基于潛在特征增強(qiáng)網(wǎng)絡(luò)的視頻描述生成方法
2024-02-29 04:40:02李偉健胡慧君
計(jì)算機(jī)工程 2024年2期
李偉健,胡慧君
(武漢科技大學(xué)計(jì)算機(jī)科學(xué)與技術(shù)學(xué)院,湖北 武漢 430065)
0 引言
視頻描述生成旨在根據(jù)視頻內(nèi)容自動(dòng)生成描述性的自然語(yǔ)言句子,視頻中蘊(yùn)含著豐富的信息[1],以往的研究致力于理解靜態(tài)的視覺(jué)信息,但是如何對(duì)視頻中豐富的時(shí)空信息進(jìn)行建模仍是一項(xiàng)具有挑戰(zhàn)性的任務(wù)[2]。
視頻中顯著對(duì)象的檢測(cè)是目前計(jì)算機(jī)視覺(jué)前沿領(lǐng)域必不可少的關(guān)鍵任務(wù),該任務(wù)通常被稱(chēng)為目標(biāo)檢測(cè)任務(wù)。例如,文獻(xiàn)[3]提出的OA-BTG 通過(guò)構(gòu)建雙向序列圖來(lái)提取視頻中的重要目標(biāo),然后整合整個(gè)視頻中的全局特征生成字幕。文獻(xiàn)[4]提出的STG-KD 采用圖卷積網(wǎng)絡(luò)(GCN)對(duì)檢測(cè)到的對(duì)象進(jìn)行關(guān)系推理,以增強(qiáng)對(duì)象級(jí)的關(guān)系表示。文獻(xiàn)[5]提出的DETR 首次采用Transformer 方法進(jìn)行視頻描述生成中的對(duì)象檢測(cè),計(jì)算輸出區(qū)域和真實(shí)區(qū)域的集合相似度,將對(duì)象檢測(cè)視為1 個(gè)直接的集合預(yù)測(cè)問(wèn)題。因此,處理不同視頻幀中對(duì)象之間的關(guān)系是視頻描述生成任務(wù)的關(guān)鍵。
現(xiàn)有方法往往是根據(jù)編碼器-解碼器的結(jié)構(gòu)設(shè)計(jì)來(lái)生成視頻描述。通過(guò)不同的特征提取器,如IncepResNetV2[6]、I3D[7]和Faster R-CNN[8],不同編碼器可以從不同角度捕捉視頻信息。顯然,同時(shí)使用不同的特征進(jìn)行連接可能會(huì)取得更優(yōu)的性能,但是這種方法往往會(huì)忽略不同特征之間的上下文語(yǔ)義信息,而這些信息在具有時(shí)空信息的視頻中起著重要作用。XU 等[9]和WANG 等[10]通過(guò)對(duì)視頻幀進(jìn)行局部特征融合來(lái)學(xué)習(xí)判別性的特征,從而提高視頻描述生成質(zhì)量。例如,文獻(xiàn)[11]提出的SAAT 通過(guò)融合對(duì)象和時(shí)間特征來(lái)生成相應(yīng)的動(dòng)詞。但是,只融合局部特征難以獲得全局的時(shí)空語(yǔ)義視頻信息。例如文獻(xiàn)[12]提出的POS+CG 設(shè)計(jì)1 個(gè)交叉門(mén)控模塊來(lái)融合外觀和運(yùn)動(dòng)特征,并進(jìn)行綜合闡述,然而,僅通過(guò)預(yù)測(cè)的全局POS 來(lái)表示生成的每個(gè)單詞,而忽略了微妙的細(xì)節(jié)信息,從而難以捕獲準(zhǔn)確的對(duì)象。
為了解決上述問(wèn)題,本文設(shè)計(jì)新的潛在特征增強(qiáng)網(wǎng)絡(luò)(LFAN)模型。該模型融合不同的特征來(lái)生成具有更高維度的潛在特征,并且通過(guò)構(gòu)建連接視頻特征的動(dòng)態(tài)圖來(lái)獲取時(shí)空信息,并利用GNN 和長(zhǎng)短時(shí)記憶(LSTM)網(wǎng)絡(luò)推理對(duì)象間的時(shí)空關(guān)系,進(jìn)一步豐富視頻內(nèi)容的特征表示,并結(jié)合LSTM 和門(mén)控循環(huán)單元(GRU)設(shè)計(jì)一種新的解碼方法來(lái)處理上下文信息和全局信息,從而生成準(zhǔn)確、流暢的視頻描述。
1 相關(guān)工作
1.1 視頻描述生成
視頻描述生成作為計(jì)算機(jī)視覺(jué)和自然語(yǔ)言處理的交叉領(lǐng)域,早期大多數(shù)方法都是基于特定的模板[13-15],這些模板需要大量人工設(shè)計(jì)的語(yǔ)言規(guī)則,并且處理有限類(lèi)別的對(duì)象、動(dòng)作等,難以生成準(zhǔn)確的語(yǔ)句描述。
隨著深度神經(jīng)網(wǎng)絡(luò)的興起,VENUGOPALAN等[16]提出一種編碼器-解碼器框架來(lái)克服這些限制。當(dāng)前,基于編解碼框架的視頻描述生成方法成為主流。YAO 等[17]提出一種動(dòng)態(tài)總結(jié)視覺(jué)特征的時(shí)間注意力機(jī)制。CHEN 等[18]提出從視頻中去除冗余幀,從而解碼重要的視覺(jué)信息以生成視頻描述。文獻(xiàn)[19]提出的M3 通過(guò)建立記憶網(wǎng)絡(luò)來(lái)模擬長(zhǎng)期的視覺(jué)文本依賴,以生成高質(zhì)量的描述。文獻(xiàn)[20]提出的MARN 設(shè)計(jì)一種記憶結(jié)構(gòu)來(lái)尋找候選詞匯和包含它所有視頻特征的關(guān)系。TAN 等[21]提出一種新的時(shí)空視覺(jué)推理模塊RMN,實(shí)現(xiàn)顯式的、可解釋的視頻字幕處理。BAI 等[22]采用生成對(duì)抗網(wǎng)絡(luò)(GAN)來(lái)保證生成描述的準(zhǔn)確性。RYU 等[23]提出一種語(yǔ)義分組網(wǎng)絡(luò)(SGN),通過(guò)語(yǔ)義組預(yù)測(cè)下1 個(gè)生成的單詞。Open-Book[24]從語(yǔ)料庫(kù)中檢索語(yǔ)句,作為生成描述性語(yǔ)句的指南。CHEN 等[25]提出R-ConvED,從已注釋的視頻句子對(duì)中檢索相關(guān)的視覺(jué)內(nèi)容和句法結(jié)構(gòu),并利用這些上下文知識(shí)促進(jìn)描述性語(yǔ)句的生成質(zhì)量。
最新的研究挑戰(zhàn)則是嘗試構(gòu)建大規(guī)模的端到端訓(xùn)練視頻描述生成網(wǎng)絡(luò),如LIN 等[26]在視頻描述生成領(lǐng)域中使用SwinBERT 進(jìn)行端到端訓(xùn)練,以生成視頻描述。但是這類(lèi)網(wǎng)絡(luò)模型通常使用Transformer進(jìn)行編解碼,訓(xùn)練參數(shù)量龐大,并且需要大量的計(jì)算資源。
1.2 潛在特征
不同的特征信息在生成視頻描述中起著重要作用。文獻(xiàn)[27]提出的GRU-EVE 使用對(duì)象標(biāo)簽增強(qiáng)視覺(jué)特征的語(yǔ)義信息。文獻(xiàn)[12]提出的POS+CG 構(gòu)建一種新穎的門(mén)控融合網(wǎng)絡(luò),對(duì)視頻的外觀和運(yùn)動(dòng)特征進(jìn)行編碼和融合。文獻(xiàn)[4]提出的STG-KD[通過(guò)GCN 構(gòu)建對(duì)象關(guān)系圖,利用對(duì)象關(guān)系圖推理視頻對(duì)象之間的時(shí)空關(guān)系以獲得潛在特征。文獻(xiàn)[28]提出的ORG-TRL 使用GCN 實(shí)現(xiàn)關(guān)系推理從而獲取視頻中的潛在特征,豐富細(xì)節(jié)對(duì)象的表示。文獻(xiàn)[11]提出的SAAT 設(shè)計(jì)1 個(gè)語(yǔ)法感知模型來(lái)增強(qiáng)動(dòng)詞的生成,使動(dòng)作和目標(biāo)之間的相關(guān)性更強(qiáng)。圖1 所示為L(zhǎng)FAN 生成描述的直觀示例。本文使用基線模型Baseline 作為對(duì)比,其中僅使用傳統(tǒng)的編碼器-解碼器框架,沒(méi)有使用圖神經(jīng)網(wǎng)絡(luò)和改進(jìn)的解碼方式。從圖1 可以看出,基線模型缺乏時(shí)空語(yǔ)義信息,無(wú)法對(duì)視頻上下文進(jìn)行全面探索,從而產(chǎn)生較差的描述。SAAT 生成目標(biāo)對(duì)象和相應(yīng)的動(dòng)詞,但沒(méi)有捕獲完整的視頻信息,從而生成不完整的描述語(yǔ)句。相反,本文模型 通過(guò)捕 捉突出 的對(duì)象“man”“chicken”和“plastic”,學(xué)習(xí)它們之間的對(duì)應(yīng)關(guān)系從而生成準(zhǔn)確的動(dòng)詞“put”,并完整描繪出視頻內(nèi)容。
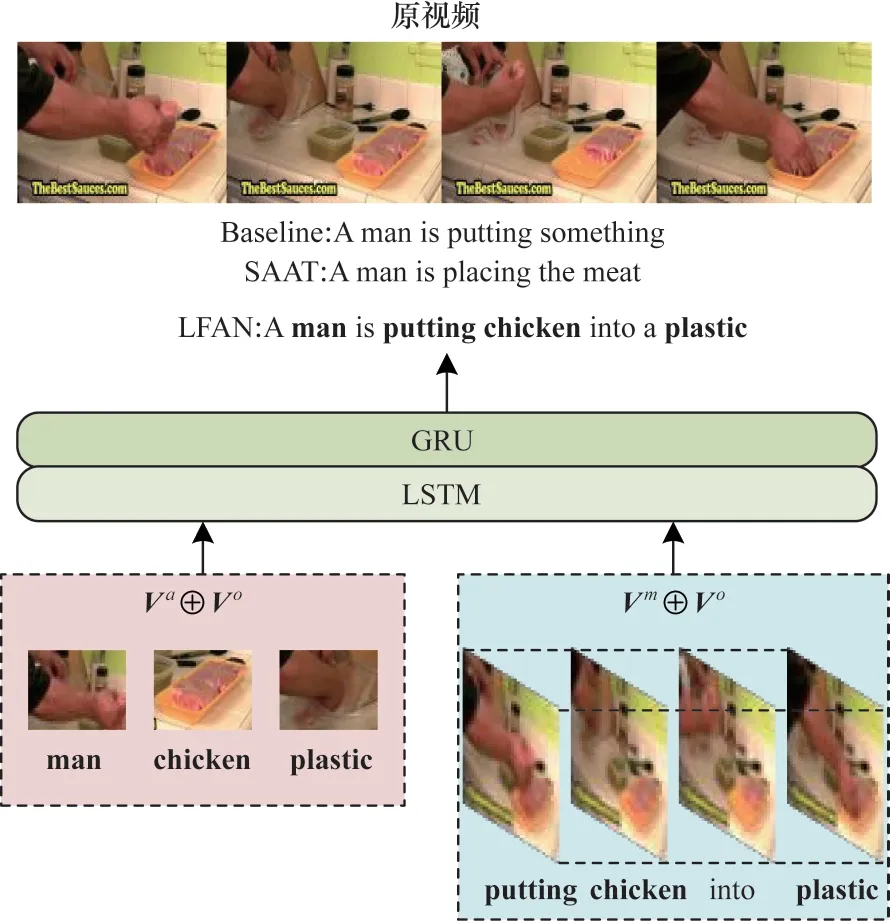
圖1 LFAN 生成描述的直觀示例Fig.1 An intuitive examples of LFAN generation descriptions
2 潛在特征增強(qiáng)網(wǎng)絡(luò)
LFAN 模型框架如圖2 所示。LFAN 模型由編碼層、潛在特征層和解碼層組成。首先,利用空間GNN增強(qiáng)目標(biāo)特征以獲得更精確的目標(biāo)區(qū)域;然后,利用語(yǔ)義GNN 和LSTM 融合外觀特征、運(yùn)動(dòng)特征和對(duì)象特征,得到具有語(yǔ)義信息的潛在特征;最后,利用可以處理全局信息的解碼器生成視頻描述。

圖2 LFAN 模型框架Fig.2 Framework of LFAN model
2.1 編碼層
在編碼階段,本文使用3 種預(yù)訓(xùn)練模型提取視頻特征。對(duì)于給定的視頻幀N,本文使用2D-CNNs和3D-CNNs 分別提取外觀特征和運(yùn)動(dòng)特征,然后使用R-CNNs 提取區(qū)域目標(biāo)特征區(qū)域目標(biāo)特征包含空間上的額外維度。
2.2 潛在特征層
LFAN 模型使用GNN 融合不同的特征,得到潛在特征,利用GNN 和LSTM 實(shí)現(xiàn)潛在特征的增強(qiáng),并得到更高維度的增強(qiáng)潛在特征,高維度的潛在特征蘊(yùn)含著豐富的語(yǔ)義信息以生成更準(zhǔn)確的視頻描述。
對(duì)于先前生成的Va,Vm和Vo,本文首先利用動(dòng)態(tài)顯著區(qū)域圖神經(jīng)網(wǎng)絡(luò)DyReg-GNN[29]對(duì)區(qū)域目標(biāo)特征Vo進(jìn)行增強(qiáng),DyReg-GNN 可以通過(guò)學(xué)習(xí)發(fā)現(xiàn)與當(dāng)前場(chǎng)景和目標(biāo)相關(guān)的顯著區(qū)域來(lái)改善視頻的關(guān)系處理過(guò)程,增強(qiáng)后的蘊(yùn)含時(shí)空信息,如式(1)所示:
其中:Ddyreg() 表示DyReg-GNN 中的圖神經(jīng)網(wǎng)絡(luò)操作。
然后將增強(qiáng)后目標(biāo)特征的中間2 維降為1 維,再將特征Vi=Va,Vm分別和增強(qiáng)后的區(qū)域目標(biāo)特征由Softmax()函數(shù)計(jì)算關(guān)系矩陣權(quán)值:
其中:Wadj∈Rd表示可學(xué)習(xí)的參數(shù);/代表矩陣點(diǎn)除。
為了讓特征同時(shí)具有幀級(jí)的時(shí)間信息和對(duì)象級(jí)的空間信息,本文將特征Vi和得到的關(guān)系矩陣相乘,相乘后的結(jié)果和區(qū)域目標(biāo)特征拼接得到潛在特征:
使用1 個(gè)雙向LSTM 對(duì)潛在特征進(jìn)行編碼,將前一時(shí)刻的隱藏狀態(tài)ht-1作為輸入:
其中:表示增強(qiáng)的潛在特征;ht表示第t個(gè)時(shí)刻的隱藏狀態(tài);ct表示第t個(gè)時(shí)刻的細(xì)胞狀態(tài)。由于ht具有豐富的歷史信息,因此它對(duì)于增強(qiáng)潛在特征具有指導(dǎo)作用。
對(duì)增強(qiáng)的潛在特征使用Transformer 中的位置編碼,保存特征之間的相對(duì)位置用于指導(dǎo)生成更流暢的描述語(yǔ)句,然后通過(guò)圖神經(jīng)網(wǎng)絡(luò)將其融合為潛在特征并參與訓(xùn)練。外觀和運(yùn)動(dòng)潛在特征如式(7)和式(8)所示:
其中:LPi表示外觀和運(yùn)動(dòng)潛在特征;PPE()表示Transformer 中的位置編碼函數(shù);K()表示kernel 函數(shù),里面是圖神經(jīng)網(wǎng)絡(luò)模塊,包含卷積和批量規(guī)范化操作以及GELU[30]激活函數(shù);×表示矩陣乘法;表示最終的增強(qiáng)外觀和運(yùn)動(dòng)潛在特征;Sselfatt()表示自注意力函數(shù),后面還有1 層LayerNorm 函數(shù)。本文考慮到雖然ReLU[31]函數(shù)能夠解決梯度消失,但是依然存在一些不可避免的問(wèn)題,如無(wú)法避免梯度爆炸,神經(jīng)網(wǎng)絡(luò)無(wú)法調(diào)整學(xué)習(xí)率的值。因此,本文采用自然語(yǔ)言處理(NLP)領(lǐng)域最近表現(xiàn)較優(yōu)的GELU 作為激活函數(shù),GELU 在BERT 和Transformer 中也得到了很好的應(yīng)用。
至此,LFAN 模型完成幀級(jí)的外觀特征和運(yùn)動(dòng)特征同對(duì)象級(jí)目標(biāo)特征的融合,從而生成具有時(shí)空動(dòng)態(tài)信息的高級(jí)潛在特征。
2.3 解碼層
本文參考ORG-TRL[6]并設(shè)計(jì)一種同時(shí)使用LSTM 和GRU 的解碼方法。LFAN 模型通過(guò)注意力LSTM 和GRU 解碼潛在特征層生成,從而逐 漸生成最終的視頻描述。
首先LFAN 模型對(duì)生成的潛在外觀特征和潛在運(yùn)動(dòng)特征進(jìn)行均值操作,然后用Cat 操作將它們拼接作為模型的全局視頻特征:
其中:表示全局視頻特征;Cat()表示Cat 拼接操作。
對(duì)于每個(gè)時(shí)間步長(zhǎng)t,LSTM 根據(jù)歷史隱藏狀態(tài)、歷史細(xì)胞狀態(tài)與均值全局特征以及之前生成的單詞wt-1進(jìn)行連接,歷史隱藏狀態(tài)和細(xì)胞狀態(tài)的表達(dá)式如式(10)所示:
對(duì)于局部對(duì)象特征,LFAN 模型使用DyReg-GNN中的方法,首先將不同幀中的對(duì)象對(duì)齊并合并在一起,然后使用空間注意模塊選擇應(yīng)該關(guān)注哪些對(duì)象,并提取局部上下文特征。局部上下文特征的表達(dá)式如下:
其中:AATT()表示DyReg-GNN 中空間注意模塊。
最后,GRU 總結(jié)全局和局部上下文特征以生成當(dāng)前隱藏狀態(tài),這樣本文生成描述時(shí)既有全局相關(guān)性也包含細(xì)粒度的上下文信息。在將單詞概率Pt解碼后是單層感知機(jī)和解碼步驟t時(shí)刻的Softmax()運(yùn)算。隱藏狀態(tài)和單詞概率的計(jì)算式如下:
其中:Pt表示詞匯量的D維向量;Wz表示權(quán)值矩陣;bz表示可學(xué)習(xí)的參數(shù)。
3 實(shí)驗(yàn)結(jié)果與分析
為合理評(píng)估該網(wǎng)絡(luò)模型的有效性和先進(jìn)性,本文在2 個(gè)廣泛使用的基準(zhǔn)數(shù)據(jù)集MSVD 和MSR-VTT 上進(jìn)行實(shí)驗(yàn),并通過(guò)4 個(gè)廣泛使用的指標(biāo)BLUE@4、METEOR、ROUGE-L 和CIDEr 進(jìn)行評(píng)估,將該方法與最先進(jìn)的方法進(jìn)行比較,并進(jìn)行消融實(shí)驗(yàn)。
3.1 數(shù)據(jù)集
MSVD 由YouTube 收集的1 970 個(gè)網(wǎng)絡(luò)視頻組成,平均視頻長(zhǎng)度為10.2 s,每個(gè)視頻大約有41 個(gè)英文句子,每個(gè)描述平均長(zhǎng)度約有7 個(gè)單詞。本文根據(jù)之前的工作[15]將數(shù)據(jù)集分為1 200 個(gè)訓(xùn)練視頻、100 個(gè)驗(yàn)證視頻和670 個(gè)測(cè)試視頻。
MSR-VTT 數(shù)據(jù)集是開(kāi)放領(lǐng)域視頻字幕生成的大規(guī)模數(shù)據(jù)集,共包含10 000 個(gè)視頻,平均視頻長(zhǎng)度為14.8 s,每個(gè)視頻有20 個(gè)人為標(biāo)注的英文描述,每個(gè)描述的平均長(zhǎng)度約為9 個(gè)單詞。本文采用標(biāo)準(zhǔn)分割將數(shù)據(jù)集分為6 513 個(gè)訓(xùn)練視頻、497 個(gè)驗(yàn)證視頻和2 990 個(gè)測(cè)試視頻。
3.2 實(shí)驗(yàn)設(shè)置
本文在特征提取上使用預(yù)訓(xùn)練好的Inception ResNetV2(IRV2)、I3D 和Faster R-CNN 分別提取外觀特征、動(dòng)作特征和目標(biāo)特征,每個(gè)視頻采用26 幀的均勻采樣,F(xiàn)aster R-CNN 從固定的26 幀中提取36 個(gè)proposal。對(duì)于語(yǔ)料庫(kù)的預(yù)處理,本文將生成的所有描述轉(zhuǎn)換為小寫(xiě)并去掉標(biāo)點(diǎn)符號(hào),最大詞匯量設(shè)置為26 個(gè)單詞,對(duì)超過(guò)26 個(gè)單詞的描述進(jìn)行零填充。本文將預(yù)訓(xùn)練GloVe.6B.300d 詞表引入到解碼器參與詞向量訓(xùn)練,詞向量維度為300。
本文用標(biāo)準(zhǔn)的交叉熵?fù)p失函數(shù)計(jì)算模型生成的描述和Ground Truth 間的差異,采用Adam 優(yōu)化器優(yōu)化LFAN 模型,初始學(xué)習(xí)率設(shè)為1×10-4,動(dòng)態(tài)調(diào)整學(xué)習(xí)率使其每5 輪削減50%。訓(xùn)練和測(cè)試批量大小分別設(shè)為256 和128,最大訓(xùn)練迭代輪次設(shè)為60 次。在MSVD 和MSR-VTT 數(shù)據(jù)集上,所有LSTM 模塊隱藏狀態(tài)大小分別設(shè)為1 024 和1 536,每個(gè)圖卷積操作的特征大小為1 024。在測(cè)試階段本文分別使用大小為4 和5 的波束搜索來(lái)生成描述。
3.3 實(shí)驗(yàn)結(jié)果定量分析
為驗(yàn)證LFAN 模型的有效性,本文選擇使用CNN 作為編碼器和LSTM 作為解碼器,在MSVD 和MSR-VTT 2 個(gè)數(shù)據(jù)集上與最先進(jìn)的方法進(jìn)行比較。
在MSVD 和MSR-VTT 數(shù)據(jù)集上不同模型的實(shí)驗(yàn)結(jié)果如表1 所示,其中,B@4、M、R、C 分別表示BLUE@4、METEOR、ROUGE-L 和CIDEr,加粗表示最優(yōu)數(shù)據(jù)。從表1 可以看出,LFAN 具有較強(qiáng)的競(jìng)爭(zhēng)優(yōu)勢(shì),在MSVD 數(shù)據(jù)集上,反映描述準(zhǔn)確性的BLEU@4 分?jǐn)?shù)為57,反映描述豐富性的CIDEr 分?jǐn)?shù)達(dá)到了100.1,在MSR-VTT 數(shù)據(jù)集 上,BLEU@4 分?jǐn)?shù)為43.8,CIDEr 分?jǐn)?shù)為50.2,在多個(gè)指標(biāo)上都優(yōu)于主流視頻描述生成方法,證明LFAN 模型的有效性。

表1 在MSVD 和MSR-VTT 數(shù)據(jù)集上不同模型的實(shí)驗(yàn)結(jié)果Table 1 Experimental results among different models on MSVD and MSR-VTT datasets
在MSR-VTT 數(shù)據(jù)集上,與不使用對(duì)象特征的RecNet、PickNet、MARN、SGN 和Open-Book 相比,LFAN 僅略遜于Open-Book,其原因?yàn)镺pen-Book 在生成關(guān)鍵詞時(shí)從文本語(yǔ)料庫(kù)中檢索多個(gè)與視頻內(nèi)容相關(guān)的句子,生成的關(guān)鍵詞與參考語(yǔ)句在生成關(guān)鍵詞時(shí),會(huì)從文本語(yǔ)料庫(kù)中檢索多個(gè)與視頻內(nèi)容相關(guān)的句子,因此生成的關(guān)鍵詞與參考語(yǔ)句的相似度更高。這種方法在METEOR 和CIDEr 評(píng)價(jià)指標(biāo)中會(huì)獲得更高的得分。而在MSVD 數(shù)據(jù)集上,LFAN 在所有評(píng)價(jià)指標(biāo)上都取得比其他方法更優(yōu)的性能,表明對(duì)象特征在視頻描述生成中發(fā)揮了重要作用,并且學(xué)到準(zhǔn)確的對(duì)象特征。
此外,LFAN 與使用對(duì)象特征的OA-BTG、GRUEVE、RMN、STG-KD、SAAT 和ORG-TRL 進(jìn)行比較。在MSR-VTT 數(shù)據(jù)集上,當(dāng)ORG-TRL 引入TRL 外部語(yǔ)言模塊來(lái)指導(dǎo)模型生成描述語(yǔ)句時(shí),ORG-TRL 的CIDEr 得分增加為50.9,當(dāng)ORG-TRL 去掉TRL 外部語(yǔ)言模塊后,在CIDEr 上的表現(xiàn)不如本文模型,得分為50.1。本文提出的LFAN 在BLUE@4 和ROUGE-L中有更好的表現(xiàn),表明LFAN 生成的視頻描述準(zhǔn)確度和召回率更高。
3.4 消融實(shí)驗(yàn)
本文主要對(duì)潛在特征模塊和解碼模塊進(jìn)行改進(jìn)。為了說(shuō)明本文的改進(jìn)措施能使模型學(xué)到更有效的信息以生成視頻描述,本文在潛在特征模塊上設(shè)計(jì)3 個(gè)消融實(shí)驗(yàn),分別是僅使用外觀特征、運(yùn)動(dòng)特征和對(duì)象特征來(lái)生成視頻描述的基線模型。
表2 和表3 所示為使用不同神經(jīng)網(wǎng)絡(luò)和不同解碼方法的消融實(shí)驗(yàn)結(jié)果。LFAN-GNN 表示使用圖神經(jīng)網(wǎng)絡(luò)融合不同特征,LFAN-DG 表示使用DyReg-GNN 加強(qiáng)目 標(biāo)特征,LFAN-LSTM 和LFAN-GRU 分別是僅使用LSTM 和GRU 作為解碼器。從表2 可以看出,無(wú)論是使用圖神經(jīng)網(wǎng)絡(luò)融合不同特征還是加入DyReg-GNN 后,模型的各項(xiàng)指標(biāo)都有所提升。相比LFAN-GNN,LFAN-DG 在2 個(gè)數(shù)據(jù) 集上的BLUE@4 分別提升了1.9 和0.6,說(shuō)明本文的改進(jìn)方法使模型提取到更準(zhǔn)確的對(duì)象信息。本文在MSVD數(shù)據(jù)集上的CIDEr 分?jǐn)?shù)比基線模型提高9.8,在MSR-VTT 數(shù)據(jù)集上比基線模型提高了3.1 的分?jǐn)?shù),進(jìn)一步證明LFAN 的有效性。

表3 使用不同解碼方法的消融實(shí)驗(yàn)結(jié)果 Table 3 Results of ablation experiments using different decoding methods
從表3 可以看出,本文設(shè)計(jì)同時(shí)使用LSTM 和GRU 的LFAN 顯然比單獨(dú)使用其中1 個(gè)解碼方法的性能更好,新的解碼方法與LFAN-LSTM 相比評(píng)估效率也得到了改善,這充分證明了本文改進(jìn)方法的有效性。
3.5 實(shí)驗(yàn)結(jié)果定性分析
圖3 所示為L(zhǎng)FAN 生成的一些描述實(shí)例與參考描述(GT)的對(duì)比。圖3 中第1 行參考視頻描述:GT1“a woman is applying something on her eyelids”;GT2“a girl is applying eye makeup”;GT3“a girl is applying makeup to her eyelid”;LFAN“a woman is applying makeup on her eye”。第2 行參考視頻描述:GT1“the man is putting meat in the bag”;GT2“a man is adding chicken to a plastic cover”;GT3“a man puts chicken breasts into a bag”;LFAN“a man is putting chicken into a plastic”。第3 行參考視頻描述:GT1“a man is dicing food”;GT2“a man is slicing garlic”;GT3“a person is slicing garlic”;LFAN“a man is chopping garlic”。第4行參考視頻描述:GT1“a woman is cooking”;GT2“a woman showing how to cut garlic cloves”;GT3“a woman is chopping garlic”;LFAN“a person is preparing some food in the kitchen”。LFAN 可以精準(zhǔn)識(shí)別出“woman”在“applying makeup”,而不是“draw something”。在第2 行的示例中,LFAN 成功地識(shí)別出主要對(duì)象信息“chicken”和“plastic”以及人物的動(dòng)作“putting”,并且排除掉桌子上其他干擾對(duì)象信息,說(shuō)明LFAN 不僅可以識(shí)別出主要對(duì)象,并且可以精準(zhǔn)地描述對(duì)象動(dòng)作。

圖3 LFAN 生成描述與參考描述實(shí)例分析Fig.3 Example analysis of LFAN generation description and reference description
4 結(jié)束語(yǔ)
視頻描述生成技術(shù)可以廣泛應(yīng)用于各種媒體軟件,在視頻推薦、輔助視覺(jué)、人機(jī)交互等領(lǐng)域也具有廣泛應(yīng)用前景[32]。本文提出一種基于潛在特征增強(qiáng)網(wǎng)絡(luò)的視頻描述生成模型LFAN。該模型著重于增強(qiáng)視頻特征的時(shí)空和語(yǔ)義信息,從而顯著提升生成的視頻描述質(zhì)量。大量的定量、定性實(shí)驗(yàn)和消融實(shí)驗(yàn)結(jié)果都證明了LFAN 的有效性,LFAN 模型能夠精準(zhǔn)地描述對(duì)象動(dòng)作。由于在生成描述中一些視頻的描述難以被模型正確地生成,這種情況尤其發(fā)生在一些罕見(jiàn)或復(fù)雜的場(chǎng)景或物體上,因此后續(xù)將基于多模態(tài)融合和KL 散度對(duì)LFAN 進(jìn)行分析研究。
猜你喜歡
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長(zhǎng)指南(2015年4期)2015-05-19 14:47:56
中外會(huì)展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
祝您健康(1987年3期)1987-12-30 09:52:32
