基于圖多層感知機(jī)的節(jié)點(diǎn)分類算法*
2023-12-10 08:49:02袁立寧黃琬雁莫嘉穎馮文剛
廣西科學(xué) 2023年5期
文 竹,袁立寧,,黃 偉,黃琬雁,莫嘉穎,馮文剛
(1.廣西警察學(xué)院信息技術(shù)學(xué)院,廣西南寧 530028;2.中國人民公安大學(xué)國家安全學(xué)院,北京 100038;3.南寧職業(yè)技術(shù)學(xué)院人工智能學(xué)院,廣西南寧 530008)
圖是一種常用的數(shù)據(jù)形式,用于表征實(shí)體間的關(guān)系,如引文網(wǎng)絡(luò)中論文之間的互引信息、社交網(wǎng)絡(luò)賬號之間的關(guān)注信息等。節(jié)點(diǎn)分類[1]是利用圖中已知的拓?fù)浣Y(jié)構(gòu)、節(jié)點(diǎn)屬性以及節(jié)點(diǎn)標(biāo)簽等信息對無標(biāo)簽節(jié)點(diǎn)進(jìn)行類別預(yù)測。因此,節(jié)點(diǎn)分類的關(guān)鍵在于如何提取原始圖中蘊(yùn)含的特征信息。圖神經(jīng)網(wǎng)絡(luò)(Graph Neural Networks,GNN)[2]是一類高效的圖特征學(xué)習(xí)方法,它通過傳遞和聚合節(jié)點(diǎn)間信息來生成保留拓?fù)浣Y(jié)構(gòu)和屬性信息的低維節(jié)點(diǎn)表示,并將其用于節(jié)點(diǎn)分類等下游圖分析任務(wù)。
近年來,已有許多研究對GNN進(jìn)行改進(jìn),這些改進(jìn)一般通過引入高效的信息傳遞和轉(zhuǎn)換方式以增強(qiáng)GNN的表征能力。圖卷積網(wǎng)絡(luò)(Graph Convolutional Network,GCN)[3]將經(jīng)典的卷積神經(jīng)網(wǎng)絡(luò)從歐式數(shù)據(jù)(圖像、音頻)推廣到非歐式數(shù)據(jù)(圖),實(shí)現(xiàn)了對拓?fù)浣Y(jié)構(gòu)和節(jié)點(diǎn)屬性信息的編碼,其在計(jì)算過程中僅使用節(jié)點(diǎn)的一階鄰域進(jìn)行聚合,這提高了模型層間信息的傳播效率。簡化圖卷積(Simplified Graph Convolution,SGC)[4]改進(jìn)了GCN的編碼策略,通過直接使用線性網(wǎng)絡(luò)編碼原始圖信息以減少模型參數(shù),降低模型復(fù)雜度;圖注意力網(wǎng)絡(luò)(Graph Attention Network,GAT)[5]在GCN的基礎(chǔ)上引入注意力機(jī)制,為一階鄰域中各節(jié)點(diǎn)分配不同的權(quán)值,使信息聚合過程能夠更加關(guān)注影響力較大的高權(quán)值鄰居節(jié)點(diǎn);GATv2[6]在GAT的基礎(chǔ)上引入動態(tài)注意力機(jī)制,修改了GAT中權(quán)值計(jì)算過程,構(gòu)建近似注意函數(shù),從而提升了GAT的表征能力;結(jié)構(gòu)感知路徑聚合圖神經(jīng)網(wǎng)絡(luò)(PathNet)[7]使用最大熵路徑采集器采樣節(jié)點(diǎn)上下文路徑,然后引入結(jié)構(gòu)感知循環(huán)單元學(xué)習(xí)上下文路徑中蘊(yùn)含的語義信息。由于淺層GNN架構(gòu)限制了模型學(xué)習(xí)高階鄰域信息的能力,而深層GNN架構(gòu)容易出現(xiàn)過平滑[8],為解決以上問題,Zhang等[9]提出的淺層雙仿射圖卷積網(wǎng)絡(luò)(Shallow Biaffine Graph Convolutional Networks,BAGCN)不僅能夠?qū)W習(xí)節(jié)點(diǎn)對遠(yuǎn)距離鄰居的直接依賴性,還能通過一階消息傳遞捕獲多跳鄰居的特征信息。
與上述通過復(fù)雜的節(jié)點(diǎn)信息傳遞和聚合方式提升模型性能的研究思路不同,本文提出了基于多層感知機(jī)(Multi-Layer Perceptron,MLP)[10]的A&T-MLP。A&T-MLP無需信息傳遞和聚合,而是通過屬性和拓?fù)湫畔⒁龑?dǎo)的對比損失以保留原始圖相關(guān)特征。具體來說,A&T-MLP首先使用屬性矩陣和鄰接矩陣計(jì)算節(jié)點(diǎn)間的相似度信息;然后使用基于相似度信息引導(dǎo)的對比損失,優(yōu)化MLP隱藏層生成的特征表示;最后引入交叉熵?fù)p失對A&T-MLP進(jìn)行端到端訓(xùn)練。
1 相關(guān)工作
1.1 MLP
MLP是一種基于前饋神經(jīng)網(wǎng)絡(luò)的深度學(xué)習(xí)模型,通常由輸入層、隱藏層和輸出層構(gòu)成,相鄰兩層之間所有輸入神經(jīng)元都和輸出神經(jīng)元相連,因此也稱為全連接神經(jīng)網(wǎng)絡(luò)。其中,輸入層用于接收原始數(shù)據(jù),隱藏層利用權(quán)重系數(shù)和激活函數(shù)對數(shù)據(jù)進(jìn)行特征提取和非線性變換,輸出層利用隱藏層生成的特征向量得到預(yù)測結(jié)果。MLP具有較強(qiáng)的表征能力,可通過特定的損失函數(shù)和反向傳播算法對其進(jìn)行訓(xùn)練優(yōu)化。MLP能夠自動地提取數(shù)據(jù)中蘊(yùn)含的潛在信息,因此可用于分類、回歸等機(jī)器學(xué)習(xí)任務(wù)。
在計(jì)算機(jī)視覺和自然語言處理領(lǐng)域,MLP被廣泛應(yīng)用于語音識別、圖像識別、語義分割等眾多任務(wù)。Hou等[11]提出了基于MLP的高效視覺識別架構(gòu),使用線性投影分別對高度和寬度特征表示進(jìn)行編碼,捕獲長距離依賴關(guān)系,進(jìn)而提升視覺識別網(wǎng)絡(luò)的性能。Gong等[12]提出了基于Cycle-MLP的DriftNet模型,該模型通過神經(jīng)元漸進(jìn)激活以促進(jìn)空間和光譜信息的融合,進(jìn)而提升了高光譜圖像像素分類的實(shí)驗(yàn)表現(xiàn)。Sun等[13]提出了多模態(tài)情緒分析模型CubeMLP,CubeMLP將所有模態(tài)特征作為輸入,并將輸入分配到3個不同的MLP單元提取特征,最后對混合多模態(tài)特征進(jìn)行展平以實(shí)現(xiàn)情緒分析任務(wù)。在圖分析領(lǐng)域,Hu等[14]提出了Graph-MLP,Graph-MLP通過拓?fù)浣Y(jié)構(gòu)中的鄰接關(guān)系構(gòu)建保留拓?fù)湫畔⒌膶Ρ葥p失,使僅使用節(jié)點(diǎn)屬性作為輸入的MLP能夠匹配GCN在節(jié)點(diǎn)分類任務(wù)中的實(shí)驗(yàn)性能。
上述研究為MLP在其他領(lǐng)域的應(yīng)用提供了理論基礎(chǔ),其性能也能夠匹配多數(shù)復(fù)雜模型的實(shí)驗(yàn)表現(xiàn)。因此,本文在已有研究的基礎(chǔ)上,提出了一種基于屬性和拓?fù)湫畔⒃鰪?qiáng)MLP模型A&T-MLP,并應(yīng)用于節(jié)點(diǎn)分類任務(wù)。
1.2 對比學(xué)習(xí)
對比學(xué)習(xí)是從大量未標(biāo)記的數(shù)據(jù)中提取可轉(zhuǎn)移的特征,并將其擴(kuò)展為特定的自監(jiān)督信息[15],使模型在訓(xùn)練過程中能夠?qū)ο嗨茦颖竞筒幌嗨茦颖具M(jìn)行區(qū)分,因此對比學(xué)習(xí)的核心思想就是增大特征空間中同類數(shù)據(jù)表示的相似性和不同類數(shù)據(jù)表示的差異性。分類任務(wù)中常見的對比損失函數(shù)的表達(dá)式為
loss(xi)=
(1)
式中,si,i表示正樣本,si,k表示負(fù)樣本。通過對比損失調(diào)整,使第i個數(shù)據(jù)與si,i之間的相似度盡可能大,與si,k之間的相似度盡可能小,從而提升模型表征原始數(shù)據(jù)信息的能力。
近年來,基于對比學(xué)習(xí)增強(qiáng)的圖深度學(xué)習(xí)模型已成為研究的熱點(diǎn)方向。除Graph-MLP模型,Wang等[16]提出了基于集群感知監(jiān)督對比損失的ClusterSCL,ClusterSCL以節(jié)點(diǎn)聚類分布的形式保留圖信息。Xia等[17]提出了一種無需數(shù)據(jù)增強(qiáng)的GNN對比學(xué)習(xí)框架SimGRACE,SimGRACE使用GNN編碼器和擾動GNN編碼器提取原始圖特征,然后通過對比兩個視圖來保留關(guān)鍵的語義信息。此外,Wang等[18]對圖對比學(xué)習(xí)中的結(jié)構(gòu)公平性進(jìn)行了探究,其研究結(jié)果表明引入對比學(xué)習(xí)后學(xué)習(xí)到的高度節(jié)點(diǎn)和低度節(jié)點(diǎn)的特征表示均優(yōu)于GCN模型。
本文提出了一種基于屬性信息和拓?fù)湫畔⒁龑?dǎo)的圖多層感知機(jī)模型,通過計(jì)算屬性相似度和拓?fù)湎嗨贫?推動特征空間中相似節(jié)點(diǎn)的低維表示相互靠近,不相似節(jié)點(diǎn)的低維表示進(jìn)一步遠(yuǎn)離,從而提升模型在節(jié)點(diǎn)分類任務(wù)上的表現(xiàn)。
2 A&T-MLP
本節(jié)主要介紹A&T-MLP的算法原理及模型構(gòu)建。首先提出模型整體架構(gòu),然后介紹用于對比損失的屬性相似度和拓?fù)湎嗨贫?接著討論用于模型訓(xùn)練的對比損失和交叉熵?fù)p失,最后介紹模型的優(yōu)化過程。
2.1 模型結(jié)構(gòu)
MLP通過全連接層(Fully Connected Layer,FC)提取數(shù)據(jù)中蘊(yùn)含的潛在信息,生成用于下游任務(wù)的特征表示。A&T-MLP在MLP的基礎(chǔ)上,通過引入兼顧節(jié)點(diǎn)屬性相似度與拓?fù)浣Y(jié)構(gòu)相似度的對比損失以增強(qiáng)模型對原始圖信息的表征能力,其整體結(jié)構(gòu)如圖1所示。由于過多的神經(jīng)網(wǎng)絡(luò)層數(shù)易導(dǎo)致模型過擬合[19],因此A&T-MLP使用3層網(wǎng)絡(luò)結(jié)構(gòu)。首先,使用MLP提取屬性矩陣X的特征,在第1層和第2層網(wǎng)絡(luò)之間引入激活函數(shù)ReLU和Dropout機(jī)制,這樣不僅能增強(qiáng)模型的非線性變換能力,還能防止參數(shù)過擬合;然后,使用屬性和拓?fù)湫畔⒁龑?dǎo)的對比損失,對第2層網(wǎng)絡(luò)生成的特征向量進(jìn)行優(yōu)化,使屬性和拓?fù)湎嗨频墓?jié)點(diǎn)在特征空間中進(jìn)一步接近,不相似的節(jié)點(diǎn)進(jìn)一步遠(yuǎn)離;最后,使用第3層網(wǎng)絡(luò)生成的特征向量計(jì)算交叉熵?fù)p失,從而實(shí)現(xiàn)節(jié)點(diǎn)分類任務(wù)。綜上,A&T-MLP的網(wǎng)絡(luò)結(jié)構(gòu)可表示為
H(1)=Dropout(ReLU(FC(X))),
(2)
H(2)=ReLU(FC(H(1))),
(3)
Z=FC(H(2))。
(4)
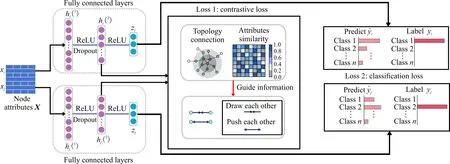
圖1 A&T-MLP的框架
2.2 屬性相似度與拓?fù)湎嗨贫?/h3>
為了充分保留原始圖中蘊(yùn)含的屬性與拓?fù)潢P(guān)聯(lián)信息,分別使用節(jié)點(diǎn)屬性矩陣X和鄰接矩陣A計(jì)算用于對比損失函數(shù)的節(jié)點(diǎn)相似度。
對于拓?fù)浣Y(jié)構(gòu),可以通過圖的一階相似度進(jìn)行表示,即直接相連的節(jié)點(diǎn)關(guān)系更加緊密[20]。如果節(jié)點(diǎn)i和j之間存在1條邊,那么i和j的一階相似度為邊的權(quán)重值(無權(quán)圖中,權(quán)重值默認(rèn)為1),如果i和j之間沒有邊,那么兩個節(jié)點(diǎn)的一階相似度為0。由于上述邊信息通常使用圖的鄰接矩陣A進(jìn)行存儲,所以A中元素Aij能夠直接表示節(jié)點(diǎn)i和j的拓?fù)湎嗨贫取?/p>
對于節(jié)點(diǎn)屬性,屬性矩陣X中元素Xij表示節(jié)點(diǎn)i和屬性j之間的關(guān)聯(lián)信息,不能直接表示節(jié)點(diǎn)間的相似度。因此,屬性相似度計(jì)算的關(guān)鍵在于如何表示節(jié)點(diǎn)在屬性空間的相似性,并通過與拓?fù)湎嗨贫认嗤男问竭M(jìn)行表示。首先,使用相似性度量算法,計(jì)算兩個節(jié)點(diǎn)的屬性相似性值Sij,本文使用余弦相似度獲取相似度矩陣S。
余弦相似度即使用兩個向量之間夾角的余弦值度量相似度:
(5)
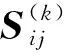
(6)
式中,γ表示包含原始圖中屬性與拓?fù)湎嗨菩畔⒌墓?jié)點(diǎn)關(guān)聯(lián)強(qiáng)度矩陣。
2.3 損失函數(shù)
在MLP提取數(shù)據(jù)特征生成節(jié)點(diǎn)表示的過程中,使用屬性和拓?fù)湟龑?dǎo)信息γ計(jì)算對比損失可以推動特征空間中相似節(jié)點(diǎn)的低維表示彼此接近,不相似節(jié)點(diǎn)的低維表示進(jìn)一步遠(yuǎn)離。基于對比損失的一般形式[公式(1)],A&T-MLP使用的對比損失lossCL表達(dá)式為
lossCL=
(7)
式中,sim表示余弦相似度函數(shù),h表示節(jié)點(diǎn)。lossCL借助節(jié)點(diǎn)的相似度信息以增大特征空間中相似節(jié)點(diǎn)的一致性和增大不相似節(jié)點(diǎn)的差異性。由于A&T-MLP是用于分類任務(wù)的模型,因此在訓(xùn)練過程中引入交叉熵?fù)p失lossCE:
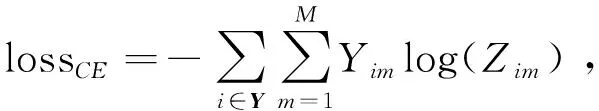
(8)
式中,Y為節(jié)點(diǎn)標(biāo)簽集合,M為標(biāo)簽的類別數(shù),Yim為符號函數(shù)(樣本i的真實(shí)類別等于m則取值1,否則取0),Zim表示觀測樣本i屬于類別m的預(yù)測概率。最后,將對比損失lossCL和交叉熵?fù)p失lossCE進(jìn)行組合,構(gòu)建完整的損失函數(shù)loss:
loss=lossCE+αlossCL,
(9)
式中,α表示平衡lossCL和lossCE的加權(quán)系數(shù)。在確定網(wǎng)絡(luò)結(jié)構(gòu)和損失函數(shù)后,A&T-MLP優(yōu)化的具體過程見算法1。
算法1A&T-MLP
輸入:屬性矩陣X,鄰接矩陣A,節(jié)點(diǎn)標(biāo)簽集合Y,隱藏層維度d、屬性相似節(jié)點(diǎn)數(shù)k,權(quán)重系數(shù)α,可訓(xùn)練參數(shù)θ。
輸出:模型優(yōu)化參數(shù)θ。
1.計(jì)算屬性矩陣X的余弦相似度得到相似度矩陣S
2.選取每個節(jié)點(diǎn)前k個相似度值構(gòu)建屬性相似度矩陣S(k)
3.對A和S(k)進(jìn)行歸一化,計(jì)算對比損失引導(dǎo)信息γ
4.Repeat
5. 使用X、θ和公式(3)、(4)生成特征矩陣H(2)和Z
6. 使用H(2)、Z、γ、α和公式(9),計(jì)算loss
7. 計(jì)算損失函數(shù)梯度?loss,利用反向傳播更新參數(shù)矩陣θ
8.Until convergence
3 結(jié)果與分析
3.1 實(shí)驗(yàn)設(shè)置
本文使用3個基準(zhǔn)圖數(shù)據(jù)集Wikipedia、Cora和Citeseer[21]評估基線模型和A&T-MLP在節(jié)點(diǎn)分類任務(wù)中的實(shí)驗(yàn)性能,使用的基線模型和構(gòu)建的基線模型均使用Python語言和深度學(xué)習(xí)框架Pytorch實(shí)現(xiàn)。數(shù)據(jù)集相關(guān)統(tǒng)計(jì)信息見表1。基線模型分別選擇GNN模型GCN[3]、SGC[4]、GAT[5]和GATv2[6],以及感知機(jī)模型MLP[10]和Graph-MLP[14]。
節(jié)點(diǎn)分類是一種多分類任務(wù),利用圖的拓?fù)浣Y(jié)構(gòu)和節(jié)點(diǎn)屬性確定每個節(jié)點(diǎn)所屬類別,因此采用常見多分類指標(biāo)Micro-F1和Macro-F1進(jìn)行評估。對于每個數(shù)據(jù)集,各模型采用相同數(shù)據(jù)集劃分,隨機(jī)抽取10%的節(jié)點(diǎn)標(biāo)簽作為訓(xùn)練集,剩余節(jié)點(diǎn)標(biāo)簽中隨機(jī)抽取50%作為測試集。
所有基線模型都先按照原始論文中建議的參數(shù)進(jìn)行初始化,然后對部分模型進(jìn)一步調(diào)整,以獲取最佳性能。對于A&T-MLP,參數(shù)主要包括學(xué)習(xí)率lr、訓(xùn)練次數(shù)epoch、隱藏層維度d、屬性相似節(jié)點(diǎn)數(shù)k以及平衡損失函數(shù)的權(quán)重系數(shù)α。A&T-MLP的最終參數(shù)設(shè)置如表2所示。
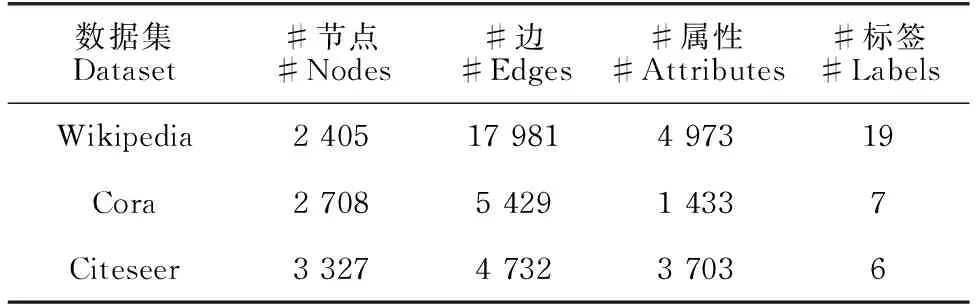
表1 數(shù)據(jù)集信息
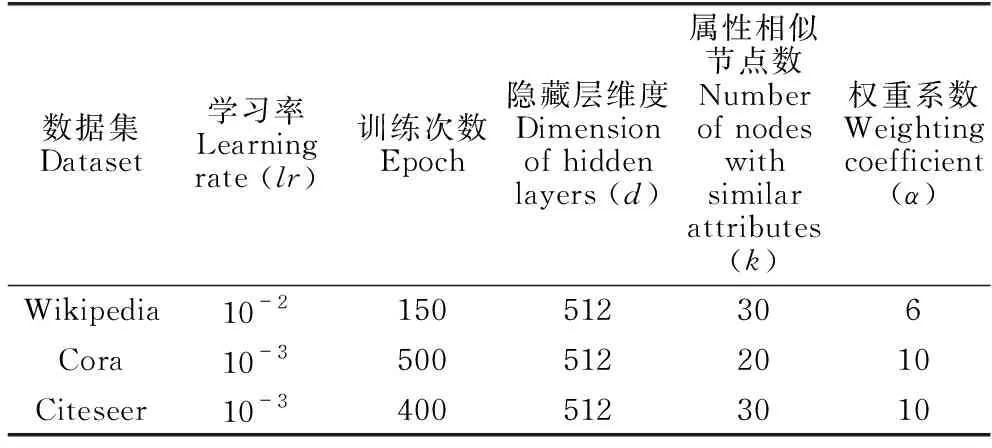
表2 A&T-MLP參數(shù)設(shè)置
3.2 實(shí)驗(yàn)結(jié)果
本節(jié)通過節(jié)點(diǎn)分類任務(wù)評估不同模型的實(shí)驗(yàn)性能,實(shí)驗(yàn)結(jié)果如表3所示。從表3可以看出,在3個數(shù)據(jù)集上,A&T-MLP模型的Micro-F1和Macro-F1分?jǐn)?shù)始終高于基線模型,表明A&T-MLP能夠有效保留原始圖的屬性和拓?fù)涮卣餍畔?并將其編碼到節(jié)點(diǎn)特征向量中,從而提升了節(jié)點(diǎn)分類能力。在屬性信息豐富的Wikipedia數(shù)據(jù)集上,所有GNN模型表現(xiàn)均弱于MLP模型,同時引入拓?fù)鋵Ρ葥p失的Graph-MLP弱于僅使用屬性信息的MLP。這表明在以屬性為主要信息的數(shù)據(jù)集上,依賴拓?fù)浣Y(jié)構(gòu)進(jìn)行特征提取和保留的方法限制了模型的表征能力,而同時使用屬性和拓?fù)湫畔⒁龑?dǎo)對比損失的A&T-MLP表現(xiàn)最好,能夠有效平衡特征向量中蘊(yùn)含的屬性和拓?fù)湫畔ⅰT谕負(fù)湫畔⒇S富的Cora和Citeseer數(shù)據(jù)集上,所有GNN模型優(yōu)于僅使用屬性信息的MLP。GNN模型的高性能得益于信息傳遞和聚合過程中拓?fù)湫畔⒌闹貜?fù)使用,Graph-MLP則是通過對比損失保留了拓?fù)潢P(guān)聯(lián)信息,而A&T-MLP的對比損失在關(guān)注拓?fù)湎嗨菩缘耐瑫r,也對屬性相似性這一重要的原始圖信息進(jìn)行關(guān)注,能夠更為充分地保留分類任務(wù)所需的特征信息。
綜上,不同基線模型在不同數(shù)據(jù)集上的表現(xiàn)差異較大,并且復(fù)雜的信息傳遞和聚合方式不一定能夠獲得最佳的性能。相較于基線模型,A&T-MLP在不同數(shù)據(jù)集上均能獲得最佳性能,證明了同時使用屬性和拓?fù)湎嗨贫刃畔⒁龑?dǎo)的對比損失,不僅能夠提升模型的預(yù)測性能,而且也增強(qiáng)了模型對不同數(shù)據(jù)的泛化能力。
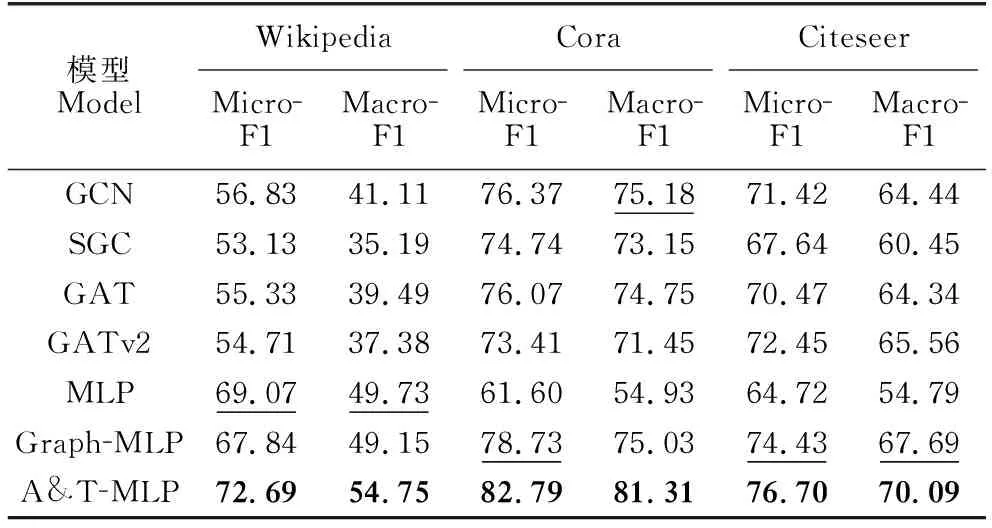
表3 節(jié)點(diǎn)分類實(shí)驗(yàn)結(jié)果
為了進(jìn)一步探究A&T-MLP在3個數(shù)據(jù)集上的性能,本文通過減少訓(xùn)練集中邊緣的數(shù)量評估基線模型和A&T-MLP在信息缺失條件下的實(shí)驗(yàn)表現(xiàn)。在邊緣缺失實(shí)驗(yàn)中,每次減少訓(xùn)練集中20%的邊信息,實(shí)驗(yàn)結(jié)果見圖2。
由圖2可知,隨著訓(xùn)練集中包含的邊信息不斷減少,各模型的實(shí)驗(yàn)性能出現(xiàn)較為明顯的波動(由于MLP僅使用屬性信息,實(shí)驗(yàn)結(jié)果不受邊信息減少影響),但A&T-MLP模型的預(yù)測結(jié)果始終優(yōu)于其他基線模型。在屬性信息豐富的Wikipedia數(shù)據(jù)集上,邊信息的減少不一定導(dǎo)致模型性能下降,相反GNN模型在邊緣缺失80%時取得了最佳實(shí)驗(yàn)結(jié)果。在拓?fù)湫畔⒇S富的Cora和Citeseer數(shù)據(jù)集上,除MLP外所有模型的實(shí)驗(yàn)性能隨邊信息的減少呈現(xiàn)出下降趨勢,特別是GATv2在邊緣缺失80%時性能下降9.53%。綜上,在邊信息大量缺失時A&T-MLP相較基線模型能夠更好地學(xué)習(xí)數(shù)據(jù)特征分布,改善節(jié)點(diǎn)分類任務(wù)的實(shí)驗(yàn)表現(xiàn)。
3.3 消融實(shí)驗(yàn)
為了驗(yàn)證拓?fù)湫畔⒑蛯傩孕畔&T-MLP模型性能的影響,在3個數(shù)據(jù)集上進(jìn)行消融實(shí)驗(yàn),記錄Micro-F1和Macro-F1。其中,不使用對比損失的變體為MLP,僅使用拓?fù)湫畔⒁龑?dǎo)對比損失的變體為T-MLP,僅使用屬性信息引導(dǎo)對比損失的變體為A-MLP。為保證實(shí)驗(yàn)結(jié)果的公平性,保持各模型參數(shù)一致。消融實(shí)驗(yàn)結(jié)果如圖3所示。相較于不使用原始圖信息、單獨(dú)使用拓?fù)湫畔⒒驅(qū)傩孕畔⒌淖凅w,同時使用兩類信息的A&T-MLP模型獲得了最佳性能,證明同時保留屬性和拓?fù)湫畔⒛軌蜻M(jìn)一步增強(qiáng)模型的表征能力,提升分類任務(wù)中的實(shí)驗(yàn)表現(xiàn)。
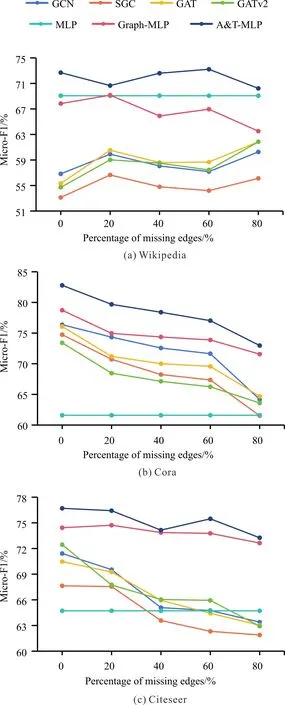
圖2 邊緣缺失實(shí)驗(yàn)結(jié)果
3.4 參數(shù)實(shí)驗(yàn)
為了分析A&T-MLP性能受參數(shù)的影響,使用Citeseer數(shù)據(jù)集進(jìn)行參數(shù)實(shí)驗(yàn),并記錄Micro-F1和Macro-F1分?jǐn)?shù)。此外,為了保證參數(shù)實(shí)驗(yàn)的公平性,除驗(yàn)證參數(shù)外,其余參數(shù)按照表3進(jìn)行設(shè)置。參數(shù)實(shí)驗(yàn)結(jié)果如圖4所示。
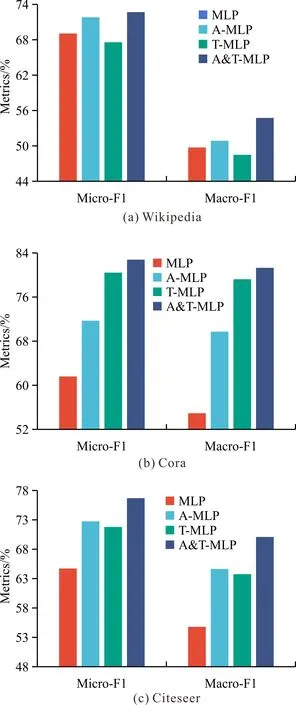
圖3 消融實(shí)驗(yàn)結(jié)果
為了驗(yàn)證隱藏層維度d對A&T-MLP性能的影響,使用不同d值進(jìn)行實(shí)驗(yàn),結(jié)果如圖4(a)所示。最初,Micro-F1和Macro-F1隨網(wǎng)絡(luò)維度的增大而提高,這是因?yàn)檩^高的維度代表了更多的神經(jīng)元,能夠編碼更多的有益信息,提升實(shí)驗(yàn)表現(xiàn)。但是,隨著維度進(jìn)一步增大,Micro-F1和Macro-F1呈現(xiàn)出下降的趨勢,這是因?yàn)檫^大的維度使節(jié)點(diǎn)表示中編碼了噪聲信息,從而影響了A&T-MLP的表現(xiàn)。
為了驗(yàn)證屬性相似節(jié)點(diǎn)數(shù)k對A&T-MLP性能的影響,使用不同k值進(jìn)行實(shí)驗(yàn),結(jié)果如圖4(b)所示。從結(jié)果看,Micro-F1和Macro-F1呈現(xiàn)先上升再下降的趨勢,過大和過小的k值下A&T-MLP的表現(xiàn)均較為一般,這是因?yàn)閗值過小無法保留充足的屬性相似度信息,而k值過大會在對比損失計(jì)算過程中引入大量噪聲節(jié)點(diǎn),影響A&T-MLP的性能。
為了驗(yàn)證損失函數(shù)中的權(quán)重系數(shù)α對模型性能的影響,使用不同α值進(jìn)行實(shí)驗(yàn),結(jié)果如圖4(c)所示。權(quán)重系數(shù)α調(diào)控了對比損失在整個損失函數(shù)中所占的比重,α值越大模型訓(xùn)練過程中越關(guān)注對比損失的優(yōu)化。從實(shí)驗(yàn)結(jié)果來看,A&T-MLP的預(yù)測性能隨著α值的增大先上升后下降,這是因?yàn)檫^于關(guān)注對比損失的優(yōu)化會導(dǎo)致對交叉熵?fù)p失的忽略,從而影響了A&T-MLP的性能。
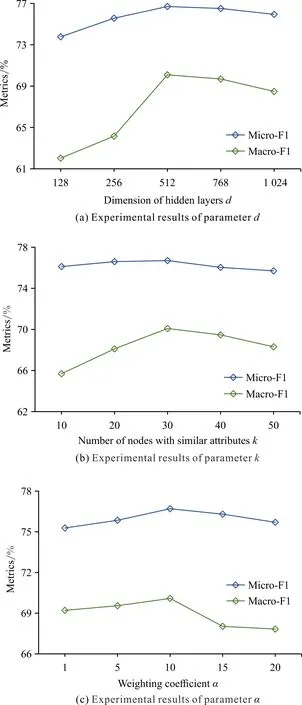
圖4 參數(shù)實(shí)驗(yàn)結(jié)果
3.5 可視化
節(jié)點(diǎn)表示蘊(yùn)含了原始圖的相關(guān)信息,對其進(jìn)行可視化能夠直觀地反映原始圖的某些特征。對于可視化任務(wù),首先使用t-SNE[22]將各模型生成的節(jié)點(diǎn)特征向量降至2維,然后根據(jù)Citeseer數(shù)據(jù)集的標(biāo)簽信息將節(jié)點(diǎn)分別標(biāo)記為6種顏色,最后在二維平面上進(jìn)行可視化,實(shí)驗(yàn)結(jié)果如圖5所示。節(jié)點(diǎn)分類準(zhǔn)確的可視化結(jié)果通常為相同顏色節(jié)點(diǎn)接近,不同顏色節(jié)點(diǎn)遠(yuǎn)離。由圖5可知,GCN、MLP、Graph-MLP和A&T-MLP均能提取原始圖中相關(guān)信息形成社區(qū)結(jié)構(gòu),但是使用屬性和拓?fù)湫畔⒁龑?dǎo)對比損失的A&T-MLP具有更高的類內(nèi)相似性和類間界限。可視化實(shí)驗(yàn)反映了模型保留同一社群節(jié)點(diǎn)相似特征的能力,證明了使用對比損失能夠增強(qiáng)模型表征能力,也更為直觀地反映了模型的分類性能。
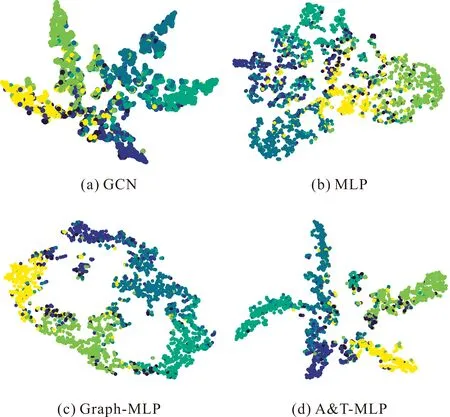
圖5 Citeseer可視化
3.6 訓(xùn)練時間
為了比較不同模型的訓(xùn)練復(fù)雜度,記錄Wikipedia數(shù)據(jù)集上迭代100次后單次迭代的平均訓(xùn)練時間(包括前向傳播、損失函數(shù)計(jì)算、反向傳播過程),實(shí)驗(yàn)結(jié)果如圖6所示。對比不同模型的訓(xùn)練時間,直接對原始圖信息編碼的GCN和MLP計(jì)算速度較快,在此基礎(chǔ)引入了更加復(fù)雜的特征提取方式的改進(jìn)模型訓(xùn)練時間進(jìn)一步增加。雖然基于MLP的改進(jìn)模型網(wǎng)絡(luò)結(jié)構(gòu)更為簡單,但是為了保留原始圖相關(guān)信息,需要借助對比損失進(jìn)行優(yōu)化,導(dǎo)致模型的訓(xùn)練時間增加。此外,對比使用對比損失的Graph-MLP和A&T-MLP,盡管A&T-MLP引入了屬性信息,但是只保留了每個節(jié)點(diǎn)前k個相似度值最大的值,因此相較于GAT和GATv2訓(xùn)練時間差異較大,相較于Graph-MLP訓(xùn)練時間差異較小,并且實(shí)驗(yàn)性能提升更為明顯。
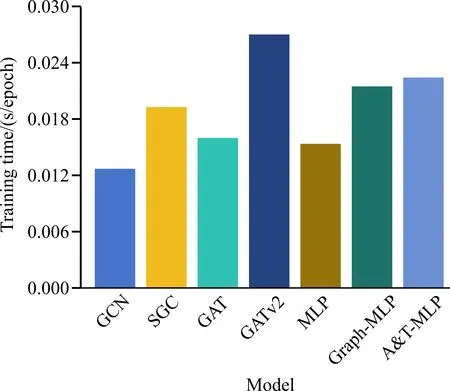
圖6 訓(xùn)練時間對比
4 結(jié)論
本文設(shè)計(jì)了一種無需信息傳遞和聚合的圖多層感知機(jī)模型A&T-MLP,通過屬性和拓?fù)湫畔⒁龑?dǎo)的對比損失有效保留原始圖特征。實(shí)驗(yàn)結(jié)果表明,基于屬性相似度與拓?fù)湎嗨贫鹊膶Ρ葥p失能夠顯著提升MLP模型在節(jié)點(diǎn)分類任務(wù)中的實(shí)驗(yàn)性能,并且優(yōu)于較為先進(jìn)的GNN基線模型。此外,A&T-MLP在處理拓?fù)湫畔⒉粶?zhǔn)確的圖數(shù)據(jù)時具有較明顯的優(yōu)勢,即使在拓?fù)湫畔⑷笔?0%的極端情況下,依然具有良好的性能。在當(dāng)前工作中,通過簡單的MLP構(gòu)建神經(jīng)網(wǎng)絡(luò)基本框架,使得模型訓(xùn)練過程中缺乏對特征中重要信息的關(guān)注。因此,在后續(xù)工作中,將在多層神經(jīng)網(wǎng)絡(luò)中引入注意力機(jī)制,增強(qiáng)關(guān)鍵特征信息的保留,并將模型應(yīng)用于社交網(wǎng)絡(luò)惡意賬戶檢測和犯罪組織成員身份發(fā)現(xiàn)等任務(wù)。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學(xué))(2019年6期)2019-10-10 01:01:50
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
