基于設備運行狀態檢測與能量回歸同步評估的居民非介入式負荷辨識算法研究
2023-12-25 05:50:58宋瑋瓊王立永宋威朱肖晶穆毅凡馮燕鈞
電測與儀表 2023年12期
宋瑋瓊,王立永,宋威,朱肖晶,穆毅凡,馮燕鈞
(1.國網北京市電力公司電力科學研究院,北京 100080;2.國網北京市電力公司門頭溝供電公司,北京 100080; 3.東南大學,南京 211189)
0 引言
非侵入負荷辨識( NILM) 技術是一種在用戶總進線處通過智能電能表或其他信號采集分析設備使用各種信號處理或模式識別方法將總測量電量的分解為各個設備分項電量的過程。非侵入負荷辨識技術能夠高效低成本的獲得用戶分項電能情況,而分項負荷電量的提取能夠同時支撐多種具體業務。文獻[1]顯示向消費者提供設備級能耗反饋可以為每個住宅節省多達12%的能源。文獻[2]通過畫像技術辨識具有特殊用電行為的弱勢群體,例如孤寡老人,針對特殊群體開展其他服務。由于分項負荷感知帶來的作用愈加重要,越來越多的學者開始進一步研究并改善非侵入負荷辨識算法的精度。
非侵入負荷辨識的傳統實現基于事件檢測、匹配的辨識方案,最早由George W. Hart 于1992 年提出[3],其依賴于正確檢測設備的“開關”事件,因其快速高效的特點受到大量學者的研究優化[4-5],但在小功率啟停、特征相似設備啟停、開關事件重疊等場景中存在事件匹配失效的局限性[6]。為解決上述問題,隱馬爾科夫模型( HMM) 被應用到負荷辨識領域。通過對用戶設備使用規律的統計分析,HMM 模型能夠學習到用電負荷的時序特征,并在一定程度上解決上述問題,文獻[7]采用最大期望算法尋找最佳的隱狀態序列,但在用電設備較多場景下算法容易陷入局部最優,文獻[8]提出了一種超狀態HMM 和稀疏維特比算法,可以分解具有大量狀態的用戶場景,但未詳細分析負荷連續變化型設備對算法的影響。
近年來,隨著神經網絡在語音圖像識別領域的大量成功應用,非侵入負荷辨識的算法研究領域因其問題本身與語音識別的相似性,也逐漸將神經網絡引入到問題的分析中。文獻[9-10]提出基于多層長短記憶神經網絡( LSTM) 深度神經網絡,實現負荷功率時間關聯性的跟蹤。文獻[11]嘗試了卷積神經網絡( CNN)串聯LSTM,通過引入CNN 提升模型特征提取能力,并改善了訓練與預測效率。文獻[12]改進了原本輸入序列輸出序列的網絡結構,提出了序列到功率點的分解方法,成功提升了分解精度,但大大增加了計算時間。在研究者不斷提升優化負荷功率分解模型準確性的同時,也有學者提出對于負荷辨識某些應用不需要準確的功率信息,只需要準確的設備運行時間,因此聚焦在設備啟停狀態的辨識上,文獻[13]使用CNN 網絡對設備進行分類,并輸出設備運行的0/1 狀態,文獻[14]通過循環神經網絡( RNN) 在實現設備是否運行的同時,額外分辨了同一設備的不同種工作狀態。
盡管在通過神經網絡進行能量回歸后根據功率閾值可以進行使用時間的判斷,但由于辨識結果的高噪聲,尤其在設備小功率運行的判斷中容易錯誤估計,因此有必要獨立的進行運行狀態估計。機器學習算法通常通過評估單個損失函數來針對一個任務進行優化,但如果存在多個相互關聯的任務,可以通過優化多個損失函數來訓練模型,而這樣的多任務學習模式可以提高每個任務的性能指標[15]。負荷辨識中能量分解和設備狀態檢測是兩個緊密相關的任務,在它們之間共享訓練參數可以進一步提高NILM 的性能。
文中針對基于能量閾值估計設備運行狀態的局限性以及能量分解過程中在設備未運行處的噪聲污染,提出了基于能量分解與設備運行狀態評估的多任務學習模型,以改善負荷辨識效果。論文首先對獨立使用能量分解網絡進行負荷辨識的方法存在的局限性進行分析,提出了狀態與能量同步估計的算法框架;隨后根據負荷能量分解與設備運行狀態的強關聯特性選擇了硬參數共享的多任務學習框架,并針對不同任務中對輸入序列全局信息與局部信息的敏感度差異,提出基于多感受野融合的殘差網絡;最后,實驗結果表明文中提出的算法方案取得了預期的效果,尤其在洗衣機與洗碗機設備上的能量誤差相較傳統網絡取得了50%的性能提升。
1 問題建模
對于非侵入負荷辨識問題,最常見的描述方式即為,總進線處有功功率序列等于各個分設備在不同時刻有功功率疊加的總和如式(1) 所示。
式中y(t) 為用戶電能表總進線處t時刻的有功功率值;xi(t) 為第i個設備在t時刻的有功功率值; ε(t)為t時刻的線路損耗及其他誤差功率值。相對應的,在進行基于深度網絡的負荷辨識算法流程如圖1 所示,通過總功率序列及分設備功率序列進行模型學習,在訓練得到最終參數后,可進行負荷的分離預測。
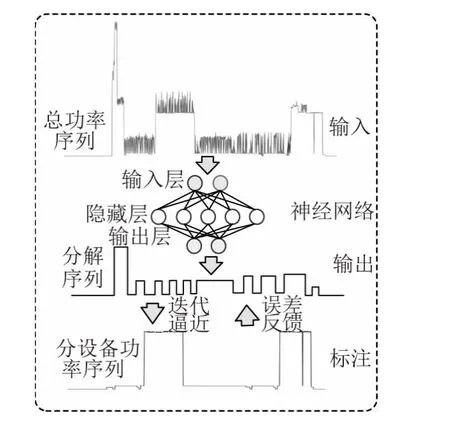
圖1 深度網絡算法學習分析過程Fig.1 Deep network algorithm learning and analysis process
在得到分項設備的功率數據后,即可通過設置閾值判斷設備的運行狀態,如式(2) 所示。
式中si(t) 為用戶t時刻的第i個設備啟停狀態,1為啟動,0 為關閉;THRi為判斷第i個設備啟停狀態的功率閾值。
而對于洗衣機、洗碗機這些小型電機類設備,其非電加熱檔位時,運行功率一般小于100 W,且運行時阻力負載不穩定,運行時功率波動,另外電機水泵程間隔運行特征,因此圖2( a) 中信號按照式(2) 分析后得到如圖2( b) 所示運行狀態情況,這與圖2( c) 所示實際設備運行狀態存在差異。對于這種狀態輸出的差異實際可以通過額外的算法進行改進,但由于神經網絡在進行信號分離時傾向在電器不工作的時段進行噪聲估計,一方面影響整體的能量分解效果,另一方面估計的噪聲可能會影響此類小功率設備在使用閾值法判斷啟停的準確性,因此同時評估設備的使用功率和運行狀態能夠進一步提升負荷辨識的準確度。

圖2 洗衣機運行功率與運行狀態示意圖Fig.2 Schematic diagram of running power and running state of washing machine
因此當可以同時評估出一個設備的運行狀態和行狀態和運行功率時,負荷辨識問題即可描述為式(3) :
式中xi(t) 為第i個設備在t時刻的有功功率值;si(t) 為用戶t時刻的第i個設備啟停狀態,每個設備的最終功率被表示為網絡輸出的功率信號與運行狀態信號的乘積。此處可以通過兩個獨立的模型同時生成功率序列和時間序列,但由于功率序列和時間序列兩者本來存在著一定的相似性,因此可以通過一個網絡同時生成有功功率與運行狀態的多任務學習模式進行設計,下一節將詳細展開說明。
2 多任務學習模型
2.1 深度網絡多任務學習
多任務學習的先驗出發點來自于為了學習一個新的任務時,通常會使用學習相關任務中所獲得的知識。從機器學習的角度來看,多任務學習是一種歸約遷移( inductive transfer) 。歸約遷移通過引入歸約偏置( inductive bias) 來改進模型,使得模型更傾向于某些假設。在多任務學習場景中,歸約偏置是由輔助任務來提供的,這會導致模型更傾向于那些可以同時解釋多個任務的解[15]。
基于深度神經網絡的多任務學習中常用兩種方法:隱層參數的硬共享與軟共享。以文中負荷辨識中能量回歸與運行狀態評估的多任務學習為例進行說明,如圖3 所示,其中參數硬共享機制中兩個子任務完全共享隱藏層參數,只在子任務相關的輸出層使用獨立的網絡參數,這種做法類似遷移學習中只在全連接輸出層進行微調的方案,能夠降低過擬合的風險;參數軟共享機制中,每個任務都有獨立的模型,獨立的參數,同時通過子任務模型參數的距離進行正則化實現模型間參數的相似性以滿足規約偏置假設,常見的距離正則化有L2距離正則化,跡正則化等。

圖3 深度網絡多任務學習機制Fig.3 Deep network multi-task learning mechanism
文中選擇硬參數共享的模式進行多任務學習,原因有如下兩點:1) 功率序列與設備序列任務非常接近,通過隱藏層參數共享,兩個任務輸出全連接層參數獨立訓練的模式能更大程度體現兩個任務的關聯性;2)硬參數共享模型能夠壓縮模型大小,提升模型訓練和計算效率。
在進行多任務訓練時,損失函數需要同時考慮功率誤差與運行狀態誤差,前者使用均方誤差,后者使用交叉熵,定義如式(4) 、式(5) 所示。
式中si(t) 和為用戶t時刻的第i個設備啟停標簽狀態與預測狀態;xi(t) 和分別為用戶t時刻的第i個設備功率標簽信息和預測信息;為t時刻設備啟動的概率,取值為0 ~1 之間。
2.2 基于多感受野融合的殘差網絡
非侵入負荷辨識問題本質上是時間序列問題的一種,在深度學習領域,用于分析和學習時間序列特征的常用網絡為RNN 循環神經網絡與LSTM 長短時間記憶網絡,其兩者都能通過記憶的方式獲得序列的因果關系,但其在訓練時與預測時缺乏并行性,一次只能處理一個時間步,極大程度地降低了網絡運行的效率。此時時間卷積網絡TCN[16]成為了處理時間序列問題的另一種選擇,類似圖像處理中二維卷積核在二維輸入上滑動,依次提取數據中的抽象特征,在時間序列處理中同樣可以使用一維卷積核在序列輸入上進行滑動,當滑動順序按照時間先后關系即可得到因果關系,并且由于卷積網絡具有很好的并行性,并不固限于一次處理一個時間步,因為時間卷積網絡有著更快的訓練與預測速度。文中以殘差結構為基礎設計一種多感受野融合的時間膨脹卷積模型,通過不同感受野對設備啟停的粗粒度信息和功率細節信息進行同步感受。
殘差結構[17]可以保證網絡充分利用其深度,解決模型訓練過程中梯度消失的問題,增強和提高模型整體學習性能,殘差塊的基本結構如圖4 所示。
膨脹卷積為多層時間卷積的組合,但在卷積過程中進行了一些輸入數據的選擇性跳過,從而得到更大的感受野,其在不改變參數數量的前提下擴大了網絡感受野,如圖5 所示。圖中為卷積核大小為3 的三層非因果膨脹卷積結構[18],非因果意味著t時刻輸出與t時間前后的輸入都有關系,增大了信息的感受。網絡的第一層膨脹率為1,即普通卷積;第二層膨脹率為2,每兩個實際卷積的輸入之間跳過了一個值; 第三層膨脹率為4,實際卷積的輸入之間跳過了三個值。t時刻的輸出yt實際上由輸入層的15 個值決定,通過依次增大膨脹率的方法,網絡擴大了感受野,使得對時間序列的特征提取更加完備、更具有優勢。

圖5 非因果膨脹卷積結構Fig.5 Non-causal dilated convolution structure
由殘差塊構成的膨脹卷積網絡中,每一個殘差塊中的兩層非因果卷積層具有相同的膨脹率,而隨著網絡變深,殘差塊的膨脹率成倍數增加,當最后一個殘差塊的膨脹率為2D時,最終輸出序列中的每一個值所具有的感受野S可用下式進行計算:
式中k為卷積核大小( 設為奇數) ;2i為每一個殘差塊中兩層非因果卷積的膨脹率。需要注意的是,由于本次算法設計要求輸入與輸出具有相同的長度,因此每層網絡需要在序列兩側進行填充零值( Padding) ,其數量為:
對于文中設計的非侵入負荷辨識多任務學習問題,既要分析全局的負荷運行狀態和負荷功率趨勢,又要細致擬合設備不同工作模式下的細節功率數據,因此在模型設計時考慮將多個具有不同感受野的膨脹卷積進行并行,分別提取不同粒度下的特征進行融合,以獲得更好的辨識效果,整體設計模型如圖6 所示。
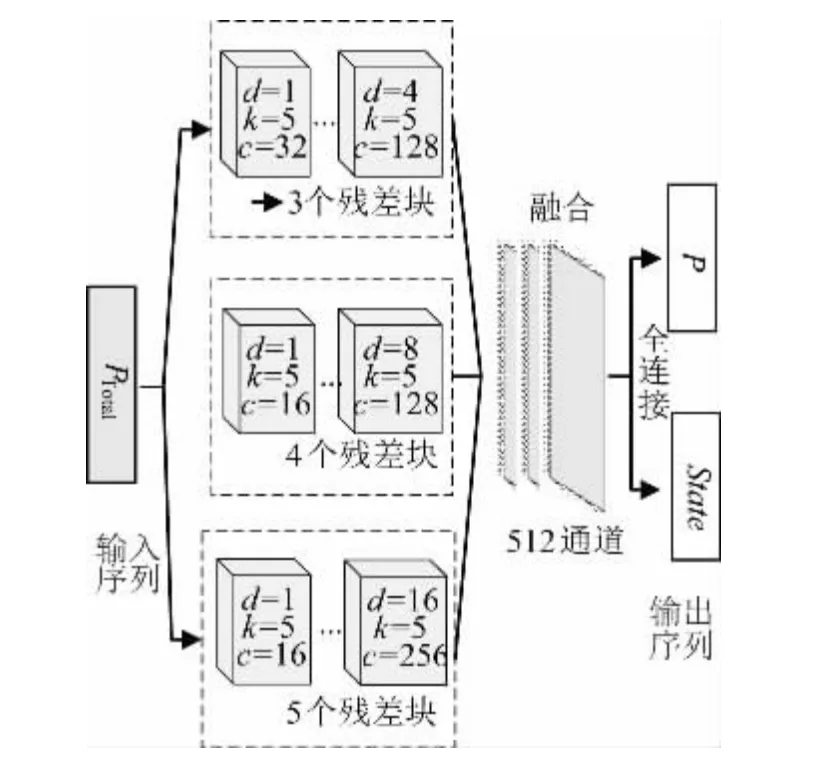
圖6 多感受野融合的網絡結構Fig.6 Network structure of multi-receptive field fusion
3 實驗與分析
3.1 樣本生成
文中選擇UK-Dale 數據集[19]作為實驗數據集,UK-Dale 采自英國,在非侵入負荷辨識科研領域有著廣泛的應用。其數據采樣頻率為1/6 Hz,錄有較多種類的電器,能滿足神經網絡訓練對數據量的要求。在這些電器中,文中選擇耗電量、運行特征及普及程度都較突出的五種電器來進行對比實驗: 電水壺,微波爐,冰箱,洗碗機,洗衣機。其中,電水壺為運行穩定的阻性負載,微波爐和冰箱為運行穩定的容性負載,洗碗機和洗衣機為持續性不規律電機負載疊加穩定阻性加熱負載,這幾類設備的選擇能夠滿足文中對多任務學習模型在波動負荷及穩定運行負荷上不同改進效果的分析。
如表1 所示,UK-Dale 數據集中,這五種電器都存在于至少三個用戶數據中,其分布情況如表1 所示。其中,微波爐和洗衣機在用戶4 中公用同一個分電能表,故文中將用戶4 中的這兩種電器的數據排除在外。文中將用戶5 統一用做測試集,其余用戶按照6 ∶1 的比例將數據劃分為訓練集與驗證集。

表1 辨識電器的分布情況Tab.1 Identifying the distribution of electrical appliances
不同類型的電器有不同范圍的運行時長。而神經網絡需要事前設定輸入樣本的長度,所以需要對以上五種電器確定不同的統一窗長。另外,每次輸入的樣本應盡可能地包含目標電器的一個完整工作周期,這方便神經網絡去從宏觀學習到電器的工作特征,由于UK-Dale 的數據采集頻率為1/6 Hz,按照各個設備典型運行時間進行分析后,可得到表2 中各類設備樣本的窗長信息,折算為分鐘信息分別為6. 4 min、12. 8 min、51.2 min、102.4 min 和102.4 min,均能覆蓋其典型運行時長。

表2 辨識電器的窗長大小Tab.2 Identifying the window size of electrical appliances
在進行樣本生成時,需要對主電能表與分電能表中的數據進行截取及標注。對于某類目標設備而言,其正樣本即為包含該類設備完整運行信息的功率曲線,具體步驟如算法1 所示,算法首先根據分電能表數據分析正在運行狀態,隨后對異常數據及實際同屬一次的運行區間進行合并,隨后將最終的運行區間隨機存入窗長序列中,并得到對應的樣本與標注;同時,由于真實工況下并不只包含有目標電器運行的情況,為保證泛化性,需要在訓練集和測試集中增加不包含有目標電器運行的樣本,使神經網絡能夠分辨目標電器運行與否的工況,隨機選取目標設備運行后一段時間內的數據,且不包含下一次該設備運行區間,加入樣本空間。
算法1:樣本生成方法如下:
輸入:分電能表曲線X,總電能表曲線Y。
輸出:正樣本集φT,功率標注集φP,啟停狀態標注集φS。具體程序如下:
①:S= find(X>Pmin) //根據設備最小運行功率Pmin得到設備運行狀態
②:記錄S 中每一段獨立的運行區間Q={si|i=1,2…}
③:根據最短運行時長duration從Q剔除異常區間&
根據最短運行間隔gap將Q中多個區間進行合并
④:For allsiinQ
⑤:計算si運行區間[start;end]及長度len
⑥:隨機生成t,并滿足t+len<windowLen
⑦:seqA=Y[start -t:start-t+windowLen]/Pmax- >φT//Pmax為用戶運行最大功率,此處進行歸一化操作
⑧:pA=X[start-t:start-t+windowLen]/Pmax- >φP
⑨:stateA=zeros(windowLen)state(t:t+len-1) =1 ->φs
⑩:隨機生成t,滿足end+t+windowLen<si+1.start
3.2 實驗模型結構
為驗證本次實驗效果的有效性,文中選取4 種網絡模型進行結果比對,第一種為文獻[14]中提出的基礎卷積網絡,第二種網絡為文中提出的多感受野融合網絡,但是不進行包含運行狀態預測的功率單任務學習,第三種網絡為文中提出的多任務辨識深度殘差網絡,第四中為文獻[20]中提出的基于軟參數共享的多任務學習網絡,他們的具體參數分別如表3、表4 所示。

表3 卷積神經網絡模型Tab.3 Convolutional neural network model
其中,網絡內Bilstm 單元和Attention 單元采用TanH 激活函數,除輸出層外所有層均采用ReLU 激活函數,輸出層采用sigmoid 激活函數。文中對四種網絡均使用動量優化器進行訓練,單任務學習的兩個網絡損失函數使用功率數據的均方誤差函數Lp,多任務學習的兩個網絡損失函數使用均方差誤差與交叉熵的組合函數,由于兩個任務在單獨訓練時的損失函數在比例上存在偏差,因此如果直接線性相加可能發生多任務優化時網絡更加側重某個子任務的優化,因此本文根據啟停辨識單任務與能量回歸單任務學習時的兩個損失函數訓練結束時的比例關系進行多任務學習時的損失函數超參數,如下式所示:
式中,系數的選擇用以保持其與能量回歸單網絡的損失函數Lp數量級保持一致,方便下文進行相關比較。
3.3 算例結果
文中的辨識結果需要從設備開關狀態與設備功率信息層面兩方面進行評價,在本次實驗中,兩個多任務學習網絡會輸出設備運行狀態,可以直接用以評價,而兩個只進行能量回歸的網絡可以參考算法1 中運行狀態計算方法對分解后的能量曲線進行啟停狀態計算。對于設備開關狀態的評價使用f1值進行。在f1評價體系中,P代表設備運行的時間點集合,N代表設備關停狀態的時間點集合,TP是預測正確的設備運行時間點集合,TN是預測正確的設備關停狀態時間點集合; 同樣地,FP和FN代表預測錯誤的設備運行時間點集合和預測錯誤的設備關停狀態時間點集合f1值可由下式進行計算。
式中precisionk描述設備k被辨識為啟動狀態的正確率;recallk描述設備k實際為運行狀態的時間點中判斷正確的比率。fk是一個介于0 到1 的值,fk值越大,證明模型的分類效果越好,若精確率與召回率有一方太小,都將影響到fk值。
對于設備功率信息的辨識準確度,文中使用平均絕對誤差( Mean Absolute Error,MAE) 進行評價,即:
式中T為樣本的長度;xt為t時刻實際的功率;(t) 為t時刻辨識得到的功率。
四個網絡在不同設備上的f1指標如表5 所示,從表中可知,四個網絡在電水壺上的f1指標接近,在洗碗機和洗衣機上文獻[15]所提多任務學習網絡與文中所提多任務學習網絡與單能量回歸網絡的差距最大,總體上文中所提網絡的f1指標在所有設備上為最大值。

表5 四種網絡模型下各類設備辨識結果的f1指標Tab.5 f1 index of identification results of various devices under four network models
四個網絡在不同設備上的MAE 指標如圖7 所示。從圖7 中可以看到,MAE 指標與f1指標在不同網絡上的趨勢基本一致,文中所提網絡在所有網絡中取得了最小的能量誤差,同時在洗衣機與洗碗機這兩個負載波動型負荷上相較其他網絡取得了最優提升,其中與基礎卷積網絡相比分別減少了60%和46%的能量誤差。而對于負載運行相對穩定的電水壺、微波爐和冰箱設備,多任務學習模型取得的性能提升遠小于在負載波動型設備上取得的效果,這實際與多任務學習模型能夠更好的消除波動型負荷的辨識結果噪聲干擾機理保持了一致。

圖7 不同模型下各類設備辨識結果的MAE 指標Fig.7 MAE index of identification results of various devices under different network models
圖8展示了多感受野殘差網絡單任務學習與多任務學習關于洗衣機設備的預測結果的細節比較,同樣從圖中可以看出,無論辨識準確性還是小功率震動部分的細節預測上,后者都優于前者。圖8( a) 下方虛線框所標注位置與圖8( b) 相比,其辨識結果的波動趨勢與真實功率曲線的匹配度低,即多任務模型改善了負荷波動狀態下的辨識噪聲污染。同時,圖8( a) 左側虛線框標注位置還存在部分錯誤辨識,多任務學習機制的引入同樣整體提升了辨識效果。
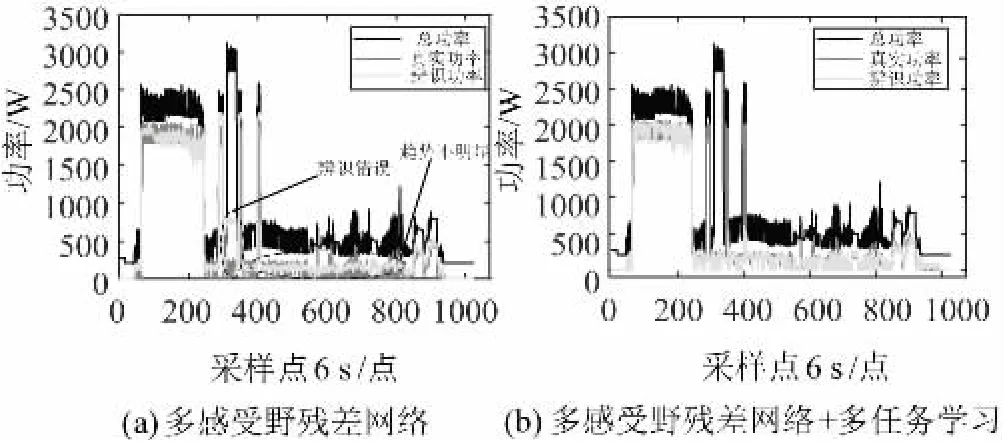
圖8 洗衣機辨識結果示意Fig.8 Schematic diagram of identification results of washing machine
通過多感受野融合單任務網絡與多任務網絡模型的變量控制實驗可知,本文所提的多任務學習機制對負荷辨識的精度進行了提升。在實際進行辨識應用時,多任務學習模型的計算復雜度并未發生實質變化,僅增加了一個全連接層的額外計算量,且在模型訓練時相比單任務學習網絡僅增加了有限數量的輪次。如圖9 所示,多任務學習模型開始訓練時損失函數值大于單任務學習模型,隨著訓練輪次的增加,單任務模型有先達到收斂條件,多任務模型在額外的15 輪迭代后也達到了收斂條件,且最終損失函數值小于單任務模型。
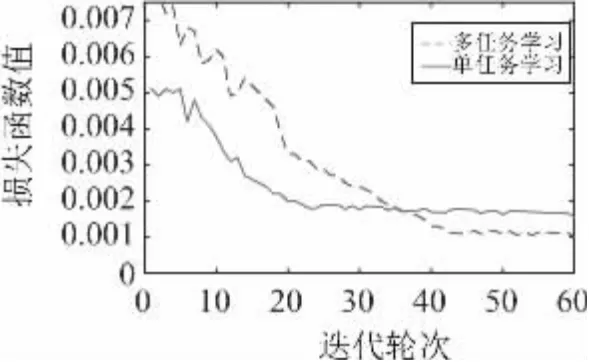
圖9 每輪次模型損失函數變化趨勢( 洗衣機)Fig.9 Change trend of model loss function in each epoch ( washing machine)
4 結束語
提出了一種基于能量分解與設備運行狀態評估的多任務學習模型,以改善僅使用負荷辨識能量回歸單網絡結果評估設備運行狀態的局限,通過狀態與能量同步估計并點乘輸出的算法框架,提升能量分解過程中在設備未運行處的噪聲污染。文中針對設備能量回歸與狀態評估任務,對輸入序列全局信息與局部信息的敏感度差異,構建了基于多感受野融合的殘差網絡。實驗結果表明,基于能量分解與設備運行狀態評估的多任務學習模型在未額外增加過多的訓練和預測計算成本的基礎上,實現了辨識精度的提升,尤其在洗衣機等存在小功率波動運行工況的設備上效果更為明顯。值得進一步優化的是,文中所設計的網絡仍然僅針對單個設備有效,不同設備需要獨立訓練不同的參數,在后續的研究中將進一步優化為單個網絡同時支持多個設備的負荷辨識,以減少實際應用時的參數存儲與計算時間成本。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中國特種設備安全(2022年6期)2022-09-20 02:52:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
經濟技術協作信息(2018年22期)2019-01-19 03:00:18
電子制作(2018年11期)2018-08-04 03:26:08
光學精密工程(2016年6期)2016-11-07 09:07:19
工業設計(2016年12期)2016-04-16 02:52:00
核科學與工程(2015年4期)2015-09-26 11:59:03
設備管理與維修(2015年12期)2015-04-09 06:57:00
