基于多源數據聚合的神經網絡側信道攻擊
2024-01-12 06:54:00張潤蓮潘兆軒李金林武小年韋永壯
計算機研究與發展 2024年1期
關鍵詞:模型
張潤蓮 潘兆軒 李金林 武小年 韋永壯
(密碼學與信息安全重點實驗室(桂林電子科技大學) 廣西桂林 541004)
(zhangrl@guet.edu.cn)
側信道攻擊通過對密碼算法在設備實際運行過程中泄露的物理信息(如時間信息、能量信息、電磁信息)進行采集和分析,從而恢復密鑰信息[1]. 側信道攻擊實用性強且破壞性大,嚴重威脅著密碼設備的安全,是近年來密碼分析的一個研究熱點. 隨著密碼設備功能的完善以及新防護手段的應用,傳統側信道攻擊的效率和成功率越來越低. 為提高側信道攻擊的效率和成功率,深度學習被引入側信道攻擊.
深度學習具有學習能力強、覆蓋范圍廣、適應性好等優點. 基于密碼設備運行過程中采集的數據,深度學習可以在一定程度上學習和提取密碼算法在設備中進行數據加密時的特征信息,實現對密碼算法的密鑰恢復[2-4]. 2016 年,Maghrebi 等人[5]將深度學習用于AES(advanced encryption standard)算法在無掩碼和有掩碼情況下的攻擊,證明基于深度學習的側信道攻擊具有更好的攻擊效果. 2017 年,Cagli 等人[6]基于卷積神經網絡實現在不需要對能量跡對齊和精確特征點提取的情況下的攻擊. 2020 年,Benadjila 等人[7]提出基于ASCAD 數據集的最優神經網絡模型,并通過實驗證明神經網絡模型的攻擊效果優于被優化的模板攻擊;Wang 等人[8]提出基于聯邦學習的側信道攻擊,使用9 個同型號的不同設備采集數據進行聯合訓練,并成功完成攻擊;Perin 等人[9]分析了基于深度學習的側信道分析模型的泛化能力并以集成技術增強模型的攻擊能力. 2021 年,Won 等人[10]提出將1 維數據的原始能量跡的測量值轉化為具有數據位置信息的2 維數據,改進了基于深度學習的側信道分析;Zaid 等人[11]則為了減少深度學習衡量指標與側信道評估指標的差異,提出一種排名損失函數并論證了成功攻擊所需的能量跡上界.
基于深度學習的側信道分析,目前普遍的方法是針對采集的能量跡,基于每個密鑰字節對應的泄露數據建模,再恢復該密鑰字節. 例如,針對AES-128 算法,基于深度學習的側信道分析將128 b 密鑰以每組8 b 劃分為16 個密鑰字節,為了恢復16 個正確密鑰需要分別對每個密鑰字節建模再進行恢復[12].深度學習高度依賴數據,數據量越大,其學習效果越好. 因此,為提高攻擊的準確率,上述方式需要采集大量數據且單獨訓練16 個模型,效率較低. 而對側信道攻擊來說,數據采集由于外部因素的限制,攻擊者可能無法采集到足夠的數據,而數據不足會嚴重影響神經網絡的訓練效果. 如何在數據采集要求無法被滿足的情況下,提高深度學習側信道攻擊的效率和準確率,成為開展深度學習側信道攻擊的關鍵. 針對該問題,數據增強技術被使用. 2020 年,王愷等人[12]通過對原始功耗曲線增加抖動和高斯噪聲實現數據增強,并將增強后的數據用于殘差網絡訓練實現密鑰恢復;同年,Wang 等人[13]將條件生成對抗網絡(conditional generative adversarial network,CGAN)用于側信道領域,通過條件生成對抗網絡生成新的數據集進行訓練數據集的擴充,從而提高能量跡不足情況下的攻擊效率. 2021 年,Luo 等人[14]和Karim 等人[15]運用Mixup技術[16]生成能量跡,增加模型攻擊效果.然而,數據增強方法需要先訓練網絡生成所需能量跡,增加了側信道攻擊中數據訓練的復雜性.
針對上述問題,提出一種基于多源數據聚合的神經網絡側信道攻擊方法,以AES-128 算法為攻擊對象,先基于16 個密鑰字節的泄露數據訓練16 個模型,并分別實現對相應16 個密鑰字節的恢復;進一步以每個模型分別恢復其他的密鑰字節,了解每個模型在特征學習過程中的泛化效果;針對每個模型對所有密鑰字節的攻擊效果打分并排序,篩選出對所有密鑰字節攻擊效果好的模型所對應的泄露數據,構建和訓練一個基于多密鑰字節泄露數據的多源數據聚合模型,再恢復所有的密鑰字節. 實驗結果表明,該方法在較少能量跡情況下不需要數據增強處理也能夠提高側信道攻擊的準確率,降低了模型訓練的開銷,減少了成功恢復密鑰所需要的能量跡數量.
1 MLP 神經網絡簡介
多層感知器(multi-layer perceptron, MLP)是一種由多個感知器單元組成的神經網絡,包括輸入層、輸出層和1 個或多個隱藏層,每一層包含1 個或多個感知器單元,每一層的所有感知器與下一層的所有感知器進行全連接,MLP 的結構如圖1 所示.
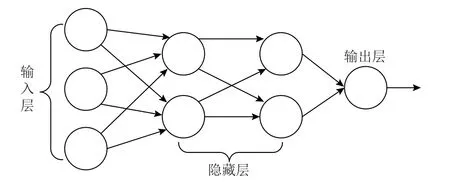
Fig.1 The structure of MLP圖1 MLP 結構
MLP 網絡模型的核心思想是通過前向傳播得到誤差,再把誤差通過反向傳播實現權重的修正,最終得到最優模型. 在反向傳播過程中通常使用隨機梯度下降法對權重值進行修正,梯度下降法的原理是計算損失函數關于所有內部變量的梯度,并進行反向傳播.
2 多源數據聚合模型
目前采用神經網絡針對AES 算法的側信道分析,主要利用采集的能量跡分別為每一個密鑰字節在第1 輪S 盒處的泄露點進行建模,再恢復該密鑰字節,如對AES-128 算法需要建立和訓練16 個模型. 這種方法需要采集大量的數據進行訓練,能量跡采集和訓練開銷大、效率低;若采集的能量跡不足,會導致模型的準確率低. 針對上述問題,提出基于多源數據聚合的模型構建方法,針對AES-128 算法篩選出對各個密鑰字節攻擊效果較好的數據集建立多源數據聚合模型,再進行密鑰恢復.
2.1 基于單密鑰字節的泄露數據集建模
在AES-128 算法加密過程中,16 個密鑰字節加密明文的操作是一個時序操作,所有的泄露都在采集的一條能量跡中. 在整個時序中,由于每個密鑰字節在加密不同明文時所泄露的能量信息具有相同特征,因此在采用深度學習方法進行側信道分析時,通常是對單個密鑰字節的泄露數據建模,在攻擊階段根據訓練結果恢復出對應字節的密鑰.
在傳統側信道攻擊中,通常使用能量消耗模型模擬真實情況下泄露的能量消耗. 能量消耗模型有不同的精度級別,一般而言,精度越高的模型攻擊效果越好,但所需要的資源也越多. 漢明重量模型是攻擊者刻畫總線與寄存器能量消耗常用的能量消耗模型,它的基本原理是假設能量消耗與寄存器中存儲數據比特1 的數目成正比. 而密碼設備S 盒置換的非線性操作在寄存器中引發的能量變化較為突出,因此主要針對S 盒的輸出通過能量消耗模型尋找相關特征.
能量跡的特征依賴于密鑰與明文,理論上針對單密鑰字節所建立的模型并以其恢復對應密鑰字節的效果是最佳的. 模型的建立需要先對采用的數據集進行數據處理,即完成數據標簽. 數據的標簽實際上是將每條能量跡的特征通過能量消耗模型重新刻畫,即將每條能量跡的分類類別由明文和密鑰轉化為標簽值函數計算后的標簽值. 假設一條能量跡中某S 盒泄露點x的明文數據為p,該單密鑰字節為k,假設采用漢明重量函數HW( )計算,則標簽值z計算方法為
對于其他能量跡,同樣在該泄露位置x計算對應的標簽值z,完成對所有能量跡在泄露點x的標簽. 采用同樣的方法,繼續針對所有能量跡的其他泄露點完成數據標簽. 以所有能量跡在某個泄露點標簽后的數據,訓練建立一個單密鑰字節模型,并以該模型恢復該泄露點對應的密鑰字節.
AES-128 算法中,使用了16 個S 盒,但這16 個S盒的真值表是相同的. 這使得基于這16 個S 盒進行運算后的數據間可能存在一定的關聯性,即所采集的能量跡不同泄露點的數據可能會表現出相似的特征. 對能量跡的標簽計算,也會將這些相似特征表現出來,即在對這些能量跡進行標簽時,通過標簽值函數f(p,k)標簽,不同泄露點的標簽結果也可能會被歸于同一類. 基于這種特征,以某個泄露點訓練的模型,若能夠有效恢復出其他泄露點對應的密鑰字節,則可以有效降低能量跡采集和模型訓練的開銷.
為評估以某個泄露點訓練的模型恢復其他泄露點對應密鑰字節,針對AES-128 算法,先采集算法運行時的能量跡,再將其劃分為16 個密鑰字節的泄露數據集,進行數據標簽處理,以這16 個密鑰字節的數據集分別訓練出16 個模型. 進一步地,利用這16個模型,先分別恢復該泄露數據集對應的密鑰字節,再分別去恢復其他密鑰字節.
采用Benadjila 等人[7]于2020 年對ASCAD 數據集提出的MLP-best 模型建立MLP 神經網絡模型,MLP 模型一共有6 層,第1 層為輸入層,其是大小為96 的1 維向量,輸入層神經元數對應單個密鑰字節在S 盒操作處的96 個能量采樣點數據. 中間4 層為隱藏層,每層隱藏層都有200 個神經元;為了在快速收斂的同時避免梯度消失并提高網絡的精度,激活函數采用RELU 函數. 最后一層是輸出層,其大小與實驗選擇的能量消耗模型有關. ASCAD 公開數據集只提供第3 個S 盒處的泄露數據,本文方法需分析AES 算法的16 個S 盒的所有泄露數據,在此選用提供了全部字節泄露的DPAContest_V4 數據集. MLPbest 在ASCAD 數據集上有局部最優效果,但并不適用于采用RSM(rotating S-box masking)掩碼方案[17]的DPAContest_V4 數據集[18]. 針對DPAContest_V4 數據集,構造新的標簽值函數計算標簽值:
將標簽值f′(p,k)作為不同明文對應能量跡的標簽值時,根據AES 的S 盒輸入異或輸出共163 種異或結果,因此輸出層設置為163 個神經元,對應163種不同標簽值的分類結果. 為提高分類的準確率,輸出層的激活函數選擇適用于多分類場景下的Softmax 函數,以將輸出映射為各個類別的分類概率.
基于上述建立的模型,利用AES-128 算法16 個密鑰字節的標簽好的數據集訓練出16 個模型,分別命名為Mi(i=1,2,…,16). 為區分不同密鑰字節的標簽數據集,以Sj(j=1,2,…,16)表示依據S 盒操作順序并完成標簽的數據集. DPAContest_V4 數據集中每個數據集Sj分別有10 000 條能量跡,從中隨機抽取8 000條作為訓練集訓練神經網絡模型Mi,剩下的2 000 條作為測試集用以恢復對應密鑰字節. 為保證效果一致,在每個模型訓練過程中統一設置相關參數:訓練的epoch=300,batchsize=100,學習率設為0.000 01,優化器使用RMSprop,使用交叉熵損失函數.
基于上述建立的16 個模型,利用相應的測試集數據分別去恢復16 個密鑰字節,各個模型恢復對應密鑰字節所用的最少能量跡數如表1 所示.
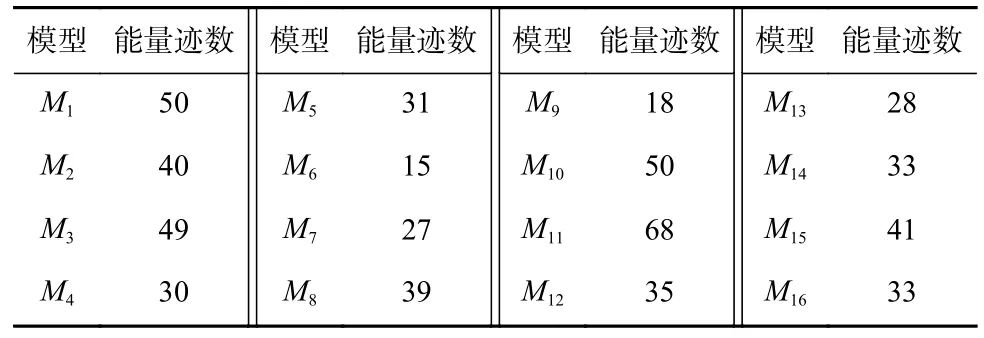
Table 1 Minimum Number of Traces for Sixteen Models Recovering the Corresponding Key Byte表1 16 個模型恢復對應密鑰字節的最少能量跡數
進一步地,為評估以某個泄露點訓練的模型是否能夠恢復其他泄露點對應密鑰字節,基于同樣的實驗環境,利用這16 個模型中的每一個模型,分別以每個密鑰字節對應的測試集數據去恢復相應的密鑰字節,各模型完成對各密鑰字節恢復的最少能量跡數如表2 所示.
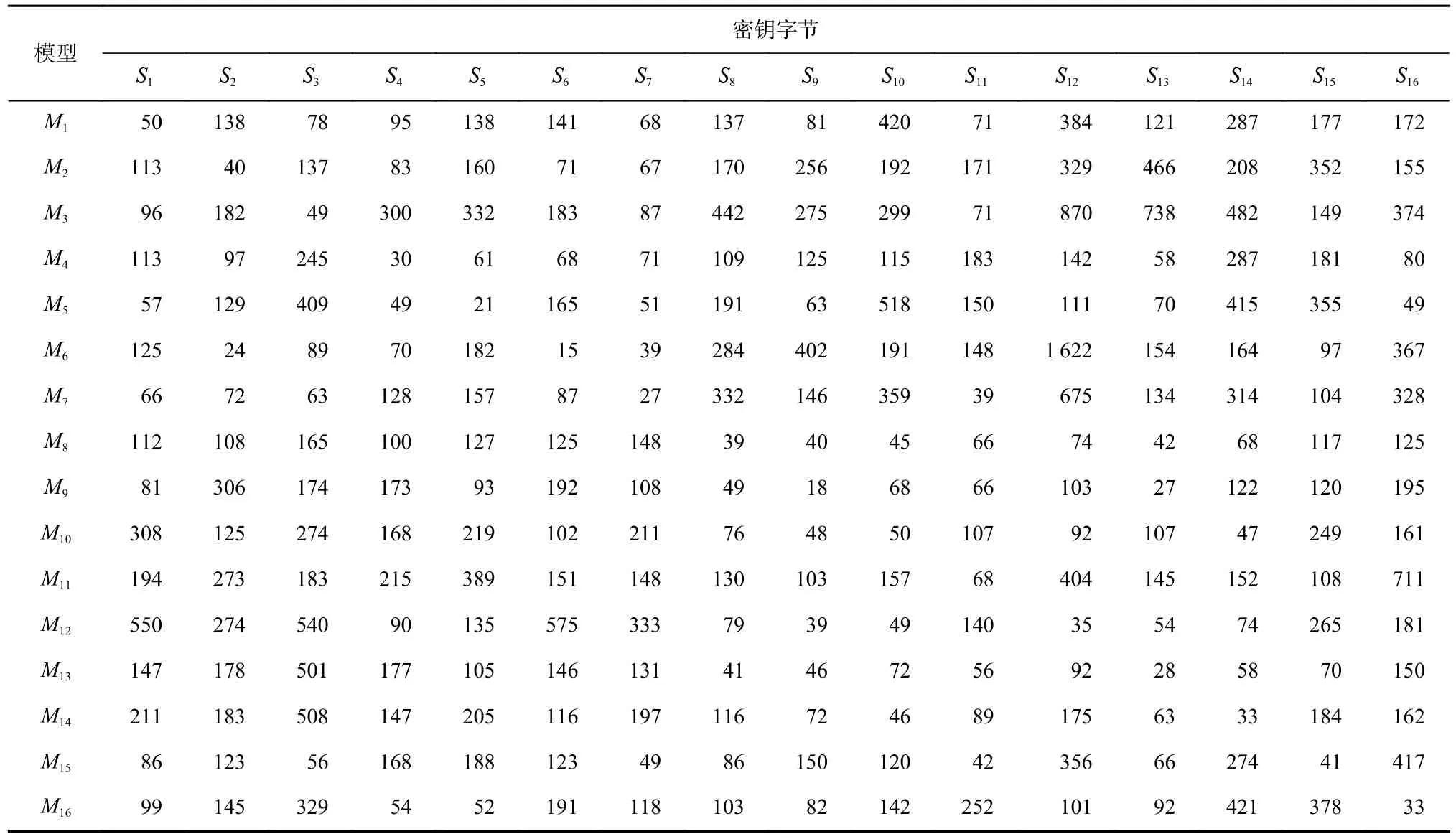
Table 2 Number of Traces for Sixteen Models Recovering Sixteen Key Bytes表2 16 個模型恢復16 個密鑰字節的能量跡數
表2 中,每一行的數值表示第i個模型Mi恢復不同密鑰字節的最少能量跡數. 從表2 中可以看出,以某個泄露點對應的密鑰字節數據建立的模型,在恢復該泄露點對應的密鑰字節時,除M10外都具有最佳效果;而以某個模型去恢復其他密鑰字節時,也都可以恢復,只是需要使用更多的能量跡數量.
2.2 數據篩選與多源數據聚合模型構建
表2 結果表明,基于神經網絡進行單密鑰字節模型訓練時,由于AES 算法中S 盒特性,密鑰泄露數據集之間存在可能相似的特征,每個模型可以一定程度上學習到其他密鑰字節的泛化特征,能夠恢復出其他泄露點對應的密鑰字節. 在因運行環境等原因無法大量采集能量跡的情況下,為減少數據采集和模型訓練,基于密鑰字節泄露數據集之間可能相似的特征,可以選用部分密鑰字節的泄露數據集訓練一個多源數據聚合模型去恢復所有密鑰字節.
為保證訓練的聚合模型具有更好的泛化效果,需要篩選出對其他所有密鑰字節的攻擊效果總體上最好的數據集進行訓練. 具體地,設計一種打分機制進行評估. 先基于不同泄露數據集構建的16 個模型中的每個模型對所有密鑰字節的攻擊結果,根據每個模型恢復各個密鑰字節的能量跡數量進行升序排序并進行打分,排序靠前的模型得分高,排序靠后的被認為對恢復密鑰的作用較小,得分降低甚至忽略不計. 以Cx(Mi,Sj)表示模型Mi在密鑰字節Sj上排序位置為x時的得分,打分方法為
根據Cx(Mi,Sj)計算出各個模型Mi在密鑰字節Sj上的得分. 基于該方法,計算每個模型Mi在所有16 個密鑰字節上的得分并求總分,以CT(Mi)表示模型Mi的總得分,則
根據表2 中不同單密鑰字節模型對各個密鑰字節恢復所需要的能量跡數,采用式(4)分別計算每個模型在恢復所有密鑰字節時的得分情況如表3 所示.
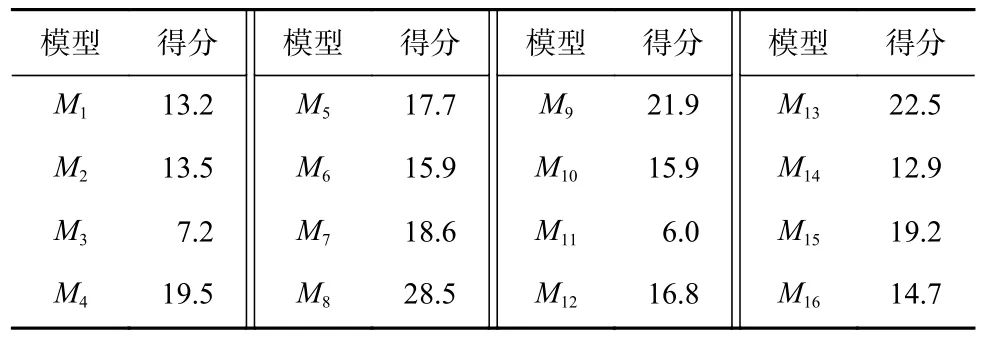
Table 3 Scores of Each Model表3 各個模型的得分
根據表3 中各個模型的得分進行升序排序,結果如表4 所示.
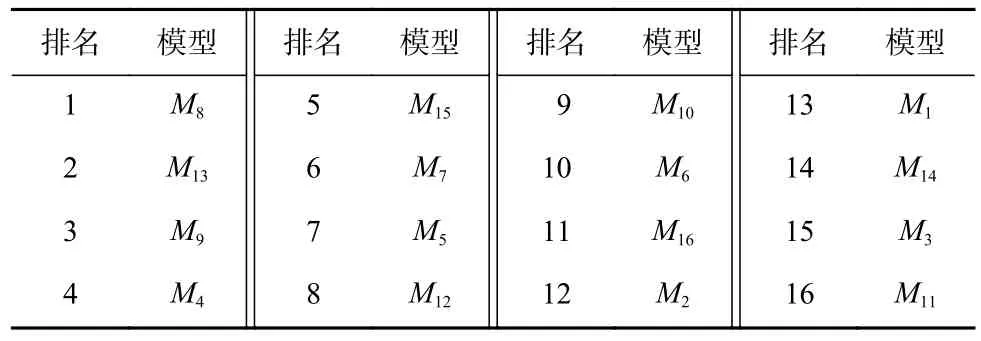
Table 4 Ranking of Each Model According to Scores表4 由得分得到的各個模型的排序
為構建一個具有較好泛化效果的聚合模型,選取排序靠前的幾個模型分別對應的密鑰字節泄露數據集進行聚合,訓練出一個多源數據聚合模型,再以聚合模型進行密鑰恢復.
在多源數據聚合模型訓練中,仍然采用Benadjila等人[7]提出的MLP-best 模型建立MLP 神經網絡模型,聚合模型的層數、激活函數和參數均與2.1 節中基于單密鑰字節構建模型相同.
3 實驗結果與分析
采用Python 語言,基于Keras 深度學習開源庫(keras 2.2.4)和TensorFlow 后端(Tensorflow 1.12.0)在硬件配置為Intel(R)CoreTMi5-6300HQ CPU@2.30 GHz、內存8 GB 和 NVIDIA GeForce GTX 960 M 顯卡的計算機上實現MLP 神經網絡模型,基于DPAContest_V4數據集構建并訓練16 個單密鑰字節模型和多源數據聚合模型,并進行密鑰恢復測試. 針對多源數據聚合模型,完成了其進行密鑰恢復的能量跡數量及與其他模型的對比測試.
3.1 不同多源數據聚合模型的攻擊效果測試
根據表4 中單密鑰字節模型對不同密鑰字節恢復的打分排名結果,按照排名情況選取各個模型對應的密鑰字節數據進行聚合,訓練多源數據聚合模型,再進行密鑰恢復. 為更好地評估不同密鑰字節數據集聚合的泛化攻擊效果,根據表4 的排名情況分別以得分排名前6,8,10,12,14,16 的模型對應的密鑰字節數據集進行多源數據聚合,建立和訓練聚合模型Mix_6,Mix_8,Mix_10,Mix_12,Mix_14,Mix_16,對不同密鑰字節數據進行恢復,并與各個單密鑰字節模型Mi恢復相應密鑰字節數據的結果進行對比,各自所需要的能量跡數如圖2 所示.
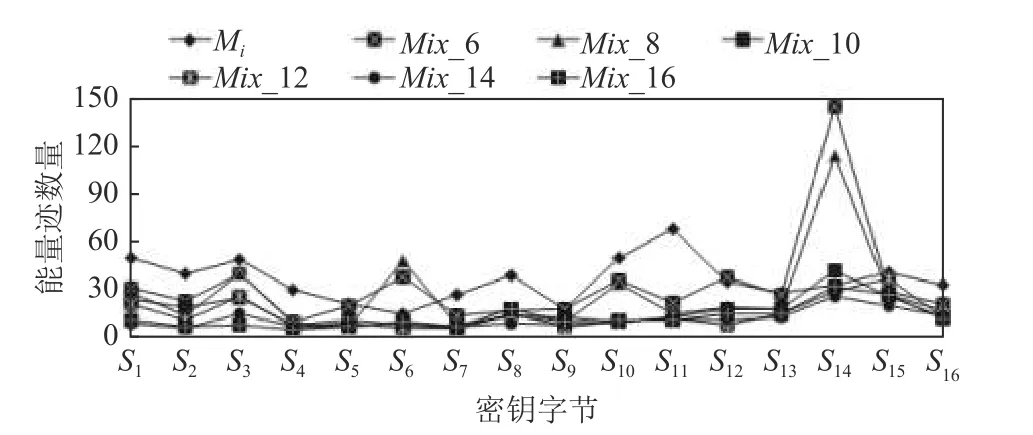
Fig.2 Number of traces for each key byte recovered by different models圖2 不同模型恢復各密鑰字節的能量跡數
圖2 結果表明,多源數據聚合模型都能夠以所聚合的部分密鑰字節泄露數據集訓練模型并有效恢復出所有密鑰字節,包括那些沒有參與聚合訓練的密鑰字節;同時,多源數據聚合模型較單密鑰字節模型的攻擊效果更好,其恢復各密鑰字節所需要的能量跡數量更少. 從對每一個密鑰字節數據的攻擊結果看,隨著聚合的數據集增加,聚合模型的攻擊效果提升,恢復該密鑰字節所需的能量跡數量減少,這表明聚合模型可以在更多的數據集中更好地學習到泛化特征.在聚合模型進行特征學習過程中,當聚合的數據集較少時,噪聲容易干擾學習結果,攻擊效果并沒有顯著提升;隨著聚合數據集的增加,噪聲干擾降低,在聚合6 個數據集進行訓練后,對整體子密鑰的恢復效果基本趨于穩定并優于單密鑰字節模型的攻擊結果.
多源數據聚合模型基于深度學習的強大學習能力,能夠基于部分采集的能量跡數據有效恢復算法整體密鑰,這在數據采集不便的情況下也能夠實現高效的攻擊;由于不需要訓練多個模型也使得模型訓練和分析測試工作有效減少.
3.2 公用數據集對比實驗與分析
現有針對密碼算法的基于深度學習的側信道分析方法,更多的仍然是針對密碼算法不同的密鑰字節分別建模和分析. 針對AES-256 算法,文獻[13]基于卷積神經網絡 (convolutional neural network,CNN)和DPAV4 數據集,以第1 輪掩碼S 盒輸出值的最低有效位作為訓練標簽,針對其選擇的某個密鑰字節對應的泄露數據集分別建模和訓練測試,使用1 000條能量跡作為訓練集,2000 條作為驗證集,2000 條作為測試集,完成對該密鑰字節的恢復,其恢復該密鑰字節所需要的能量跡為550 條.
采用多源數據聚合模型方法,按表4 分別取前8,10 個數據集聚合訓練模型Mix_8,Mix_10,與文獻[13]在同樣數據集大小條件下進行模型訓練并對前16 個密鑰字節進行恢復;同時,根據算法原始的密鑰字節順序選取前8,10 個密鑰字節的泄露數據集,采用本文的多源數據聚合思想以同樣數據集大小聚合訓練模型MO_8,MO_10 并恢復前16 個密鑰字節,與在同樣數據集大小情況下采用單密鑰字節泄露數據訓練模型Mi的密鑰恢復結果對比,各自所需能量跡數如表5 所示.
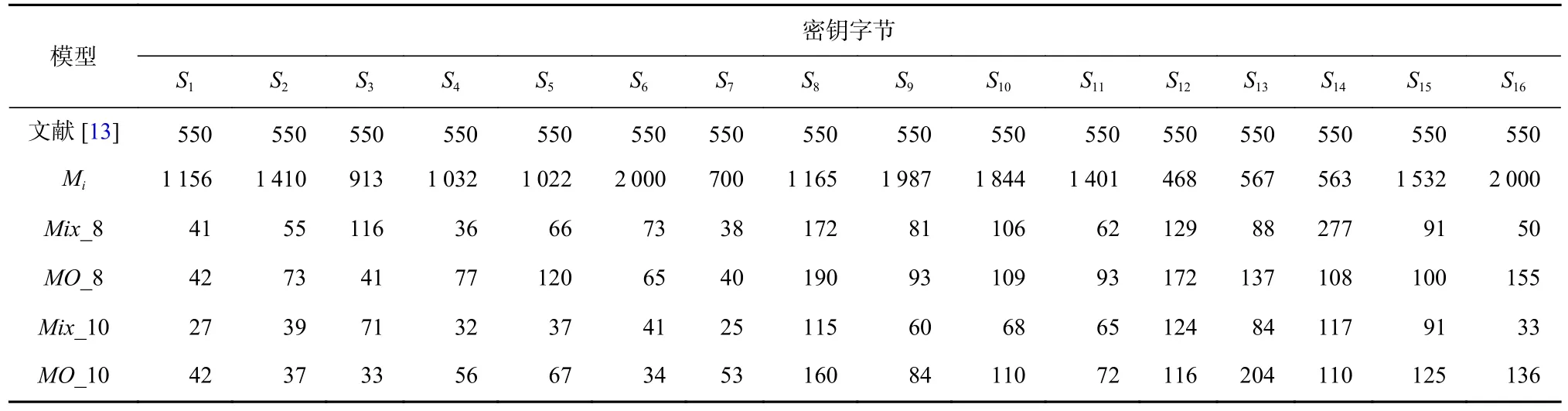
Table 5 Recovery Results of Six Models for 16 Key Bytes表5 6 個模型對16 個密鑰字節的恢復結果
文獻[13]通過已知的掩碼計算掩碼S 盒的輸出,將其轉換為一個不受保護的實現,本實驗中采用式(2)的標簽方案并未對掩碼進行額外操作,因此在只有1 000 條訓練數據下訓練的單密鑰字節模型效果不太理想,但在2 000 條能量跡內也能恢復正確密鑰.
表5 結果也顯示多源數據聚合模型恢復密鑰字節的效果都優于文獻[13],所需能量跡數量更少;隨著聚合數據集的增加,聚合模型對密鑰字節的恢復效果更好,所需要的能量跡數減少. 模型Mix_8,Mix_10 的攻擊效果分別優于模型MO_8,MO_10,這表明基于打分排名后篩選的多源數據聚合模型具有更好的泛化特征學習能力,其攻擊效果要優于不做數據篩選的多源數據聚合模型,恢復密鑰字節所需使用的能量跡數更少.
文獻[9]基于MLP 網絡和DPAV4 數據集,進行50 次隨機超參數搜索訓練得到50 個MLP 網絡并使用引導聚集(bootstrap aggregating)算法進行集成,針對第1 個密鑰字節的數據進行訓練與恢復,以第1 輪掩碼S 盒輸出值的漢明重量作為訓練標簽,34 000 條能量跡作為訓練集,1 000 條作為驗證集,1 000 條作為測試集進行實驗. 采用同樣的數據集規模,基于多源數據聚合模型方法,按表4 分別取前8,10,12 個數據集聚合訓練模型Mix_8,Mix_10,Mix_12 進行密鑰恢復;同時,根據算法原始的密鑰字節順序選取前8,10,12 個密鑰字節的泄露數據集,采用本文的多源數據聚合方法以同樣數據集大小聚合訓練模型MO_8,MO_10,MO_12 并恢復密鑰,各自所需能量跡數如表6所示.
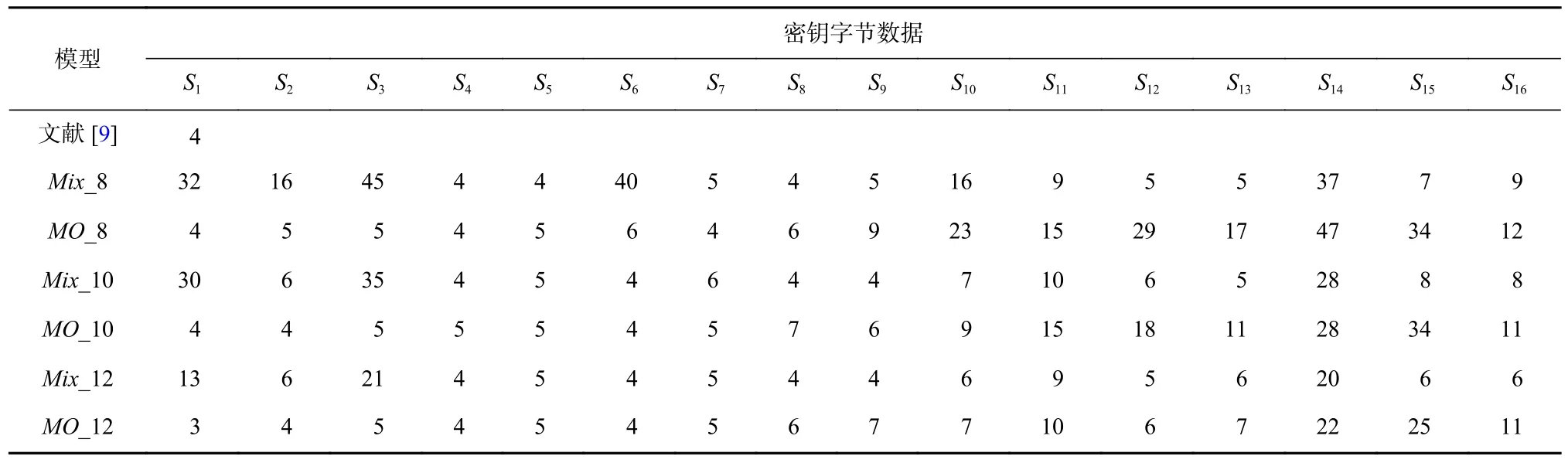
Table 6 Recovery Results of Seven Models for 16 Key Bytes表6 7 個模型對16 個密鑰字節的恢復結果
表6 結果顯示,相較于文獻[9]中的結果,采用聚合模型進行攻擊,各個模型中參與了訓練的密鑰字節的恢復所需要的能量跡在4 條左右,未參與訓練的密鑰字節的恢復需要更多的能量跡數;但采用聚合模型僅需要訓練1 個模型,開銷小、時間短,且在聚合12 個密鑰字節的泄露數據集后,對未參與訓練的密鑰字節恢復密鑰的能量跡數量都有效減少,而文獻[9]需要訓練50 個不同的模型才完成對第1個密鑰字節的攻擊,要完成對16 個密鑰字節的攻擊,其模型訓練的開銷極大、時間過長.
相比于表5 中的結果,表6 結果也顯示聚合模型中相應密鑰恢復所需要的能量跡數量進一步減少.這表明隨著數據規模的增加,神經網絡可以充分地學習到訓練數據的特征,聚合模型的攻擊成功率更高;其次,采用基于打分排名后篩選的數據聚合模型具有更好的泛化特征學習能力,其總體攻擊效果仍然優于不做數據篩選的聚合模型;同時,隨著參與訓練的數據量增加,泄露數據參與了訓練的密鑰字節更容易被恢復,因其特征能夠被更好地提取出來.
3.3 實測數據集對比實驗與分析
使用MathMagic 側信道分析儀,搭載目標芯片STC89C52 單片機,實現無防護的AES-128 算法,模擬數據采集困難、所采集的能量跡少的情景,共采集3 500 條能量跡,以其中3 000 條能量跡作為訓練集,剩下500 條能量跡作為測試集. 實驗中先通過相關性分析確定密鑰字節在能量跡中的泄露位置,采用式(1)進行計算,由于漢明重量模型對應9 種類別,因此在保持MLP 模型結構參數與2.1 節模型參數其余部分不變的基礎上,將輸出層節點數設置為9. 對每個密鑰字節獨立建模并攻擊,各單密鑰字節模型記為Mi. 采用多源數據聚合模型方法,按表4 選取前8,10 個泄露數據集聚合訓練模型Mix_8,Mix_10,同時按密碼算法原始密鑰字節順序選取前8,10 個數據集聚合訓練模型MO_8,MO_10,并分別恢復各密鑰字節,各個模型完成密鑰恢復所需的能量跡數對比結果如表7 所示.
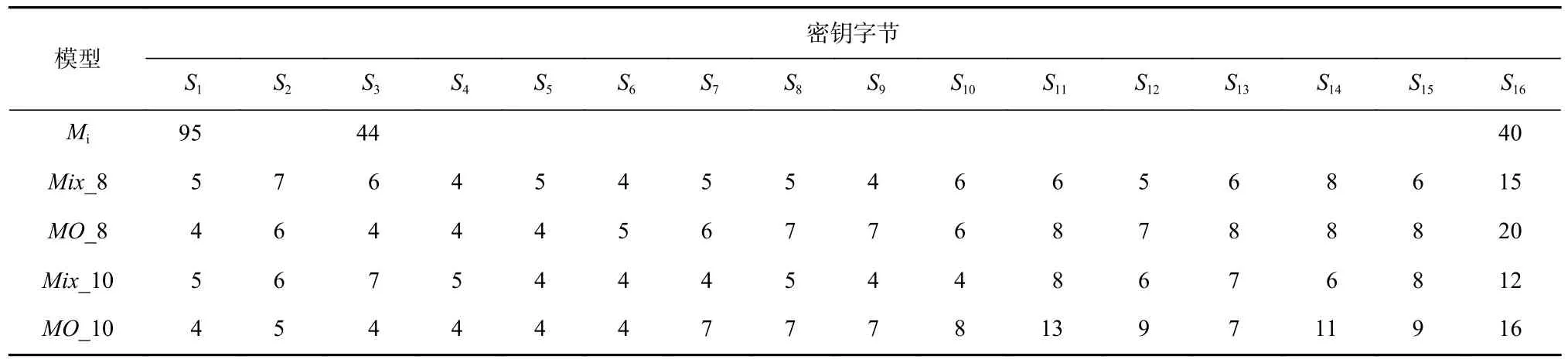
Table 7 Recovery Results of Five Models for 16 Key Bytes表7 5 個模型對16 個密鑰字節的恢復結果
表7 結果表明,由于訓練數據的不足,采用單密鑰字節建模并進行密鑰恢復時,僅恢復出其中的3個字節,其他模型因不能學習到足夠的特征,無法恢復密鑰;采用多源數據聚合模型方法都有效完成了密鑰恢復,優于單密鑰字節模型攻擊結果. 在Mix_8,Mix_10 中,恢復前3 個密鑰字節的能量跡數較MO_8,MO_10 所需的能量跡數稍多,主要原因在于這些密鑰字節泄露數據在Mix_8,Mix_10 中未參與訓練,而在MO_8,MO_10 中參與了訓練,在訓練數據不足的情況下未參與訓練的密鑰字節特征學習效果相對減弱. 但總體上,與采用公用數據集訓練模型一樣,采用實測數據集訓練模型時,基于打分排名后篩選的多源數據聚合模型仍然具有更好的泛化特征學習能力,其攻擊效果優于不做數據篩選的多源數據聚合模型,恢復密鑰字節所需使用的能量跡數更少. 此外,相對于加掩防護的公用數據集實驗,實測實驗針對的是未加掩碼防護的AES-128 算法,因此更容易完成攻擊,恢復密鑰所需的能量跡數大大減少.
3.4 針對Present 算法的聚合模型實驗與分析
為評估本文方法的通用性,將聚合模型應用于Present 算法,驗證數據聚合模型的分析效果. Present算法是一個4 b 的S 盒且SPN 結構的輕量級密碼算法. 使用osrtoolkit 功耗采集平臺,搭載目標芯片ATMEGA2560,實現無防護的Present 算法,采集3 500條能量跡,以其中3 000 條能量跡作為訓練集,500 條能量跡作為測試集. 實驗中先通過相關性分析確定密鑰半字節在能量跡中的泄露位置,以真實密鑰作為身份標簽,訓練的epoch=300,batchsize=100,學習率設為0.000 01,優化器使用RMSprop,使用交叉熵損失函數,將輸出層節點數設置為16. 對16 個密鑰半字節分別獨立建模并攻擊,各密鑰半字節模型記為Mi.利用這16 個模型中的每一個模型,分別以每個密鑰半字節對應的測試集數據去恢復所有的密鑰半字節,各模型完成對各密鑰半字節恢復的最少能量跡數如表8 所示.
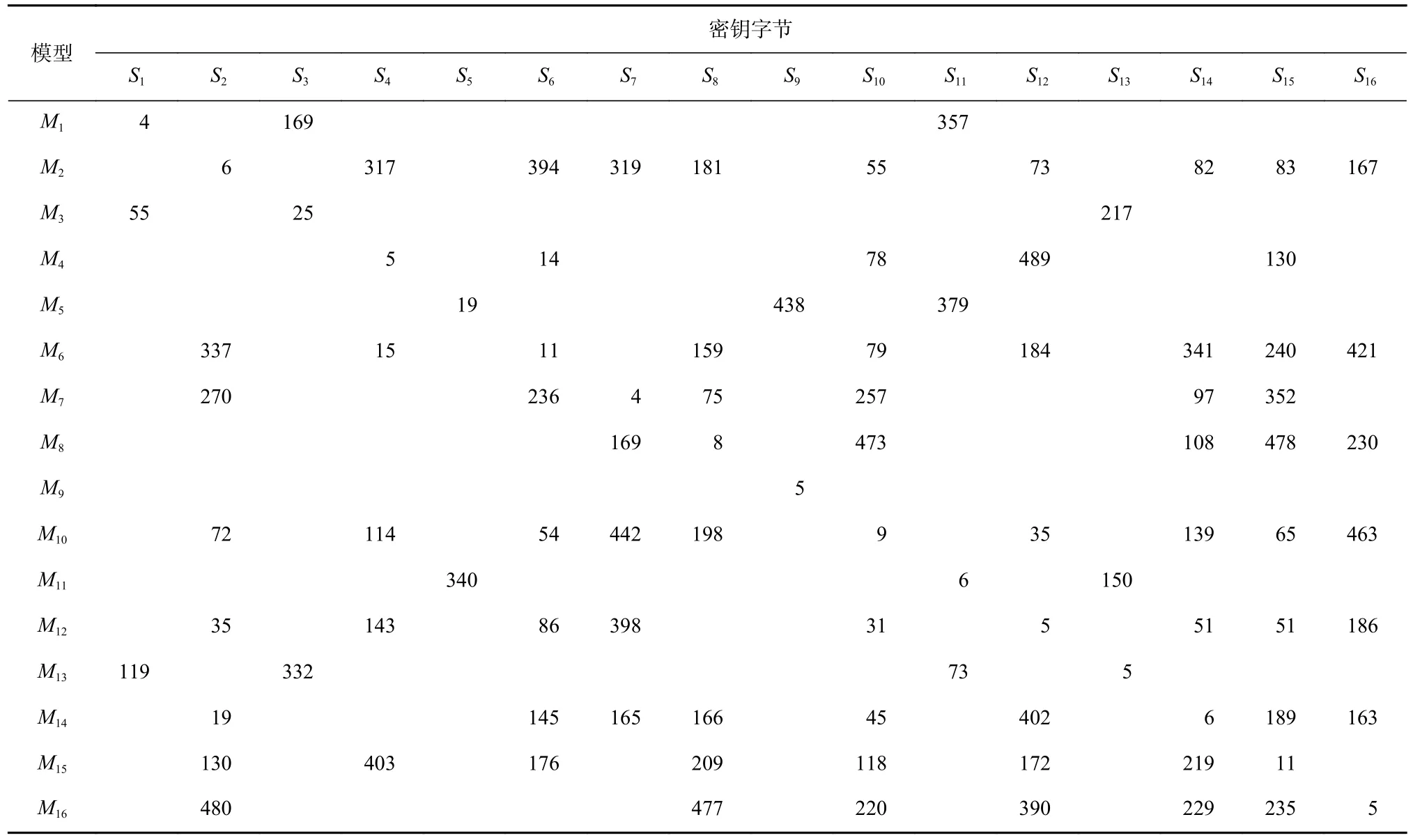
Table 8 Number of Traces for Sixteen Models Recovering Sixteen Key Nibbles for Present Algorithms表8 針對Present 算法16 個模型恢復16 個密鑰字節的能量跡數
根據式(4),基于表8 的結果計算每個模型在恢復所有密鑰半字節時的得分,結果如表9 所示.采用多源數據聚合模型方法,對表9 以得分高低排序后選取前8,10,12,16 個泄露數據集聚合訓練模型Mix_8,Mix_10,Mix_12,Mix_16,分別恢復各密鑰半字節,所需的能量跡數與單密鑰半字節建模恢復的結果對比情況如表10 所示.

Table 9 Scores of Sixteen Models表9 16 個模型的得分
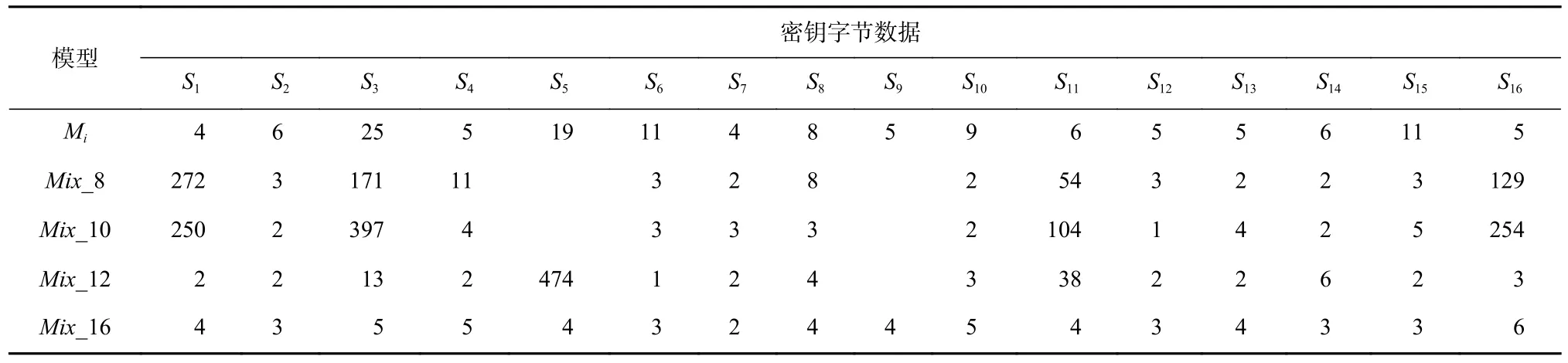
Table 10 Recovery Results of Different Models for Each Key Nibble表10 不同模型對各密鑰半字節的恢復結果
表10 結果表明,在聚合模型中,由于密鑰半字節S5和S9對應模型得分較低,相應數據集未能在Mix_8,Mix_10 中參與訓練,無法被恢復. 但在Mix_12模型中,S5對應的數據集盡管沒有參與訓練,但由于有更多數據集參與訓練,相應特征被學習,也能夠被有效恢復. 而基于所有數據集的聚合模型,能夠以更少的能量跡數量恢復所有密鑰半字節. 從所有聚合模型恢復的結果看,若數據集參與了聚合模型訓練,其恢復相應密鑰半字節所需要的能量跡數量均少于單密鑰半字節模型的結果;在單密鑰半字節模型中無法恢復的其他密鑰半字節,在聚合模型中除1 或2個密鑰半字節外,其他的都能夠有效恢復,這表明多源數據聚合模型具有更好的泛化特征學習能力,相對于單密鑰半字節模型,有效提升了其恢復密鑰的能力. 針對不同算法的攻擊結果,表明了本文提出的多源數據聚合模型在攻擊時具有較好的通用性.
4 結束語
為降低在實際應用中基于深度學習進行側信道攻擊所需要的數據采集和模型訓練開銷,提出一種基于多源數據聚合的神經網絡側信道攻擊方法. 該方法針對AES-128 算法,通過評估單密鑰字節模型的泛化效果,篩選出對各密鑰字節恢復效果最好的部分密鑰字節泄露數據集,構建多源數據聚合模型,再進行密鑰恢復. 實驗測試結果表明,多源數據聚合模型具有良好的泛化效果,有效提高了密鑰恢復的準確率和效率,降低了恢復密鑰所需的能量跡數量,可在能量跡采集困難、能量跡較少的情況下依然具有較好的攻擊效果. 在今后工作中,將考慮結合數據增強技術,進一步提升在能量跡不足情況下的密鑰恢復效果. 與此同時,也將研究針對深度學習側信道攻擊的防御措施,提高密碼算法應用的安全性. 深度學習側信道攻擊主要針對S 盒部件的泄露數據開展攻擊. 因此,為有效預防深度學習側信道攻擊,一方面是在密碼部件設計中,考慮S 盒抗側信道攻擊的能力,并研究密碼算法結構整體的安全性;另一方面是研究針對側信道攻擊的掩碼防護技術,消除密碼算法功耗泄露與中間值之間的可預測關系,達到防護的目的.
作者貢獻聲明:張潤蓮設計研究方案,撰寫初稿;潘兆軒參與方案討論、實驗研究及結果分析;李金林采集數據,參與實驗研究及結果分析;武小年參與設計研究方案及論文修改;韋永壯參與論文修改.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
