基于局部線性重疊聚類算法的網絡攻擊溯源分析方法*
2024-02-16 08:47:08王亮,鐘夫,黃健
通信技術 2024年1期
王 亮,鐘 夫,黃 健
(中電科網絡安全科技股份公司,四川 成都 610095)
0 引言
隨著網絡技術的發展和信息化程度的提高,網絡規模和信息系統也日趨龐大和復雜,科技的進步提升了人們的工作效能和生活便利,但也給網絡空間帶來了更大的安全風險和威脅。針對高價值目標,出于商業或政治動機,網絡攻擊者個體或團隊不再沿用過往單一的攻擊模式,而是在一個較長周期內,結合多種先進的方法、工具及技術,持續和隱蔽地損害目標利益。因此,通過入侵檢測系統、防火墻、Web 應用防護系統(Web Application Firewall,WAF)等傳統網絡安全防護體系提供的不完備的、孤島式的檢測信息來識別風險和威脅,存在信息冗余高、虛檢和漏檢頻繁的問題[1]。為了應對日趨嚴峻的網絡安全形勢,很多企業搭建了安全運營中心(Security Operations Center,SOC)體系,集中化管理安全產品的日志、事件和告警,并且平臺大都提供基于規則匹配的關聯分析機制,但由于普遍缺乏安全風險上下文,且只能識別已知威脅,信息孤島效應還是沒有得以解決[2]。近來,依托大數據、人工智能技術的迭代演進,以及高級持續性威脅的研究,出現了一些面向攻擊溯源的分析方法,大體思路為基于海量數據,結合網絡攻擊過程模型[3],根據資產、安全產品日志和網絡流量的時間和空間相關性,來構建大數據[4-9]、機器學習[10-11]或者知識圖譜[12-17]的檢測模型,還原攻擊過程和路徑;但這些方法或多或少面臨海量數據的計算復雜度過高,欠缺高質量的標簽數據,沒有先驗信息和專家知識,復雜威脅過程還原能力弱,攻擊路徑溯源容錯率低等問題,因此尚無有效的規模應用。
對此,本文提出了一種基于局部線性重疊聚類算法的網絡攻擊溯源分析方法。該方法首先挖掘安全產品上報日志中的攻擊特征,據此對資產、海量安全事件進行社團劃分;其次綜合分析社團中攻擊鏈階段、攻擊時序、攻擊源和目標信息等的局部線性關系,通過重疊聚類算法進行攻擊路徑溯源。該方法較好地解決了上述海量安全事件處理復雜度高、攻擊路徑溯源容錯率低等問題。
1 相關技術
1.1 溯源圖譜
溯源圖譜是根據設備上報告警生成的具有有向圖結構的數據,可以用于描述系統行為。所有系統級別的實體被當作溯源圖中的節點,而實體之間的操作被當作溯源圖的邊。根據目前設備上報的內容分析,將唯一IP 作為實體,IP 與IP 之間的交互事件類型作為邊,因此定義如下:
定義1:“溯源圖譜”是一個帶有標簽的有向無循環圖,G=(V,E,L,M,K,Z)。其中,V是圖中的頂點,表示攻擊過程事件中的網絡實體集合;E是圖中邊的集合,描述網絡實體之間的關系;L是網絡實體數據類型標簽集合;M是網絡實體和標簽的映射集合;K表示V事件的集合;Z表示E事件的集合。
定義2:“網絡實體”是網絡中存在的IP 地址。
定義3:“網絡實體關系”表示網絡實體之間的相互作用和聯系。
具體的溯源圖譜如圖1 所示。
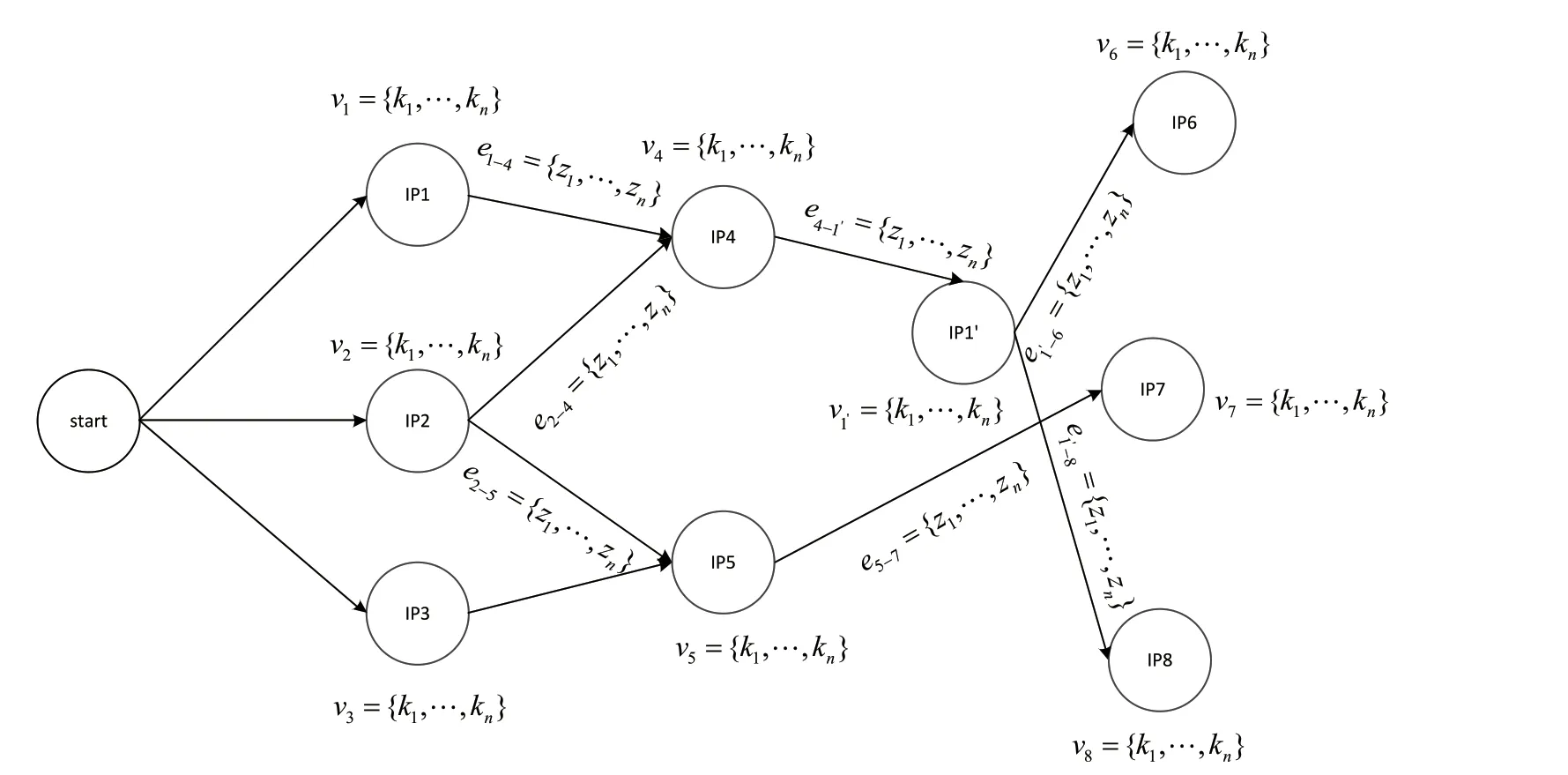
圖1 溯源圖譜
如圖1所示,頂點V、邊E、實體類型標簽集合L、實體與標簽的集合M、頂點事件集合K、邊事件集合表示如下:
1.2 攻擊溯源
攻擊溯源是在溯源圖G中以v為開始節點,使得G中存在li條路徑,當該li的概率超過某個閾值時,則為G的可疑網絡攻擊鏈路,其數學定義為:
式中:top_prob為計算攻擊鏈路的概率函數,thread表示閾值。,如圖2所示。
圖2 中,加粗實線表示最有可能的攻擊鏈路,虛線表示的可行性較低一些,細實線表示不太可能的攻擊鏈路。其中,z表示邊事件集合,k表示節點事件集合,如果該事件參與了鏈路中相關攻擊過程,則對其進行標注。
2 基于重疊聚類技術的攻擊溯源分析
攻擊場景由事件組成,在形成的社團中,事件數量較多,且事件與事件相互形成的攻擊特性的事件組合也非常多,無法通過枚舉的方式進行一一判斷符合攻擊場景的事件組合,因此本文選用Cyber Kill Chain 網絡攻擊模型進行建模,在離散的攻擊事件之間建立連接并構建符合認知的攻擊場景,從而輔助執行攻擊行為檢測、評估和防御等各個流程[18]。Cyber Kill Chain 模型將網絡攻擊鏈總結為7 個步驟,即偵察目標、投遞植入、漏洞利用、安裝駐留、命令控制、行動收割、清除痕跡。在利用該模型進行攻擊路徑溯源的過程中,由于某一個攻擊步驟是下一個攻擊產生的前提,滿足攻擊路徑溯源的組合事件較多,且存在某一個步驟屬于其他攻擊路徑溯源中的攻擊步驟,因此攻擊路徑溯源存在重疊性,為此定義其數學模型如下:
給定數據集X={x1,x2,…,xn}∈?n×m,使得f(X)=O,其中O={(x1,x2,…,xn),(xo,xp,…,xi),L,(xf,xm,…,xj)}表示數據集X被分配到不同的攻擊場景集合中。
本文設計的攻擊溯源分析流程包括數據源采集、構建溯源圖、劃分攻擊社團和通過重疊聚類進行攻擊溯源4 個步驟,如圖3 所示。
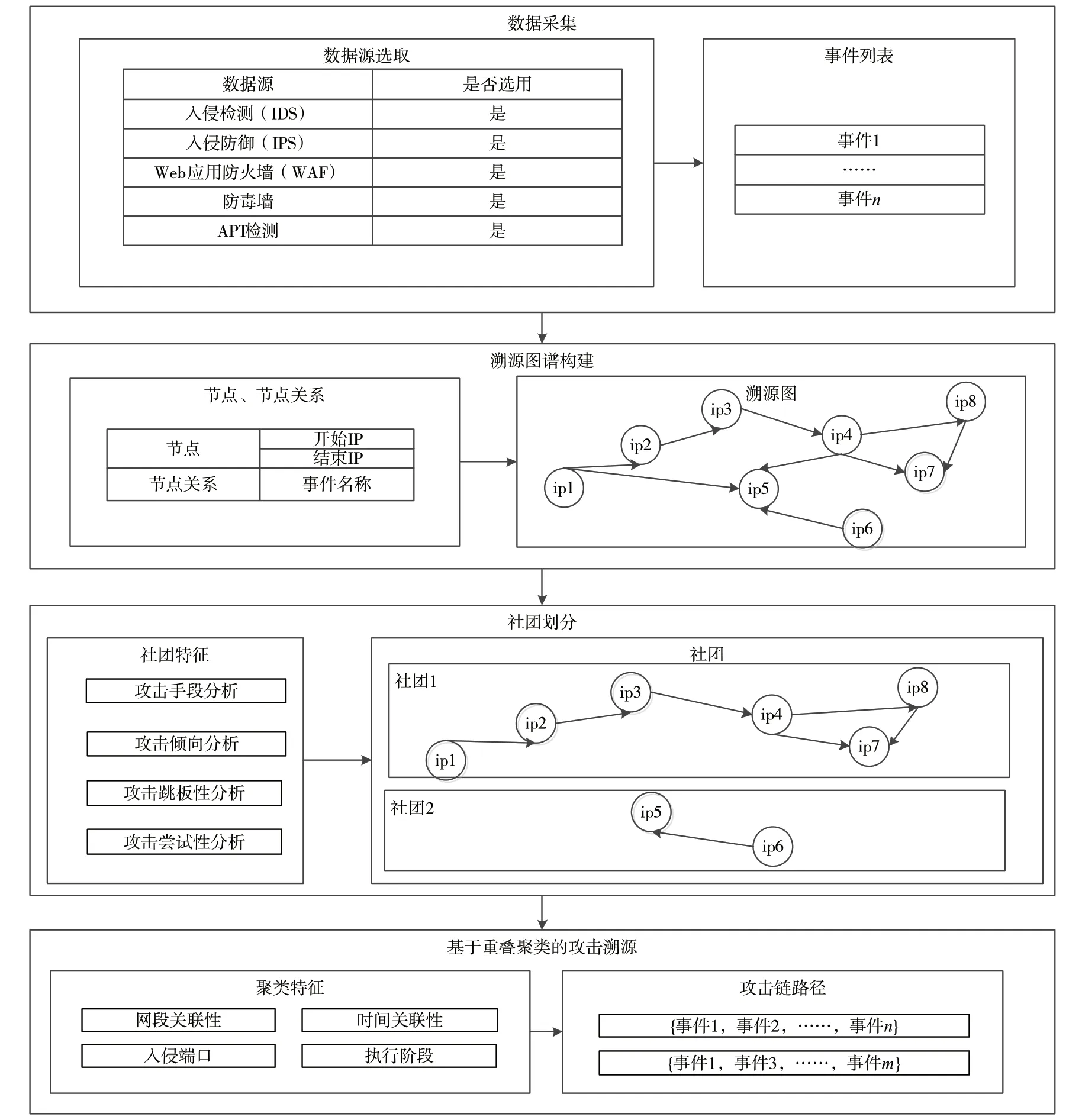
圖3 攻擊溯源的分析流程
在圖3 中,數據采集主要來自安全設備上報的日志,作為構建溯源圖的數據輸入。考慮到數據量規模帶來的計算復雜度,利用網絡攻擊的社團性進行社團劃分,從而減輕其溯源的計算量,最后應用于重疊聚類算法對社團進行攻擊溯源分析,得到可疑度高的攻擊溯源相關事件。
2.1 數據源采集
常見的數據源有流量檢測日志、安全設備日志、訪問記錄、服務運行日志、用戶認證記錄、pcap 日志包、威脅情報、服務運行狀態等。根據目前所具有的采集能力,采集的數據主要來自入侵檢測(Intrusion Detection System,IDS)、入侵防御(Intrusion Prevention System,IPS)、Web 應用防火墻(Web Application Firewall,WAF)、防毒墻、高級持續性威脅(Advanced Persistent Threat,APT)檢測設備,并按照相關事件模型定義進行抽取,其攻擊階段屬性符合Kill Chain 模型,按照時間順序進行事件存儲。
2.2 構建溯源圖
第1 個階段主要是構建溯源圖結構,從圖譜的結構出發對網絡攻擊進行分析,因此根據定義1、2、3 構建溯源圖,其中,原始數據分為兩類:一類是節點事件,形成節點,該事件只有HostIP 值,沒有源IP 和目的IP 的值;另一類是節點與節點產生邊的事件,該事件具有源IP 和目的IP 的值。
將第1 類事件產出的所有事件形成一個節點,并將該節點包含的所有事件用數組的屬性保存;第2 類事件對應形成節點與節點的邊關系,并與第1類事件具有相同的IP 進行事件融合,若源IP 或者目的IP 與第1 類事件IP 相同,則不生成新的節點,否則添加新的節點。
2.3 基于攻擊特性的溯源圖社團劃分
由于原始數據在一段時間中產生的量特別巨大,且從攻擊的宏觀性角度來看,其具有社團性的特點,因此在這個階段的主要目標是通過社團的劃分減少攻擊溯源的計算量,以及在分割的過程中減少攻擊事件的錯誤劃分。對此,根據定義節點間的攻擊性的權重向量對社團進行劃分,且社團劃分為無監督劃分,根據權重向量對社團的增益性進行劃分。
針對溯源圖譜中的攻擊特性,經過相關安全專家討論,設計如表1 所示的節點間事件數量的變化性、節點間的交互性、節點間的事件類別多樣性、節點所處溯源網絡結構的最大深度4 個指標,作為溯源圖中邊的攻擊特性衡量的向量,并利用信息熵對這4 個指標進行線性加權,得到邊的權重。

表1 溯源圖譜攻擊特征
根據表1,進行如下定義。
定義4:單位時間內節點間數量變化np1=max(在一段時間內,上一時刻與下一時刻產生的斜率),表示一種攻擊的可能性。
定義6:事件類別np3=max(在一段時間內,上一時刻與下一時刻產生的斜率),表示攻擊手段的變化性。
節點邊的權重為以上定義的4 個特征的信息熵,并利用相關社團劃分算法對溯源圖進行社團劃分,其中信息熵計算公式如下:
2.4 重疊聚類
研究發現,僅利用X={x1,x2,…,xn}的Kill Chain模型的攻擊階段屬性來構建離散攻擊事件的攻擊場景有局限性,如分布式拒絕服務(Distributed Denial of Service,DDOS)攻擊在事件的表現上具有時間性的特點,為此參考文獻[19]中事件攻擊相似性的處理,使用時間關聯性、網段關聯特性、入侵端口、執行的階段性這4個特征作為攻擊路徑溯源的依據,具體特征如表2 所示。

表2 事件特征
根據表2 的事件特征,本文定義特征計算方式如下文所述,其中ai和aj分別代表兩組數據且j>i。
(1)時間引起的事件關聯性:時間反映了攻擊事件之間的前后關系,隨著時間的推移,兩個攻擊事件之間的關聯性逐漸減弱。其相似性度量可定義為:
(2)網段關聯特性:一般而言,攻擊方的IP地址大都從同一網段中發起,因此同一攻擊方在IDS 告警日志的源IP 或目的IP 上具有相似性。其相似性度量可定義為:
式中:M=max{H(ai,sIP,aj,sIP),H(ai,sIP,aj,dIP)},H(ai,dIP,aj,sIP),H(ai,dIP,aj,dIP),其中H函數是兩個IP 地址的二進制表示從左到右位相同的數目,sIP指源IP 地址,dIP指目的IP 地址。
(3)入侵端口:假使攻擊方使用不同的工具進行服務器入侵訪問并成功得手,那么這兩條數據的HTTP 請求方法、服務器端口號、客戶端端口號、客戶端環境、HTTP 響應碼應該具有相同之處。目前原始信息中只有相關端口,因此其相似性度量定義為:
(4)執行的階段性:從殺傷鏈的特點來看,前一條事件的攻擊方法造成的結果可能是展開下一條事件中的攻擊方法的前提條件。其相似性度量可定義為:
目前大部分對攻擊路徑溯源的方法都是非重疊性的處理,使得攻擊路徑溯源的容錯率較低。雖然有利用重疊算法進行直接聚類的,但是在構造攻擊溯源路徑特征進行距離計算時,存在對屬性特征變化不敏感的情況。為此本文提出基于局部線性重疊的聚類算法對攻擊路徑溯源進行聚類,具體計算過程如下文所述。
(1)局部線性處理。xi與xj在歐式空間中的關系如圖4 所示。為了使得特征距離計算具有敏感性,利用該相互關系進行表示。同時,為了滿足xi在高維空間中的稀疏性,利用局部線性進行處理,并且為了關注xi形成的所有可能的攻擊路徑,利用近鄰點進行表示。
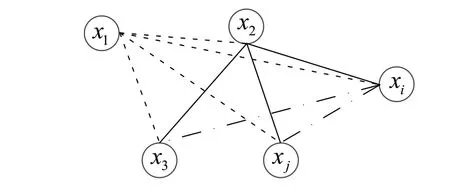
圖4 局部近鄰點
因此,xi由其k個近鄰點表示:
式中:lj為噪聲點,fjk為相似性。
(2)K 近鄰點的確定。K 近鄰點的確定大部分是利用K 最近鄰(k-Nearest Neighbor,KNN)算法找出其k個近鄰點。在攻擊溯源路徑中,特別是路徑的最后一步,其與之相鄰的點往往小于k個點,因此k近鄰點是不固定的,故而通過對xi利用kmeans 進行聚類,確定近鄰點個數。
(3)fjk的權重求解。為了使得fjk盡可能與X矩陣相似,構造的數學模型如下:
式中:||·||F為范數,λ是為了引入噪聲添加的系數。
(4)重疊聚類。本文參考基于圖熵聚類的重疊社區發現算法[20]中利用信息熵的思路,進行重疊聚類算法設計,步驟如下:
①將數據集中的xi作為候選節點,從候選節點中選取部分節點存入種子集合中;
②隨機選取種子集合中的一個節點,并加入其所有鄰居節點組合成一個類;
③計算聚類中鄰居節點的熵值,如果熵值降低則移除;
④計算其聚類外的邊界點的熵值,如果熵值降低則添加;
⑤輸出具有最小熵值的聚類并從種子集中刪除該種子;
⑥重復以上步驟直到種子集中沒有種子剩余。
3 應用列舉
本文提出的算法已作為安全運行監管系統的核心能力應用于威脅監測模塊,在某企業的實際使用中,針對不同廠商上報的威脅日志,安全運行監管系統會對網絡攻擊類和惡意代碼類威脅事件按照標準數據模型進行轉換,并按事件模型定義對齊進行信息補全,再進行數據抽取、構圖、分析,最后利用相關的數據構造溯源圖,如圖5 所示。
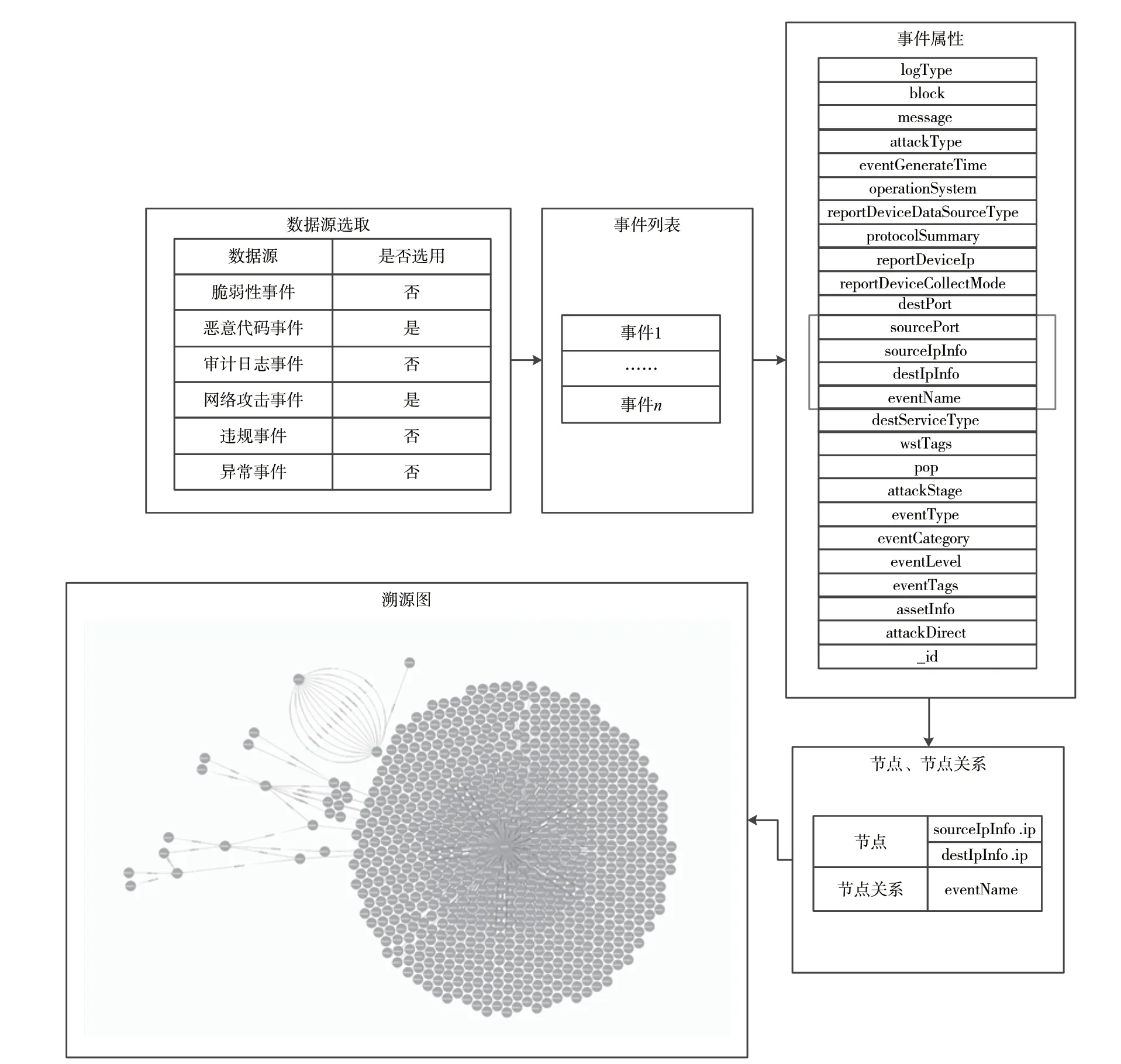
圖5 溯源圖構建流
根據2.3 節的溯源圖邊權重的定義計算方式進行社團劃分,選用Lovain 算法進行社團劃分,結果如圖6 所示。
針對2.4 節所篩選出的事件特征,使得特征之間具有相似性和階段性,將相似的進行聚合,從而得到候選攻擊鏈事件。由于沒有任何先驗信息和專家知識,聚類算法以相似性度量為基礎能夠有效識別和挖掘無標簽數據中的潛在聚簇信息,本文利用重疊聚類進行相關聚類,結果如圖7 所示,其中具有攻擊特性的攻擊事件鏈集合1 的事件如表3所示。
通過以上分析可以看出,此模型算法具有如下優點:
(1)處理告警信息中的誤報問題。主要體現在重疊聚類對事件特征進行稀疏的過程中,將與攻擊特性不相關的事件進行去除。
(2)處理告警信息中漏報的問題。主要體現在重疊聚類方法對具有攻擊特性的事件鏈進行聚合的過程中,將具有階段性、時間關聯性、端口和網段的同源性數據拉近。kill chain 模型的攻擊鏈的7個階段分別為:偵察目標—投遞植入—漏洞利用—命令控制—安裝駐留—行動收割—清除痕跡。因此,此過程中可能存在“命令控制”的漏報事件,需要相關安全人員進行排查。
4 結語
本文利用安全設備上報的日志數據在溯源圖譜的定義上構建相關圖譜,在降低攻擊路徑溯源的計算復雜度和計算量的基礎上,提取溯源圖譜具有攻擊特性的邊權重,并利用Lovain 算法進行社團劃分,將溯源圖譜拆分為具有攻擊特性的溯源子圖社團。最后利用本文提出的基于重疊聚類技術進行攻擊溯源分析。實驗結果表明,該算法設計能夠有效對攻擊進行溯源,并有效地改善溯源中誤報和漏報的缺點。
猜你喜歡
中等數學(2022年2期)2022-06-05 07:10:50
中學生數理化·七年級數學人教版(2021年11期)2021-12-06 05:38:48
海峽姐妹(2020年9期)2021-01-04 01:35:44
VOGUE服飾與美容(2020年9期)2020-09-02 14:47:26
小學生學習指導(低年級)(2020年6期)2020-07-25 02:31:36
小學生學習指導(低年級)(2018年9期)2018-09-26 05:59:44
瘋狂英語·新讀寫(2018年2期)2018-09-07 09:32:10
數學小靈通·3-4年級(2017年6期)2017-06-22 11:28:50
山東青年(2016年1期)2016-02-28 14:25:25
當代修辭學(2014年3期)2014-01-21 02:30:44
