基于孤立森林的城軌車輛空轉滑行異常檢測方法研究
2024-01-16 10:13:56陳美霞梁師嵩胡佳喬
鐵道機車車輛 2023年6期
陳美霞,梁師嵩,胡佳喬
(中車南京浦鎮車輛有限公司,南京 210031)
在城軌列車運行中,列車牽引力通過輪軌滾動接觸界面上的黏著與蠕滑來傳遞,輪軌間的黏著—蠕滑特性直接影響列車牽引和制動性能。車輪在原地轉動沒有前進的現象稱為空轉,而車輪在鋼軌上只有滑動沒有滾動的現象則稱為滑行[1]。空轉會導致輪軌擦傷,而嚴重的擦傷往往是鋼軌疲勞失效的重要原因之一。滑行會形成車輪擦傷,車輪擦傷不僅會使列車運行時車輛/軌道產生強烈振動,還會導致車輪軸承、車軸和軌道的損傷,影響行車安全,增加維修費用;此外,車輪踏面擦傷還會造成輪軌黏著性能進一步降低。
目前城軌列車均已采取一系列的措施應對空轉滑行問題,比如噴沙、降低牽引力、制動壓力修正等方法[2-8],雖有一定的效果,但空轉滑行現象始終難以完全避免,特別是位于進出站區段站臺區域,車輛啟停、軌面污染等都會導致空轉/滑行問題更加突出。
輕微的空轉/滑行現象對于列車運行沒有太大影響和安全隱患,經過常規的日常檢修即可處理,但較為嚴重的空轉/滑行現象可能需要及時識別出來并對其進行緊急處理。較為嚴重的空轉/滑行現象在列車運行中即可視為異常,文中的目的就是識別出此類異常。因為空轉/滑行和列車速度、負載、駕駛模式、路段等息息相關,不適合使用單一的標準進行判斷。所以文中針對該問題,提出了一種基于孤立森林的異常檢測方法。通過對空轉/滑行的次數進行監測、統計、分析,并對之建模,進而判斷列車或軌道是否存在潛在風險。空轉/滑行是列車軸速變化的體現,當列車在低黏著條件下制動或牽引運行時,系統將檢測到空轉或者滑行,如短時間內次數異常,則可推測黏著條件較差或者速度傳感器故障,存在擦輪、冒進、抱死或牽引變流器故障風險。
1 孤立森林算法介紹
孤立森林(Isolation Forest)算法因其具有易于理解、開銷小、時間復雜度低等特點,所以采用孤立森林來實現空轉/滑行的異常檢測。孤立森林算法的步驟如下[9-11]:
(1)首先要獲取原始數據集,集中的數據都具有共同的多維特征。
(2)設置樣本集大小n和孤立樹的數量m。構建一棵孤立樹需要從原始數據集抽樣出n個數據,作為這棵孤立樹的樣本數據集。
(3)在樣本數據集中,隨機選擇數據的一個特征,并算出樣本集的數據在此特征上的所有值范圍,在這個范圍中隨機選一個值,根據這個特征值對樣本集進行劃分,將樣本中特征值小于該值的數據劃分到節點的左子節點,特征值大于該值的數據劃分到節點的右子節點。
(4)分別在左右2 個子節點的數據集上重復第3 步的過程,不斷隨機選擇特征進行劃分,直到子節點上只有1 個節點無法再分或者節點達到了樹的最大深度。
(5)構建好孤立樹后,需要計算每個數據在孤立樹上的路徑長度。計算方法以遍歷二叉搜索樹的方式從孤立樹中搜索每個數據,在孤立樹中根據節點的分支條件不斷向下搜索,每向下一次則路徑長度加1。最后找到數據點后,返回路徑長度記為h(x)。
(6)計算待測數據在孤立森林中的平均路徑長度,然后帶入公式計算出異常指數,計算公式為式(1)~式(3):
式中:E(h(x))為數據x在所有樹中的路程長度均值;c(n)為n個點構建的二叉搜索樹的平均路徑長度;ξ為歐拉常數;S(x,n)中x為數據編號,n為樣本集大小,S為數據x在由n個數據的樣本集構成的孤立樹中的異常指數。S(x,n)的值與E(h(x))相關,E(h(x))越小,說明數據越早被孤立出來,則S值越大,表示該數據異常程度越高,反之S值越小則異常程度越低。S的取值范圍為[0,1],在正常情況下,數據集中正常數據的異常指數都會在0.5 左右。
2 異常檢測方案設計
2.1 總體方案
首先通過數據探索性分析,了解已知數據,探索變量間的相互關系,以此確定與上述背景技術中提出的問題密切相關的參數;然后針對這一系列參數進行數據預處理,完成模型特征構建;接著將構建好的特征參數輸入模型,進行模型構建調參;最后將實時數據經過預處理后持續輸入已構建好的模型,開始在線運行,以此實現列車當前空轉和滑行次數的異常檢測。總體方案如圖1所示。
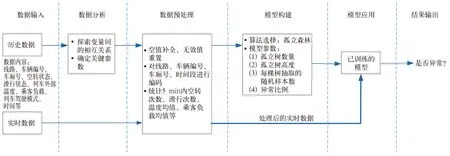
圖1 總體方案
2.2 數據探索分析
模型相關的特征數據一般分為類別特征數據和數字特征數據,對于類別特征數據,可做以下分析:類別特征箱形圖可視化、類別特征的小提琴圖可視化、類別特征的柱形圖可視化類別、特征類別頻數可視化等。
對于數字特征數據,可做以下分析:相關性分析、特征值分布偏度和峰值、數字特征的分布可視化、數字特征相互之間的關系可視化、多變量互相回歸關系可視化等。
2.3 數據預處理
數據預處理分3 步:空值、異常值處理,模型特征構造,數據降維。
(1)空值、異常值處理:空值是指某一條數據缺失某些參數數值,如果缺失參數數量不多且影響不大可不處理;如果缺失數據太多,選擇刪除;如果缺失參數不多且重要,可采用插值補全方法處理,包括采用均值、中位數、眾數等補充。異常值是指數據格式錯誤或者明顯超出參數數值合理范圍的數據,該部分數據同樣可采用刪除或者清空后補全的方法進行處理。
(2)模型特征構造:構造統計特征,例如均值、求和、比例、標準差等;構造時間特征,包括相對時間和絕對時間,工作日、雙休日、節假日等;構造地理信息特征,包括坐標區域、分布編碼等;特征非線性變換,包括取對數log、平方、開平方根等;通過特征組合、特征交叉構造新特征。
(3)數據降維:如果需要,可采用主成分分析(PCA)、獨立成分分析(ICA)、線性判別分析(LDA)等方法降維。
文中輸入數據空值、異常值較少,主要采取刪除和補全的方式進行處理。特征構造如下:
線路(編碼)
車輛編號(編碼)
時間段(按5 min 進行時間切片,然后編碼)
各時間段內牽引檢測滑行次數
各時間段內制動檢測滑行次數
各時間段內乘客負載均值
各時間段內乘客負載峰值
各時間段內列車速度均值
各時間段內列車速度峰值
各時間段內列車速度峰值/均值
實際的工作中,地質工程投資時非常復雜的,會受到多方面因素影響,上述安全投資模型是在特定條件下建立的,和地質工程實際情況具有一定的差距。但是實際工作中我們能夠以這一模型作為借鑒,從而提升投資的科學有效性,降低其風險。比如,地質工程成本中包含有形成本和無形成本,如事故發生后引發的執政危機,因此,政府相關部門會強制性的要求相關企業在左右決策點的右部進行投資,以便于進一步確保工程的安全性。
所用特征數據維度較小,不進行降維處理。
2.4 模型構建
空轉/滑行異常檢測模型構建流程如圖2所示。
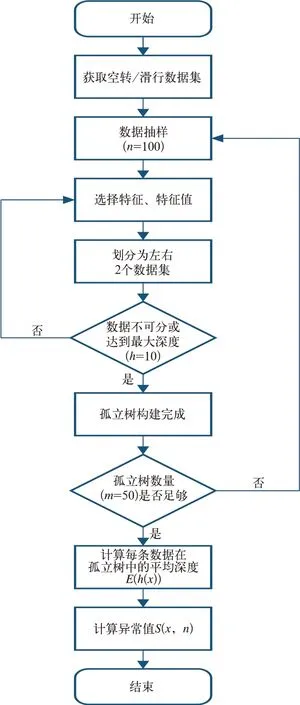
圖2 空轉/滑行模型構建流程圖
文中算法相關參數經過調參之后設置如下:孤立樹數量=50,孤立樹最大深度=10,每棵樹訓練樣本數量=100,異常比例=0.005。模型構建以及調參完成之后,利用Python 中joblib 軟件包保存到本地備用。
2.5 模型應用
模型應用步驟如下:
(1)首先通過Python 中joblib 軟件包加載上一步中已構建完成的模型。
(2)接收實時數據,數據預處理。
(3)將處理好的數據輸入到已加載的模型。
(4)根據模型輸出判斷輸入數據的異常與否。
(5)將結果反饋至上一層應用系統。
3 實施案例
以下將以南京—寧溧線車輛為例,描述整個方案的實施過程,模型相關參數均可根據不同應用場景和需求進行調整。南京—寧溧線目前有T0~T11 總共12 輛車在線運行,其中針對每一輛車的實施方案均一致,下面以T4 為例進行說明。
3.1 數據探索分析
從空轉/滑行產生的基本原理可以推導出與之相關的關鍵參數主要有車輛載重、駕駛模式、車輛速度、軌面溫濕度等,抽取T4 車輛某年7 月11日0 點至7 月12 日0 點的運行數據進行展示,如圖3、圖4 所示。可以發現,車輛載重、車輛駕駛模式、車輛速度變化情況基本一致,每個站點附近速度會產相應生變化,車輛各軸的載重也會因為乘客上下車發生波動,根據站點ID 變化情況可以看出每跑完一遍線路駕駛模式會有短暫的變化。而空轉/滑行發生時間的附近,以上各參數均有相應的變化。
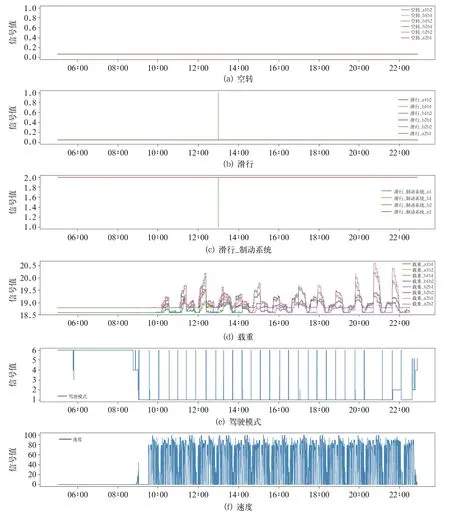
圖3 南京寧溧線T4 車運行參數變化情況
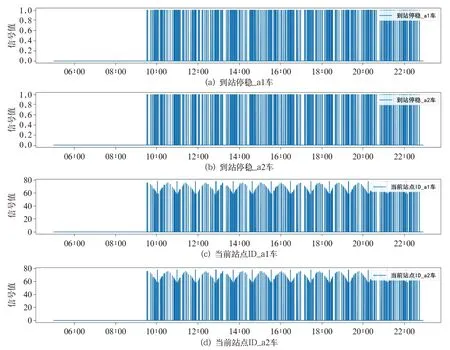
圖4 南京寧溧線T4 車運行站點停穩信息變化情況
進一步將數據按5 min的時間長度進行切分統計,T4 車 某年7 月11 日10 點~11 點相 關參數 統計信息如圖5、圖6 所示。可以看出,滑行事件主要發生在10∶00∶00 至10∶05∶00 之間,這個區間發生滑行的車廂轉向架載重均值、載重峰值均較大。而該時間段內,在速度峰值較高的情況下,平均速度卻很小,說明該區間內存在較大減速操作。綜上可知,載重均值、載重峰值、速度均值、速度峰值、速度峰值均值比均與空轉/滑行有一定的關聯。
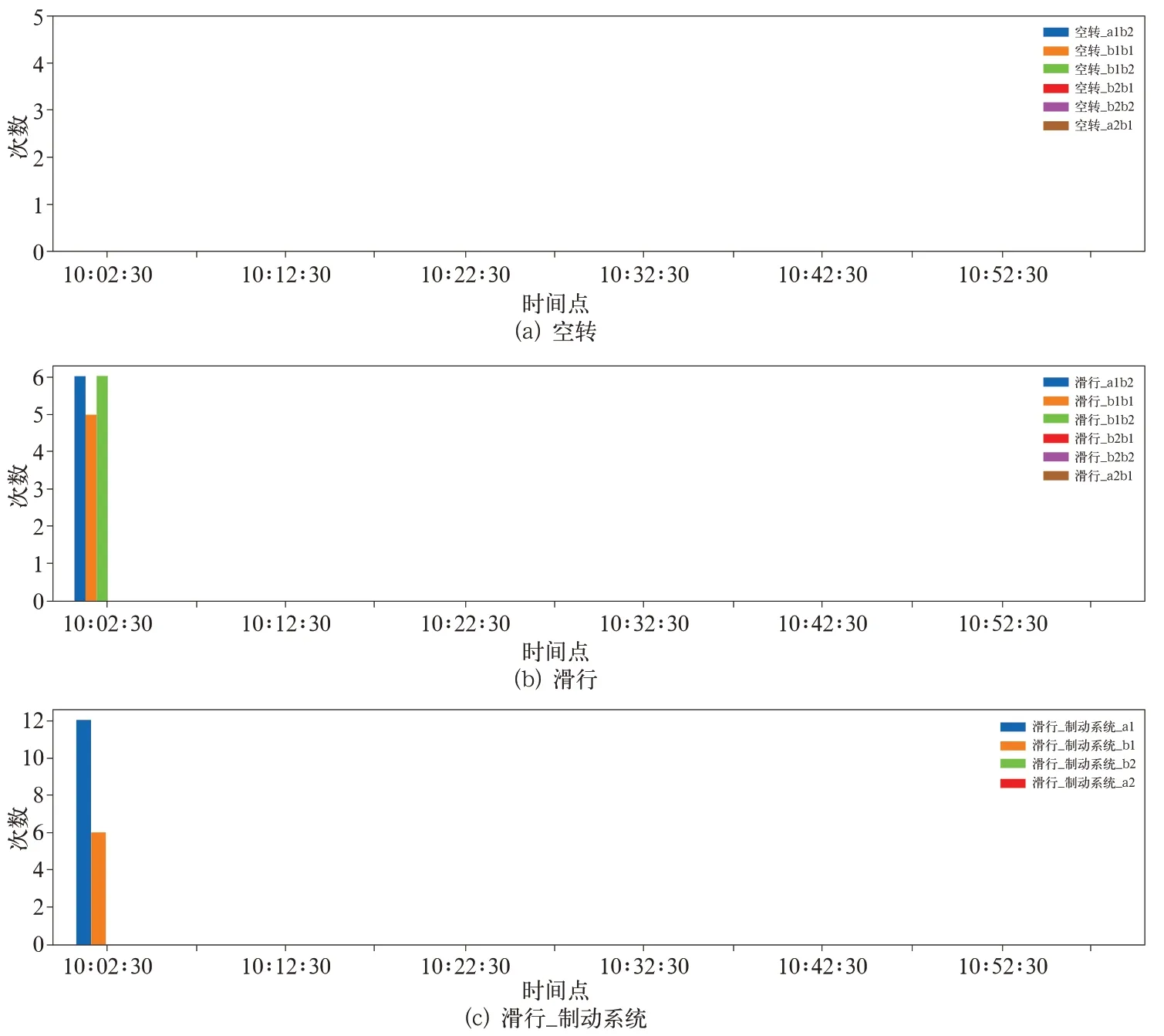
圖5 南京寧溧線T4 車空轉/滑行統計(7-11 10:00~ 7-11 11:00)
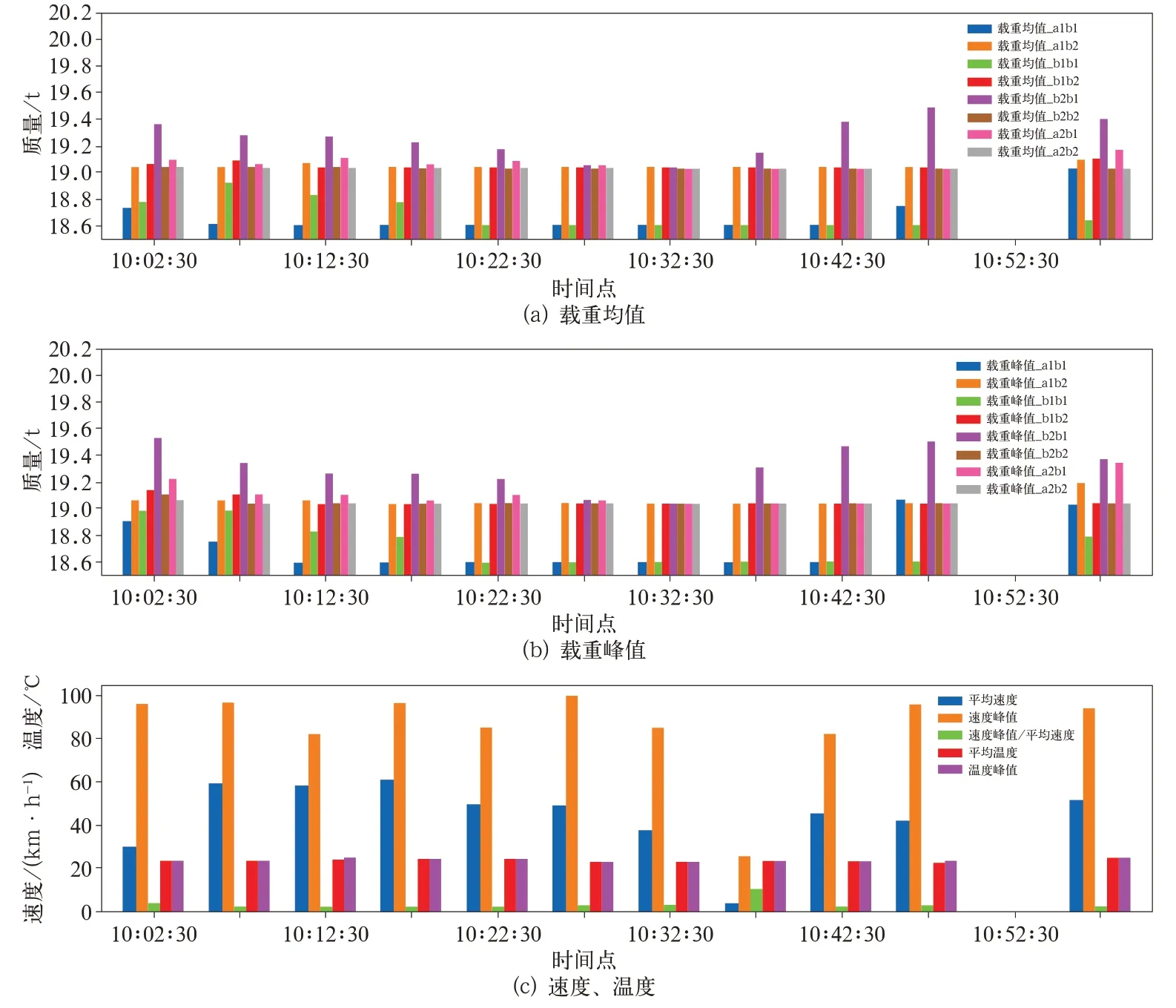
圖6 南京寧溧線T4 車載重及速度信息統計(7-11 10:00~ 7-11 11:00)
3.2 數據預處理
在上述數據探索分析過程中發現有部分時間數據缺失,主要采取刪除的方式處理,重要數據采取補全措施。
根據數據探索分析結果,主要特征構造如下:
5 min 內A1 車B2 架空轉次數
5 min 內B1 車B1 架空轉次數
5 min 內B1 車B2 架空轉次數
5 min 內B2 車B1 架空轉次數
5 min 內B2 車B2 架空轉次數
5 min 內A2 車B1 架空轉次數
5 min 內牽引檢測A1 車B2 架滑行次數
5 min 內牽引檢測B1 車B1 架滑行次數
5 min 內牽引檢測B1 車B2 架滑行次數
5 min 內牽引檢測B2 車B1 架滑行次數
5 min 內牽引檢測B2 車B2 架滑行次數
5 min 內牽引檢測A2 車B1 架滑行次數
5 min 內制動檢測A1 車滑行次數
5 min 內制動檢測B1 車滑行次數
5 min 內制動檢測B2 車滑行次數
5 min 內制動檢測A2 車滑行次數
5 min 內乘客負載均值
5 min 內乘客負載峰值
5 min 內列車速度均值
5 min 內列車速度峰值
5 min 內列車速度峰值/均值
3.3 模型構建
首先通過數據預處理步驟準備好模型訓練數據,文中選取南京—寧溧線T4 車某年7 月11 日0點至7 月12 日0 點數據作為訓練數據,按5 min的時間長度進行切片,然后按照上一步進行處理,最后獲取288 條訓練數據。
模型算法孤立森林相關參數經過調參之后設置如下:孤立樹數量=50,孤立樹最大深度=10,每棵樹訓練樣本數量=100,異常比例=0.005。將訓練數據輸入模型,開始訓練。待模型訓練完成之后,利用模型分辨訓練數據中的異常數據,得到1條與實際情況一致的異常數據:
[ 0,0,0,0,0,0,6,5,6,0,0,0,12,6,0,0,……]
以上數據對應字段含義依次為:
5 min 內A1 車B2 架空轉次數
5 min 內B1 車B1 架空轉次數
5 min 內B1 車B2 架空轉次數
5 min 內B2 車B1 架空轉次數
5 min 內B2 車B2 架空轉次數
5 min 內A2 車B1 架空轉次數
5 min 內牽引檢測A1 車B2 架滑行次數
5 min 內牽引檢測B1 車B1 架滑行次數
5 min 內牽引檢測B1 車B2 架滑行次數
5 min 內牽引檢測B2 車B1 架滑行次數
5 min 內牽引檢測B2 車B2 架滑行次數
5 min 內牽引檢測A2 車B1 架滑行次數
5 min 內制動檢測A1 車滑行次數
5 min 內制動檢測B1 車滑行次數
5 min 內制動檢測B2 車滑行次數
5 min 內制動檢測A2 車滑行次數
模型構建完成之后,利用Python 中joblib 軟件包保存為本地文件備用。
3.4 模型應用
首先采用Python 腳本加載上一步驟中保存下來的模型文件,然后將實時數據按照第2 步驟中的方法進行預處理,隨后輸入模型,通過模型的predict 方法獲取模型判斷結果,最后將模型結果以及相關數據一同反饋至上一層應用系統。
采用南京寧—溧線T4 車某年7 月12 日0 點至7 月20 日0 點數據模擬實時數據輸入模型,得到2條與實際情況一致的異常數據:
[ 0,0,0,3,3,0,0,0,0,0,0,0,0,0,0,0,……]
[12,23,15,16,21,27,0,0,0,0,0,0,0,0,0,0,……]
前6 項分別為:
5 min 內A1 車B2 架空轉次數
5 min 內B1 車B1 架空轉次數
5 min 內B1 車B2 架空轉次數
5 min 內B2 車B1 架空轉次數
5 min 內B2 車B2 架空轉次數
5 min 內A2 車B1 架空轉次數
4 結論
空轉/滑行異常難以準確檢測的問題,文中提出基于孤立森林的檢測方法可以很好地解決。從實施案例可以看出,對于車輛空轉/滑行異常的識別達到了預期的效果。后續計劃進一步優化算法,收集更多的訓練數據(包括正常和異常數據),以達到更加精確的判斷結果。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
