命名數據網絡中基于分級的數據緩存方法
2024-03-05 12:13:16侯睿沙莫金繼歡
中南民族大學學報(自然科學版) 2024年2期
侯睿,沙莫,金繼歡
(中南民族大學 計算機科學學院,武漢 430074)
命名數據網絡(Named Data Networking, NDN)已經成為未來互聯網體系結構有效的解決方案之一[1].在NDN 中,數據內容請求者(Consumer)將所需數據內容名稱封裝在Interest 包中,發送至NDN 核心網絡去尋找目標信息[2];內容發布者(Publisher)將Consumer 所需數據內容封裝成Data 包對Consumer 做出響應,Data 包沿Interest 包傳輸路徑反方向返回至Consumer,完成數據交互.
NDN 中有三種數據結構,即內容存儲(Content Store, CS)、待定興趣表(Pending Interest Table,PIT)和轉發信息表(Forwarding Information Base,FIB)[3].CS 負責緩存所接收到的Data 包中的數據內容;PIT 用于記錄還未獲得響應的Interest 包封裝的數據內容名稱和接口信息;FIB用于轉發Interest包.
由于NDN 固有的泛在緩存(Cache Everything Everywhere, CEE)機制存在路由器中數據內容多樣性低以及頻繁的數據替換等問題.因此設計一種優化的分布式緩存方法,對降低網絡內緩存冗余度,提高Consumer獲取數據的時間效率有著重要意義.
1 相關研究
針對NDN 中數據內容的緩存問題,PSARAS 等人提出一種基于概率的緩存方法(ProbCache)[4],該方法通過計算傳輸路徑上路由器對數據的緩存概率,并將數據緩存在概率最大的路由器上,以此減少網絡的內容副本.但基于概率緩存方法存在較大的隨機性,缺乏對多次被請求的數據內容(內容熱度)的考慮;LAOUTARIS 等人提出一種下一跳緩存方法(Leave Copy Down, LCD)[5]將數據緩存在數據返回路徑上命中路由器的下一跳路由器,使得請求頻率高的數據緩存在靠近Consumer 的路由器中.但隨著對同一內容的請求增多,傳輸路徑的路由器中會緩存相同的內容副本,沒有從根本上解決數據冗余的問題;ZHANG等人提出一種基于數據請求節點的就近緩存方法(Consumer-based Proximity Caching Algorithm, CPCA)[6],將熱度高的數據內容優先緩存在靠近Consumer 的路由器中,提高緩存命中率,同時降低熱度高的數據內容的傳輸跳數,該方法的不足在于靠近Consumer 的路由器存在高頻替換的問題;CHAI 等人提出一種基于介數的緩存方法(Betw)[7],該方法首先為路由器定義了介數概念,即經過某一路由器的傳輸路徑越多,該路由器的介數越大,之后將數據內容緩存在介數最大的路由器上,這種方法降低了網絡的數據冗余,但數據內容都緩存在介數最大的路由器中時,由于CS的緩存容量有限,熱度高的數據內容可能會被替換;GUO 等人提出一種基于數據內容熱度與節點介數的緩存方法(HotBetw)[8],通過計算數據內容熱度和路由器介數來決定Data 包的緩存位置.熱度高的數據內容緩存在介數最大的路由器中,熱度低的數據內容隨機緩存在傳輸路徑上的任意路由器中,當熱度高的數據內容數量多時,這種方法中介數大的路由器存在高頻替換的問題;GUO 等人提出一種基于內容類型的隔跳概率緩存方法(Content Type based Jumping Probability, CTJP)[9],該方法將數據業務進行分類,同時計算傳輸路徑上路由器的緩存概率,從而降低網絡內數據冗余,但該方法的請求時延并不理想;CHEN 等人提出一種區分服務的緩存方法(DiffCache)[10],該方法將數據業務分為無需緩存、盡力緩存和減少延遲三類,分別給三類業務賦予權值,并計算數據內容在每個節點的緩存概率,但在緩存容量變化范圍內,盡力緩存和減少延遲兩種業務的緩存比例波動較大;ALHOWAIDI 等人提出一種使用軟件定義網絡(Software Defined Networking,SDN)實現的數據緩存管理方法[11],該方法將大于CS存儲空間的數據進行分塊,分別緩存在不同路由器中,通過建立控制器,同時控制器向路由器發布配置指令的方式來通知路由器存取數據塊,從而實現大數據文件的分布式緩存,文件預存取方法沒有考慮到文件緩存的最佳位置,數據請求時延的變化不夠明顯.
2 分級數據緩存方法
2.1 方法原理
為了進一步提升NDN 網絡的數據緩存和傳輸性能,本文針對以上方法中存在的數據內容多樣性低、頻繁替換等問題提出一種分級數據緩存方法(Hierarchical data caching, HDC).首先將 Interest 包和Data包格式進行改進,如圖1所示:
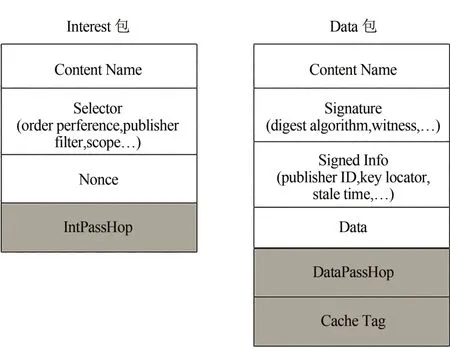
圖1 改進后的Interest包和Data包的格式Fig.1 Improved format of Interest packets and Data packets
Interest 包增加IntPassHop 字段,用來記錄Interest 包轉發過程中經過的路由器數量;Data 包增加DataPassHop字段和CacheTag字段,中DataPassHop字段用來記錄Data 包沿途返回過程中到達的路由器數量,CacheTag 字段用來決定數據緩存在傳輸路徑的哪一個路由器中.
HDC 方法的核心在于將傳輸路徑上的路由器進行分級,同時根據Data 包的CacheTag 字段值決定數據的緩存位置.圖2為傳輸路徑分級示意圖.
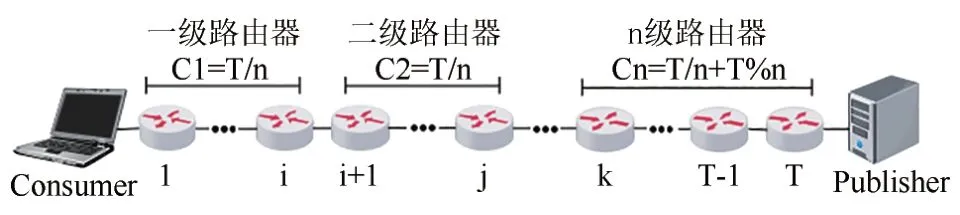
圖2 分級數據緩存示意圖Fig.2 Schematic diagram of hierarchical data cache
如圖2 所示,傳輸路徑上共有T個路由器,將T個路由器分成n級,其中第1 到第n-1 級路由器數量均為T/n,第n級路由器數量為T/n+T%n.
為了驗證分級數量對于網絡傳輸性能的影響,本文嘗試將傳輸路徑分為一到五個等級,并根據緩存命中率(Cache Hit Ratio, CHR)[12]、平均路由跳數(Average Route Hop, ARH)[13]和平均請求時延(Average Request Delay, ARD)[14]進行對比分析.
不失一般性,分析實驗中設定路由器數量為500 個,其中設置了1 個Publisher,網絡邊緣設置10 個Consumer,路由器中CS 容量平均為50 Kbyte.假設Interest 包發送過程符合Zipf 分布[15],Zipf 系數越大,Consumer 請求數據內容的重復度越高,其系數值設定為0.9.
圖3~5 分別為五種分級情況CHR、ARH、ARD的對比結果:
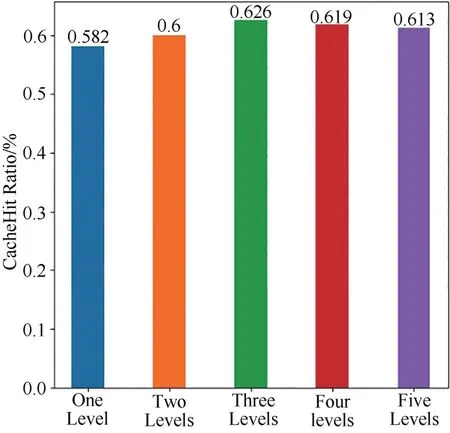
圖3 不同分級數量緩存命中率Fig.3 Cache hit ratio with different levels
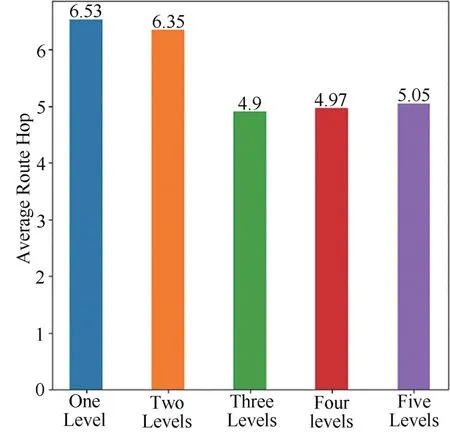
圖4 不同分級數量平均路由跳數Fig.4 The average route hops with different levels
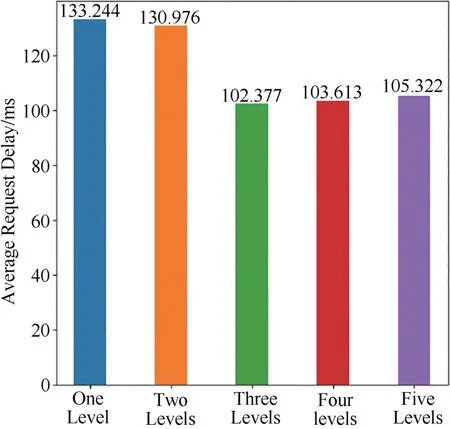
圖5 不同分級數量平均請求時延Fig.5 The average request delay with different levels
從實驗結果可見,將傳輸路徑分為三個等級時,全網平均CHR 最高,ARH 和ARD 最低.因此,在接下來的分析中,本文將路由器的級數分為三級.
2.2 HDC方法
在HDC方法中,靠近Consumer的路由器被劃分為第一級,靠近Publisher的路由器被劃分為第三級.
將Interest 中IntPassHop 字段值設為L, Data 包的DataPassHop字段值設為M,傳輸路徑中路由器總數為T.第一、二、三級路由器數量分別為:
根據以上分級方法,傳輸路徑的路由器劃分會出現均勻劃分和非均勻劃分兩種情況,如圖6 和7所示:
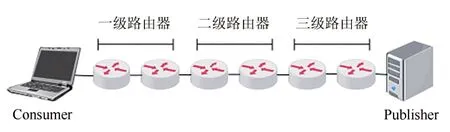
圖6 均勻劃分Fig.6 Uniform division
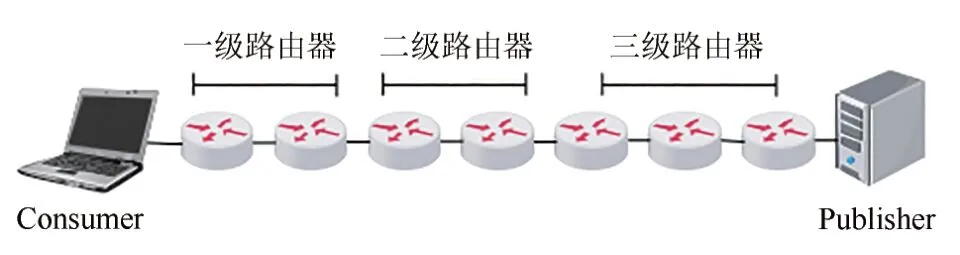
圖7 非均勻劃分Fig.7 Non-uniform division
Data 包中的CacheTag 字段值決定了數據內容被緩存的路由器.
CacheTag字段值設為K,計算如下:
當Consumer 第一次請求名為data1 的數據內容時,K的取值范圍是(0,C3),傳輸過程中Data包每到達一個路由器K值減1,當K=0時將Data 包緩存在路由器A 中,緩存完畢繼續向Consumer 轉發Data包,在其他路由器上不再進行緩存操作.
當Consumer 第二次請求名為data1 的數據內容時,Data包從路由器A發出,此時K取值范圍是(C3-M+1,C2+C3-M),傳輸過程中Data 包每到達一個路由器K值減1,當K=0時將Data 包緩存在路由器B中,緩存完畢繼續向Consumer 轉發Data 包,在其他路由器上不再進行緩存操作.
當Consumer 第三次請求名為data1 的數據內容時,Data 包從路由器B 發出,此時K的取值范圍是(C2+C3-M+1,T-M),傳輸過程中Data 包每到達一個路由器K值減1,當K=0時將Data 包緩存在路由器C 中,緩存完畢繼續向Consumer 轉發Data 包,在其他路由器上不再進行緩存操作.
當Consumer 第四次請求名為data1 的數據內容時,如果路由器C 是距離Consumer 最近的路由器,則路由器C 向Consumer 轉發Data 包.如果路由器C不是距離Consumer最近的路由,則Data 包從路由器C 發出,此時K=T-M,傳輸過程中Data 包每到達一個路由器K值減1,當K=0時將Data 包緩存在距離Consumer 最近的路由器D 中,緩存完畢繼續向Consumer轉發Data包.
HDC緩存過程偽代碼如下:
算法1:Publisher 接收到Interest 包后進行處理,并將Data包返回至Consumer

Algorithm 1 Publisher process interest packet Input: Interest packet arriving at the Publisher Output: Data packet returned to Consumer T ← interest.ip //Total number of routers C3 ← T/3 + T%3 //Number of routers at C3 data.ct ← rand(0, C3) //Set CacheTag value
算法2:路由器接收到Interest包后進行處理,并將Data包返回至Consumer
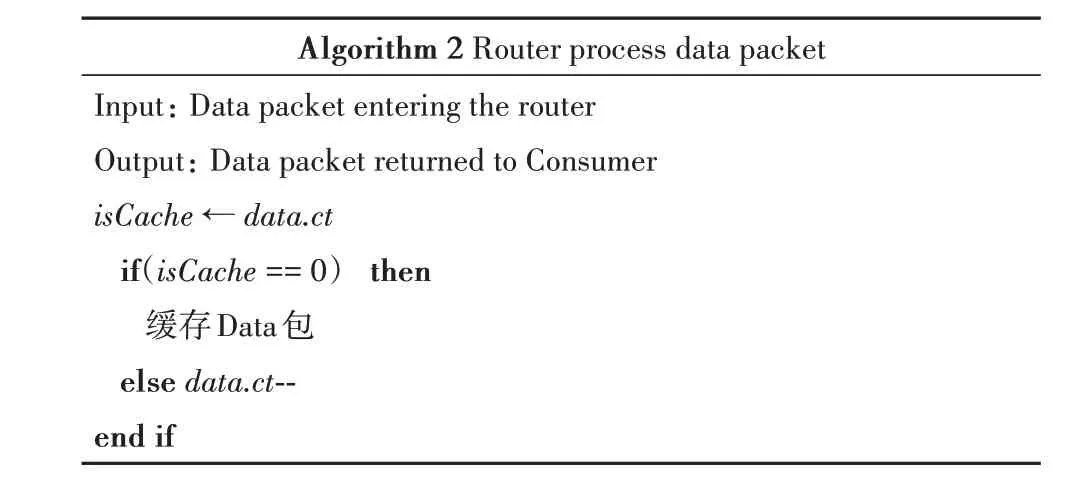
Algorithm 2 Router process data packet Input: Data packet entering the router Output: Data packet returned to Consumer isCache ← data.ct if(isCache == 0) then緩存Data包else data.ct--end if
算法3:Interest 包在路由器中被命中,路由器將Data包返回至Consumer

Algorithm 3 Interest packet hit in router Input: Interest packet entering the router Output: Data packet returned to Consumer T ← interest.iph + data.dph M ← data.dph C3 ← T/3 + T%3 C2 ← T/3 C1 ← T/3 if Data包緩存在C3中then data.ct ← rand(C3-M+1, C3+C2-M)else if Data包緩存在C2中then data.ct ← rand(C2+C3-M+1 , T-M )else if Data包緩存在C1中then data.ct ← T-M end if
3 仿真與性能分析
采用ndnSIM平臺進行仿真實驗,隨機生成一個具有500 個路由器的網絡拓撲,在網絡中設置1 個Publisher,在網絡邊緣設置10 個Consumer,仿真時間50 s,緩存替換方法為最近最少使用替換算法(Least Recently Used, LRU).考慮到真實網絡環境中路由器緩存容量遠小于網絡中數據內容總量,本文將緩存容量比R=C/N(路由器緩存容量/內容總量)的值設置為(0.01,0.05)之間,數據內容的請求模式服從Zipf 分布,將鏈路上隊列在傳輸過程中可容納的最大Data 包數量設置為20 個.實驗參數見表1:
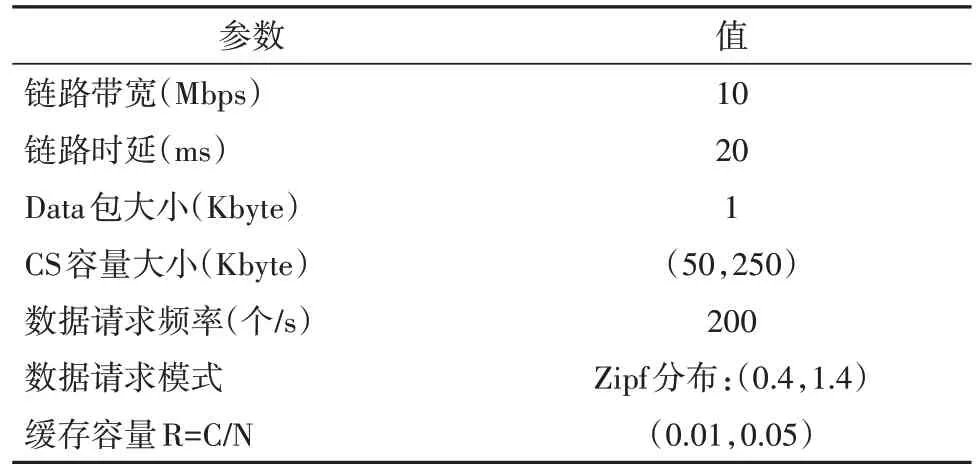
表1 實驗參數Tab.1 Experiment parameter
本文將HDC 方法與CEE 方法、ProbCache 方法、LCD 方法從CHR,ARH 和ARD 等三方面進行對比分析.
圖8 所示為R=0.02 且α=0.7 時四種方法的緩存命中率對比.實驗分別從R 在(0.01,0.05)之間和α在(0.4,1.4)之間進行對比實驗.
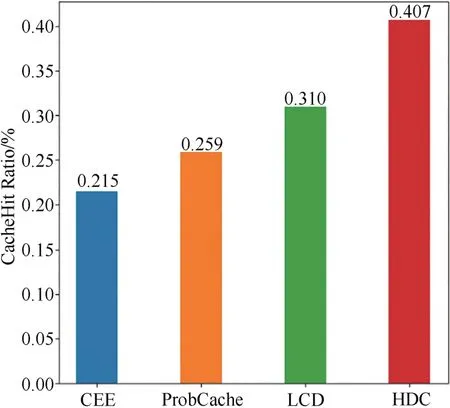
圖8 四種方法的緩存命中率對比Fig.8 Comparison of cache hit ratio of four methods
圖9所示為當α=0.7且R 在(0.01,0.05)之間時,四種方法緩存命中率變化.從圖中看到,隨著R 增大,路由器緩存的Data 包增多,四種方法的緩存命中率都有所提高,其中CEE 方法的命中率最低,HDC方法在R變化范圍內緩存命中率最高.
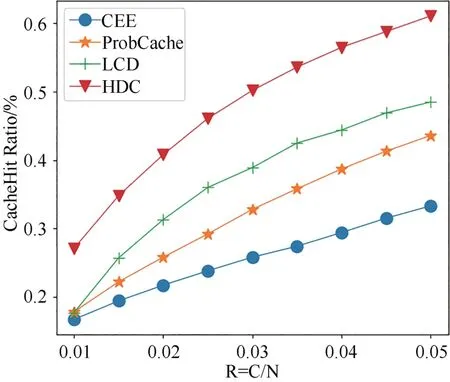
圖9 不同緩存容量比下四種方法緩存命中率的變化Fig.9 Variation of cache hit ratio of four methods with different cache capacity ratios
圖10所示為當R=0.02且α在(0.4,1.4)之間時,四種方法的緩存命中率變化.從圖中看出,四種方法的緩存命中率隨著α的增大而提升.其中LCD 方法的緩存命中率只有在α=0.5 時小于ProbCache 方法的緩存命中率, HDC 方法在α值變化范圍內緩存命中率對比其他三種方法具有明顯優勢.
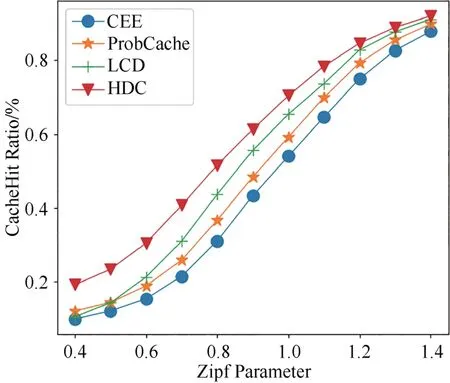
圖10 不同Zipf系數下四種方法緩存命中率的變化Fig.10 Variation of cache hit ratio of four methods with different Zipf parameter
圖11所示為R=0.02且α=0.7時四種方法的平均路由跳數對比.從圖中看出CEE方法的平均路由跳數最高,HDC方法的平均路由跳數小于其他三種方法.
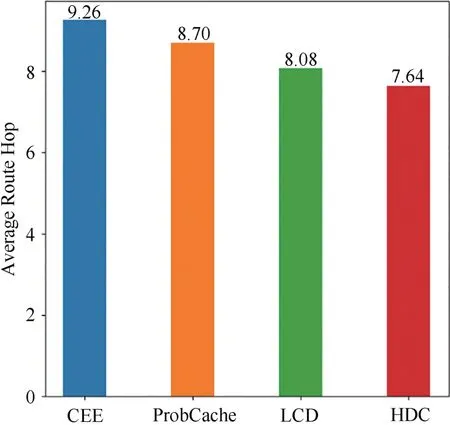
圖11 四種方法的平均路由跳數對比Fig.11 Comparison of average routing hops of four methods
圖12 所示為當α=0.7 且R 在(0.01,0.05)之間時,四種方法平均路由跳數變化.從圖中看出,隨著R 的增大,四種方法的全網平均路由跳數呈現下降趨勢.其中HDC 方法的平均路由跳數減少最多,且在R比值變化范圍內平均路由跳數最低.
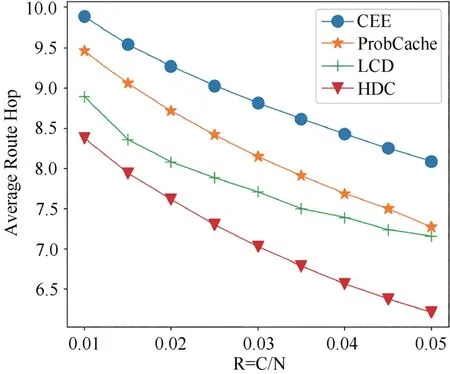
圖12 不同緩存容量比下四種方法平均路由跳數的變化Fig.12 Variation of average route hops of four methods with different cache capacity ratios
圖13所示為當R=0.02且α在(0.4,1.4)之間時,四種方法的平均路由跳數變化.從圖中可以看出,隨著α的增大,四種方法的平均路由跳數趨于相同,在α值變化范圍內HDC 方法的平均路由跳數始終小于其他三種緩存方法,在α=0.4 時LCD 方法的平均路由跳數大于ProbCache 方法,其他情況下ProbCache方法優于LCD方法.
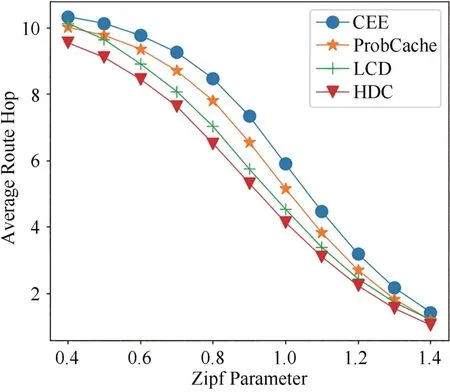
圖13 不同Zipf系數下四種方法平均路由跳數的變化Fig.13 Variation of the average route hops of four methods with different Zipf parameter
圖14 所示為R=0.02 且α=0.7 時,四種方法的平均請求時延的對比.從圖中看出,HDC 方法的平均請求時延明顯小于其他三種緩存方法,其中CEE 方法的平均請求時延最大.
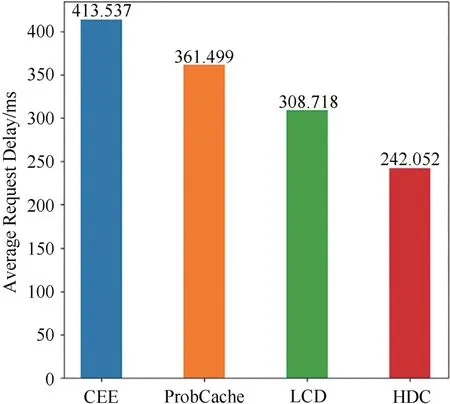
圖14 四種方法的平均請求時延對比Fig.14 Comparison of average request delay of four methods
圖15 所示為當α=0.7 且R 在(0.01,0.05)之間時,四種方法平均請求時延變化.從圖中看出,當R比增大時,四種方法的平均請求時延都明顯降低,其中HDC 方法在R 比值變化范圍內平均請求時延一直最低.CEE 方法的平均請求時延雖然也得到顯著降低,但在R 比值變化范圍內對比其他三種緩存方法平均請求時延最大.
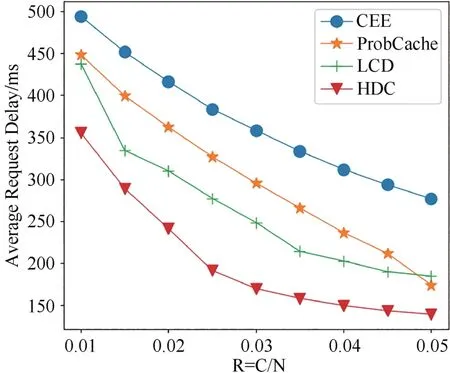
圖15 不同緩存容量比下四種方法平均請求時延的變化Fig.15 Variation of average request delay of four methods with different cache capacity ratios
圖16所示為當R=0.02且α在(0.4,1.4)之間時,四種方法的平均請求時延變化.從圖中看出,四種方法的平均請求時延隨著α的增大而降低,且隨著α的增大,四種方法的平均請求時延趨于相等.在α的變化范圍內,HDC 方法的平均請求時延一直小于其他三種緩存方法.
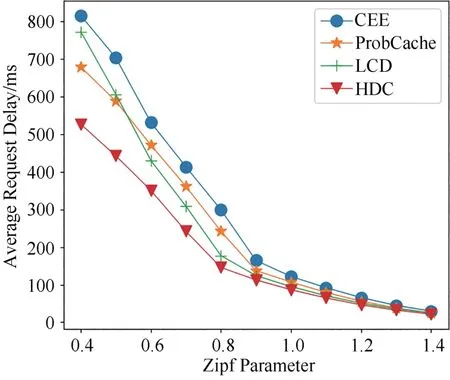
圖16 不同Zipf系數下四種方法平均請求時延的變化Fig.16 Variation of average request delay of four methods with different Zipf parameter
4 結語
本文為解決NDN 存在的緩存冗余等問題,提出一種基于分級緩存的方法,通過對傳輸路徑上的路由器進行分級,根據數據內容熱度將其緩存在相應等級的路由器中.仿真結果顯示,所提方法對比CEE、ProbCache 和LCD 方法,網絡的緩存命中率得到了提升,同時降低了平均路由跳數和平均請求時延.
猜你喜歡
科學大眾(2022年11期)2022-06-21 09:20:52
科學大眾(2021年21期)2022-01-18 05:53:48
科學大眾(2021年17期)2021-10-14 08:34:02
兒童故事畫報(2019年5期)2019-05-26 14:26:14
臺聲(2016年2期)2016-09-16 01:06:53
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
