最大化互信息約束的R-NLN高頻工件圖像分類模型
2024-01-03 13:32:34許知建歐陽(yáng)李毅李柏林熊鷹
機(jī)械制造與自動(dòng)化 2023年6期
許知建,歐陽(yáng),李毅,李柏林,熊鷹
(西南交通大學(xué) 機(jī)械工程學(xué)院,四川 成都 610031)
0 引言
現(xiàn)代工業(yè)生產(chǎn)中,通常采用基于零件的表面圖像進(jìn)行零件分類[1]。在卷積神經(jīng)網(wǎng)絡(luò)(convolutional neural network,CNN)[2]提出之前,常用人工設(shè)計(jì)的圖像特征,如尺度不變特征變換SIFT[3]、方向梯度直方圖HOG[4]、模板匹配[5]等完成零件的分類。但人為定義的特征,對(duì)于不同種類零件的泛化性較差。近年來(lái),隨著數(shù)據(jù)量的爆炸式增加和計(jì)算機(jī)硬件性能的飛速發(fā)展,基于CNN的深度學(xué)習(xí)模型在圖像分類領(lǐng)域取得了重要的地位。但當(dāng)樣本數(shù)量較少時(shí),CNN無(wú)法將訓(xùn)練集的數(shù)據(jù)合理泛化到測(cè)試集。基于此,研究者提出了小樣本學(xué)習(xí)(few-shot learning,FSL)[6]。而高頻元件精密加工工件(簡(jiǎn)稱為高頻工件)因其需定制而產(chǎn)量極低,是該問(wèn)題下典型的工程應(yīng)用對(duì)象。
為使小樣本模型能夠有效提取圖像特征,VILALTA等[7]提出了基于元學(xué)習(xí)的模型,在識(shí)別新類之前,只訓(xùn)練模型提取特征的能力,這類模型被稱為特征提取器。為使模型在提取特征后具有分析特征的能力,研究者提出了基于度量的分類算法[8],在特征提取器之后設(shè)置一個(gè)度量器(measurer),在統(tǒng)一的特征空間中比較支持集(support set)樣本特征和查詢集(query set)樣本特征之間的距離,最后輸出類別概率分布以完成分類。
文獻(xiàn)[9]的實(shí)驗(yàn)結(jié)果表明,對(duì)于自然圖像的分類,傳統(tǒng)小樣本模型的分類效果次于傳統(tǒng)CNN模型。2018年,WANG等[10]提出了非局部網(wǎng)絡(luò)(non-local network,NLN),通過(guò)非局部操作提取圖像的全局特征,該網(wǎng)絡(luò)被廣泛應(yīng)用于小樣本目標(biāo)識(shí)別和分類領(lǐng)域。YUE等[11]將NLN應(yīng)用于細(xì)粒度目標(biāo)識(shí)別和視頻分類,取得了良好的效果。LIU等[12]提出使用NLN進(jìn)行圖像恢復(fù),將NLN嵌入到循環(huán)神經(jīng)網(wǎng)絡(luò)(recurrent neural network,RNN),在訓(xùn)練集更小的情況下取得了較好的性能。黃立勤等[13]提出一種NLN模塊結(jié)合非局部卷積神經(jīng)網(wǎng)絡(luò)和圖卷積網(wǎng)絡(luò),應(yīng)用于肺動(dòng)靜脈的自動(dòng)分離。然而,NLN只完成了由全局到局部的全局提取部分,并且高頻工件圖像還存在類間差異小、全局噪聲大的特點(diǎn),所以要求模型不僅可以提取任務(wù)特征,還具備較好的魯棒性。
因此,本文提出一種基于最大化互信息(mutual information,MI)約束的關(guān)聯(lián)非局部網(wǎng)絡(luò)(related non-local network,R-NLN)高頻工件分類模型。R-NLN將查詢(支持)樣本的全局特征和局部特征(local feature),通過(guò)NLN進(jìn)行交叉關(guān)聯(lián)以獲得適應(yīng)于查詢?nèi)蝿?wù)的任務(wù)特征;又通過(guò)在損失函數(shù)中加入互信息熵正則項(xiàng),最大化約束任務(wù)特征和局部特征之間的互信息。本文的主要貢獻(xiàn)有:
1)提出了一種基于關(guān)聯(lián)特征的R-NLN特征提取器,完成對(duì)工件表面圖像自適應(yīng)任務(wù)特征的提取;
2)提出了一種將最大化互信息作為約束條件的損失函數(shù),提高了模型的魯棒性。
1 模型結(jié)構(gòu)和相關(guān)理論
1.1 R-NLN總體結(jié)構(gòu)
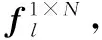

圖1 R-NLN總體結(jié)構(gòu)

1.2 基于NLN的任務(wù)特征提取器ξ2
ξ2采用了NLN作為模型的嵌入單元來(lái)提取圖像的任務(wù)特征。傳統(tǒng)卷積核普遍選用3×3或5×5的規(guī)格,通過(guò)遍歷樣本上的所有區(qū)域以提取該區(qū)域的特征。這類卷積核可有效降低樣本的維度,減少模型權(quán)重的參數(shù)規(guī)模,從而保證訓(xùn)練的可行性。但是由于自身只能提取局部區(qū)域的特征,忽略了遠(yuǎn)距離像素點(diǎn)之間的關(guān)系,所以難以提取全局特征,因此把這樣的網(wǎng)絡(luò)稱為局部網(wǎng)絡(luò)。
與局部網(wǎng)絡(luò)相反,非局部網(wǎng)絡(luò)的特點(diǎn)是不受卷積核規(guī)格的限制,采用了非局部單元(non-local block)擴(kuò)大特征參考的區(qū)域。非局部單元的特征提取如下式所示:
(1)
式中:向量x是指輸入的圖像特征;i和j分別是特征上的i位置和j位置;yi是在i位置上的全局特征值;xi是在i位置的原始特征值;xj是在j位置的原始特征值;f(xi,xj)是計(jì)算圖像上i位置和j位置的關(guān)聯(lián)度的線性函數(shù);g(xj)是將j位置的原始特征值線性映射為全局特征值的函數(shù);Θ(x)作為歸一化函數(shù)將輸入映射到統(tǒng)一的特征空間。
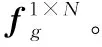
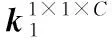

圖2 全局特征提取單元
(2)
(3)
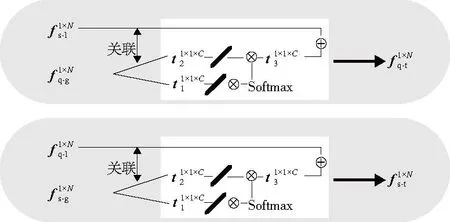
圖3 任務(wù)特征提取單元
1.3 基于余弦相似度的度量器Ω
(4)
式中:s是相似度函數(shù)similarity;i代表向量的第i維。
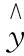
(5)
式中i和j分別表示第i和第j個(gè)樣本;d為余弦距離函數(shù)。
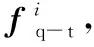
(6)
1.4 基于最大化互信息約束的損失函數(shù)
在ξ2提取任務(wù)特征的過(guò)程中,會(huì)受到遍布于高頻工件表面的全局噪聲干擾,又由于樣本數(shù)量稀少,模型在訓(xùn)練后期極有可能對(duì)噪聲信號(hào)產(chǎn)生過(guò)擬合。但是ξ1提取的局部特征都是低維度特征,受到干擾的幅度較小,所以考慮在損失函數(shù)中利用局部特征抗干擾性較好的特點(diǎn)構(gòu)建相關(guān)正則項(xiàng),以約束模型在訓(xùn)練時(shí)參考局部特征和任務(wù)特征之間的互信息,從而預(yù)防模型對(duì)噪聲產(chǎn)生過(guò)擬合,提高R-NLN模型的魯棒性。本文采用交叉熵?fù)p失函數(shù):
(7)
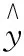
基于信息熵理論,互信息被定義為:對(duì)于兩個(gè)隨機(jī)變量X和Y,如果其聯(lián)合分布為p(x,y),邊緣分布為p(x)和p(y),則X和Y的互信息分布I(X;Y)為
(8)
在R-NLN中,需要最大化局部特征向量fl和任務(wù)特征向量ft的互信息,由于信息熵是對(duì)一個(gè)隨機(jī)變量不確定性的度量,所以使用信息熵來(lái)度量互信息的大小。對(duì)于一個(gè)離散型的隨機(jī)變量X~p(x),信息熵被定義為
(9)
上式表明信息熵是隨機(jī)變量X的函數(shù)log(1/p(X))的期望。熵的值越大,表示該隨機(jī)變量的離散程度越大。本文使用互信息熵的大小來(lái)描述局部特征和任務(wù)特征之間的互有信息量,當(dāng)局部特征和任務(wù)特征之間的重合度較大時(shí),互信息熵LMI越小,反之亦然。結(jié)合式(8)和式(9),提出互信息熵正則項(xiàng)lMI:
(10)
最后基于交叉熵?fù)p失函數(shù)和互信息正則項(xiàng),提出最大化互信息約束的損失函數(shù)Loss:
(11)
式中:λ是用于平衡交叉熵和互信息熵正則項(xiàng)的超參數(shù);N是查詢集樣本的數(shù)量。
通過(guò)梯度反向傳播更新特征提取器ξ2中卷積核組K2={ki|k∈R1×1×c,i=1,2,3}的權(quán)重W:
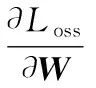
(12)
W=W-η(?lc-e+λ?lMI)
(13)
式中η是控制每一次反向傳播中的梯度下降速度的超參數(shù),即學(xué)習(xí)率。
在交叉熵?fù)p失函數(shù)中,加入了基于互信息熵的正則化項(xiàng)后,參數(shù)的權(quán)重變化將會(huì)受到互信息的約束,避免了訓(xùn)練過(guò)程中受到干擾信號(hào)的影響而導(dǎo)致的過(guò)擬合,進(jìn)而提高了R-NLN模型的魯棒性。
2 實(shí)驗(yàn)
2.1 數(shù)據(jù)集和實(shí)驗(yàn)環(huán)境
采用miniImageNet數(shù)據(jù)集和高頻元件精密加工工件數(shù)據(jù)集(簡(jiǎn)稱為高頻工件數(shù)據(jù)集)進(jìn)行實(shí)驗(yàn)。其中,miniImageNet數(shù)據(jù)集包含100類的自然圖像,每類包含600張彩色圖像,共有60 000張圖像樣本。高頻工件數(shù)據(jù)集是科技專項(xiàng)下制作的數(shù)據(jù)集,包括50類小樣本工件圖像,每類包含15張彩色圖像,共有750張?jiān)紙D像樣本,部分樣本如圖4所示。

圖4 部分高頻工件數(shù)據(jù)集實(shí)例
由于高頻工件的樣本較小,所以對(duì)該數(shù)據(jù)集采用了隨機(jī)水平/垂直翻轉(zhuǎn)將數(shù)據(jù)集擴(kuò)大2倍。采用16∶4∶5的比例設(shè)置驗(yàn)證集、訓(xùn)練集、測(cè)試集。表1展示了數(shù)據(jù)集的基本情況。
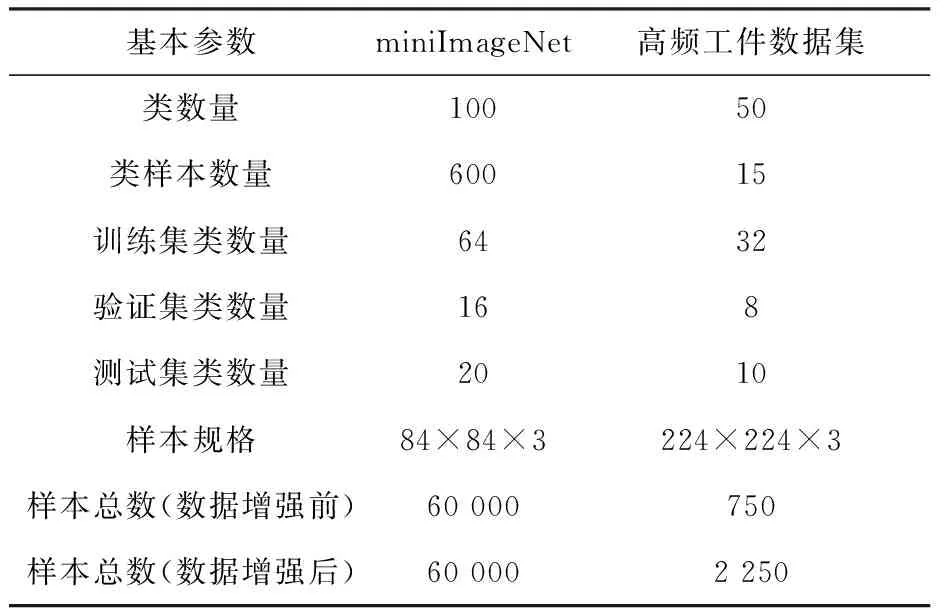
表1 數(shù)據(jù)集基本情況
實(shí)驗(yàn)軟件采用PyTorch深度學(xué)習(xí)框架,硬件采用Intel? CoreTM I5-9400F CPU@2.90Ghz、NVIDIA Geforce GTX 1080 GPU、32G運(yùn)行內(nèi)存的工作站。訓(xùn)練和測(cè)試階段都基于小樣本學(xué)習(xí)下的標(biāo)準(zhǔn)方法N-wayK-shot進(jìn)行,所有實(shí)驗(yàn)均采用Adam優(yōu)化算法加速模型的訓(xùn)練速率,超參數(shù)λ和η初始值分別設(shè)置為0.1和0.01。
2.2 分類性能實(shí)驗(yàn)
高頻工件在表面紋理、特征形狀以及顏色上都未表現(xiàn)出較大差異,屬于語(yǔ)義差別較小的圖像。而自然圖像在上述方面的差異較大。為探究R-NLN的性能是否依賴于類間的語(yǔ)義性差別大小,選取自然圖像數(shù)據(jù)集和高頻工件圖像數(shù)據(jù)集作對(duì)照實(shí)驗(yàn)。
對(duì)于自然圖像分類,使用小樣本領(lǐng)域的經(jīng)典數(shù)據(jù)集miniImageNet進(jìn)行分類測(cè)試。在訓(xùn)練過(guò)程中,從38 400個(gè)訓(xùn)練集樣本里隨機(jī)抽取1 000個(gè)任務(wù)樣本,每個(gè)任務(wù)即為1個(gè)mini-batch,并且每10個(gè)任務(wù)作為Epoch,所以一共有100個(gè)Epoch,即訓(xùn)練次數(shù)為100次。
對(duì)于高頻工件圖像分類,使用高頻工件數(shù)據(jù)集進(jìn)行分類測(cè)試。在訓(xùn)練過(guò)程中,從1 440個(gè)訓(xùn)練集樣本里隨機(jī)抽取1 000個(gè)任務(wù)樣本,每個(gè)任務(wù)即為1個(gè)mini-batch。為了完成對(duì)照實(shí)驗(yàn),所以選取每10個(gè)任務(wù)作為1個(gè)Epoch,即訓(xùn)練次數(shù)同樣為100次。
過(guò)程中采取跨任務(wù)機(jī)制訓(xùn)練R-NLN模型,在每個(gè)5-way 1-shot(或5-way 5-shot)任務(wù)中,除了每個(gè)類的1(或5)張圖像外,還會(huì)從每個(gè)類別中隨機(jī)抽取4張圖像作為查詢集。即對(duì)于一個(gè)5-way 1-shot(或5-way 5-shot)任務(wù),每一個(gè)訓(xùn)練集中會(huì)有5(或25)張支持集圖像和25張查詢集圖像。
采用小樣本領(lǐng)域的3類主流算法進(jìn)行對(duì)比實(shí)驗(yàn),包括:基于遷移學(xué)習(xí)的方法SSMN[14]和PPA[15];基于元學(xué)習(xí)的方法MN[16]、PN[17]、RN[18]、MAML[19]和AAN[20];基于圖卷積網(wǎng)絡(luò)的方法TPN[21]和GCN[22]。采用平均分類準(zhǔn)確率mAp來(lái)評(píng)價(jià)各種算法的性能。在測(cè)試過(guò)程中,從測(cè)試數(shù)據(jù)集中隨機(jī)抽取1 000個(gè)任務(wù)樣本,以重復(fù)10次的Top-1的平均分類準(zhǔn)確率作為最終的評(píng)價(jià)指標(biāo)。在訓(xùn)練中為了優(yōu)化梯度下降過(guò)程,每訓(xùn)練1個(gè)Epoch則使學(xué)習(xí)率減小1/2。由于采用了端到端的訓(xùn)練形式,所以過(guò)程中也無(wú)需微調(diào)超參數(shù)。實(shí)驗(yàn)結(jié)果如表2所示。
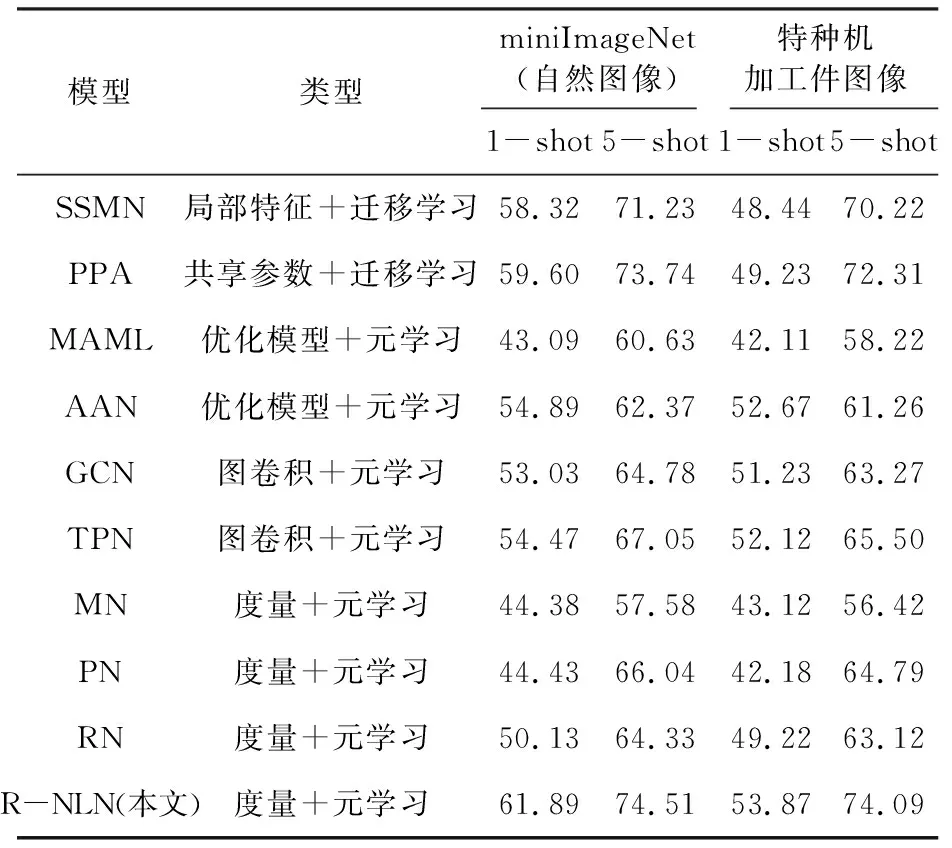
表2 分類性能實(shí)驗(yàn)結(jié)果 單位:%
從表2中可以看出,以5-way 5-shot為參考,在自然圖像miniImageNet分類中,R-NLN的mAp比遷移學(xué)習(xí)算法高2.0%,比圖卷積算法高8.6%,比其他元學(xué)習(xí)方法高11.8%。在高頻工件圖像分類中,R-NLN的mAp比遷移學(xué)習(xí)算法高2.8%,比圖卷積算法高9.7%,比其他元學(xué)習(xí)算法高12.6%。
因此可知,由于任務(wù)特征的提取和互信息約束的共同作用,提高了模型對(duì)于自然圖像中關(guān)鍵特征的學(xué)習(xí)能力,在不依賴于類間語(yǔ)義距離的情況下對(duì)于復(fù)雜語(yǔ)義圖像的理解有比較顯著的提升。在高頻工件圖像中,R-NLN在mAp上不僅比同類的元學(xué)習(xí)算法高6.1%,而且比圖卷積算法高9.6%,比遷移學(xué)習(xí)算法高5.0%。這是因?yàn)樵趽p失函數(shù)上采用了互信息約束,對(duì)樣本表面噪聲的抗干擾能力做了特定優(yōu)化,所以模型的魯棒性有一定的提升。
2.3 消融實(shí)驗(yàn)
R-NLN主要通過(guò)兩點(diǎn)來(lái)提高小樣本高頻工件的分類準(zhǔn)確率:1)提取基于NLN的全局特征和局部特征的自適應(yīng)任務(wù)特征;2)通過(guò)損失函數(shù)的互信息約束減少模型對(duì)于元件表面噪聲的擬合。為了能夠分析任務(wù)特征提取和互信息約束對(duì)于各自模型的提升,使用控制變量法對(duì)模型進(jìn)行了消融實(shí)驗(yàn),分別驗(yàn)證了以上兩點(diǎn)的有效性。
實(shí)驗(yàn)以5-way 1-shot(5-shot)為基準(zhǔn),采用16∶4∶5的比例設(shè)置驗(yàn)證集、訓(xùn)練集、測(cè)試集。在訓(xùn)練過(guò)程中,從1 440個(gè)訓(xùn)練集樣本里隨機(jī)抽取1 000個(gè)任務(wù)樣本,每個(gè)任務(wù)即為1個(gè)mini-batch,選取每10個(gè)任務(wù)作為1個(gè)Epoch,即訓(xùn)練次數(shù)為100次。使用RN和PN作為對(duì)照組,進(jìn)行了4組實(shí)驗(yàn):①只提取任務(wù)特征;②只進(jìn)行互信息約束;③不提取任務(wù)特征+不進(jìn)行互信息約束;④同時(shí)進(jìn)行任務(wù)特征提取和互信息約束。實(shí)驗(yàn)結(jié)果如表3所示。

表3 在高頻工件數(shù)據(jù)集上的消融實(shí)驗(yàn)結(jié)果 單位:%
從表3的實(shí)驗(yàn)結(jié)果可以看出:以5-shot的數(shù)據(jù)為基準(zhǔn),通過(guò)比較對(duì)照組PN、RN及①和③,可知R-NLN中的任務(wù)特征提取模塊提高了10.1%的準(zhǔn)確率。因?yàn)槿蝿?wù)特征的本質(zhì)是基于全局特征和局部特征的關(guān)聯(lián)度而提取的細(xì)粒度特征,它對(duì)于查詢樣本具有更好的適應(yīng)性,在小樣本條件下由于支持樣本數(shù)量少,模型需要盡可能地理解樣本,而提取任務(wù)特征在這樣的情況下能顯著提高模型的分類性能。
通過(guò)比較對(duì)照組PN、RN及②和③,可知,互信息約束在沒(méi)有進(jìn)行任務(wù)特征提取的條件下,無(wú)法顯著提高模型的分類準(zhǔn)確率。因?yàn)榛バ畔⒓s束本身是通過(guò)對(duì)于局部特征和任務(wù)特征的互信息來(lái)消除模型對(duì)于噪聲的擬合,如果不進(jìn)行任務(wù)特征的提取,那么實(shí)際上任務(wù)特征就退化為全局特征,相當(dāng)于約束了全局和局部特征之間的互信息,失去了任務(wù)特征對(duì)于不同任務(wù)之間噪聲的適應(yīng)性,所以并不能顯著降低模型對(duì)于噪聲的擬合。
通過(guò)對(duì)比①和④可知,互信息約束在提取任務(wù)特征的前提下提高了4.3%的準(zhǔn)確率。原因是最大化互信息約束有效提高了模型的魯棒性,彌補(bǔ)了全局特征容易擬合噪聲的短板。
綜上可知,本文提出的“任務(wù)特征提取”和“互信息約束”各司其職,一方面提高了模型對(duì)于任務(wù)特征的提取能力,另一方面通過(guò)最大化互信息約束充分利用了局部特征中的優(yōu)點(diǎn),提高了模型的魯棒性,所以R-NLN模型可以獲得更高的分類精度。
3 結(jié)語(yǔ)
本文針對(duì)高頻元件精密加工工件樣本稀缺難以訓(xùn)練傳統(tǒng)CNN模型的問(wèn)題,提出了一種最大化互信息約束的R-NLN高頻工件圖像分類模型。R-NLN將查詢(支持)樣本的全局特征和局部特征通過(guò)NLN進(jìn)行交叉關(guān)聯(lián)以獲得適應(yīng)于查詢?nèi)蝿?wù)的任務(wù)特征,從而提高了模型對(duì)支持樣本和查詢樣本之間重點(diǎn)關(guān)聯(lián)部分的提取能力。此外,針對(duì)高頻工件圖像上全局噪聲信號(hào)較為明顯的特點(diǎn),通過(guò)在損失函數(shù)中添加互信息熵正則項(xiàng),以實(shí)現(xiàn)在訓(xùn)練過(guò)程中最大化任務(wù)特征和局部特征之間互信息的約束,完成模型的魯棒性優(yōu)化。對(duì)miniImageNet和高頻工件數(shù)據(jù)集的實(shí)驗(yàn)結(jié)果表明,該模型的分類準(zhǔn)確率顯著高于其他主流的小樣本分類模型。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
