基于集成樹和MoE的饋線統計線損率雙層估計模型
2024-02-21 09:44:16王守相張丙杰趙倩宇郭陸陽
電工技術學報 2024年3期
王守相 張丙杰 趙倩宇 郭陸陽 張 晟
基于集成樹和MoE的饋線統計線損率雙層估計模型
王守相1,2張丙杰1,2趙倩宇1,2郭陸陽1,2張 晟1,2
(1. 天津大學教育部智能電網重點實驗室 天津 300072 2. 天津市電力系統仿真控制重點實驗室 天津 300072)
統計線損率是衡量電力系統經濟運行的重要指標。然而,用戶用電數據采集異常、數據傳輸中斷等因素會導致統計線損率異常或缺失,這嚴重阻礙了智能配電網的線損精益化管理與經濟高效運行。針對饋線統計線損率合理值的估計問題,該文提出了一種基于集成樹和混合專家系統(MoE)的饋線統計線損率雙層估計模型。首先,使用最大信息系數以更有效地分析統計線損率與其相關特征間的非線性關系,并采用魯棒性強的K-Medoids聚類算法對饋線進行精細劃分;然后,使用Stacking集成學習框架,基于基估計和元估計雙層模型對饋線統計線損率進行兩階段估計,選用決策樹和各類集成樹模型作為基估計模型對統計線損率進行初步估計,將各基估計模型輸出結果輸入元估計模型MoE中進行最終估計,使用方均根誤差(RMSE)和平均絕對誤差(MAE)來衡量模型所估計統計線損率的合理性;最后,通過算例分析表明,與其他模型相比,該文所提饋線統計線損率雙層估計模型具有更低的RMSE和MAE,對饋線統計線損率的估計效果更好。
統計線損率 線損率估計 機器學習 集成樹 混合專家系統
0 引言
降低線損是電力企業節能增效、實現雙碳目標的重要途徑。據統計,2021年,南方電網通過降低線損率減少了350萬t碳排放量[1],而饋線線損占電網總線損的50%以上[2]。因此,開展配電網饋線線損分析研究具有重要意義。
統計線損率是電網進行線損精細化管理的重要指標[3]。用戶用電數據采集異常、數據傳輸中斷等因素會導致統計線損率異常或缺失,從而使統計線損率無法反映線損的真實情況[4-5]。為此,需要對饋線統計線損率的合理值進行估計。
隨著智能配電網的建設和人工智能技術的發展,基于數據驅動的線損率估計模型成為研究熱點[6-9]。該類模型分為單一估計模型[10-15]和多模型融合[16-21]。文獻[10]使用快速獨立成分分析進行特征選取,然后通過支持向量回歸(Support Vector Regression, SVR)對饋線線損進行估計。文獻[11]使用粒子群優化算法來優化SVR的參數,一定程度上提升了線損估計精度。文獻[12]使用灰色關聯分析對特征進行篩選,然后使用BP(back propagation)神經網絡對線損率進行估計。文獻[13]使用降噪自編碼器(Denoising Autoencoder, DAE)對特征進行重構,然后使用長短期記憶網絡(Long Short-Term Memory, LSTM)對饋線日線損率進行估計。文獻[14]提出一種深度遷移學習網絡,實現對含分布式電源的電網線損進行估計。考慮到饋線種類繁多,文獻[15]首先使用模糊C均值聚類對饋線進行聚類,然后對每一個類饋線進行線損估計,實現了對饋線線損更精細化的管理。文獻[10-15]均使用單一估計模型進行線損率估計,其估計精度有待提升。
多模型融合是提升模型性能的有效方法[16],其在線損率估計領域也有所應用[17-21]。文獻[17]使用基于Bagging集成學習思想的隨機森林模型對臺區線損率進行估計。文獻[18]使用基于Boosting集成學習思想的極限梯度提升樹[19](eXtreme Gradient Boosting, XGBoost)對饋線統計線損率進行估計。文獻[20-21]將Stacking集成學習分別應用到饋線線損和臺區線損估計,各基估計模型均選用機器學習模型,元估計模型均采用梯度提升樹(Gradient Boosting Decision Tree, GBDT)。文獻[17-21]在一定程度上提高了線損率估計的準確性。然而,其所用模型均為機器學習模型,該類模型應用到線損率估計等復雜場景時,存在特征挖掘不充分、泛化能力較差的問題。深度神經網絡在理論上可以擬合任何數據間的非線性關系,經過訓練可以具有良好的泛化能力[22]。谷歌提出一種混合專家系統神經網絡,針對一個估計任務同時訓練多個高度專業化的專家神經網絡模型,從而可以深入挖掘數據間的潛在聯系,進一步提高估計準確性[23]。
為此,本文基于Stacking集成學習思想,提出一種基于集成樹和混合專家系統的饋線統計線損率雙層估計模型。首先使用最大信息系數對所選特征有效性進行驗證;然后使用K-Medoids聚類算法對饋線進行聚類;最后針對每一類饋線訓練統計線損率雙層估計模型。選用決策樹、隨機森林、極限隨機樹[24](Extremely Randomized Tree, ExtraTree)、GBDT、自適應提升樹[25](Adaptive Boosting Tree, AdaBoost)和XGBoost模型作為基估計模型對線損率進行初步估計,并使用元估計模型混合專家系統(Mixture of Experts, MoE)對基估計模型結果進行深度融合,得到統計線損率最終估計結果。
1 基于最大信息系數和K-Medoids的饋線聚類
1.1 饋線統計線損率特征選取


式中,g為供電量;s為售電量。
統計線損是由理論線損和管理線損共同組成。因此,將理論線損率作為統計線損率估計的一個特征。而理論線損是通過潮流計算某段時間內已投運的變壓器和線路上產生的線損,與線路和變壓器有關的運行數據有線路總長度、線路供電量、線路投運時間、配電變壓器額定容量與配變投運時間等,這些指標也間接影響著統計線損率,為此也將上述特征作為統計線損率估計的特征。
通過上述物理層面的分析可知,統計線損率與其各特征之間并非簡單的線性關系,下面從數據角度進行量化分析。最大信息系數[26](Maximal Information Coefficient, MIC)是一種基于信息論的相關性檢驗方法。與基于統計學理論的相關系數相比,最大信息系數可以更有效地衡量變量間的非線性關系。為此,選取最大信息系數對統計線損率與各特征之間的相關性進行分析。
式中,()為與的聯合概率分布;()和()分別為與的邊緣概率分布;為二元集合。
根據式(3)的約束改變和,計算不同網格數下的最大互信息值,其中最大值即為最大信息系數,有

式中,為饋線數量。MIC的取值范圍為[0,1],特征與統計線損率之間的MIC越大,則該特征與統計線損率之間的相關性越強;MIC越小,則相關性越弱。
在進行聚類或統計線損率估計時,每條饋線將用一個向量表征,輸入聚類模型或者估計模型中。饋線進行聚類與統計線損率估計時所用輸入向量有所不同,聚類時,輸入向量為統計線損率與其特征向量拼接所得,而進行統計線損率估計時,輸入向量即為特征向量。
1.2 K-Medoids聚類算法
不同饋線的線路供電量、配電變壓器(簡稱“配變”)額定容量等特征可能差別較大,這會影響模型對饋線統計線損率的估計性能。因此,將所選饋線特征輸入到聚類模型,確定饋線類別后再分別進行估計。K-Medoids聚類算法是一種基于劃分思想的聚類算法,該算法超參數少,且魯棒性高[27]。因此,使用K-Medoids聚類算法對饋線進行聚類。算法具體流程如圖1所示。

圖1 K-Medoids聚類算法流程

式中,為非聚類中心饋線的特征向量;為第個聚類簇中心饋線的特征向量。
聚類效果的評價指標為戴維森堡指數(Davies-Bouldin Index, DBI)和Calinski-Harabz指數(Calinski-Harabaz Index, CHI),計算公式分別為


式中,為聚類簇數;為第個聚類簇;為第個聚類簇;為第個簇內數據點到該簇質心的距離;d為聚類簇和之間的距離;D為饋線數據集的中心饋線。當DBI越小,CHI越大時,類內間距越小,類間間距越大,聚類的效果越好。
2 基于集成樹和混合專家系統的饋線統計線損率雙層估計模型
由于饋線種類復雜,單一估計模型往往只能對一部分饋線線損率具有較好的估計效果。Stacking集成估計模型可以融合多個估計模型優勢,該模型分為兩層,第一層為多個基估計模型,第二層為元估計模型。基于Stacking集成學習思想,本文提出基于集成樹和混合專家系統的雙層估計模型對各類型饋線統計線損率進行估計。首先,將饋線特征向量輸入各基估計模型(決策樹和集成樹模型)。然后將各基估計模型的估計結果送入元估計模型(混合專家系統)進行二次估計,得到最終的統計線損率估計結果。
2.1 基估計模型
本文主要選用決策樹(Decision Tree, DT)及集成樹模型作為基估計模型。對于線損率估計任務,估計模型的誤差主要來源于兩方面:一方面是估計偏差,另一方面是估計方差,兩者共同構成估計模型的估計誤差。
Bagging是并行集成方法,其每個基模型之間相互獨立,可以降低方差。隨機森林(Random Forest, RF)是基于Bagging思想的模型,給每一個基模型隨機分配相同數量的饋線,從而可以降低方差。ExtraTree與隨機森林相似,但ExtraTree直接使用所有饋線進行訓練,且線損率特征完全隨機分裂。隨機性的增強可以進一步減小估計方差,但可能會造成偏差增大。為此,將兩種估計模型均作為基估計模型來平衡方差和偏差,進而減小估計誤差。
Boosting是串行集成方法,每個弱估計器根據上一個弱估計器的估計結果進行權重更新,從而不斷改進模型,降低偏差。AdaBoost、GBDT、XGBoost是基于Boosting思想的三種模型。AdaBoost采用自適應策略,減少估計誤差大的饋線的權重,增大估計誤差小的饋線的權重。不同于AdaBoost通過調整饋線權重的方式訓練模型,GBDT是通過減少損失函數的梯度來更新權重,以最快的速度最小化饋線線損估計值與真實值之間的誤差為目標對估計模型進行擬合。考慮到AdaBoost和GBDT分別是從不同的角度降低偏差,為此將兩個模型均作為基估計模型。此外,XGBoost將GBDT的目標函數進行二階泰勒展開,同時加入了正則項,可以防止過擬合,也將其作為一個基估計模型。
由于估計模型復雜度的上升可能會導致估計方差變大,從而會導致過擬合,反而使估計效果變差。為此,將決策樹也作為一個基估計模型來平衡方差和偏差。綜上所述,本文選取決策樹、隨機森林、ExtraTree、GBDT、AdaBoost和XGBoost為饋線統計線損率估計基模型。
2.2 元估計模型——稀疏門控混合專家系統
模型融合是一種提高模型估計效果的有效方法。谷歌提出一種稀疏門控混合專家系統神經網絡,通過建立多個高度專業化的專家神經網絡深入挖掘數據中的潛在聯系,并使用稀疏門控網絡控制各專家系統的輸出,防止模型過擬合。MoE網絡結構如圖2所示。
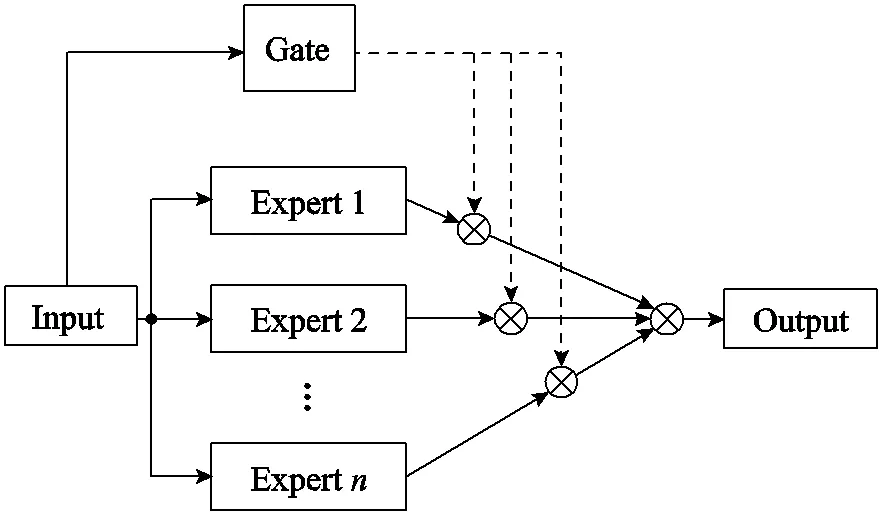
圖2 MoE網絡結構
將訓練數據輸入各個專家網絡(圖2中的Expert 1~Expert)和稀疏門控網絡(圖2中Gate),根據訓練數據不斷更新參數,建立起輸入與輸出之間的函數關系,實現每個專家系統的高度專業化。然后通過稀疏門控網絡控制各專家系統的輸出,最終的輸出可以表示為
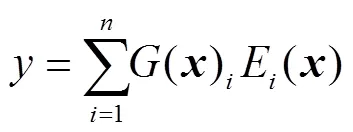


2.3 基于集成樹模型和MoE的饋線統計線損率雙層估計模型



圖3 所提估計模型架構
經過各基估計模型的估計后,將基估計模型估計結果向量輸入元估計模型(混合專家系統)中,得到最終的線損率估計結果pred為

2.4 評估指標
為了評估模型估計所得統計線損率的合理性與準確性,本文采用方均根誤差(Root Mean Square Error, RMSE)和平均絕對誤差(Mean Absolute Error, MAE)來衡量各估計模型的估計誤差。RMSE對數據異常值敏感,可以放大估計偏差較大點的誤差,MAE可以防止因正負誤差抵消而導致的誤差減小,其公式分別為
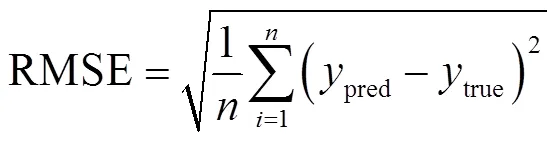

式中,為饋線條數;pred為統計線損率估計值;true為統計線損率真實值。由MAE和RMSE公式可知,估計模型的兩個指標值越小,其所估計的線損率越合理和準確。
3 算例分析
3.1 算例介紹和實驗配置
本文選取某市1 117條饋線對上述所提方法的有效性進行驗證。所采集數據均為線損管理系統中質量碼無問題的數據,每條饋線包含的記錄數據有統計線損率、理論線損率、線路總長度、線路供電量、線路投運時間、配變額定容量與配變投運時間。為了增強結果可信性,基于交叉驗證的思想,將數據分為10份。將數據集按照7:2:1比例劃分為訓練集、驗證集和測試集,取10次交叉驗證結果的均值作為模型的最終估計結果[15]。文中所涉及的機器學習模型基于Scikit-learn進行搭建,深度學習模型基于Keras和TensorFlow進行搭建。
3.2 特征有效性驗證
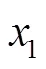

圖4 各特征最大信息系數
可以看到,理論線損率的最大信息系數為0.948,這從數據角度驗證了理論線損率與統計線損率之間的強相關關系。此外,其余各特征的MIC均在65%以上,這證明各特征與統計線損率之間均具有較高相關性,故可以將各特征作為饋線聚類和統計線損率估計的特征。
3.3 聚類簇數選擇
使用K-Medoids聚類算法對饋線進行聚類,分別計算饋線為2~9個類別時的CHI和DBI,CHI和DBI與聚類簇數的關系如圖5所示,當聚類簇為3時,CHI最大,DBI最小。亦即此時各類饋線之間的間距大,每類饋線內部各條饋線之間的間距小,聚類效果最優。因此,將饋線聚類為三類。其中,第1類饋線有588條,第2類饋線有355條,第3類饋線有174條。

圖5 CHI和DBI與聚類簇數的關系
3.4 聚類有效性驗證
為了驗證聚類對統計線損率估計效果的提升作用,本文將不同估計模型聚類前的RMSE和MAE與聚類后對三類饋線估計的總體RMSE和MAE進行對比,結果見表1。
表1 基估計模型聚類前后RMSE和MAE對比
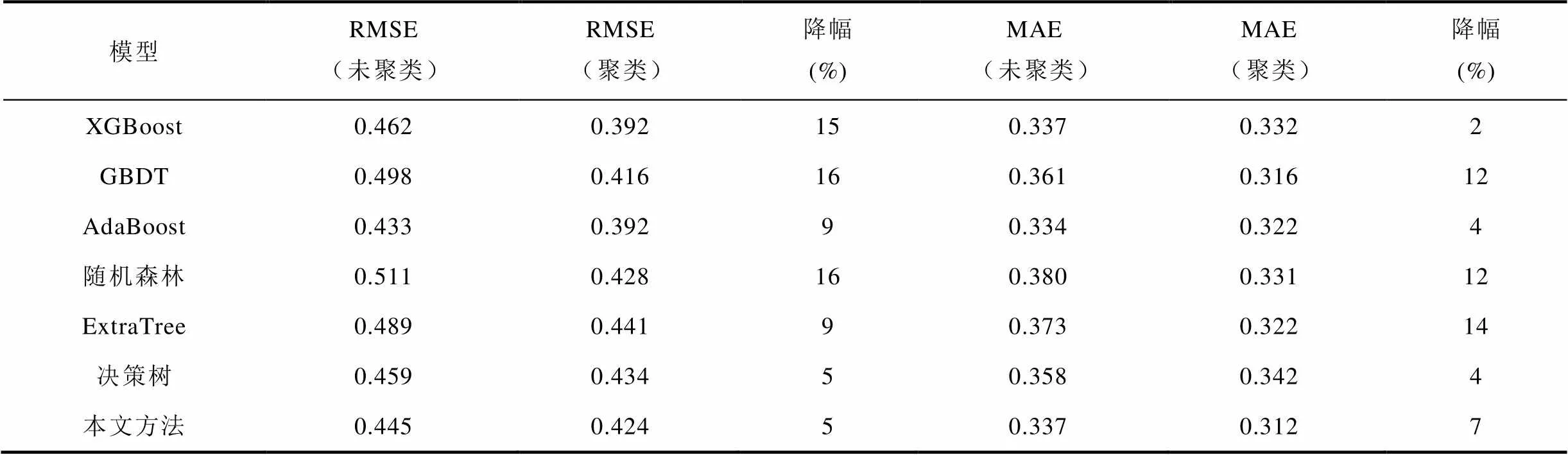
Tab.1 Comparison of RMSE and MAE before and after base estimator clustering
與未聚類時相比,經過聚類后,各基估計模型的RMSE和MAE均有所下降。其中,隨機森林和GBDT的RMSE下降了16%,ExtraTree的MAE下降了14%。本文所提方法的RMSE和MAE也下降了5%和7%。因此,對饋線進行聚類之后再估計,可以提高饋線統計線損率估計準確性。
3.5 各模型估計效果對比
為了驗證本文所提方法具有更好的估計效果,除了與各基估計模型的效果進行對比,本文還與線性加權模型進行對比。線性加權模型為

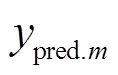
采取兩種方式進行權重分配,第一種為簡單加權(Simple Weighting, SW),即按照各基估計模型的估計誤差進行排序,本文選取估計誤差最小的四個模型,按照誤差降序分配0.1、0.2、0.3、0.4權重(見附表1~附表3)。第二種采用粒子群優化加權算法(Particle Swarm Optimization Weighting, PSOW),通過建立以估計誤差最小為目標的優化函數,使用粒子群算法尋優得到最優權重。優化函數為
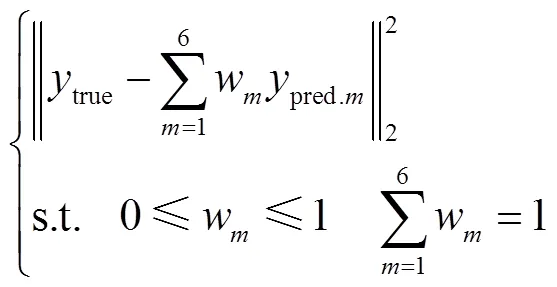
下面對各模型在三類饋線測試集上的表現進行分析,表2為各個模型進行線損率估計的RMSE和MAE對比,圖6、圖7和圖8分別為不同模型對各類饋線中每條饋線的線損估計誤差。
表2 各模型RMSE和MAE對比

Tab.2 RMSE and MAE comparison of each model
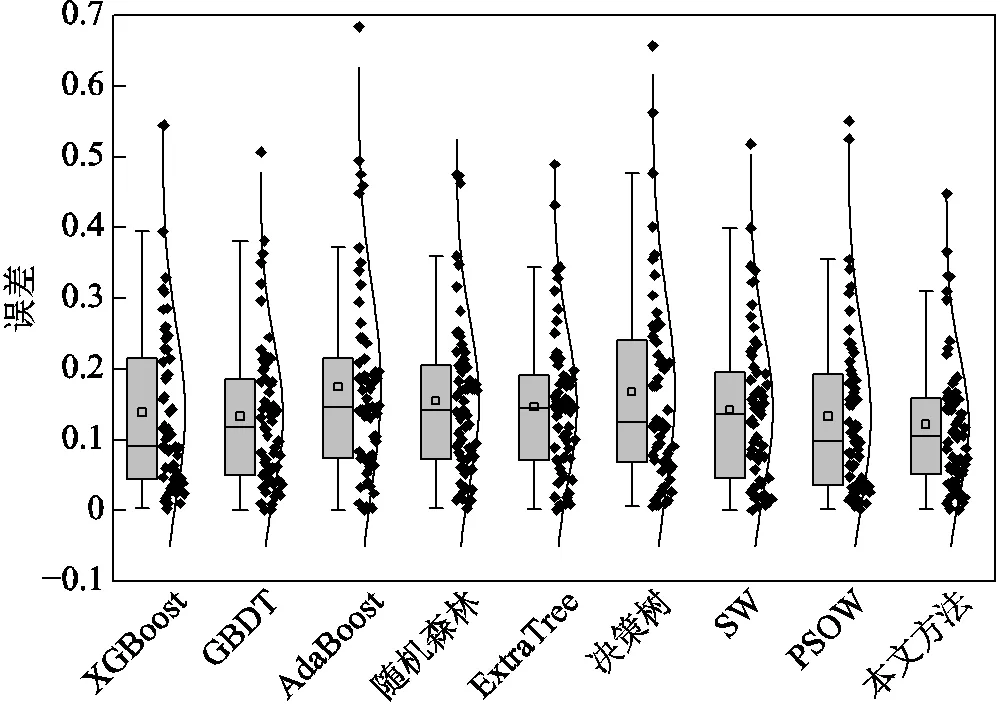
圖6 第一類饋線線損率誤差分布

圖7 第二類饋線線損率誤差分布
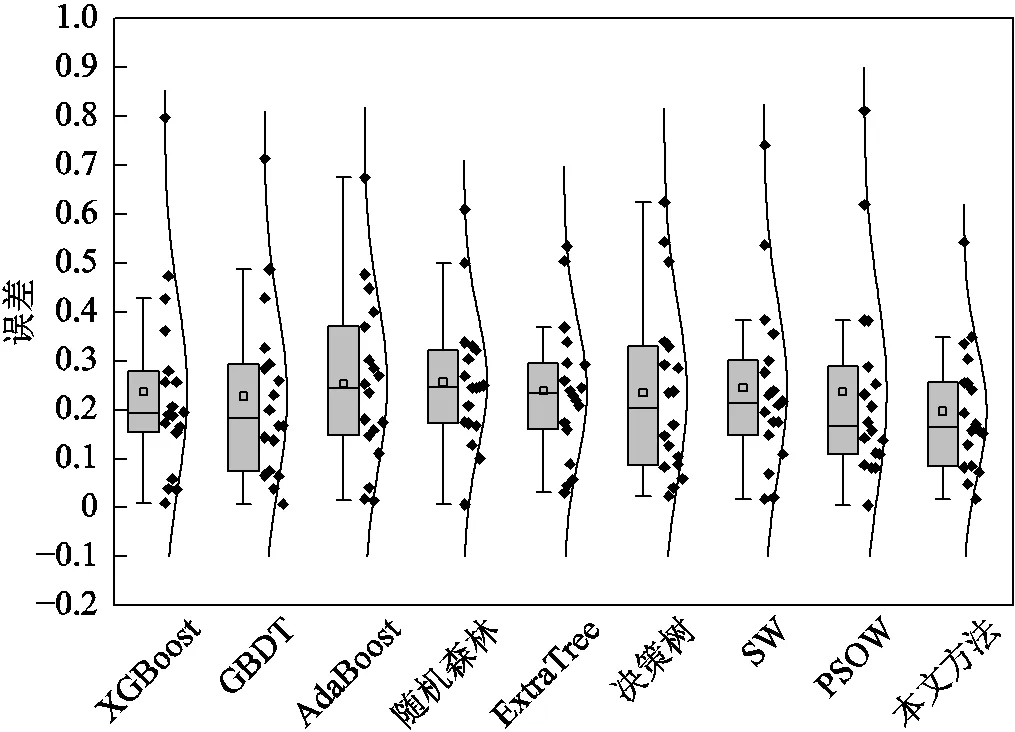
圖8 第三類饋線線損率誤差分布
首先分析各基估計模型對于不同類別饋線的估計結果。在六個基估計模型中,隨機森林模型對第一類和第二類饋線估計的RMSE均為最小。但在對第三類饋線進行估計的基模型中,隨機森林表現欠佳,ExtraTree的RMSE最小,其值為0.38。此外,在對第三類饋線進行估計時,ExtraTree的MAE也為最小。這是因為圖8中ExtraTree的線損估計誤差大部分分布在0.2~0.3附近,且離群點的離群程度較低。但在對第一類饋線和第二類饋線進行估計時,ExtraTree的性能不是最優。這說明,單個基估計模型只能對某些類別饋線線損率進行準確估計。
對比線性加權模型與各基模型,在對第一類和第二類饋線進行估計時,與各類饋線最優基模型(評估指標值最小的基估計模型)對比,線性加權模型的RMSE和MAE均有所下降,這是因為線性加權模型對估計結果進行二次集成,從而使估計準確性得到進一步提高。但在對第三類饋線進行線損率估計時,線性加權模型的RMSE與MAE均不如最優基估計模型,這是由于第三類饋線的數量較少,導致訓練過程中出現了嚴重過擬合,從而使得線性加權模型在測試集上效果變差。
由上述分析可知,與單一估計模型相比,線性加權估計模型能進一步提高饋線統計線損率估計準確性,但其還不能充分挖掘數據間的潛在關系,在對數量較少的第三類饋線進行線損率估計時易產生過擬合。因此,各單一估計模型和線性加權模型均不能實現對多種類型饋線線損率的準確估計。
本文所提模型在一定程度上解決了模型過擬合問題,實現了對各類饋線更準確的估計。在對第一類和第二類饋線進行線損率估計時,本文方法的RMSE分別比各類饋線最優基模型低5%和8%。這是因為,不同于SW和PSOW的線性加權,專家神經網絡中的不同專家可以深入挖掘線損數據的非線性關系,對于訓練樣本充足的第一類和第二類饋線,本文方法估計準確性高于各類饋線基估計模型和線性加權模型。在對訓練數據較少的第三類饋線進行估計時,雖然本文方法比ExtraTree的RMSE高1.8%,但其比線性加權模型降低了6.77%,在一定程度上防止了過擬合。
對比線性加權模型,在估計三類饋線時,由表2可知,本文方法的MAE分別下降7%、5%和11%。與各類饋線最優基估計模型相比,本文方法估計三類饋線統計線損率時,其MAE分別下降8%、7%和5%。由圖6~圖8也可以看到,在對每一類饋線進行線損率估計時,與其他模型相比,本文方法的誤差分布更集中于低誤差區域,而且本文方法的誤差分布中位數與平均值相近,這說明本文所提統計線損率估計模型的準確性和穩定性更好。
為了進一步驗證本文方法的可行性,選取文獻[15]和文獻[16]的方法對比,RMSE和MAE對比結果見表3。
表3 RMSE和MAE對比

Tab.3 RMSE and MAE comparison
由表3可知,本文方法的RMSE和MAE較其他兩種算法更低。在對第一類饋線進行估計時,本文方法比文獻[20]方法的MAE下降了11%。在對第三類饋線進行估計時,本文方法的RMSE比文獻[21]下降了9%。因為文獻[20]和文獻[21]的元估計模型為機器學習模型,其對數據挖掘的能力弱于混合專家系統。綜上可知,與現有的線損估計模型相比,本文所提基于集成樹模型和MoE的雙層估計模型對不同類型饋線統計線損率均有更好的估計效果。
4 結論
本文針對饋線統計線損率數據質量差的問題,提出了一種基于集成樹和MoE的饋線統計線損率雙層估計模型,得到以下主要結論:
1)使用最大信息系數選取理論線損率及相關饋線特征為饋線聚類和統計線損率估計的特征指標,并驗證了K-Medoids聚類可以提高饋線統計線損率估計準確性。
2)基于Stacking集成學習思想,使用集成樹模型和混合專家系統對饋線統計線損率進行兩階段估計。選用決策樹及不同集成樹模型作為基估計模型進行初步估計,使用混合專家系統網絡作為元估計模型進行最終估計。相比于其他集成估計模型,本文所提估計模型對饋線統計線損率具有更好的估計效果。
3)對于訓練樣本較少的第三類饋線,本文方法存在一定程度的過擬合,后續可圍繞小樣本集下的饋線統計線損率估計進行研究。
附 錄
附表1 第一類饋線各模型參數
App.Tab.1 Model parameters of the first kind of feeder

模型名稱模型參數 XGBoostmax_depth = 25, n_estimators=30 GBDTn_estimators=25,max_depth=15,min_samples_leaf=15,min_samples_split=10 AdaBoostn_estimators=50,max_depth=10,min_samples_leaf=15,min_samples_split=10 隨機森林n_estimators=50,max_depth=15,min_samples_leaf=10,min_samples_split=10 ExtraTreen_estimators=50,max_depth=5,min_samples_leaf=5,min_samples_split=10 決策樹max_depth=8,min_samples_leaf=10,min_samples_split=10 SW權重向量w=[0,0.1,0.2,0.4,0.3,0] PSOW權重向量w=[0.75,0.21,0,0,0.04,0] MoE特征共享層:units=100, num_experts=6任務層:Dense層(units=64,32,16,1)
附表2 第二類饋線各模型參數
App.Tab.2 Model parameters of the second kind of feeder

模型名稱模型參數 XGBoostmax_depth = 10,n_estimators=10 GBDTn_estimators=50,max_depth=15,min_samples_leaf=15,min_samples_split=10 AdaBoostn_estimators=50,max_depth=10,min_samples_leaf=15,min_samples_split=10 隨機森林n_estimators=60,max_depth=15,min_samples_leaf=15,min_samples_split=10 ExtraTreen_estimators=15,max_depth=20,min_samples_leaf=15,min_samples_split=10 決策樹max_depth=10,min_samples_leaf=5,min_samples_split=10 SW權重向量w=[0.1,0.2,0,0.3,0,0.4] PSOW權重向量w=[0.2,0,0.32,0,0.38,0.1] MoE特征共享層:units=30, num_experts=6任務層:Dense層(units=16,8,1)
附表3 第三類饋線各模型參數
App.Tab.3 Model parameters of the third kind of feeder

模型名稱模型參數 XGBoostmax_depth = 5, n_estimators=50 GBDTn_estimators=50,max_depth=5,min_samples_leaf=5,min_samples_split=5 AdaBoostn_estimators=50,max_depth=10,min_samples_leaf=1,min_samples_split=2 隨機森林n_estimators=10,max_depth=5,min_samples_leaf=5,min_samples_split=5 ExtraTreen_estimators=15,max_depth=5,min_samples_leaf=5,min_samples_split=5 決策樹max_depth=15,min_samples_leaf=1,min_samples_split=2 SW權重向量w=[0.1,0.3,0,0.2,0.4,0] PSOW權重向量w=[0,0.1,0.8,0,0.1,0] MoE特征共享層:units=10, num_experts=6任務層:Dense層(units=6,3,1)
[1] 南方電網公司. 2021年綠色低碳發展年刊[EB/OL]. (2022-06-13)[2022-10-20].https://www.csg.cn/shzr/ zrbg/202206/P020220613351130050261.
[2] 馬喜平, 賈嶸, 梁琛, 等. 高比例新能源接入下電力系統降損研究綜述[J]. 電網技術, 2022, 46(11): 4305-4315.
Ma Xiping, Jia Rong, Liang Chen, et al. Review of researches on loss reduction in context of high penetration of renewable power generation[J]. Power System Technology, 2022, 46(11): 4305-4315.
[3] 王方雨, 劉文穎, 陳鑫鑫, 等. 基于“秩和”近似相等特性的同期線損異常數據辨識方法[J]. 電工技術學報, 2020, 35(22): 4771-4783.
Wang Fangyu, Liu Wenying, Chen Xinxin, et al. Abnormal data identification of synchronous line loss based on the approximate equality of rank sum[J]. Transactions of China Electrotechnical Society, 2020, 35(22): 4771-4783.
[4] 唐登平, 李俊, 孟展, 等. 統計線損數據準確性研究[J]. 電力系統保護與控制, 2018, 46(24): 33-39.
Tang Dengping, Li Jun, Meng Zhan, et al. Research on accuracy of statistical line losses[J]. Power System Protection and Control, 2018, 46(24): 33-39.
[5] 黃彥欽, 余浩, 尹鈞毅, 等. 電力物聯網數據傳輸方案:現狀與基于5G技術的展望[J]. 電工技術學報, 2021, 36(17): 3581-3593.
Huang Yanqin, Yu Hao, Yin Junyi, et al. Data transmission schemes of power Internet of Things: present and outlook based on 5G technology[J]. Transactions of China Electrotechnical Society, 2021, 36(17): 3581-3593.
[6] 馬偉明. 關于電工學科前沿技術發展的若干思考[J]. 電工技術學報, 2021, 36(22): 4627-4636.
Ma Weiming. Thoughts on the development of frontier technology in electrical engineering[J]. Transactions of China Electrotechnical Society, 2021, 36(22): 4627-4636.
[7] 劉晟源, 章天晗, 林振智, 等. 數據賦能低壓配用電系統精益化運行的關鍵技術與算法[J]. 電力系統自動化, 2023, 47(3): 187-199.
Liu Shengyuan, Zhang Tianhan, Lin Zhenzhi, et al. Key technologies and algorithms of data empowerment for lean operation of low-voltage power distribution and consumption system[J]. Automation of Electric Power Systems, 2023, 47(3): 187-199.
[8] 李鵬, 習偉, 蔡田田, 等. 數字電網的理念、架構與關鍵技術[J]. 中國電機工程學報, 2022, 42(14): 5002-5017.
Li Peng, Xi Wei, Cai Tiantian, et al. Concept, architecture and key technologies of digital power grids[J]. Proceedings of the CSEE, 2022, 42(14): 5002-5017.
[9] 徐煥增, 孔政敏, 王帥, 等. 基于動態線損及FMRLS算法的智能電表誤差在線評估模型[J]. 中國電機工程學報, 2021, 41(24): 8349-8358.
Xu Huanzeng, Kong Zhengmin, Wang Shuai, et al. Online error evaluation model of smart meter based on dynamic line loss and FMRLS algorithm[J]. Proceedings of the CSEE, 2021, 41(24): 8349-8358.
[10] 彭建春, 李春暉, 祁學紅, 等. 基于快速獨立成分分析和支持向量回歸的混合饋線線損估算[J]. 電力系統保護與控制, 2012, 40(3): 51-55.
Peng Jianchun, Li Chunhui, Qi Xuehong, et al. Loss estimation of power distribution systems based on fast independent component analysis and support vector regression[J]. Power System Protection and Control, 2012, 40(3): 51-55.
[11] 徐茹枝, 王宇飛. 粒子群優化的支持向量回歸機計算配電網理論線損方法[J]. 電力自動化設備, 2012, 32(5): 86-89, 93.
Xu Ruzhi, Wang Yufei. Theoretical line loss calculation based on SVR and PSO for distribution system[J]. Electric Power Automation Equipment, 2012, 32(5): 86-89, 93.
[12] 張義濤, 王澤忠, 劉麗平, 等. 基于灰色關聯分析和改進神經網絡的10 kV配電網線損預測[J]. 電網技術, 2019, 43(4): 1404-1410.
Zhang Yitao, Wang Zezhong, Liu Liping, et al. A 10 kV distribution network line loss prediction method based on grey correlation analysis and improved artificial neural network[J]. Power System Technology, 2019, 43(4): 1404-1410.
[13] 周王峰, 李勇, 郭釔秀, 等. 基于DAE-LSTM神經網絡的配電網日線損率預測[J]. 電力系統保護與控制, 2021, 49(17): 48-56.
Zhou Wangfeng, Li Yong, Guo Yixiu, et al. Daily line loss rate forecasting of a distribution network based on DAE-LSTM[J]. Power System Protection and Control, 2021, 49(17): 48-56.
[14] 盧志剛, 楊英杰, 李學平, 等. 基于深度遷移學習理論含風電光伏系統的地區電網網損率計算[J]. 中國電機工程學報, 2020, 40(13): 4102-4111.
Lu Zhigang, Yang Yingjie, Li Xueping, et al. A deep migration learning based power loss rate calculation method for distributed power system with wind and solar generation[J]. Proceedings of the CSEE, 2020, 40(13): 4102-4111.
[15] 歐陽森, 馮天瑞, 安曉華. 考慮饋線聚類特性的中壓配網線損率測算模型[J]. 電力自動化設備, 2016, 36(9): 33-39.
Ouyang Sen, Feng Tianrui, An Xiaohua. Line-loss rate calculation model considering feeder clustering features for medium-voltage distribution network[J]. Electric Power Automation Equipment, 2016, 36(9): 33-39.
[16] 徐建軍, 黃立達, 閆麗梅, 等. 基于層次多任務深度學習的絕緣子自爆缺陷檢測[J]. 電工技術學報, 2021, 36(7): 1407-1415.
Xu Jianjun, Huang Lida, Yan Limei, et al. Insulator self-explosion defect detection based on hierarchical multi-task deep learning[J]. Transactions of China Electrotechnical Society, 2021, 36(7): 1407-1415.
[17] 王守相, 周凱, 蘇運. 基于隨機森林算法的臺區合理線損率估計方法[J]. 電力自動化設備, 2017, 37(11): 39-45.
Wang Shouxiang, Zhou Kai, Su Yun. Line loss rate estimation method of transformer district based on random forest algorithm[J]. Electric Power Automation Equipment, 2017, 37(11): 39-45.
[18] Wang Shouxiang, Dong Pengfei, Tian Yingjie. A novel method of statistical line loss estimation for distribution feeders based on feeder cluster and modified XGBoost[J]. Energies, 2017, 10(12): 2067.
[19] 馬良玉, 程善珍. 基于支持向量數據描述和XGBoost的風電機組異常工況預警研究[J]. 電工技術學報, 2022, 37(13): 3241-3249.
Ma Liangyu, Cheng Shanzhen. Abnormal state early warning of wind turbine generator based on support vector data description and XGBoost[J]. Transactions of China Electrotechnical Society, 2022, 37(13): 3241-3249.
[20] 鄧威, 郭釔秀, 李勇, 等. 基于特征選擇和Stacking集成學習的配電網網損預測[J]. 電力系統保護與控制, 2020, 48(15): 108-115.
Deng Wei, Guo Yixiu, Li Yong, et al. Power losses prediction based on feature selection and Stacking integrated learning[J]. Power System Protection and Control, 2020, 48(15): 108-115.
[21] 董美娜, 劉麗平, 王澤忠, 等. 基于Stacking集成學習的有源臺區線損率評估方法[J]. 電測與儀表, 2023, 60(6): 134-139.
Dong Meina, Liu Liping, Wang Zezhong, et al. A line loss rate evaluation method based on Stacking ensemble learning for transformer district with DG[J]. Eleetrical Measurement & Instrumentation, 2023, 60(6): 134-139.
[22] Khodayar M, Liu Guangyi, Wang Jianhui, et al. Deep learning in power systems research: a review[J]. CSEE Journal of Power and Energy Systems, 2020, 7(2): 209-220.
[23] Shazeer N, Mirhoseini A, Maziarz K, et al. Outrageously large neural networks: the sparsely-gated mixture-of-experts layer[EB/OL]. 2017: arXiv: 1701.06538. https://arxiv.org/abs/1701.06538.
[24] Sambasivam G, Amudhavel J, Sathya G. A predictive performance analysis of vitamin D deficiency severity using machine learning methods[J]. IEEE Access, 2020, 8: 109492-109507.
[25] 賈科, 宣振文, 林瑤琦, 等. 基于Adaboost算法的并網光伏發電系統的孤島檢測法[J]. 電工技術學報, 2018, 33(5): 1106-1113.
Jia Ke, Xuan Zhenwen, Lin Yaoqi, et al. An islanding detection method for grid-connected photovoltaic power system based on adaboost algorithm[J]. Transactions of China Electrotechnical Society, 2018, 33(5): 1106-1113.
[26] 邱高, 劉俊勇, 劉友波, 等. 風電外送通道極限傳輸能力的自適應向量機估計[J]. 電工技術學報, 2018, 33(14): 3342-3352.
Qiu Gao, Liu Junyong, Liu Youbo, et al. Adaptive support vector machine estimation for total transfer capability of wind power exporting corridors[J]. Transactions of China Electrotechnical Society, 2018, 33(14): 3342-3352.
[27] 胡聰, 徐敏, 洪德華, 等. 基于改進K-medoids聚類和SVM的異常用電模式在線檢測方法[J]. 國外電子測量技術, 2022, 41(2): 53-59.
Hu Cong, Xu Min, Hong Dehua, et al. Online detection method for abnormal electricity model behavior based on improved K-medoids clustering and SVM[J]. Foreign Electronic Measurement Technology, 2022, 41(2): 53-59.
Double-Layers Stacking Estimation Model for Feeder Statistical Line Loss Rate Based on Tree-Based Ensemble Learning and MoE
Wang Shouxiang1,2Zhang Bingjie1,2Zhao Qianyu1,2Guo Luyang1,2Zhang Sheng1,2
(1. Key Laboratory of Smart Grid of Ministry of Education Tianjin University Tianjin 300072 China 2. Tianjin Key Laboratory of Power System Simulation and Control Tianjin University Tianjin 300072 China)
Reducing line loss is important for power grids to save energy and achieve carbon neutrality. Statistical line loss rate is an important indicator for the refined management of line loss in the power grid. However, abnormal data collection of power consumption, interruption of data transmission and other factors lead to the abnormality or missing of statistical line loss rate. At present, the ensemble learning framework is applied to the field of line loss estimation, but models used for estimation are all machine learning models, so the estimation accuracy needs to be improved. In order to improve the accuracy of statistical line loss rate estimation, a double-layers estimation model for feeder statistical line loss rate based on tree-based ensemble learning and mixture of experts (MoE) is proposed.
Firstly, the maximum information coefficient (MIC) is used to effectively analyze the nonlinear relationship between the statistical line loss rate and its correlated features, so as to build a feature set of statistical line loss rate. Secondly, the feature vector of each feeder is input to the robust K-Medoids clustering algorithm to realize the fine division of feeders. Thirdly, using the Stacking integrated learning framework, the feeder statistical line loss rate is estimated in two stages based on the base estimation and meta estimation double-layer models. The decision tree, gradient boosting decision tree (GBDT), adaptive Boosting (AdaBoost), extreme gradient Boosting (XGBoost), random forest and extremely randomized tree (ExtraTree) are selected as base estimation models for preliminary estimation of the statistical line loss rate, and the output results of each base estimation model are input into the meta estimation model MoE for final estimation.
A comprehensive set of experiments has been conducted on a real-world feeder statistical line loss rate dataset (1) The MIC values of statistical line loss rate and theoretical line loss rate, total length of line, line power supply, line operation time, rated capacity of distribution transformer, operation time of distribution transformer are respectively 0.948, 0.81, 0.701, 0.672, 0.768 and 0.683, which demonstrates the high correlation between each feature and the statistical line loss rate. (2) Feature vectors are fed into the K-medoids algorithm, feeders are divided into three parts. Through clustering, the total RMSE and MAE of statistical line loss rate estimated by the proposed model are decreased by 5% and 7% respectively. (3) Compared with other models, the error distribution of proposed model is concentrated in the low error area, and the between the median value and the mean value is closer, which means the proposed model has better accuracy and stability. The comparison between the proposed model and other ensemble model which has the best performance shows that, the RMSE of each type of feeders estimated by the proposed model are reduced by 4%, 2%, 5% respectively, and the MAE of each type of feeders estimated by the proposed model are reduced by 10%, 3%, 9% respectively.
The following conclusions can be drawn from the simulation analysis: (1) The maximum information coefficient is used to verify the rationality of using the theoretical line loss rate and its related features for feeder clustering and statistical line loss rate estimation. (2) Compared with direct estimation, the estimation accuracy of statistical line loss rate can be improved by clustering feeders using K-medoids algorithm. (3) Compared with the existing ensemble estimation model, the estimation model proposed in this paper has lower RMSE and MAE, which means the statistical line loss rate estimated by the proposed model is more reasonable.
Statistical line loss rate, line loss rate estimation, machine learning, tree-based ensemble learning, mixture of experts
TM744
10.19595/j.cnki.1000-6753.tces.221994
國家自然科學基金資助項目(U2166202)。
2022-10-20
2023-01-27
王守相 男,1973年生,博士,教授,博士生導師,研究方向為分布式發電、微網與智能配電網等。E-mail:sxwang@tju.edu.cn。
郭陸陽 男,1995年生,博士研究生,研究方向為智能配電網。E-mail:guoluyang@tju.edu.cn(通信作者)
(編輯 赫 蕾)
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
