YOLOv4-tiny 模型在邊緣計算平臺的加速設計
2024-01-23 07:32:38靳永強王藝鋼
物聯網技術 2024年1期
趙 洋,靳永強,王藝鋼
(沈陽化工大學,遼寧 沈陽 110142)
0 引 言
隨著各種深度學習算法在邊緣計算中的廣泛使用,多種深度神經網絡硬件部署平臺應運而生[1-4]。當前使用較為普遍的部署平臺包括:圖形處理單元(Graphics Processing Unit, GPU)、專用集成電路(Application Specific Integrated Circuit, ASIC)和現場可編程門陣列(Field Programmable Gate Array, FPGA)[5-8]。GPU 因具有優秀的計算性能,在深度學習中有著較為廣泛的應用[9-11]。優秀的計算性能是建立在不考慮功耗、算力成本、部件散熱等因素的前提條件下的,因此GPU 在深度學習的訓練過程以及云端部署中被廣泛使用。當將GPU 作為邊緣計算平臺部署深度學習模型時,功耗、成本、散熱等因素的影響使其難以應用到嵌入式端。ASIC因具備高性能和低功耗的優勢,在嵌入式系統中有廣泛的使用[12-15]。但其靈活性低、開發周期長和成本較高等方面的缺點并不適于快速迭代的卷積神經網絡。與ASIC 相比,FPGA同樣具有高性能、低功耗的優勢,而FPGA 成本較低,并且具有較強的可重構性,能夠很好地適應卷積神經網絡的快速發展,因此更適合在嵌入式領域作為深度學習網絡部署的平臺[16-18]。
FPGA 具有可重構、高性能、低功耗以及高性能產品的快速發展和更加靈活的架構設計等特點。近年來,越來越多的研究人員將注意力集中在基于FPGA 的深度學習硬件加速實現上。Yu 等[19]提出使用Winograd 快速算法,可在FPGA上實現加速卷積計算。雖然可以有效地降低片上資源的消耗,但該算法只適用于卷積核較小的卷積網絡,對卷積核較大的卷積網絡的加速效果并不明顯。梅志偉等[20]提出了一種融合乘加樹與脈動陣列的乘加陣列來加速卷積層的計算。該算法節省了硬件資源,并提高了計算性能,但對于數字信號處理單元DSP 的資源利用率并不高,并沒有充分使用硬件資源。上述研究所提出的各種方法,雖然實現了FPGA 的深度學習硬件加速的功能,但存在著不適用于卷積核較大的卷積網絡以及對片上資源利用率不高的現象。因此,針對以往在FPGA 硬件加速的過程中出現的這兩種現象,本文設計了一種基于輸入輸出通道并行組合的硬件加速器的方案。該方案中包括的標準卷積、點卷積、池化等硬件加速內核模塊(Intellectual Property, IP)均采用流水線架構,對模型參數進行參數量化處理,有效地節省片上資源,提高資源的利用率,并以YOLOv4-tiny 模型為例在FPGA 上部署實現。
1 相關理論
目標檢測在邊緣計算過程中應用十分廣泛。目前,基于深度學習應用在目標檢測領域的主流算法有:SSD、RCNN、Fast RCNN、YOLO 等模型。這些網絡的模型計算規模大、參數多、計算復雜,不適合在資源較小的硬件加速平臺部署。YOLO 模型的精簡版本YOLOv4-tiny 使用了13×13、26×26兩種尺度預測網絡對目標進行分類和回歸預測。YOLOv4-tiny 的網絡層數僅有38 層,其模型規模較小、參數量較少且檢測精度尚可,對硬件要求低,適合在硬件平臺資源較小的情況下進行部署,提高了將目標檢測方法部署在嵌入式系統或移動設備上的可行性。
1.1 YOLOv4-tiny 網絡模型
YOLOv4-tiny 的網絡結構由主干特征提取網絡CSPDarknet53-tiny 和特征金字塔網絡(Feature Pyramid Networks, FPN)兩部分組成。YOLOv4-tiny 的模型結構如圖1 所示。

圖1 YOLOv4-tiny 的模型結構
CSPDarknet53-tiny 作為主干特征提取網絡,由DarknetConv2D_BN_Leaky模塊和Resblock_Body模塊堆疊形成。其中,DarknetConv2D_BN_Leaky 模塊由二維卷積層DarknetConv2D、歸一化層BN 和激活函數LeakyReLU 三部分組成。Resblock_Body 模塊分為兩部分:一部分是模塊主干部分對殘差塊進行堆疊得到輸出Feat1;另一部分是引入較大的殘差邊,經過少量的處理后連接到Concat 模塊,對兩部分的輸出進行通道維度上的堆疊,再經過池化處理得到模塊的輸出Feat2。Resblock_Body 模塊結構如圖2 所示。
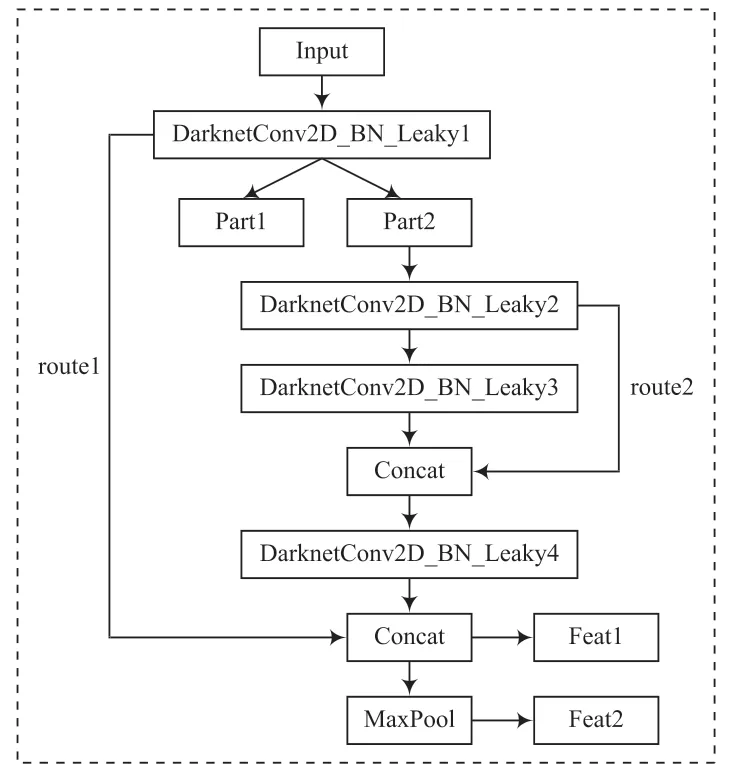
圖2 Resblock_Body 模塊結構
FPN 作為特征增強網絡,主要解決的是目標檢測中的多尺度問題,一般分兩個步驟來構建特征金字塔:(1)Feat2經過1×1point-wish 卷積處理之后得到FPN 模塊的第一個輸出P1;(2)P1 再經過1×1point-wish 卷積和上采樣處理與Feat1 在通道維度上進行堆疊,得到FPN 模塊的第二個輸出P2。最后,將得到的兩個模塊P1 和P2 進行卷積處理便可得到兩個用于邊界框預測的特征層YOLO Head1 和YOLO Head2。
1.2 ZYNQ 平臺和高層次綜合
ZYNQ 平臺是賽靈思公司推出的新一代的全可編程片上系統(All-Programmable SOC, APSOC)。相較于傳統的FPGA 平臺,ZYNQ 平臺除了傳統的可編程邏輯(Programmable Logic, PL)部件外,還包括了以ARM CorteX-A9 為核心的處理系統(Processing System, PS)。ZYNQ 平臺將ARM 處理器的軟件可編程性與FPGA 的硬件可編程性進行完美整合,使其既能夠在ARM 上部署操作系統和運行軟件程序,也能夠利用FPGA 的并行性特點對軟件中需要并行加速的部分進行加速,提高整個系統的性能;此外,也保留了嵌入式平臺的體積小、能耗低、靈活性強的特點。
高層次綜合(High-Level Synthesis, HLS)是賽靈思公司推出的FPGA 設計工具,它可以將高層次語言描述的邏輯結構轉換成寄存器傳輸級(Register-Transfer Level, RTL)的電路模型。開發者可以使用C、C++或SystemC 等高級語言對FPGA 進行系統建模,極大地提升了其工作效率,緩解了設計復雜度。當前FPGA 里有著大量成熟的、有固定功能和位置的IP 單元可以被HLS 工具充分利用,十分適合深度學習算法的快速驗證。
2 硬件系統設計
2.1 硬件架構設計
本文設計的FPGA 端的硬件架構,主要由卷積模塊、池化模塊、重排序模塊、輸入輸出緩沖區、權重緩沖區、控制器模塊以及AXI4 接口組成。其結構如圖3 所示。其中Feature Data Router 是緩沖區的數據路由邏輯。
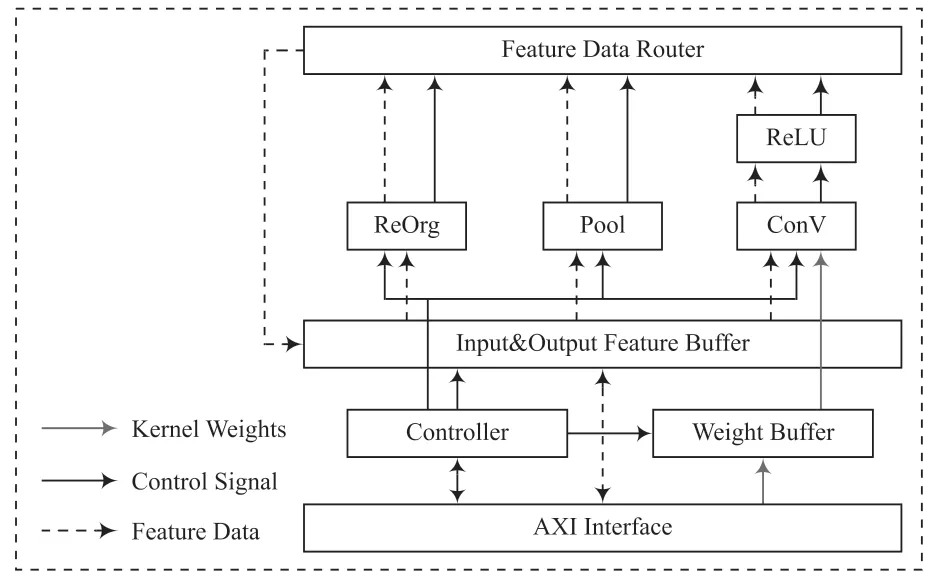
圖3 硬件架構
完成一次完整的加速過程,首先需要從外界通過AXI4接口總線向輸入緩存區讀寫輸入特征圖數據,向權重緩沖區讀寫權重數據;控制器在接收到AXI4 接口總線開始的信號后,加速器中的運算模塊被激活。加速器將根據網絡模型架構層次來順序激活各層的控制邏輯;在一層的計算被激活后,控制器通過控制信號控制讀取相應的數據,提供給運算邏輯進行對應的運算,再將運算結果通過數據路由邏輯寫入到輸出緩沖區;一層計算結束時,下一層計算被激活,依次進行;最后將計算結果和運算模塊結束信號通過AXI4 接口總線傳送到外界。
2.2 雙緩存結構
由于深度神經網絡的參數量較大,FPGA 的片內緩存空間難以將全部數據載入,因此本文通過雙緩存乒乓結構的設計,將參數分配到片外存儲器上;對圖像進行識別時,再從片外存儲器上讀取所需的數據,即構建兩塊存儲緩存區,利用流水線的方式,交替進行讀取操作,如圖4 所示。其中,t1為加速器讀取輸入數據的時間;t2為加速器獲取輸出數據的時間;t3為加速器輸出數據寫入緩存區的時間。
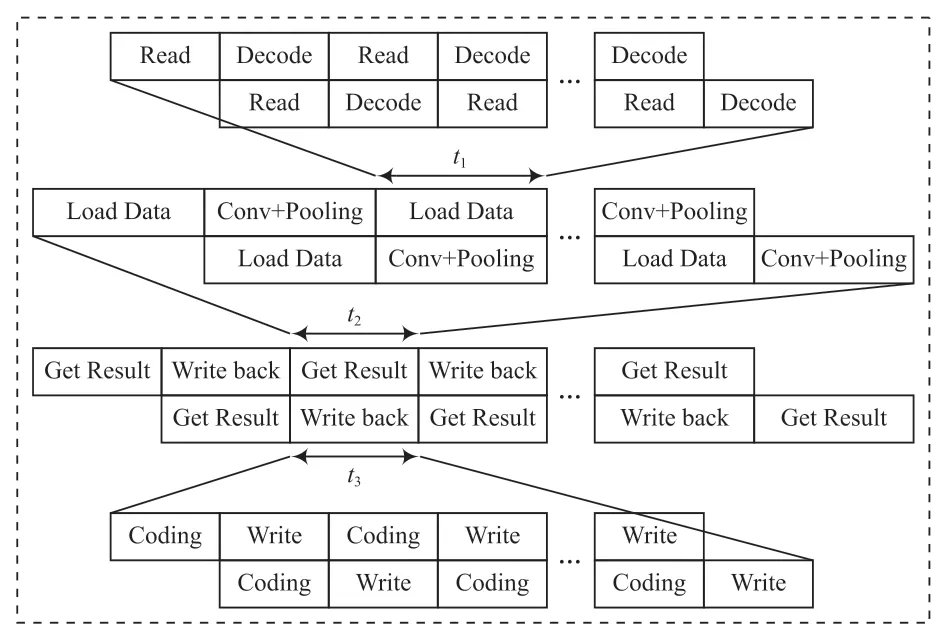
圖4 雙緩存流水結構
2.3 模塊優化與實現
目標檢測中使用的卷積神經網絡主要使用的基礎單元包括卷積單元和池化單元。將目標檢測模型YOLOv4-tiny 部署在FPGA 上的過程中,主要就是針對這兩個部分進行優化設計。
2.3.1 卷積單元設計
對模型中的卷積部分采用輸入、輸出特征圖間組合并行的策略。輸入特征圖數為Mi,輸出特征圖數為Nj,卷積核的大小為K,對輸入特征圖和輸出特征圖進行二維展開并行,單個周期內相同位置的卷積窗口需要Mi×Nj個乘積累加運算單元以及Nj個加法器,并行度為Mi×Nj。每個計算周期內,卷積模塊從存儲輸入特征圖的緩沖區讀取Mi個輸入特征值,同時讀入Mi×Nj個卷積核中特征圖相同位置的權重,進行Mi×Nj次并行乘法運算;復用Mi個輸入特征圖進行乘法運算,經過Nj個加法樹累加后得到的卷積結果,存入相對應的輸出緩存區。
卷積單元設計中大部分使用的是乘法器和加法器資源。在進行卷積運算時,運算邏輯資源的消耗與網絡選擇的數據精度密不可分。不同精度下,運算邏輯資源的消耗見表1所列。
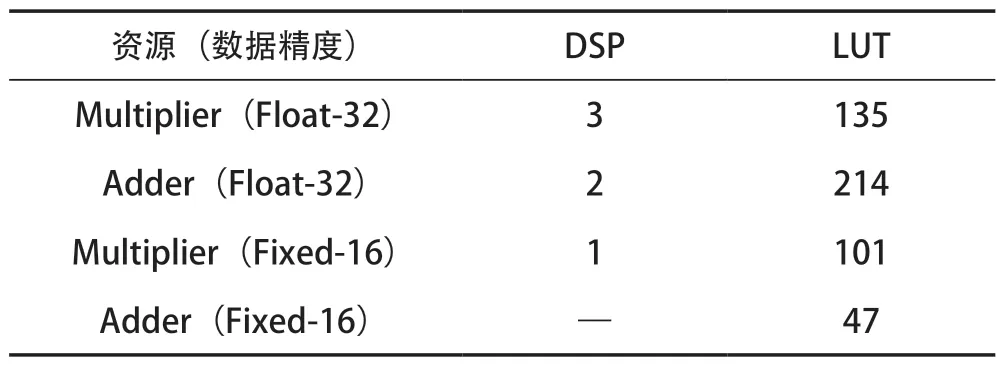
表1 資源消耗對比
2.3.2 池化單元設計
池化單元的算法原理與卷積單元類似,但池化運算單元往往負責完成單一的特征圖計算,并且使用的是比較器,而非乘法器和加法器。其原理如圖5 所示。

圖5 池化操作原理
在圖5 所示的結構中,每個時鐘周期池化單元讀取一個輸入特征圖數據并與比較器中的寄存器值進行比較,再將比較的最大值存入寄存器中。在YOLOv4-tiny 算法中池化層的大小和步長都為2,即K=S=2,經過K2個周期后得到池化結果,將結果寫入輸出緩存區中。考慮到池化單元消耗的資源較少,在此不再過多敘述。
3 實驗驗證與評估
3.1 實驗環境
本實驗使用的是Xilinx PYNQ-Z2 開發板(ARM 雙核Cortex-A9+FPGA),主芯片為ZYNQ XC7Z020-1CLG400C,其中FPGA 上DSP、LUT、BRAM_18K 和FF 的可用資源數分別為220、53 200、280 和106 400。此外,板上還包括一個ARM 雙核處理器和一個大小為512 MB 的DDR3 內存。采用的神經網絡模型是YOLOv4-tiny,數據集為VOC 數據集。使用Vivado HLS 2019.2 進行卷積運算單元和池化運算單元的設計,并生成對應的IP 核,使用Vivado 2019.2 進行綜合布局布線。
3.2 系統實現
本文采用軟硬件協同的方式對YOLOv4-tiny 網絡模型進行加速設計,整個加速系統如圖6 所示,分為PS(Processor System)和PL(Programming Logic)兩部分。PS 端的ARM處理器主要負責對整個執行流程的控制,包括數據預處理、配置模型參數和初始化加速系統。PL 端的FPGA 邏輯資源主要用于卷積、池化等的運算。DDR 為片外存儲器、Block_RAM 為片上存儲器,PS 和PL 通過AXI 總線接口進行交互。
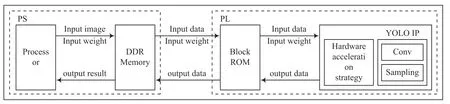
圖6 系統架構示意圖
輸入數據流經過PS 端的預處理,將待輸入特征圖和權重參數存入片外存儲器DDR 上,PL 端通過AXI 總線從片外存儲器DDR 讀取數據至片上存儲器Block_RAM 后,將數據輸入到硬件加速模塊,進行卷積、池化運算,計算完成后將結果返回給Block_RAM,繼續返回給DDR 作為下一層網絡的輸入或結果輸出。
3.3 資源評估與性能評估
使用Vivado2019.2 進行綜合布局布線后,其給出的資源消耗情況見表2 所列。其中,DSP 主要用于卷積、池化運算模塊中乘法器和加法器的設計,使用率為99.09%;其他運算邏輯和控制邏輯均使用LUT,使用率為76.26%;BRAM_18k 主要用于輸入輸出緩沖區和權重值較大的權重緩沖區,使用率為68.57%;對于權重值較小的權重緩沖區不適合使用BRAM,而是使用LUTRAM 資源來存儲,使用率為40.78%;寄存器FF 的使用率為47.22%。
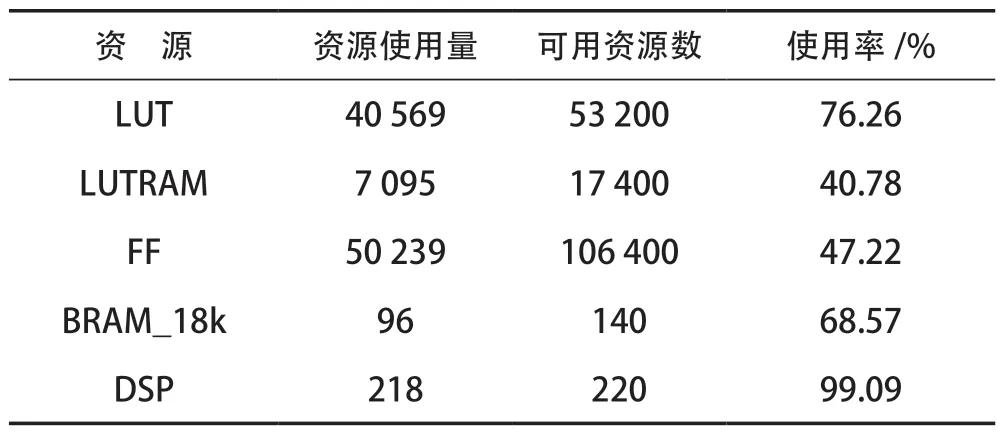
表2 FPGA 資源消耗情況
將本文設計與其他平臺實現的加速效果進行比較,見表3所列。文獻[21]設計的YOLOv2-tiny 加速器,將卷積和池化操作相結合,減少加速器的片外訪存時間,功率為11.8 W,是本文加速器功率的3.96 倍。文獻[22]中是針對YOLOv3-tiny 設計的一種可配置的硬件加速器,使用的是Ultrascale+XCKU040 平臺,其可用資源數是本文使用平臺的8 倍,但其消耗的片上資源是本設計的3.89 倍。
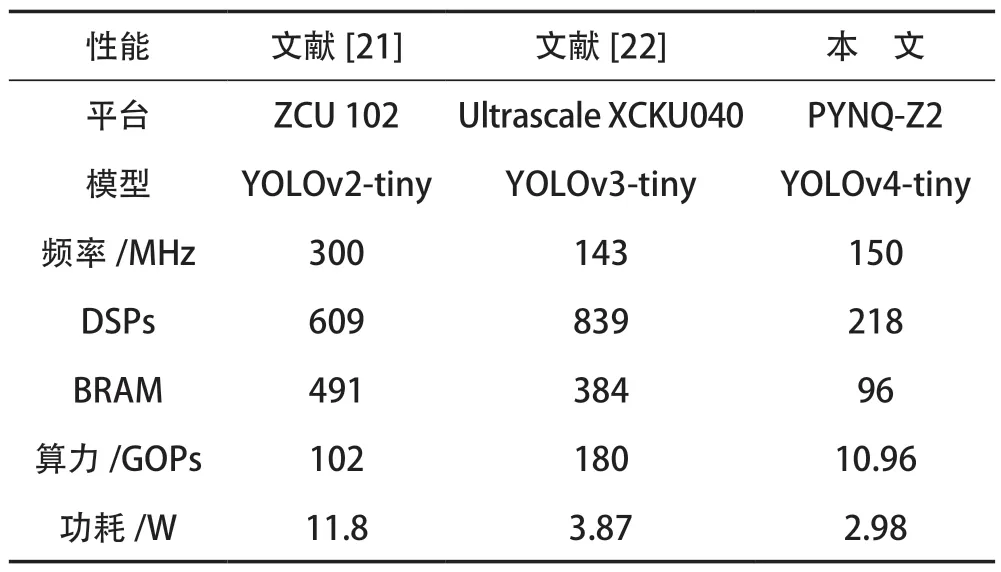
表3 與其他FPGA 平臺加速器設計的比較
4 結 語
本文從網絡模型參數和結構方面進行分析,對YOLOv4-tiny 模型進行硬件加速設計,對參數進行了16 位定點量化處理,使用了卷積輸入輸出并行組合策略進行加速。此外,使用乒乓雙緩存機制,提高帶寬利用率,減少傳輸時延;并在PYNQ-Z2 平臺上進行板級驗證,經過對資源、性能等方面的綜合評估,該加速器的功耗為2.98 W,有效算力達到10.96 GOPs。與已有文獻中提及的在FPGA 部署深度學習算法的實驗結果進行比較發現,本文設計的深度學習模型在邊緣計算平臺上的加速設計方案檢測精度最高、反應時間最短、檢測效率最優。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
數學物理學報(2020年2期)2020-06-02 11:29:24
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
藝術啟蒙(2018年7期)2018-08-23 09:14:18
海峽姐妹(2017年7期)2017-07-31 19:08:17
Coco薇(2017年5期)2017-06-05 08:53:16
資源再生(2017年3期)2017-06-01 12:20:59
