基于YOLOv7的人體關(guān)聯(lián)實(shí)時吸煙目標(biāo)檢測方法
2024-01-29 00:31:13孫冰李好黃鑫凱任長寧鄒啟杰
軟件工程 2024年1期
孫冰 李好 黃鑫凱 任長寧 鄒啟杰





關(guān)鍵詞:吸煙檢測;目標(biāo)關(guān)聯(lián);YOLOv7;目標(biāo)檢測
0 引言(Introduction)
多數(shù)作業(yè)環(huán)境明令禁止吸煙,諸如物流倉儲、化工工廠、供電單位等,雖然可以通過中央監(jiān)控系統(tǒng)實(shí)時監(jiān)控各種作業(yè)場景,但是主要依賴人工監(jiān)查,存在漏報情況,不但不能節(jié)省人力成本,而且會對企業(yè)和工作人員的生命財產(chǎn)安全造成威脅。隨著計算機(jī)視覺技術(shù)的發(fā)展,目標(biāo)檢測技術(shù)日漸成熟,智能檢測得到廣泛的研究和應(yīng)用,由此本文提出一項(xiàng)基于YOLOv7[1]的人體關(guān)聯(lián)實(shí)時吸煙目標(biāo)檢測方法。
當(dāng)下不乏實(shí)時吸煙行為檢測的相關(guān)研究,但是對于實(shí)際應(yīng)用仍有可提升、待完善的地方,具體如下:第一,對于復(fù)雜場景小目標(biāo)(煙)的檢測精度尚有提升空間[2-3];第二,僅對香煙進(jìn)行檢測,對香煙相似物存在漏檢誤報的情況[4-5];第三,部分研究雖然通過增加姿態(tài)檢測、特征檢測、面部檢測等方式進(jìn)行優(yōu)化,但是復(fù)雜的算法導(dǎo)致模型檢測速度降低[3,6]。基于以上問題,本文提出改進(jìn)方法。首先,通過數(shù)據(jù)增強(qiáng)提升算法小目標(biāo)檢測能力,從而提高香煙檢測的準(zhǔn)確率,并解決過擬合問題;其次,基于當(dāng)前比較先進(jìn)的YOLOv7算法同時檢測人和煙,通過設(shè)置人和煙的目標(biāo)關(guān)聯(lián)閾值,增加檢測條件的限制,降低誤檢率;最后,經(jīng)過對比實(shí)驗(yàn)和消融實(shí)驗(yàn)驗(yàn)證方法的有效性和檢測方法性能的提升程度,并用工作現(xiàn)場視頻進(jìn)行算法的驗(yàn)證。
1 目標(biāo)檢測(Object detection)
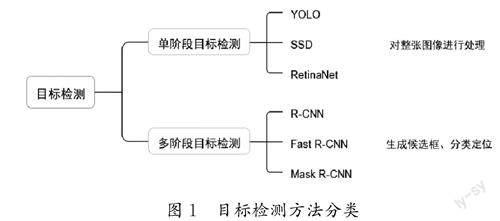
現(xiàn)有典型的目標(biāo)檢測方法可以分為單階段目標(biāo)檢測(YOLO、SSD、RetinaNet等)和多階段目標(biāo)檢測(R-CNN、FastR-CNN、Mask R-CNN等)(圖1)[7-8]。
1.1 多階段目標(biāo)檢測算法
多階段目標(biāo)檢測算法通常包含兩個階段,即生成候選框和分類定位。在第一個階段,算法使用候選框生成器生成多個候選框,每個候選框都與某個物體相對應(yīng)。在第二階段,候選框中的特征圖將被送入一個分類器和回歸器中,以進(jìn)一步提取物體的位置和類別信息。常見的多階段目標(biāo)檢測算法有R-CNN及其變種Fast R-CNN和Mask R-CNN等[8]。多階段目標(biāo)檢測算法通過使用候選框定位和識別物體,具有更高的準(zhǔn)確率和定位精度。但是,與單階段目標(biāo)檢測算法相比,多階段目標(biāo)檢測的計算復(fù)雜度更高,計算速度較慢,不適用于對實(shí)時檢測要求高的作業(yè)環(huán)境。
1.2 單階段目標(biāo)檢測算法
單階段目標(biāo)檢測算法通過處理整張圖像預(yù)測物體的位置和類別。這種算法速度較快,適合實(shí)時應(yīng)用場景。常見的單階段目標(biāo)檢測算法有(Single Shot MultiBox Detector,SSD)、RetinaNet、YOLO等[3]。這些算法通常將物體位置和類別信息結(jié)合起來作為網(wǎng)絡(luò)輸出,使用較少的候選框定位物體。SSD是以單個CNN為基礎(chǔ)的目標(biāo)檢測算法,可以同時檢測不同大小和比例的物體。RetinaNet將分類和回歸任務(wù)分別交給兩個并行的子網(wǎng)絡(luò)來解決分類精度和定位精度不平衡的問題,同時引入損失函數(shù)來調(diào)整難易樣本的權(quán)重,故此能夠獲得更好的目標(biāo)檢測性能。
YOLO是端到端的單階段目標(biāo)檢測算法,具有快速和高準(zhǔn)確率的特點(diǎn)。YOLO將輸入圖像劃分成網(wǎng)格,并對各個網(wǎng)格進(jìn)行分類、定位,生成每個物體的邊界錨框和概率。YOLO采用卷積神經(jīng)網(wǎng)絡(luò)處理整個圖像,以便于實(shí)時應(yīng)用。2020年發(fā)布的YOLOv5具有更小的模型體積和更快的推理速度,同時在目標(biāo)檢測精度方面也有一定的提升。2022年發(fā)表的YOLOv7算法集成以往YOLO系列的優(yōu)點(diǎn),并不斷推陳出新,盡管在準(zhǔn)確率和運(yùn)算速度上較以往YOLO系列都有所提升,但存在對小目標(biāo)檢測精度不夠的問題。在本實(shí)驗(yàn)測試中發(fā)現(xiàn),YOLOv7比以往YOLO系列更容易出現(xiàn)過擬合現(xiàn)象。相比多階段目標(biāo)檢測算法,單階段目標(biāo)檢測算法的處理速度更快、計算復(fù)雜度更低,適合實(shí)時應(yīng)用場景。但是,單階段目標(biāo)檢測算法在一些復(fù)雜場景下的準(zhǔn)確率可能不如多階段目標(biāo)檢測算法,因此本文在YOLOv7算法的基礎(chǔ)上做了一些調(diào)整,以適應(yīng)極小目標(biāo)(香煙)的檢測。
2 基于YOLOv7的吸煙檢測方法(A smokingdetection method based on YOLOv7)
2.1 YOLOv7模型
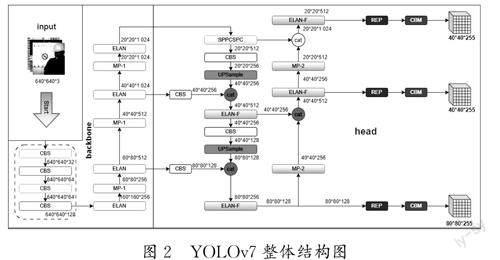
YOLOv7算法主要由輸入端(Input)、主干網(wǎng)絡(luò)(Backbone)和頭部網(wǎng)絡(luò)(Head)構(gòu)成,采用擴(kuò)展高效長程注意力網(wǎng)絡(luò)(EELAN)、基于級聯(lián)模型的模型縮放、卷積重參數(shù)化等策略,在檢測效率與精度之間取得了非常好的平衡[9-10]。輸入端由數(shù)據(jù)增強(qiáng)、自適應(yīng)錨框計算和自適應(yīng)圖片放縮構(gòu)成,將輸入圖像縮放至固定的尺寸,實(shí)現(xiàn)數(shù)據(jù)增強(qiáng)。主干網(wǎng)絡(luò)主要由多個CBS、ELAN、MPConv等模塊組成,用于圖像特征的提取[11]。預(yù)測端用于預(yù)測,采用聚合特征金字塔網(wǎng)絡(luò)結(jié)構(gòu),將底層信息通過自底向上的路徑傳遞到高層,實(shí)現(xiàn)差別層次特征的融合,借助REPcon結(jié)構(gòu)對不同尺度的特性進(jìn)行通道數(shù)調(diào)整。
如圖2所示,YOLOv7首先對輸入的圖片進(jìn)行預(yù)處理,處理為640×640像素大小的RGB圖片,其次輸入主干網(wǎng)絡(luò),通過主干網(wǎng)絡(luò)的三層高效長程注意力網(wǎng)絡(luò)進(jìn)行輸出,并繼續(xù)在頭部網(wǎng)絡(luò)層輸出三個不同大小的特征圖,經(jīng)過重參數(shù)化和卷積進(jìn)行圖像分類、圖像前后背景分類以及邊框預(yù)測,輸出最后的結(jié)果。
2.2 數(shù)據(jù)集增強(qiáng)
本實(shí)驗(yàn)通過互聯(lián)網(wǎng)收集了來自安防場景、公共場所、危險場所等現(xiàn)實(shí)場景的共計3 628張吸煙行為的圖像,并通過旋轉(zhuǎn)方式進(jìn)行數(shù)據(jù)集增強(qiáng),將抽煙行為數(shù)據(jù)集擴(kuò)充到14 512張,結(jié)合14 508張人體數(shù)據(jù)集,共計29 020張圖像,并按70%、15%和15%的占比分成訓(xùn)練集、測試集和驗(yàn)證集,數(shù)據(jù)集劃分見表1。
對數(shù)據(jù)集進(jìn)行如圖3所示的標(biāo)簽標(biāo)注,采用線上標(biāo)注工具makesense進(jìn)行目標(biāo)標(biāo)注,分別標(biāo)記為“person”“smoke”,獲得以文本文件形式存儲的標(biāo)注結(jié)果。
2.3 目標(biāo)關(guān)聯(lián)
吸煙行為的出現(xiàn)一般需要同時具備兩個基本條件———人和煙,故本研究通過YOLOv7模型同時定位人和煙,并進(jìn)行目標(biāo)關(guān)聯(lián),在算法中計算人和煙的中心點(diǎn)距離,當(dāng)二者距離小于設(shè)定閾值后,發(fā)出吸煙告警,實(shí)現(xiàn)吸煙檢測。
場地人員檢測錨框(x2p -x1p )×(y2p -y1p ) <50 000時,人的坐標(biāo)(xp ,yp )如下:
3 實(shí)驗(yàn)與分析(Experiment and analysis)
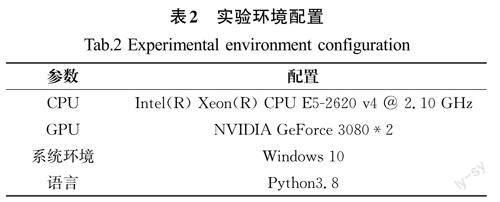
3.1 實(shí)驗(yàn)環(huán)境
實(shí)驗(yàn)環(huán)境使用Windows 10操作系統(tǒng)、NVIDIA GeForceRTX 3080顯卡進(jìn)行運(yùn)算。具體實(shí)驗(yàn)配置見表2。網(wǎng)絡(luò)模型訓(xùn)練階段,訓(xùn)練迭代次數(shù)設(shè)置為150次,Batch size 設(shè)置為8,Imgsize 設(shè)置為[640,640],設(shè)置好限定條件后進(jìn)行訓(xùn)練。
3.2 性能分析
3.2.1 分析指標(biāo)
本實(shí)驗(yàn)將查準(zhǔn)率(Precision)、召回率(Recall)、平均精度均值(mAP)作為評價指標(biāo),生成了三者隨迭代次數(shù)變化的折線圖,并生成Precision-recall曲線圖像作為分析評價的輔助參考。
精確率也稱查準(zhǔn)率,該指標(biāo)用來判斷模型檢測是否準(zhǔn)確,是在識別出的物體中正確的正向預(yù)測所占的比率。在公式(3)中,TP 表示真的正樣本,F(xiàn)P 表示假的正樣本。
召回率也稱查全率,是指正確識別出的物體占總物體數(shù)的比率,該指標(biāo)用來判斷模型檢測是否全面,在公式(4)中,F(xiàn)N表示假的負(fù)樣本。
AP 代表Precision-recall 曲線下方面積,分類器越好,AP值越高。如公式(5)所示,目標(biāo)檢測算法中最重要的指標(biāo)之一mAP 代表多個類別AP 的平均值,大小處于[0,1]內(nèi),越接近1,表明該目標(biāo)檢測模型在給定的數(shù)據(jù)集上的檢測效果越好。
3.2.2 結(jié)果分析
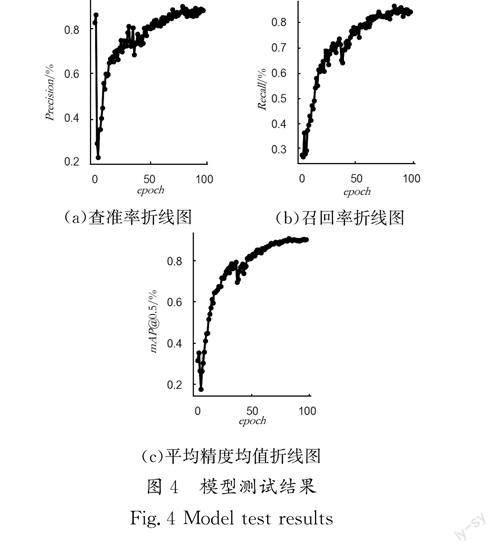
將實(shí)驗(yàn)數(shù)據(jù)進(jìn)行可視化處理,繪制查準(zhǔn)率、召回率和平均精度均值的折線圖,如圖4(a)、圖4(b)所示,查準(zhǔn)率和召回率均達(dá)到90%且圖4(c)中的平均精度均值達(dá)到90%以上,說明模型在檢測精度上表現(xiàn)出色。
通過不斷改變識別閾值,使得系統(tǒng)能夠依次識別前N 張圖片,閾值變化的同時會導(dǎo)致Recall 與Precision 值的變化,從而得到Precision-recall 曲線[12]。如圖5所示,本模型測試所得曲線下方的面積較大,并且在Recall 值增長的同時,Precision 的值能保持在一個很高的水平,在Precision 和Recall 之間實(shí)現(xiàn)了較好的平衡[12]。
為了驗(yàn)證本模型性能,將原YOLOv7作為基線模型,通過對YOLOv7模型定位內(nèi)容的修改比對進(jìn)行如表3所示的消融實(shí)驗(yàn),分別取實(shí)驗(yàn)中最優(yōu)的模型在制作好的測試集進(jìn)行驗(yàn)證。在基于YOLOv7分別進(jìn)行僅定位香煙和人體關(guān)聯(lián)檢測兩種方法中,雖然人體關(guān)聯(lián)的方法犧牲了一定的訓(xùn)練時長,但是將誤檢率降低到了0.001%,較僅定位香煙的方法有6%的性能提升,基本解決了香煙檢測的誤判問題。
3.2.3 性能對比
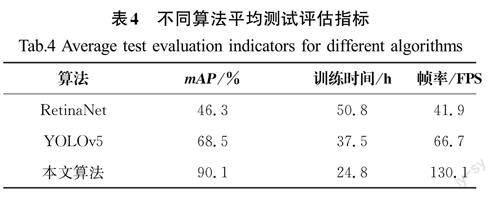
為了證明本文方法對比于其他方法在檢測準(zhǔn)確率、模型精簡度和檢測速度上具有一定優(yōu)勢,選取RetinaNet和YOLOv5兩種算法在同一數(shù)據(jù)集上進(jìn)行測試,以mAP、訓(xùn)練時間和幀率作為評價指標(biāo)進(jìn)行3種算法的性能對比判斷。
由表4可知,與其他兩種算法相比,本文所提方法的mAP值較RetinaNet算法提升了94.6%,較YOLOv5算法提升了31.5%,訓(xùn)練時間較RetinaNet算法和YOLOv5算法分別縮短了51.2%、33.9%,幀率分別提高了210.5%、95.1%,性能提升效果顯著。
綜合對比實(shí)驗(yàn)結(jié)果,基于YOLOv7的人體關(guān)聯(lián)實(shí)時吸煙目標(biāo)檢測方法較RetinaNet和YOLOv5算法大大提升了吸煙行為的檢測準(zhǔn)確率,降低了訓(xùn)練時間,提高了檢測幀率。
3.3 檢測結(jié)果可視化
使用現(xiàn)場拍攝的安防場景吸煙行為和人員作業(yè)行為的視頻做測試,在低像素、遠(yuǎn)距離的情況下,圖6(a)中安防器械場地準(zhǔn)確定位了場地作業(yè)人員。圖6(b)中安防辦公場地準(zhǔn)確定位了人和煙,判斷滿足距離關(guān)系后,以人和煙中心為對角線框出吸煙行為,實(shí)現(xiàn)抽煙行為的準(zhǔn)確定位,并對吸煙行為發(fā)出告警。
分別在不同光線、不同角度、不同像素情況下進(jìn)行視頻檢測驗(yàn)證,結(jié)果如圖7所示,圖7(a)有照明高像素正面視角和圖7(b)無照明低像素側(cè)面視角都成功定位了人和煙,并判斷存在抽煙行為,說明方法具有一定的可靠性和可行性。
4 結(jié)論(Conclusion
本文以復(fù)雜背景下小目標(biāo)檢測為基礎(chǔ),針對安全要求較高的環(huán)境下的吸煙行為檢測進(jìn)行研究,提出了基于YOLOv7的人體關(guān)聯(lián)的實(shí)時吸煙目標(biāo)檢測方法。通過同時關(guān)聯(lián)定位香煙和場地內(nèi)人員,提升吸煙行為檢測的準(zhǔn)確度。通過以相同數(shù)據(jù)集為基礎(chǔ)進(jìn)行驗(yàn)證發(fā)現(xiàn),人體關(guān)聯(lián)檢測較僅定位香煙檢測,雖然在訓(xùn)練時間上有一定的犧牲,但是顯著提升了檢測準(zhǔn)確度。此外在同一數(shù)據(jù)集驗(yàn)證發(fā)現(xiàn),YOLOv7算法與RetinaNet、YOLOv5算法相比,大大縮短了檢測時間,并且檢測準(zhǔn)確度和幀率都顯著提升,說明本方法能夠有效提升檢測率,降低漏檢率,具備實(shí)時性和高效性。
