基于紅外和可見光的多模態(tài)數(shù)據(jù)融合方法研究
2024-01-31 13:23:18王芳羅藝闖劉小虎邢靜
電子制作 2024年2期
王芳,羅藝闖,劉小虎,邢靜
(西安培華學(xué)院 智能科學(xué)與信息工程學(xué)院,陜西西安,710125)
0 引言
隨著硬件設(shè)備及相關(guān)技術(shù)的發(fā)展,基于紅外和可見光的多源圖像融合技術(shù)在軍事探測、視頻監(jiān)控、醫(yī)療成像、圖像水印等方面得到了廣泛的應(yīng)用[1]。其利用不同傳感器的特點進行優(yōu)勢互補,結(jié)合圖像處理技術(shù)將不同分辨率、不同來源的多模態(tài)的圖像融合成為一幅包含豐富信息的圖像,整體流程如圖1 所示。通常,可見光圖像具有較高的分辨率、豐富的細節(jié)信息及較強的對比度,但易受到光照、運動等因素的影響,而紅外圖像有較強的抗干擾能力,能夠有效捕獲目標(biāo)的輪廓信息,但分辨率較低、細節(jié)保持較差,易受熱交叉等因素的影響,通過多模態(tài)數(shù)據(jù)融合技術(shù)可實現(xiàn)信息的有效互補,擴展系統(tǒng)的時空覆蓋率,有效增強系統(tǒng)的魯棒性。隨著以深度學(xué)習(xí)為代表的人工智能技術(shù)的發(fā)展,如何實現(xiàn)基于紅外和可見光多模態(tài)數(shù)據(jù)的有效融合,是目前研究的熱點和難點。
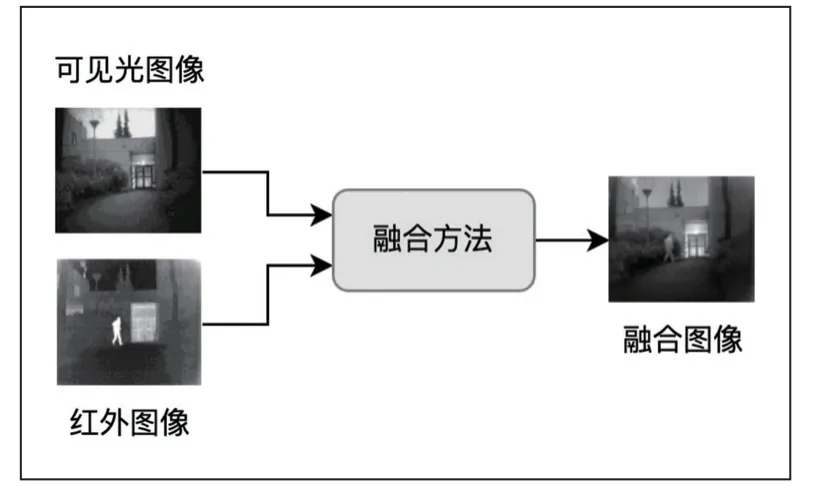
圖1 基于紅外和可見光的多模態(tài)數(shù)據(jù)融合示意
1 融合分類及評價指標(biāo)
基于紅外和可見光的多模態(tài)數(shù)據(jù)融合,可按照融合級別、融合域及融合方法來進行劃分[9],其中每種類別又包含不同的劃分。
具體地,根據(jù)融合級別可分為像素級融合、特征級融合和決策級融合[2]。像素級融合直接對圖像像素點進行融合,如主成分分析方法、小波變換法等,但其需要大量的預(yù)處理且由于缺乏嚴(yán)格的對齊,導(dǎo)致融合結(jié)果存在嚴(yán)重的畸變;特征級融合通過濾波器或表示學(xué)習(xí)來抽取圖像的表征,進而對特征信息進行融合,如特征金字塔法、卷積神經(jīng)網(wǎng)絡(luò)方法等,處理速度快但會丟失特定的信息;決策級融合由各模態(tài)分別實現(xiàn)信息的決策后,合并實現(xiàn)全局最優(yōu)決策,如貝葉斯方法、模糊聚類法等[3],但其缺乏具體的視覺感知,因此不適于計算機視覺相關(guān)的下游任務(wù)。
根據(jù)融合域可分為基于空間和基于變換的方法。基于空間的融合方法直接作用原圖像,如加權(quán)平均、形態(tài)學(xué)算子等,但這種方法通常會產(chǎn)生一些如譜畸變的效果。而基于變換的融合方法采用合適的變換方法來避免該問題,如金字塔變換、小波變換等,其首先將原圖像投影到變換空間中,進行相應(yīng)的濾波計算,然后再逆變換到原圖像空間。
根據(jù)融合方法可分為多尺度變換、稀疏編碼、混合融合方法及基于神經(jīng)網(wǎng)絡(luò)的方法。基于多尺度變換的方法首先利用特征金字塔、小波變換等算法來抽取不同尺度的表示,然后采用特定的融合規(guī)則對不同尺度的表示進行融合,最后將所有尺度融合的結(jié)果相加并進行逆變換得到最終的融合圖像。基于稀疏編碼的方法將原圖像用一個完備的字典進行編碼來獲取稀疏系數(shù),然后采用不同的融合策略結(jié)合系數(shù)進行加權(quán)融合得到融合圖像,可以看出,其也可作為一種融合策略。混合融合方法結(jié)合了其他融合方法的優(yōu)點,如將多尺度變換方法和稀疏編碼的方法進行結(jié)合,其中多尺度變換方法來獲取低頻特征信息,但會存在視覺冗余信息,進而結(jié)合稀疏編碼來進行改善融合效果。當(dāng)前,最具前景的方法是基于深度學(xué)習(xí)的方法,涉及不同的網(wǎng)絡(luò)結(jié)構(gòu),將在下部分進行詳細闡述。
對于融合方法的評估,通常有客觀評價方法和主觀評價法。主觀評價從觀察者的角度來評估融合圖像的清晰度、亮度和對比度等。客觀評價通過構(gòu)建客觀的評價指標(biāo)對融合圖像進行評價,主要包括基于信息理論的指標(biāo),如FMI,QNICE和QM等,基于圖像特征的指標(biāo),如QA/BF,QP等,基于圖像結(jié)構(gòu)相似性的指標(biāo),如SSIM,QY等,以及基于感知啟發(fā)的指標(biāo),如VIF,QCV等[4]。
2 紅外可見光融合方法
通過上述融合方法的分類及原理的梳理,可以看出像素級融合和基于空間的方法的思想相同,基于多尺度的方法和基于變換域的分類原理一致,混合融合的方法基于其他的方法,進行結(jié)合而得到,因此,本文基于融合的基本原理,按照基于空域的方法、基于變換域的方法、基于稀疏編碼和基于神經(jīng)網(wǎng)絡(luò)的方法來結(jié)合具體的算法進行闡述,并將除基于神經(jīng)網(wǎng)絡(luò)的方法以外的其他的方法稱為基于傳統(tǒng)的融合方法,具體如下:
■2.1 傳統(tǒng)的融合方法
傳統(tǒng)的圖像融合方法包括基于空域的方法、基于變換域的方法及基于稀疏編碼和字典學(xué)習(xí)的方法[4]。基于空域的方法通過計算不同模態(tài)的局部或像素級顯著性,進行加權(quán)平均得到融合圖像;基于變換域的方法首先將源圖像變換到變換域(如小波域)中,以獲得不同頻率的分量,然后通過設(shè)計相應(yīng)的融合規(guī)則對分量進行融合,最終逆變換回源空間得到融合圖像,常用的方法有拉普拉斯金字塔(LP)、低通金字塔(RP)、離散小波(DWT)、離散余弦(DCT)、曲線簇變換(CVT)等。基于稀疏編碼和字典學(xué)習(xí)的方法通常基于稀疏系數(shù)來獲得圖像的局部表征和全局表征,并通過加權(quán)融合算法來得到融合圖像。
傳統(tǒng)的圖像融合方法主要受限于以下兩個方面:首先,通過復(fù)雜的人工設(shè)計提取的特征通常無法有效地保留圖像中的信息,從而導(dǎo)致融合圖像中存在偽影;其次,特征提取方法通常是針對特定的任務(wù)來設(shè)計的,難以有效地遷移到其他任務(wù)中。
■2.2 基于深度學(xué)習(xí)的融合方法
由于深度學(xué)習(xí)能夠有效地解決傳統(tǒng)方法中手工提取特征不全和特征編碼設(shè)計復(fù)雜等問題,目前,基于深度學(xué)習(xí)的融合方法,大都采用特征級融合。常見的基于深度學(xué)習(xí)的紅外可見光融合框架,主要包含基于自編碼器(AE)的方法、基于卷積神經(jīng)網(wǎng)絡(luò)(CNN)的方法和基于生成對抗網(wǎng)絡(luò)(GAN)的方法,分別如圖2、圖3、圖4 所示。
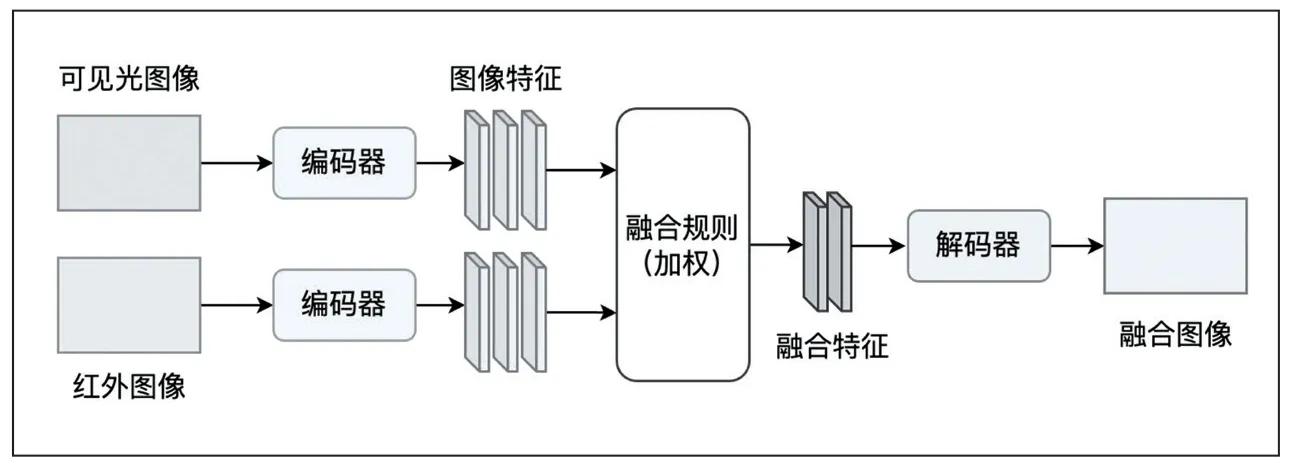
圖2 基于自編碼器的融合方法
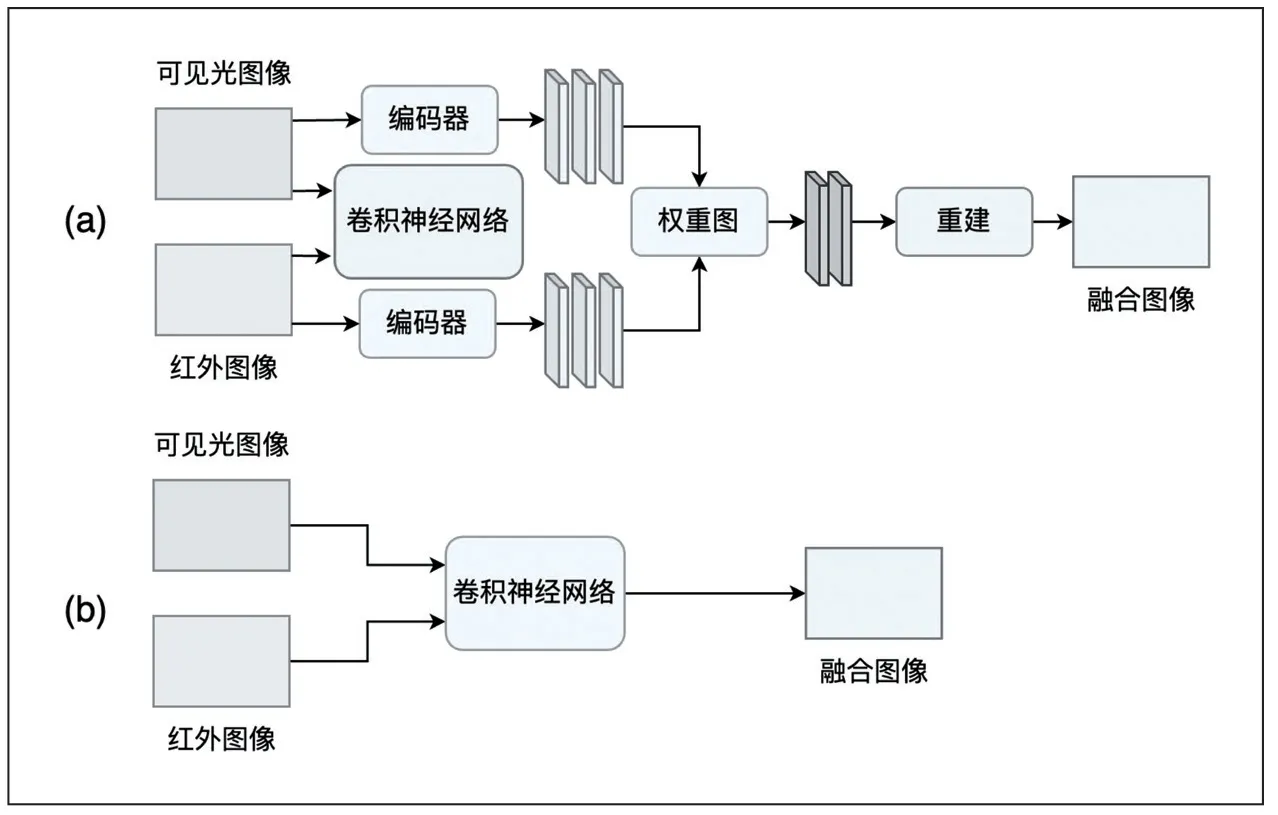
圖3 基于卷積神經(jīng)網(wǎng)絡(luò)的方法
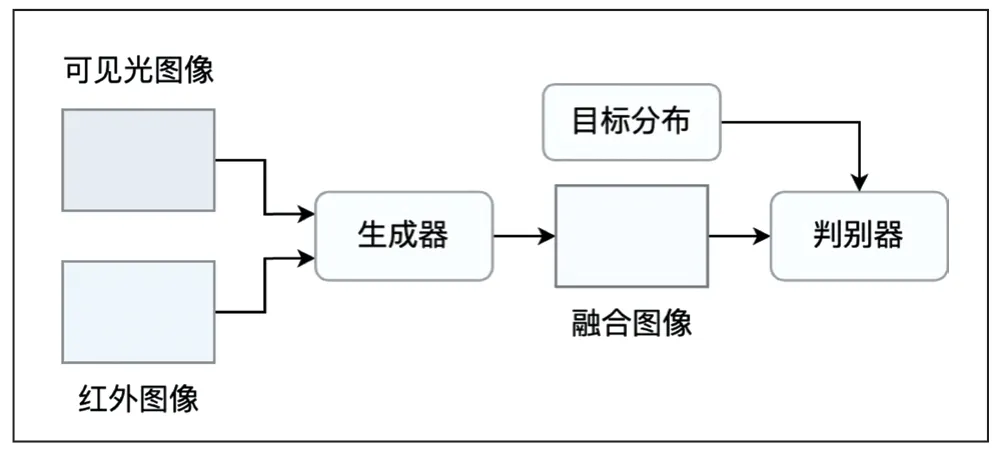
圖4 基于生成對抗網(wǎng)絡(luò)的方法
基于自編碼器的方法通常基于預(yù)訓(xùn)練的自編碼器,然后結(jié)合特定的數(shù)據(jù)集對其進行訓(xùn)練來抽取特定的特征和融合圖像重建,其中中間特征的融合可采用常規(guī)的融合規(guī)則來實現(xiàn),如圖2 所示。DenseFuse[5]方法是其典型代表,其在MS-COCO 數(shù)據(jù)集上來訓(xùn)練編碼器和解碼器,并采用逐像素相加和L1-正則的融合方法來實現(xiàn)特征的融合。
基于卷積神經(jīng)網(wǎng)絡(luò)的方法在圖像融合過程中采用不同的方式來引入卷積神經(jīng)網(wǎng)絡(luò),一種采用端到端的方式來進行特征提取、特征融合和圖像重建,如圖3(a)所示,PMGI 是其典型代表,其基于梯度損失來引導(dǎo)網(wǎng)絡(luò)直接生成融合圖像。另一種采用預(yù)訓(xùn)練的CNN 來進行融合,而圖像重建則采用傳統(tǒng)方法實現(xiàn),如圖3(b)所示,Liu[6]等采用CNN 來獲取融合權(quán)重,而圖像分解和重建采用Laplacian金字塔實現(xiàn)。
基于生成對抗網(wǎng)絡(luò)的方法依靠生成器和鑒別器之間的對抗性博弈來估計目標(biāo)的概率分布,以一種隱含的方式聯(lián)合完成特征提取、特征融合和圖像重建,如圖4 所示。FusionGAN[7]是其典型代表,其采用對抗學(xué)習(xí)來融合紅外圖像和可見光圖像,進而豐富融合圖像的紋理特征。
基于自編碼器的方法其關(guān)鍵在于特征融合規(guī)則的設(shè)計,目前多采用基于人工設(shè)計的方法來實現(xiàn),如加權(quán)、L1-正則的方法,不可自學(xué)習(xí),限制了融合效果。基于卷積神經(jīng)網(wǎng)絡(luò)的方法易受到網(wǎng)絡(luò)結(jié)構(gòu)和損失函數(shù)的影響,而基于預(yù)訓(xùn)練的網(wǎng)絡(luò)不能兼顧特征提取和圖像重建,融合效果有限。基于生成對抗網(wǎng)絡(luò)的方法目前最為常用,能夠隱含地完成特征抽取、特征融合和圖像重建,并產(chǎn)生較理想的融合效果,但如何在訓(xùn)練過程中保持生成器和判別器的平衡,是其面臨的難題。
3 融合方法發(fā)展趨勢
隨著Transformer[8]結(jié)構(gòu)的提出,由于其能夠構(gòu)建長距離信息依賴,在自然語言處理領(lǐng)域所展現(xiàn)出極大的優(yōu)勢,受啟發(fā)于此,圖像領(lǐng)域首先在圖像分類任務(wù)上提出了視覺Transformer 結(jié)構(gòu)ViT[10],后續(xù)目標(biāo)檢測和分割也提出了相應(yīng)的基于Transformer 結(jié)構(gòu)的方法,并展現(xiàn)出了較卷積神經(jīng)網(wǎng)絡(luò)好的性能。因此,在紅外和可見光多模態(tài)融合方法的基礎(chǔ)上,提出了基于Transformer 結(jié)構(gòu)的方法,其基本結(jié)構(gòu)如圖5 所示。
基于Transformer 的融合方法能夠充分利用局部特征信息,并對長距離依賴進行建模,克服了現(xiàn)有融合方法缺乏全局上下文信息的問題,自動學(xué)習(xí)融合規(guī)則,展現(xiàn)出了更具前景的性能。從圖5 可以看出,基于Transformer的融合方法整體框架包含編碼器模塊、特征融合模塊和編碼器模塊三個部分組成,其中編碼器用于提取圖像特征,特征融合實現(xiàn)可將光和紅外特征的融合,解碼器用于圖像重建,生成最終的融合圖像。
(1)編碼器模塊通常基于預(yù)訓(xùn)練模型來提取圖像的特征fi(i∈ {1,2}),其中,i=1表示紅外特征,i=2表示可將光特征。通常采用卷積神經(jīng)網(wǎng)絡(luò)、Transformer 編碼器網(wǎng)絡(luò)或卷積神經(jīng)網(wǎng)絡(luò)和Transformer 編碼器相融合的網(wǎng)絡(luò)結(jié)構(gòu)來實現(xiàn),以提取圖像的局部信息和全局信息。通常由于紅外和可見光圖像所包含信息的差異性,編碼器模塊采用不同的網(wǎng)絡(luò)權(quán)重來提取相應(yīng)圖像的特征,并且,為了訓(xùn)練的穩(wěn)定性,在設(shè)計時會融入殘差網(wǎng)絡(luò)結(jié)構(gòu)。由于并不是所有的特征都有助于融合圖像的重建,因此,需要給不同的特征以不同的權(quán)重,即所要闡述的基于自注意力的特征融合。
(2)特征融合模塊首先基于圖像特征生成細化特征,然后采用融合策略進行特征融合生成最終的特征,作為解碼器的輸入。基于Transformer 的融合方法通常采用基于注意力的融合策略,以同時保留視覺細節(jié)信息和顯著的熱輻射區(qū)域。為了精準(zhǔn)獲取圖像的顯著特征,首先需要構(gòu)建注意力圖:
其中,Q,K分別表示自注意力中的Query 和Key,d 為特征維度,Wq和Wk為投射層權(quán)重,實現(xiàn)對特征fi的編碼,通過該步驟即可得到各特征對應(yīng)的權(quán)重,進而利用注意力加權(quán)得到融合特征:
其中,V為自注意力中的Value,Qv為可學(xué)習(xí)的投射層權(quán)重。具體在實現(xiàn)時,可采用類似ViT 的Transformer結(jié)構(gòu):
其中,MSA為多頭注意力網(wǎng)絡(luò),MLP為多層感知機網(wǎng)絡(luò)。由于自注意力機制需要遍歷特征圖的所有位置,具有平方計算復(fù)雜度,因此通常需要結(jié)合線性注意力、軸注意力機制及基于先驗的注意力機制來降低計算復(fù)雜度,提升計算效率。
(3)解碼器模塊基于融合特征生成融合圖像,因此可以采用反卷積或Transformer 的解碼器來實現(xiàn)。由于融合后的特征可能會丟失一些特定的細節(jié)信息,因此,結(jié)合編碼器的特征對于重建至關(guān)重要,以補充重建圖像的細節(jié)信息。
此外,為了獲取較好的融合效果,損失函數(shù)的設(shè)計起到了非常重要的作用,除了像素級別的重建,還需要充分地捕獲圖像的結(jié)構(gòu)信息和梯度信息,具體如下:
其中,Lmse為均方損失函數(shù),用于度量像素級別的重建效果,Lssim為結(jié)構(gòu)相似性損失函數(shù)[11],用于學(xué)習(xí)圖像的結(jié)構(gòu)信息,Ltv表示變分損失函數(shù)[12],用來保留圖像的梯度信息,以消除圖像重建過程的噪聲。λ1和λ2是用來平衡各損失的系數(shù)。
未來,可以從以下幾個方面進行研究:①任務(wù)相關(guān)的融合方法:由于不同的任務(wù)所需要的信息不同,可以根據(jù)不同的任務(wù)設(shè)計自監(jiān)督學(xué)習(xí)的代理任務(wù),來學(xué)習(xí)任務(wù)相關(guān)的融合特征。②更有效的特征抽取方法:卷積神經(jīng)網(wǎng)絡(luò)和Transformer 結(jié)構(gòu)各有優(yōu)勢,如何結(jié)合兩種網(wǎng)絡(luò)結(jié)構(gòu)以提取更有效的特征,也是值得研究的方向。③高效的網(wǎng)絡(luò)訓(xùn)練方法:基于Transformer 的融合方法通常需要較大的數(shù)據(jù)量,及較長的訓(xùn)練的時間,如何結(jié)合網(wǎng)絡(luò)結(jié)構(gòu)和參數(shù)有效微調(diào)方法,實現(xiàn)融合模型的快速構(gòu)建,也是研究的重點。
4 總結(jié)
基于紅外和可見光的多模態(tài)數(shù)據(jù)融合方法,需同時兼容特征提取、特征融合及圖像重建,關(guān)鍵在于融合規(guī)則的構(gòu)建,傳統(tǒng)的融合方法在特征提取和融合規(guī)則方面均需要人工設(shè)計,基于深度學(xué)習(xí)的融合方法,解決了特征自動構(gòu)建問題,但在融合規(guī)則方面多還是基于加權(quán)或L1 正則等方法,無法自動學(xué)習(xí)實現(xiàn)特征融合,且存在受網(wǎng)絡(luò)結(jié)構(gòu)影響及訓(xùn)練困難等問題,基于Transformer 的方法能夠?qū)﹂L距離依賴進行建模,表達及泛化能力強,可實現(xiàn)特征融合的自學(xué)習(xí),且網(wǎng)絡(luò)結(jié)構(gòu)模塊化,可方便地和其他網(wǎng)絡(luò)結(jié)構(gòu)相結(jié)合,具有極大的發(fā)展前景。
猜你喜歡
今日農(nóng)業(yè)(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學(xué)生數(shù)理化(高中版.高考數(shù)學(xué))(2021年1期)2021-03-19 08:28:38
現(xiàn)代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
湖北經(jīng)濟學(xué)院學(xué)報·人文社科版(2015年8期)2015-12-29 05:53:07
上海電機學(xué)院學(xué)報(2015年4期)2015-02-28 14:30:00
計算物理(2014年2期)2014-03-11 17:01:39
