一種基于動態時序劃分的視頻理解方法
2024-01-27 13:41:31董淑慧
電腦知識與技術 2023年36期
關鍵詞:語言
董淑慧
摘要:近年來,隨著語言-視覺模型的快速發展,結合視覺編碼器和大語言模型進行視頻理解的方法極大超越了傳統的視頻行為分類模型。由于大語言模型可以很好地進行信息的歸納和推理,因此可以將視頻幀的特征輸入大語言模型,從而得到每一幀的場景描述,最終整理成一個視頻的詳細信息。盡管上述方法可以得到一個視頻非常詳盡的描述,但是卻忽略了視頻中不同場景的重要性,從而無法準確理解視頻中的關鍵信息。文章提出了一種基于動態時序劃分的視頻理解方法,首先根據場景對視頻進行切片,然后通過一個自適應的重要性評估網絡計算每個視頻切片的重要性得分,最后基于重要性得分將每個視頻切片的特征進行加權平均得到最終的視頻特征。相較于直接提取視頻特征的方法,該方法所獲取的視頻特征結合了不同視頻片段的重要性,更容易理解視頻中的關鍵信息。該方法在多個視頻理解基準上進行實驗,均獲得5%~10%的提升,充分證明了該方法在視頻理解中的有效性。
關鍵詞:語言-視覺模型;動態時序劃分;視頻切片;視頻理解
中圖分類號:TP391? ? ? 文獻標識碼:A
文章編號:1009-3044(2023)36-0019-03
開放科學(資源服務)標識碼(OSID)
0 引言
視頻是人類進行信息傳遞過程中一個非常重要的載體,它結合了視覺、音頻、文本等信息,即使是一個很短的視頻片段,也集成了豐富的信息量。因此,設計一個機器用于理解視頻是研究人員一直努力的目標。相較于圖像理解而言,視頻數據最大的難點在于時序信息難以編碼。時序信息表示的是不同視頻幀之間信息的變化,這是視頻特征需要表示的一個關鍵信息。
為了能夠有效地編碼視頻中的時序信息,以前的研究工作主要有兩種方法。其中一種是使用3D卷積神經網絡(簡稱 CNN)直接對視頻進行編碼[1-2],這種方法完全依賴于卷積網絡,能夠學會如何提取不同幀之間的時序信息。隨著近些年來視覺編碼器性能的飛速發展,圖像編碼器能夠提取到泛化性能很強的圖像特征,因此直接對單幀圖像特征進行池化也能夠獲取到視頻的特征[3]。第一種方法獲取到的視頻特征依賴于訓練卷積網絡過程中的下游任務,對于不同的下游任務都需要重新訓練。第二種方法可以直接使用一個預訓練模型對視頻進行編碼,不需要重新訓練,可以很好地泛化到不同的下游任務。
上述的兩種視頻特征提取的方法都存在一個問題,這些方法無法獲取到視頻在不同片段中的重要性。例如,在一部電影這種長視頻中,重要的關鍵情節只占其中的一小部分,如果對所有時間都采用相同的做法進行編碼,則無法準確理解電影中的核心情節。為了解決上述方法所存在的問題,本文提出了一種基于動態時序劃分的方法,首先根據情節對視頻進行切片,然后再計算不同切片之間的重要性。本方法結合了上述兩種方法的優點,既能夠結合連續多幀的信息,又能夠關注到每一幀中的細節。
1 基于動態時序劃分的時序理解方法
1.1 視頻理解框架
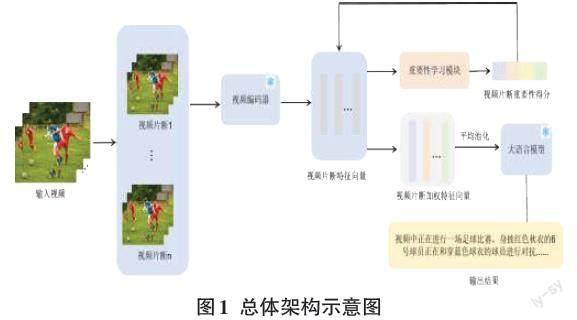
在本文提出的視頻理解框架中,最主要的思想是通過重要性學習模塊區分不同視頻片段的重要性,內容更豐富的視頻片段在最后的視頻特征中占有更大的比重。這種方法可以讓大語言模型在理解視頻的時候更著重于關鍵內容,使得大語言模型輸出更符合視頻內容的描述。具體結構如圖1所示。
整個流程分為三個部分,完整的視頻記作[V],首先使用視頻切片工具PySceneDetect[4]將視頻切成多個片段,[V={v1, v2, ...,vn}],這樣可以根據不同的情節獨立編碼視頻。然后使用視頻編碼器[Fv]對每個視頻片段提取特征,由于當前已經有很多泛化性能很強的視頻編碼器,因此這里直接加載預訓練的模型參數[5],并且凍結該部分。具體的計算過程如式(1)所示。
[E={e1, e2, ...,en} = Fv(V), E∈Rn×d]? ? ? ? ? ? (1)
視頻編碼器輸出的每個視頻片段的特征向量[E={e1, e2, ...,en}],每個特征向量的維度為[d]。為了得到不同視頻片段在完整視頻中的重要性得分,將每個視頻片段輸入到一個重要性學習模塊[Fs]。為了讓模型的結構盡可能簡潔,這里使用一個多層感知機(簡稱MLP)來實現重要性學習模塊。重要性學習模塊輸出的是每個視頻片段的重要性得分記為[S]。如式(2)所示。
[S={s1, s2, ...,sn} = Fs(E), s1+ s2+ ...+sn = 1]? (2)
得到每個視頻片段特征向量的權重得分之后,將得分分別乘上對應的特征向量,然后對加權之后的特征向量進行平均池化,得到最終完整視頻的特征向量T。相較于最大值池化而言,平均池化更加適合視頻理解任務。因此在一個完整的視頻中,雖然重要的情節占其中很大的比例,但是情節平淡的視頻片段也能夠幫助大語言模型更全面地分析視頻的內容。如式(3)所示。
[T=1n1n(s1e1 +s2e2 +... + snen )]? ? ? ?(3)
最后,需要將完整的視頻特征輸入大語言模型中,最終輸出視頻詳細的描述。在早些年的大語言模型如GPT-3[6]中,模型的輸入限制只能是文本特征,并不支持視覺信息的理解。后續有一些工作如CLIP[5]在大批量的圖像-文本對中預訓練多模型,從而可以對齊文本特征與視覺特征。于是這種思想被引入大語言模型中,由于視覺特征可以對齊到文本特征,因此可以將視覺的特征直接輸入大語言模型中,得到圖片或者視頻中內容的描述[7]。
1.2 重要性評估模塊
在視頻內容分析的流程中,重要性評估模塊扮演著關鍵角色。此模塊的核心任務是評估每個視頻片段在整個視頻中的重要性,為后續的視頻理解和特征提取提供依據。具體實現上,這一模塊采用了多層感知機(MLP)的結構,它能有效地學習和識別視頻片段的重要性特征。這個模塊是整個框架中唯一需要參數調整的模塊,由于視頻編碼器和大語言模型參數都是凍結的,所有該方法的訓練是極其輕量化的。
首先,從視頻編碼器提取出的特征向量被輸入重要性評估模塊。多層感知機通過其多層結構對這些特征進行深度分析,從而評估每個視頻片段的重要性。這一過程通過一系列的非線性變換,使得模型可以捕捉到視頻片段中復雜的、層次性的特征。
輸出的是每個視頻片段的重要性得分,這些得分反映了各個片段對于整體視頻內容理解的貢獻度。通過這種方式,模型能夠區分哪些片段是關鍵的(如劇情高潮、重要事件等),哪些則相對次要。這種分辨能力對于后續的特征融合和視頻理解至關重要,能夠確保大語言模型在分析視頻時關注到最關鍵的內容。
除了上述的作用外,重要性評估模塊還有一個重要的功能是進一步對齊視覺特征和文本特征。由于視覺編碼器和大語言模型都是分別進行預訓練,這兩個模型并不在一個特征空間中。如果直接將視覺編碼器輸出的特征向量直接輸入大語言模型,會造成極大的語義偏差。在引入重要性評估模塊之后,在訓練過程中除了學習不同視頻片段的重要性得分之外,同時也在不斷拉齊視覺編碼器和大語言模型之間的特征偏差。
1.3 大語言模型
在視頻內容分析的最后階段,大語言模型的作用是將處理過的視頻特征轉化為詳細的視頻描述。這一過程標志著從純視覺信息到文本描述的轉換,是理解和表述視頻內容的關鍵步驟。
早期的大型語言模型,如GPT-3,主要限于處理文本信息,無法直接處理視覺信息。但隨著技術的發展,出現了如CLIP這樣的多模態預訓練模型,它們能夠在大規模圖像-文本對數據上進行預訓練,實現視覺特征與文本特征的對齊。這種技術的發展使得大語言模型能夠直接處理視覺信息。
在整個視頻理解流程中,經過重要性評估和特征提取后,視頻的視覺特征被轉換為與文本特征相對齊的格式。這些特征隨后被輸入大語言模型中。模型利用其強大的文本生成能力,結合輸入的視覺特征,生成對視頻內容的詳細描述。這種描述不僅包括視頻的基本內容,還能深入揭示視頻的情感色彩、敘事結構等更加復雜的層面。
總之,大語言模型在視頻內容分析中的應用,極大地拓展了其在多模態理解領域的可能性,為視頻內容的深度理解和描述提供了強有力的工具。
2 實驗結果
2.1 實驗條件與基準
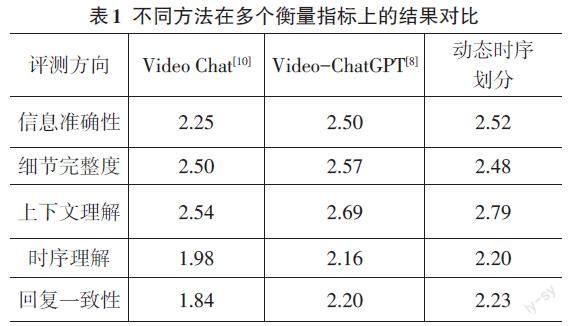
為了更加全面、公平地評估本文提出的方法,采用與Video-ChatGPT[8]相同的評測基準。基于ActivityNet-200[9]數據集,來定量評估該方法生成文本描述的準確性。這個評測基準會從5個方面來衡量模型的性能,分別是信息的準確性、細節的完整性、上下文理解、時序理解以及回復一致性。并且會從兩個主要的對比實驗來觀察該方法的特性,第一個對比實驗是比較與當面最先進方法的一些差距,第二個實驗是對比添加與不添加重要性評估模塊對最終結果的影響。
2.2 對比結果分析
通過與當前最先進的視頻理解方法在多個衡量角度的對比,可以看出本文提出基于動態時序劃分的視頻理解方法在很多方面有著非常明顯的優勢。具體如表1所示。
實驗結果表明,動態時序劃分方法在視頻內容分析中整體上表現出色,尤其在上下文理解、時序理解和回復一致性方面優于以往的Video Chat和Video-ChatGPT方法。它通過更精確地分析視頻的內容結構,能夠更有效地理解視頻內容的上下文和時間發展,從而在保持信息準確性和回復一致性方面表現更好。雖然在細節完整度方面略遜于Video-ChatGPT,這是因為重要性評估模塊會減弱一些平淡情節對最終視頻描述的影響,但其在處理具有復雜時序和上下文關系的視頻內容方面的整體優勢是明顯的。
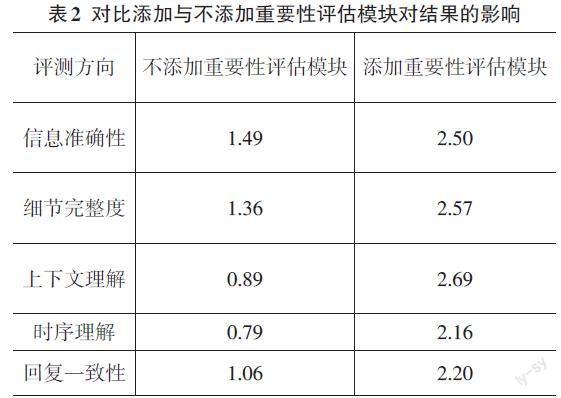
從表2的實驗對比可以看出,添加重要性評估模塊顯著提升了視頻內容分析的性能。在所有評測方向上,使用重要性評估模塊的方法比不使用時表現得更好。具體來說,信息準確性、細節完整度、上下文理解、時序理解和回復一致性都有了顯著的提升。這些改進突出了重要性評估模塊在視頻分析中的關鍵作用,特別是在理解視頻內容的上下文和時序方面。通過準確評估每個視頻片段的重要性,這一模塊有效地指導了整個分析過程,確保了結果的準確性和一致性,同時也提高了對視頻細節的完整捕捉。這表明在視頻內容分析中,重要性評估模塊是不可或缺的一個環節。
從結果中還能看出,如果沒有添加重要性評估模塊,在所有評測方向都會有極大的性能下降。這也充分證明了重要性評估模塊不僅僅能夠幫助大語言模型更好地理解視頻,而且還在對齊視覺特征與語言特征中起到的關鍵作用。如果沒有該模塊,視覺特征和語言特征之間有著較大的偏差,從而導致在所有的評測中都展現了極差的結果。
3 結束語
為了解決以往視頻理解方法中都忽略了不同情節重要性的問題,本文提出了一種基于動態時序劃分的視頻理解方法。通過重要性評估模塊對不同視頻片段進行打分,然后將得分作為權重對視頻片段特征進行加權平均,從而得到最后的視頻特征。融合了不同視頻片段重要性的視頻特征輸入大語言模型,能夠更好地幫助大語言模型去理解視頻中重要性更高的情節。同時,重要性評估模塊也幫助模型能夠更好地對齊視覺特征與語言特征,從而得到更準確的結果。最后,本文從5個評估方向全面對比最先進方法的結果,證明了該方法在視頻理解中的有效性。
參考文獻:
[1] TRAN D,BOURDEV L,FERGUS R,et al.Learning spatiotemporal features with 3D convolutional networks[C]//2015 IEEE International Conference on Computer Vision (ICCV).Santiago,Chile.IEEE,2015:4489-4497.
[2] FEICHTENHOFER C,FAN H Q,MALIK J,et al.SlowFast networks for video recognition[C]//2019 IEEE/CVF International Conference on Computer Vision (ICCV).Seoul,Korea (South).IEEE,2019:6201-6210.
[3] WANG Y,LI K C,LI Y Z,et al.InternVideo:general video foundation models via generative and discriminative learning[EB/OL].[2023-03-10].2022:arXiv:2212.03191.https://arxiv.org/abs/2212.03191.pdf.
[4] Pyscenedetect:Video scene cut detection and analysis tool[EB/OL].[2023-05-10].https://www.scenedetect.com/.
[5] RADFORD A,KIM J W,HALLACY C,et al.Learning transferable visual models from natural language supervision[EB/OL].[2023-03-10].2021:arXiv:2103.00020.https://arxiv.org/abs/2103.00020.pdf.
[6] BROWN T B.Language models are few-shot learners[C]//Proceedings of the 34th International Conference on Neural Information Processing Systems, NIPS’20, Red Hook, NY, USA. Curran Associates Inc,2020.
[7] LI J N,LI D X,XIONG C M,et al.BLIP:bootstrapping language-image pre-training for unified vision-language understanding and generation[C]//International Conference on Machine Learning,2022.
[8] MAAZ M,RASHEED H,KHAN S,et al.Video-ChatGPT:towards detailed video understanding via large vision and language models[EB/OL].[2023-03-10].2023:arXiv:2306.05424.https://arxiv.org/abs/2306.05424.pdf.
[9] HEILBRONB G F C,ESCORCIA V,NIEBLES J C.Activitynet:A large-scale video benchmark for human activity understanding[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2015:961-970.
[10] LI K C,HE Y N ,WANG Y,et al.Videochat:Chat-centric video understanding[EB/OL].[2023-06-02].https://arxiv.org/pdf/2305.06355v1.pdf.
【通聯編輯:謝媛媛】
猜你喜歡
中華詩詞(2023年8期)2023-02-06 08:51:28
文苑(2020年4期)2020-05-30 12:35:30
小學生作文(中高年級適用)(2018年3期)2018-04-18 01:24:47
瘋狂英語·新策略(2017年8期)2017-05-31 08:13:46
華北電力大學學報(社會科學版)(2016年4期)2016-12-01 03:59:30
新聞傳播(2016年10期)2016-09-26 12:15:04
玉溪師范學院學報(2015年1期)2015-08-22 02:51:58
少兒科學周刊·少年版(2015年4期)2015-07-07 21:11:17
語文知識(2014年10期)2014-02-28 22:00:56
中學生英語高中綜合天地(2009年10期)2009-12-29 00:00:00
