融合多源異構(gòu)在線評論的開放式創(chuàng)新社區(qū)創(chuàng)意采納預(yù)測研究
2024-02-04 09:45:24劉嘉宇祝琳琳李世鈺
情報學報 2024年1期
劉嘉宇,李 賀,沈 旺,祝琳琳,李世鈺
(吉林大學商學與管理學院,長春 130012)
0 引 言
黨的二十大報告全面系統(tǒng)深入地闡述了中國式現(xiàn)代化的科學內(nèi)涵[1]。隨著數(shù)智化技術(shù)和知識經(jīng)濟的發(fā)展,越來越多的企業(yè)意識到僅僅依靠內(nèi)部資源進行高成本的創(chuàng)新活動,已經(jīng)難以適應(yīng)快速發(fā)展的市場需求以及日益激烈的企業(yè)競爭。在這種背景下,“開放式創(chuàng)新”逐漸成為企業(yè)創(chuàng)新的主導模式[2]。Chesbrough[3]首次明確提出了開放式創(chuàng)新的概念,該觀念強調(diào)用戶不再是產(chǎn)品的被動接受者,而是企業(yè)在市場實踐中取得競爭優(yōu)勢的重要力量。以小米MIUI 論壇、Dell's Idea Storms 和Apple Develop‐er 等為代表的社區(qū),更是開放式創(chuàng)新理念的生動實踐,通過整合用戶創(chuàng)意和企業(yè)內(nèi)部資源,構(gòu)建了用戶和企業(yè)雙贏的創(chuàng)新生態(tài)。在該類開放式創(chuàng)新社區(qū)中,用戶圍繞產(chǎn)品使用經(jīng)驗、改進建議、新創(chuàng)意等,產(chǎn)生了大量的在線評論[4]。這些在線評論包含了許多有用的信息,如產(chǎn)品創(chuàng)意,這些信息不僅可以為消費者提供購買決策支持,而且可以讓生產(chǎn)商和供應(yīng)商識別產(chǎn)品創(chuàng)新機會。然而,社區(qū)中同樣充斥著眾多無實質(zhì)性內(nèi)容的信息,這嚴重影響了企業(yè)吸納用戶創(chuàng)意方案的效率。因此,如何在海量的用戶評論中快速篩選出有價值的創(chuàng)意,加快企業(yè)創(chuàng)新資源的涌入,即創(chuàng)意采納預(yù)測成為企業(yè)和社區(qū)平臺管理面臨的重要問題。
既往以在線評論為數(shù)據(jù)源預(yù)測開放式創(chuàng)新社區(qū)中的創(chuàng)意采納研究主要依靠單一的文本特征[5-6]。不可否認的是,文本評論中片面、過時,甚至虛假、錯誤的信息廣泛存在,嚴重降低了基于在線評論的創(chuàng)意采納預(yù)測的效率和準確性[7]。在線評論數(shù)據(jù)來源不同,形式多樣,同一對象的不同表達之間存在很大差異,迫切需要完整、有效、靈活、高擴展性的數(shù)據(jù)集成框架和數(shù)據(jù)融合方法,高效地預(yù)測有價值的用戶創(chuàng)意。因此,本文提出了一種多源異構(gòu)在線評論數(shù)據(jù)融合基礎(chǔ)上的創(chuàng)意采納預(yù)測方法。多源異構(gòu)作為大數(shù)據(jù)的基本特征之一,其概念源自軍事領(lǐng)域,即通過多傳感器獲取多層次、多方面的信息,并對這些信息進行整合、加工和處理,以達到特定的目的[8]。在社會化環(huán)境中,特別是電子商務(wù)領(lǐng)域,多源異構(gòu)在線評論的定義至今仍不清晰,這嚴重限制了多源異構(gòu)在線評論的價值發(fā)掘和利用。為實現(xiàn)基于多源異構(gòu)在線評論數(shù)據(jù)融合的創(chuàng)意采納預(yù)測,本文基于信任轉(zhuǎn)移和價值共創(chuàng)理論,對多源異構(gòu)在線評論做出了解釋。此外,在多源異構(gòu)數(shù)據(jù)融合任務(wù)中,現(xiàn)階段的數(shù)據(jù)挖掘手段存在研究粒度較粗、忽視圖邏輯作用、研究體系不完善等問題。基于圖論的圖模型,作為一種數(shù)據(jù)挖掘手段,能夠使數(shù)據(jù)集之間實現(xiàn)基于語義的整合,不僅能夠提供基于語義的思考框架,還能在更高層面上考慮各數(shù)據(jù)倉儲的相互聯(lián)系[9]。當大量的在線產(chǎn)品評論數(shù)據(jù)映射成一個整體圖模型時,有助于產(chǎn)生新的規(guī)律,進而提供知識發(fā)現(xiàn)的新視角。
鑒于以往研究中存在的問題和應(yīng)用圖模型進行數(shù)據(jù)挖掘的優(yōu)勢,本文提出了融合多源異構(gòu)在線評論的開放式創(chuàng)新社區(qū)創(chuàng)意采納預(yù)測研究,主要研究內(nèi)容包括:第一,歸納了信任轉(zhuǎn)移和價值共創(chuàng)視角下多源異構(gòu)在線評論的定義;第二,實現(xiàn)了基于圖模型的多源異構(gòu)在線評論數(shù)據(jù)的特征級融合;第三,提出了基于多源異構(gòu)數(shù)據(jù)融合的開放式創(chuàng)新社區(qū)創(chuàng)意采納預(yù)測模型;第四,驗證了圖模型中的圖注意力網(wǎng)絡(luò)在分類場景中的應(yīng)用優(yōu)勢。通過上述研究,旨在幫助開放式創(chuàng)新社區(qū)管理者暢通與外部創(chuàng)新資源的溝通交流渠道,及時響應(yīng)外部需求來改善產(chǎn)品和服務(wù),進而贏得市場優(yōu)勢。
1 相關(guān)工作
作為創(chuàng)意生命周期的最后環(huán)節(jié),創(chuàng)意的采納與否成為衡量其質(zhì)量和價值的標準,在創(chuàng)新過程中發(fā)揮承上啟下的作用,最終影響企業(yè)創(chuàng)新的方向和效果[10-11]。然而,隨著開放式創(chuàng)新社區(qū)用戶建議的過載,如何在資源有限的情況下幫助企業(yè)和社區(qū)平臺預(yù)測有價值的創(chuàng)意,已成為國內(nèi)外研究的一個熱點。現(xiàn)有研究主要集中在以下幾個方面。①領(lǐng)先用戶識別研究。這類研究認為領(lǐng)先用戶提出的建議往往是高價值的創(chuàng)意。例如,黃璐[12]在研究Salesforce社區(qū)時,通過細分用戶群體,構(gòu)建了基于AdaBoost算法的開放式創(chuàng)新社區(qū)創(chuàng)意采納預(yù)測模型;Marti‐nez-Torres 等[13]應(yīng)用粒子群優(yōu)化方法提取用戶參與特征,以識別具有更多機會產(chǎn)生潛在可采納想法的領(lǐng)先用戶。②基于在線評論文本情感分析的開放式創(chuàng)新社區(qū)創(chuàng)意采納預(yù)測。例如,王婷婷[14]通過分析評論情感對創(chuàng)意采納的影響,采用支持向量機和隨機森林算法進行了創(chuàng)意采納預(yù)測,為企業(yè)后續(xù)篩選和預(yù)測創(chuàng)意采納提供了理論依據(jù);Lee 等[15]選擇MyS‐tarbucksIdea.com 獲取創(chuàng)意和評論中的情感特征,利用人工神經(jīng)網(wǎng)絡(luò)、決策樹和貝葉斯網(wǎng)絡(luò)等數(shù)據(jù)挖掘技術(shù)開發(fā)了新的分類模型,以識別潛在的創(chuàng)意發(fā)布者。
圖模型是一種由點和線組成的用于描述系統(tǒng)的圖形[16]。語義豐富、靈活、可擴展、適宜數(shù)據(jù)量龐大的應(yīng)用以及支持分布式數(shù)據(jù)存儲,使圖模型適應(yīng)網(wǎng)絡(luò)化的計算環(huán)境,比其他算法更適合社交網(wǎng)絡(luò)背景下的數(shù)據(jù)挖掘研究。基于圖模型融合多源異構(gòu)在線評論的應(yīng)用研究主要集中在以下幾個方面。①基于圖模型融合多源異構(gòu)在線評論的個性化推薦研究。例如,Hu 等[17]提出了一個高效的數(shù)據(jù)融合模型MR3(a model of rating, review, and relation),同時融合評論評分、評論文本和評論社會關(guān)系3 種異構(gòu)數(shù)據(jù),并結(jié)合鄰居圖結(jié)構(gòu)挖掘隱式反饋信息,實驗結(jié)果表明融合多源異構(gòu)評論信息的模型系統(tǒng)推薦性能良好。②基于圖模型融合多源異構(gòu)在線評論的產(chǎn)品排序研究。例如,Yang 等[18]提出了一種集成在線評論豐富和異構(gòu)信息的方法,將在線評論分為描述性信息和比較性信息,并將兩種信息整合到有向圖結(jié)構(gòu)中,最終得到了產(chǎn)品的排名,幫助消費者在比較多個產(chǎn)品時做出適當?shù)馁徺I決策。③基于圖模型融合多源異構(gòu)在線評論的用戶需求挖掘研究。例如,Guo 等[19]提出了一種考慮用戶個人需求的在線評論挖掘方法,并通過有向圖模型來集成多源異構(gòu)的產(chǎn)品評論信息,將評論文本數(shù)據(jù)和數(shù)值數(shù)據(jù)結(jié)合了起來。由此可見,圖模型為基于在線評論的個性化推薦、產(chǎn)品排序和用戶需求挖掘等提供了新的方法技術(shù)支撐。
綜上所述,已有的以機器學習分類算法預(yù)測有價值創(chuàng)意的研究主要關(guān)注單一的文本屬性如情感特征,忽視了評論數(shù)據(jù)其他方面的應(yīng)用,存在挖掘粒度較粗的問題。此外,基于圖模型融合多源異構(gòu)在線評論的開放式創(chuàng)新社區(qū)創(chuàng)意采納預(yù)測的應(yīng)用研究較少。即使有學者利用在線評論實現(xiàn)數(shù)據(jù)融合基礎(chǔ)上的創(chuàng)意采納,更關(guān)注的也是多源異構(gòu)數(shù)據(jù),在線評論僅作為多源數(shù)據(jù)的一種,這無法充分發(fā)揮出評論數(shù)據(jù)在創(chuàng)意采納預(yù)測中的應(yīng)用價值。更重要的是,多源異構(gòu)數(shù)據(jù)融合研究雖取得了一定的突破,但多源異構(gòu)數(shù)據(jù)融合的定義不適用于多源異構(gòu)在線評論。其原因在于多源異構(gòu)數(shù)據(jù)融合中的“多源”指的是來自不同傳感器中的數(shù)據(jù),而在線評論是每一個用戶根據(jù)自身對產(chǎn)品或服務(wù)的體驗產(chǎn)生的觀點、想法。在多源異構(gòu)數(shù)據(jù)理念下,在線評論本身即具備多源的屬性,而數(shù)據(jù)多源是數(shù)據(jù)異構(gòu)的前提。盡管已有的關(guān)于多源異構(gòu)數(shù)據(jù)融合的研究針對同一主題選擇了不同的數(shù)據(jù)源,并取得了理想效果,但不同平臺或數(shù)據(jù)集存在字段內(nèi)容不一致、不清楚是否為同一用戶等問題,這給多源異構(gòu)在線評論數(shù)據(jù)融合問題帶來了一定的困難。因此,需借鑒多源異構(gòu)數(shù)據(jù)理念重塑多源異構(gòu)在線評論的內(nèi)涵,并選擇適合多源異構(gòu)在線評論數(shù)據(jù)融合與挖掘方法。
2 融合多源異構(gòu)在線評論的創(chuàng)意采納預(yù)測方法
針對單純基于評論文本的開放式創(chuàng)新社區(qū)創(chuàng)意采納預(yù)測和多源異構(gòu)在線評論數(shù)據(jù)融合存在的挑戰(zhàn),本文提出了融合多源異構(gòu)在線評論的創(chuàng)意采納預(yù)測方法。遵循“理論基礎(chǔ)→數(shù)據(jù)獲取→特征體系設(shè)計→特征融合→效果評價”的研究邏輯,圖1 描述了本文方法中的各功能層級及機理內(nèi)容。①理論基礎(chǔ)層:數(shù)據(jù)級融合、特征級融合和決策級融合是目前最常見的數(shù)據(jù)融合方法[20]。在多源異構(gòu)在線評論數(shù)據(jù)融合任務(wù)中,數(shù)據(jù)級融合面臨實體無法對齊和不同平臺數(shù)據(jù)字段不統(tǒng)一等問題,而決策級融合則存在真實數(shù)據(jù)質(zhì)量不佳和決策成本代價高的問題。因此,本文采用特征級方式融合多源異構(gòu)在線評論。此外,本文基于信任轉(zhuǎn)移理論和價值共創(chuàng)理論,定義了多源異構(gòu)在線評論。②數(shù)據(jù)獲取層:依據(jù)多源異構(gòu)在線評論的定義,獲取社區(qū)平臺中評論用戶及其與其他用戶互動中產(chǎn)生的文本型評論(評論和追評等)和數(shù)值型評論(情感和評分等),構(gòu)建多源異構(gòu)在線評論數(shù)據(jù)集。③特征體系設(shè)計層:基于啟發(fā)式系統(tǒng)性說服模型,本文提出了結(jié)合啟發(fā)式評論者、啟發(fā)式評論和系統(tǒng)性評論等多維度特征來實現(xiàn)創(chuàng)意采納預(yù)測的方法。④特征融合層:從多源異構(gòu)在線評論數(shù)據(jù)融合方法的角度來看,本文選擇了圖模型中的圖注意力網(wǎng)絡(luò),實現(xiàn)啟發(fā)式評論者、啟發(fā)式評論和系統(tǒng)性評論數(shù)據(jù)的特征級融合。⑤效果評價層:將本文方法的識別結(jié)果與已有同類研究中的識別算法進行對比,以說明本文方法的性能和數(shù)據(jù)融合的效果。
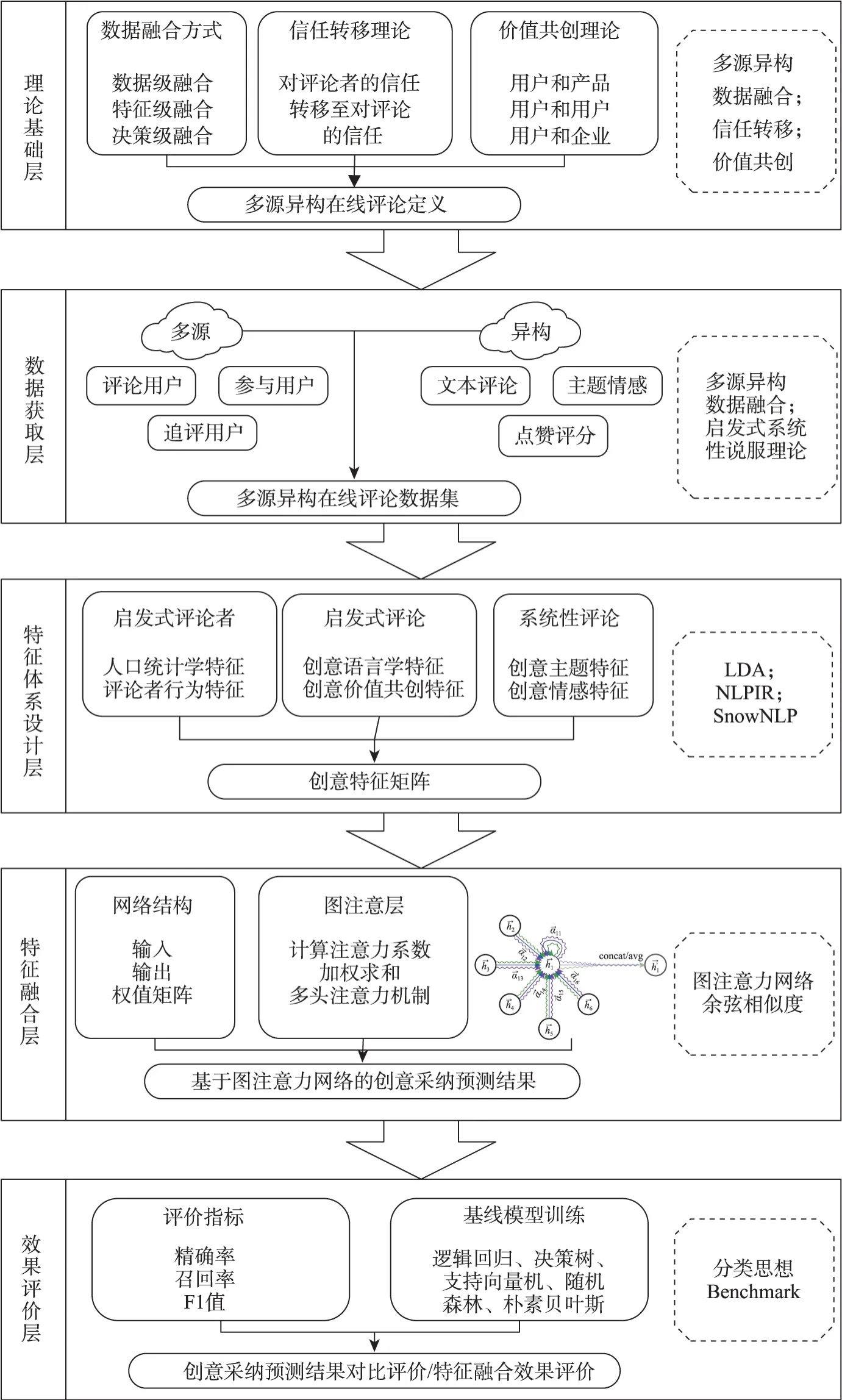
圖1 基于多源異構(gòu)在線評論數(shù)據(jù)融合的創(chuàng)意采納預(yù)測方法
2.1 信任轉(zhuǎn)移和價值共創(chuàng)視角下在線評論的多源異構(gòu)特征
在實現(xiàn)基于多源異構(gòu)在線評論數(shù)據(jù)融合的創(chuàng)意采納預(yù)測研究前,本文首先依據(jù)多源異構(gòu)數(shù)據(jù)融合的理念,歸納了多源異構(gòu)在線評論的定義,并基于信任轉(zhuǎn)移理論和價值共創(chuàng)理論分析了在線評論本身具備的多源異構(gòu)屬性。
Khaleghi 等[21]將多源異構(gòu)數(shù)據(jù)融合定義為,為了共同的任務(wù)或目標,把不同用戶、不同來源渠道產(chǎn)生的具有多種不同的表現(xiàn)方式(如數(shù)值型、文本型、圖形圖像、音頻視頻)但描述同一主題的數(shù)據(jù)融合在一起。正如上文所述,在線評論是不同用戶在體驗同一產(chǎn)品或服務(wù)后,根據(jù)自身的實際感受采用評分或撰寫文本方式,針對產(chǎn)品或服務(wù)提出的觀點、看法。顯然,在線評論本身就來自不同用戶,即具備多源異構(gòu)的屬性。因此,在多源異構(gòu)數(shù)據(jù)融合理念和在線評論本身多源異構(gòu)屬性的指導下,將多源異構(gòu)在線評論的多源定義為來源多源,即在線評論是由不同用戶所發(fā)表的關(guān)于產(chǎn)品/服務(wù)的觀點。將多源異構(gòu)在線評論中的異構(gòu)定義為數(shù)據(jù)結(jié)構(gòu)異構(gòu),文本型、數(shù)值型、圖片型和音頻視頻型在線評論均可視為異構(gòu)性在線評論。因此,本文所做的基于多源異構(gòu)在線評論數(shù)據(jù)融合的創(chuàng)意采納預(yù)測的主要任務(wù)是,對不同用戶針對同一產(chǎn)品/服務(wù)發(fā)布的數(shù)值型、文本型建議性評論抽取相應(yīng)的特征,在特征融合基礎(chǔ)上實現(xiàn)產(chǎn)品創(chuàng)意采納的預(yù)測,并對預(yù)測結(jié)果進行評價。
2.1.1 信任轉(zhuǎn)移視角下在線評論的多源異構(gòu)特征
信任轉(zhuǎn)移理論表明,當委托人幾乎沒有直接經(jīng)驗時,信任可以從一個可信的證據(jù)來源轉(zhuǎn)移到另一個人或群體[22]。Stewart[23]認為信任轉(zhuǎn)移同樣適用于互聯(lián)網(wǎng)環(huán)境,即用戶在與技術(shù)互動或在線上環(huán)境決策時,信任發(fā)揮著至關(guān)重要的作用。Verhagen 等[24]的研究結(jié)果表明,消費者對實體店的服務(wù)、商品、氛圍和布局等的信任,顯著影響了消費者的在線購買意愿。同樣地,關(guān)于在線評論的相關(guān)研究結(jié)果表明,對評論者的信任會使閱讀評論的用戶將信任轉(zhuǎn)移到對評論者評論的信任上。例如,Ma 等[25]發(fā)現(xiàn)評論者的評論頻率、評論長度和評論可讀性,會隨著評論者徽章級別的提高而顯著增加;Leong 等[26]認為,評論者屬性如語言風格、發(fā)表的體驗和個人資料照片的披露在移動社交商務(wù)的信任形成中的作用至關(guān)重要。因此,本文認為企業(yè)在對用戶的創(chuàng)意進行采納決策時,不僅會考慮評論者的評論文本,還會考慮評論者的個人屬性。也就是說,對評論文本的信任轉(zhuǎn)移到了對評論者的信任上。因此,在將多源異構(gòu)在線評論的多源定義為來源多源的情況下,本文認為特征來源多源,即來自評論和評論者的特征均會影響企業(yè)對用戶創(chuàng)意的采納。
2.1.2 價值共創(chuàng)視角下在線評論的多源異構(gòu)特征
消費者使用企業(yè)產(chǎn)品創(chuàng)造價值、消費者與消費者互動創(chuàng)造價值以及消費者與企業(yè)互動創(chuàng)造價值是消費領(lǐng)域價值共創(chuàng)典型的3 個層次[27]。張寧等[28]分析了企業(yè)開放式創(chuàng)新社區(qū)創(chuàng)意采納影響因素,發(fā)現(xiàn)創(chuàng)意的信息熵和情感強度對創(chuàng)意采納有顯著正向影響,消費者間的互動正向影響創(chuàng)意的采納;消費者間的互動包括對創(chuàng)意的瀏覽、點贊和評論。企業(yè)是否決定采納用戶的創(chuàng)意,本質(zhì)上考慮的是創(chuàng)意的價值,而創(chuàng)意的價值不僅來自消費者和產(chǎn)品的互動、消費者和企業(yè)的互動,更受到消費者與其他消費者之間的互動的影響。也就是說,消費者、企業(yè)和產(chǎn)品之間的互動能夠增加創(chuàng)意的價值。因此,在將多源異構(gòu)在線評論的多源定義為來源多源的情況下,本文認為價值來源多源,即來自消費者、企業(yè)和其他消費者間的互動產(chǎn)生的價值均會影響企業(yè)對用戶創(chuàng)意的采納。
2.2 啟發(fā)式系統(tǒng)性說服視角下基于在線評論的創(chuàng)意特征設(shè)計
基于多源異構(gòu)在線評論的定義,本文將在線評論的多源定義為來源多源,來源多源包含特征來源多源和價值來源多源,異構(gòu)指的是與產(chǎn)品創(chuàng)意相關(guān)的文本型、數(shù)值型等評論的數(shù)據(jù)結(jié)構(gòu)。圍繞該思想,本文基于啟發(fā)式系統(tǒng)性說服模型分析了基于在線評論的創(chuàng)意采納的影響因素,并設(shè)計了創(chuàng)意的相關(guān)特征。在已有研究中,學者試圖通過使用啟發(fā)式系統(tǒng)性說服模型(heuristic-systematic model,HSM)來理解影響在線評論感知價值的因素,該模型假定信息可以被系統(tǒng)性或啟發(fā)式地處理[29]。用戶提交的建議型評論,本質(zhì)上是說服企業(yè)接受自己建議的過程,因此,啟發(fā)式系統(tǒng)性說服適合創(chuàng)意采納情境。基于此,本文將多來源特征分為啟發(fā)式評論、啟發(fā)式評論者和系統(tǒng)性評論3 類,從在線評論中表征有價值的創(chuàng)意。
2.2.1 啟發(fā)式評論特征
當讀者不想對所呈現(xiàn)的信息考慮太多時,可以基于表面內(nèi)容對信息進行啟發(fā)式處理。關(guān)于在線評論的啟發(fā)式特征,已有研究主要考慮的是文本的語言學特征[30]。基于多源異構(gòu)在線評論的定義,消費者和消費者的互動也可以增加評論文本的價值,促進創(chuàng)意的采納。已有研究表明,消費者和消費者間的互動行為,如創(chuàng)意的點贊、參與和回復(fù),對創(chuàng)意采納起到了積極作用[28]。因此,本文中的啟發(fā)式評論特征主要包括創(chuàng)意語言學特征和創(chuàng)意價值共創(chuàng)特征。其中,創(chuàng)意語言學特征主要包括創(chuàng)意長度、創(chuàng)意中相關(guān)詞語的詞頻(如命名實體、數(shù)詞和量詞)、評論中相關(guān)詞語的詞性(如名詞、動詞)和創(chuàng)意豐富度(如創(chuàng)意的表達方式),創(chuàng)意價值共創(chuàng)特征主要包括創(chuàng)意支持度(如創(chuàng)意獲得的點贊數(shù))、創(chuàng)意流行度(如其他用戶對創(chuàng)意的回復(fù)數(shù))和創(chuàng)意關(guān)注度(如創(chuàng)意的參與人數(shù))。
2.2.2 啟發(fā)式評論者特征
當讀者基于表面內(nèi)容對信息進行啟發(fā)式處理時,對評論者身份、地位等的信任可以轉(zhuǎn)移到對評論內(nèi)容的信任,增加基于評論的創(chuàng)意采納的概率。因此,本文從啟發(fā)式系統(tǒng)性說服模型的角度出發(fā),將與在線評論相關(guān)的啟發(fā)式因素分為評論者和評論維度。啟發(fā)式評論者特征主要包括創(chuàng)意者人口統(tǒng)計學特征和創(chuàng)意者行為特征。其中,創(chuàng)意者人口統(tǒng)計學特征主要包括提交創(chuàng)意用戶信息,如是否有頭像、身份勛章數(shù)、粉絲數(shù)、關(guān)注數(shù)和圈子數(shù);創(chuàng)意者行為特征主要包括獲贊數(shù)、活躍勛章數(shù)、歷史動態(tài)、以前提交的創(chuàng)意數(shù)、之前被采納的建議數(shù)和創(chuàng)意采納率。
2.2.3 系統(tǒng)性評論特征
當讀者仔細閱讀評論并考慮所有可用的信息時,是在系統(tǒng)地處理信息。已有研究考慮了系統(tǒng)性信息處理中評論信息的情感和評論內(nèi)容的質(zhì)量。情感分析的中心是確定文本背后的觀點,一種常見的分析類型是情感極性檢測,即某個文本的總體方向是正面、負面或中立。情感強度作為情感的量化,也能說明評論者的情感特征。此外,主題模型作為一種可以從內(nèi)容中識別潛在內(nèi)容模式的工具,其將文檔視為概率主題的產(chǎn)物,并幫助發(fā)現(xiàn)出現(xiàn)在文檔集合中的一組主題。除了基于文本揭示主題外,應(yīng)用主題模型方法還可以實現(xiàn)文本特征提取的大幅降維。因此,本文的系統(tǒng)性評論特征主要包括創(chuàng)意情感特征和創(chuàng)意主題特征。其中,創(chuàng)意情感特征主要包括情感強度和情感極性,情感強度可基于SnowNLP 得出,SnowNLP 的取值范圍為[-1,1],越接近1 則情感越積極;創(chuàng)意主題特征是基于主題模型確定出的評論文本的主題內(nèi)容。
2.3 融合多源異構(gòu)在線評論的創(chuàng)意采納預(yù)測過程
2.3.1 融合多源異構(gòu)在線評論的圖注意力網(wǎng)絡(luò)構(gòu)建
圖注意力網(wǎng)絡(luò)(graph attention networks,GAT)本質(zhì)上是一種圖神經(jīng)網(wǎng)絡(luò),通過將注意力機制(at‐tention)與圖卷積結(jié)合,適用于處理圖結(jié)構(gòu)化數(shù)據(jù)。GAT 的優(yōu)勢:①不需要了解整個圖結(jié)構(gòu),只需知道每個節(jié)點的鄰居節(jié)點;②計算速度快,不需要昂貴的矩陣運算,可以在不同的節(jié)點上進行并行計算;③可以對未見過的圖結(jié)構(gòu)進行處理[31]。鑒于GAT 的上述優(yōu)點,本文在開放式創(chuàng)新社區(qū)創(chuàng)意采納預(yù)測研究中使用了圖注意力網(wǎng)絡(luò)中的注意力機制,實現(xiàn)了多源異構(gòu)特征的融合,構(gòu)建了圖注意力網(wǎng)絡(luò),并基于該網(wǎng)絡(luò)實現(xiàn)了創(chuàng)意采納的預(yù)測。圖注意力網(wǎng)絡(luò)作為圖模型的一種,也存在頂點和邊。在本文中,頂點和邊的設(shè)定如下。
(1)頂點
頂點是開放式創(chuàng)新社區(qū)的用戶,用戶通過在社區(qū)中提交評論,形成了自身在社區(qū)中的活動行為。結(jié)合用戶的個人身份信息、評論內(nèi)容和與其他消費者間的互動,本文抽取了啟發(fā)式評論者、啟發(fā)式評論和系統(tǒng)性評論等特征,并對特征進行量化。因此,對用戶來說,通過量化特征所形成的空間向量表征了用戶節(jié)點的特征。
(2)邊
本文依據(jù)余弦相似度計算了用戶間發(fā)布評論的語義相似度。余弦相似度的計算公式為
其中,A和B表示兩條用戶評論;i表示基于分詞、去停用詞后評論中的第i個實詞;n表示該評論中實詞的總數(shù)。語義相似度高,表明創(chuàng)意內(nèi)容類似,即用戶對產(chǎn)品擁有相似的觀點。但在數(shù)據(jù)量較大的情況下,依據(jù)語義相似度所有節(jié)點相連容易導致圖數(shù)據(jù)結(jié)構(gòu)偏大,影響后續(xù)分類預(yù)測性能。本文選擇了與創(chuàng)意者相似度最高的前3 名用戶進行連接,以方便后續(xù)操作。
2.3.2 基于圖注意力網(wǎng)絡(luò)的創(chuàng)意特征融合過程
GAT 是引入注意力機制的圖神經(jīng)網(wǎng)絡(luò),主要通過注意力機制實現(xiàn)開放式創(chuàng)新社區(qū)用戶節(jié)點特征的提取與融合。基于圖注意力網(wǎng)絡(luò)的創(chuàng)意特征融合過程如下。
(1)圖注意力層的輸入與輸出
(2)基于注意力機制的特征選擇與提取
特征輸入后,需要至少通過一次線性轉(zhuǎn)換才可以得到所需的輸出特征,所以需要對所有節(jié)點計算一個權(quán)重矩陣:W∈RF×F′。該權(quán)重表示輸入特征F和輸出特征F′之間的關(guān)系。此外,GAT 需要引用自注意力機制(self-attention),使用一個共享的注意力機制α,計算輸入特征向量的注意力系數(shù)[32]。注意力系數(shù)的主要作用在于計算每個節(jié)點i的鄰居節(jié)點k對它的重要性。注意力系數(shù)計算公式為
其中,i、j表示節(jié)點。公式(2)說明了節(jié)點j對i的重要性,而不需要考慮圖結(jié)構(gòu)的信息。
通過masked attention 將上述注意力機制引入圖結(jié)構(gòu)后,采用softmax 函數(shù)實現(xiàn)注意力系數(shù)歸一化,即
圖2 所示是基于注意力機制的特征選擇與提取[33]。圖2 左側(cè)是兩個用戶節(jié)點之間注意力系數(shù)的計算過程,圖2 右側(cè)是根據(jù)鄰近節(jié)點注意力系數(shù)計算節(jié)點特征的實例,不同的箭頭樣式和顏色表示獨立的注意力計算,來自每個頭部的聚合特征被連接或平均以獲得通過這種方法,可以對每個節(jié)點進行自適應(yīng)的特征選擇,從而提升模型的表達能力和準確度。
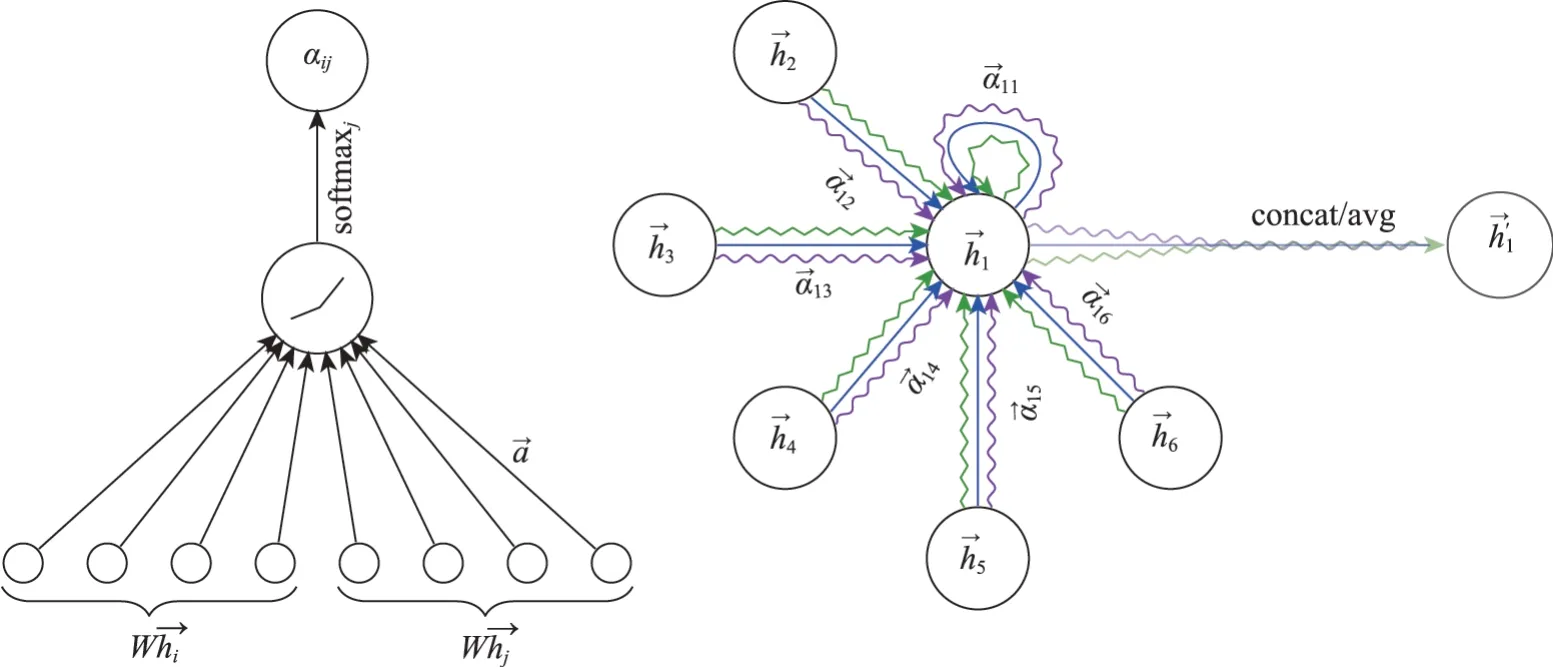
圖2 基于注意力機制的特征選擇與提取[33](彩圖請見https://qbxb.istic.ac.cn)
(3)基于注意力系數(shù)的特征輸出
基于上述過程得到了正則化后用戶節(jié)點的注意力系數(shù),可以基于該系數(shù)獲取節(jié)點的輸出特征。輸出特征預(yù)測公式為
其中,σ為非線性函數(shù);j表示所有與i相鄰的用戶節(jié)點。通過公式(4)輸出用戶節(jié)點i的特征。
(4)基于多頭注意力機制的穩(wěn)定性保證
多頭注意力機制的作用是使模型處理能力增強,訓練過程更加平穩(wěn),每個節(jié)點到節(jié)點都有k個連接,每個連接都代表一個注意力系數(shù)[34]。
2.3.3 基于創(chuàng)意特征融合的創(chuàng)意采納預(yù)測過程
基于創(chuàng)意特征融合的創(chuàng)意采納預(yù)測過程實質(zhì)上是一個基于GAT 分類的過程。在上文特征選擇與融合基礎(chǔ)上,創(chuàng)意采納預(yù)測過程主要采用softmax 函數(shù)、交叉熵損失函數(shù)和梯度下降法實現(xiàn)。
(1)基于softmax 函數(shù)的分類
對節(jié)點向量輸入實現(xiàn)特征融合后,使用GAT 將各個節(jié)點的鄰居節(jié)點分別賦予不同的權(quán)重,最后圖注意力機制將獲取的不同權(quán)重的特征,通過自身的權(quán)重更新分配新的權(quán)重。權(quán)重較大的特征對分類更有影響力,權(quán)重較低的特征對網(wǎng)絡(luò)分類結(jié)果影響較小。GAT 在分類中采用softmax 函數(shù)[33]
(2)訓練與參數(shù)更新
得到預(yù)測分類結(jié)果后,基于已有的創(chuàng)意采納預(yù)測標簽,可以判斷分類結(jié)果的準確性。對于結(jié)果的改進,GAT 采用交叉熵損失函數(shù)和梯度下降法更新參數(shù)矩陣。交叉熵損失函數(shù)的作用在于反映實際輸出結(jié)果與預(yù)測結(jié)果的相似性,梯度下降法的作用在于遞歸性地逼近最小偏差,增加結(jié)果的準確性[35]。通過優(yōu)化參數(shù),減小預(yù)測結(jié)果的誤差,保證創(chuàng)意采納預(yù)測的準確。
2.4 基于多源異構(gòu)在線評論數(shù)據(jù)融合的創(chuàng)意采納預(yù)測效果評價
常用的機器學習分類算法有邏輯回歸(logistic regression,LR)、決策樹(decision tree,DT)、樸素貝葉斯(naive Bayes,NB)、支持向量機(sup‐port vector machine,SVM) 和隨機森林(random forest,RF)[36]等。在機器學習中,特征是被觀測對象的一個獨立可觀測的屬性或者特點,如識別水果的種類,需要考慮的特征或?qū)傩园ù笮 ⑿螤睢㈩伾龋粋€特征不足以代表一個物體,所以機器學習中使用特征的組合即特征向量來進行表示。特征向量是一個n維的數(shù)值向量,可以用來代表某個東西。已有的創(chuàng)意采納研究通常采用機器學習分類算法,創(chuàng)意采納本質(zhì)上是一個二分類的思想,即創(chuàng)意的采納或者不采納。因此,本文將常用的機器學習分類算法作為基準模型,與圖注意力網(wǎng)絡(luò)進行對比。此外,機器學習也是一個依賴多特征的方式,這與本文的特征融合有相似思想,因此,本文通過圖注意力網(wǎng)絡(luò)與機器學習的創(chuàng)意采納預(yù)測效果,來判斷圖注意力網(wǎng)絡(luò)特征融合的效果。
2.4.1 基準模型
邏輯回歸模型通常用于研究疾病流行率及其與預(yù)測變量的關(guān)系,是研究輸出結(jié)果與潛在相關(guān)因素之間關(guān)聯(lián)的標準方法。在機器學習中,決策樹屬于監(jiān)督學習的一種,作為一個預(yù)測模型,其代表的是對象屬性與對象值之間的一種映射關(guān)系。基于貝葉斯決策論的樸素貝葉斯是用已知類別的數(shù)據(jù)集訓練模型,從而實現(xiàn)對未知類別數(shù)據(jù)的類別判斷。支持向量機的原理概括來說就是在樣本空間尋找最佳分類面即超平面,然后將訓練樣本分開。隨機森林是一個包含多棵決策樹的分類器,其基本思想是利用多棵樹對樣本進行訓練并預(yù)測[37]。以上經(jīng)典的機器學習分類算法是本文采用的基準模型。
在已有研究中,王婷婷[14]采用支持向量機和隨機森林算法對創(chuàng)意采納進行了預(yù)測,為企業(yè)篩選預(yù)測創(chuàng)意采納提供了新的工具方法。為識別潛在的想法發(fā)布者,Lee 等[15]利用人工神經(jīng)網(wǎng)絡(luò)、決策樹和貝葉斯網(wǎng)絡(luò)等數(shù)據(jù)挖掘技術(shù)開發(fā)了新的分類模型。Daradkeh[38]使用邏輯回歸模型對Tableau 社區(qū)數(shù)據(jù)進行了測試,結(jié)果表明虛擬眾包社區(qū)對用戶和想法的認可與想法采納呈正相關(guān)。為驗證本文方法的有效性,將LR、DT、NB、SVM 和RF 等在創(chuàng)意采納等研究中使用過的模型作為本文的基準模型。此外,結(jié)合本文數(shù)據(jù)特征和實際需求調(diào)整了上述模型的參數(shù),以保證模型在本文數(shù)據(jù)集上發(fā)揮出最佳性能。
2.4.2 評價指標
開放式創(chuàng)新社區(qū)創(chuàng)意采納預(yù)測實質(zhì)上是一個二分類任務(wù)。鑒于此,本文選擇了經(jīng)常用于分類任務(wù)的精確率(precision)、召回率(recall) 和F1 值3個指標來評估模型的性能。混淆矩陣如表1 所示,3 個指標的計算公式分別為
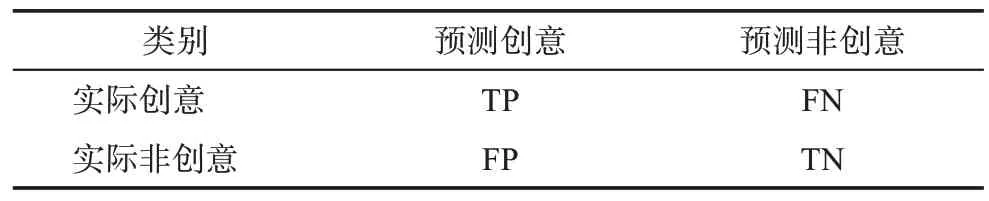
表1 混淆矩陣
其中,TP(true positive)表示實際為創(chuàng)意,并被正確預(yù)測為創(chuàng)意的樣本數(shù)量;FN(false negative)表示實際為創(chuàng)意,而被預(yù)測為非創(chuàng)意的樣本數(shù)量;FP(false positive)表示實際為非創(chuàng)意,而被預(yù)測為創(chuàng)意的樣本數(shù)量。另外,TN(true negative)表示實際為非創(chuàng)意,并被正確預(yù)測為非創(chuàng)意的樣本數(shù)量。精確率測量的是實際為創(chuàng)意并被正確預(yù)測為創(chuàng)意的樣本數(shù)量(TP)在實際為創(chuàng)意并被正確預(yù)測為創(chuàng)意的樣本數(shù)量與實際為非創(chuàng)意而被預(yù)測為創(chuàng)意的樣本數(shù)量之和(TP 與FP 的和)中所占的比例。召回率衡量的是實際為創(chuàng)意并被正確預(yù)測為創(chuàng)意的樣本數(shù)量(TP)在實際為創(chuàng)意并被正確預(yù)測為創(chuàng)意的樣本數(shù)量與實際為創(chuàng)意而被預(yù)測為非創(chuàng)意的樣本數(shù)量之和(TP 與FN 的和)中所占的比例。F1 值調(diào)和了精確率和召回率,是對模型預(yù)測創(chuàng)意采納性能的整體評估。
3 實證研究
3.1 數(shù)據(jù)采集
本文選擇小米MIUI 社區(qū)中的用戶建議板塊作為實證數(shù)據(jù)來源(圖3)。理由如下:第一,據(jù)統(tǒng)計,MIUI 系統(tǒng)80%的修改意見是由社區(qū)用戶貢獻的[39],由此可見,小米社區(qū)是一個活躍度較高的開放式創(chuàng)新社區(qū);第二,在研究設(shè)計中,基于本文提出的基于在線評論的開放式創(chuàng)新社區(qū)產(chǎn)品創(chuàng)意特征體系,小米社區(qū)用戶建議板塊數(shù)據(jù)分布基本能夠滿足研究需求;第三,基于文獻調(diào)研,小米社區(qū)用戶建議板塊在關(guān)于開放式創(chuàng)新社區(qū)的研究中出現(xiàn)頻率較高。因此,本文將社區(qū)用戶在2022 年1 月1 日—2022 年11 月27 日提交的產(chǎn)品建議帖子、用戶信息和與其他用戶交互過程中產(chǎn)生的字段內(nèi)容作為實證數(shù)據(jù)來源,數(shù)據(jù)爬取時間為2022 年11 月27 日,共爬取21888 條用戶建議。
圖3 小米MIUI社區(qū)用戶建議板塊
3.2 數(shù)據(jù)清洗及預(yù)處理
為保證數(shù)據(jù)來源質(zhì)量,本文采用人工瀏覽方式進行數(shù)據(jù)清洗及預(yù)處理:①刪除數(shù)據(jù)集中評論帶無效鏈接數(shù)據(jù)591 條;②刪除用戶信息及評論信息存在缺失值數(shù)據(jù)468 條;③刪除爬取過程中重復(fù)性數(shù)據(jù)197 條。經(jīng)過上述操作后,最終得到20632 條數(shù)據(jù)作為實驗數(shù)據(jù)。
3.3 基于在線評論的開放式創(chuàng)新社區(qū)產(chǎn)品創(chuàng)意特征體系構(gòu)建
基于文獻調(diào)研,本文在已有同類研究,如謠言識別、在線評論有用性識別相關(guān)研究的基礎(chǔ)上,構(gòu)建了基于在線評論的開放式創(chuàng)新社區(qū)產(chǎn)品創(chuàng)意特征體系,如表2 所示。圖4 是基于LDA(latent Dirich‐let allocation)的創(chuàng)意文本主題一致性得分,K=18時,主題一致性得分最高,為0.4406,迭代次數(shù)為500。
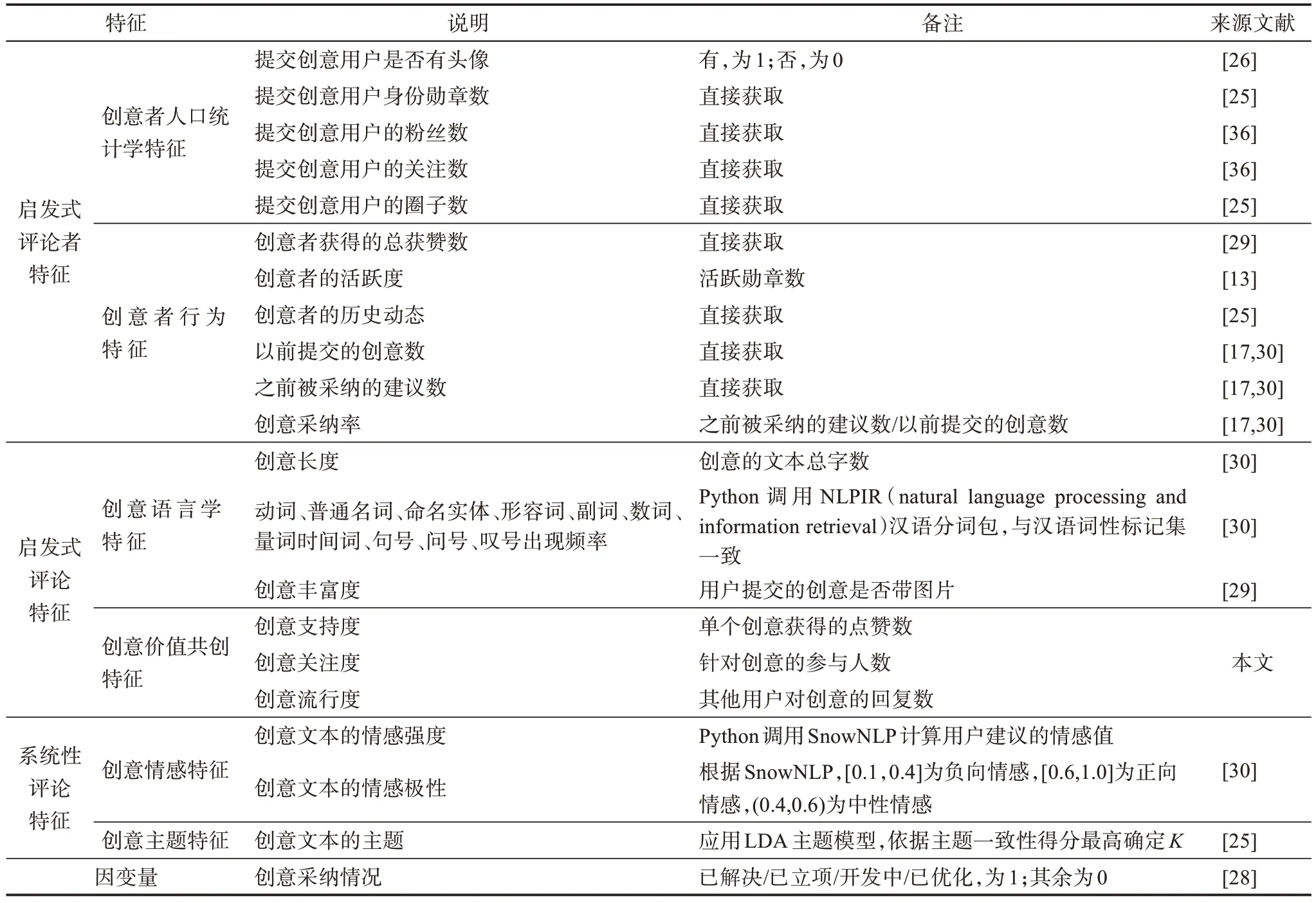
表2 基于在線評論的開放式創(chuàng)新社區(qū)產(chǎn)品創(chuàng)意特征體系
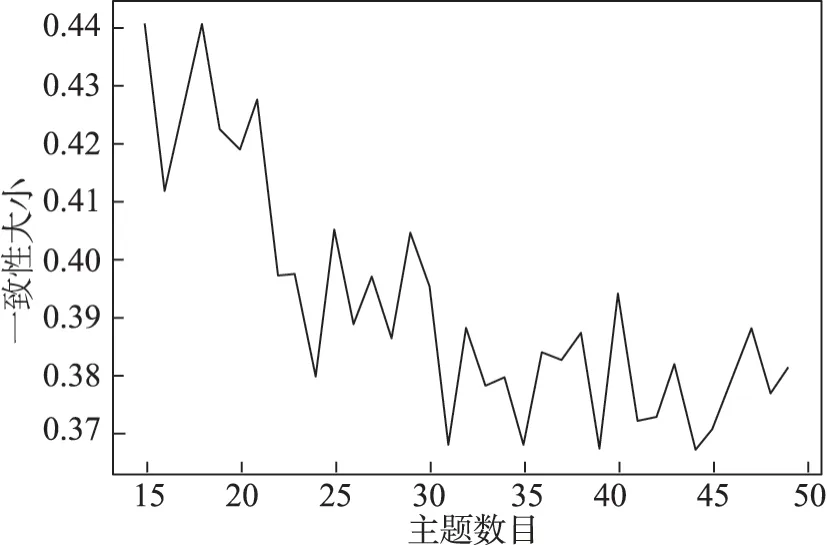
圖4 基于LDA的創(chuàng)意文本主題一致性得分
3.4 基于多源異構(gòu)在線評論數(shù)據(jù)融合的創(chuàng)意采納預(yù)測結(jié)果
3.4.1 實驗設(shè)置
表3 所示是本文在運行模型過程中的相關(guān)實驗設(shè)置。

表3 實驗設(shè)置
3.4.2 參數(shù)設(shè)置
本文就GAT 模型的主要參數(shù),如學習率、Dropout 和迭代次數(shù)等進行了分析。將采集的數(shù)據(jù)集按照8∶2 分為訓練集和測試集,其中訓練集用于學習圖注意力網(wǎng)絡(luò)中的相關(guān)參數(shù),測試集用于驗證分類預(yù)測算法的準確性。參考已有研究,本文采用了窮舉調(diào)參的方式以獲取模型的最佳實驗性能,具體過程:保證其他模型參數(shù)不變,每次設(shè)定一組參數(shù)組合,改變其中一個參數(shù)帶入模型,并得出相應(yīng)的評價指標結(jié)果。重復(fù)上述操作,直至得出模型的最佳性能結(jié)果停止。例如,當Drop‐out 取值為0.6 時,模型的表現(xiàn)最好,隨著Dropout的取值逐漸增加或遞減,模型性能也隨之降低。最終,通過表4 中的參數(shù)設(shè)置,模型得出了理想的結(jié)果。

表4 參數(shù)設(shè)置
3.4.3 預(yù)測結(jié)果
表5 顯示了每個模型獲得的分類預(yù)測結(jié)果。從精確率的角度來看,所有模型的性能都相對較好,精確率在0.93~0.96。但是,在召回率和F1 值方面,模型之間的創(chuàng)意采納預(yù)測性能存在較大的差異。召回率衡量了模型正確預(yù)測創(chuàng)意采納的能力,該值越高越好。由表5 可以看出,本文提出的GAT 模型的召回率最高,達到0.9813,這意味著其在創(chuàng)意采納預(yù)測方面表現(xiàn)出較好的性能,也說明了圖注意力機制在特征融合效果方面的優(yōu)勢。NB 模型的召回率僅為0.4983,表明該模型對創(chuàng)意采納預(yù)測能力較差。作為精確率和召回率的調(diào)和平均值,F(xiàn)1 值可以衡量模型在正確預(yù)測創(chuàng)意采納和錯誤預(yù)測創(chuàng)意采納之間達到平衡的能力。本文提出的GAT 模型的F1值最高,達到了0.9721,這意味著該模型在正確預(yù)測創(chuàng)意采納和錯誤預(yù)測創(chuàng)意采納之間取得了較好的平衡。與之相比,NB 的F1 值僅為0.6359,表明該模型在正確預(yù)測創(chuàng)意采納和錯誤預(yù)測創(chuàng)意采納之間的平衡能力較差。
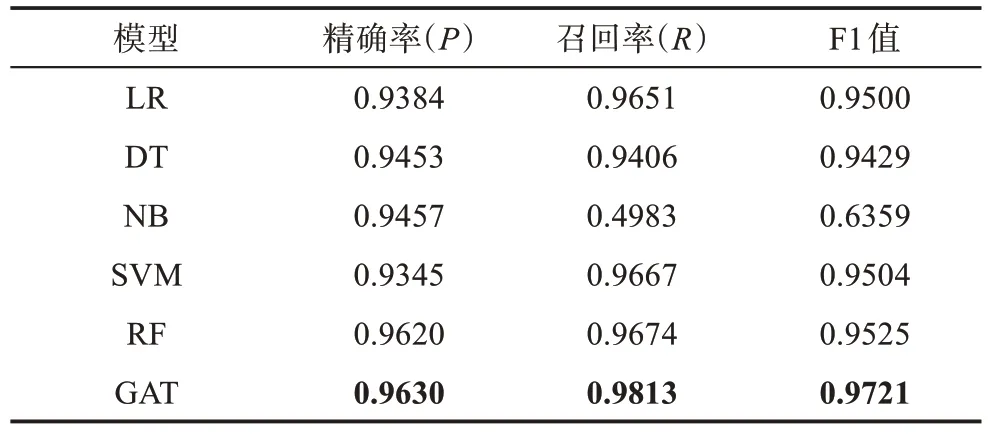
表5 基于多源異構(gòu)在線評論數(shù)據(jù)融合的創(chuàng)意采納預(yù)測結(jié)果
綜上所述,不同模型在不同性能指標上表現(xiàn)各不相同,需要根據(jù)具體任務(wù)和實際數(shù)據(jù)選擇最適合的模型。在融合多源異構(gòu)在線評論的開放式創(chuàng)新社區(qū)創(chuàng)意采納預(yù)測任務(wù)中,GAT 模型在多個指標上均表現(xiàn)較好,可能是最優(yōu)選擇。
4 討 論
4.1 貢 獻
(1)本文歸納了信任轉(zhuǎn)移和價值共創(chuàng)視角下多源異構(gòu)在線評論的定義。
多源異構(gòu)數(shù)據(jù)融合是大數(shù)據(jù)時代研究的前沿,并取得了一些研究成果。在已有研究中,圍繞同一主題或內(nèi)容從不同渠道獲取數(shù)據(jù)的多源異構(gòu)數(shù)據(jù)融合概念與多源異構(gòu)在線評論具有一定的區(qū)別。在多源異構(gòu)數(shù)據(jù)融合研究中,在線評論僅作為其中的一種數(shù)據(jù)來源,嚴重限制了用戶聲音的表達。鑒于真實數(shù)據(jù)驅(qū)動下研究的需要和在線評論的重要價值,本文在多源異構(gòu)數(shù)據(jù)融合理念的啟發(fā)下,基于信任轉(zhuǎn)移理論和價值共創(chuàng)理論,定義了多源異構(gòu)在線評論。其中,多源包括特征來源多源和價值來源多源。異構(gòu)則是在線評論中相關(guān)的文本、情感得分以及主題內(nèi)容等用戶內(nèi)容的表達。通過這一概念,不斷厘清在線評論的邊界和結(jié)構(gòu),推動以用戶生成內(nèi)容中的在線評論研究的深化,引領(lǐng)電子商務(wù)、知識經(jīng)濟和商務(wù)智能的發(fā)展。
(2)本文實現(xiàn)了基于圖模型的多源異構(gòu)在線評論數(shù)據(jù)的特征級融合。
數(shù)據(jù)融合的方式包含數(shù)據(jù)級融合、特征級融合和決策級融合。其中,數(shù)據(jù)級融合包含的粒度更細、內(nèi)容多樣,但是受數(shù)據(jù)質(zhì)量的限制,簡單的物理融合容易引發(fā)不良后果。決策級融合需要每個層級的傳感器都有一定的決策意識,這樣做雖然數(shù)據(jù)量小,但是魯棒性好。在互聯(lián)網(wǎng)環(huán)境下,虛假信息、恐怖信息等廣泛存在,且用戶的“無意識言論”較多,初始決策的代價較高。基于特征的數(shù)據(jù)融合是從原始數(shù)據(jù)中提取特征,再對提取的特征進行融合。由于部分特征可能直接與決策相關(guān),因此,本文提出了基于圖模型的多源異構(gòu)在線評論數(shù)據(jù)的特征級融合。在融合方法方面,機器學習與特征工程息息相關(guān),但是存在精度不高等問題,圖模型是適合大數(shù)據(jù)時代的一種數(shù)據(jù)挖掘方法,本文通過構(gòu)建圖注意力網(wǎng)絡(luò),基于圖注意力機制實現(xiàn)了多源異構(gòu)在線評論數(shù)據(jù)的特征級融合,并取得了良好的融合效果。
(3)本文提出了融合多源異構(gòu)在線評論的開放式創(chuàng)新社區(qū)創(chuàng)意采納預(yù)測。
開放式創(chuàng)新社區(qū)的發(fā)展,導致注冊用戶爆發(fā)式增長,引發(fā)了用戶提交的建議評論的海量增長。這種增長導致企業(yè)難以在資源有限的情況下快速響應(yīng)用戶建議并篩選出高價值的用戶創(chuàng)意,進而實現(xiàn)產(chǎn)品或服務(wù)的創(chuàng)新。因此,國內(nèi)外學者紛紛對此展開研究,助力企業(yè)整合資源實現(xiàn)用戶創(chuàng)意的識別預(yù)測。以往基于在線評論的開放式創(chuàng)新社區(qū)創(chuàng)意采納預(yù)測研究僅依賴用戶提交的評論文本特征,較少關(guān)注評論者個人屬性以及社區(qū)用戶直接的交流互動實現(xiàn)的價值共創(chuàng)。本文基于啟發(fā)式系統(tǒng)性說服模型,整合了以往研究的成果,并提出了用戶個人屬性(創(chuàng)意者人口統(tǒng)計學特征、創(chuàng)意者行為特征)和創(chuàng)意者的價值共創(chuàng)特征(創(chuàng)意的支持、流行和關(guān)注)。通過啟發(fā)式評論者、啟發(fā)式評論和系統(tǒng)性評論的融合,實現(xiàn)了開放式創(chuàng)新社區(qū)創(chuàng)意采納的預(yù)測研究,通過效果評估,本文基于圖模型數(shù)據(jù)融合的創(chuàng)意采納預(yù)測效果的綜合性能超過97%,優(yōu)于已有的機器學習分類算法。
(4)本文驗證了圖模型中的圖注意力網(wǎng)絡(luò)在分類場景中的應(yīng)用優(yōu)勢。
以圖論為基礎(chǔ)的圖模型,對在線產(chǎn)品評論進行文本挖掘與圖學習分析,為探索在線產(chǎn)品評論理論研究提供一個新的研究視角,對電子商務(wù)運營商探究用戶評論行為規(guī)律及探索潛在評論文本語義關(guān)聯(lián)挖掘具有重要的實踐意義。運用圖學習方法提供數(shù)據(jù)挖掘與知識發(fā)現(xiàn)的新視角,為商務(wù)智能帶來新的附加價值。在此背景下,本文提出了基于圖模型的數(shù)據(jù)融合方法,并在融合基礎(chǔ)上實現(xiàn)開放式創(chuàng)新社區(qū)的創(chuàng)意采納預(yù)測。研究結(jié)果表明,與傳統(tǒng)的機器學習分類算法相比,基于圖模型數(shù)據(jù)融合的分類性能在創(chuàng)意采納預(yù)測任務(wù)中取得了良好效果。
4.2 研究意義
本文的理論意義在于豐富并拓展了多源異構(gòu)數(shù)據(jù)融合的研究體系,指導領(lǐng)域多源異構(gòu)數(shù)據(jù)融合研究。基于啟發(fā)式系統(tǒng)性說服模型,從信任轉(zhuǎn)移和價值共創(chuàng)視角,設(shè)計了開放式創(chuàng)新社區(qū)用戶創(chuàng)意的特征體系,歸納了在線評論多源異構(gòu)的本質(zhì)屬性,深化了多源異構(gòu)數(shù)據(jù)融合在電子商務(wù)領(lǐng)域的進一步應(yīng)用。本文提出的多源異構(gòu)的定義可以拓寬至社交媒體其他數(shù)據(jù)場景下分類預(yù)測,豐富了社交媒體環(huán)境下數(shù)據(jù)融合的理論框架,完善了多源真實數(shù)據(jù)驅(qū)動下的研究理論體系。
本文的實踐意義在于完善并優(yōu)化了開放式創(chuàng)新社區(qū)創(chuàng)意采納預(yù)測的方法,可以幫助電子商務(wù)平臺完善運營及管理模式;通過創(chuàng)意采納預(yù)測的研究,解決了傳統(tǒng)的創(chuàng)意識別效率低下以及社區(qū)平臺信息過載等問題,可以使企業(yè)和社區(qū)平臺更加集中精力加速創(chuàng)新,為爭奪市場優(yōu)勢、占領(lǐng)市場地位打下堅實基礎(chǔ),也為后續(xù)識別社區(qū)中的領(lǐng)先用戶和尋找激勵用戶持續(xù)知識貢獻的因素提供了指導。
4.3 不足與展望
本文的研究結(jié)果具有一些貢獻和意義,但也存在局限性。比如,本文收集了開放式創(chuàng)新社區(qū)的評論數(shù)據(jù),并以社區(qū)中的采納標簽作為創(chuàng)意采納的衡量,但被企業(yè)采納的建議始終是少數(shù),因此,數(shù)據(jù)存在不平衡情況。后續(xù)研究可以提出不平衡數(shù)據(jù)集上的基于圖模型數(shù)據(jù)融合的分類方法,以解決數(shù)據(jù)存在的不平衡問題,不斷提升研究結(jié)果的準確性,最終形成統(tǒng)一的基于多源異構(gòu)在線評論數(shù)據(jù)融合的創(chuàng)意采納預(yù)測方法體系。
5 結(jié) 論
在世界百年未有之大變局下,創(chuàng)新驅(qū)動不僅是技術(shù)創(chuàng)新,還要有制度創(chuàng)新與之配套。開放式創(chuàng)新理念是整合企業(yè)的內(nèi)外資源實現(xiàn)創(chuàng)新的重要抓手。本文以開放式創(chuàng)新社區(qū)中的創(chuàng)意采納預(yù)測為研究目標,針對現(xiàn)有研究依賴單純的文本特征的局限,本文提出了多源異構(gòu)在線評論數(shù)據(jù)融合的思路。針對多源異構(gòu)真實數(shù)據(jù)存在的現(xiàn)實困擾,本文重新梳理了多源異構(gòu)在線評論的內(nèi)涵。針對現(xiàn)有的分類預(yù)測方法存在的細粒度不強、語義知識忽略的問題,本文提出了利用圖模型中的圖注意力網(wǎng)絡(luò)特征融合的方式實現(xiàn)創(chuàng)意采納預(yù)測,并取得了良好的效果。通過上述研究目標的實現(xiàn),本文不僅證明了圖模型在特征融合中的有效性,而且從融合評論特征和評論者特征的角度,為創(chuàng)意采納預(yù)測做出了方法和理論上的貢獻。
猜你喜歡
今日農(nóng)業(yè)(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數(shù)理化(高中版.高考數(shù)學)(2021年1期)2021-03-19 08:28:38
現(xiàn)代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
