基于實體自適應信息混合的KGE負采樣方法
2024-01-01 00:00:00李航許洺韶
沈陽師范大學學報(自然科學版) 2024年1期





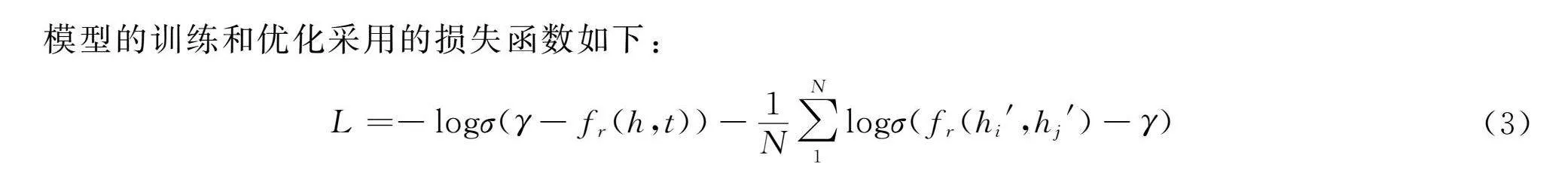

摘"" 要:在知識圖譜補全(knowdge graph completion,KGC)任務中,負采樣方法并不被重視,但其對補全精度能造成巨大的影響。一方面,當前一些負采樣方法使用較少的參數,產生的負樣本質量較低;另一方面,如對抗性負采樣的負采樣方法雖然能夠生成高質量的負樣本,但其計算復雜度較高。為解決生成負例三元組過程中出現的以上問題,提出了一種新的基于實體自適應信息混合的負采樣方法(entity adaptive information hybrid-negative sampling,EAIH-NS),EAIH-NS將實體的嵌入表示以層次聚類的方法分簇分類,能實現較好的分簇效果,且結果具有較強的可解釋性。同時,在分簇排序的條件下以高斯分布的方式選取多個負樣本,采用混合操作最終得到高質量的負例三元組。EAIH-NS采用了相對于其他負采樣方法更少的參數,降低了模型的復雜度,在知識圖譜數據集的實驗中都得到了較好的性能提升。
關 鍵 詞:負采樣; 知識圖譜補全; 層次聚類; 混合操作
氧化鈷; 納米結構; 電容器; 電催化
中圖分類號:TP319""" 文獻標志碼:A
doi:10.3969/ j.issn.16735862.2024.01.009
Negative sampling method based on entity adaptive information hybrid for knowledge graph embedding
CUI Song "LYU Yan "CHEN Lanfeng1,2
LI Hang, XU Mingshao
(1. College of Physical Science and Technology, Shenyang Normal University, Shenyang 110034, China)
(Software College, Shenyang Normal University, Shenyang 110034, China)
Abstract:
Negative sampling methods are not emphasized in the task of knowledge graph completin, but they can have a huge impact on the complementation accuracy. On the one hand, some negative sampling methods use fewer parameters and produce lower-quality negative samples; on the other hand, some negative sampling methods such as adversarial negative sampling are capable of generating high-quality negative samples, but their computational complexity is high. To address the above issues. proposing a method named Entity Adaptive Information Hybrid Negative Sampling for Knowledge Graph Embedding(EAIH-NS). EAIH-NS classifies the embedded representations of entities in clusters by hierarchical clustering, which can achieve better clustering results. Afterwards, negative samples are selected in a Gaussian distribution under the condition of cluster ordering. At the same time,multiple negative samples are selected in a Gaussian distribution, and a mixing operation is used to finally obtain a high-quality negative triples. EAIH-NS employs fewer parameters relative to other negative sampling methods, which reduces the complexity of the model and results in better performance improvement in all the experiments on the knowledge graph dataset.
Key words:
negative sampling; knowledge graph complementation; hierarchical clustering; mixing operation
知識圖譜的概念由Google于2012年提出:現實世界的知識可以通過(head,relation,tail)形式的三元組來表示,即(h,r,t)。知識圖譜技術自誕生以來,廣泛應用于醫療、工業等多個領域[14]。然而,隨著社會的發展,人類的知識在不斷地改變和增加,當前的知識圖譜并不完整,嚴重影響到下層應用的性能。針對知識圖譜的不完整性問題,知識圖譜補全(knowledge graph completion,KGC)技術應運而生。在知識圖譜補全任務中,除了使用正確的三元組外,還需要引入錯誤的三元組來增強模型的辨別能力,負采樣方法就是生成這些負樣本的技術。當前研究最多使用的是均勻負采樣方法,該方法雖實現簡單、參數較少,但生成的負樣本不具有挑戰性,造成知識圖譜補全精度較低的問題。同時,其他的負采樣方法如對抗性負采樣等也出現參數較多、復雜度高等問題。
動態負采樣方法可以用更少的參數實現更好的預測精度,例如,自適應負采樣(adaptive negative sampling,ANS)使用K-means聚類將所有實體分類為相似實體的組,并且對于每個正三元組,隨機選擇一個正實體所在簇中的負實體,替換該頭部或尾部的正實體生成負樣本[5]。這種方法相比靜態負采樣方法(如均勻負采樣)能生成更具挑戰性的負采樣樣本,以達到提升補全精度的目的。盡管其改進了負樣本的選擇,但由于K-means聚類算法傾向于在樣本空間密集的區域中生成質心,這可能導致樣本稀疏的區域中的負樣本不準確。同時,負樣本的生成在許多現有的負采樣方法中缺乏創新,因為它們通常依賴于選擇預先存在的負實體向量作為負樣本,這限制了模型預測復雜數據關系的能力。
針對上述問題,本文提出了一種新的負采樣方法——實體自適應信息混合負采樣,即EAIH-NS(entity adaptive information hybrid-negative sampling)。EAIH-NS中的自適應實體分類方法可以有效地對形狀復雜或大小不同的數據集進行分類,更好地處理具有自然層次結構的數據,提高數據的可解釋性;EAIH-NS中的負實體信息混合方法通過在聚類后從高斯分布中選擇多個負實體來增加負樣本的多樣性和復雜性,并通過混合操作混合來自多個負主體的信息來生成新的、更具挑戰性的負樣本,這為訓練模型提供了更多的信息。將該方法在多個經典知識表示學習模型和2個通用知識圖譜數據集上進行實驗評估,較其基線取得了顯著的性能提升。此外,相較于現有其他的負采樣方法,EAIH-NS在實驗中的表現同樣具有競爭力。
1 相關工作
靜態負采樣是知識圖譜補全任務中常用的一種方法。均勻負采樣是知識表示學習模型中使用的主要方法,該方法在替換正三元組中頭部實體或尾部實體過程中均勻地覆蓋整個樣本空間,以相同概率抽取樣本解決生成負樣本的挑戰[6]。然而,均勻負采樣可能會產生假陰性樣本,假陰性是知識圖譜補全任務中的一個重要挑戰。當前已經提出了各種負采樣方法來解決這個問題,其中一種方法是伯努利負采樣方法,伯努利負采樣方法是基于關系的映射性質,用不同的概率替換正三元組的頭部或尾部實體[7]。然而,在涉及約束或不平衡數據的情況下,使用均勻負采樣或伯努利負采樣方法可能無法充分捕捉目標三元組的缺失成分。
在知識圖譜補全任務中,靜態負采樣方法往往會產生過于簡單化的負樣本,為了避免這種情況,研究人員提出了一種基于動態分布的采樣方法。ANS[5]是一種使用K-means聚類[8]模型生成負樣本的方法,但是,由于K-means聚類算法傾向于在樣本空間密集的區域生成質心,這可能導致在樣本稀疏的區域中出現不準確的負樣本。SANS方法結合已知的圖結構,通過從節點的 k 跳鄰域中選擇負樣本來利用豐富的圖結構[9]。方法MixGCF 利用了混合的操作,并不從數據中采樣原始樣本,設計了混合跳轉技術來合成負樣本,但擁有一定的計算復雜度[10]。對抗性負采樣方法是一類新興的技術,例如IGAN和KBGAN引入了生成對抗網絡來選擇高質量的負樣本。在這種方法中,生成器網絡由損壞的三元組嵌入向量組成,
判別器接收生成器生成的樣本和從知識圖譜中抽取的真實樣本,計算判別器的損失函數并更新相關參數,多次迭代生成高質量負樣本[1112]。然而,在大規模的知識圖互補任務中,對抗性網絡往往需要更多的參數和開銷。
2 方 法
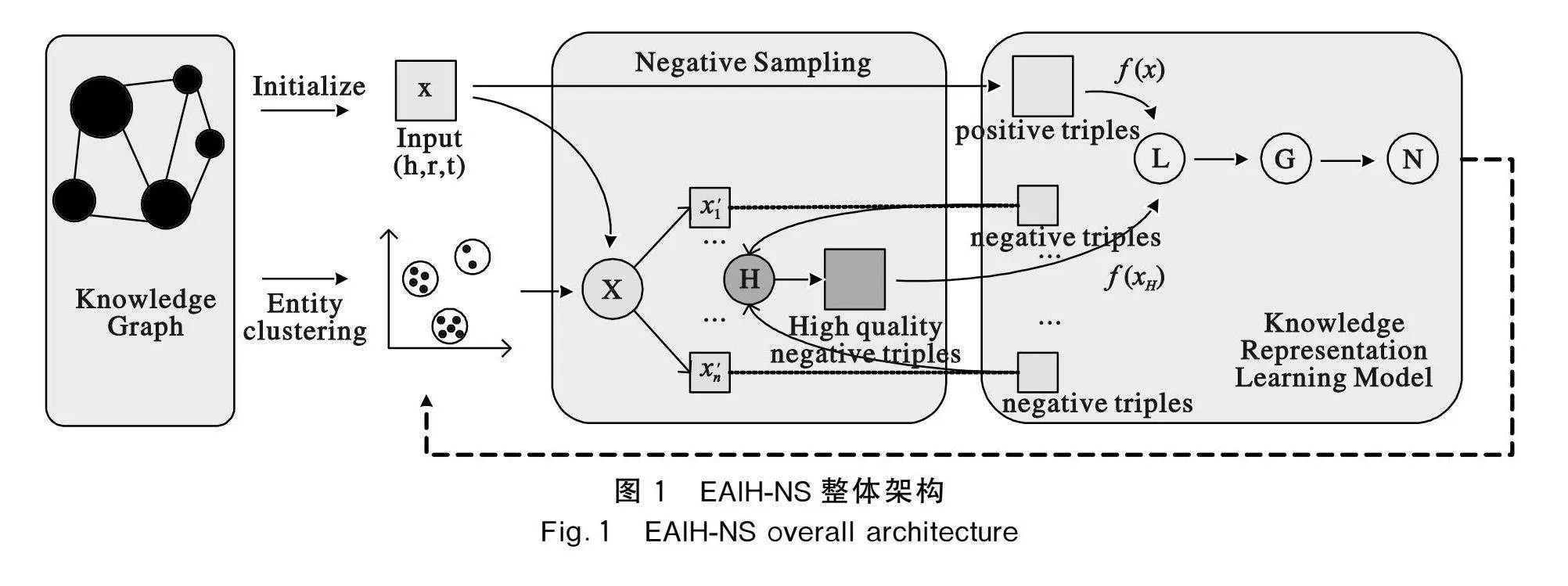
EAIH-NS的整體架構如圖1所示。將知識圖譜中所有的實體通過層次聚類生成更具語義合理性的分簇,后將需替換的實體所在的簇X通過高斯分布選擇多個本就與正實體相近的負實體x′n,并使用混合函數H混合其相應的信息以生成更具有挑戰性的高質量負例三元組,最后選擇知識表示學習模型計算損失函數L,G代表梯度更新,N表示嵌入標準化。由于聚類算法被用于知識圖嵌入訓練的實體,隨著學習的進展,實體嵌入將不斷變化。因此,應使聚類的簇不斷更新以適應不斷變化的實體嵌入。
2.1 實體分類
知識圖譜數據集中包括的三元組是已存在的事實,不包括負例三元組,這些負例三元組是通過用這些已存在的實際三元組替換頭實體或尾實體而獲得的。在EAIH-NS方法中,如圖1所示,負示例三元組的生成在很大程度上依賴于實體聚類的效果,類似的方法如ANS使用K-means算法對實體進行聚類。然而,面對與復雜知識圖相關的更大規模任務,K-means算法簡單地計算實體與質心之間的距離,在語義上并不能提供良好的聚類效果。層次聚類能夠很好地考慮實體之間的語義關系,并不如K-means算法一樣隨機生成質心,這也為稀疏數據提供了極好的聚類效果。
最初,每個實體被視為一個單獨的簇,計算實體之間的歐幾里得距離,通過計算實體之間歐幾里得距離找到最近的2個簇,并將它們合并到一個新的簇中,之后,更新距離矩陣以反映新簇與其他簇之間的距離,并重復這些步驟以獲得多個知識圖譜實體簇。通過層次聚類獲得的簇中包含的實體具有相似的特性,為負樣本的選擇提供了良好的基礎。實體聚類如圖2所示,其中n個m維實體被合成為k個聚類。
在訓練迭代過程中,通過知識表示學習模型計算出損失后,實體嵌入向量不斷優化和改變,實體之間的相似性也會隨之改變,需要更新聚類結果以適應新的實體,從而繼續為后續訓練提供高質量負樣本的來源。這樣的更新不需要在每一次訓練中執行,實驗得出每3個訓練周期執行一次更新即可適應實體向量的改變。
2.2 負實體信息混合
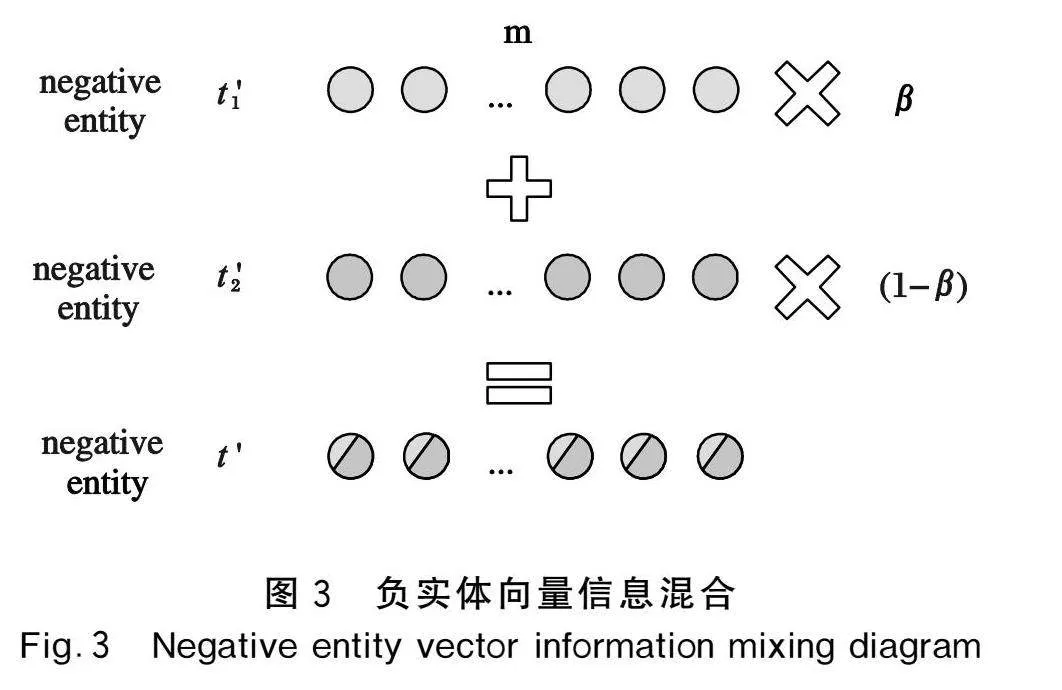
負實體信息混合部分在實體聚類模塊獲得更具語義關系的實體分簇基礎上,繼續生成更高質量的負實體以提高模型的負樣本挑戰性,達到提升模型精度的目的。EAIH-NS通過選擇與正實體信息相似的其他實體作為負實體的備選,因為這些負實體本就和正實體具有較強的語義關聯,后選擇其中的2個負實體混合信息生成更有挑戰性的新負實體,該負實體在向量角度對模型的訓練中更具挑戰性,但其可能本身并不是真正的實體,突破了其他負采樣方法中僅通過選擇現有的負實體生成負樣本的方法。假設一個正三元組(h,r,t)的尾實體t選擇2個相應的負實體t′1和t′2,選擇β作為混合系數將負實體混合生成新負實體t′并替換正實體t,生成負三元組(h,r,t′),混合公式為
t′=β×t′1+(1-β)×t′2(1)
其中β通過在(0,1)區間內隨機獲得。負實體向量信息混合如圖3所示,假設負實體t′1和t′2被嵌入為m維的向量,該圖展示混合過程中負實體的結構變化。
被混合信息的負實體是使用實體分類方法后,所有正實體按簇排序后的實體序號上高斯分布來獲得的。通常的負樣本選擇是通過隨機分布抽樣完成的,考慮到層次聚類獲得的簇內具有強語義關系,且在實體數量上有所不同,有大的聚類和小的聚類,在具有大量實體的大型集群中,集群內隨機抽樣是不錯的選擇,但在具有少量實體的小型集群中,很容易多次捕獲同一個負實體,在獲取新負實體的混合操作中賦予該實體更大的信息權重。高斯分布采樣可以有效避免這一情況的發生,在聚類后,將所有的實體按簇進行索引排序分配。假設共有n個實體,對排序分配出的索引[0~n)進行高斯分布,從一個均值為μ、方差為σ的高斯分布中速記抽取實體索引xi,xj,即xi,xj~N(μ,σ),其中μ代表正實體x對應的實體索引,σ代表了采樣的分散程度,這2個實體索引對應上述混合操作的負實體t′1和t′2。為簡單實現這一抽取操作,可以先從標準正態分布N(0,1)采樣,然后通過線性變換乘σ再加μ得到所需分布的樣本,在獲取較強語義關系的負實體的同時,避免小簇重復使用負實體,增強模型的學習效果。公式如下:
xi,xj~(N(0,1)×σ+μ)(2)
根據正實體所在簇的大小動態調整σ以獲取最優的負實體進入混合操作,高斯分布采樣如圖4所示。為避免生成假陰性樣本的影響,在獲得xi,xj時和混合生成t′時,都將替換正樣本檢查是否已存在該三元組。
模型的訓練和優化采用的損失函數如下:
L=-logσ(γ-fr(h,t))-1N∑N1logσ(fr(hi′,hj′)-γ)(3)
其中:γ是超參數邊距;σ代表sigmoid激活函數。EAIH-NS算法如下所示:
算法1 EAIH-NS算法
Input:知識圖譜中實體和關系集合G=(E,R),訓練、驗證、測試三元組(h,r,t)
1:初始化:初始化實體的嵌入向量e∈E和關系的嵌入向量r∈R.
2:while ilt;=max_step do
3: "采樣一個小批量Gbatch∈G;
4: "while (h,r,t)∈Gbatchdo
5:" "層次聚類并按簇排序分配實體序號
6:" "通過對實體序號高斯分布xi,xj~(N(0,1)×σ+μ)獲得2個和正實體具有較強語義聯系的負實體t′1和t′2
7:" "混合負實體信息t′=β×t′1+(1-β)×t′2得到更高質量的新負實體t′
8:" "新負實體替換頭或尾正實體,檢查新負三元組是否不在預先存在的三元組中
9: ""使用損失函數方程(3)更新相關參數
10: "end while
11: "if(epoch mod 3)==0 then
12:" "重新層次聚類和實體索引生成
13:end while
Output:更新調整后的實體和關系向量
3 實驗和分析
3.1 數據集
EAIH-NS方法主要針對知識圖譜補全任務,通過比較選擇了幾個標準化的數據集。這些數據集有助于公平地比較不同模型的性能。FB15k和WN18是2個早期常用的數據集,它們分別源自FreeBase和WordNet,這2個知識庫廣泛應用于語義網和自然語言處理領域,包含大量的實體及其相互間的關系。但這些初代數據集中存在如數據泄露等問題,即原始數據集中包含大量易于通過模式匹配進行預測的逆關系,對實驗精度具有一定影響。FB15k-237和WN18RR這2個數據集在FB15k和WN18數據集上通過移除可能導致算法過度擬合的三元組,有效提高了鏈接預測任務的挑戰性,在知識圖譜補全任務中更具挑戰性和通用性,可以更好地區分模型的效率,數據集的基本統計數據如表1所示。
3.2 實驗設置
3.2.1 評估方法
在測試階段,對于每個三元組,文章將頭部實體替換為當前 KG 中的所有其他實體,并計算這些替換的三元組和原始三元組的分數,使用第2節中指定的評分函數。由于一些替換后的三元組也可能在原始數據集的訓練、驗證和測試集中存在,因此過濾掉這些三元組然后將剩余三元組按分數降序排列,該排名列表中正確三元組的排名用于評估,整個過程在替換尾部實體時重復。繼之前的研究,使用最常用的指標平均倒數排名(MRR)和 Hits@10。對于所有指標,更高的值意味著更好的性能。
3.2.2 訓練設置
文章模型以PyTorch作為深度學習框架,在A40顯卡上進行所有實驗操作,使用Adam作為梯度優化器。在訓練過程中,該模型在驗證集上不斷進行測試,測試結果被用作評估模型參數優缺點的標準。表2展示了實驗選用模型部分參數。
3.3 實驗結果及分析
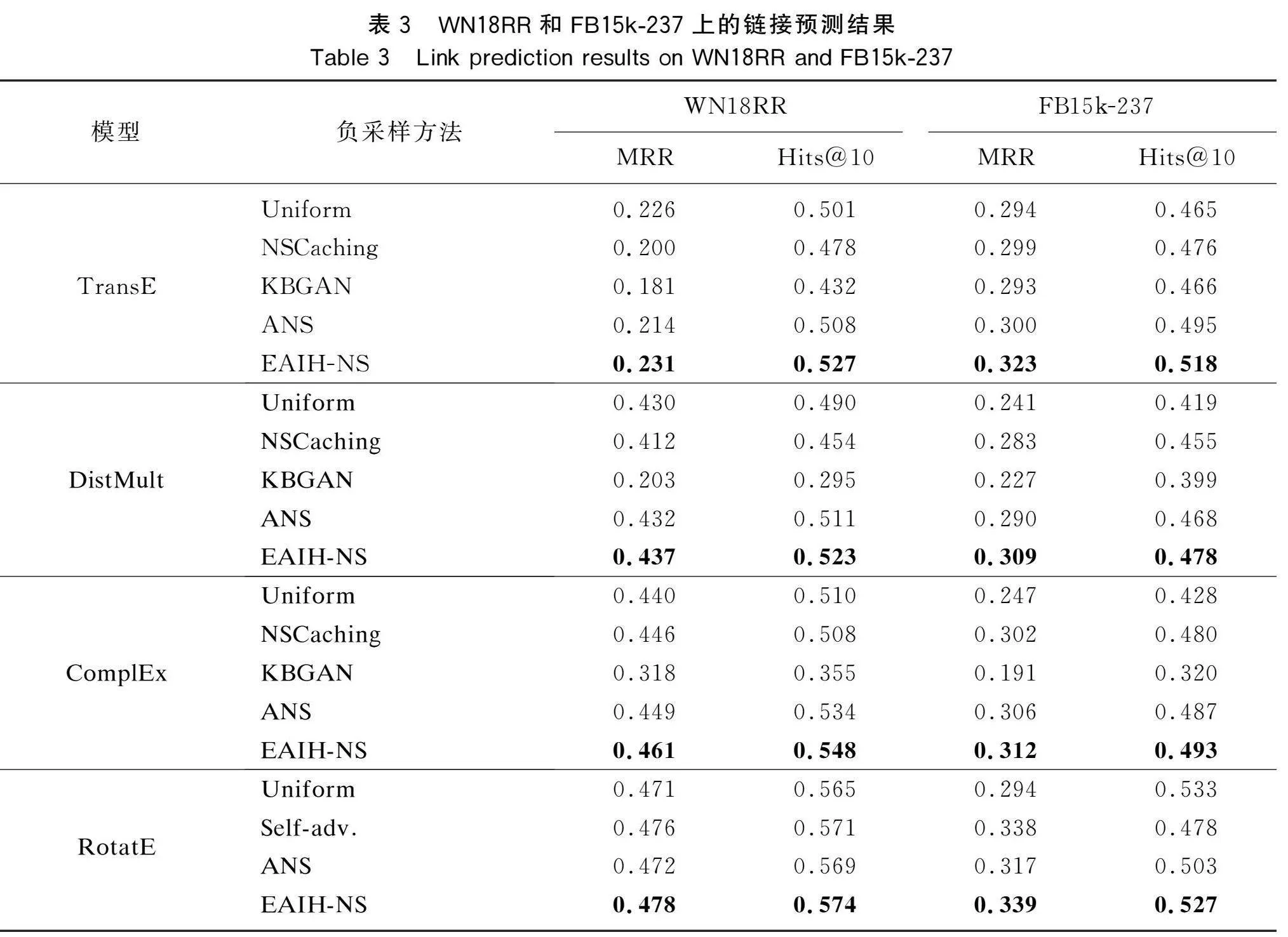
負采樣方法依賴于知識表示學習模型,會對模型的預測精度產生極大的影響。為了充分證明EAIH-NS方法的有效性和優越性,實驗選擇了不同的負采樣方法對不同的知識表示學習模型進行比較測試。負采樣方法選擇經典的均勻負采樣(uniform),從整個實體集中隨機采樣負實體;KBGAN負采樣方法,通過生成對抗網絡框架中的生成器生成高質量的負樣本來訓練[12];NSCaching負采樣方法,構建緩存以存儲高質量的負樣本;還有就是利用K-means聚類選擇負實體的ANS負采樣方法[13]。知識表示學習模型選擇了經典模型TransE、DistMult[14]、ComplEx[15]和RotatE[16],由于原始的RotatE模型使用了自對抗負采樣方法,因此實驗也將自對抗負采樣方法添加到RotatE模型中進行比較。
表3顯示了在2個知識圖譜數據集上使用不同負采樣方法得到的每個模型的實驗結果。表中的實驗數據部分參考了經典文獻和原始論文。將實驗重復3次,以最佳結果作為實驗結果,并用粗體表示在該評價指標下的最佳性能。
實驗結果表明,與其他經典的負采樣方法相比,EAIH-NS產生了顯著的差異,并在提高鏈路預測任務的準確性方面發揮了重要作用。這證明了EAIH-NS方法的有效性,與均勻等靜態負采樣技術和ANS等動態負采樣技術相比,在評估指標上有了很大精進。在RotatE模型的負采樣技術比較實驗中,還比較了對抗性負采樣技術中性能較好的一種——自對抗負采樣技術,在與對抗性負采樣的數據對比中,EAIH-NS方法比KBGAN有更顯著的性能改進,并且與自對抗負采樣技術產生了極其接近的結果,在FB15k-237數據集上,關于Hits@10指標產生了略弱于自對抗負采樣技術的結果。然而,EAIH-NS方法使用了比自對抗負采樣技術更少的參數,降低了模型的整體復雜度。
EAIH-NS相比其基線也產生了顯著的性能提升效果,例如,在TransE模型的情況下,EAIH-NS在WN18RR數據集上相比其基線ANS在MRR指標上的性能提高了7.9%,在FB15k-237數據集上得到的MRR數據提高了7.7%。這說明了層次聚類算法聚集更強語義關系的實體,且混合負實體信息產生更具挑戰性實體對負采樣方法的提升作用,進而影響到知識表示學習模型在鏈接預測任務上的性能。
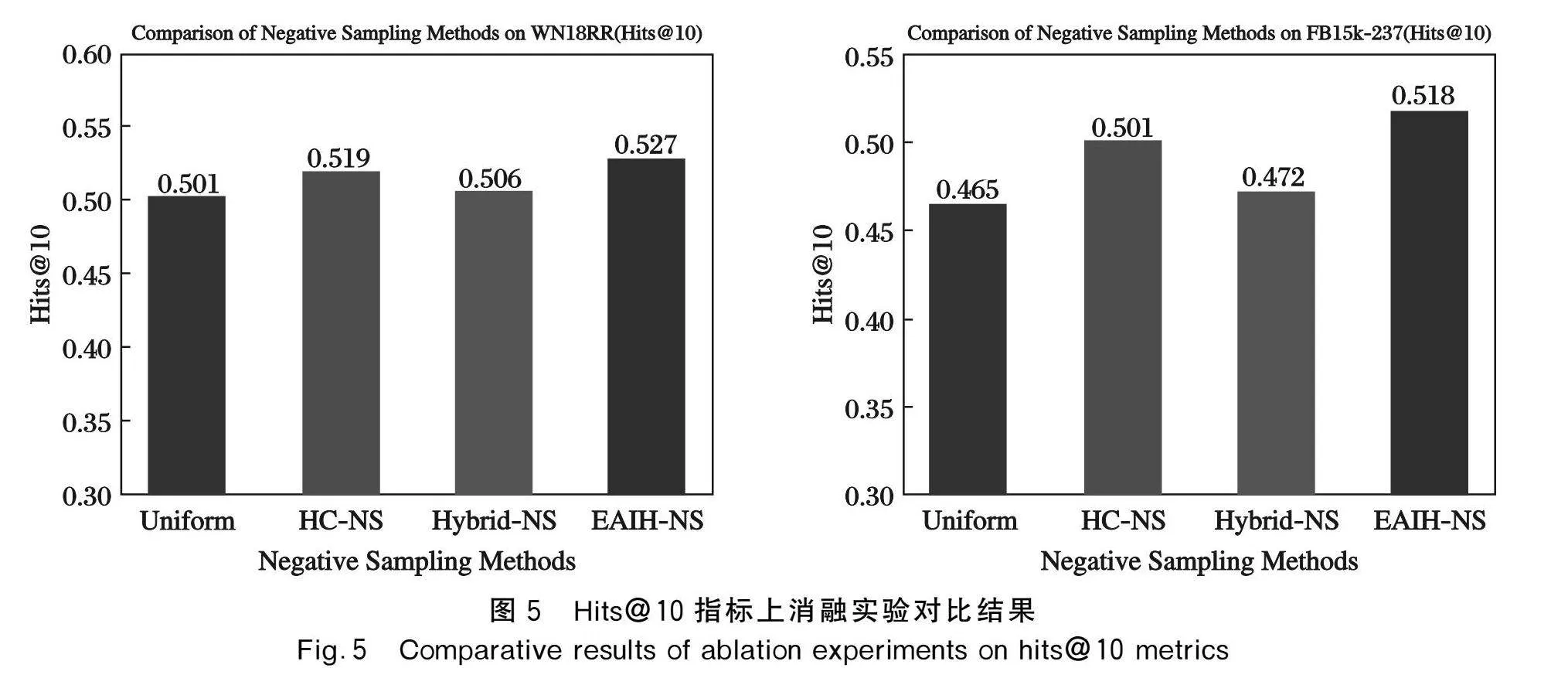
EAIH-NS方法包括實體分類和負實體信息混合。圖5展示了消融實驗的設計,以證明在TransE模型下2種方法分別對模型的提升效果。負采樣方法選擇均勻負采樣(uniform)、層次聚類負采樣(HC-NS)、信息混合負采樣(Hybrid NS)和EAIH-NS。
結果表明,在這2個數據集中都產生了更有區分度的結果。然而,由于Hybrid NS中混合信息的來源是從所有實體中隨機提取的負實體,因此生成的新負實體與隨機均勻負采樣沒有太大區別,性能改進非常有限,在FB15k-237數據集上僅提高了1.5%,遠低于HC-NS。HC-NS與均勻負采樣相比提高了7.7%的性能。EAIH-NS負采樣方法優化了負實體的提取來源,通過實體分類獲得高質量的負實體來源,然后混合負實體信息生成新的負實體,在FB15k-237數據集上,相比于HC-NS和Uniform性能分別提高了3.3%和11.3%。
同理,在WN18RR數據集上,產生了與上述結論類似的實驗結果。Hybrid NS相較于隨機均勻負采樣方法僅產生了1%的性能提升,幾乎可忽略不計。HC-NS方法由于采用了更聚焦于語義層次的實體分類方法,相較于隨機均勻負采樣方法和Hybrid NS方法分別產生了3.6%和2.7%的性能提升。EAIH-NS方法在Hybrid NS方法的基礎上改進了采樣的混合負實體來源,結合了HC-NS方法聚焦實體語義層次的優勢,在WN18RR數據集同樣產生了更具挑戰的負實體,提升了鏈接預測結果的精度。
EAIH-NS在保持較高性能的同時簡化了模型的復雜度,同時通過消融實驗證明了該方法不同模塊的有效性,在實際應用中展現出了極大的潛力。特別是在對比不同的負采樣技術時,EAIH-NS相較普遍采用的知識圖譜負采樣方法產生了更高的精度,這提升了知識圖譜的完整性和準確性,有效擴展了知識圖譜的應用場景。同時利用更少的參數和更簡單的結構,達到了與復雜負采樣方法相似的實驗結果,降低了模型整體復雜度,有助于知識圖譜的實際下游任務應用,節約了計算資源。
4 結 論
當前知識圖譜的負采樣方法部分實現簡單,負樣本質量差;部分質量高,復雜性高。文章提出的EAIH-NS方法利用實體分類和負實體信息混合,有效地對形狀復雜或大小不同的數據集進行聚類,形成更穩定、更高質量的實體簇,進而生成更具挑戰性的負實體,提高了知識圖譜補全的質量。EAIH-NS中使用的實體分類可以在面對小規模和一般規模的知識圖譜時提供高效的分類結果,但在面對復雜的高維知識圖譜時,分類結果在訓練過程中需要多次更新,這對硬件的性能提出了要求,對分類的結果提出了挑戰,未來的研究將集中于研究更有效的方法適應復雜的高維知識圖譜。
致謝 感謝沈陽師范大學研究生項目支持經費專項資金資助項目(SYNUXJ2024055)的支持。
參考文獻:
[1]DONG X L,GABRILOVICH E,HEITZ G,et al.Knowledge vault:A web-scale approach to probabilistic knowledge fusion[C]//Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York:Association for Computing Machinery,2014:601610.
[2]NICKEL M,MURPHY K,TRESP V,et al.A review of relational machine learning for knowledge graphs[J].Proc IEEE,2015,104(1):1133.
[3]WANG Q,MAO Z D,WANG B,et al.Knowledge graph embedding:A survey of approaches and applications[J].IEEE Trans Knowl Data Eng,2017,29(12):27242743.
[4]HOGAN A,BLOMQVIST E,COCHEZ M,et al.Knowledge graphs[J].ACM Comput Surv(Csur),2021,54(4):137.
[5]QIN S G,RAO G J,BIN C Z,et al.Knowledge graph embedding based on adaptive negative sampling[C]//Data Science:5th International Conference of Pioneering Computer Scientists,Engineers and Educators.Guilin:Springer,2019:551563.
[6]BORDES A,USUNIER N,GARCIA-DURAN A,et al.Translating embeddings for modeling multi-relational data[C]// Proceedings of the 26th International Conference on Neural Information Processing Systems.New York:Curran Associates Inc,2013:17872795.
[7]WANG Z,ZHANG J W,FENG J L,et al.Knowledge graph embedding by translating on hyperplanes[C]// Proceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence.Québec City:Publication History,2014:11121119.
[8]KRISHNA K,MURTY M N.Genetic K-means algorithm[J].IEEE Trans Syst,Man,Cybern,Part B(Cybernetics),1999,29(3):433439.
[9]KIAN A,AARASH F,YASMIN S,et al.Structure aware negative sampling in knowledge graphs[C]//Conference on Empirical Methods in Natural Language Processing.Puta:Association for Computational Linguistics,2020:60936101.
[10]HUANG T L,DONG Y X,DING M,et al.MixGCF:An improved training method for graph neural network-based recommender systems[C]//Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery amp; Data Mining.New York:Association for Computing Machinery,2021:665674.
[11]WANG P,LI S,PAN R.Incorporating gan for negative sampling in knowledge representation learning[C]//Proceedings of the AAAI Conference on Artificial Intelligence.New Orleans:AAAI,2018:2005-2012.
[12]HU K,LIU H,HAO T Y.A knowledge selective adversarial network for link prediction in knowledge graph[C]//Natural Language Processing and Chinese Computing:8th CCF International Conference.Dunhuang:Springer,2019:171183.
[13]ZHANG Y,YAO Q,SHAO Y,et al.NSCaching:Simple and efficient negative sampling for knowledge graph embedding[C]//2019 IEEE 35th International Conference on Data Engineering(ICDE).Aomen:IEEE,2019:614625.
[14]YANG B S,YIH W-T,HE X,et al.Embedding entities and relations for learning and inference in knowledge bases[C]//Proceedings of the International Conference on Learning Representations.San Diego:ITHACA,2015:113.
[15]TROUILLON T,WELBL J,RIEDEL S,et al.Complex embeddings for simple link prediction[C]//International Conference on Machine Learning.New York:JMLR,2016:20712080.
[16]SUN Z Q,DENG Z H,NIE J Y,et al.RotatE:Knowledge graph embedding by relational rotation in complex space[C]//Proceedings of the International Conference on Learning Representations.New Orleans:ITHACA,2019:118.
【責任編輯:孫 可】
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
光學精密工程(2016年6期)2016-11-07 09:07:19
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
