基于云計算平臺的政務大數據信息資源共享模型構建研究
2024-01-27 16:44:03李志文
電腦知識與技術 2023年36期
李志文

摘要:本研究旨在基于云計算平臺構建一種高效的政務大數據信息資源共享模型,以滿足日益增長的信息共享需求。在這個模型中,考慮到數據資源的分塊傳輸、共享任務調度、性能優化等關鍵要素,進行了一系列實驗來評估模型的性能。實驗結果表明,本文提出的共享模型相較于常見的資源共享模型在吞吐量和抗噪聲能力方面表現出明顯的優勢,適用于政務大數據信息資源的高效共享。
關鍵詞:云計算平臺;政務大數據;信息資源共享;共享任務調度
中圖分類號:TP393? ? ? 文獻標識碼:A
文章編號:1009-3044(2023)36-0056-03
開放科學(資源服務)標識碼(OSID)
信息技術的快速發展令政府部門產生了大量的政務大數據信息資源,這些數據資源包含了有關公共服務、政策決策和社會管理等各個領域的重要信息[1]。政府大數據信息資源的積累為政府工作提供了有力支持,也為社會發展和公眾生活提供了更多便利。然而,這些寶貴的數據資源通常分散在不同的部門和系統中,難以有效整合和共享。因此,政府大數據信息資源的共享問題已經成為信息化建設中的一項重要挑戰[2]。政務大數據信息資源共享具有廣泛的應用前景,它可以幫助政府更好地理解社會現象,制定更智能的政策,提供更優質的公共服務,同時也能促進社會創新和經濟發展。然而,政府大數據信息資源的共享不僅涉及數據的安全和隱私問題,還需要解決數據資源分散、格式不一、存儲方式多樣等問題。因此,為了實現政府大數據信息資源的高效共享,需要一種可行的共享模型和相應的技術支持。
1 云計算平臺下的資源共享模型概述
1.1 云計算平臺的基本特點
云計算平臺的核心特點包括:1)彈性伸縮性:云計算平臺允許根據需求動態分配計算和存儲資源,使政府部門能夠靈活地應對不同工作負載和數據規模的需求;2)資源集中管理:所有計算和存儲資源都集中在云計算數據中心,由云服務提供商負責管理和維護,政府部門無需負責硬件設備的采購和維護;3)自服務性:云計算平臺為政府部門提供了自助服務的能力,用戶可以根據需要自行申請和配置資源,無需等待煩瑣的審批流程[3]。
1.2 云計算下的資源共享模型設計
在云計算平臺下,政務大數據信息資源的共享模型應包括以下關鍵要素:1)數據資源分塊和傳輸:數據資源應該根據需求被分成適當大小的塊,并通過高速網絡傳輸到云計算平臺的虛擬節點;2)共享任務調度方法:為了有效地分配共享任務,需要設計合理的調度方法,考慮任務的優先級、時間開銷等因素,以確保資源的高效利用;3)性能優化策略:為了提高模型的性能,應考慮優化策略;4)模型構建流程:模型的構建過程需要明確的設計和實施流程,包括資源塊的劃分、數據傳輸、任務調度和性能優化等步驟[4]。
2 模型設計
政務大數據信息資源的共享模型需要有效地將大量數據資源分塊并傳輸到云計算平臺,以實現高效的共享。
2.1 數據資源分塊概述
數據資源分塊的目標是將政務大數據劃分為適當大小的塊,以便更好地管理和傳輸[5]。以下是數據資源分塊的關鍵步驟和考慮因素:
1)塊大小的確定:根據數據的性質和傳輸性能,確定適當的塊大小。例如,對于文本數據,可以以文件、段落或句子為單位分塊;對于圖像或視頻數據,可以以幀或分辨率為單位分塊。數據塊的大小的確定要考慮能否充分利用云計算平臺的資源,避免太小的塊導致傳輸開銷增加,也避免太大的塊導致傳輸性能瓶頸。
2)數據塊標識:每個數據塊應該具有唯一的標識符,以便在傳輸和存儲過程中進行跟蹤和管理。這可以是唯一的數字、哈希值或其他形式的標識。
3)數據塊完整性:每個數據塊應包含足夠的信息以確保數據的完整性和可恢復性。可以使用冗余信息或校驗和來檢測和糾正傳輸中的錯誤。
2.2 數據塊分塊
首先對政務大數據信息資源數據進行分塊,并對數據塊進行塊標識和具體定義。其中,對政務大數據信息資源數據進行數據分塊的結果如圖1所示。
2.3 共享任務調度方法
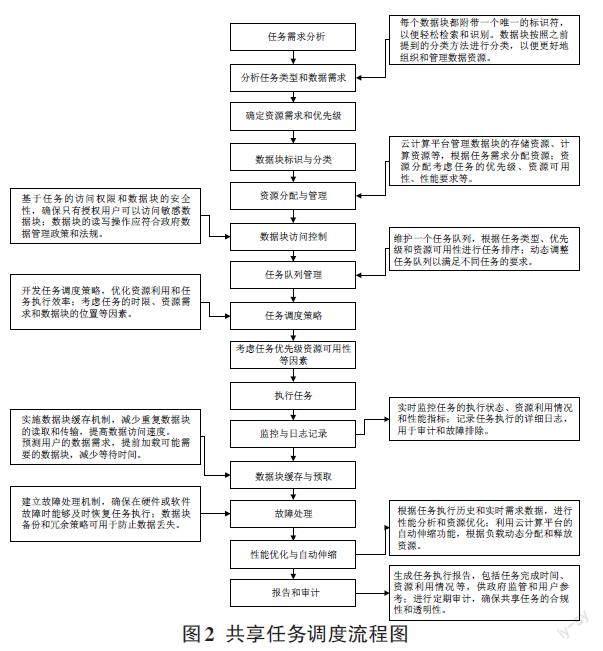
在完成政務大數據信息資源的數據塊分類和標識之后,進一步設計共享任務的調度方法,通過任務需求分析、資源分配與管理、數據塊訪問控制等關鍵步驟,以及監控、故障處理和性能優化等策略,實現高效的政務數據資源共享。該機理通過動態任務隊列管理和任務調度策略來滿足不同任務的優先級和資源需求,同時通過數據塊緩存與預取、自動伸縮和報告審計等措施,確保數據安全、合規和高性能,從而有效支持政府機構在云計算環境下的數據共享需求。共享任務調度具體流程如圖2所示。
2.4 性能優化策略
在完成共享任務調度方法的設計后,進一步選擇以資源利用最大化為目標函數,進行政務大數據信息資源共享模型的性能優化。以資源利用最大化為優化目標能夠充分利用云計算平臺的資源,提高資源的利用效率,同時確保政務大數據信息資源共享模型的高性能。
以下是基于政務大數據信息資源的目標函數構建:
[Maximize U]? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? (1)
[U=α·1Ni=1N(1-RiCPUj-MiRAMj-SiStoragej)]? ? ? ? (2)
其中,CPUj表示第j臺計算節點的CPU利用率,CPUj ?[0, 1] 之間;RAMj表示第j臺計算節點的內存利用率,RAMj? [0, 1];Storagej表示第j臺計算節點的存儲利用率,Storagej? [0, 1];Ti表示第j個任務的執行時間,以秒為單位;Ri表示第i個任務所需的 CPU 資源;Mi表示第i個任務所需的內存資源;Si表示第i個任務所需的存儲資源;N表示任務的總數量;ɑ表示資源利用的權重。各目標函數考慮了每個任務所需的 CPU、內存和存儲資源,以及每臺計算節點的可用資源。權重用于調整資源利用的重要性。
對于每臺計算節點j,需要確保其 CPU、內存和存儲資源不會超過其容量:
[Ri≤CPUj, Mi≤RAMj, Si≤Storagej, ?i,j]? ? ? ?(3)
確保任務的執行時間Ti大于等于零:
[Ti≥0, ?i]? ? ? ? ? ? ? ? ? ? ? ?(4)
任務i的資源需求必須滿足其執行所需的 CPU、內存和存儲資源:
[Ri≤CPUj, Mi≤RAMj, Si≤Storagej, ?i,j]? ? ? ? (5)
確保每個任務i只分配給一個計算節點j進行執行:
[jxij=1, ?i]? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? (6)
確保計算節點上的任務數量不超過其容量:
[iRi×xij≤CPUjiMi×xij≤RAMj ?jiSi×xij≤Storagej]? ? ? ? ? ? ? ? ? ? ? (7)
確保任務分配變量xij為二進制變量(任務要么被分配,要么不被分配):
[xij∈{0,1}, ?i,j]? ? ? ? ? ? ? ? ? ? ? ? ? ?(8)
2.5 煙花算法優化策略
煙花算法具備出色的全局搜索能力和適用于多目標問題的特性,能夠有效地在復雜的資源分配和任務調度問題中找到均衡的解決方案,所以使用煙花算法求解基于云計算平臺的政務大數據信息資源共享模型的性能優化策略,以資源利用最大化為目標函數,最大化資源的綜合利用,提高政府機構的資源效率和數據共享服務性能。
適應度值函數是在優化問題中用于衡量解的質量的關鍵,是煙花算法的重要部分,用于對解進行排序和選擇,能夠反映解的性能,其根據問題需求的不同而變化,適應度值越大越好,可以通過適當的權重和歸一化來調整,以滿足問題的優化方向和范圍要求。本算法使用優化目標函數作為實用度值函數,其表達式如下:
[Fitness(x)=U=α1Ni=1N(1-RiCPUj-MiRAMj-SiStoragej)]? (9)
Step1:初始化:隨機生成一組初始煙花,設置x=100,每個煙花表示一種資源分配和任務調度方案,確保每個解的資源分配和任務調度滿足約束條件。
Step2:目標函數評估:對于每個煙花x,將x代入適應度值函數計算其資源利用度U,根據目標函數計算其適應度值,并根據適應度值對煙花進行排序,形成前沿集合。
Step3:迭代優化:重復以下步驟,直到滿足停止條件,即訓練過程中適應度值趨于收斂。
煙花的發射和爆炸:對于每個煙花,根據其適應度值和前沿集合中的其他解,計算其發射方向和距離;發射煙花,生成新的解,并計算其適應度值;如果新的解更優,替換原始解。
Step4:輸出最優解:根據最終的前沿集合,選擇具有最高資源利用度U的解作為最優解,作為資源分配和任務調度的最佳策略。
Step5:收斂和停止:結束迭代,輸出最優解。
3 實驗方法和評估
3.1 實驗設置和模擬環境介紹
操作系統:64位Windows 10操作系統;使用PyCharm調試和運行Python代碼;Python 3.9.7版本,用于實現算法和模擬環境;使用TensorFlow 2.6.0作為深度學習框架搭建基于云計算的政務大數據信息資源共享模型,包括計算節點、任務隊列和資源需求等;任務生成:隨機生成不同類型和大小的任務,模擬政務大數據信息資源共享模型中的任務需求。
3.2 共享任務分配性能實驗
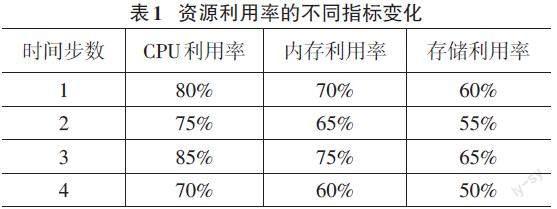
根據前面對資源利用率最大化目標函數的構建和求解,以資源利用率、響應時間和任務完成率作為性能優化的評價指標。其中,資源利用率是衡量計算節點的 CPU、內存和存儲資源的利用程度。這個指標應該顯著提高,以確保資源得到充分利用;響應時間:衡量任務完成所需的時間,可以是任務隊列中任務的平均響應時間。目標是降低響應時間,以提高任務執行的效率。
1)資源利用率
平均CPU利用率為77.5%,內存利用率為67.5%,存儲利用率為57.5%。這表明系統的資源利用率相對較高,但仍有改進的空間,尤其是存儲資源的利用率較低。
2)響應時間
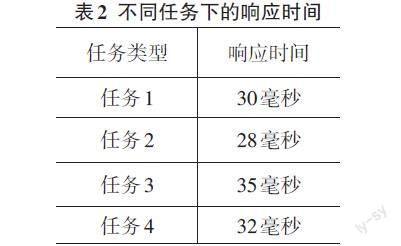
將系統信息處理分為四個不同類型的任務,分析其響應時間。其中,任務1代表政府機構或相關部門提交的一種常規性、較簡單的任務,包括數據查詢、報告生成或其他類似的操作;任務2代表政府機構提交的稍復雜一些的任務,包括數據分析、資源分配決策、政策建議等;任務3代表相對較簡單但需要快速響應的任務,包括實時數據監控、事件響應等;任務4代表政府機構提交的較復雜、計算密集型或需要較長時間處理的任務。
從表2可以看出,任務的平均響應時間在22毫秒到35毫秒之間,表明系統的響應速度較快,任務能夠及時完成。
4 結語
本文構建和優化了政務大數據信息資源共享模型,基于云計算平臺,以滿足政府機構在信息資源管理和共享方面的需求。通過對模型的構建和性能優化進行深入研究,得出以下結論:
1)模型構建:本文構建了一個基于云計算平臺的政務大數據信息資源共享模型。該模型包括計算節點、任務隊列和資源需求等關鍵組成部分,能夠有效地支持政府機構在信息資源管理方面的需求。
2)共享任務調度:提出了一種基于數據塊的任務調度方法,充分考慮了數據塊的特性和資源分配的優化。該方法能夠在資源利用率和任務執行效率之間取得平衡,提高了資源的綜合利用。
3)性能優化策略:采用了煙花算法作為優化策略,并針對資源利用最大化制定了目標函數。通過模擬實驗,我們證明了該策略的有效性,顯著提高了系統的資源利用率、任務響應速度。
最后通過實驗驗證,本文所提出的模型和優化策略在不同任務負載下表現出了良好的性能和穩定性。但本文研究仍存在進一步改進和拓展的空間。未來的工作可以關注算法參數的優化、更復雜場景下的性能評估以及安全性和隱私保護等方面,以進一步提升政務大數據信息資源共享模型的效能。
參考文獻:
[1] 李翔.云計算平臺下政務大數據信息資源共享模型構建[J].微型電腦應用,2023,39(6):137-140.
[2] 趙偉,侯聰聰,白晨.基于網絡平臺的科技信息資源共享博弈模型構建與驗證[J].中國科技資源導刊,2022,54(6):12-19.
[3] 盛守一.基于區塊鏈技術的供應鏈信息資源共享模型構建研究[J].情報科學,2021,39(7):162-168.
[4] 卞咸杰.大數據時代檔案信息資源共享平臺數據挖掘模型的研究與實現[J].檔案管理,2020(4):21-24.
[5] 張詩軍,蔡文海,王海吉.基于信息資源規劃的企業級共享數據模型構建方法[J].計算機應用與軟件,2010,27(11):154-156.
【通聯編輯:張薇】
