基于深度注意力的融合全局和語義特征的圖像描述模型*
2024-03-14 08:37:36及昕浩彭玉青
網(wǎng)絡(luò)安全與數(shù)據(jù)管理 2024年2期
及昕浩,彭玉青
(河北工業(yè)大學(xué) 人工智能與數(shù)據(jù)科學(xué)學(xué)院,天津 300401)
0 引言
圖像描述[1-2]是一種使用自然語言描述圖像內(nèi)容的任務(wù),是一項涉及計算機視覺領(lǐng)域和自然語言處理領(lǐng)域的跨領(lǐng)域研究內(nèi)容。目前大多數(shù)方法使用卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Network,CNN)編碼圖像以提取圖像特征,然后使用Transformer網(wǎng)絡(luò)結(jié)構(gòu)來解析圖像特征并生成描述語句。Pan等人[3]提出了X-Linear注意力塊來捕獲單或多模態(tài)之間的二階相互作用,并將其集成到Transformer編碼器和解碼器中。Cornia等人[4]在Transformer編碼器和解碼器中設(shè)計了類似網(wǎng)格的連接,以利用編碼器的低級和高級特征。多數(shù)研究者針對Transformer網(wǎng)絡(luò)結(jié)構(gòu)進(jìn)行改進(jìn),沒有關(guān)注CNN提取到的圖像特征其對應(yīng)的感受野是均勻的網(wǎng)格,難以明顯地關(guān)注圖像中對象內(nèi)容信息的問題。此外Transformer模型中的注意力機制僅僅是隱式地計算單個區(qū)域和其他區(qū)域的相似性,無法捕捉長距離的關(guān)系。
為了解決以上問題,本文提出了融合全局和語義特征的圖像描述模型。該模型構(gòu)建語義信息提取器,用語義信息來表示圖像中關(guān)鍵的對象內(nèi)容。同時提出多元特征融合模塊,結(jié)合全局和語義特征來更加準(zhǔn)確地表示圖像內(nèi)容。此外,設(shè)計一種新的深度注意力機制來加強注意力機制的計算,增強圖像特征與文本特征的交互,提高描述語句的準(zhǔn)確性。
1 相關(guān)工作
基于深度學(xué)習(xí)的圖像描述方法是研究的重要方向,這類方法主要經(jīng)歷了兩個階段。第一階段采用編碼器-解碼器框架,使用CNN作為編碼器,從圖像中提取固定大小的網(wǎng)格特征來表示視覺信息,然后使用RNN或者LSTM作為解碼器解析圖像特征并生成描述語句。Anderson等[5]在此框架基礎(chǔ)上利用目標(biāo)檢測技術(shù)從圖像中提取實體目標(biāo)來表示圖像內(nèi)容。第二階段,由于Transformer在自然語言處理領(lǐng)域取得顯著突破,研究者們將Transformer引入圖像領(lǐng)域,許多基于Transformer改進(jìn)的模型在圖像描述效果上也有顯著提升。Cornia[4]等人提出在圖像編碼階段加入記憶向量,編碼層和解碼層以網(wǎng)狀連接來利用低級和高級特征,顯著提升了圖像描述的效果。Guo等人[6]通過使用幾何信息來增強區(qū)域級特征,然后將這些特征輸入到Transformer模型中,取得了不錯的結(jié)果。Li等人[7]利用圖像場景圖實現(xiàn)圖像描述。從這些研究的成果來看,如何提取幾何特征,如何加入更多形式的圖像特征來更加準(zhǔn)確地表示圖像內(nèi)容,使得模型更好地理解圖像,進(jìn)而生成更加準(zhǔn)確而自然的描述語句,是一個值得深入研究的方向。
受文獻(xiàn)[7]的工作啟發(fā),本文模型在場景圖的基礎(chǔ)上進(jìn)一步提取語義信息并結(jié)合全圖特征進(jìn)行圖像描述。具體工作如下:
(1)提出語義提取模塊,對場景信息進(jìn)行編碼;
(2)提出多元特征融合模塊,將全局特征和語義特征進(jìn)行融合;
(3)提出深度自注意力機制,使圖像特征和文本特征更好地交互。
2 總體框架
本文提出的模型分為兩個部分:圖像特征提取部分和預(yù)測描述語句生成部分。圖1為該模型的結(jié)構(gòu)圖。在圖像特征提取部分,圖片經(jīng)過ResNet101[8]網(wǎng)絡(luò)獲得全局特征,經(jīng)過Faster R-CNN[9]檢測得到圖像中的對象、屬性以及對象之間的關(guān)系信息,并經(jīng)過語義信息提取模塊進(jìn)行語義提取,獲得更高級的語義信息,全局特征和圖像的語義信息經(jīng)過多特征融合模塊,輸入到預(yù)測描述語句生成部分。在描述語句生成部分,圖像特征經(jīng)過編碼器處理,編碼后的圖像特征和文本特征在基于深度注意力的解碼器中進(jìn)行交互,生成預(yù)測的描述語句。

圖1 融合全局和語義特征的圖像描述模型結(jié)構(gòu)圖
2.1 語義信息提取模塊
為了解決傳統(tǒng)CNN編碼器在識別圖像特征方面的局限性,本文加入對象信息來使模型關(guān)注圖像中更為重要的區(qū)域。對象信息包括對象區(qū)域在圖像中的位置、對象之間的關(guān)系等信息。經(jīng)過研究分析,本文認(rèn)為Faster R-CNN得到的對象信息只是低階的對象信息特征,相較于經(jīng)過ResNet 101網(wǎng)絡(luò)提取的圖像特征比較淺顯,與圖像特征并不在一個維度空間中,需要對對象和位置信息進(jìn)行處理。因此本文提出語義信息提取模塊,將較為淺顯的對象信息——對象及對象之間的幾何關(guān)系重新進(jìn)行編碼,學(xué)習(xí)各對象節(jié)點的上下文感知嵌入向量,提取出更豐富的高級語義信息,使對象信息映射到與全圖特征一樣的空間維度,如圖2所示。

圖2 語義特征提取模塊結(jié)構(gòu)圖
給定一張圖片,本文方法使用Faster R-CNN提取到圖像的對象特征O={O1,O2,…,Oi}、對象屬性A={a1,a2,…,am}和對象位置信息Oi=(xi,yi,wi,hi),對象之間的幾何關(guān)系特征由式(1)計算獲得:
(1)
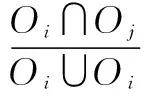

(2)
(3)
(4)
(5)
式中,φO、φA、φR是嵌入層,具體為Linear-FC-ReLU-Dropout層,[·,·]表示拼接操作,f(·)表示FC-ReLU-Dropout操作。
2.2 多元特征融合模塊
對于整張圖像來說,使用卷積神經(jīng)網(wǎng)絡(luò)可以提取到圖像的全局信息和各種對象,獲得較為準(zhǔn)確的背景信息,而使用Faster R-CNN和語義信息提取模塊對圖像進(jìn)行語義特征提取,可以得到更具體、更準(zhǔn)確的對象內(nèi)容和空間信息。基于此,本文在使用卷積神經(jīng)網(wǎng)絡(luò)對圖像編碼的基礎(chǔ)上加入語義特征,提出一種結(jié)合全局信息和包含關(guān)鍵對象內(nèi)容的語義特征的多特征融合模塊,該模塊負(fù)責(zé)融合圖像的全局特征和語義特征,如圖3所示。

圖3 多元特征融合模塊結(jié)構(gòu)圖
本文以與文獻(xiàn)[8]中相同的方式提取圖像的全局特征,用F表示。提取到的語義特征用G表示。為了能夠獲取準(zhǔn)確的背景信息和局部的對象語義信息,全局特征和語義特征經(jīng)過不同的卷積操作映射到統(tǒng)一空間維度,相加操作后得到特征H=(h1,h2,…,hm),以供圖像特征選擇全局信息和語義信息。為了更加充分地利用全局特征和語義特征,本文使用卷積操作對特征H進(jìn)行處理得到特征S,使得全局特征和語義特征進(jìn)行交互,可以有效地捕獲全局上下文關(guān)系。為了實現(xiàn)對全局信息和語義信息的選取,特征S經(jīng)過不同的卷積操作得到向量A和向量B,之后A與B進(jìn)行Softmax操作分別得到全局特征的權(quán)重a和語義特征的權(quán)重b,最后經(jīng)過卷積操作處理之后的全局特征和語義特征分別乘以對應(yīng)的權(quán)重再相加得到多特征融合模塊的輸出,即表示圖像內(nèi)容的視覺特征V,具體過程如下:
H=fF(F)+fG(G)
(6)
S=Conv(H)
(7)
(8)
(9)
V=a·fF(F)+b·fG(G)
(10)
其中,fF和fG分別是對全局特征和語義特征進(jìn)行卷積操作,fA和fB是對特征S進(jìn)行不同的卷積操作。
為了更好地擬合特征,在得到視覺特征V之后,還要經(jīng)過自注意力層、前反饋層和歸一化處理,得到最終的圖像特征X。
2.3 基于深度注意力的解碼器
傳統(tǒng)的注意力機制在圖像文本交互時,需要對整個圖像特征圖進(jìn)行注意力權(quán)重的計算,因此無法捕捉長距離的關(guān)系,基于此,本文提出基于深度注意力的解碼器,如圖4所示。

圖4 基于深度注意力的解碼器
為了緩解無法捕捉長距離關(guān)系的問題,首先對圖像特征X先進(jìn)行一次線性操作得到K,長距離的特征之間可以相互獲得關(guān)系信息。文本特征T經(jīng)過掩碼自注意力和線性操作得到Q。之后圖像特征K與文本特征Q進(jìn)行點積操作,此時圖像特征與文本特征進(jìn)行了對齊,得到圖像特征的注意力值,與文本相對應(yīng)的圖像區(qū)域注意力值越高,與文本不相關(guān)的圖像特征注意力值就越低,最后注意力值與圖像特征V進(jìn)行相乘,此時注意力值高對應(yīng)的圖像區(qū)域就是圖像中最主要的信息,可以進(jìn)而生成更加準(zhǔn)確的描述語句。注意力的計算公式如下:
(11)
式中,Q是文本特征,K和X都是圖像特征,Q,K和X在同一維度,d是其維度。
圖像特征與文本特征交互之后經(jīng)過Softmax操作,全連接層和前反饋層得到最終的描述語句。
3 實驗與分析
3.1 數(shù)據(jù)集和評價指標(biāo)
本文設(shè)計的模型使用Microsoft COCO數(shù)據(jù)集進(jìn)行訓(xùn)練,該數(shù)據(jù)集有123 287張圖片,每張圖片有對應(yīng)的5句英文描述,在實驗過程中,使用Karpathy方法對數(shù)據(jù)集進(jìn)行劃分。在文本處理階段,將訓(xùn)練集中對應(yīng)的描述語句單詞均轉(zhuǎn)化為小寫形式,在建立單詞庫時,用特殊字符“UNK”來標(biāo)記替換詞庫中出現(xiàn)次數(shù)少于等于5的單詞。在驗證和測試階段生成描述語句時,設(shè)置預(yù)測描述語句最多生成16個單詞。
本文采用在圖像描述工作中被廣泛應(yīng)用的BLEU、ROUGE、METEOR和CIDEr評估指標(biāo)來評估生成語句的質(zhì)量。
3.2 實驗結(jié)果與分析
3.2.1 消融實驗
為驗證本文提出的語義提取模塊、多特征融合模塊以及使用深度注意力機制對模型的影響程度,設(shè)置4組消融實驗進(jìn)行分析,表1展示了消融實驗結(jié)果。其中Base表示基線模型,是本文所實現(xiàn)的M2-Transformer模型。DA表示使用基于深度注意力機制的解碼器來對齊視覺和文本特征并生成描述語句的模型。Sem表示在M2-Transformer模型的基礎(chǔ)上加入使用語義提取模塊所提取到的語義特征,全局特征和語義特征相加來表示圖像特征的圖像描述模型。Sem-Fus是加入語義特征之后,使用融合模塊來將全局特征和語義特征進(jìn)行融合操作來表示圖像特征然后輸入到M2-Transformer模型中。Final為本文最終的模型。
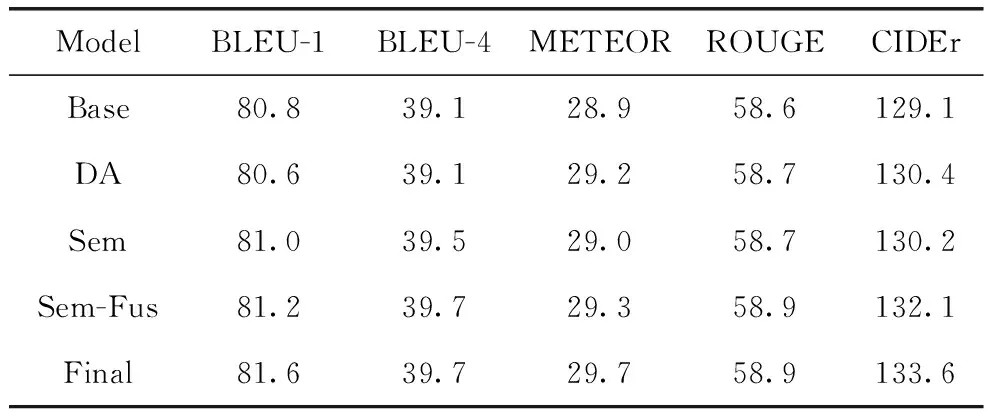
表1 消融實驗結(jié)果
由表1可見,本文所提的模型相比于其他模型達(dá)到最佳,說明所提方法是有效的。具體來說,DA相較于基線模型在METEOR、ROUGE和CIDEr分?jǐn)?shù)上有了顯著提升,說明基于深度注意力的解碼器能更好地對齊圖像和文本特征,生成更加準(zhǔn)確的描述語句。加入語義特征的Sem模型在BLEU分?jǐn)?shù)上明顯高于基線模型,說明生成的描述語句與標(biāo)簽的N元數(shù)組個數(shù)明顯增多,生成單詞的準(zhǔn)確率提高。在加入語義特征的基礎(chǔ)上,使用多特征融合模塊的Sem-Fus模型比只加入語義特征的Sem模型在分?jǐn)?shù)上有了明顯的提升,可以說明多特征融合模塊可以很好地融合全局特征與語義特征,使得模型可以更加準(zhǔn)確地建模背景信息和圖像中關(guān)鍵的對象內(nèi)容信息。
3.2.2 驗證語義提取模塊有效性
為了驗證語義提取模塊的有效性,設(shè)置了兩組對比實驗,如表2所示,第一組實驗使用GCN網(wǎng)絡(luò)對對象節(jié)點進(jìn)行處理,可以感知上下文節(jié)點,從中提取語義信息;第二組就是本文的語義特征提取模塊,在感知上下文節(jié)點的同時,進(jìn)一步提取語義特征。

表2 語義提取模塊的有效性驗證
實驗結(jié)果表明,語義特征提取模塊能夠更好地提取圖像中的語義信息,更加準(zhǔn)確地表示圖像內(nèi)容。
3.2.3 驗證多元特征融合模塊有效性
為了驗證多元特征融合模塊的有效性,本文在使用語義特征提取模塊提取語義特征,并與全局特征進(jìn)行融合的圖像描述模型基礎(chǔ)上,又做了一組實驗,對語義特征和全局特征各添加了一個可學(xué)習(xí)的參數(shù)α1和α2(α1和α2經(jīng)過Softmax化),實驗結(jié)果表明,使用本文提出的多特征融合模塊可以很好地將全局特征和語義特征進(jìn)行融合,使得模型可以更加準(zhǔn)確地建模背景信息和圖像中關(guān)鍵的對象內(nèi)容信息。實驗結(jié)果如表3所示。
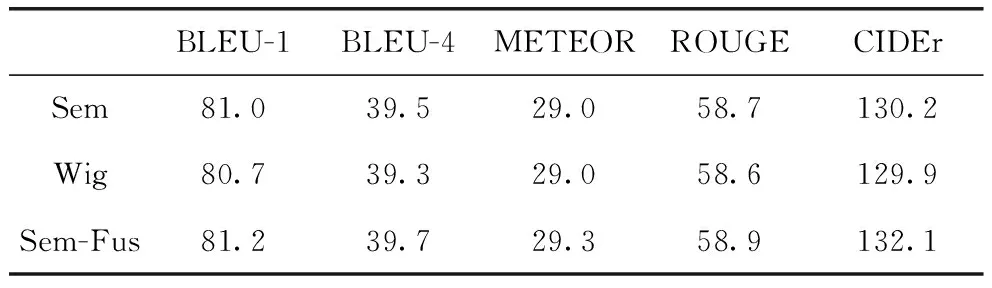
表3 多特征融合模塊的有效性驗證
3.2.4 對比實驗
表4為本文方法與其他圖像描述方法的比較,其中Up-Down[3]首先從預(yù)訓(xùn)練的對象檢測器中提取區(qū)域特征,然后通過注意機制選擇這些特征來生成描述語句;GCN-LSTM[10]和SGAE[11](Scene Graph Auto-Encoder)利用Graph CNN來捕獲圖像中的語義信息和關(guān)系信息,以提高描述語句的質(zhì)量;ORT[12](Object Relation Transformer)對區(qū)域特征之間的空間關(guān)系進(jìn)行建模;VSUA[5]使用圖像語義和幾何圖,利用單詞和不同類別的圖節(jié)點對齊實現(xiàn)圖像描述;M2[4](Meshed-Memory transformer)構(gòu)造用于解碼的網(wǎng)狀連接網(wǎng)絡(luò)結(jié)構(gòu);AST[13]使用自適應(yīng)門控機制來調(diào)整視覺和語義信息之間的注意力。由表4可見,本文模型相比其他模型在各項指標(biāo)上均達(dá)最優(yōu)。

表4 與現(xiàn)有的方法比較
4 結(jié)論
本文分析了現(xiàn)有圖像描述研究中的特征提取方法,根據(jù)全局特征和局部特征的優(yōu)缺點,提出了多特征融合模塊,該方法能有效地融合全局特征和語義特征。實驗結(jié)果表明,經(jīng)過語義提取模塊的語義信息能夠提高模型對圖像內(nèi)容的關(guān)注,同時深度注意力機制也能很好地對齊視覺與文本,生成更準(zhǔn)確的描述語句。
猜你喜歡
今日農(nóng)業(yè)(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學(xué)生數(shù)理化(高中版.高考數(shù)學(xué))(2021年1期)2021-03-19 08:28:38
現(xiàn)代出版(2020年3期)2020-06-20 07:10:34
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現(xiàn)代語文(2016年21期)2016-05-25 13:13:44
大連民族大學(xué)學(xué)報(2015年2期)2015-02-27 08:28:11
 網(wǎng)絡(luò)安全與數(shù)據(jù)管理2024年2期
網(wǎng)絡(luò)安全與數(shù)據(jù)管理2024年2期
- 網(wǎng)絡(luò)安全與數(shù)據(jù)管理的其它文章
- 免于同意之合同所必需規(guī)則的原理探究與落地適用*
- 基于數(shù)據(jù)中臺的高校數(shù)據(jù)服務(wù)體系及快速應(yīng)用構(gòu)建研究
- 基于耗散結(jié)構(gòu)理論的政府?dāng)?shù)據(jù)治理研究*
- 融合電影流行性與觀影時間的協(xié)同過濾算法
- 基于機器學(xué)習(xí)建模的液體火箭發(fā)動機噴管內(nèi)型面優(yōu)化設(shè)計
- 基于區(qū)塊鏈的低軌衛(wèi)星互聯(lián)網(wǎng)跨域數(shù)據(jù)調(diào)度設(shè)計