通常情況下,訓(xùn)練中涉及的特征變量越多,所攜帶的信息越豐富,訓(xùn)練結(jié)果可能更準(zhǔn)確、泛化性能更好[27],但如果無(wú)限制地增加特征變量數(shù)量,會(huì)導(dǎo)致工作量巨大。另外,含氣飽和度訓(xùn)練樣本的取值分布往往具有“非平衡”特征,尤其是復(fù)雜天然氣探區(qū),含氣層往往薄薄地發(fā)育在大套背景巖性中,當(dāng)高含氣層樣本過(guò)少,而低含氣層樣本過(guò)多時(shí),會(huì)使訓(xùn)練結(jié)果向低含氣層偏倚,導(dǎo)致含氣飽和度的預(yù)測(cè)準(zhǔn)確率較低。
基于隨機(jī)森林(RF)預(yù)測(cè)含氣飽和度,引入合成少數(shù)類(lèi)過(guò)采樣技術(shù)以消除樣本不平衡對(duì)RF 訓(xùn)練的影響,采用自動(dòng)特征變量擴(kuò)展策略解決含氣飽和度回歸對(duì)特征變量數(shù)量的依賴(lài),利用隨機(jī)森林對(duì)特征變量進(jìn)行含氣飽和度預(yù)測(cè)重要性排名,優(yōu)選重要性較高的特征變量進(jìn)行最終隨機(jī)森林訓(xùn)練,并將該方法在實(shí)際工區(qū)中進(jìn)行應(yīng)用,以期提高地震信息對(duì)天然氣藏含氣飽和度的定量預(yù)測(cè)能力。
1 方法原理
1.1 特征變量擴(kuò)展
RF 算法用于含氣飽和度預(yù)測(cè)的一個(gè)關(guān)鍵步驟是要準(zhǔn)備足夠的特征變量作為訓(xùn)練集。Alvarez等[28]對(duì)縱波阻抗、橫波阻抗、縱橫波速度比、拉梅參數(shù)×密度、剪切模量×密度、拉梅參數(shù)/剪切模量、(拉梅參數(shù)-剪切模量)×密度、泊松比、楊氏模量×密度、體積模量×密度、泊松阻抗等11 種常用的地震彈性參數(shù)進(jìn)行數(shù)學(xué)變換,得到了大量的地震衍生屬性作為孔隙度、含水飽和度與泥質(zhì)含量等物性參數(shù)線(xiàn)性回歸的基礎(chǔ)屬性集,在常規(guī)碎屑巖物性參數(shù)預(yù)測(cè)中取得較好的應(yīng)用效果。然而,且不論該方法采用線(xiàn)性回歸的合理性,實(shí)際上常用的彈性參數(shù)的數(shù)量就遠(yuǎn)遠(yuǎn)超過(guò)11 種,該方法可能會(huì)遺漏對(duì)目標(biāo)敏感的彈性參數(shù)。另外,每個(gè)彈性參數(shù)的獲取都需要基于疊前地震反演或利用不同的變換公式轉(zhuǎn)換得到,自動(dòng)化程度較低,且變換過(guò)程中也存在誤差積累和放大的風(fēng)險(xiǎn)。尤其是對(duì)于各向異性比較明顯的致密砂巖或頁(yè)巖氣藏,疊前地震反演本身就存在極大的不確定性。為克服人工準(zhǔn)備大量特征變量的問(wèn)題,利用擴(kuò)展彈性阻抗(EEI)自動(dòng)生成一系列彈性屬性作為特征變量。Whitcombe 等[29]在Connolly彈性阻抗方程的基礎(chǔ)上提出了EEI方程的定義:
式中:χ為角度,(°),取值-90°~90°;vp,vs,vp0和vs0分別為縱波速度、橫波速度、目的層平均縱波速度和平均橫波速度,m/s;ρ和ρ0分別為密度和目的層平均密度,kg/m3;k=vs2/vp2。
由式(1)可知,EEI可以由vp,vs和ρ這3 個(gè)基本的彈性參數(shù)計(jì)算得出,通過(guò)調(diào)整χ的大小可以對(duì)EEI進(jìn)行調(diào)整,當(dāng)其與一些彈性參數(shù)近似成正比,可以用于巖性或流體識(shí)別[29]。此外,EEI還可以對(duì)常見(jiàn)的測(cè)井屬性(如電阻率、伽馬)進(jìn)行較好的擬合[30]。通過(guò)疊前地震反演技術(shù)易獲得vp,vs和ρ這3個(gè)基本的彈性參數(shù)體,使用不同值的EEI作為特征變量替代常規(guī)彈性參數(shù)。
首先,針對(duì)從疊前地震反演獲得的彈性參數(shù)存在一定誤差這一問(wèn)題,直接從疊前地震反演得到的彈性參數(shù)數(shù)據(jù)體中提取井旁道的縱波速度、橫波速度和密度偽井曲線(xiàn)作為與含氣飽和度測(cè)井解釋標(biāo)簽對(duì)應(yīng)的彈性參數(shù)樣本,采用機(jī)器學(xué)習(xí)算法進(jìn)行處理。即使訓(xùn)練樣本帶有一定的誤差,機(jī)器學(xué)習(xí)也能在無(wú)意識(shí)下學(xué)習(xí)得到包含噪聲的映射模型,直接將帶有誤差的特征變量映射為含氣飽和度。需要注意的是,特征變量的誤差也不能過(guò)大,會(huì)削弱有效信息。其次,設(shè)定角度χ 的變化步長(zhǎng),將縱波速度、橫波速度和密度偽井曲線(xiàn)帶入式(1),自動(dòng)生成一系列不同角度的EEI曲線(xiàn)。然后,根據(jù)Alvarez等[28]的數(shù)學(xué)變換思想,采用對(duì)數(shù)、指數(shù)、倒數(shù)、平方、開(kāi)方運(yùn)算對(duì)擴(kuò)展彈性阻抗進(jìn)一步擴(kuò)充,以設(shè)定χ為5°為例(表1),每個(gè)數(shù)字代表一個(gè)特征變量,可得到222 個(gè)彈性屬性作為特征變量數(shù)據(jù)集。最后,將生成的井旁道特征變量和對(duì)應(yīng)的含氣飽和度測(cè)井解釋標(biāo)簽作為監(jiān)督學(xué)習(xí)的原始訓(xùn)練集。
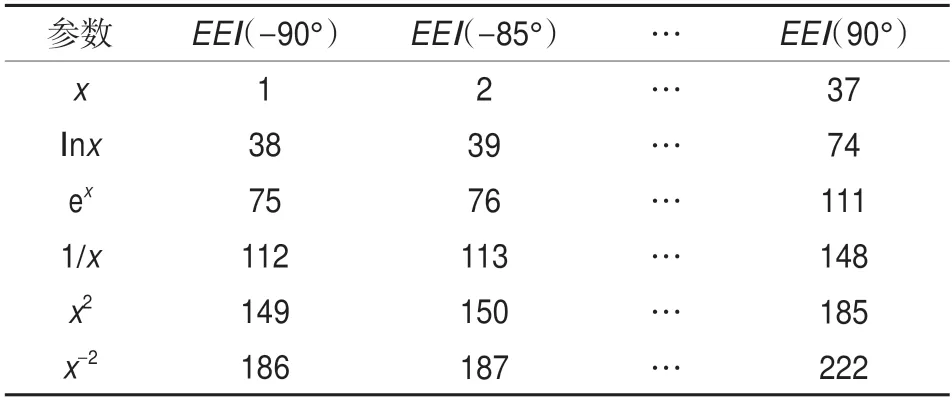
表1 擴(kuò)展特征變量Table 1 Extended feature variables
在實(shí)際操作中,還可以針對(duì)具體條件來(lái)設(shè)定需要擴(kuò)展的特征變量的數(shù)量。為了盡量不遺漏潛在的目標(biāo)敏感彈性屬性,χ 的變化步長(zhǎng)可以設(shè)定得更小,以獲得更多的特征變量。另外,也可以使用或增加其他的數(shù)學(xué)運(yùn)算方法來(lái)進(jìn)行自動(dòng)轉(zhuǎn)換,進(jìn)一步擴(kuò)充特征變量的種類(lèi)來(lái)增加特征變量數(shù)據(jù)集中有敏感性屬性的可能性。
1.2 樣本平衡化處理
RF 算法的核心是采用Bootstrap 抽樣法對(duì)原始樣本集進(jìn)行重新抽樣,隨機(jī)生成k個(gè)子訓(xùn)練集S1,S2,...,Sk。通過(guò)Bootstrap 抽樣,每個(gè)訓(xùn)練子集平均包含約63.2%的樣本,而剩余37.8%的“袋外”樣本則用于驗(yàn)證[19]。每個(gè)子訓(xùn)練集所包含的元素不盡相同,這可以保證決策樹(shù)的多樣性,使得訓(xùn)練模型具備泛化性,但在Bootstrap 抽樣過(guò)程中,所有樣本每次抽樣的概率都是相同的,這就意味著在不同類(lèi)別樣本數(shù)量差別很大的樣本集上訓(xùn)練時(shí),往往會(huì)出現(xiàn)分類(lèi)面向多數(shù)類(lèi)樣本偏倚的現(xiàn)象,少數(shù)類(lèi)樣本無(wú)法獲得理想的分類(lèi)效果。近幾年來(lái),機(jī)器學(xué)習(xí)中不平衡數(shù)據(jù)的分類(lèi)問(wèn)題受到了越來(lái)越多的關(guān)注[31],這里的“不平衡數(shù)據(jù)”是指分類(lèi)問(wèn)題中對(duì)應(yīng)于每個(gè)類(lèi)別的樣本數(shù)量是不同的,而且數(shù)量差異較大。這種不平衡數(shù)據(jù)往往會(huì)惡化機(jī)器學(xué)習(xí)算法的性能[32],如在進(jìn)行巖性識(shí)別時(shí),當(dāng)樣本集中目標(biāo)巖性(如含氣砂巖)的樣本數(shù)量過(guò)少,而非目標(biāo)巖性(如泥巖)的樣本數(shù)量過(guò)多時(shí),會(huì)使預(yù)測(cè)結(jié)果向非目標(biāo)巖性偏倚,導(dǎo)致目標(biāo)巖性的預(yù)測(cè)準(zhǔn)確率較低。同樣,對(duì)于含氣飽和度回歸也有這樣的問(wèn)題。在中國(guó)西部地區(qū),有利氣藏通常厚度較小,發(fā)育在大套地層中,若含氣飽和度較高的有利儲(chǔ)層訓(xùn)練樣本數(shù)較少,而含氣飽和度較低的非有利儲(chǔ)層的訓(xùn)練樣本數(shù)較多,RF回歸器的訓(xùn)練可能會(huì)偏向于非有利儲(chǔ)層,影響有利儲(chǔ)層的含氣飽和度回歸精度。
對(duì)于不平衡數(shù)據(jù)的處理一般有過(guò)采樣和欠采樣2 種方法。過(guò)采樣是通過(guò)復(fù)制少數(shù)類(lèi)樣本來(lái)增加其規(guī)模,欠采樣則是隨機(jī)刪除一些多數(shù)類(lèi)樣本的數(shù)量。考慮到機(jī)器學(xué)習(xí)含氣飽和度回歸主要以測(cè)井?dāng)?shù)據(jù)作為訓(xùn)練樣本,而測(cè)井成本較高,往往數(shù)量也不多,因此不刪除多數(shù)類(lèi)樣本,而是采用過(guò)采樣方法來(lái)處理少數(shù)類(lèi)樣本。在機(jī)器學(xué)習(xí)領(lǐng)域,應(yīng)用較多的過(guò)采樣方法是合成少數(shù)類(lèi)過(guò)采樣技術(shù)(Synthetic Minority Oversampling Technique,SMOTE),該技術(shù)通過(guò)分析少數(shù)類(lèi)樣本的特征,人工合成新的樣本,并將新的樣本加入到數(shù)據(jù)集中,直到各類(lèi)樣本的數(shù)量趨于平衡,形成一個(gè)大的平衡訓(xùn)練集,其實(shí)施步驟如下[33]:
(1)對(duì)于少數(shù)類(lèi)中的每個(gè)樣本,利用歐式距離計(jì)算其與少數(shù)類(lèi)中所有樣本的距離,并獲得m個(gè)最近的鄰點(diǎn)。
(2)根據(jù)不平衡類(lèi)比例設(shè)定抽樣比例,確定少數(shù)類(lèi)樣本的抽樣放大最終數(shù)量為N。對(duì)于少數(shù)類(lèi)中的樣本x,從m個(gè)最近的鄰點(diǎn)中隨機(jī)選擇幾個(gè)樣本y,構(gòu)建新的樣本z:
式中:rand(0,1)為隨機(jī)數(shù),取值0~1。
(3)重復(fù)步驟(1)—(2),直到少數(shù)類(lèi)樣本數(shù)量增加到預(yù)先設(shè)定的數(shù)值N。
然而,該方法并沒(méi)有考慮樣本的邊界問(wèn)題,可能會(huì)造成樣本取值的大量重疊,在離群點(diǎn)附近也會(huì)產(chǎn)生一些不能提供有效信息的樣本,降低學(xué)習(xí)性能。邊界合成少數(shù)過(guò)采樣技術(shù)(BSMOTE)是在SMOTE 基礎(chǔ)上改進(jìn)的過(guò)采樣算法[34],如圖1 所示,該算法在采樣過(guò)程中將少數(shù)類(lèi)樣本分為“安全”“危險(xiǎn)”和“噪聲”3 類(lèi),“安全”類(lèi)別是指鄰域超過(guò)一半的樣本是少數(shù)類(lèi)樣本(如圖1 中點(diǎn)A 所示);“危險(xiǎn)”類(lèi)別是指鄰域超過(guò)一半的樣本為多數(shù)類(lèi)樣本,視為邊界上的樣本(如圖1 中點(diǎn)B 所示);“噪聲”類(lèi)別是指樣本被多數(shù)類(lèi)樣本包圍(如圖1 中的點(diǎn)C 所示),只對(duì)被標(biāo)記為“危險(xiǎn)”的樣本進(jìn)行過(guò)采樣合成新樣本,可以改善樣本的類(lèi)別分布。
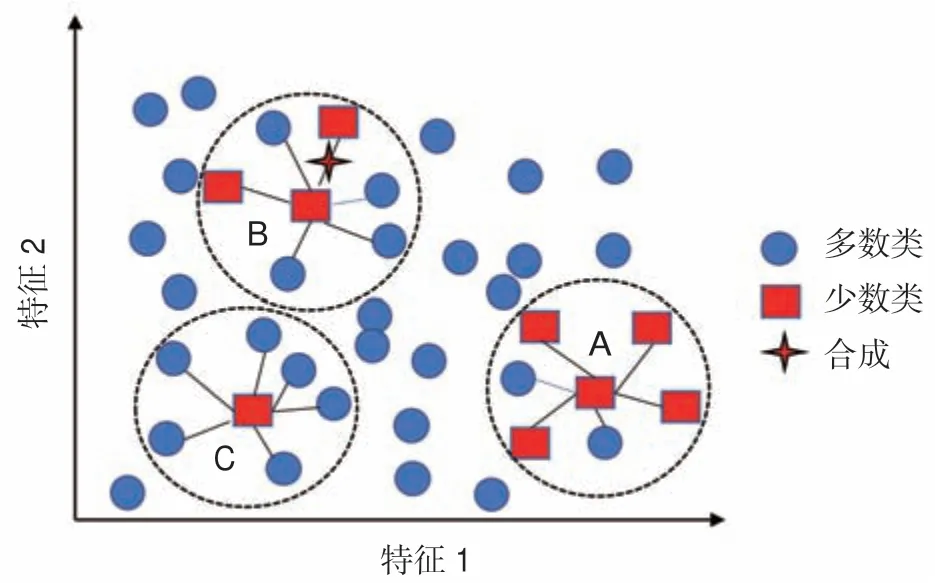
圖1 BSMOTE 原理示意圖Fig.1 Schematic diagram of BSMOTE
1.3 隨機(jī)森林回歸器構(gòu)建
作為一種數(shù)據(jù)驅(qū)動(dòng)算法,RF 對(duì)每個(gè)Bootstrap抽樣得到的子訓(xùn)練集S1,S2,...,Sk分別進(jìn)行決策樹(shù)建模,從而顯著提高了模型的準(zhǔn)確性和魯棒性,在處理各種復(fù)雜的預(yù)測(cè)和分類(lèi)問(wèn)題時(shí)表現(xiàn)出了出色的性能。在RF 中,每棵決策樹(shù)都獨(dú)立地為給定的數(shù)據(jù)樣本提供一個(gè)預(yù)測(cè)值,然后將全部k棵決策樹(shù)的預(yù)測(cè)值取平均作為最終的輸出值。這種集成方法在處理高維數(shù)據(jù)和大規(guī)模數(shù)據(jù)時(shí),可以有效地應(yīng)對(duì)過(guò)擬合和欠擬合的問(wèn)題。決策樹(shù)構(gòu)建算法采用Breiman 提出的CART 算法[23],其基本步驟為
(1)特征選擇。CART 算法對(duì)于每一個(gè)節(jié)點(diǎn)都需要選擇最佳的特征進(jìn)行分裂,通常基于基尼系數(shù)來(lái)進(jìn)行特征選擇,以實(shí)現(xiàn)節(jié)點(diǎn)的最佳分裂。
(2)節(jié)點(diǎn)分裂。根據(jù)選定的特征,對(duì)節(jié)點(diǎn)進(jìn)行分裂,使得各個(gè)子節(jié)點(diǎn)中的樣本盡可能屬于同一類(lèi)別(分類(lèi)樹(shù))或者具有相似的回歸值(回歸樹(shù))。
(3)遞歸構(gòu)建。重復(fù)對(duì)子節(jié)點(diǎn)進(jìn)行上述分裂操作,直到滿(mǎn)足停止條件。如在分類(lèi)樹(shù)中,可以設(shè)定樹(shù)的最大深度或者節(jié)點(diǎn)中樣本數(shù)量的最小閾值;在回歸樹(shù)中,也可以設(shè)置類(lèi)似的停止條件。
(4)剪枝。構(gòu)建完整的決策樹(shù)后,可以對(duì)樹(shù)進(jìn)行剪枝,通過(guò)降低樹(shù)的復(fù)雜度來(lái)提高模型的泛化能力,防止過(guò)擬合。
根據(jù)本文提出的特征變量擴(kuò)展方法,可以將疊前地震反演得到的縱波速度、橫波速度和密度數(shù)據(jù)體生成222 個(gè)特征變量作為RF 回歸器的輸入數(shù)據(jù)。然而,擴(kuò)展彈性阻抗變量之間本身也具有一定的相關(guān)性,大量信息重復(fù)的特征變量可能帶來(lái)過(guò)多的冗余信息和計(jì)算消耗。有些特征變量可能是極為敏感的指標(biāo)參數(shù),而有的特征變量可能包含的有效信息很少,選擇對(duì)目標(biāo)回歸貢獻(xiàn)較大的特征變量可以加快過(guò)程并提高預(yù)測(cè)的準(zhǔn)確性。
RF 的另一個(gè)優(yōu)點(diǎn)是可以提供變量重要性(Variable important,VI)的衡量標(biāo)準(zhǔn),根據(jù)特征變量的預(yù)測(cè)能力進(jìn)行排序[35]。用隨機(jī)森林進(jìn)行特征重要性評(píng)估的思想就是衡量每個(gè)特征在隨機(jī)森林中的每棵樹(shù)上所做的貢獻(xiàn),取所有樹(shù)的平均貢獻(xiàn)來(lái)比較特征變量的貢獻(xiàn)大小。在RF 中,有Gini 重要性和互換精度重要性2 種得分評(píng)價(jià)標(biāo)準(zhǔn),對(duì)于含氣飽和度預(yù)測(cè)這類(lèi)回歸問(wèn)題宜采用互換精度重要性來(lái)計(jì)算VI 得分。根據(jù)Bootstrap 采樣思想,每棵決策樹(shù)都有子樣本集37.8%的“袋外”樣本在構(gòu)建過(guò)程中并沒(méi)有使用,可以被用來(lái)計(jì)算特征變量的重要性。
第i棵樹(shù),第j個(gè)特征變量Xj的VI 得分[35]為
取所有樹(shù)的平均VI 得分作為變量的最終VI得分,根據(jù)VI 得分的排名,選擇排名靠前的特征變量作為RF 回歸器構(gòu)建的最終使用特征變量。
2 實(shí)施流程
基于特征變量擴(kuò)展的含氣飽和度隨機(jī)森林預(yù)測(cè)方法在實(shí)際生產(chǎn)中的實(shí)施流程如圖2 所示,主要有4 個(gè)步驟:
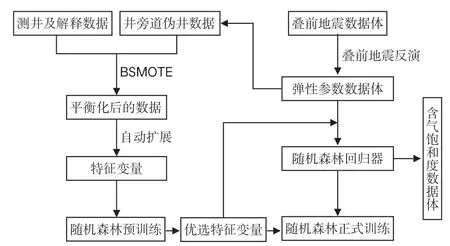
圖2 隨機(jī)森林含氣飽和度預(yù)測(cè)流程Fig.2 Workflow of gas saturationprediction by random forests
(1)訓(xùn)練樣本平衡化處理。抽取井旁道縱波速度、橫波速度和密度3 個(gè)彈性參數(shù)的疊前地震反演結(jié)果作為基本特征變量樣本,根據(jù)測(cè)井有利儲(chǔ)層分類(lèi)解釋結(jié)果,采用BSMOTE 方法對(duì)基本特征變量和對(duì)應(yīng)的含氣飽和度樣本進(jìn)行平衡化處理。
(2)特征變量樣本擴(kuò)展。對(duì)平衡化后的彈性參數(shù)樣本應(yīng)用表1 所列擴(kuò)展方式進(jìn)行自動(dòng)擴(kuò)展并編號(hào),得到擴(kuò)展的特征變量樣本。
(3)隨機(jī)森林回歸器訓(xùn)練。分為預(yù)訓(xùn)練和正式訓(xùn)練,先開(kāi)展RF 預(yù)訓(xùn)練,根據(jù)式(3)對(duì)各特征變量進(jìn)行重要性排名,優(yōu)選排名靠前的特征變量,輸入優(yōu)選的特征變量樣本和目標(biāo)物性參數(shù)標(biāo)簽,進(jìn)行RF 正式訓(xùn)練,得到最優(yōu)的回歸器。
(4)含氣飽和度預(yù)測(cè)。根據(jù)步驟(3)中優(yōu)選的特征變量的編號(hào),依據(jù)表1 中對(duì)應(yīng)的擴(kuò)展方式,將彈性參數(shù)疊前地震反演成果數(shù)據(jù)體整體轉(zhuǎn)換為特征變量數(shù)據(jù)體,輸入到訓(xùn)練好的隨機(jī)森林回歸器中,輸出預(yù)測(cè)的含氣飽和度數(shù)據(jù)體。
3 應(yīng)用實(shí)例
以中國(guó)西部某天然氣藏研究區(qū)為例驗(yàn)證新方法的有效性。該研究區(qū)氣藏埋藏較深、分布廣泛、有效儲(chǔ)層厚度大。早期部署的探井獲得高產(chǎn)工業(yè)氣流,顯示出該區(qū)域氣藏巨大的資源潛力,但隨著探井部署的增多,發(fā)現(xiàn)產(chǎn)能橫向差異較大,鉆井風(fēng)險(xiǎn)大,需要精細(xì)刻畫(huà)有利氣藏的分布。然而,該區(qū)域氣藏經(jīng)過(guò)多期礦物轉(zhuǎn)化,巖石礦物的組成和孔隙結(jié)構(gòu)相比淺層氣藏更加復(fù)雜,彈性參數(shù)不僅與含氣飽和度有關(guān),還受巖相、孔隙度和孔隙結(jié)構(gòu)的影響,巖石物理模型難以準(zhǔn)確建立,導(dǎo)致常規(guī)基于巖石物理模型的含氣飽和度反演方法的精度較低,難以有效指導(dǎo)勘探井位的部署。因此,有必要嘗試基于數(shù)據(jù)驅(qū)動(dòng)的方式獲取高精度含氣飽和度信息來(lái)減少勘探風(fēng)險(xiǎn)。
3.1 單井分析
圖3 為研究區(qū)某重點(diǎn)井的含氣飽和度測(cè)井解釋曲線(xiàn)及從縱波速度、橫波速度和密度疊前地震反演數(shù)據(jù)體中提取的對(duì)應(yīng)井旁道偽井曲線(xiàn)。可以看到含氣飽和度解釋曲線(xiàn)與縱波速度、橫波速度和密度偽井曲線(xiàn)間并沒(méi)有直觀(guān)的線(xiàn)性關(guān)系,利用簡(jiǎn)單的數(shù)學(xué)公式難以將彈性參數(shù)進(jìn)一步轉(zhuǎn)換為含氣飽和度。

圖3 中國(guó)西部某天然氣藏含氣飽和度測(cè)井解釋曲線(xiàn)及井旁道彈性參數(shù)反演曲線(xiàn)Fig.3 Log interpretation curve of gas saturation and inversion curves of elastic parameters from the uphole trace in a natural gas reservoir in western China
圖4 為不同角度的EEI曲線(xiàn)和利用圖3 中縱波速度、橫波速度和密度曲線(xiàn)計(jì)算得到的拉梅阻抗(拉梅參數(shù)×密度)λρ曲線(xiàn)。λρ通常被用作反映巖石剛度變化的巖性和流體識(shí)別指標(biāo)[36]。可以觀(guān)察到,不同角度的EEI曲線(xiàn)具有不同的變化形態(tài),突出的特征也不同,當(dāng)角度為20°時(shí),EEI(20°)與λρ曲線(xiàn)非常相似,相關(guān)系數(shù)達(dá)到0.97,表明EEI隨著角度的變化確實(shí)可以逼近一些常見(jiàn)的彈性參數(shù)。因此,本文提出的利用EEI隨角度變化的這種特性開(kāi)展特征變量的擴(kuò)展具有一定現(xiàn)實(shí)依據(jù)。
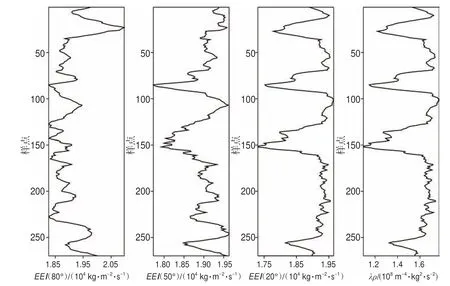
圖4 中國(guó)西部某天然氣藏3 個(gè)不同角度的EEI 曲線(xiàn)與拉梅阻抗曲線(xiàn)Fig.4 Well curves of EEI withthree different angles andLame impedance curve in a natural gas reservoir in western China
根據(jù)表1 的生成方式,得到222 個(gè)擴(kuò)展變量進(jìn)行VI 排序。如圖5 所示,并非每個(gè)變量對(duì)含氣飽和度預(yù)測(cè)都很重要,許多變量的重要性非常低,這表明存在信息冗余。最高、最低VI 變量分別為EEI(20°)-2和EEI(50°)2,將這2 個(gè)變量對(duì)應(yīng)的特征變量曲線(xiàn)與測(cè)井解釋的含氣飽和度曲線(xiàn)進(jìn)行對(duì)比(圖6)可知,最高VI 特征變量曲線(xiàn)大致上可以反映含氣飽和度曲線(xiàn)的變化,而最低VI 特征變量曲線(xiàn)與含氣飽和度曲線(xiàn)差異大,證明了VI 的可靠性。
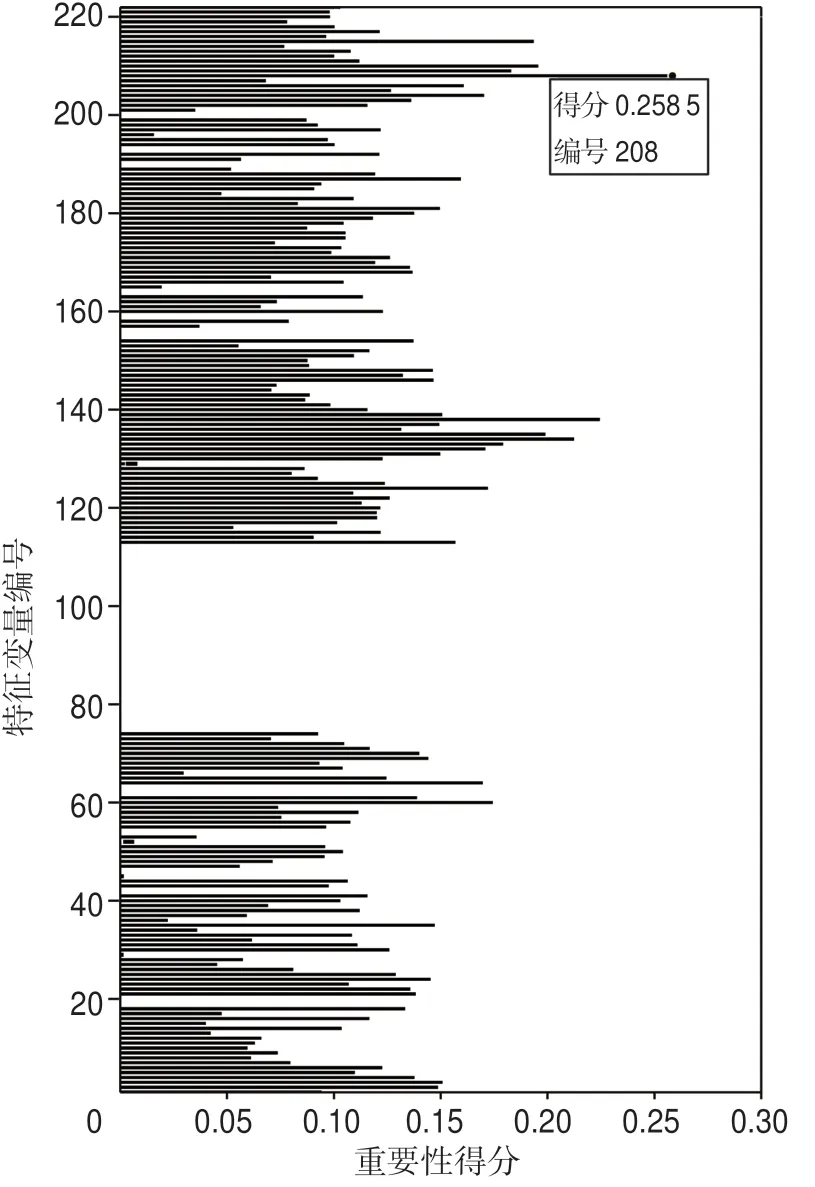
圖5 中國(guó)西部某天然氣藏含氣飽和度隨機(jī)森林預(yù)測(cè)時(shí)222 個(gè)擴(kuò)展特征變量的重要性得分情況Fig.5 Importance scores of 222 extended feature variables in random forests prediction of gas saturation in a natural gas reservoir in western China
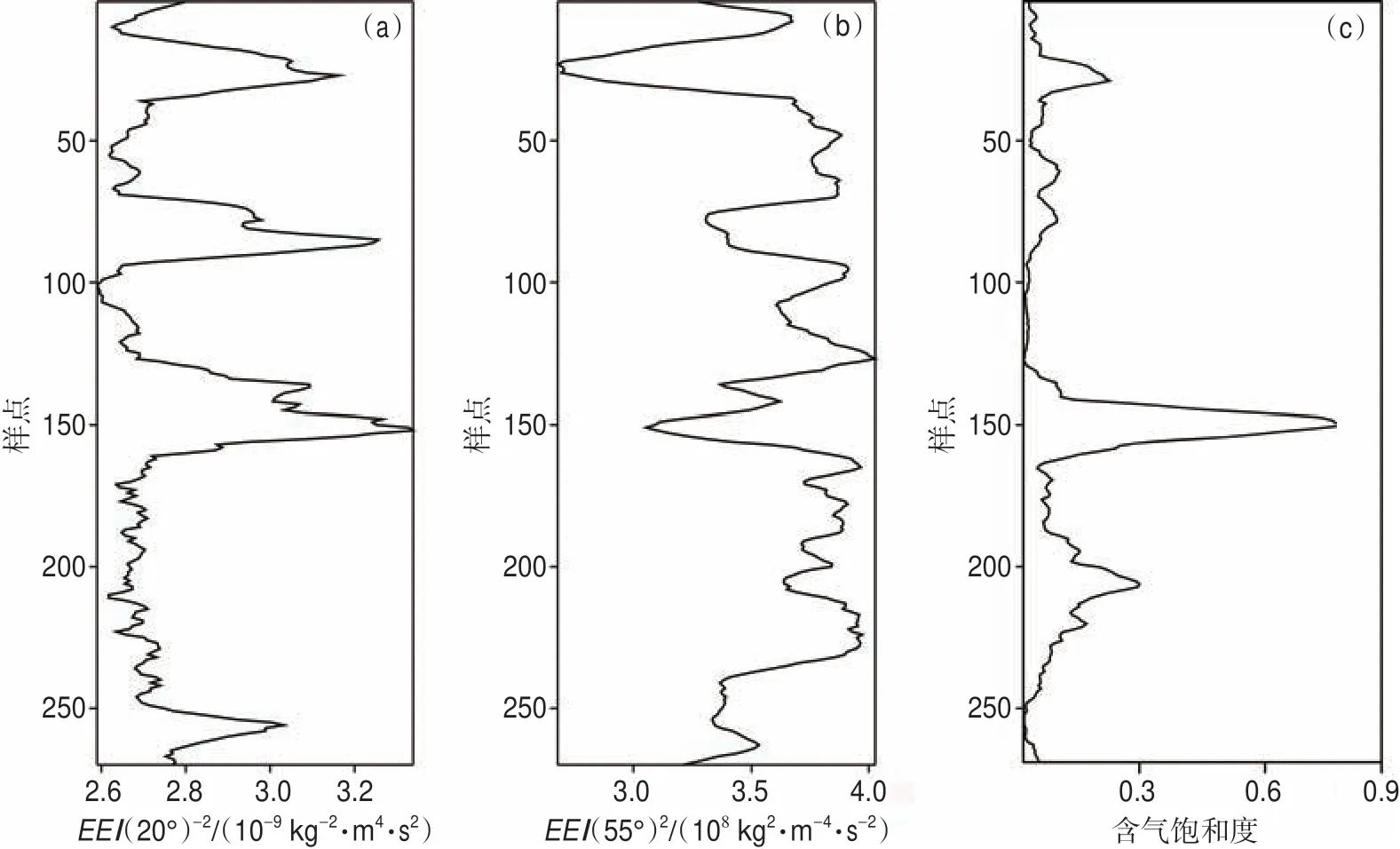
圖6 中國(guó)西部某天然氣藏含氣飽和度隨機(jī)森林預(yù)測(cè)時(shí)最高(a)、最低(b)重要性特征變量曲線(xiàn)與含氣飽和度(c)形態(tài)對(duì)比Fig.6 Curve shape comparison of the highest(a)and lowest(b)importancefeature variable curves predicted by random forestsand logging interpretation curves gas saturation(c)in a natural gas reservoir in western China
綜上所述,與λρ相關(guān)性最高的特征變量曲線(xiàn)(參見(jiàn)圖4)、重要性最高的特征變量曲線(xiàn)(圖6)的整體形態(tài)均與密度曲線(xiàn)相似(整體方向上有所不同),這也說(shuō)明了利用擴(kuò)展特征屬性能夠代替常規(guī)需要人工一一提取或轉(zhuǎn)換計(jì)算的彈性參數(shù)。本文中提取的擴(kuò)展策略能夠得到222 種擴(kuò)展屬性供優(yōu)選作為含氣性敏感的特征變量,但并不能只用一個(gè)擴(kuò)展特征變量就預(yù)測(cè)含氣飽和度,即使是重要性最高的特征變量曲線(xiàn)與含氣飽和度曲線(xiàn)在細(xì)節(jié)上仍有一定的差異,還需要其他特征變量來(lái)參與修正。
按照變量重要性從高到低的排序,依次加入到RF 訓(xùn)練中,如圖7 所示,僅以重要性最高的特征變量進(jìn)行單個(gè)訓(xùn)練,預(yù)測(cè)的含氣飽和度曲線(xiàn)與真實(shí)含氣飽和度曲線(xiàn)的相關(guān)系數(shù)為0.47,隨著特征變量數(shù)量的增加,相關(guān)系數(shù)先上升,當(dāng)數(shù)量達(dá)到約20 個(gè)時(shí)(如圖7 中紅點(diǎn)所示),相關(guān)系數(shù)趨于平緩,約為0.90。因此,可以認(rèn)為在本例中只需前20 個(gè)特征變量即可滿(mǎn)足訓(xùn)練要求。
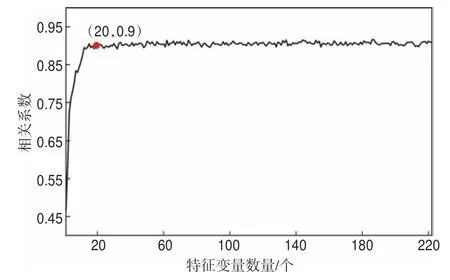
圖7 中國(guó)西部某天然氣藏基于特征變量擴(kuò)展的含氣飽和度隨機(jī)森林預(yù)測(cè)結(jié)果和含氣飽和度測(cè)井解釋的相關(guān)系數(shù)-特征變量數(shù)量曲線(xiàn)Fig.7 Variations in the corresponding correlation coefficient between the gas saturation predicted by random forestsand the the real gas saturation curve in relation to the number of variables in a natural gas reservoir in western China
將未平衡化的全部222 個(gè)變量、VI 前20 個(gè)變量和11 個(gè)常用彈性參數(shù)分別作為隨機(jī)森林回歸器訓(xùn)練的特征變量,預(yù)測(cè)得到的含氣飽和度曲線(xiàn)如圖8 所示。全部222 個(gè)變量的預(yù)測(cè)曲線(xiàn)與VI 前20個(gè)特征變量的預(yù)測(cè)曲線(xiàn)幾乎重合,且與真實(shí)含氣飽和度曲線(xiàn)的吻合程度較高,明顯優(yōu)于利用11 個(gè)常用彈性參數(shù)參與訓(xùn)練的預(yù)測(cè)結(jié)果,但在高含氣飽和度區(qū)間(如圖8 中黑色箭頭所示)有明顯的偏差。分析認(rèn)為處于高含氣飽和度區(qū)間段的樣本占比較小,導(dǎo)致RF 回歸器的訓(xùn)練偏向低含氣飽和度樣本。因此,需要對(duì)參與訓(xùn)練的樣本進(jìn)行平衡化處理。

圖8 中國(guó)西部某天然氣藏3 種不同的特征變量的含氣飽和度隨機(jī)森林預(yù)測(cè)結(jié)果與含氣飽和度測(cè)井解釋曲線(xiàn)對(duì)比Fig.8 Comparison among the gas saturation curvespredicted by random forestswith three different feature variables and the real gas saturationcurve in a natural gas reservoir in western China
利用BSMOTE 方法對(duì)預(yù)測(cè)的含氣飽和度曲線(xiàn)及其對(duì)應(yīng)的特征變量進(jìn)行平衡化處理后,原始樣本中低含氣飽和度的樣本數(shù)量未發(fā)生改變,而高含氣飽和度的樣本數(shù)量明顯增加,且取值更加豐富,高、低含氣飽和度樣本數(shù)量大致達(dá)到平衡(圖9)。
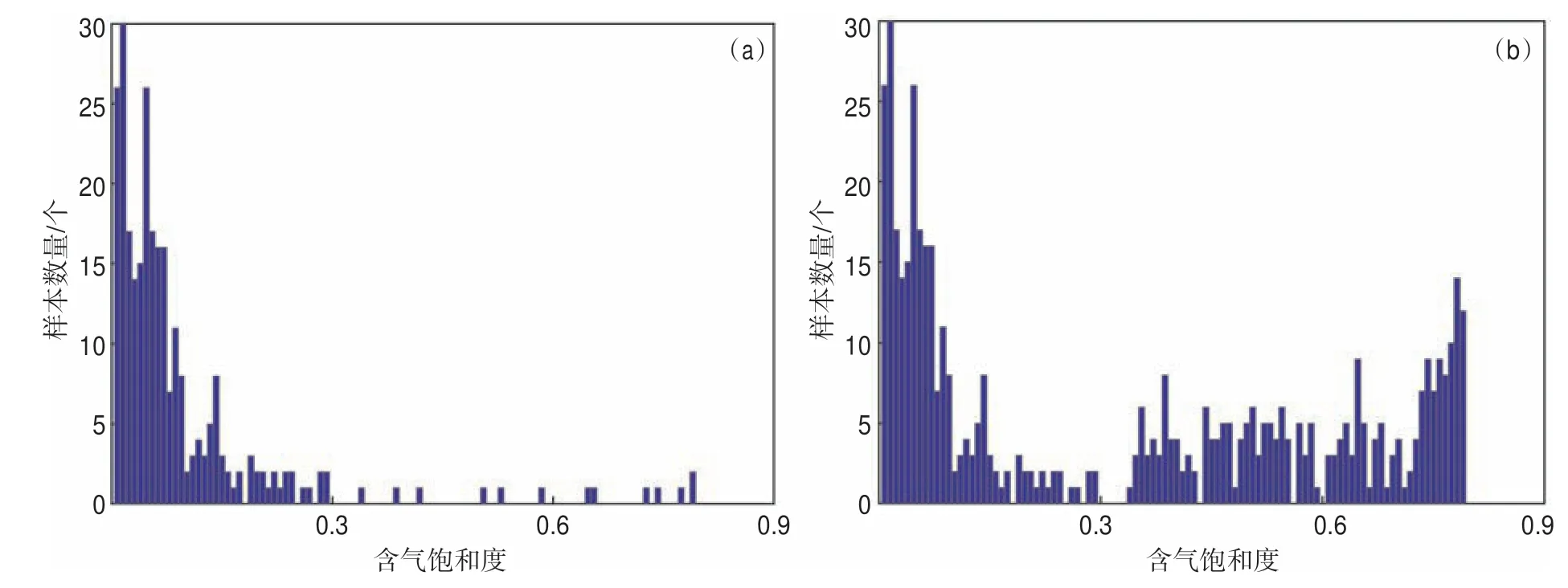
圖9 中國(guó)西部某天然氣藏含氣飽和度樣本平衡化前(a)、后(b)直方統(tǒng)計(jì)Fig.9 Histogram ofgas saturation before(a)and after sample balancing(b)in a natural gas reservoir in western China
對(duì)經(jīng)過(guò)BSMOTE 處理后的樣本進(jìn)行訓(xùn)練,采用VI 排名前20 的特征變量參與訓(xùn)練,高含氣飽和度區(qū)間的預(yù)測(cè)結(jié)果有明顯的改善(圖10),相關(guān)系數(shù)由平衡前的0.903 2 上升到平衡后的0.985 5。這也說(shuō)明了對(duì)于含氣飽和度這類(lèi)不平衡數(shù)據(jù)的預(yù)測(cè),樣本平衡問(wèn)題是不可忽視的。
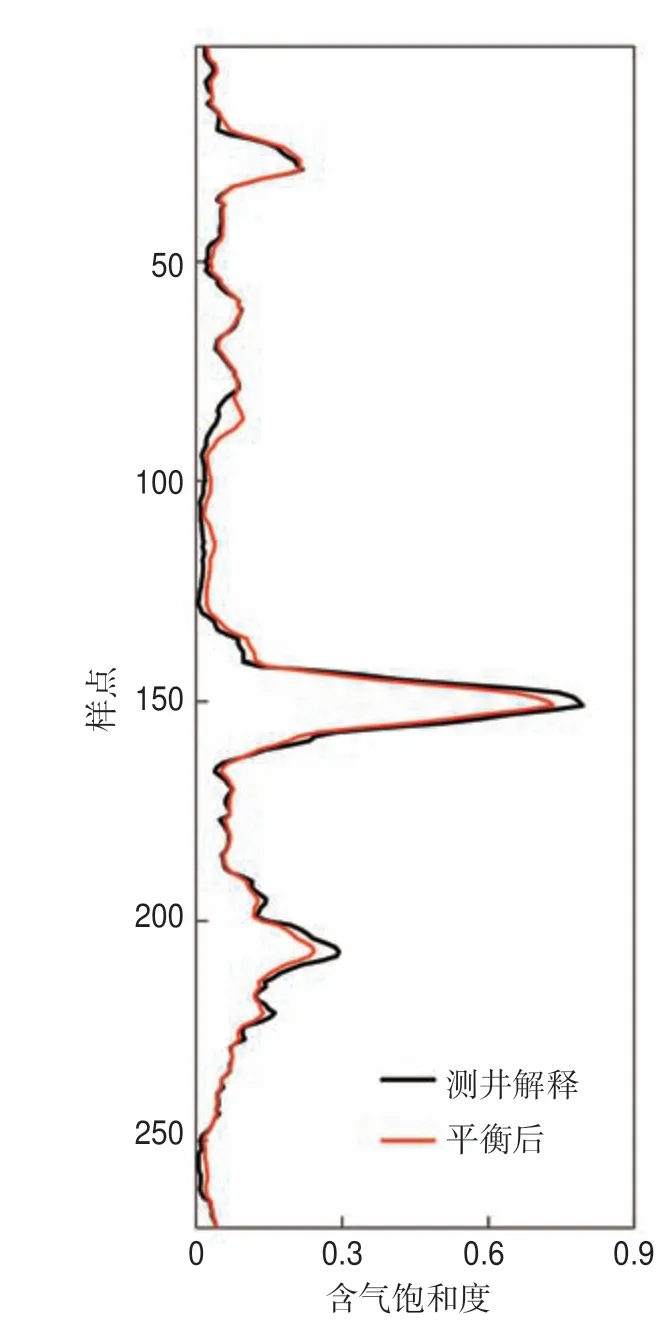
圖10 中國(guó)西部某天然氣藏樣本平衡化后含氣飽和度隨機(jī)森林預(yù)測(cè)結(jié)果與含氣飽和度測(cè)井解釋曲線(xiàn)對(duì)比Fig.10 Comparison between the gassaturation curves predicted by random forestsafter sample balancing and the real gas saturation curve in a natural gas reservoir in western China
3.2 二維資料應(yīng)用分析
研究區(qū)前期勘探經(jīng)驗(yàn)和綜合分析表明,含氣飽和度與其他物性參數(shù)具有較好的線(xiàn)性關(guān)系,找到高含氣飽和度區(qū)域通常就意味著能找到有利氣藏。因而,生產(chǎn)上需要利用地震儲(chǔ)層預(yù)測(cè)方法優(yōu)選含氣飽和度較高的目標(biāo)區(qū)域?yàn)殂@井的軌跡設(shè)計(jì)提供依據(jù)。
研究區(qū)含氣飽和度測(cè)井解釋結(jié)果(圖11 中黑色曲線(xiàn))顯示目的層上部發(fā)育1 套含氣飽和度較低的差氣層(圖11 中藍(lán)色箭頭所示),下部發(fā)育1 套含氣飽和度較高的高產(chǎn)氣層(圖11 中紅色箭頭所示)。將區(qū)內(nèi)A 井和C 井作為訓(xùn)練參與井,B 井作為驗(yàn)證井,分別采用本文方法和常規(guī)方法(基于常規(guī)未平衡化的11 個(gè)彈性參數(shù)作為RF 的輸入)預(yù)測(cè)含氣飽和度并繪制連井剖面(圖11)。結(jié)果顯示,采用常規(guī)方法解釋該區(qū)發(fā)育上、下2 套含氣飽和度較高且值相近的儲(chǔ)層(圖11a 中虛線(xiàn)框所示),很容易被解釋為具備同一品質(zhì)的儲(chǔ)層,而本文方法解釋的這2 套儲(chǔ)層含氣飽和度差異較大,下部的儲(chǔ)層(圖11b 中虛線(xiàn)框所示)含氣飽和度明顯更高,這一結(jié)果與測(cè)井解釋結(jié)果一致。
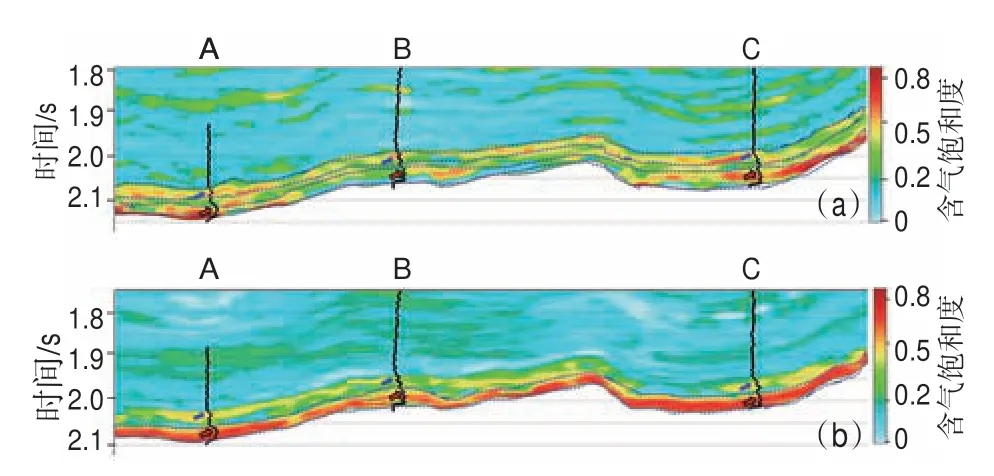
圖11 常規(guī)方法(a)與基于特征變量擴(kuò)展的隨機(jī)森林法(b)預(yù)測(cè)的含氣飽和度剖面Fig.11 Gas saturation profiles predicted by conventional method(a)and random forestswith feature variable extension(b)
為了進(jìn)一步驗(yàn)證本文方法的正確性,抽取驗(yàn)證井B 井的井旁道反演結(jié)果(圖12)可知,本文方法預(yù)測(cè)結(jié)果整體上與含氣飽和度測(cè)井解釋曲線(xiàn)吻合較好,而常規(guī)方法在高含氣飽和度部位出現(xiàn)了較大的偏差,很可能會(huì)被錯(cuò)誤地解釋為差氣層。
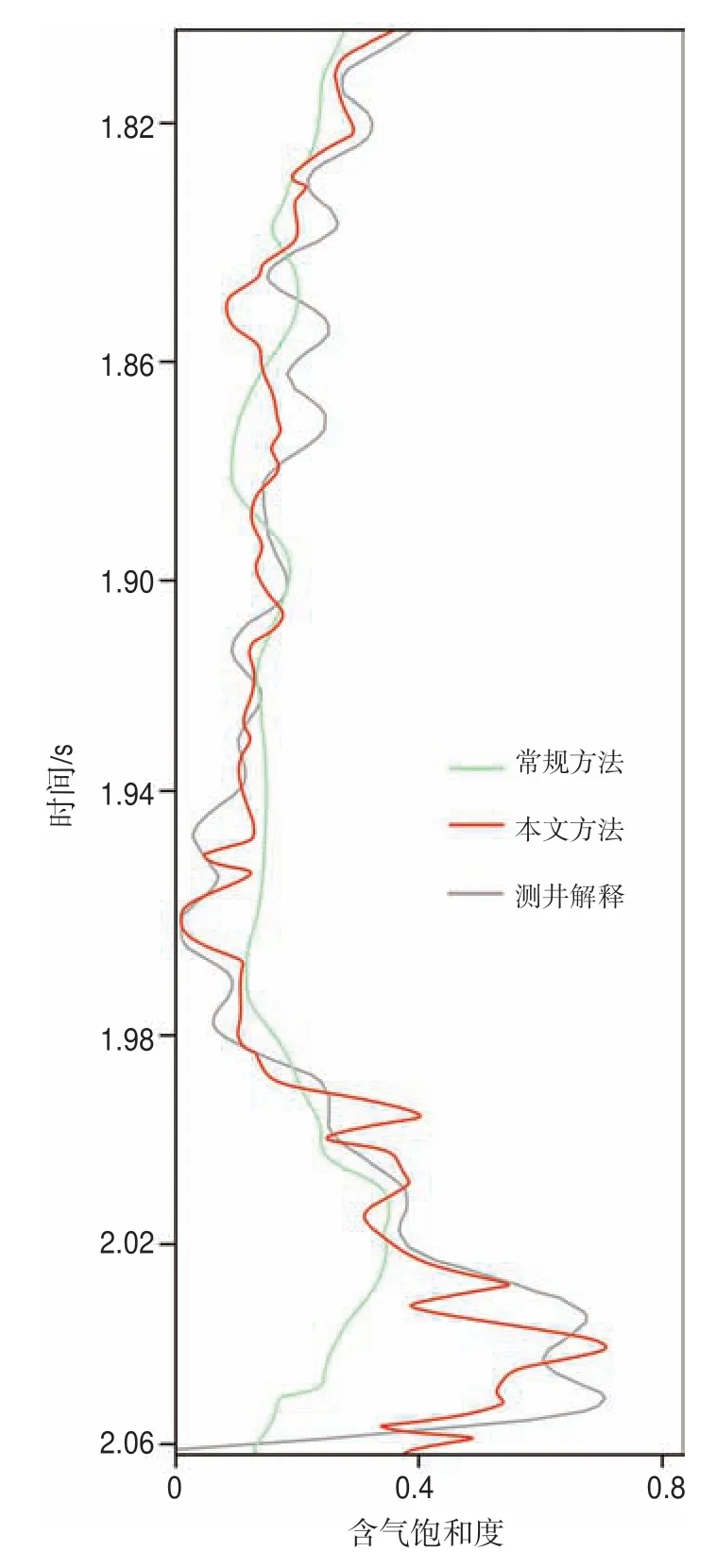
圖12 采用常規(guī)方法和基于特征變量擴(kuò)展的隨機(jī)森林法預(yù)測(cè)的驗(yàn)證井含氣飽和度對(duì)比Fig.12 Comparison of gas saturation of validation well predicted by conventional methods and random forestswith with feature variable extension
4 結(jié)論
(1)對(duì)于含氣飽和度這類(lèi)連續(xù)型數(shù)值回歸問(wèn)題,基于數(shù)據(jù)驅(qū)動(dòng)的機(jī)器學(xué)習(xí)方法為取得最佳性能,需要大量的特征變量作為訓(xùn)練集,利用擴(kuò)展彈性阻抗自動(dòng)生成222 個(gè)擴(kuò)展彈性屬性作為機(jī)器學(xué)習(xí)的訓(xùn)練集,能夠大幅減少特征變量提取和優(yōu)選的人工工作量。
(2)大量信息重復(fù)的特征變量會(huì)帶來(lái)過(guò)多的冗余信息和計(jì)算消耗,利用隨機(jī)森林預(yù)訓(xùn)練對(duì)特征變量進(jìn)行重要性排名,優(yōu)選對(duì)含氣飽和度預(yù)測(cè)重要性較高的特征變量參與正式訓(xùn)練,能夠有效減少信息的冗余。
(3)“不平衡數(shù)據(jù)”特征會(huì)惡化機(jī)器學(xué)習(xí)算法的性能,而復(fù)雜氣藏的含氣飽和度的取值分布往往也具有“不平衡”特征,引入邊界合成少數(shù)類(lèi)過(guò)采樣技術(shù)能有效解決儲(chǔ)層和非儲(chǔ)層的含氣飽和度樣本取值分布不平衡導(dǎo)致的隨機(jī)森林回歸器訓(xùn)練偏倚的問(wèn)題。
(4)基于特征變量擴(kuò)展的含氣飽和度隨機(jī)森林預(yù)測(cè)方法在實(shí)際資料應(yīng)用中能有效增強(qiáng)隨機(jī)森林算法在含氣飽和度地震預(yù)測(cè)方面的能力,且特征變量擴(kuò)展策略對(duì)于孔隙度、有機(jī)質(zhì)含量等其他氣藏物性參數(shù)的機(jī)器學(xué)習(xí)預(yù)測(cè)同樣有借鑒意義。
猜你喜歡
數(shù)學(xué)小靈通·3-4年級(jí)(2024年2期)2024-05-15 02:02:28
中學(xué)生數(shù)理化(高中版.高考數(shù)學(xué))(2022年3期)2022-04-26 14:04:16
數(shù)學(xué)年刊A輯(中文版)(2020年1期)2020-05-19 00:30:36
空間科學(xué)學(xué)報(bào)(2020年2期)2020-04-01 03:50:40
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
中等數(shù)學(xué)(2019年8期)2019-11-25 01:38:14
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
新聞傳播(2018年11期)2018-08-29 08:15:24
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
廣西科技大學(xué)學(xué)報(bào)(2016年1期)2016-06-22 13:10:38

- 巖性油氣藏的其它文章
- 智能物探技術(shù)的過(guò)去、現(xiàn)在與未來(lái)
- 基于SSOM 的流動(dòng)單元?jiǎng)澐址椒吧a(chǎn)應(yīng)用
——以渤海灣盆地F 油田古近系沙三中亞段湖底濁積水道為例 - 鄂爾多斯盆地大牛地氣田二疊系山西組砂體疊置模式及油氣開(kāi)發(fā)意義
- 四川盆地簡(jiǎn)陽(yáng)地區(qū)二疊系火山碎屑巖儲(chǔ)層特征與成巖演化
- 塔里木盆地順北1 號(hào)斷裂帶奧陶系碳酸鹽巖儲(chǔ)層結(jié)構(gòu)表征及三維地質(zhì)建模
- 濱里海盆地東緣北特魯瓦油田石炭系碳酸鹽巖儲(chǔ)層裂縫網(wǎng)絡(luò)連通性評(píng)價(jià)