自動目標識別評價方法發(fā)展述評
2024-01-02 12:19:18傅瑞罡
雷達學(xué)報 2023年6期
何 峻 傅瑞罡 付 強
(國防科技大學(xué)電子科學(xué)學(xué)院自動目標識別全國重點實驗室 長沙 410073)
1 引言
信息化時代中對于深層次信息的需求日益迫切,目標識別就是根據(jù)某物體呈現(xiàn)的特征進行分析和判斷,從而達到辨認和識別其身份和屬性的目的。當這一過程不需要人工參與而只由機器自動完成時,就稱該過程為自動目標識別(Automatic Target Recognition,ATR)。一旦將此項重要的任務(wù)交由機器來自主完成,應(yīng)該如何評價ATR所取得的實際作用?
由于ATR技術(shù)與模式識別、人工智能等技術(shù)有著許多共同點,因此雷達、光學(xué)等信息處理研究領(lǐng)域中都包含ATR這一研究方向,許多學(xué)術(shù)機構(gòu)及期刊會議也設(shè)有ATR專欄。IEEE很早就從圖像處理角度定義過ATR:自動目標識別一般指通過計算機處理來自各種傳感器的數(shù)據(jù),實現(xiàn)自主或輔助目標的檢測和識別[1]。
很多學(xué)者系統(tǒng)梳理過ATR的概念與技術(shù)發(fā)展。例如,文獻[2]對雷達ATR技術(shù)現(xiàn)狀與發(fā)展認識進行了總結(jié),文獻[3]從工程視角進一步對ATR技術(shù)發(fā)展進行了評述。ATR技術(shù)研究需要多個學(xué)科方向進行交叉融合[4],而測試與評價對任何技術(shù)領(lǐng)域的發(fā)展都是非常重要的。隨著ATR技術(shù)的快速發(fā)展,ATR評價方法的研究也逐步得到重視。例如,Ross等人[5—11]在歷年SPIE會議上發(fā)表了一系列論文闡述SAR ATR評價的理念與方法,李彥鵬等人[12—14]對ATR效果評估進行了深入研究。但從總體來看,近年來通用性的評價方法研究較為少見。ATR評價方法研究經(jīng)常被歸屬于某個相關(guān)技術(shù)領(lǐng)域,點綴在眾多的圖形圖像[15,16]、信息處理[17,18]、系統(tǒng)工程[19,20],乃至運籌管理[21,22]等領(lǐng)域的期刊或會議論文集中。
專門總結(jié)ATR評價方法的綜述研究更為少見,更多的是在論文、專著中作為ATR技術(shù)發(fā)展的組成部分予以介紹。例如,文獻[12,23—27]雖然都以ATR評價方法作為主題,但研究重點在于提出新的評價方法;文獻[13]對ATR評價進行了介紹,但主要成果是為ATR系統(tǒng)的性能評價提供綜合性分析工具。文獻[28]是一篇有關(guān)ATR算法評價方法的綜述文獻,更多的是對上述學(xué)位論文及專著相關(guān)部分的總結(jié)。十多年來,ATR技術(shù)領(lǐng)域有了新的發(fā)展,同時給ATR評價帶來了新的問題,但是該領(lǐng)域缺乏最新的綜述文獻對這些新進展進行歸納與總結(jié)。
本文面向通用的ATR算法與系統(tǒng),不僅梳理和總結(jié)了ATR技術(shù)及其評價方法的發(fā)展,還對ATR評價方法研究背后的基礎(chǔ)理論、方法模型等開展了分析討論,并針對當前方法研究中存在的關(guān)鍵問題給出了自己的見解,旨在為科學(xué)、有效的ATR算法與系統(tǒng)評價提供方法借鑒和啟發(fā)引導(dǎo)。
2 ATR技術(shù)發(fā)展回顧
2.1 統(tǒng)計模式識別應(yīng)用
20世紀80~90年代的ATR研究基本可以看作統(tǒng)計模式識別理論在具體應(yīng)用領(lǐng)域中的探索實踐,處理方法上沿襲了傳統(tǒng)的特征提取與選擇、模板建庫、分類器設(shè)計、匹配決策等經(jīng)典模式識別環(huán)節(jié)。特征提取在統(tǒng)計模式識別中尤為關(guān)鍵,這也是早期ATR研究的重點內(nèi)容。
以雷達對空中目標的識別為例,目標信號特征包括飛機的動力構(gòu)件調(diào)制特征、目標諧振區(qū)極點特征、極化散射矩陣的不變量、微動特征,以及雷達成像時散射中心、結(jié)構(gòu)特征等[29]。目標特征提取需要大量的實測數(shù)據(jù),而當時的數(shù)據(jù)采集手段較為有限,造成用于匹配模板的標準狀態(tài)與目標的實際狀態(tài)之間存在較大差異,導(dǎo)致這一時期ATR系統(tǒng)的實用性較差。
2.2 基于模型或信息輔助的技術(shù)
當人們認識到模板匹配方法的局限性之后,開始嘗試采用模型預(yù)測來應(yīng)對實際情況中目標變化的多樣性。基于模型的分類識別逐漸成為當時ATR研究的主流技術(shù)。其中,頗具代表性的當屬美國國防部高級研究計劃局(Defense Advanced Research Projects Agency,DARPA)和美國空軍實驗室(Air Force Research Laboratory,AFRL)聯(lián)合開展的MSTAR (Moving and Stationary Target Acquisition and Recognition)計劃[30],研制出較為成熟的基于模型SAR ATR系統(tǒng)。
針對傳統(tǒng)ATR系統(tǒng)難以引入外部信息、缺少對目標相關(guān)知識利用等問題,文獻[31]建議采用知識推理輔助的目標識別方法。這類方法中,基于上下文知識的目標識別技術(shù)首先得到了關(guān)注和深入研究[32]。隨后,本體論[33]、可視化[34]、數(shù)據(jù)融合[35]等方法被陸續(xù)引入。ATR研究的范圍逐步提升到更廣泛的全局信息利用層面。
2.3 深度學(xué)習(xí)方法
早期基于神經(jīng)網(wǎng)絡(luò)的ATR技術(shù)大多采用小規(guī)模的網(wǎng)絡(luò)分類器[36—39]。隨著深度學(xué)習(xí)研究興起,深度學(xué)習(xí)方法已成為當前ATR技術(shù)的一個研究熱點[40—42]。深度卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Networks,CNN)的成功[43]同樣在聲吶圖像、雷達圖像的識別應(yīng)用中得到了驗證[44—46]。深度學(xué)習(xí)方法在信息處理過程中不再嚴格區(qū)分“特征提取”與“分類識別”,而是直接完成目標識別的全過程[47]。
目前,CNN已被廣泛應(yīng)用于一維距離像識別[48—50]、SAR圖像識別[51—55]和紅外圖像識別[56—58]等場景,并且被證明在提升泛化性能方面有不錯的表現(xiàn)[59],但有些場景中也容易受到噪聲干擾[60,61]和欺騙[62]等因素影響。另外,雖然遷移學(xué)習(xí)[63]在SAR圖像ATR的應(yīng)用中取得了一定成功[64—66],但人們還是對深度學(xué)習(xí)ATR方法的可解釋性存在著一定的疑惑[67]。
2.4 困難與制約
從20世紀50年代雷達目標識別領(lǐng)域研究[68]開始,ATR技術(shù)已經(jīng)取得了長足的進步。然而,要真正解決目標識別問題,ATR技術(shù)仍面臨許多困難與挑戰(zhàn)。除了目標識別問題本身的復(fù)雜性之外,ATR領(lǐng)域缺乏系統(tǒng)、科學(xué)的性能測試與評價方法也是制約其技術(shù)發(fā)展的瓶頸問題之一。
ATR評價方法研究正是要致力于改變這一現(xiàn)狀,對ATR算法或系統(tǒng)進行性能評價與預(yù)測,使得ATR研究具備成為真正科學(xué)領(lǐng)域的基本要素[4]。文獻[69]是有關(guān)ATR發(fā)展的較早評述,其中對于ATR評價重要性和發(fā)展的預(yù)測已被實踐所證明。為構(gòu)建實用化的ATR系統(tǒng),必須先建立起有效的ATR評價方法及性能測試系統(tǒng)[70]。
3 ATR評價方法研究成果
ATR評價實際上貫穿于整個ATR研制過程。以研制一個ATR算法為例,圖1[71]給出了ATR評價在各個階段的不同內(nèi)容。

圖1 典型ATR研制與測試生命周期[71]Fig.1 A typical ATR development and test life cycle[71]
無論處于哪個階段,ATR算法的評價都離不開性能指標定義、測試條件構(gòu)建和推斷與決策等環(huán)節(jié)。本節(jié)分別歸納總結(jié)這幾方面的研究成果。
3.1 性能指標定義
識別性能對于ATR算法來說無疑非常重要,許多文獻中提到的ATR性能指標就是指衡量其識別能力的指標。至于泛化能力等其他方面的能力,通常采用分析某個關(guān)鍵識別指標(如識別率)隨測試條件變化的下降程度來度量。故本文重點闡述ATR識別性能指標。
混淆矩陣(Confusion Matrix)從模式分類研究時期起就被廣泛使用,通常記錄成一張由行和列構(gòu)成的二維表格。單元格用下標(i,j)定位,記錄目標i被自動判別為目標j的次數(shù)或比率。配合彩色或灰度幅度值,混淆矩陣能夠更加直觀地展示目標識別的結(jié)果,如圖2[72]所示。
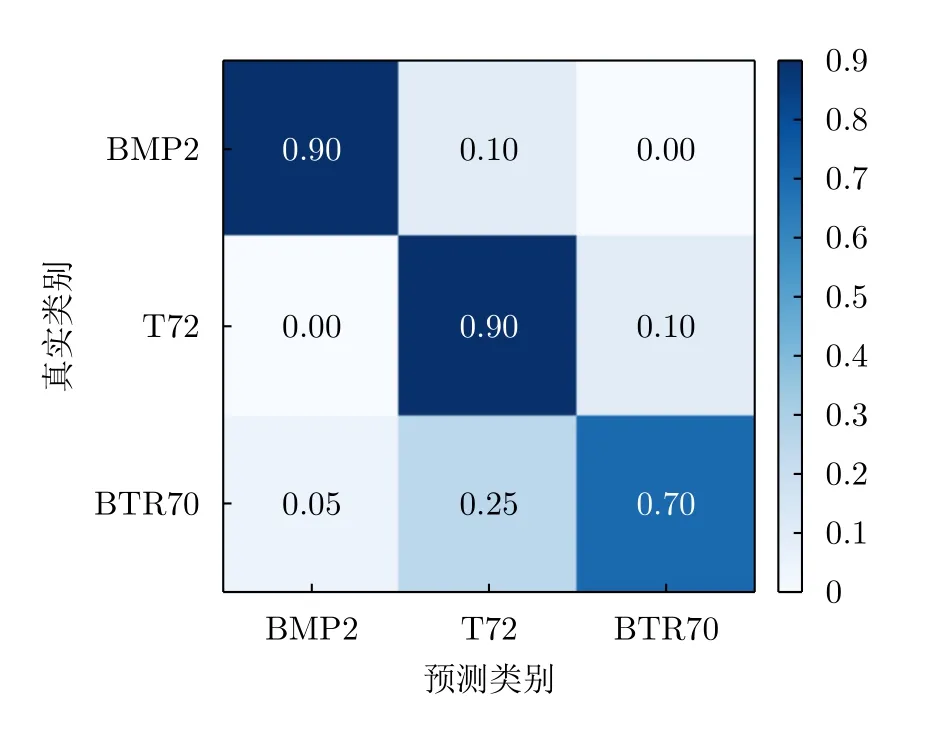
圖2 3類目標識別結(jié)果混淆矩陣[72]Fig.2 Classification result map of three types of targets[72]
對于m類目標的情況,混淆矩陣至少包含了m2個單元格,詳細記錄了ATR算法對于每一類目標正確識別及混淆判別的結(jié)果。當目標類型數(shù)據(jù)較多時,混淆矩陣難以直觀展示測試結(jié)果。對此,可以利用混淆矩陣推算出另一類被經(jīng)常使用的評價指標—概率型指標,反映ATR過程中對某個目標類別的正確/錯誤判別概率,如檢測概率(Probability of Detection,PD)、虛警概率(Probability of False Alarm,PFA)、識別率等。
如果說概率型指標是以數(shù)的形式對混淆矩陣進行簡化,那么ROC (Receiver Operating Characteristic)曲線就是用圖的形式對PD和PFA之間存在的約束關(guān)系進行描述。ROC曲線最早應(yīng)用于雷達檢測領(lǐng)域,如圖3[73]所示。

圖3 雙正態(tài)分布生成的ROC曲線[73]Fig.3 Sample N-N ROC curve generation[73]
圖3給出了存在高斯白噪聲(非目標)n情況下,對同樣服從正態(tài)分布的信號(目標)sn依據(jù)檢測門限x0得到的ROC曲線。顯然,越大的曲線下面積(Area Under the Curve,AUC)意味著ATR系統(tǒng)在保持低虛警概率P(S/n)的同時,具有更高的檢測概率P(S/sn)。AUC因而成為評價“目標-非目標”這種二分類ATR算法性能的最常見評價指標,并逐步從雷達ATR領(lǐng)域擴展到其他領(lǐng)域,如醫(yī)學(xué)病理圖像ATR診斷性能評價[74,75]。文獻[76]對一些基于ROC曲線的ATR算法性能評價方法進行了較為系統(tǒng)的總結(jié)。
采用深度學(xué)習(xí)方法的ATR算法,更傾向于采用由精確率(Precision)和召回率(Recall)所構(gòu)成的P-R曲線[77]。為避免P-R曲線因為樣本的排序而出現(xiàn)搖擺,一般還要對其進行平滑處理,如圖4所示。

圖4 實際P-R曲線與平滑后P-R曲線Fig.4 Actual and smoothed P-R Curve
與AUC類似,平均精度(Average Precision,AP)由P-R曲線所衍生,表示不同召回率下精確率的平均值。至于如何對P-R曲線做離散化取值,如何計算平滑后的P-R曲線下面積,都有一系列相應(yīng)的規(guī)范要求,具體方法可以參考文獻[78,79]。此外,P-R曲線雖然同樣是針對某類目標而言的,但可以通過對各類目標的AP值再取平均值(mean AP,mAP)來實現(xiàn)多分類的ATR算法性能評價。因此,AUC也可以說是mAP的特例。
綜上所述,ATR算法識別性能的評價指標主要包括:以表格形式記錄的混淆矩陣,根據(jù)目標識別階段定義的概率型指標,以及ROC曲線、P-R曲線等圖形及衍生指標。表1總結(jié)了常見的ATR識別性能指標。

表1 常見ATR識別性能指標Tab.1 Common ATR performance measures
3.2 測試條件構(gòu)建
ATR技術(shù)最終將應(yīng)用于真實環(huán)境,需要將ATR算法加載到實際系統(tǒng)中進行檢驗。MSTAR計劃將SAR ATR系統(tǒng)所處的條件分為4類[9]:ATR系統(tǒng)面臨的真實環(huán)境稱為工作條件(Operation Conditions,OC),性能評價時所構(gòu)建的測試條件(Test Condtions)只是OC的子集。用于算法訓(xùn)練的數(shù)據(jù)樣本代表了ATR系統(tǒng)的訓(xùn)練條件(Training Condtions)。此外,對于模型驅(qū)動的ATR系統(tǒng)還可以定義其建模條件(Modeled Condtions)。上述4類條件之間的關(guān)系如圖5(a)所示;而ATR系統(tǒng)評價其實只能考察ATR系統(tǒng)的準確性(Accuracy)、穩(wěn)健性(Robustness)和擴展性(Extensibility),三者共同反映了部分的有效性(Utility),如圖5(b)所示。

圖5 MSTAR計劃中的訓(xùn)練與測試條件[9]Fig.5 Training and testing conditions in MSTAR program[9]
為了更好地評價ATR系統(tǒng)的擴展性,AFRL進一步將OC劃分為標準工作條件(Standard Operation Condition,SOC)和擴展工作條件(Extended Operation Condition,EOC)[80],根據(jù)ATR任務(wù)的具體需求設(shè)置具有代表性的EOC,并在目標類型、地面背景、傳感器姿態(tài)等因素維度上構(gòu)建差異化的測試條件。測試條件構(gòu)建最后體現(xiàn)為不同的數(shù)據(jù)集:一般來說,SOC采集的一部分數(shù)據(jù)構(gòu)成訓(xùn)練數(shù)據(jù)集,主要被用作ATR算法訓(xùn)練開發(fā)和自檢;EOC的數(shù)據(jù)相對于研制方保密,形成測試數(shù)據(jù)集并用于ATR系統(tǒng)性能評價。
在SAR ATR技術(shù)領(lǐng)域中,MSTAR數(shù)據(jù)集被廣泛使用。MSTAR數(shù)據(jù)集包含X波段0.25 m×0.25 m分辨率的全方位SAR圖像序列,方位角間隔1°,圖像分辨率128×128像素,所含目標多為車輛[81]。其中,常見的幾類地面目標如圖6所示[82]。

圖6 10類MSTAR目標的光學(xué)及SAR圖像[82]Fig.6 Optic and SAR images of 10 MSTAR targets[82]
公開發(fā)布的數(shù)據(jù)中提供設(shè)置的因素包括外形差異和俯仰角差異[82]。通常一類(Class)目標中包括若干不同的類型(Type),用于評價ATR算法在目標外形差異條件下的擴展性;部分目標還具有多個差異較大俯仰角的觀測圖像,用于評價ATR算法在不同成像視角條件下的擴展性。文獻[83]總結(jié)了如何正確使用MSTAR數(shù)據(jù)開展SAR ATR評價工作。文獻[84]對MSTAR數(shù)據(jù)所發(fā)揮的作用進行了分析,總結(jié)了1995—2020年使用該數(shù)據(jù)論文的引用次數(shù),如圖7所示。

圖7 MSTAR數(shù)據(jù)引文進展[84]Fig.7 MSTAR citation progression[84]
在光學(xué)圖像ATR技術(shù)領(lǐng)域,包含海量圖像的數(shù)據(jù)集為ATR系統(tǒng)提供了比較接近真實環(huán)境的測試條件,從而極大地促進了數(shù)據(jù)驅(qū)動的ATR技術(shù)飛速發(fā)展。其中,頗具代表性的圖像數(shù)據(jù)集有PASCAL VOC[85,86],ImageNet[87],MS COCO[88]和Open Images[89]等。這些數(shù)據(jù)集經(jīng)常被作為目標檢測、模式識別等領(lǐng)域中ATR算法性能測試的基準條件。
3.3 推斷與決策
分析表1不難發(fā)現(xiàn),混淆矩陣由于其記錄結(jié)果難以直觀比較,需要轉(zhuǎn)換為反映特定性能的概率型指標;而體現(xiàn)“檢測-虛警”“精確率-召回率”等概率型指標之間相互約束關(guān)系的ROC曲線、P-R曲線等,也是以概率指標作為基礎(chǔ)。由于實際測試次數(shù)的限制,基于概率型指標的性能評價通常被歸結(jié)為統(tǒng)計推斷問題,下面結(jié)合實例進行詳細介紹。
以識別率指標為例,在統(tǒng)計學(xué)中可抽象為Bernoulli試驗的成敗概率。記n個測試樣本中正確識別的次數(shù)為X,則X為服從二項分布的隨機變量。X=k(k=0,1,2,···,n)的概率為
當n較大時(至少要求n≥30),識別率指標的測試結(jié)果=X/n可以用正態(tài)分布近似,在置信度1—α下識別率指標的區(qū)間估計結(jié)果為
其中,zα/2表示標準正態(tài)分布N(0,1)的α/2分位數(shù)。
對ATR算法性能評價中特別關(guān)心的識別率達標問題,可以通過構(gòu)建檢驗統(tǒng)計量進行假設(shè)檢驗予以判斷。例如,合同對ATR算法的識別率指標要求為p0,可以構(gòu)建如下的原假設(shè)H0和備選假設(shè)H1來判斷識別率精確率是否達標[73]:
其中的檢驗統(tǒng)計量z0由測試結(jié)果、合同要求值p0和樣本容量n共同計算。若該假設(shè)檢驗的顯著性水平取α,則當z0>—zα?xí)r,判定識別率指標達到規(guī)定值。
文獻[90]在上述正態(tài)近似假設(shè)前提下,對等價誤識率的估計精度、區(qū)分度等問題進行了詳細討論,其研究結(jié)果表明需要大量的測試樣本才能保證推斷結(jié)果具有統(tǒng)計意義。對任意測試樣本容量的一般情況,文獻[91]提出了一種基于特定事件貝葉斯后驗概率的評價方法,有效解決了根據(jù)概率型指標進行ATR算法考核檢驗、比較排序等評價問題。
上述評價方法都只是根據(jù)某個關(guān)鍵的概率型指標進行評價,但實際中的ATR系統(tǒng)具有多方面屬性,需要構(gòu)建合適的評價指標體系才能開展全面評價。ATR系統(tǒng)評價所面臨的多指標綜合評價問題,在決策分析領(lǐng)域中被稱為多屬性決策(Multi-Attribute Decision-Making,MADM)問題,一般可采用分值模型或關(guān)系模型進行多指標聚合。
顧名思義,分值模型通過獲取綜合評分來實現(xiàn)多指標綜合評價,類似于雷達等技術(shù)領(lǐng)域中廣泛使用質(zhì)量因數(shù)(Figure of Metric,FoM)[92]對系統(tǒng)的整體性能進行綜合描述。FoM的通式可概括為
其中,ai表示第i個指標的評分值,wi表示該項指標的權(quán)重。
為得到ATR系統(tǒng)的綜合評分值,Klimack等人[93]將決策分析(Decision Analysis,DA)理論引入ATR系統(tǒng)評價,以價值函數(shù)和效用函數(shù)作為獲取指標評分值的量化工具,然后再用一種混合價值/效用(Hybrid Value-Utility)[94]的分值模型聚合多個指標的評分值。文獻[95]結(jié)合某ATR系統(tǒng)評價給出了詳細的指標分解、賦權(quán)和評分過程,并且歸納出一個通用的評分決策模型,如圖8[95]所示。圖8中底層的紅色曲線表示各指標值的概率分布,倒數(shù)第二級的綠色曲線表示每個指標對應(yīng)的價值函數(shù)或效用函數(shù),需要根據(jù)具體的應(yīng)用場景進行構(gòu)建。
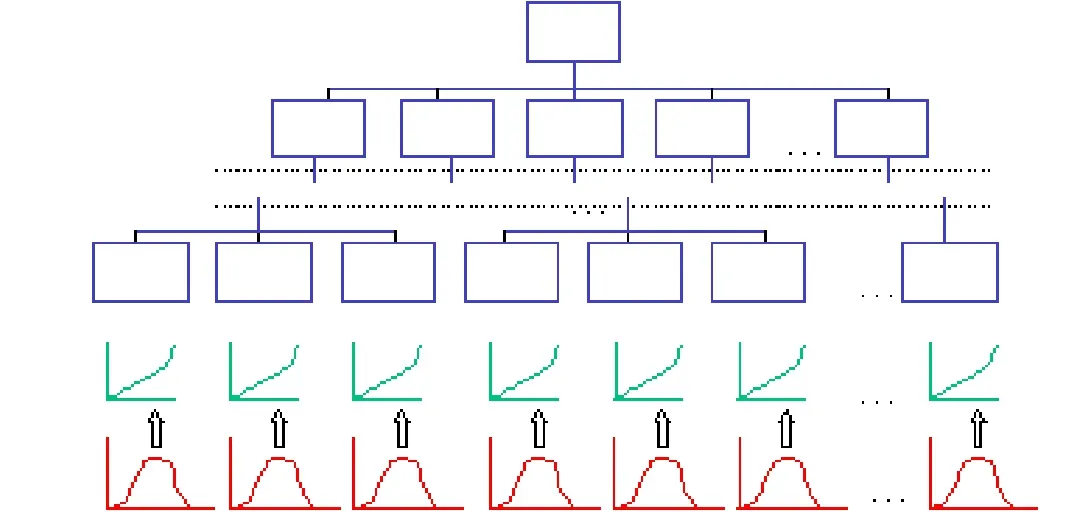
圖8 通用決策分析模型結(jié)構(gòu)[95]Fig.8 Common decision analysis model structure[95]
除分值模型之外,關(guān)系模型是另一類常見的評價決策模型。關(guān)系模型從形式上可以概況為[96]:稱(U,R)為評價關(guān)系模型,其中U={x1,x2,···,xn}為評價對象集,R為評價對象之間的關(guān)系集
其中,R(xi,xj)表示評價對象xi與xj之間的某種優(yōu)劣關(guān)系。
不同于分值模型,關(guān)系模型避開了不同數(shù)據(jù)類型指標的評分要求,不需要為每個評價指標構(gòu)造價值函數(shù)或效用函數(shù)。例如,對ATR系統(tǒng)評價中最為常見的實數(shù)型、風(fēng)險型和區(qū)間型指標,文獻[97]通過建立基于標準優(yōu)劣差異x的偏好映射實現(xiàn)對式(5)中矩陣元素的賦值,從而完成了混合3種數(shù)據(jù)類型的多指標ATR系統(tǒng)綜合評價。
4 ATR評價研究最新進展
第3節(jié)分別對ATR評價方法研究中的性能指標定義、測試條件構(gòu)建、推斷與決策等方面的成果進行了歸納總結(jié),本節(jié)繼續(xù)對一些最新的研究進展進行分析與評述。
性能指標定義方面,消除評價指標不確定性的歸一化方法研究已經(jīng)開始引起關(guān)注。例如,對于識別率等具有不確定性的概率型指標,文獻[98]提出一種前景函數(shù)構(gòu)建方法,將識別率的增量轉(zhuǎn)變成前景價值,其所設(shè)計的前景價值函數(shù)不僅具有邊際遞減效應(yīng),而且不敏感于測試樣本容量的變化。另外,隨著深度學(xué)習(xí)方法在ATR技術(shù)領(lǐng)域的廣泛應(yīng)用,對于ATR算法可解釋性[99,100]的要求日益強烈,成為這類ATR算法評價的研究熱點。可解釋性研究的重點在于提出可量化的指標,但是當前常見的一些方法(如LIME[101],Grad-CAM[102]等)尚缺乏被一致認可的量化指標。
測試條件構(gòu)建方面,隨著國內(nèi)學(xué)界對數(shù)據(jù)的逐漸重視,國內(nèi)多個研究機構(gòu)陸續(xù)發(fā)布了可用于ATR算法研究與系統(tǒng)測評的數(shù)據(jù)資源,包括雷達[103—105]、紅外[106,107]等多種傳感器采集的數(shù)據(jù)。代表測試條件的數(shù)據(jù)集質(zhì)量問題,也開始引起人們的廣泛關(guān)注。例如,文獻[108]分別針對圖像數(shù)據(jù)集和文本數(shù)據(jù)集,提出了面向任務(wù)的數(shù)據(jù)集質(zhì)量評價和數(shù)據(jù)選擇方法,實現(xiàn)了任務(wù)相關(guān)性和內(nèi)容多樣性的量化度量。當實測數(shù)據(jù)不能完全滿足工作條件的多樣性需求時,人工合成及仿真計算等方法也逐步成為一種有益的補充手段[109—112]。通過不斷提高所構(gòu)建測試條件與實際工作條件的逼真度,ATR系統(tǒng)的有效性可以用在測試數(shù)據(jù)集上的擴展性來等效近似。
推斷與決策方面,適用于ATR評價的混合型多屬性決策問題已引起國內(nèi)外的普遍關(guān)注,陸續(xù)提出了多種混合型多屬性決策方法[113,114]。國內(nèi)學(xué)者對區(qū)間數(shù)[115,116]、模糊型[117,118]和語言變量[119]等類型的多數(shù)屬性決策問題抱有較濃厚的研究興趣。文獻[120]總結(jié)了各類不確定性和混合型多屬性決策方法,給出了一些新的決策方法與應(yīng)用實例。ATR系統(tǒng)評價方法研究中,借鑒這些最新決策理論成果的報道較為少見。文獻[121]針對制導(dǎo)裝置提出了基于區(qū)間直覺模糊集的性能評價方法,但是評價方法的合理性仍有待實際應(yīng)用檢驗。
5 結(jié)語
ATR評價方法的研究伴隨著ATR技術(shù)發(fā)展,陸續(xù)取得了不少研究成果。理論上,測評方法分為理論分析和實驗測量兩種技術(shù)途徑,本文只涉及基于測試的評價方法。這是由于ATR技術(shù)與實際應(yīng)用結(jié)合緊密,大部分的ATR算法和ATR系統(tǒng)的性能指標需要根據(jù)實際測試結(jié)果計算,因而制約了理論分析方法的發(fā)展。對基于測試的ATR評價方法,獲取識別率等關(guān)鍵指標的邊界值是一個難點問題。作者認為,如果將ATR算法作為結(jié)構(gòu)未知的“黑箱”進行測試,始終難以從根本上解決ATR算法的可信應(yīng)用問題。基于理論分析的方法研究,則有可能從對ATR算法內(nèi)部認知的角度突破該難題。
下面根據(jù)當前的研究現(xiàn)狀,提出兩個值得深入思考和持續(xù)研究的方向。
(1) 借鑒多屬性決策理論,進行綜合評價方法創(chuàng)新。
現(xiàn)階段對于不確定性多屬性決策方法、不確定信息下的案例推理決策方法等方面的研究成果頗為豐富,但對ATR系統(tǒng)評價而言,最為關(guān)鍵的問題是根據(jù)評價指標自身的定義與內(nèi)涵,謹慎選擇合適的不確定信息類型予以描述和度量,然后再從眾多的已有方法成果中挑選合適的決策模型(亦稱為集結(jié)算子)來融合決策者的主觀偏好。這些研究工作貌似只是對現(xiàn)有理論方法的修改,卻靈活解決了ATR評價工作所要面臨的各種實際問題,也是構(gòu)建ATR評價指標體系的理論依據(jù)所在。因此,有必要針對ATR評價問題中特有的混合型多屬性決策問題,研究相應(yīng)的決策模型及綜合評價方法,解決多指標的ATR綜合評價問題。
(2) 持續(xù)數(shù)據(jù)工程建設(shè),提升測試樣本數(shù)據(jù)質(zhì)量。
ATR算法技術(shù)主流從最初的模板匹配到后面的模型驅(qū)動,再到現(xiàn)在的以深度學(xué)習(xí)為代表的數(shù)據(jù)驅(qū)動,對于訓(xùn)練數(shù)據(jù)和測試數(shù)據(jù)的需求都在不斷增加。ATR評價主要關(guān)心如何適當減少測試數(shù)據(jù),同時又能夠保證測試樣本涵蓋實際工作條件的各類場景,實際上提出了數(shù)據(jù)使用規(guī)范與數(shù)據(jù)集質(zhì)量評價這兩個方面的需求。因此,還需進一步加強測試流程的規(guī)范化研究,重點分析測試樣本的數(shù)據(jù)質(zhì)量,構(gòu)建合理的質(zhì)量指標體系對測試數(shù)據(jù)集進行量化考核,保證測試結(jié)果反映ATR系統(tǒng)的真實性能表現(xiàn)。
ATR評價方法的研究已取得一定成果,但仍然跟不上ATR技術(shù)的發(fā)展需求。隨著相關(guān)學(xué)科領(lǐng)域的發(fā)展及ATR技術(shù)自身的持續(xù)深入研究,建議在ATR技術(shù)領(lǐng)域中將ATR評價設(shè)立為一個獨立的研究方向,為模式分類、目標檢測、敵我識別、無人作戰(zhàn)等高新技術(shù)應(yīng)用提供科學(xué)的檢驗標準與決策依據(jù)。
利益沖突所有作者均聲明不存在利益沖突
Conflict of Interests The authors declare that there is no conflict of interests
猜你喜歡
工業(yè)設(shè)計(2022年8期)2022-09-09 07:43:20
石油瀝青(2021年4期)2021-10-14 08:50:44
軍民兩用技術(shù)與產(chǎn)品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
家庭影院技術(shù)(2017年9期)2017-09-26 03:41:45
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
中國教育技術(shù)裝備(2015年19期)2015-03-01 02:43:07
俄羅斯問題研究(2012年1期)2012-03-25 09:54:51
