基于卷積神經網絡的物品識別系統設計
2024-01-01 00:00:00陳永聰曾宇浩鄧云清
電子產品世界 2024年5期
關鍵詞:CNN;物品識別;系統設計
0引言
卷積神經網絡(convolutionalneuralnetwork,CNN)作為深度學習的重要分支,憑借其強大的特征提取能力而被廣泛應用于識別領域,并取得顯著效果。物品識別則被廣泛應用于智能物流、自動化生產、智能安防等多個領域。然而,面對復雜多變的物品形態與類別,傳統識別方法常常無法取得理想效果。在這種背景下,本文設計了一套高效、實用的物品識別系統,其具有重要理論價值與現實意義,有助于大幅提升物品識別的準確率與效率。
1物品識別系統設計與實現
1.1總體設計
本系統由PC瀏覽器客戶端、Android客戶端及后臺服務器三大部分構成。后臺服務器主要負責運算與處理,其先接收來自不同客戶端的用戶請求,隨后對上傳的圖片完成接收、預處理與識別[1]。該過程又被細分成圖片接收、識別及結果返回等核心流程。
對于PC瀏覽器客戶端,專門為用戶設計了一個直觀且友好的交互界面。用戶只需在瀏覽器地址欄輸入特定網址,便能輕松訪問系統主界面。在選擇并上傳本地圖片后,系統將迅速進行識別處理,并在頁面中即時顯示識別結果,從而為用戶提供一種流暢、高效的操作體驗。
為更好地滿足移動端用戶的需求,專門研發了Android客戶端。本設計應用Cordova技術,將功能交互、頁面設計及樣式等元素巧妙地打包成一個完整的Android應用[2]。用戶可以隨時使用手機拍攝照片或選擇本地圖片進行識別,實現了Android客戶端與后臺服務器的完美對接,大大提高了系統的便捷性與實用性。
1.2技術架構
在構建物品識別系統過程中,因表述性狀態轉移(representationalstatetransfer,REST)適應性強且優勢顯著,將其作為Web架構。設計系統架構時,先將服務器與客戶端分離,使服務器端專注于數據處理與邏輯運算,而客戶端則負責與用戶完成交互。為提升系統可靠性與安全性,本設計利用REST的無狀態特性,同時啟用數據緩存,優化網絡效率。此外,為優化系統性能,本文還適當引入網關、代理等中間層,從而完成負載均衡、身份驗證等操作。在開發過程中,通過定義清晰的應用程序編程接口(applicationprogramminginterface,API)與數據格式,保證了通信的高效與簡潔。最后,考慮到智能手機的硬件限制,本設計將計算密集型算法全部部署到服務端,以充分利用服務端的強大計算能力[3]。
1.3卷積神經網絡模型構建
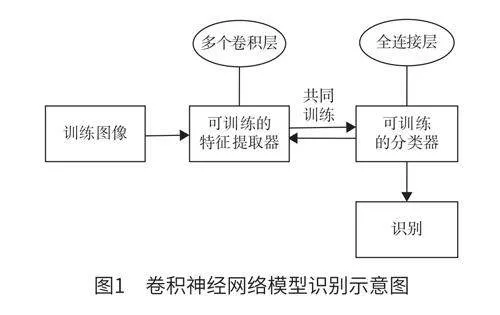
卷積神經網絡模型是物品識別系統的核心組成部分。本設計利用深度CNN算法中的AlexNet模型來構建卷積神經網絡模型,借助MXNet輕松地定義卷積層、激活層以及池化層等神經網絡的基本組件。具體構建流程為:首先,定義一個輸入層以接收待識別的物品圖像;其次,運用多個卷積層對圖像完成特征提取,且每個卷積層均配備了激活函數,如修正線性單元(rectifiedlinearunit,ReLU),其可以增加網絡的非線性表達能力;再次,利用池化層來降低數據的維度,同時保留最重要的特征;最后,借助連接層與Softmax函數來調整輸出層神經元產生的誤差值,從而得到最終的識別結果[4]。卷積神經網絡模型識別示意圖如圖1所示。
在基于CNN的物品識別過程中,首先需要進行圖像訓練,為充分利用圖像視覺信息,本文設計多卷積層作為特征提取器,以深入挖掘輸入訓練圖像的內在特征。其中,每一個卷積層均利用卷積運算來捕捉圖像的局部特征,如邊緣、紋理等。隨著卷積層的加深,網絡可以逐步提取出更加抽象與高級的特征。訓練過程中,利用反向傳播算法來實時更新卷積層的參數,如卷積核的偏置、權重等。同時,憑借計算誤差信號與反向傳播,持續調整與優化相關的參數。此外,同步調整分類器的參數,以保證其能夠準確地根據提取的特征實現對物品圖像的分類或識別。CNN能夠端到端地學習從輸入圖像至最終識別結果的映射關系[5]。
1.4交叉訓練優化CNN模型性能
為進一步提高物品識別的準確率,本設計還應用了交叉訓練的方法。在交叉訓練過程中,需要持續調整網絡參數,以不斷優化模型的性能。具體實現步驟如下:首先,將原始數據集分為訓練集與驗證集,并利用驗證集對訓練結果完成評估。通過反復多次迭代訓練,持續調整網絡參數,直到獲得滿意的準確率。其次,訓練過程中還采用隨機梯度下降算法來進一步優化網絡參數[6]。該算法通過計算損失函數的梯度來調整與更正網絡參數,以此不斷逼近最優解。最后,本設計還引入了動量、學習率衰減等技巧來加速訓練過程,以迅速提高模型的泛化能力。
1.5CNN模型保存與物品識別
在模型訓練完成后,需要將訓練好的模型保存下來,以供后續使用。模型的保存包括網絡結構與網絡參數保存,可以使用MXNet提供的函數model.save()來保留訓練后穩定的網絡結構與網絡參數,且保存的文件占用內存很小,便于后續加載與使用。隨后,便可以使用基于卷積神經網絡模型的物品識別系統來識別新的物品圖像。識別過程中,將待識別的圖像上傳到已經訓練好的模型中,并且利用前向傳播計算得到識別結果,該識別結果可以是一個類別、一個標簽或其他形式的信息。在使用時,可利用已保存好的模型文件來加載模型,并使用該模型來識別新的物品圖像,整體過程簡單高效,且可以滿足實時性的要求[7]。
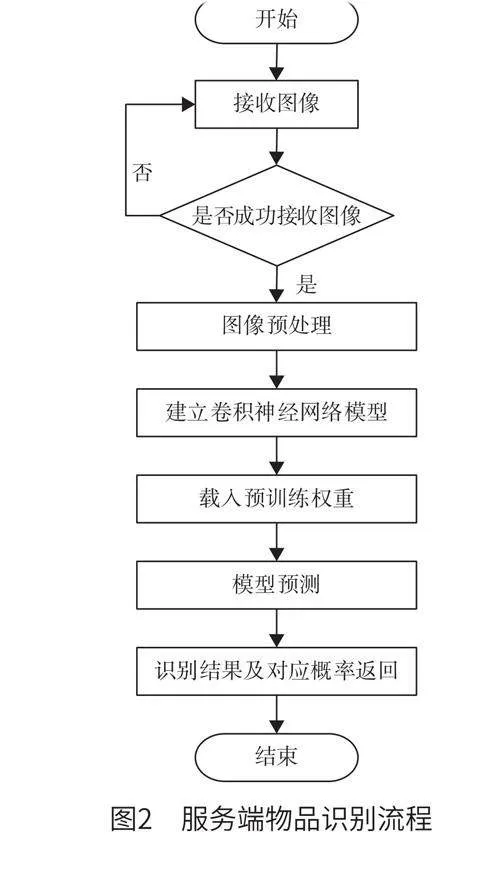
實際應用過程中,由服務端負責接收并處理來自Android端與PC瀏覽器端的識別請求,并執行圖像識別任務,最終返回精確的識別結果。具體來說,當用戶啟動Android應用或在PC瀏覽器中訪問物品識別系統時,服務端完成路由分發,根據請求的地址,智能地調用不同的接口(首頁接口與圖像識別接口)。一旦用戶上傳物品圖片,服務端將立即調用專門的圖像識別接口。圖片識別完成后,服務端將識別結果封裝成標準的數據格式,而后借助網絡將其返回給客戶端。服務端物品識別流程如圖2所示。
在實際處理圖像過程中,首先,服務端判斷用戶是否成功上傳物品圖像,如果上傳不成功則需重新上傳。其次,當服務端成功接收到物品圖像后,對其進行預處理,將圖像轉化成指定格式,以更好地適應后續的卷積神經網絡模型。最后,構建與配置卷積神經網絡模型,并使用該模型推理分析預處理好的圖像數據流。該模型能夠根據輸入的圖像,計算出與權重文件中每個類別標簽的相似度或匹配程度,并將這些相似度評分或概率值作為輸出結果。另外,該系統還具備識別物品類別與表面屬性的功能。本文利用Corel數據集與FMD數據集訓練了CNN模型,在接收來自用戶上傳的物品圖片后,系統使用訓練好的卷積神經網絡模型完成分類預測,從而得出識別結果并將其返回給客戶端。
2實驗結果及分析
2.1數據集與實驗設置
為深入驗證CNN模型在物品識別方面的性能,本文采用多個標準數據集完成實驗,涉及Caltech101、FMD等數據集[8]。數據集涵蓋了廣泛的物品類別,為客觀準確評估CNN模型提供了必要基礎。在實驗環境方面,本文采用Win10系統,配備4GB內存與Inteli5處理器,同時選用MATLABR2015b作為主要編程環境,以保障實驗的可靠性與可重復性。
2.2實驗結果與分析
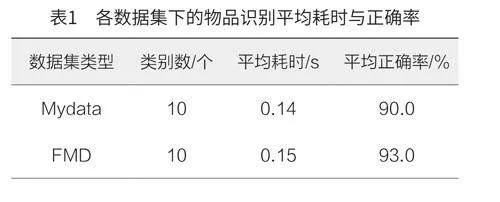
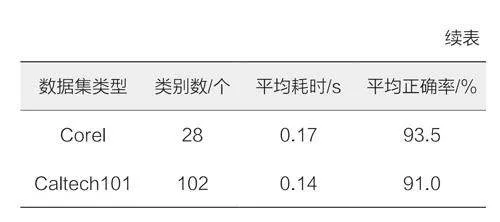
實驗過程中,本文重點關注CNN在物品識別任務中的性能表現,尤其是識別時間與識別正確率,各數據集下的物品識別平均耗時與正確率如表1所示。
結果顯示,對于包含10個類別的Mydata數據集,系統平均耗時0.14s,平均正確率高達90.0%。在更具挑戰性的Caltech101與Corel數據集中,系統同樣表現出了良好的性能,尤其是在Caltech101數據集上,盡管類別數增至102個,但平均正確率仍達到了91.0%。而在FMD數據集上,系統平均正確率達到93.0%,這證明了卷積神經網絡模型在該特定數據集上識別任務更具挑戰性。
3結語
通過深入研究與實驗驗證,本文成功地設計與實現了一套基于CNN的物品識別系統。該系統在各類標準數據集上表現出卓越的性能,驗證了CNN在物品識別領域的實用性與有效性。然而,該物品識別系統仍存在一定的局限性,如在處理物品遮擋、極端形變等特定場景時準確率與效率仍有待提升。未來,將持續優化網絡結構,積極探索更多先進的算法技術,如增量學習、注意力機制等,以進一步提升物品識別系統的適應性與識別能力。
