基于GRU-LSTM算法的物聯(lián)網(wǎng)數(shù)據(jù)入侵檢測分析
2023-12-21 11:59:21王大蕾
電子產(chǎn)品世界 2023年10期
王大蕾

關(guān)鍵詞:GRU-LSTM 算法;數(shù)據(jù)入侵;檢測方法;誤報(bào)率
中圖分類號:TN915.08;TP391.44 文獻(xiàn)標(biāo)識(shí)碼:A
0 引言
當(dāng)前,物聯(lián)網(wǎng)技術(shù)的廣泛應(yīng)用已經(jīng)對人們的日常生活以及工業(yè)生產(chǎn)過程產(chǎn)生了重要影響,也為各類互聯(lián)網(wǎng)應(yīng)用技術(shù)的發(fā)展提供了可靠的基礎(chǔ)[1]。網(wǎng)絡(luò)通信技術(shù)的進(jìn)步對各行業(yè)都產(chǎn)生了明顯影響,一旦離開網(wǎng)絡(luò),所有行業(yè)都將無法正常運(yùn)行,因此需要進(jìn)一步提升網(wǎng)絡(luò)的安全性能,這是許多學(xué)者開展互聯(lián)網(wǎng)研究的重點(diǎn)方向[2-3]。為有效防范網(wǎng)絡(luò)威脅,提升網(wǎng)絡(luò)安全性,需要建立可靠的入侵檢測方法。除了需要對網(wǎng)絡(luò)中的計(jì)算機(jī)進(jìn)行監(jiān)測以外,還需在傳輸過程中對各類數(shù)據(jù)做好防范,對網(wǎng)絡(luò)受到的攻擊、信息竊取等行為進(jìn)行嚴(yán)密監(jiān)控,建立網(wǎng)絡(luò)非法訪問等行為的保護(hù)技術(shù)[4]。現(xiàn)階段,防火墻在各類網(wǎng)絡(luò)系統(tǒng)中已成為一類有效的防護(hù)措施,能夠?qū)W(wǎng)絡(luò)受到的各類攻擊行為進(jìn)行精確檢測,由此實(shí)現(xiàn)網(wǎng)絡(luò)安全性的大幅提升[5]。利用監(jiān)測系統(tǒng)實(shí)現(xiàn)網(wǎng)絡(luò)日志的自動(dòng)收集,并對各項(xiàng)信息動(dòng)態(tài)進(jìn)行監(jiān)聽與自動(dòng)處理,從中獲取有用的內(nèi)容,快速判斷網(wǎng)絡(luò)入侵行為[6-7]。本文綜合考慮循環(huán)神經(jīng)網(wǎng)絡(luò)(recurrent neural network,RNN) 和長短期記憶(long short-term memory,LSTM)網(wǎng)絡(luò)兩種網(wǎng)絡(luò)的各自運(yùn)行性能,針對其不足之處進(jìn)行了重新調(diào)整,并對LSTM 實(shí)施優(yōu)化得到門控循環(huán)單元(gate recurrent unit,GRU)網(wǎng)絡(luò),進(jìn)而獲得GRU-LSTM 高效算法,之后將其與傳統(tǒng)形式的Softmax(邏輯回歸)分類技術(shù)進(jìn)行比較分析,結(jié)果發(fā)現(xiàn)GRU-LSTM 算法的入侵檢測性能更優(yōu)。
1 GRU-LSTM算法
GRU是循環(huán)神經(jīng)網(wǎng)絡(luò)的一種,具有很好的長期記憶和反向傳播梯度優(yōu)勢。以支持向量機(jī)(supportvector machines,SVM)取代Softmax,作為GRU模型輸出,并利用交叉熵函數(shù)計(jì)算出損失[8]。損失函數(shù)按照如下進(jìn)行:
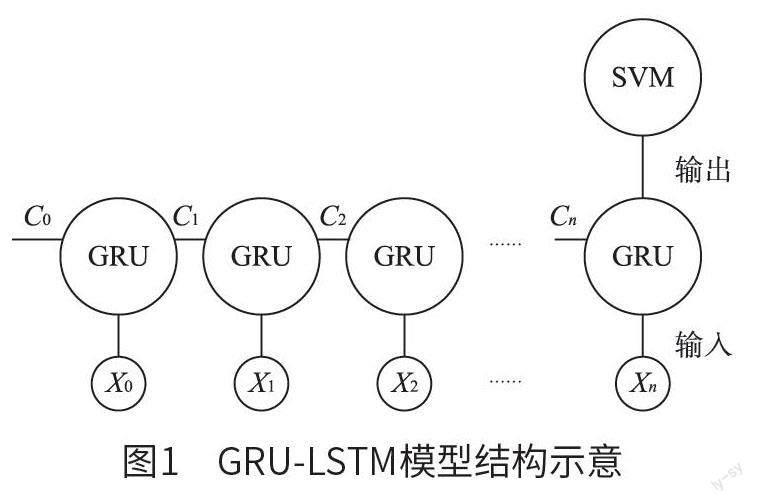
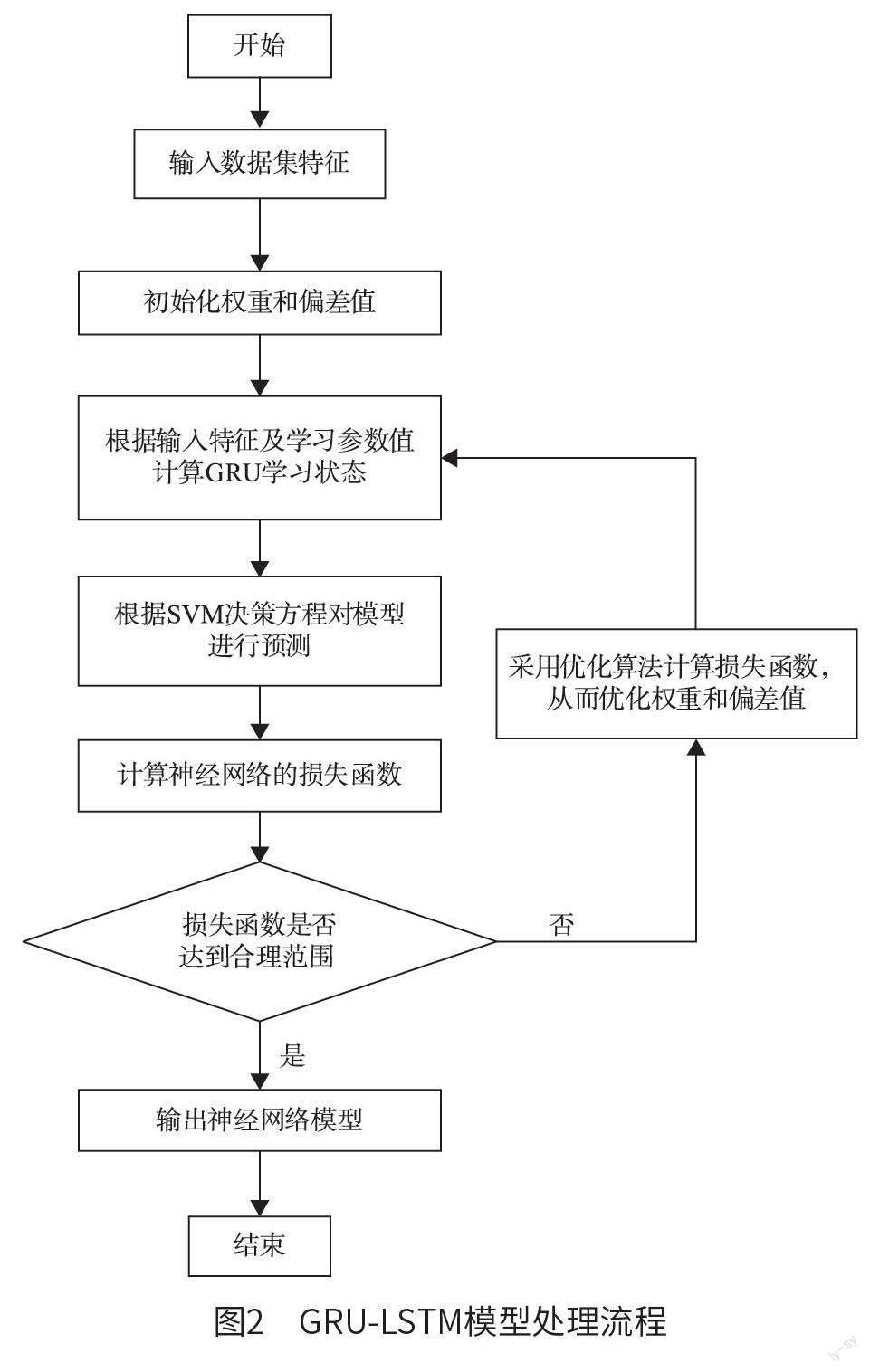
圖1 為GRU-LSTM 模型結(jié)構(gòu)示意, 圖2 為GRU-LSTM 模型處理流程。將所有數(shù)據(jù)輸入模型內(nèi),再利用網(wǎng)絡(luò)進(jìn)行處理,實(shí)現(xiàn)對權(quán)重與偏差的控制。判斷損失函數(shù)與理想值之間的偏差,并對權(quán)值與偏差進(jìn)行多次迭代,最終獲得最佳的網(wǎng)絡(luò)模型。
2 結(jié)果分析
表1 是本實(shí)驗(yàn)獲得的各項(xiàng)參數(shù)結(jié)果,可以發(fā)現(xiàn),模型訓(xùn)練精度及其所需的訓(xùn)練時(shí)間受儲(chǔ)量、訓(xùn)練次數(shù)等參數(shù)的綜合影響。為獲得更高的訓(xùn)練效率,進(jìn)行了多次測試,結(jié)果顯示在儲(chǔ)量為512 B 的條件下表現(xiàn)出了最優(yōu)狀態(tài),能夠?qū)崿F(xiàn)對下降過程的精確控制,震蕩幅度顯著減小。為消除訓(xùn)練階段網(wǎng)絡(luò)出現(xiàn)的過擬合現(xiàn)象,可選擇dropout(臨時(shí)丟棄函數(shù))方法來有效避免以上問題。dropout 進(jìn)行網(wǎng)絡(luò)訓(xùn)練時(shí),按照恒定概率不斷去除無效的網(wǎng)絡(luò)神經(jīng)元,由此實(shí)現(xiàn)減弱神經(jīng)元間的相互作用,形成更簡單的結(jié)構(gòu),有效防止過擬合的問題。根據(jù)本實(shí)驗(yàn)測試結(jié)果可知,GRU-LSTM 和GRU-Softmax 兩個(gè)模型的dropout 值分別為0.82 與0.79。
表2 是各模型入侵檢測得到的參數(shù),按照同樣的過程完成模型的訓(xùn)練,總共實(shí)施訓(xùn)練次數(shù)為10次,網(wǎng)絡(luò)流量數(shù)據(jù)都是30 000行,測試次數(shù)為10次。由表2 可知,GRU-LSTM 表現(xiàn)出了比GRU-Softmax更高的控制精確度和檢測率,通過對比發(fā)現(xiàn),相較于傳統(tǒng)的GRU-Softmax 方法,綜合運(yùn)用LSTM 網(wǎng)絡(luò)與GRU 網(wǎng)絡(luò)進(jìn)行處理具有更優(yōu)二分類優(yōu)勢。
不同攻擊類型下測試對比結(jié)果如表3 所示。由表3 可知,整體性能上GRU-LSTM 算法優(yōu)于GRUSoftmax算法。說明GRU-LSTM 算法在檢測攻擊時(shí)將其判斷成正常行為的概率較小,減小了入侵概率。
在網(wǎng)絡(luò)入侵行為被發(fā)現(xiàn)時(shí),系統(tǒng)便會(huì)把報(bào)警信息迅速反饋給用戶,從而避免整個(gè)系統(tǒng)出現(xiàn)運(yùn)行異常的情況,并且也能夠有效保護(hù)系統(tǒng)中的儲(chǔ)存數(shù)據(jù)[9]。考慮到檢測網(wǎng)絡(luò)入侵時(shí)需要記錄多方面的數(shù)據(jù)信息,因此形成的數(shù)據(jù)量很大,從而形成明顯的噪聲,導(dǎo)致系統(tǒng)算法無法正常運(yùn)行,出現(xiàn)訓(xùn)練結(jié)果存在明顯偏差的問題。GRU-LSTM 網(wǎng)絡(luò)能夠滿足自主學(xué)習(xí)以及良好的適應(yīng)性要求,在入侵檢測階段解決存在的各類潛在問題[10-11]。
為了進(jìn)一步分析算法的可靠性,在NSL-KDD數(shù)據(jù)集上進(jìn)行了各性能測試,檢測結(jié)果如表4 所示。由表4 可知, 相較于GRU-Softmax 算法,GRULSTM算法下各項(xiàng)性能均表現(xiàn)出優(yōu)異的狀態(tài)。可見采用LSTM 替換Softmax 能提高算法整體的運(yùn)算能力。
3 結(jié)論
本文開展基于GRU-LSTM 算法的物聯(lián)網(wǎng)數(shù)據(jù)入侵檢測分析,取得如下結(jié)果。
(1)利用dropout 進(jìn)行網(wǎng)絡(luò)訓(xùn)練,實(shí)現(xiàn)減弱神經(jīng)元間的相互作用,有效防止過擬合。本實(shí)驗(yàn)測試GRU-LSTM 和GRU-Softmax 兩個(gè)模型的dropout 值分別為0.82 與0.79。GRU-LSTM 表現(xiàn)出了比GRUSoftmax更高的控制精確度和檢測率。
(2)GRU-LSTM 算法在檢測攻擊時(shí)將其判斷成正常行為的概率較小,減小了入侵概率,獲得了更優(yōu)的精確度、檢測率與誤報(bào)率。
該研究能夠彌補(bǔ)傳統(tǒng)機(jī)器學(xué)習(xí)算法在處理數(shù)據(jù)時(shí)的局限性,但在面對海量數(shù)據(jù)時(shí)存在計(jì)算冗長的問題,期待后續(xù)引入深度學(xué)習(xí)算法解決這一問題。
