基于改進SSD和ISESAM融合的無人機弱小目標檢測方法*
2023-12-11 12:10:20張銀環(huán)薛靜云王寧寧韓澤佳
艦船電子工程 2023年9期
張銀環(huán) 薛靜云 王寧寧 韓澤佳
(1.渭南職業(yè)技術(shù)學(xué)院建筑工程學(xué)院 渭南 714000)(2.西安工業(yè)大學(xué)機電工程學(xué)院 西安 710021)
1 引言
目標檢測在人臉識別、門禁考勤、過閘乘車等方面具有重要的應(yīng)用價值,被國內(nèi)外學(xué)者和研究人員密切關(guān)注[1]。目標檢測實質(zhì)是找到一種將圖像轉(zhuǎn)換為特征空間的方法,即特征提取方法[2]。常見目標檢測方法分兩類:一類是通過傳統(tǒng)機器學(xué)習(xí)算法提取;另一類是通過深度神經(jīng)網(wǎng)絡(luò)方法提取。在計算機視覺領(lǐng)域,利用卷積神經(jīng)網(wǎng)絡(luò)在目標檢測領(lǐng)域取得了巨大的成就[3]。
基于深度學(xué)習(xí)的無人機目標檢測算法分兩類:基于R-CNN 系列的二階段目標檢測架構(gòu)和基于回歸的單階段目標檢測架構(gòu)[4]。2014年,Grishick等[5]提出區(qū)域CNN 算法,通過使用選擇性搜索(Selective Search,SS)的R-CNN 消除了對幾個區(qū)域的選擇,在PASCAL VOC-2007 數(shù)據(jù)集上的準確率達到67%。盡管R-CNN 方法提升了檢測精度,但在無人機圖像輸入CNN 網(wǎng)絡(luò)之前,需將候選框區(qū)域中的無人機圖像轉(zhuǎn)換為固定大小,造成圖像部分特征丟失。2015年,Grishick[6]提出Faster R-CNN,使用區(qū)域建議RPN 網(wǎng)絡(luò)替代了選擇搜索算法,在PASCAL VOC2007 數(shù)據(jù)集上的準確率提升到70%。2018年Joseph Redmon[7]提出YOLOV3 算法,在TITAN GPU 上運行檢測速度能超過40fps,而一般視頻播放速度為26fps,因此可實現(xiàn)實時檢測,但在PASCAL VOC-2007 準確率僅為63.4%,檢測精度偏低。由于減少anchor的產(chǎn)生直接輸出檢測結(jié)果,造成檢測精度不高,特別是對于一些低空無人機小目標。2016年Liu 等[8]提出SSD 算法,檢測精度與Faster R-CNN相近或者更高,能對低空無人機視頻實現(xiàn)實時檢測。2022年,Jia等[9]提出輕量SSD算法對弱小目標進行檢測,能夠在壓縮參數(shù)的同時,保證算法檢測速度和檢測精度,可有效實現(xiàn)對弱小目標的檢測。然而該模型將注意力集中于較低特征層,忽略上下文的語義信息,從而對圖像中部分重疊目標的檢測效果有一定影響。2022年,文獻[10]提出改進的YOLO 模型,在檢測精度上有較大提升,然而針對弱小目標的檢測,由于缺乏理論指導(dǎo),檢測精度仍有較大的提升空間。綜之,現(xiàn)有方法存在較少模型參數(shù)與較高檢測精度之間的矛盾,弱小目標及在遮擋環(huán)境下檢測精度不高的問題。
針對以上問題,本文提出一種改進的SSD和ISESAM融合算法,以較低的計算成本換取更高的檢測精度。采用輕量化MobileNetV3網(wǎng)絡(luò)模型作為主干取代SSD 算法中的VGG 網(wǎng)絡(luò),以降低算法復(fù)雜性。同時突出了一個新的時空注意力(Improved Squeeze Excitation and Spatial Attention Module,ISESAM)模塊代替MobileNetV3中SE 模塊,從時空方面提高檢測精度。最后通過實驗驗證本文提出改進SSD算法先進性。
2 改進SSD目標檢測網(wǎng)絡(luò)模塊
改進SSD 算法由改進的MobileNetV3與額外功能層組成。研究發(fā)現(xiàn)低空飛行的無人機屬于小目標,在檢測過程中存在背景相似及飛行模糊的問題,采用輕量級MobileNetV3 網(wǎng)絡(luò)模型作為主干取代了SSD 算法中的VGG 網(wǎng)絡(luò),如圖1中紅色標記部分,以降低算法復(fù)雜性。針對檢測精度不高的問題,本文提出了一個新的時空注意力(Improved Squeeze Excitation and Spatial Attention Module,ISESAM)模塊。采用通道和空間注意力機制,可以精確檢測弱小目標。同時改進SSD 算法中的激活函數(shù)解決神經(jīng)元“失活”的問題,從而能夠在低層網(wǎng)絡(luò)中更有效地提取圖像特征。

圖1 改進SSD算法框架
3 改進SSD目標檢測模塊
ISESAM 模塊是改進的SSD 目標檢測模算法核心,它是由ISE 和SAM 兩模塊組成,如圖2所示。為避免參數(shù)爆增而導(dǎo)致計算消耗過負荷問題,并能充分提取圖像空間特征,分別提出ISE 和SAM 模塊。ISESAM模塊為通道和空間包含重要信息的像素賦予較大權(quán)重,旨在提高目標檢測精度。

圖2 ISESAM模塊結(jié)構(gòu)
3.1 ISESAM模塊
MobileNetV3 網(wǎng)絡(luò)模型中的SE[11]模塊僅學(xué)習(xí)了通道間特征相關(guān)性,忽略了特征空間相關(guān)性。研究表明,使用空間注意力模塊可以在空間上持續(xù)檢測,提升小目標檢測準確率。這種方法有效的主要原因是特征圖的每個元素對應(yīng)原圖的一個區(qū)域,對輸出特征圖的每個位置賦予不同的權(quán)重相當于對原圖的不同區(qū)域賦予不同的影響因子。因此,本文提出改進時空注意力模塊ISESAM 代替Mobile-NetV3 網(wǎng)絡(luò)模型中的SE 模塊。ISESAM 由和組成,其中,ISE 借鑒SE-block 設(shè)計思想[13~14]并對其進行改進,可為重要行為特征在通道方面賦予較大權(quán)重,檢測關(guān)鍵特征。SAM是從空間維度關(guān)注檢測重要特征的模塊,ISESAM模塊結(jié)構(gòu)如圖2所示。
Wang[12]通過實驗證明attention block 中保持channel 數(shù)不變的重要性,證明了避免降維和適當?shù)目缤ǖ澜换τ谕ǖ雷⒁鈱W(xué)習(xí)的重要性。同時為了避免SE 模塊中存在神經(jīng)元“失活”的問題,本文對SE 模塊進行優(yōu)化,提出改進的注意力網(wǎng)絡(luò)結(jié)構(gòu)(improved SE block,ISE block)。
3.2 ISE-block設(shè)計
ISE-block 結(jié)構(gòu),如圖3所示,包括一個全局平局池化層(Global Average Pooling,GAP),2個1*1的自適應(yīng)卷積層adaptive conv,一個池化層Leaky Relu,一個標準化BN 層和一個Sigmoid 激活層,共六層。其中:1)GAP 層丟棄dropout 可解決全連接層容易導(dǎo)致模型過擬合問題。其思想是將最后一層多層感知機(Muti Layer Perceptron,MLP)輸出的每一張feature map相加求平均,如下式:

圖3 SE and ISE-block對比
其中,i,j 表示每張feature map 像素點的坐標,H,W代表圖像的寬、高,uc為局部描述符的集合,共c個,Zc為視頻中第c幀圖像像素均值的權(quán)重。因此輸出的每張feature map 都形成1*1*C 向量輸入至softmax 中進行分類。2)標準化(Batch Normalization,BN)層數(shù)據(jù)分布在神經(jīng)網(wǎng)絡(luò)訓(xùn)練階段會產(chǎn)生重要影響。使用Sigmoid 激活函數(shù),輸入接近于5時已經(jīng)處在激勵函數(shù)的飽和階段,而上層的Leaky Relu 輸出值y'多半超過5 這一范圍,因此,在Sigmoid 激活函數(shù)之前應(yīng)添加BN 層。將3)ISE 模塊產(chǎn)生的特征圖H×W×C 輸入到SAM 模塊,設(shè)置跨通道數(shù)最佳為k=5,對輸入的特征圖使用空間特征關(guān)聯(lián)操作,進一步提取圖像空間特征[11]。最后通過Sigmoid 激活函數(shù)輸出,為通道上包含重要信息的特征賦予較大權(quán)重,從而提高目標檢測精度。
3.3 改進激活函數(shù)
MobileNetV3 在它的深層網(wǎng)絡(luò)中采用了新設(shè)計的Hard-Swish激活函數(shù),但在其淺層網(wǎng)絡(luò)中ReLU6激活函數(shù),當在x <0 時,ReLU6 激活函數(shù)不僅失去活性,而且可能導(dǎo)致梯度消失,使網(wǎng)絡(luò)無法訓(xùn)練,對圖像特征提取不準確。在非線性激活函數(shù)中Sigmoid函數(shù)公式如式(2)所示,Tanh函數(shù)公式如式(3)所示,ELU 函數(shù)公式如式(4)所示,Leaky-ReLU[15]函數(shù)公式如式(5)所示。
幾個激活函數(shù)公式的曲線圖像,如圖4所示,從圖中可以看出Leaky-ReLU 具有所有ReLU 的優(yōu)點,并且不存在神經(jīng)元“失活”問題。

圖4 不同激活函數(shù)曲線
本文將Leaky-ReLU 激活函數(shù)思想與ReLU6激活函數(shù)思想結(jié)合,形成了一個新的公式Leaky-ReLU6,如下式:
由式(6)可得,組合激活函數(shù)分為三個部分,當x<0 時,函數(shù)值為αx,其中參數(shù)α是一個非常小的值,可以在模型訓(xùn)練過程中手動調(diào)整,找出模型效果最優(yōu)的參數(shù)值,并在后續(xù)的測試過程中繼續(xù);當0 <x<6 時,函數(shù)為線性增長,當函數(shù)值上升到6時,就保持在6 不再上升,改進的Leaky-ReLU6 激活函數(shù)的圖像,如圖5所示。
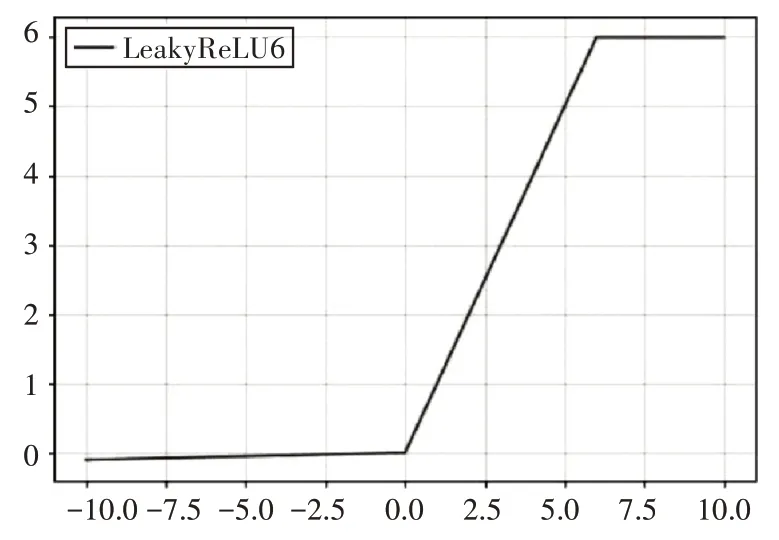
圖5 Leaky-ReLU6激活函數(shù)圖像
3.4 改進后SSD模型
改進后SSD 模型詳細構(gòu)造見表1,表中Input代表輸入層網(wǎng)絡(luò)中圖片大小;poera 代表對特征層進行的block 操作;瓶頸層Bneck 代表bottleneck layers;擴張因子為Exp;#out 表示為特征層的通道數(shù);√表示添加了ISESAM。NL 為非線性激活函數(shù)Non-Linearity,其中HS、L-RE 分別代表Mobile-NetV3中的H-Swish和Leaky-ReLU6激活函數(shù)。
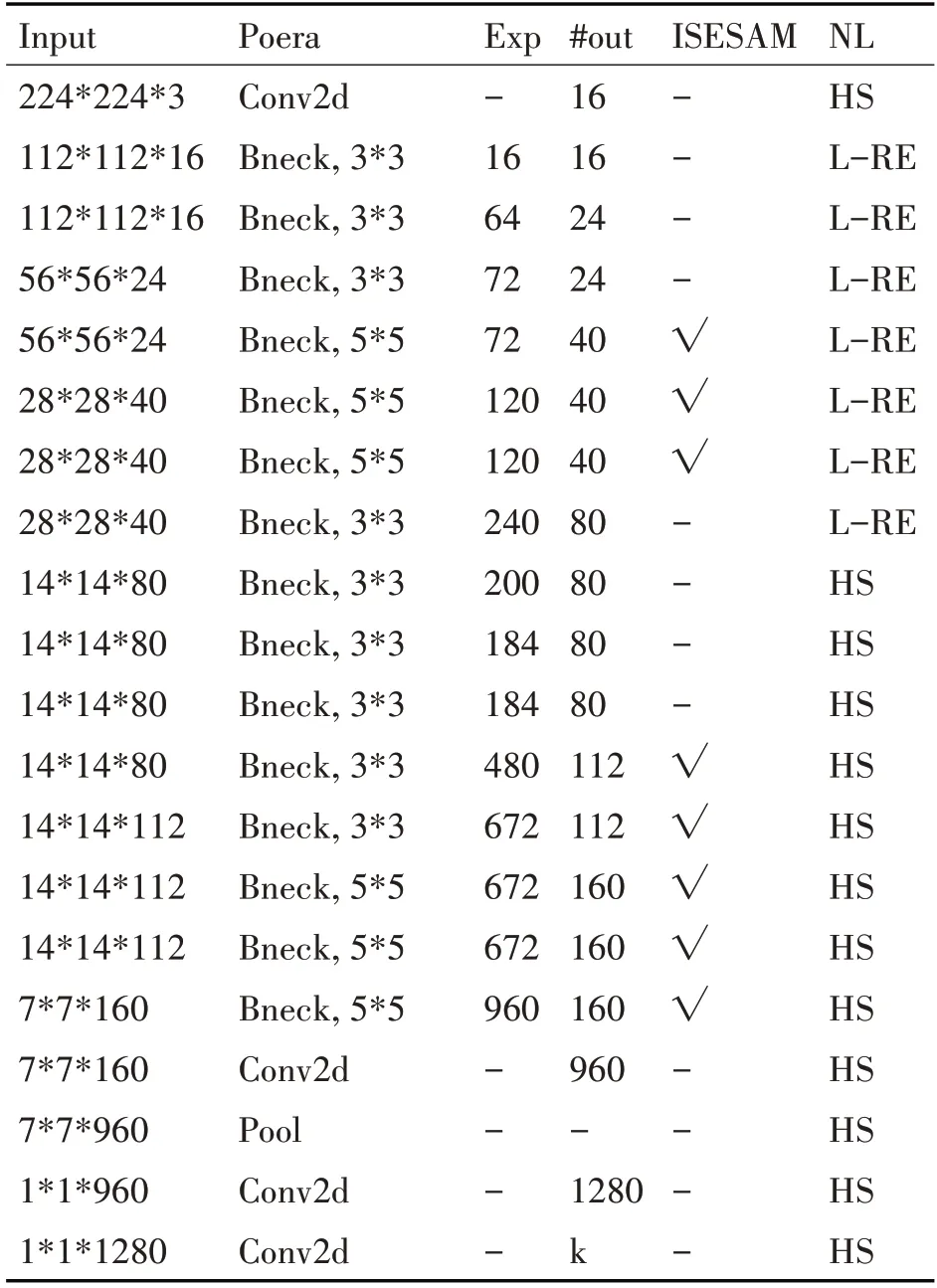
表1 改進的SSD模型具體參數(shù)
4 實驗與分析
4.1 數(shù)據(jù)庫
本文所建立的無人機目標檢測數(shù)據(jù)庫是根據(jù)檢測過程中可能出現(xiàn)的不同飛行情況進行構(gòu)建。本數(shù)據(jù)庫既包括訓(xùn)練無人機的正樣本,也包括關(guān)于鳥類和大型客機的負樣本,由于沒有公開的無人機數(shù)據(jù)庫,本文獲取的檢測數(shù)據(jù)庫主要是通過在公開數(shù)據(jù)集PASCAL VOC 和COCO 數(shù)據(jù)集中的無人機、鳥類和大型客機樣本以及自行拍攝樣本構(gòu)建。
4.2 實驗環(huán)境配置
實驗訓(xùn)練以及測試顯卡為Nvidia GeForce RTX1660,處理器為Intel(R)Core(TM)i5 10400F,實驗操作系統(tǒng)為Ubuntu20.04,程序運行環(huán)境為Python3.7,計算框架版本為Cuda11.0,深度神經(jīng)網(wǎng)絡(luò)加速庫為Cudnn8.0,深度學(xué)習(xí)框架為Pytorch1.6,訓(xùn)練中的部分超參數(shù)設(shè)置,見表2。
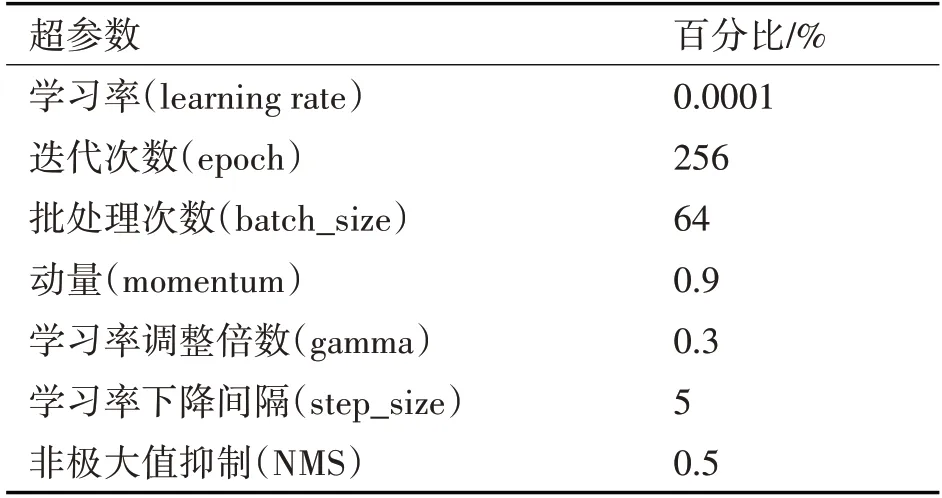
表2 訓(xùn)練超參數(shù)設(shè)置
4.3 實驗結(jié)果及分析
將SSD-MobileNetV3 算法和本文算法均采用8進程數(shù)訓(xùn)練,初始學(xué)習(xí)率為0.0001,每隔5 步降低一次學(xué)習(xí)率,在經(jīng)過256 輪的迭代后訓(xùn)練模型學(xué)習(xí)率穩(wěn)定在0,同時訓(xùn)練損失達到最小,網(wǎng)絡(luò)達到擬合狀態(tài)。訓(xùn)練損失和學(xué)習(xí)率對比,如圖6所示。

圖6 訓(xùn)練損失和學(xué)習(xí)率對比圖
其中圖6(a)為SSD 算法經(jīng)過迭代后的訓(xùn)練損失Loss 和學(xué)習(xí)率lr,圖6(b)為本文算法使用Leaky-ReLU6 損失函數(shù)后的訓(xùn)練損失Loss 和學(xué)習(xí)率lr。通過對比發(fā)現(xiàn)本文算法在改進損失函數(shù)后,訓(xùn)練的損失能更快的降到最低,同時損失也更趨向于平穩(wěn)。訓(xùn)練結(jié)果所產(chǎn)生的P-R 對比曲線,如圖7所示,曲線縱坐標為精度Precision,橫坐標為召回Recall,平均精度為P-R 曲線的下面積,其中圖7(a)中為SSD 算法產(chǎn)生的P-R 曲線圖,圖7(b)是本文算法產(chǎn)生的P-R曲線圖。
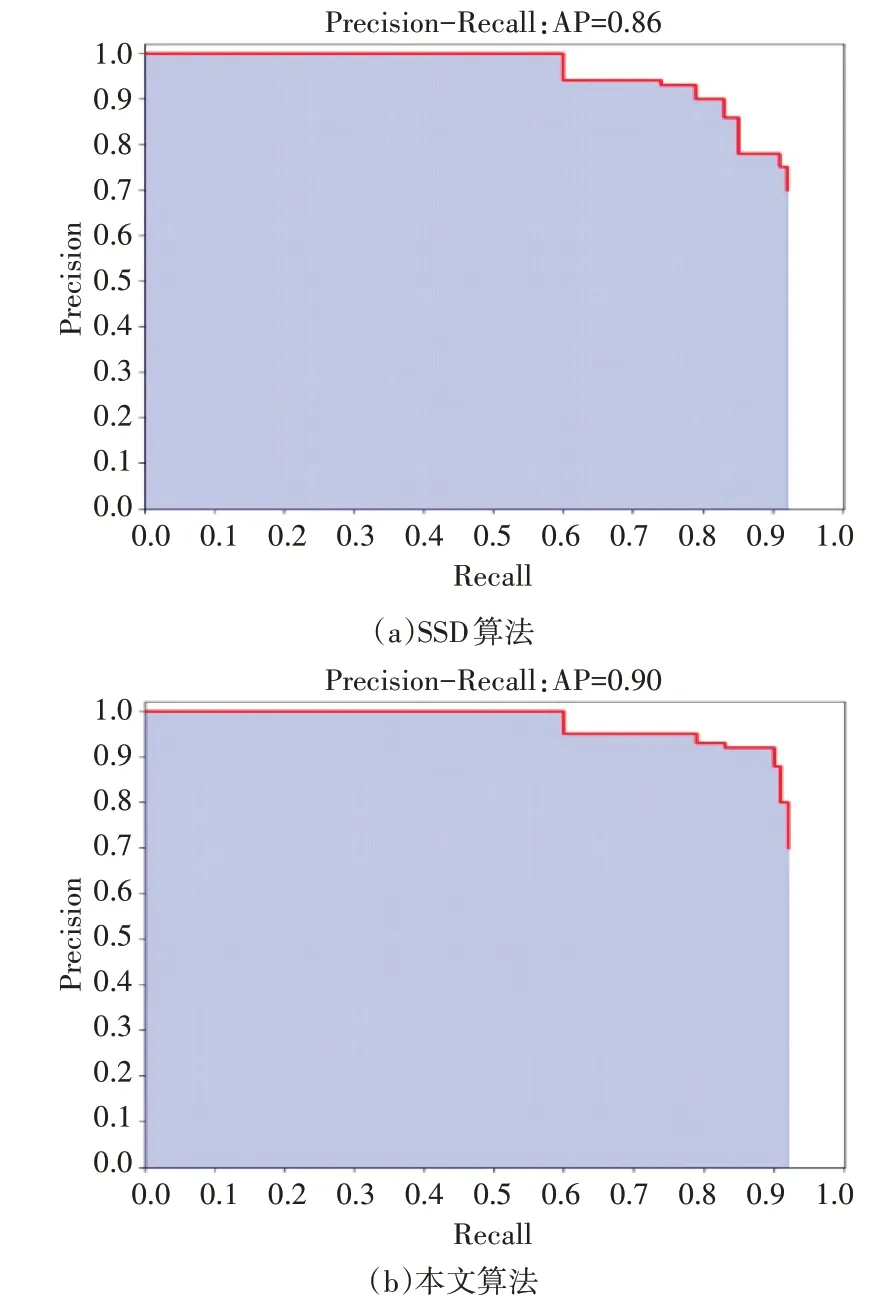
圖7 P-R曲線對比圖
通過圖7 可得,改進后的SSD 算法比原SSD 算法目標檢測平均精度提高了4%。通過加載訓(xùn)練數(shù)據(jù)集產(chǎn)生的權(quán)重文件對SSD 算法和本文算法進行對比檢測實驗。如圖8所示,其中圖8(a)為SSD 算法對無人機小目標檢測結(jié)果,圖8(b)為本文算法對無人機小目標檢測結(jié)果。

圖8 SSD算法與本文算法檢測結(jié)果對比
通過對無人機目標飛行過程中遇到的復(fù)雜背景問題檢測實驗對比如圖8所示,易得在遇到相似背景圖(a)和圖(b)左圖所示時,SSD 算法與本文檢測算法的檢測準確率分別65%和95%。針對簡單的單一背景,兩種算法的檢測精度分別為72%和98%,如圖(a)、(b)中間圖像。在最右側(cè)圖中,均為光照昏暗條件下,兩種算法的檢測為分別為58%和81%,說明光線對檢測結(jié)果存在較大影響。經(jīng)過檢測精度對比結(jié)果可得,SSD 算法存在誤檢以及檢測精度不高的問題,而改進后的SSD算法對無人機目標飛行過程中遇到的背景相似及光照不足等問題具有更好的檢測結(jié)果。
為進一步證明本文算法的先進性,將本文算法與經(jīng)典Faster-Rcnn、Yolov3、SSD、SSD-Mobile-NetV3 算法對比,在本文構(gòu)建的無人機數(shù)據(jù)集進行訓(xùn)練和測試,評價指標包括檢測精確度、檢測速度以及模型大小三個方面,實驗對比結(jié)果,見表3。
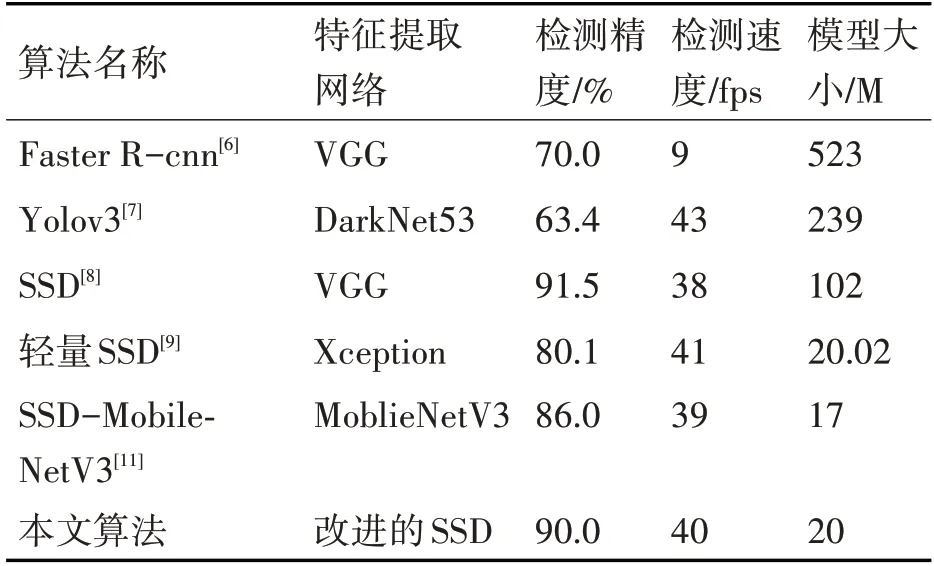
表3 與其他算法的實驗結(jié)果對比
由表3 可得盡管Faster-Rcnn 和Yolov3 檢測算法精確度不低,但是算法模型都較大,不適合在微型邊緣計算平臺上進行部署,同時Faster-Rcnn 檢測算法檢測速度只有9fps,達不到實時的檢測要求,不符合本文對無人機實施目標檢測的要求。SSD-MobileNetV3 模型參數(shù)量最少為17M,但是它的檢測精確度不如本文算法。本文通過對SSDMobileNetV3 進行改進,在檢測速度以及模型大小不損失太多的情況下,有效地提高了對無人機目標的檢測精確度。相對于原SSD算法,雖然在檢測精確度相差不大,但是在檢測速度上提高了5.26%,同時模型大小減少到20M,更適合在微型邊緣計算平臺上執(zhí)行,具有實踐意義。
5 結(jié)語
本文提出一種改進的SSD 算法用于低空無人機小目標檢測。針對標準的SSD 目標檢測算法參數(shù)量較大、對設(shè)備計算能力需求較高等特點,在保證一定的檢測精度的情況下,以SSD-MobileNetV3網(wǎng)絡(luò)作為特征提取模塊,對SSD算法進行輕量化優(yōu)化。同時對低空無人機目標檢測過程中出現(xiàn)的小目標、飛行遮擋以及背景相似問題,提出ISESAM模塊和改進激活函數(shù)對SSD-MobileNetV3 算法進行改進,形成本文提出改進SSD算法。通過在大型數(shù)據(jù)集上實驗,可得本文算法提高了低空無人機小目標的檢測效果,同時也更適合在微型邊緣計算平臺上進行部署。然而小樣本的目標檢測尚未深入討論,今后將繼續(xù)研究,進一步提高算法的魯棒性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
