基于變量分組降維的辛烷值損失預測模型
2023-12-02 14:53:57申平田德生
湖北工業大學學報 2023年1期
申平 田德生
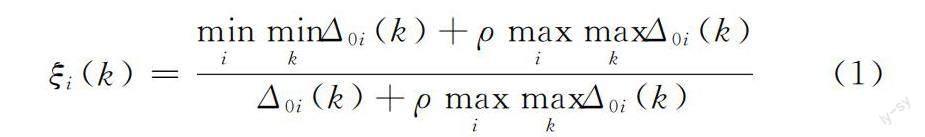
[摘 要]針對精煉汽油辛烷值損失的問題,基于灰色關聯度分析方法與最大信息系數方法,給出變量分組降維的特征選擇方法,以有效選擇出具有獨立性代表的特征;與隨機森林算法相結合,提出一種辛烷值損失量預測模型。由于操作變量之間具有高度非線性和相互強耦聯的關系,采用變量分組降維,即考慮操作變量、性質變量與產品硫含量、辛烷值損失的關系來篩選特征。利用灰色關聯度篩選出對辛烷值損失和產品硫含量的關聯程度較強的特征,排序后由最大信息系數篩選出28個獨立變量。收集研究生數學建模競賽試題數據,采用隨機森林算法進行仿真預測計算。計算結果表明,基于變量分組的特征選擇和辛烷值損失預測模型得到的均方誤差為0.0086,擬合值R2為92.5%。
[關鍵詞]變量分組; 灰色關聯度; 最大信息系數; 隨機森林; 辛烷值損失預測
[中圖分類號]TE62[文獻標識碼]A
成品汽油是由原油經過一系列的工藝加工而成,其中催化裂化就是將原油中40%~60%重油輕質化的一個重要工序,經過這一工序得到的催化裂化汽油具有高硫、高烯烴的缺點,為了達到可使用的汽油質量要求,就必須進行脫硫和降烯烴的精制處理。在對催化裂化汽油進行脫硫和降烯烴的精制過程中,往往會導致汽油辛烷值下降。
高品質的汽油具有較高的辛烷值和低的含硫量。影響辛烷值損失的因素包括原料性質、待生吸附劑性質、再生吸附劑性質和產品性質等變量以及300多個操作變量(控制變量)。辛烷值是反映汽油燃燒性能的重要指標,人們把它作為汽油的商品牌號(例如89#、92#、95#),它的高低直接與經濟收益相聯系。為了經濟效益的最大化,在減少環境污染(即控制硫含量)的基礎上,進行降低辛烷值損失研究就顯得尤為重要,權衡深度脫硫與辛烷值損失之間的關系,也成為人們關注的問題。很多學者在影響汽油辛烷值損失因素、優化降低辛烷值損失的操作變量等方面進行廣泛研究。高潔等[1]為了降低辛烷值損失,制定了優化操作條件的相關措施;齊萬松等[2]采用吸附劑低活性、降低氫油比、提高反應溫度等操作條件去降低汽油脫硫的辛烷值損失;黃宏林等[3]在分析裝置辛烷值損失原因后制定了優化調整措施,分階段進行優化調整裝置的參數,優化調整后產品辛烷值損失得以降低;張玉瑞等[4]經過調和實驗,建立了非線型回歸模型,調和辛烷值模型的預測模型。
學者大多側重于化工過程的建模研究,即在化工條件下降低辛烷值損失因素的研究。實際上,由于煉油工藝過程的復雜性以及設備的多樣性,操作變量(控制變量)之間具有高度非線性和相互強耦聯的關系,若是采用化工過程建模研究,僅僅通過數據關聯或機理建模的方法來實現優化控制,往往達不到理想的效果。因此,筆者采用不同的方法建立辛烷值損失預測模型。這個問題涉及變量數量眾多,對于有大量變量的工程技術應用問題經常采取先降維后建模的方法。由于不同的變量相互耦聯關系強度不同,且它們對辛烷值損失的影響程度不一樣,因此本文在進行變量降維之前先對變量進行分組,對不同的組別分別進行降維,確定篩選出主要變量后,再建立辛烷值損失預測模型。
本文研究的是精煉汽油生產過程辛烷值損失量的預測問題,這也是一個涉及變量多的非線性問題,常用的統計方法解決這類問題都不奏效。為了達到良好的預測效果,采取變量分組降維思路結合灰色關聯度與最大信息系數方法,處理高維變量降維問題。文本數據集來源于2020年“華為杯”第十七屆中國研究生數學建模競賽B題。數據中有7個原料性質變量、2個待生吸附劑性質變量、2個再生吸附劑性質變量和354個操作變量。先通過過濾型算法方差選擇法去掉方差小的變量;再根據對催化裂化汽油精制脫硫裝置的工藝操作特點,將變量分為操作變量組和性質變量組。對不同組別分別計算變量與產品汽油的辛烷值和含硫量的灰色關聯度,得到一個排序(顯示這些變量對辛烷值損失和產品硫含量的關聯性程度);之后運用最大信息系數計算變量之間的信息系數,確定篩選出具有代表性和獨立性的變量;最后采用隨機森林算法進行辛烷值損失量的預測。
1 主要原理和核心算法
針對變量數量多且不同的變量相互耦聯關系強度不同的情況,本文采取分組降維,采取的方法是灰色關聯度法和最大信息系數法。灰色關聯度法對于變量間相互耦聯關系強度不同的排序問題具有優勢,最大信息系數方法更適合篩選出獨立特征(變量)。最大信息系數能夠將最大的特征去除,得到相對獨立的特征去除相關性較大的特征,在保證特征關聯度的同時也考慮特征之間的獨立性,使選擇的特征盡可能具有獨立性和代表性。
在建立預測辛烷值損失模型時,本文選擇隨機森林預測算法。這種算法在很多數據集上建立隨機的樹,樹與樹之間(即特征子集之間)具有相互獨立的特點,因此以部分的特征數據進行預測,仍可以維持結果準確度。
1.1 灰色關聯度分析
灰色關聯度(GRA)[5]可以通過對比參考數據列與比較數據列的相似程度去衡量兩者的關系是否具有關聯性。關聯系數
其中:Δ0i(k)表示第k點X0與Xi的絕對差;ρ為分辨系數,其作用是減少因Δmax數值失真而導致的誤差,ρ一般取0.5。
1.2 最大信息系數
最大信息系數(MIC)[7]主要用于衡量兩個變量X和Y之間的線性或非線性耦合關聯強度。
設X,Y是取值于數據集D中的兩個隨機變量,兩個隨機變量(X,Y)聯合概率密度函數為p(x,y),邊緣概率密度函數為p(x)和p(y),定義兩個隨機變量取值x和y之間的互信息為
將數據集D 中兩個隨機變量的不同取值用網格分布的方式劃分,即將隨機變量X和Y的取值分別劃分為a個網格和b個網格,形成a×b個網格劃分。由于隨機變量X和Y取值的隨機性,它們在不同的網格劃分方法中的分布也不同,將不同網格劃分方法中的互信息MI(x;y)的最大值作為最大互信息值。經過歸一化處理可得最大信息系數MIC的表達式[8]為
其中,B(n)=n0.6。最大信息系數的取值在[0,1]之間,取值越接近1,代表隨機變量X、Y之間的依賴關系越強;取值越接近0,代表隨機變量X、Y之間的依賴關系越弱。
1.3 隨機森林預測算法
隨機森林算法(RF)是一種有監督學習算法,在處理分類和回歸問題方面具有優越的性能。它通過構建多棵相互獨立的決策樹組成的森林來完成決策、分類和回歸的任務[9]。經過訓練后,算法中設立森林的每一棵決策樹會分別對新輸入的樣本進行預測,由多顆樹預測值的均值決定最終預測結果。
構造隨機森林算法的步驟為3步[15]:1)確定用于構造的樹的個數;2)對數據進行自助采樣;3)基于新數據集構造決策樹。
2 結果
2.1 數據的收集
本文數據集來源于2020年“華為杯”第十七屆中國研究生數學建模競賽B題(https: //cpipc.chinadegrees.cn//cw/4924b7f01749981b29502e9)。該數據集是某石化企業的催化裂化汽油精制脫硫裝置積累的大量歷史數據,包括從催化裂化汽油精制裝置采集的325個數據樣本,每個數據樣本中有7個原料性質變量、2個待生吸附劑性質變量、2個再生吸附劑性質變量(以上被稱為性質變量)和354個操作變量。這些數據采自于中石化高橋石化實時數據庫(霍尼韋爾PHD)及LIMS實驗數據庫。其中操作變量數據來自于實時數據庫。
2.2 計算結果及分析
2.2.1 數據預處理
1)去除異常值 去除異常值的根據是3σ原則處理,并采用3σ邊緣數值進行替換。對于超過操作變量取值范圍的變量,刪除異常比例為較高的操作變量,即刪除7個變量,它們是S.ZORB.TE_2005.PV,S.ZORB.PT_9403.PV,S.ZORB.LC_1201.PV,S.ZORB.FT_1004.TOTAL,S.ZORB.FT_9101.TOTAL,S.ZORB.TE_5007.DACA,S.ZORB.PT_2106.DACA.PV。處理后的數據包含11個性質變量和347個操作變量。
2)線性過濾法預處理 線性過濾法預處理就是對數據進行相關性和共線性的度量處理,刪除數據中的方差較小變量。這一過程中,對于347個操作變量,去除強共線性>0.9的138個操作變量,剩下209個操作變量。10個性質變量保持不變。
2.2.2 特征的選取
1)變量分組降維 考慮到數據性質變量和操作變量與對辛烷值損失的不同影響程度,故將變量分為性質變量組和操作變量組。通過Python語言計算灰色關聯度選出變量,將因變量辛烷值損失和產品硫含量分別作為參考序列,分組后的變量作為自變量序列,分開分析篩選變量。將變量進行歸一化處理(區間化),采用式(1)計算出關聯系數,計算出10個性質變量與209個操作變量分別對產品硫含量和辛烷值損失的灰色關聯度,計算結果如表1和表2。
根據表1和表2結果,將得到的灰色關聯度進行排序。為保證選取的變量在30個以內,在選取與產品硫含量較大關聯度的變量時,可選取GRA1>0.5644的前6個性質變量、GRA2>0.8244的前20個操作變量,共26個變量;在選取與辛烷值損失較大關聯度的變量時,可選取GRA2>0.6990的前6個性質變量、GRA4>0.7602的前24個操作變量。表3和表4分別表示選出的變量對于產品硫含量和辛烷值損失的灰色關聯度排序。
對表3和表4篩選出的變量進行匯總,去掉重復和關聯度相對較低的變量,最終選出8個性質變量和39個操作變量,共計47個變量(表5)。
2)獨立性的判別 為了去除表5中具有較為復雜耦合關系的變量(獨立性較差),采用最大信息系數方法進行篩選。運用R軟件對式(2)計算出的47個變量之間的互信息進行編程,將其代入式(3),得到特征之間的最大信息系數。最大信息系數的圖像如圖1a所示。
在圖1中,橫縱坐標表示不同的變量,中間的圓形色點色度代表兩個變量之間最大信息系數的強弱,偏向紅褐色表明兩個變量之間的相關性強度較強。色度變化范圍為0~1,其值越接近1,顏色越接近紅褐色。
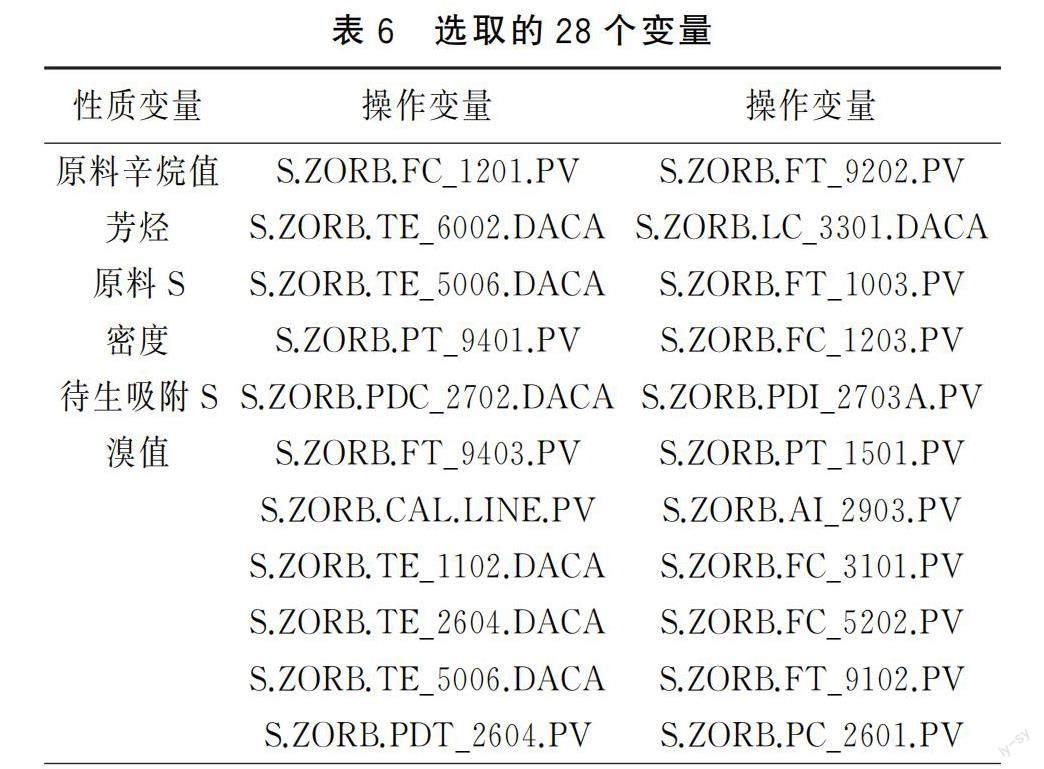
為選出獨立性強的變量,首先剔除最大信息系數大于0.5的變量。通過對辛烷值的模擬計算和結果對比,選取28個變量,其中性質變量6個,操作變量22個(表6)。
對選擇出28個變量(特征),計算28個重要特征的最大信息系數,如圖1b所示。圖1b中色點顏色值均在0.5以下,這表明變量之間耦合關系不強,即所選變量具有較好的獨立性。
2.2.3 辛烷值損失預測結果與分析 對辛烷值損失預測計算,擬建立隨機森林算法[10]模型。Scikit-learn工具包是一個開源的基于Python編程語言的機器學習工具庫。
1)確定森林中樹的數目,即決策數樹數目[11]。在Scikit-learn工具包中RandomForestRegressor函數,決策數樹目以參數n_estimators表示。理論上講n_estimators越大越好,但由于計算機資源的占用會導致訓練和預測時間的增加[12]。在Scikit-learn中n_estimators默認為10,本文通過設定為20,50,80測試,最終設定為50。
2)對數據進行自助采樣。從樣本集中有放回地重復隨機抽取一個樣本,共抽取n_sample次,組成新的數據集。新數據集的樣本容量與原數據集的相等,本文數據集的樣本容量為325。
3)基于新數據集來構造決策樹。在每個結點處選取特征的一個子集,選取的特征子集中特征的個數通過max_features參數來控制,一般max_features參數的設置不宜過小。在Scikit-learn中,max_features有以下幾種設置:auto,sqrt,log2,None[12]。這里設置為None。
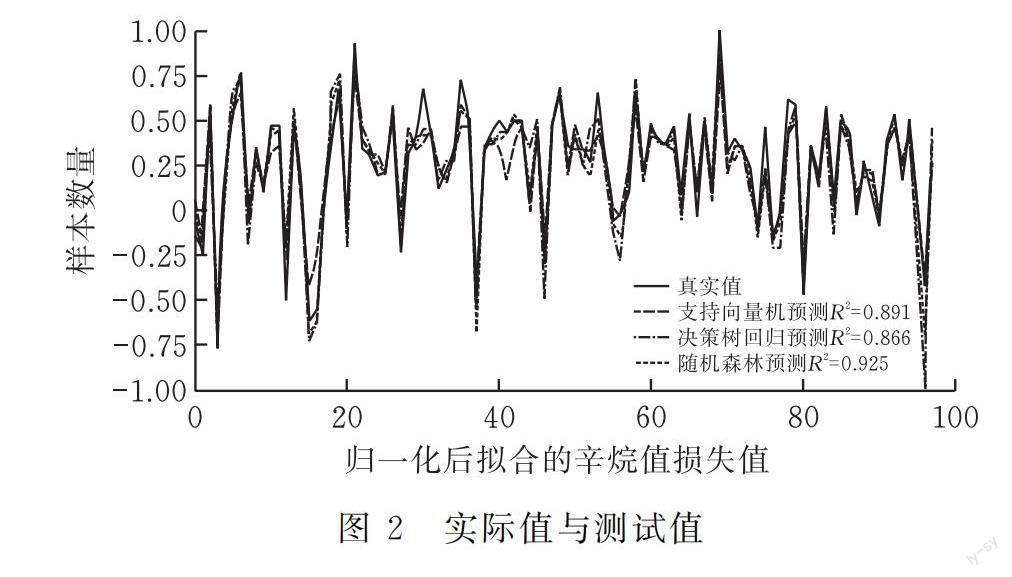
在計算中,產品辛烷值作為被解釋變量,變量數據進行歸一化處理后,將隨機選取的228個樣本數據作為訓練集數據,選取97個樣本數據作為測試集數據,利用測試集數據對擬合好的模型進行辛烷值損失的預測。計算結果見圖2。
圖2中:紅色的曲線為真實值的波動情況;綠色為隨機森林模型[13]預測曲線,擬合值R2為92.5%;藍色的曲線為支持向量機回歸模型[14]預測曲線,擬合值R2為89.1%;淺綠色為決策數回歸模型[15]預測曲線,擬合值R2為86.6%。從圖2可知,基于隨機森林算法的預測值曲線與真實值曲線的重疊程度最高,說明所建立的預測模型預測效果較好。
比較不同的算法預測模型的預測性能。表7為預測性能評價指標MSE值、MAE值、R2的值。
從表7結果可知,本文使用的隨機森林算法的均方誤差(MSE)為0.0086,平方絕對誤差(MAE)為0.0653,MSE和MAE值均比支持向量機回歸和決策樹回歸的小,這進一步說明隨機森林算法的預測精度優于支持向量機回歸和決策樹回歸,而且基于變量分組降維的隨機森林算法的可決系數達到92%以上。在模型能力的解釋方面,該方法能解釋樣本數據中92%以上的信息,體現其具有合理性。
3 結束語
針對選取具有獨立性和代表性的重要特征,以及建立預測辛烷值損失預測模型的問題,提出了基于變量分組的特征選擇和辛烷值損失預測模型。通過變量分組,將性質變量和操作變量分別處理,分析其與產品硫含量、辛烷值損失的關系;通過灰色關聯度方法得到關聯度強的特征,排序進行篩選;再利用最大信息系數篩選出獨立性特征,最終得到28個特征。在預測模型方面,采用隨機森林構建辛烷值損失預測模型,與支持向量機回歸和決策樹回歸算法比較,構建的隨機森林辛烷值損失預測模型得到的均方誤差為0.0086,R2為92.5%。通過將變量分組并采取融合灰色關聯度分析方法和最大信息系數方法,在選擇具有代表性特征的同時,更保證操作變量之間的獨立性。
[ 參 考 文 獻 ]
[1] 高潔,王莉娟,孫麗琳. 優化操作條件降低汽油辛烷值損失[J]. 石油化工應用,2011, 11(11):97-101.
[2] 齊萬松,姬曉軍,侯玉寶,等. SZorb裝置降低汽油辛烷值損失的探索與實踐[J].煉油技術與工程, 2014,44(11):5-10.
[3] 黃宏林,李燁,谷曉琳. 優化操作條件降低汽油加氫裝置辛烷值損失[J]. 石油化工應用, 2015, 34(12): 116-118.
[4] 張玉瑞,陳微微,周曉龍,等. 一種改進的調合辛烷值模型預測汽油研究法辛烷值[J]. 石油煉制與化工, 2011,1(03):14-28.
[5] 江世艷,王燕青,徐越峰,等. 基于灰色關聯分析的電網安全事故關鍵致因分析[J].中國電力,2020(10):56-59.
[6] 張曉娜. 我國服務業與城鎮化的灰色關聯度實證考察[J]. 統計與決策,2020(09):97-100.
[7] RESHEF D N, RESHEF Y A, FINUCANE H K, et al. Detecting Novel Associations in Large Data Sets[J].Science, 2011,334(6062): 1518-1524.
[8] 張瑩,杜井濤,吳懷崗. 基于最大信息系數的主成分分析貝葉斯分類算法[J]. 信息與電腦, 2020,32(11),63-66.
[9] TIN K H. The random subspace method for constructing decision forests[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1998, 8(10): 832-844.
[10]YU F B, WEI C H, DENG P. Deep exploration of random forest model boosts the interpretability of machine learning studies of complicated immune responses and lung burden of nanoparticles[J]. Science Advances, 2021, 5(26): 7-22.
[11]盧維學,吳和成,萬里洋. 基于融合隨機森林算法的PLS對降水量的預測[J]. 統計與決策.2020,8(18):27-31.
[12]暮雪成冰,隨機森林n_estimators參數max_features參數[EB/OL].[2019-06-19]https://blog.csdn.net/u012768474/article/details/92829985.
[13]BREIMAN L. Random forests[J]. Mach Learn,2001, (45): 5-32.
[14]周洲,焦文玲,任樂梅,田興浩. 蟻群算法分配權重的燃氣日負荷組合預測模型[J].哈爾濱工業大學學報,2021(06):177-183.
[15]王馬強. 數據挖掘方法在信用卡違約預測中的應用[D]. 武漢:華中師范大學.2020.
Feature Selection and Octane Number Loss Prediction
Model Based on Variable Grouping
SHEN Ping, TIAN Desheng
(School of Science, Hubei Univ. of Tech., Wuhan 430068,China)
Abstract:This paper studies the octane number loss of refined gasoline. In order to effectively select the features with independent representation, based on the grey relational analysis method and the maximum information coefficient method, the feature selection method of variable grouping dimension reduction is given. Combined with stochastic forest algorithm, a prediction model of octane number loss is proposed. In view of the highly nonlinear and strongly coupled relationship among operational variables, variable grouping is adopted to reduce dimension, that is, the relationship between operational variables and property variables and sulfur content and octane number loss of products is considered to screen features. The features with strong correlation between octane number loss and sulfur content of products were screened by grey correlation degree, and 28 independent variables were screened by maximum information coefficient after sorting. The data of postgraduate mathematical modeling contest are collected, and the random forest algorithm is used for simulation and prediction calculation. The calculation results show that the mean square error of feature selection and octane number loss prediction model based on variable grouping is 0.0086, and the fitting value R2is 92.5%.
Keywords:variable grouping; grey correlation degree; maximum information coefficient; random forest; octane number loss predict
[責任編校:張 眾]
