依據(jù)散列查找的分布式網(wǎng)絡(luò)數(shù)據(jù)分流算法
2023-12-27 05:05:54梁鑫龍徐永貴
新鄉(xiāng)學(xué)院學(xué)報(bào) 2023年12期
梁鑫龍,徐永貴,史 君
(淄博師范高等專科學(xué)校信息系,山東 淄博 255100)
近年來,在各項(xiàng)先進(jìn)技術(shù)的大力推動(dòng)下,互聯(lián)網(wǎng)規(guī)模和應(yīng)用數(shù)據(jù)量呈直線上升趨勢(shì), 越來越多的應(yīng)用需要借助分布式網(wǎng)絡(luò)實(shí)現(xiàn)快速且精準(zhǔn)的數(shù)據(jù)分流。例如,在通過路由器轉(zhuǎn)發(fā)網(wǎng)絡(luò)數(shù)據(jù)時(shí), 需要在較短時(shí)間內(nèi)快速找出分布式數(shù)據(jù)中的路由表,確保數(shù)據(jù)可以實(shí)現(xiàn)精準(zhǔn)分流。可見,針對(duì)數(shù)據(jù)分流展開研究是十分必要的。現(xiàn)階段,針對(duì)分布式網(wǎng)絡(luò)中的數(shù)據(jù)分流,一般使用專門的分流裝置,按照分流策略,將大流量網(wǎng)絡(luò)中的數(shù)據(jù)分成幾個(gè)小流量的數(shù)據(jù)。 但是,當(dāng)前的分流算法有兩大問題,一是數(shù)據(jù)的完整性問題,二是負(fù)載平衡問題。
對(duì)此, 本文提出基于散列查找的分布式網(wǎng)絡(luò)數(shù)據(jù)分流算法。通過對(duì)網(wǎng)絡(luò)數(shù)據(jù)進(jìn)行特征提取,根據(jù)數(shù)據(jù)不同的特性,將其劃分為多種不同的種類;通過不斷更新數(shù)據(jù)聚類中心,使數(shù)據(jù)具有高度動(dòng)態(tài)變化特征,實(shí)現(xiàn)數(shù)據(jù)的分流處理。將本文方法與其他方法進(jìn)行對(duì)比,結(jié)果表明,本文方法具有最佳的數(shù)據(jù)分流處理效果。
1 分布式網(wǎng)絡(luò)數(shù)據(jù)分流描述
1.1 “流”的局部性定義
“流” 可以被理解為具有相同目的和地址的數(shù)據(jù)包,顧名思義,分流[1-2]就是將具有相同地址和目的的數(shù)據(jù)包劃分為多個(gè)不同的流。 在網(wǎng)絡(luò)環(huán)境下,F(xiàn)TP (文件傳輸協(xié)議)文件和WEB(全球廣域網(wǎng))界面[3]以及其他協(xié)議等具有相同的地址,需要對(duì)其分流后再傳輸。一旦FTP 文件首次發(fā)送成功, 那么在一定的時(shí)間范圍內(nèi),其他分組在同一數(shù)據(jù)流中的成功傳遞概率[4]將會(huì)顯著提高。這種現(xiàn)象稱為流的局部性特征,示意圖如圖1 所示。

圖1 “流”的局部性特征示意圖
1.2 分布式網(wǎng)絡(luò)數(shù)據(jù)分流約束條件
式中,w表示分布式網(wǎng)絡(luò)的大小,x表示網(wǎng)絡(luò)節(jié)點(diǎn)通道,b表示嵌入維數(shù)最小值。
對(duì)分布式網(wǎng)絡(luò)數(shù)據(jù)做歸一化處理[6],得到
將數(shù)據(jù)分流問題近似地看作是具有約束特征的非線性問題,那么可得
通過上述計(jì)算, 可以得到數(shù)據(jù)分流的對(duì)偶函數(shù)[7]表達(dá)式
式中,α表示網(wǎng)絡(luò)節(jié)點(diǎn)的約束條件[8]。
式(4)的約束特性為
在高維空間中,通過式(5)的約束,計(jì)算對(duì)偶函數(shù)的二次函數(shù),表達(dá)式為
1.3 能量消耗模型
當(dāng)網(wǎng)絡(luò)節(jié)點(diǎn)發(fā)送和接收相同數(shù)量的數(shù)據(jù)時(shí), 能耗計(jì)算公式為
式中,l表示分布式網(wǎng)絡(luò)節(jié)點(diǎn)接收和發(fā)送的數(shù)據(jù)總量。
對(duì)于接收數(shù)據(jù)的源節(jié)點(diǎn)來說, 由于其包含頭部信息,使得第k個(gè)獲取數(shù)據(jù)的源節(jié)點(diǎn)能量消耗為
式中,表示源節(jié)點(diǎn)接收數(shù)據(jù)的能耗,、分別表示數(shù)據(jù)量的大小。
將源節(jié)點(diǎn)接收的數(shù)據(jù)做壓縮處理后再進(jìn)行傳輸分流,這個(gè)過程能耗計(jì)算公式為
通過上述分析計(jì)算可知, 分布式網(wǎng)絡(luò)數(shù)據(jù)傳輸分流能耗與數(shù)據(jù)量大小有著直接關(guān)系,數(shù)據(jù)量越大,傳輸和分流數(shù)據(jù)所產(chǎn)生的能耗就越高。
2 基于散列查找的分布式網(wǎng)絡(luò)數(shù)據(jù)分流實(shí)現(xiàn)
將同一個(gè)流中完成分流的數(shù)據(jù)進(jìn)行緩存, 緩存可以減少算法計(jì)算時(shí)間,減少散列表的查找步驟,提高算法整體的運(yùn)算效率。 散列查找中“流”的局部性原理[9]如圖2 所示。
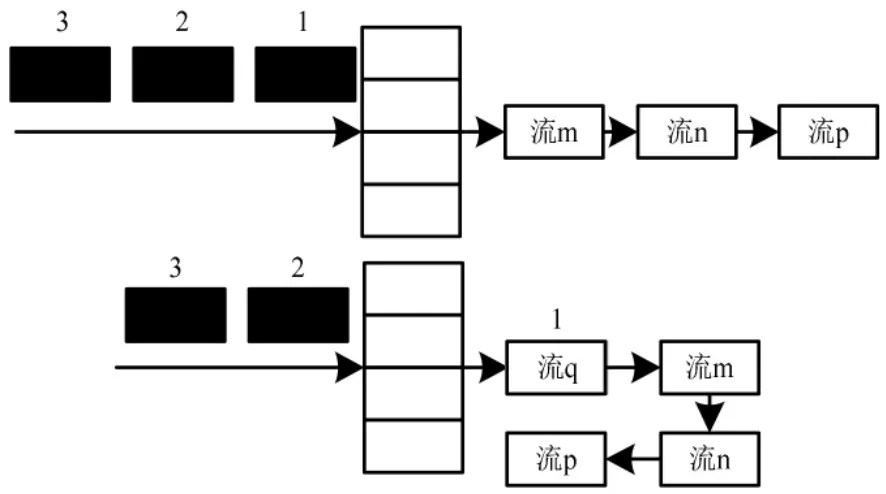
圖2 散列查找中“流”的局部性原理圖
2.1 分布式網(wǎng)絡(luò)數(shù)據(jù)特征提取
完成對(duì)分布式網(wǎng)絡(luò)數(shù)據(jù)的能耗分析后, 從空間重建觀點(diǎn)出發(fā),利用非線性映射方法[10],建立數(shù)據(jù)分流過程的時(shí)間序列信息模型。利用指標(biāo)數(shù)據(jù)的映射方法,建立一個(gè)具有高維映射矢量的非線性模型, 并對(duì)其進(jìn)行分析,得出最優(yōu)解和最大延遲特性,從而實(shí)現(xiàn)對(duì)網(wǎng)絡(luò)數(shù)據(jù)的特征提取。
式中,t0表示數(shù)據(jù)采集初始時(shí)刻, ?t表示數(shù)據(jù)采集間隔時(shí)間段,表示所有網(wǎng)絡(luò)數(shù)據(jù)在同一時(shí)間序列下的相似性特征度,?n表示數(shù)據(jù)相關(guān)性系數(shù)。
式中,si表示映射向量分量,g表示數(shù)據(jù)時(shí)間序列系數(shù)值。
構(gòu)建分布式網(wǎng)絡(luò)數(shù)據(jù)目標(biāo)查找函數(shù), 將R定義為分流過程中數(shù)據(jù)特征矢量的關(guān)聯(lián)函數(shù)[12],ug為數(shù)據(jù)交叉分布模型,用公式表示為
式中,a0表示網(wǎng)絡(luò)數(shù)據(jù)原始采樣幅值,ua?1表示分布式網(wǎng)絡(luò)數(shù)據(jù)均值與方差完全相同的標(biāo)量序列,bi表示最佳分裂屬性。
接下來利用C均值聚類算法對(duì)目標(biāo)函數(shù)進(jìn)行求解,假設(shè)μik是目標(biāo)函數(shù)的聚類最大值,表達(dá)式為
通過式(13)得到數(shù)據(jù)時(shí)延特征ξi,至此完成分布式網(wǎng)絡(luò)數(shù)據(jù)的特征提取。 計(jì)算過程為
2.2 分布式網(wǎng)絡(luò)數(shù)據(jù)分流實(shí)現(xiàn)
對(duì)分布式網(wǎng)絡(luò)數(shù)據(jù)的特征提取后, 根據(jù)數(shù)據(jù)自身特性的不同, 劃分為不同的種類, 完成數(shù)據(jù)的分流處理。 分流的第一步是確定分布式網(wǎng)絡(luò)數(shù)據(jù)的原始聚類中心,在分流過程中不斷更新該中心的內(nèi)容,以此滿足環(huán)境變化帶來的數(shù)據(jù)高度動(dòng)態(tài)變化特征。
用d表示網(wǎng)絡(luò)數(shù)據(jù)的初始聚類中心,將v定義為初始特征數(shù)量, 選出其中的κ個(gè)特征作為初始聚類核心Si,每個(gè)Si代表一種數(shù)據(jù)類型。 通過對(duì)數(shù)據(jù)特征的分析和計(jì)算后,得到v?κ個(gè)數(shù)據(jù)特征與Si之間的目標(biāo)距離。 然后,將數(shù)據(jù)特征劃分到不同的聚類核心中,實(shí)現(xiàn)數(shù)據(jù)特征點(diǎn)的匹配。
通過上述描述將網(wǎng)絡(luò)數(shù)據(jù)特征區(qū)劃分為κ個(gè)不同特征
其中,zi表示分布式網(wǎng)絡(luò)數(shù)據(jù)特性,表示Si的均值化結(jié)果,DF表示網(wǎng)絡(luò)數(shù)據(jù)特征區(qū)劃分形式總數(shù)的類型特征。在分布式網(wǎng)絡(luò)數(shù)據(jù)分流的過程中,通過對(duì)數(shù)據(jù)特征分析和計(jì)算,將數(shù)據(jù)劃分為不同的類型,并根據(jù)特征點(diǎn)匹配的結(jié)果進(jìn)行數(shù)據(jù)分流[13],以達(dá)到提高數(shù)據(jù)處理效率和實(shí)現(xiàn)優(yōu)化的目的。
將網(wǎng)絡(luò)數(shù)據(jù)特征區(qū)劃分為κ種特征后,數(shù)據(jù)特性集合為T j(j=1,2, …,κ),簡(jiǎn)化表示為T={DF}。 經(jīng)過重復(fù)迭代計(jì)算后,確定分布式網(wǎng)絡(luò)數(shù)據(jù)的分流過程。
步驟一:確定分布式網(wǎng)絡(luò)數(shù)據(jù)的原始聚類中心d,將其劃分為κ個(gè)子聚類中心,劃分過程需在滿足
的基礎(chǔ)上進(jìn)行。
步驟二:對(duì)數(shù)據(jù)特性做循環(huán)迭代計(jì)算,得到新的數(shù)據(jù)特征集合TFi+1。
步驟三:當(dāng)g=0時(shí),聚類中心為TF0。
步驟四:在此基礎(chǔ)上,分析數(shù)據(jù)分流過程中的誤差和方差。 當(dāng)方差滿足預(yù)先設(shè)定的值后,停止計(jì)算,輸出結(jié)果即為最終的分流結(jié)果。
網(wǎng)絡(luò)數(shù)據(jù)的聚類中心不斷更新變化,可以更好地適應(yīng)互聯(lián)網(wǎng)環(huán)境下的數(shù)據(jù)動(dòng)態(tài)變化特性[14],得到最佳分流函數(shù)
綜上所述, 基于散列查找的分布式網(wǎng)絡(luò)數(shù)據(jù)分流過程如圖3 所示。

圖3 基于散列查找的分布式網(wǎng)絡(luò)數(shù)據(jù)分流過程
3 仿真實(shí)驗(yàn)
為了驗(yàn)證本文方法在實(shí)際應(yīng)用中是否同樣有效,與馬爾科夫決策過程和數(shù)據(jù)分區(qū)算法展開對(duì)比仿真實(shí)驗(yàn)。實(shí)驗(yàn)中,數(shù)據(jù)集選用的是Kddcup99 數(shù)據(jù)集,其中包含了實(shí)驗(yàn)所需要的高速網(wǎng)絡(luò)流量數(shù)據(jù)。
3.1 所提方法性能測(cè)試
為了驗(yàn)證所提方法在網(wǎng)絡(luò)數(shù)據(jù)分流方面的性能,以網(wǎng)絡(luò)擁塞率為指標(biāo)對(duì)其進(jìn)行測(cè)試,結(jié)果如圖4 所示。

圖4 所提方法平均時(shí)延結(jié)果
從圖4 中可以看出, 所提方法擁塞率始終都保持在較低的水平, 可保證數(shù)據(jù)分流時(shí)具有較高的傳輸效率。這是由于所提方法對(duì)數(shù)據(jù)進(jìn)行聚類劃分,根據(jù)數(shù)據(jù)特性的不同將其劃分到不同的聚類中心中, 結(jié)合最佳分流函數(shù), 即可保證數(shù)據(jù)在分流過程中避免出現(xiàn)擁塞的情況。
3.2 3 種算法負(fù)載平衡效果對(duì)比
計(jì)算機(jī)負(fù)載平衡效果可以通過計(jì)算丟包率與網(wǎng)絡(luò)數(shù)據(jù)流量得到。 3 種算法負(fù)載平衡效果如圖5 所示。

圖5 3 種算法負(fù)載平衡效果對(duì)比結(jié)果
通過觀察圖5 可以很明顯地看出: 在3 種算法中,本文方法的丟包率最低,且曲線整體波動(dòng)較為平緩。 反觀其他兩種方法,丟包率相對(duì)較高,而且曲線波動(dòng)幅度較大。
3.3 3 種算法分流效率對(duì)比
分流效率OEο就是分流得到的網(wǎng)絡(luò)數(shù)據(jù)流量與數(shù)據(jù)總流量之間的比率,計(jì)算公式為
分流效率可以更加清晰地反映分流算法的性能優(yōu)劣。 分流效率值越接近100%,算法的分流性能就越優(yōu)秀。 3 種算法分流效率對(duì)比結(jié)果如圖6 所示。

圖6 3 種算法分流效率對(duì)比結(jié)果
從圖6 中可以看出:隨著網(wǎng)絡(luò)數(shù)據(jù)流量的不斷增加,3 種算法展現(xiàn)出了不同的分流效率; 本文方法取得的分流效率最接近100%,數(shù)據(jù)分區(qū)算法次之,馬爾科夫決策過程最低。這是由于本文方法對(duì)網(wǎng)絡(luò)數(shù)據(jù)進(jìn)行特征提取后, 通過映射的方式建立了非線性數(shù)據(jù)分流模型,在一定程度上提高了算法的分流效率。
4 結(jié)論
傳統(tǒng)算法在對(duì)網(wǎng)絡(luò)數(shù)據(jù)分流時(shí)常常存在分流效率低、耗時(shí)長(zhǎng)、負(fù)載不平衡等情況,基于此,本文提出了基于散列查找的分布式網(wǎng)絡(luò)數(shù)據(jù)分流算法。對(duì)網(wǎng)絡(luò)數(shù)據(jù)分流能耗計(jì)算后,對(duì)散列查找中“流”的局域性展開分析;建立網(wǎng)絡(luò)數(shù)據(jù)分流的目標(biāo)函數(shù),通過求解計(jì)算后完成數(shù)據(jù)的特征提取;將數(shù)據(jù)特征區(qū)劃分為不同的類型,通過計(jì)算數(shù)據(jù)特性誤差方差完成數(shù)據(jù)分流。 仿真實(shí)驗(yàn)結(jié)果表明,本文方法取得了最佳負(fù)載平衡效果和較高分流效率。
猜你喜歡
甘肅教育(2020年14期)2020-09-11 07:57:42
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
中國(guó)生物醫(yī)學(xué)工程學(xué)報(bào)(2017年6期)2017-02-10 05:11:45
時(shí)代英語(yǔ)·高二(2015年1期)2015-03-16 00:08:11
噪聲與振動(dòng)控制(2015年4期)2015-01-01 07:08:21
中國(guó)衛(wèi)生(2014年11期)2014-11-12 13:11:32
河南科技(2014年23期)2014-02-27 14:19:15
