用于方面級情感分析的情感增強雙圖卷積網絡
2024-01-11 13:15:28張文軒殷雁君
計算機與生活 2024年1期
張文軒,殷雁君,智 敏
內蒙古師范大學 計算機科學技術學院,呼和浩特 010022
隨著社交網絡和電子商務的快速發展,情感分析(sentiment analysis,SA)已經成為自然語言處理領域(natural language processing,NLP)的一個熱門研究課題[1]。方面級情感分析(aspect based sentiment analysis,ABSA)是一項面向實體級的細粒度情感分析任務,旨在確定句子中給定方面的情感極性,即積極、消極或中性。與傳統的情感分析任務不同,ABSA 任務能夠為給定句子中可能涉及的多個方面分別進行情感極性預測。以句子“The food is so good and so popular that waiting can really be a nightmare.”為例,句中包含“food”和“waiting”兩個方面項。ABSA任務要求模型能夠根據“food”和“waiting”對應的意見項“good”和“nightmare”分別預測出積極與消極的情感極性。而傳統的情感分析僅能夠對整個文檔或句子預測一個整體的情感極性,顯然不適合處理這類包含多種不同情感的文本。因此,ABSA以其能夠準確地識別用戶對某個具體方面的態度而在市場調研、輿情監測等領域具有寶貴的應用價值[2]。
ABSA 任務的關鍵在于從上下文中捕捉和建立方面項與其對應的意見項之間的依賴關系。基于句子的不同部分對方面發揮不同作用的思路,過去的ABSA 研究廣泛采用注意力機制(attention mechanism)[3]對句中詞語間的語義關聯進行建模[4-5]。但由于文本的復雜性,單純的注意力機制往往不能準確捕獲方面及其上下文詞之間的依賴關系。
考慮到方面項與其對應意見項之間的語法結構關系能夠為情感極性預測提供幫助,基于依存樹構建圖神經網絡(graph neural network,GNN)的方法已經成為近年來ABSA 研究的重要方向[5]。這類方法利用依存解析工具將句子的語法結構轉化為圖結構,并在此基礎上利用圖卷積網絡(graph convolution network,GCN)[6]、圖注意力網絡(graph attention networks,GAT)[7]等方法進行表示學習,使得方面項與距離較遠的意見項能夠進行更加高效、準確的信息交互。然而,基于依存樹的圖神經網絡在ABSA任務中依然存在以下問題:一是大多數現有的基于圖神經網絡的方法在圖的構建過程中只考慮詞語間的語法依賴關系,而忽略了情感知識在建模特定方面與上下文間情感依賴關系中的作用[8]。二是這類模型性能高度依賴于依存解析結果的準確性,尤其是處理復雜或語法知識不敏感的樣本[9-10]。
針對現有方法缺少情感知識輔助的缺陷,本文利用情感知識構建情感增強的語法圖卷積(affection enhanced syntax based GCN,AesGCN),從多功能情感知識庫SenticNet 中引入情感知識參與圖的構造,以幫助模型提取上下文與特定方面之間的情感依賴關系。針對現有方法對依存樹解析準確性依賴程度較高的問題,基于自注意力機制構建基于注意力的圖卷積(attention based GCN,AttGCN),并設計了3種正則化器對注意力機制的學習進行指導,以便準確地捕獲方面及其對應意見項之間的依賴關系,其中本文提出的一種語法正則化器能夠幫助模型自發地學習與基于語法知識構建的鄰接矩陣具有相似結構的注意力權重。將AesGCN 與AttGCN 以并聯方式相結合,提出了一種用于方面級情感分析的情感增強雙圖卷積網絡(affection enhanced dual graph convolution network,AEDGCN)。在3 個公開數據集上的一系列實驗表明,與現有的ABSA 方法相比,本文提出的AEDGCN實現了較為先進的性能。
1 相關研究
與傳統的句子級或文檔級情感分析任務不同,方面級情感分析是一種面向實體的細粒度情感分析任務。早期的ABSA 方法主要基于情感詞典和機器學習[11-12],這類方法主要依靠手工提取特征,雖然在特定領域有良好表現,但需要耗費大量人工成本并且無法對方面項及其上下文之間的依賴關系進行建模。
近年來,由于注意力機制在上下文語義建模中的良好表現,大量工作嘗試將基于注意力的神經網絡模型應用于ABSA任務,其主要目的在于利用注意力機制捕捉和建立方面項及其上下文之間的聯系[4]。例如,Wang 等[13]提出的ATAE-LSTM(attention-based LSTM with aspect embedding)將方面詞向量和上下文詞向量組合作為長短期記憶網絡(long short-term memory,LSTM)的輸入,利用注意力機制為上下文賦予不同的權重以提取有利于ABSA 任務的語義特征。而IAN(interactive attention network)[14]、MGAN(multi-grained attention network)[15]和AOA(attentionover-attention neural network)[16]則基于交互注意力機制為上下文分配權重,以實現方面項與上下文間的情感關系建模。盡管上述方法已經在ABSA 任務中取得了良好的性能,但由于缺乏對語法知識的利用,當句子成分較為復雜或句中存在多個方面時,將難以對方面項的情感極性做出準確判斷。
考慮到語法知識在ABSA任務中的重要性,基于依存樹建立GNN 的方法逐漸成為ABSA 領域的研究熱點。依存語法分析通過對句子中詞與詞之間的語法關系進行抽取和篩選構建依存樹,能夠有效縮短方面項和意見項之間的距離[17],在一定程度規避語法無關上下文帶來的噪聲信息。例如,Zhang 等[18]基于依存樹建立無向圖,利用GCN 學習包含語法知識的上下文表示,在當時實現了最先進的ABSA 性能。Huang 等[19]提出的目標依賴的圖注意力網絡(targetdependent graph attention network,TD-GAT)則基于依存樹構建圖注意力網絡進行表示學習,并采用LSTM 單元結構逐層更新節點。Wang 等[20]則引入依賴關系類型信息,并以目標方面為根節點對依存樹進行修剪,構建關系圖注意力網絡(relational graph attention network,R-GAT),大幅提升了性能。然而,這類方法具有詞語節點嚴格按照圖結構進行信息交互的特點,導致模型性能高度依賴依存樹解析質量。特別是當句子結構較為復雜或對語法不敏感導致依存樹解析質量較差時,模型將難以維持原有性能。
考慮到這一缺陷,最近的研究嘗試將依存圖與基于有監督學習的圖結構以并行的方式相結合,實現二者的優勢互補,在提升ABSA性能的同時有效減輕模型對依存樹的依賴程度。例如,Xu 等[21]提出的注意力增強的圖卷積網絡(attention-enhanced graph convolutional network,AEGCN)基于多頭自注意力和GCN 構建雙通道模型,并通過通道間的交互注意力機制使得兩種特征相互增強。類似的,Chen 等[22]利用歸納生成的潛在圖和依存圖進行表示學習,并通過門控機制進行特征融合。Li 等[10]提出的雙圖卷積網絡(dual graph convolutional network,DualGCN)則構造了基于語法的圖卷積網絡SynGCN 和基于語義的圖卷積網絡SemGCN 以分別提取語法和語義特征,并利用雙仿射模塊(BiAffine module)使得兩種特征產生交互,實現了先進的ABSA性能。
ABSA 的另一個研究熱點是如何引入外部情感知識,即利用外部情感知識對模型或輸入特征進行增強以幫助模型更好地理解不同情感強度的詞語對ABSA 任務的貢獻度。Ma 等[23]基于SenticNet將情感知識納入LSTM模型,以提取方面級和句子級情感特征。Liang 等[8]則利用SenticNet的情感知識為依存圖賦予邊權重,提出了基于SenticNet 的圖卷積模型(SenticNet-based graph convolutional network,Sentic-GCN),能夠更為準確地關注方面相關的情感詞。Zhong 等[24]則利用知識圖譜嵌入(knowledge graph embedding,KGE)技術對WordNet中的知識建模為分布式表示,以增強模型的輸入特征。
基于SenticNet 取得的顯著性能,本文利用SenticNet 對語法圖進行增強,構造基于情感增強的語法圖卷積AesGCN,提取具有一定情感知識的語法特征。同時,利用自注意力機制捕捉詞語間語義關聯,構建基于注意力的圖卷積AttGCN,并設計了三種正則化器對注意力學習進行指導,以提取經過語法信息指導的語義特征。基于AesGCN 和AttGCN構建雙圖卷積架構,并利用BiAffine 模塊實現兩種特征間的相互增強,幫助模型準確、高效地提取符合語法及語義依賴關系的特征,以實現先進的ABSA性能。
2 情感增強雙圖卷積模型
本章將詳細介紹本文提出的用于方面級情感分析的情感增強雙圖卷積網絡AEDGCN,其流程如圖1所示。
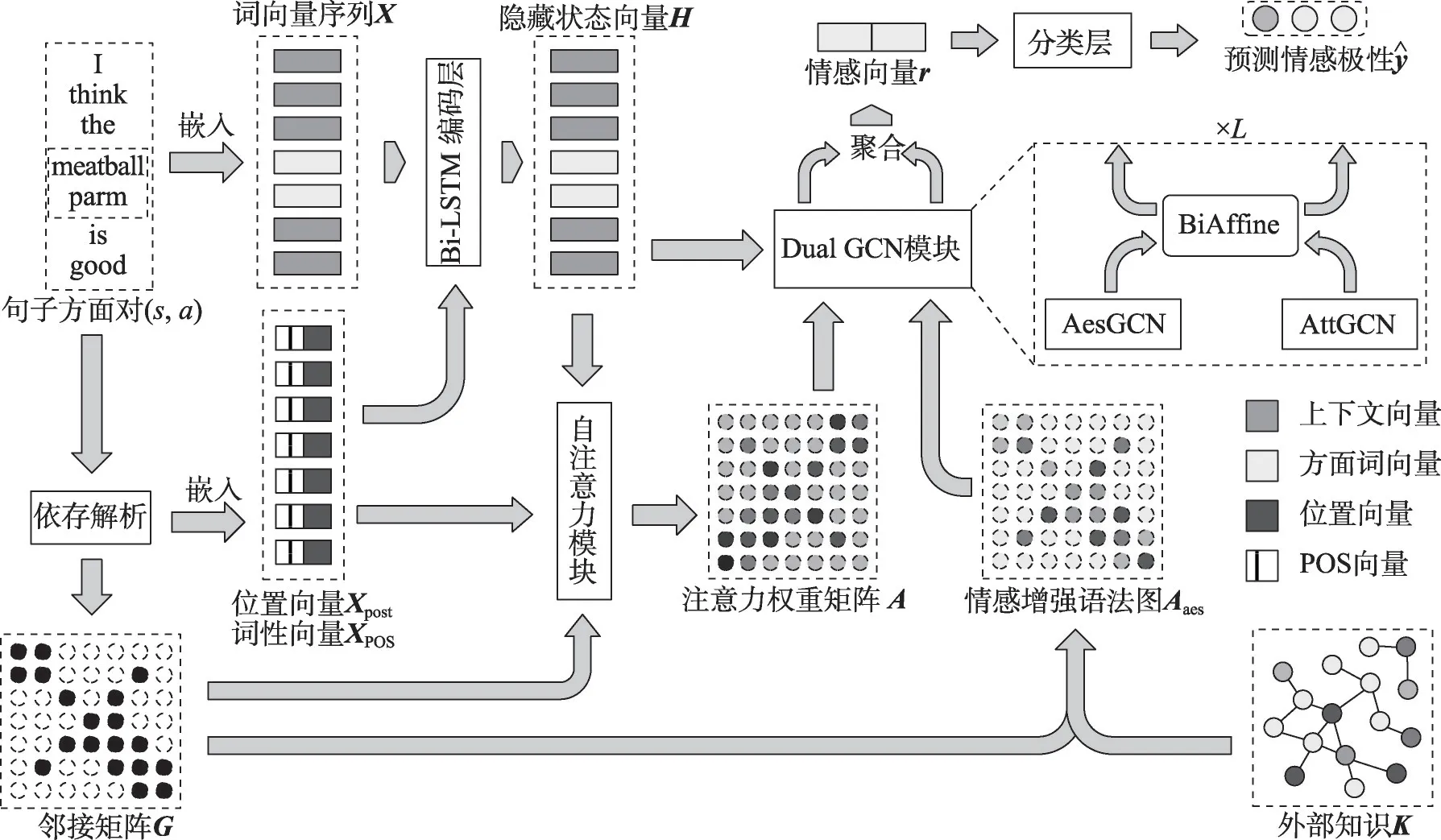
圖1 AEDGCN整體流程Fig.1 Overall process of AEDGCN
模型由預處理、雙向LSTM(bi-directional long short-term memory,BiLSTM)編碼層、自注意力模塊、雙圖卷積模塊和分類層等結構組成。模型以句子方面對(s,a) 為輸入,其包含一個長度為n的句子s={w1,w2,…,wτ+1,…,wτ+m,…,wn},以及從該句第τ+1 個詞開始的長度為m的方面a={wτ+1,wτ+2,…,wτ+m}。首先通過預處理為句子s生成鄰接矩陣G、情感增強語法圖Aaes以及位置、詞性(part of speech,POS)向量,并將句子s經嵌入得到的詞向量序列輸入Bi-LSTM 進行編碼,編碼后的隱藏向量與位置、詞性向量進行拼接送入自注意力模塊計算注意力權重矩陣,同時設計了三種正則化器對注意力權重矩陣進行約束。
將情感增強語法圖與注意力權重矩陣作為圖結構,構建包含基于情感增強的語法圖卷積AesGCN和基于注意力的圖卷積AttGCN 的并行通道雙圖卷積(DualGCN)模塊,分別對Bi-LSTM 層得到的隱藏向量進行圖卷積操作。將雙圖卷積模塊輸出的方面節點表示進行聚合,得到用于分類的方面情感向量。最后將方面情感向量送入分類層得到情感預測結果。
2.1 預處理
2.1.1 依存解析
預處理的第一步是對輸入句子s進行依存解析(dependency parsing),構建包含句中詞語間的語法依賴關系的鄰接矩陣G∈Rn×n。具體來說,對于鄰接矩陣G中的任意元素gij,若詞wi和詞wj在依存樹中存在語法關系,則令gij=gji=1,否則令gij=gji=0。同時為G中所有節點添加自連接,即gii=1。此外,參考Sun 等[25]的研究,根據句中詞語同方面項間的相對位置關系及依存解析結果為每個詞語分配位置標簽和詞性標簽,并基于位置標簽和詞性標簽對句子進行嵌入表示,生成可學習的位置向量,其中dpt和dps分別表示位置向量和詞性向量的維度。
2.1.2 情感增強
考慮到大多數現有的基于依存樹的ABSA 研究對情感知識的忽視,本文參考Liang 等[8]的研究,將包含200 000 個概念的SenticNet 6[26]作為情感知識來源對語法圖,即鄰接矩陣G進行增強。SenticNet 是一個公開的意見挖掘和情感分析資源,提供了一組語義、情感、極性關聯的自然語言概念。SenticNet 中的每個概念都對應一個情感值,其中強積極概念的情感值接近1,強消極概念的情感值則接近-1。Xing 等[27]通過領域適應任務的實驗證明,SenticNet 包含的知識涵蓋多個領域,并且在增強情感表征學習方面相比其他情感詞典具有顯著優勢。
對于句子s中任意兩個詞語wi、wj,其情感權重Sij定義為:
其中,SenticNet(wi) ∈[-1,1]表示詞wi在SenticNet 中的情感得分,且SenticNet(wi)=0 表示wi為中性詞或wi在SenticNet中不存在。
此外,設置方面指示權重Tij用于強調方面項及其上下文間的情感依賴關系:
將Sij、Tij與基于依存樹的鄰接矩陣G相結合,構建未歸一化的情感增強語法圖aes∈Rn×n,對于aes中的情感增強元素,其形式化定義為:
最后利用softmax 函數對aes進行歸一化,生成情感增強語法圖Aaes∈Rn×n:
2.2 嵌入與Bi-LSTM編碼層
對于句子方面對(s,a),利用嵌入矩陣E∈R|V|×de獲取句子s的詞向量表示X={x1,x2,…,xn},其中|V|是詞表大小,de是詞向量維度。將X與位置向量Xpost和詞性向量XPOS進行拼接,得到輸入特征
將X′送入Bi-LSTM層進行編碼以獲得包含上下文信息的隱藏狀態向量H={h1,h2,…,hn},其中是Bi-LSTM 在時間步i處的隱藏向量,dhid為隱藏狀態向量維度。
2.3 自注意力模塊
自注意力模塊通過自注意力機制獲取具有可學習權重的注意力權重矩陣A∈Rn×n用于后續的圖表示學習。相較于邊權重固定的鄰接矩陣G,自注意力機制可以根據詞語間的語義相關性動態地分配邊權重,有助于模型適應對語法不敏感的文本。
輸入特征H′經過線性映射分別生成查詢向量和鍵向量,并用于計算注意力權重矩陣A,其中dk是查詢向量和鍵向量的維度,形式上:
2.3.1 語法正則化
如前文所述,由于文本的復雜性,單純的注意力機制難以準確捕獲詞語間的依賴關系。因此,本文提出語法正則化器RS,以幫助模型自發地學習與基于語法知識構建的鄰接矩陣具有相似結構的注意力權重,而不是直接基于圖結構進行表示學習。
在基于GAT[7]的模型中,為使得圖結構中的每個節點只與其各自的鄰居節點產生信息交互,使用圖結構對自注意力機制生成的注意力權重矩陣進行過濾操作。以An中元素為例,基于鄰接矩陣G的過濾機制maskG(?)定義如下:
其中,inf 表示無窮大。利用maskG(?)對An進行過濾,經歸一化得到基于圖G的注意力權重矩陣AG∈Rn×n:
語法正則化器RS的形式化定義如下:
其中,||?||2表示L2 范數。直觀上,RS通過計算A和AG間的L2 范數,能夠鼓勵句中詞語在表示學習過程中更多關注與自身在語法上具有直接關聯的詞語,反之則給予懲罰,以避免注意力機制引入過多語法上無關的噪聲信息。本文不直接將AG作為注意力權重的理由是,在依存樹解析性能不穩定的情況下直接使用AG會導致模型丟棄任務相關信息而引入噪聲的情況。此外,現有的方面級情感分類任務的訓練樣本集較小,使用AG也將導致語料庫中大量詞語無法參與到表示學習中,對模型魯棒性造成不利影響。
2.3.2 差異正則化
情感增強語法圖Aaes利用先驗的外部工具或知識定義邊權重,然而在具體的評論文本中,詞語間的依賴關系可能與先驗知識存在偏差,尤其是在一些復雜的或不規范的文本中。為充分發揮先驗知識與注意力機制各自的優勢,并減輕模型對于先驗知識的依賴性,本文參考Li等[10]的研究在兩種圖結構之間定義了一個差異正則化器RD,以鼓勵注意力機制捕捉到與先驗知識不同的有助于ABSA 任務的依賴關系。形式上:
值得注意的是,差異正則化器只對A具有約束作用。
2.3.3 正交正則化
直觀上,句子中每個詞語出現的位置及發揮的作用都不盡相同,其各自的依賴關系也應當指向句中不同的詞語。因此,本文參考Li等[10]的研究添加了一個正交正則化器RO以幫助不同詞語的注意力權重分布之間能夠顯示出區分性,其定義為:
其中,I∈Rn×n是一個單位陣。RO的本質在于通過促進AAT中每個非對角元素趨于最小化,以保證矩陣A趨于正交。
2.4 雙圖卷積模塊
雙圖卷積模塊將句子的隱藏狀態向量H分別輸入到AesGCN、AttGCN 兩個通道中,并利用一個雙仿射模塊實現通道間信息交互。通過堆疊L個DualGCN 模塊進行充分的節點表示學習。對最后一層AesGCN 及AttGCN 輸出的方面節點表示進行聚合與拼接,形成最終的方面情感表示。
2.4.1 基于情感增強的語法圖卷積
AesGCN 將情感增強語法圖Aaes作為鄰接矩陣進行GCN 操作,以學習給定方面的情感依賴。參考Kipf 和Welling[6]的研究,AesGCN 各層的形式化定義如下:
2.4.2 基于注意力的圖卷積
AttGCN 將自注意力模塊得到的注意力權重矩陣A作為鄰接矩陣進行圖卷積操作,其優勢在于:一是能夠動態地捕捉詞語間的語義關聯,相比基于語法的依存圖更為靈活;二是可以適應對語法知識不敏感的在線評論。AttGCN各層的形式化定義如下:
2.4.3 雙仿射模塊
為保證AesGCN 和AttGCN 之間能進行有效的信息交流,本文參考Tang 等[9]和Li 等[10]的研究,采用雙仿射變換作為通道間的信息溝通橋梁,形式上:
2.4.4 方面聚合
對AesGCN和AttGCN的最終層輸出
2.5 分類層
將方面情感表示r送入一個線性層,并利用softmax函數生成關于方面項情感極性的預測分布:
2.6 模型訓練
模型利用交叉熵損失對情感分類任務進行監督:
其中,λ、μ和η是調節損失平衡性的超參數,ε是正則化系數,θ是模型參數集合。
3 實驗與分析
本文在3 個公開數據集上對提出的AEDGCN 模型進行了一系列實驗,以驗證其在性能上的先進性和可解釋性。
3.1 數據集
本文在3 個公開數據集上進行實驗,包括SemEval-2014 任務[28]的餐廳評論數據集Rest14 和筆記本電腦評論數據集Lap14,以及由Dong等[29]整理的Twitter 推文數據集。數據集中的每條樣本均是由真實的評論語句、評論中出現的方面詞和其對應的情感類別組成,并且標簽只包含積極、中性和消極。本文參考Sun 等[25]的處理方法對數據集進行預處理,處理后的各數據集統計數據如表1所示。
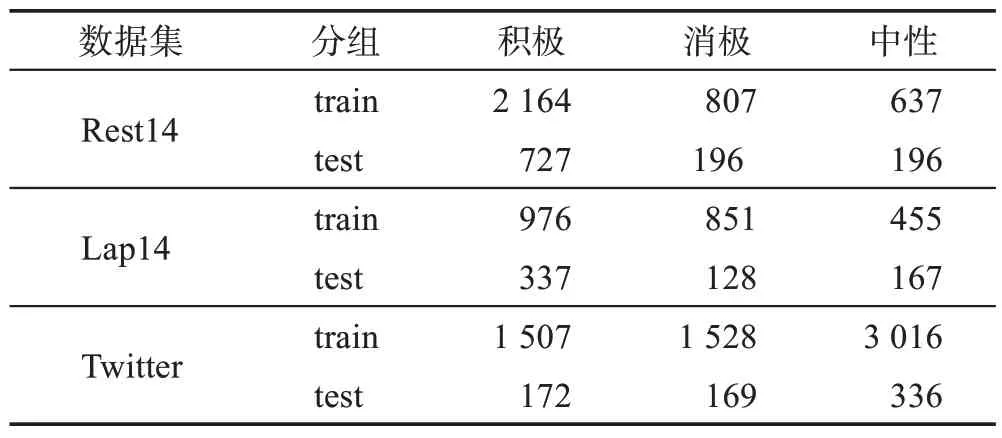
表1 各數據集統計數據Table 1 Statistics of datasets
3.2 實驗設置
本文使用Nvidia Tesla T4 GPU進行模型訓練,選擇CUDA 10.1 和cudnn 7.0 作為GPU 加速庫,并利用pytorch 1.9.0框架實現模型代碼。
使用Stanford 解析器(https://stanfordnlp.github.io/CoreNLP/)獲取數據集中所有評論文本的依存語法關系。使用Pennington 等[30]提供的300 維GloVe 詞向量作為本文模型和全部對比模型的初始化詞嵌入,位置向量維度dpt設置為30,詞性向量維度dps設置為30,BiLSTM輸出的隱藏狀態維度dhid設置為50,查詢向量和鍵向量的維度dk設置為50,GCN 層數設置為2 層且所有GCN 層的輸出維度dout均設置為50。本文對BiLSTM 編碼層的輸入應用丟棄率為0.7 的dropout操作,對每個GCN層的輸入應用丟棄率為0.5的dropout 操作,對自注意力模塊和雙仿射注意力模塊中的注意力權重矩陣應用丟棄率為0.1 的dropout操作。設置語法正則化系數λ=0.5,差異正則化系數μ=0.5,正交正則化系數η=0.1,參數正則化系數ε=1× 10-4。模型訓練采用學習率為0.002 的Adam優化器,設置batch 大小為32,在每個數據集上進行50輪訓練。
3.3 對比模型
為了全面評估和分析本文提出的AEDGCN 在ABSA 任務中的性能,本文選取了一系列基于不同方法類型的代表性模型與AEDGCN 進行比較,其簡要描述如下:
(1)ATAE-LSTM[13]:利用LSTM 對句子進行建模,基于上下文與方面項的相關性對上下文進行加權聚合。
(2)MemNet[31]:將上下文句子視為外部記憶,在上下文的詞向量表示上應用多跳注意力機制,并將最后一跳的輸出作為方面的最終表示。
(3)IAN[14]:使用兩個LSTM 分別對方面和上下文進行編碼,并利用交互注意力機制對方面和上下文間的關系進行建模。
(4)TNet[32]:將Bi-LSTM 編碼后的句子特征表示經過連續的面向方面的上下文編碼和注意力機制進行特征融合與提取,并使用CNN 提取最終的特征表示。
(5)ASGCN(aspect-specific graph convolutional networks)[18]:使用Bi-LSTM 獲取句子的特征表示,通過基于依存樹的GCN 學習特定于方面的上下文表示,并利用注意力機制聚合上下文表示用于分類。
(6)CDT(convolution over dependency tree)[25]:使用Bi-LSTM 獲取句子的特征表示,并通過基于依存樹的GCN學習方面表示。
(7)BiGCN(bi-level interactive graph convolution network)[33]:基于依存樹和詞共現關系構建語法圖和詞匯圖,歸納區分不同類型的語法依賴關系和詞共現關系,設計了雙層次交互式圖卷積網絡以充分學習節點表示。
(8)SenticGCN[8]:基于依存樹和SenticNet知識庫構建情感增強的依存圖,并將其應用于ASGCN 的模型架構進行表示學習。
(9)TD-GAT[19]:提出基于依存樹的圖注意力網絡,并采用LSTM單元逐層更新節點表示。
(10)R-GAT[20]:通過對依存樹進行重塑和剪枝定義了一種面向方面的依存樹結構,并基于此利用詞特征和依存關系特征構建關系圖注意力網絡進行表示學習。
(11)kumaGCN[22]:利用HardKuma 分布對句子的語義信息進行采樣,歸納生成方面特定的潛在圖結構,并引入門控機制將潛在圖與依存樹相結合。
(12)DGEDT(dependency graph enhanced dualtransformer)[9]:一種雙通道Transformer 結構,分別基于多頭自注意力和依存樹上的GCN學習句子的平面表示和圖表示,并利用BiAffine進行通道間信息交互。
(13)DualGCN[10]:通過構建基于依存解析概率矩陣的SynGCN 和注意力機制的SemGCN 雙通道結構集成語法知識和語義信息,并利用雙仿射模塊進行通道間信息交互。此外,在SemGCN 中利用正交正則化和差異正則化幫助模型更為準確地捕獲不同于語法結構的語義關聯。
(14)DM-GCN(dynamic and multi-channel graph convolutional networks)[34]:分別基于依存樹和多頭自注意力機制構建句法圖與語義圖,并通過句法圖卷積(Syntax GCN)和語義圖卷積(Semantic GCN)分別提取相應信息,同時利用一個帶有參數共享策略的公共圖卷積模塊Common GCN 獲取兩個空間的共享信息。最后將3 個通道提取的信息進行融合并用于分類任務。
3.4 實驗結果
本節在全部3 個數據集上比較了AEDGCN 和對比模型的ABSA性能,其中各對比模型的實驗結果分別來自其原論文。實驗結果如表2所示,其中字體加粗的表示當前指標中的最優結果,加下劃線的表示次優結果,加“*”號的則表示該數據集上的目前最先進結果。此外,“Att”表示基于注意力的模型,“Syn+GCN”表示基于依存樹的GCN 模型,“Syn+Att”表示依存樹與注意力相結合的模型。
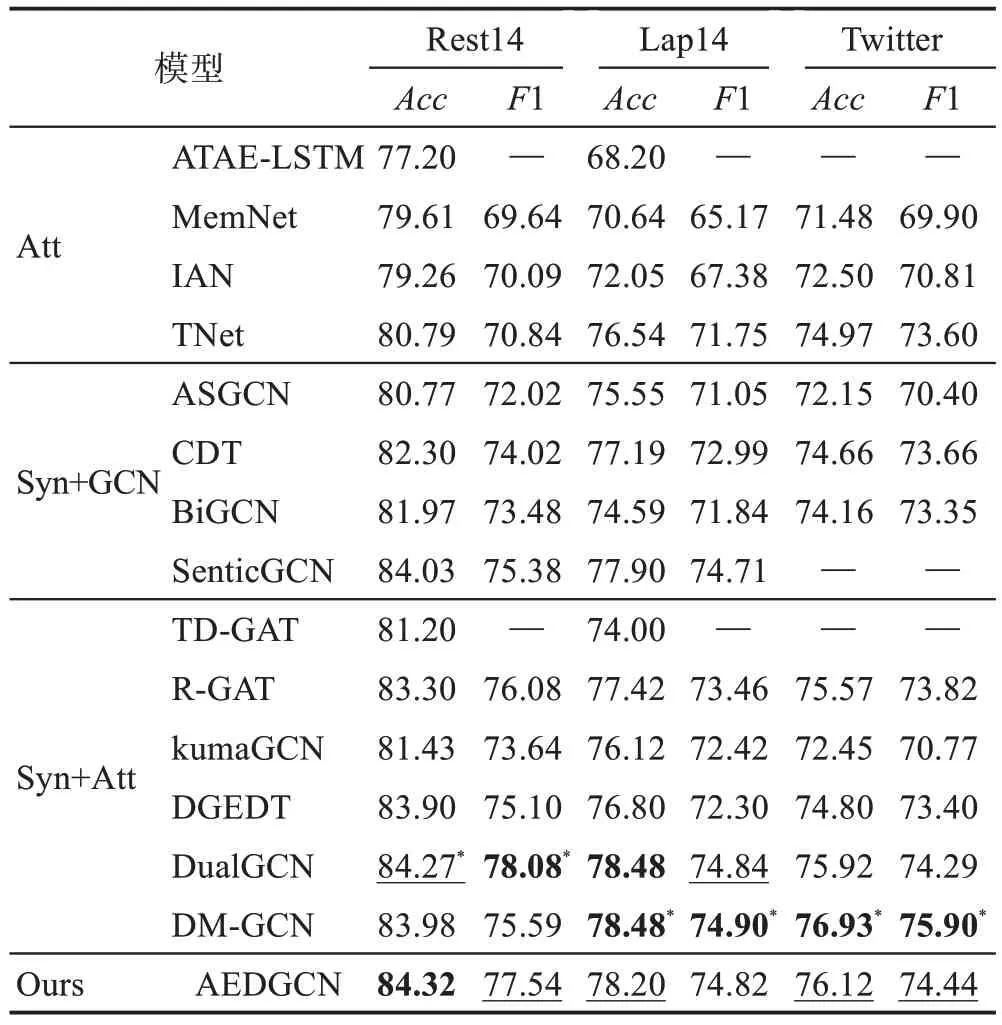
表2 實驗結果Table 2 Experimental results 單位:%
如表2 所示,本文提出的AEDGCN 在Rest14 上的準確率和F1 值分別取得了最優和次優結果,在Twitter 數據集上的準確率和F1 值都取得了次優結果,在Lap14 數據集上的準確率也取得了次優結果,實現了較為先進的情感分類性能,證明了本文模型在ABSA任務中的有效性。相較于其他對比模型,本文的AEDGCN 與取得目前最先進性能的DM-GCN都在對語法知識不敏感的Twitter 數據集上具有顯著的性能優勢,這是由于二者均利用語法與語義信息構建多通道架構,能夠充分發揮語法知識和注意力機制各自的優勢,一定程度減輕了模型對于依存樹解析質量的依賴性,增強了模型的魯棒性。
觀察包含情感知識的SenticGCN 和AEDGCN,二者都顯示出較為優異的性能,證明引入情感知識對于ABSA 任務具有積極作用。而AEDGCN 的性能更優于SenticGCN,證明了本文所采用的將圖結構與注意力相結合的雙圖卷積架構的有效性。關于AEDGCN 在Lap14 數據集上表現稍遜,本文認為可能的原因是Lap14 數據集中存在大量包含數字及專業術語的評論,與情感知識的聯系較弱。
從表2 還可以看出,ASGCN、CDT 等“Syn+GCN”模型在大多數數據集上的性能都明顯優于ATAE-LSTM、MemNet等“Att”模型,說明相較于注意力機制,依存樹對詞語間語法依賴關系的建模能夠更為準確地捕捉方面項與其對應意見項之間的聯系。而觀察R-GAT、DGEDT、DualGCN 等“Syn+Att”模型,其性能明顯優于ASGCN、CDT 等“Syn+GCN”的GCN模型。這說明相較于邊權值固定且缺乏區分性的GCN 方法,將圖結構與注意力相結合的表示學習方法更有利于ABSA任務。
此外,本文將AEDGCN 與表2 中性能較為先進的CDT、SenticGCN、DualGCN、DM-GCN等模型的參數規模進行了比較,以驗證本文模型的高效性,其結果如表3 所示。可以觀察到,本文提出的AEDGCN的參數規模較小,與CDT、DualGCN 相近,且明顯小于SenticGCN、DGEDT、DM-GCN。同時由表2可知,AEDGCN 在大部分數據集上的ABSA 性能普遍優于CDT、SenticGCN、DGEDT 等對比模型,并達到了與DualGCN、DM-GCN 所實現的目前最先進性能較為接近的結果,即AEDGCN 能夠利用較少的參數實現先進的ABSA性能,具有一定的參數高效性。

表3 模型參數量比較Table 3 Comparison of model parameters
3.5 消融實驗
為進一步驗證AEDGCN 中各模塊的有效性,本文基于3.2 節中的參數設置,設計了7 組對比模型,包括:
(1)AesGCN:去除自注意力模塊、雙圖卷積模塊中的AttGCN 通道及雙仿射模塊,僅使用AesGCN 通道進行表示學習。
(2)AttGCN:去除雙圖卷積模塊的AesGCN 通道及通道間的雙仿射模塊,僅使用AttGCN 通道進行表示學習,仍然使用3種正則化器對自注意力機制進行監督。
(3)AEDGCN-w/o-BiAffine:去除雙圖卷積模塊中兩通道間的雙仿射模塊。
(4)AEDGCN-w/o-RS:去除語法正則化器RS,即不使用語法圖G對注意力權重矩陣A進行約束。
(5)AEDGCN-w/o-RD:去除差異正則化器RD,即不使用情感增強語法圖Aaes對注意力權重矩陣A進行差異化約束。
(6)AEDGCN-w/o-RO:去除正交正則化器RO,即不對注意力權重矩陣A做正交化要求。
(7)AEDGCN-w/o-sentic:不使用SenticNet 中的情感知識對語法圖進行增強,而僅使用鄰接矩陣G作為AesGCN通道的輸入圖結構。此外,為避免節點度的差異對表示學習產生不利影響,對G進行歸一化得到∈Rn×n并用于后續的GCN 操作。中元素的形式化定義為:
其中,gij表示鄰接矩陣G中的元素。
使用以上對比模型在全部3 個數據集上進行消融實驗,結果如表4所示。

表4 消融實驗結果Table 4 Experimental results of ablation study 單位:%
觀察AesGCN 和AttGCN 的表現可知,AesGCN和AttGCN 在3 個數據集上的性能相較于AEDGCN均出現不同程度的衰退,這表明僅基于先驗知識的情感增強語法圖和僅基于自主學習的注意力機制對詞語間依賴關系進行建模都不足以應對ABSA 任務的復雜情況,需要將二者結合才能夠充分發揮各自的優勢。此外,AttGCN 在Rest14 數據集上性能與AesGCN 相近,在Lap14 與Twitter 數據集上性能普遍優于AesGCN,且在Twitter 數據集上差距最為明顯,這說明在AEDGCN 中,具有正則化監督的自注意力機制對ABSA任務的貢獻更大,尤其是處理對語法知識不敏感的樣本時。
觀察AEDGCN-w/o-BiAffine 的表現可知,去除BiAffine模塊會導致模型性能大幅下降,同時AEDGCNw/o-BiAffine 的性能也與AesGCN、AttGCN 相近,這表明直接以雙通道的形式將先驗的情感知識與注意力機制進行簡單的結合依然不足以實現準確的依賴關系建模,需要利用通道間的信息交互實現二者的優勢互補。
從表4還可以觀察到,AEDGCN-w/o-RS、AEDGCNw/o-RD和AEDGCN-w/o-RO的性能相比AEDGCN 在3 個數據集上的準確率均出現了超過1個百分點的顯著下降,說明本文使用的3 種正則化器都能夠幫助注意力機制更為準確地捕捉語義相關性。其中AEDGCN-w/o-RS的下降幅度略大于AEDGCN-w/o-RD和AEDGCN-w/o-RO,證明了本文提出的語法正則化器能夠有效利用依存樹中包含的語法知識為模型的依賴關系建模提供幫助。值得注意的是,同AEDGCN-w/o-RS、AEDGCN-w/o-RD和AEDGCN-w/o-RO相比,AEDGCN 并沒有參數上的增加,表明本文使用的3 種正則化器能夠在不引入額外參數的情況下提高模型的表示學習能力,具有一定的高效性。
此外,通過對比AEDGCN-w/o-sentic和AEDGCN之間的性能差異,能夠證明情感增強圖卷積的有效性,即利用SenticNet 包含的情感知識對依存樹進行增強可以在很大程度上促進情感傾向較為明顯的詞語在表示學習過程中獲得更多關注。
總體上,完整的AEDGCN 模型實現了最佳的情感分類性能,有力證明了AEDGCN 中各模塊的有效性。
3.6 雙圖卷積模塊層數的影響
為探究DualGCN 模塊層數L對AEDGCN 模型性能的影響,本文在Lap14和Twitter數據集上評估了在L取值為1~6 時模型的準確率,實驗結果如圖2 所示。從圖2中不難看出,當堆疊2~3個DualGCN 模塊時,模型性能最好。一方面,當僅使用1 層DualGCN模塊時,每個節點只能與其一階鄰域產生信息交互;另一方面,當層數過多時,基于圖結構的多次信息交互將導致過平滑現象,即圖節點表示間缺乏區分性,同時參數的增加也會導致模型訓練難度增大以及泛化能力降低。
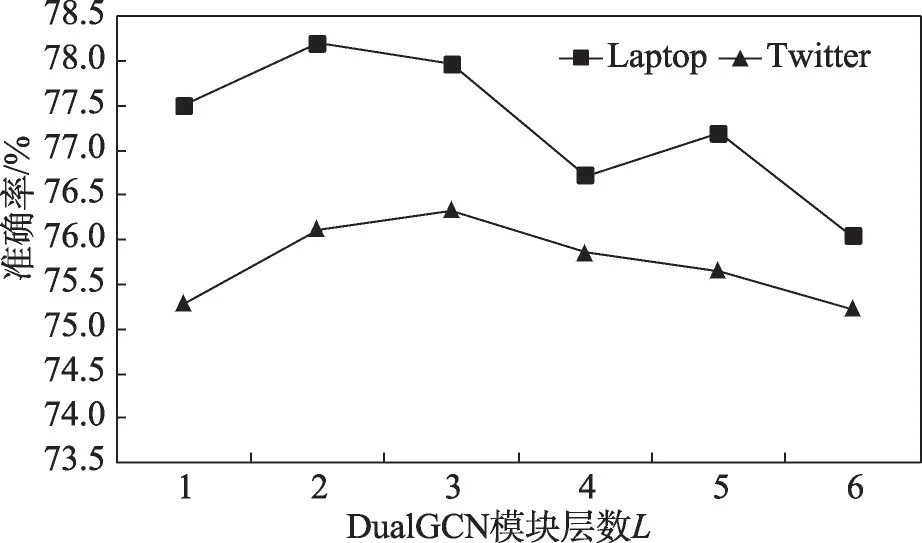
圖2 DualGCN模塊層數L的影響Fig.2 Effect of DualGCN module layer number L
3.7 案例研究
3.7.1 雙圖卷積模塊的有效性
本文基于AesGCN、AttGCN 和AEDGCN 模型對Rest14 數據集中的2 個案例進行分析以更加直觀地說明本文采用的雙圖卷積結構的有效性。結果如表5 所示,其中P、N 和O 分別代表積極、消極和中性情感。圖3、圖4展示了例句(a)、(b)的依存樹。圖5~圖7分別顯示了在處理例句(a)時,AesGCN中的情感增強語法圖以及AttGCN 和AEDGCN 中的注意力權重矩陣的可視化結果。圖8~圖10則分別展示了在處理例句(b)時AesGCN 中的情感增強語法圖以及AttGCN和AEDGCN中的注意力權重矩陣的可視化結果。

表5 AesGCN、AttGCN及AEDGCN的預測結果Table 5 Prediction results of AesGCN,AttGCN and AEDGCN

圖3 例句(a)依存樹Fig.3 Dependency tree of example sentence(a)

圖4 例句(b)依存樹Fig.4 Dependency tree of example sentence(b)
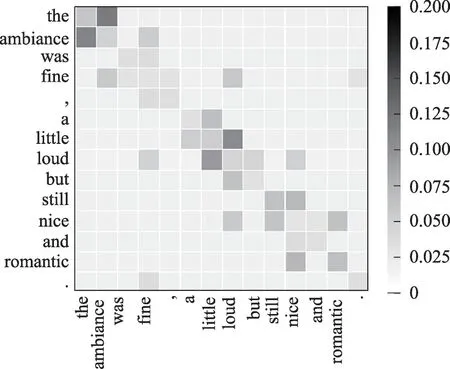
圖5 AesGCN中例句(a)的情感增強語法圖Fig.5 Affection-enhanced-syntax graph of example sentence(a)in AesGCN
由表5 可知,AEDGCN 和AttGCN 都準確識別出方面詞“ambiance”的情感極性為積極,而AesGCN 誤判為消極。觀察圖3 和圖5,本文認為可能的原因是“ambiance”與其對應意見詞間的語法距離過遠。具體來說,方面詞“ambiance”與意見詞“fine”“loud”的語法距離分別為1 和2,與意見詞“nice”“romantic”的語法距離則分別為3 和4,因此在使用2 層的GCN 操作時,“nice”“romantic”無法與方面詞產生信息交互,導致模型根據具有強消極情感的“loud”得出錯誤的預測結果。而由圖6、圖7 可知,AttGCN 和AEDGCN中的注意力機制能夠從全局的角度為方面詞捕捉對情感分類有利的語義關聯,因而給予了“fine”較多的關注,有效彌補了語法圖存在的缺陷。

圖6 AttGCN中例句(a)的注意力權重矩陣Fig.6 Attention weight matrix of example sentence(a)in AttGCN

圖7 AEDGCN中例句(a)的注意力權重矩陣Fig.7 Attention weight matrix of example sentence(a)in AEDGCN
由表5可知,AEDGCN和AesGCN都準確識別出方面詞“table”的情感極性為中性,而AttGCN 誤判為消極。觀察圖4、圖8,方面“table”和“hostess”的語法相關項幾乎不存在重疊,說明語法知識能夠有效區分句中不同方面對應的語法依賴關系。而從圖9 可以看出,AttGCN 中的注意力權重較為分散,且大部分詞語都給予“hostess”的意見詞“greeted”較多的關注,導致模型預測錯誤。此外由圖10 可知,相較于AesGCN,AEDGCN 中的注意力權重分布更為集中,且有效減少了來自“greeted”的干擾,原因在于通道間信息交互使得AEDGCN中的注意力機制能夠得到語法知識的指導。

圖8 AesGCN中例句(b)的情感增強語法圖Fig.8 Affection-enhanced-syntax graph of example sentence(b)in AesGCN

圖9 AttGCN中例句(b)的注意力權重矩陣Fig.9 Attention weight matrix of example sentence(b)in AttGCN

圖10 AEDGCN中例句(b)的注意力權重矩陣Fig.10 Attention weight matrix of example sentence(b)in AEDGCN
總體上,得益于雙圖卷積結構,本文提出的AEDGCN 能夠充分結合注意力機制與依存樹二者的優勢,實現了較為先進、穩定的ABSA性能。
3.7.2 情感知識的有效性
本文基于AEDGCN-w/o-sentic 和AEDGCN 模型對Rest14 數據集中的案例進行分析,以更好地理解情感知識在ABSA 任務中的重要性,結果如表6 所示。例句(c)的依存樹如圖11 所示。圖12、圖13 分別展示了在處理例句(c)時AEDGCN-w/o-sentic 中語法圖和AEDGCN中情感增強語法圖的可視化結果。

表6 AEDGCN-w/o-sentic及AEDGCN的預測結果Table 6 Prediction results of AEDGCN-w/o-sentic and AEDGCN

圖11 例句(c)依存樹Fig.11 Dependency tree of example sentence(c)
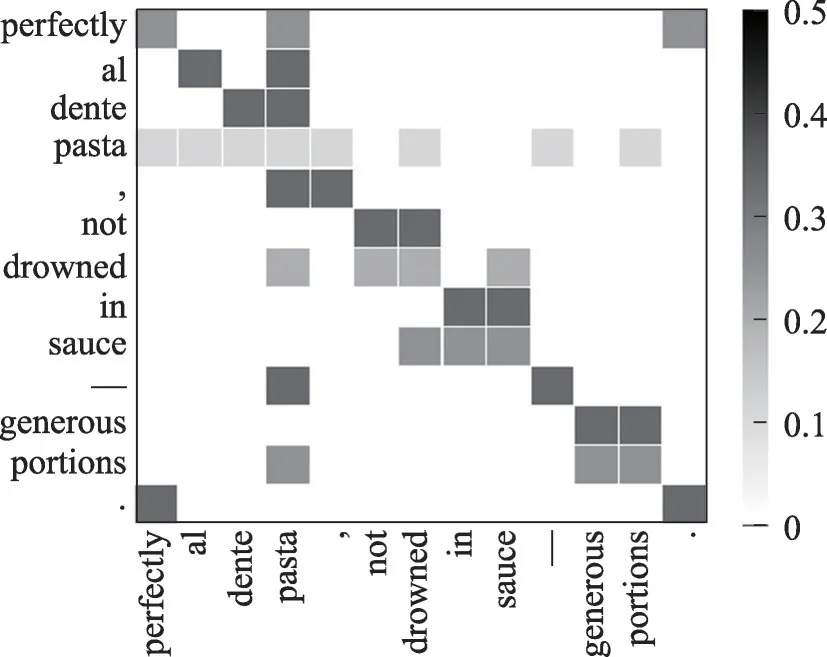
圖12 AEDGCN-w/o-sentic中例句(c)的語法圖Fig.12 Syntax graph of example sentence(c)in AEDGCN-w/o-sentic

圖13 AEDGCN中例句(c)的情感增強語法圖Fig.13 Affection-enhanced-syntax graph of example sentence(c)in AEDGCN
由表6 可知,AEDGCN 能夠準確識別出方面詞“pasta”的情感極性為積極,而AEDGCN-w/o-sentic誤判為消極。由圖11可知,例句(c)中存在大量與“pasta”具有直接或間接語法關聯的詞語。然而通過觀察圖12 展示的語法圖中“pasta”與“perfectly”各自所在行,方面詞“pasta”為其眾多相關詞賦予了相同的邊權重,意見詞“perfectly”則為方面詞“pasta”與無關詞“.”賦予了相同的邊權重,這類現象會導致模型難以辨別ABSA 任務所需的意見詞。觀察圖13 展示的情感增強語法圖中“pasta”與“perfectly”各自所在行,二者間的邊權重相較于其他無關詞得到了強調,有利于模型得出正確的預測結果。由此可見,情感知識可以幫助模型更好地關注對情感極性預測任務幫助較大的詞語。
4 結束語
本文提出了一種用于方面級情感分析的情感增強雙圖卷積模型AEDGCN。為了強調情感知識在ABSA任務中的作用,模型利用SenticNet包含的情感知識對依存樹生成的圖結構進行增強以獲取情感增強語法圖。模型基于情感增強的語法圖與自注意力機制分別構建AesGCN 和AttGCN,以幫助模型更為準確、高效地捕捉詞語間的語法及語義依賴關系,同時減輕了模型對依存樹解析質量的依賴程度。在三個公開數據集上的一系列實驗證明了模型在性能上的先進性和組成成分的可解釋性。未來的工作將繼續探索新的情感知識引入方式以更加真實地反映方面項及其對于意見項間情感聯系,以及如何更加準確、高效地對語義關系進行建模。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中國生殖健康(2020年5期)2021-01-18 02:59:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
家庭醫學(下半月)(2020年4期)2020-05-30 12:42:50
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
中國生殖健康(2018年5期)2018-11-06 07:15:40
光學精密工程(2016年6期)2016-11-07 09:07:19
發明與創新(2016年6期)2016-08-21 13:49:38
