基于局部信息增強注意力機制的網絡流量預測
2023-11-23 07:20:36何迎利胡光宇張浩曲志堅王子靈
科學技術與工程 2023年30期
何迎利,胡光宇,張浩,曲志堅,王子靈
(1.南京南瑞信息通信科技有限公司,南京 211100; 2.國網山東省電力公司,濟南 250012;3.山東理工大學計算機科學與技術學院,淄博 255049)
靈活以太網(flexible ethernet,FlexE)是實現網絡業務隔離和網絡切片的新技術,通過解耦以太網MAC(media access control)和PHY(physical layer)速率,實現對資源的靈活和精細化管理,滿足高速網絡傳送、靈活帶寬設置等需求[1]。基于FlexE技術的大型互聯網切片智能管控平臺在對網絡資源進行分配和調度以及業務動態編排之前能夠提前預測FlexE Client設備的網絡流量情況將會顯著提高資源分配和業務動態編排算法的性能[2-3]。
對不同設備的網絡流量進行準確預測成為業界關注的熱點問題之一。開始,大多采用傳統的統計模型來預測網絡流量,如以時間點為基礎建立的多元線性自回歸模型(autoregression,AR)、自回歸移動平均(autoregressive moving average,ARMA)和自回歸綜合移動平均(autoregressive integrated moving average,ARIMA)等線性模型。這些模型通過設置未知參數去擬合多項式函數,從而逼近網絡流量的真實值以達到預測的目的。線性模型的特點是需要人工憑借經驗設置多種參數來擬合數據,僅適用于短期流量預測且對于周期性較小和非線性的流量數據預測效果較差[4]。
近年來,隨著機器學習尤其是深度學習的不斷發展,利用機器學習模型預測網絡流量成為目前的主流方法。為了充分提取交通流中復雜的時空依賴關系,宋瑞蓉等[5]基于卷積神經網絡設計了一種能夠融合多維時空特征的流量預測模型,提高了預測性能。Valkanis等[6]提出了一種基于強化學習的新型流量預測機制,并利用該預測機制設計了一種彈性光網絡內的啟發式路由和頻譜分配算法以高效公平地分配網絡資源。Nie等[7]提出了一種基于強化學習的機制預測物聯網內部的網絡流量,通過將網絡流量預測問題建模為馬爾可夫決策過程實現預測算法。Yu等[8]針對長期流量預測的誤差積累問題,通過將5個雙向循環神經網絡集成到一個框架中,設計了一個多時間間隔特征學習網絡來處理長期網絡流量預測任務,該網絡具有在不同時間間隔提取長期流量特征的強大能力。Zhang等[9]針對網絡預測過程中用戶行為的復雜性以及網絡應用程序的多樣性提出了一個基于深度學習的加密數據包分類器來識別網絡應用程序,并以此為基礎提出一種基于深度學習的網絡流量預測方法。Zhang等[10]提出了一種基于長短期記憶的網絡流量預測模型,為了避免突發性對模型的負面激勵,還提出了一種滑動窗口梯度下降的神經網絡權值優化算法以適應不同網絡應用程序引起的流量模式的突發性變化。高志宇等[11]提出一種基于生成對抗網絡的流量預測方法,利用生成網絡與判別網絡的博弈對抗實現高精度的預測流量。王菁等[12]提出了一種結合動態擴散卷積模塊和卷積交互模塊的預測模型,該模型可以同時捕獲網絡流量中的空間特征和時間特征,提高了預測性能。薛自杰等[13]為了捕獲網絡流量中復雜的時空特征,基于編碼器-解碼器結構提出一種時空特征融合的神經網絡模型用于網絡流量預測。
綜上所述,網絡測量和管理對于未來的智能網絡服務質量和提高用戶體驗質量至關重要。準確預測網絡狀態可以支持網絡測量,并為網絡資源管理提供額外的時間。隨著網絡數據規模越來越大,深度學習技術在網絡測量和管理中發揮了關鍵作用。然而,由于網絡頻繁更新的流量拓撲結構,不同網絡應用程序引起的流量模式的動態變化,使得網絡中的設備流量具有復雜的非線性特征和空間依賴關系,網絡流量的分布特性也已經超出傳統意義上認為的泊松分布或者 Markov分布。這些問題導致目前的網絡流量預測方法在預測性能以及預測方法適應性方面仍然有待進一步提高。
為了實現一種局部信息增強的注意力機制以增強網絡流量時序數據中局部的上下文信息,同時將該注意力機制引入經典時序數據預測模型(long short term memory,LSTM)和門控循環單元(gate recurrent unit,GRU)模型以提高經典模型在網絡設備流量預測方面的性能,現通過兩個從運營商網絡中采集的網絡設備數據驗證所提出方法的有效性。
1 經典網絡流量預測模型簡介
1.1 LSTM結構
LSTM是一種時間循環神經網絡,是為了解決一般的循環神經網絡存在的長期依賴問題而專門設計出來的,其能夠對時間序列中長短期依賴的信息進行學習,從而對時間序列中的間隔和延遲事件進行處理和預測。
如圖1所示,LSTM網絡由輸入門(input gate)、遺忘門(forget gate)和輸出門(output gate)3個門構成。輸入門將新的信息選擇性的記錄到細胞狀態中。遺忘門對細胞狀態中的信息進行選擇性的遺忘,從而保留下來最具有特征的記憶細胞狀態。輸出門對結果進行選擇行輸出。
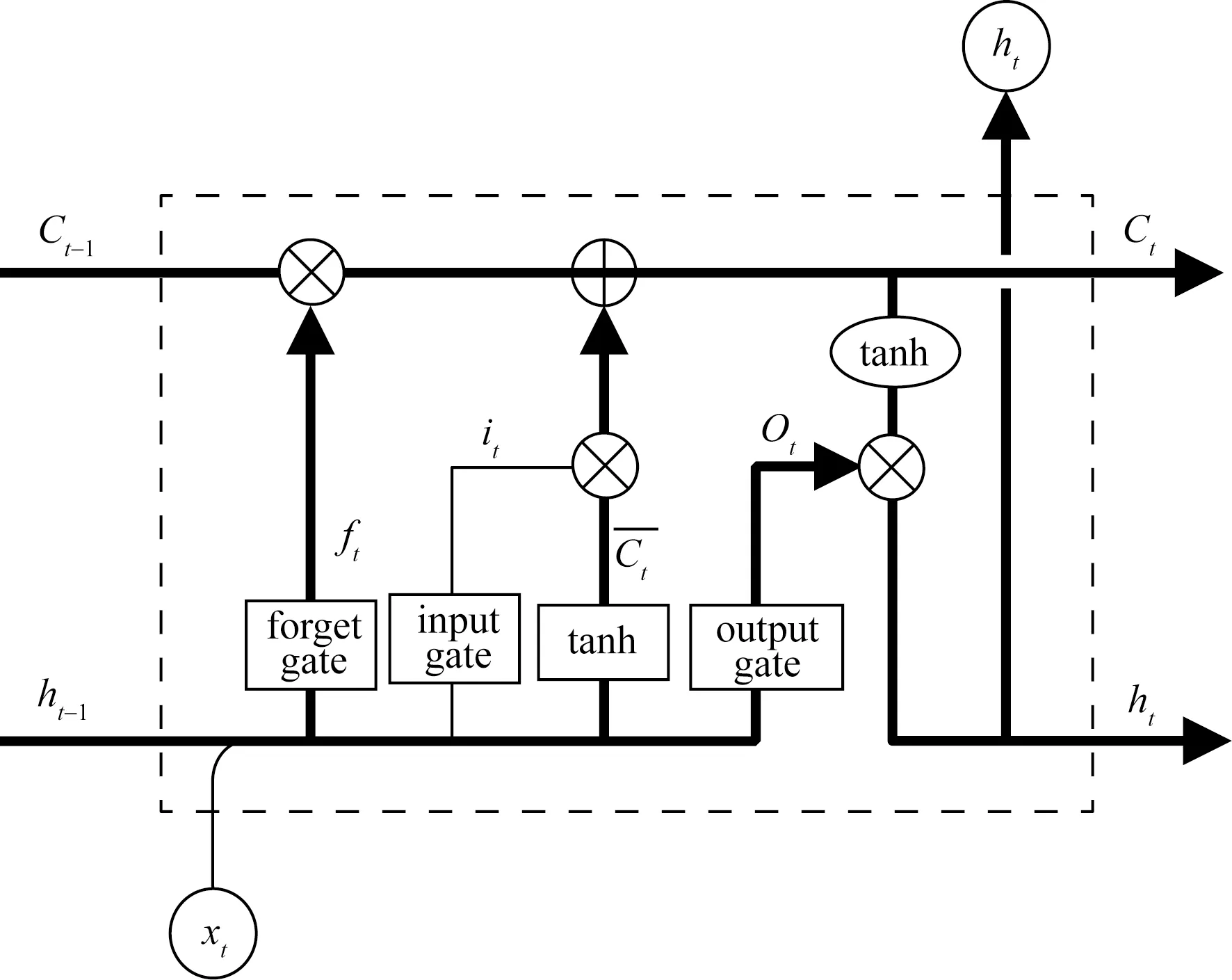
t為時間片,表示第t個時刻;xt為t 時刻的輸入;h為隱藏狀態,表示的是短期記憶;ht-1為t-1時刻的隱藏狀態;ht為t時刻的隱藏狀態;C為細胞狀態,表示的是長期記憶;Ct-1為t-1時刻的細胞狀態;Ct為t時刻的細胞狀態; ft為t時刻遺忘門的輸出;it為t時刻輸入門的輸出;Ot為t時刻輸出門的輸出;tanh為單元狀態更新值的激活函數
1.2 GRU結構
GRU是LSTM的變體,結構如圖2所示,同樣使用門控機制。GRU與LSTM不同的是它只有重置門和更新門。重置門決定了之前信息的遺忘程度,更新門選擇新的信息。
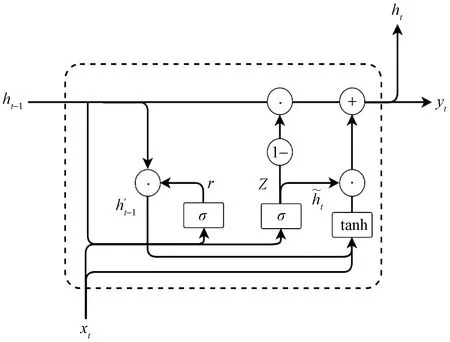
圖2 GRU單元結構

1.3 注意力機制
在機器學習領域注意力機制的核心操作是從序列中學習每一個元素的重要程度,得到一串權重參數,然后按重要程度將元素合并。這個權重參數就是注意力分配系數。具體而言,把元素看作由鍵(Key,K)和值(Value,V)組成的鍵值對,Q表示查詢值。注意力機制就是通過計算Q與K的相似度獲得每個V值的權重,并對Value值進行加權求和得到最終的Attention值。
注意力機制的計算過程可分為3步。首先,如式(1)所示,計算Q和K的相似度;然后,如式(2)所示,利用softmax函數對注意力得分進行數值轉換;最后,如式(3)所示,根據權重系數對V進行加權求和得出Attention值。
Si=F(Q,ki)
(1)
(2)
(3)
式中:si為第i個位置序列的注意力得分;F為相似度計算函數;ki為第i個位置序列的關鍵字;注意力得分si用softmax函數進行歸一化后,得到注意力概率分布αi;vi為第i個位置序列的數值。
2 基于局部信息增強注意力機制的預測模型
2.1 局部上下文信息增強的注意力機制
傳統注意力機制雖然可以學習序列中某時刻信息在序列整體中的相關性,但是在突出某時刻對于序列整體感知的同時,局部信息被弱化的缺點也顯露出來。網絡流量序列的局部信息能夠從微觀角度對時間序列進行解釋,是時間序列中相鄰元素之間的依賴性、趨勢性、隨機性以及多種特性變動的疊加和組合,這是傳統注意力的整體感知所不能涉及的問題。這里通過對注意力機制的內部進行改進從而提升注意力機制的局部感知能力。
傳統的注意力機制計算過程中對一個序列點的Q、K和V進行單獨投影計算,不能充分利用到序列上下文的信息,導致序列數據中的一些局部信息無法被提取到。這一問題體現在對于時間序列上兩個差別較大的特征,利用傳統注意力機制計算出來的兩個特征的絕對值可能一樣,也即對這兩個特征有相同的注意力打分值。
然而,事實上單獨局部特征信息得出來的注意力打分值可能是不同的。針對傳統注意力機制存在的這一問題,這里使用卷積計算作為注意力機制的計算規則,將輸入轉換為Q和K,增加模型的局部感知能力。結合卷積操作的注意力機制生成的Q和K可以更好地學習局部的上下文信息,充分發揮時序序列中某一時刻承上啟下的作用。通過局部信息來計算它們的相似度,有助于提高模型預測的準確性。局部上下文信息增強的注意力機制計算規則如式(4)~式(6)所示,其結果框架如圖3所示。
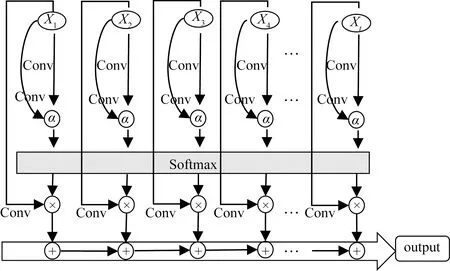
output為輸出
Q=conv(Q′)
(4)
K=conv(K′)
(5)
(6)
式中:conv為卷積計算函數;Q和K為初始狀態的Q′和K′經過卷積后得到的;KT為K的轉置;Q與KT經過相乘生成了相似度矩陣;對相似度矩陣每個元素除以dk,dk為K的維度大小。
2.2 融合局部上下文信息增強注意力機制的LSTM模型
LSTM模型和GRU模型都是RNN(recurrent neural network)系列的模型,該類模型雖然在處理時間序列上有較好的性能,但是這些模型在捕捉序列的長期依賴性方面還存在困難。注意力機制可以在一定程度上彌補這些模型捕捉序列長期依賴關系困難的問題。此外,通過對局部上下文信息增強可以進一步增強模型捕獲局部信息的能力。因此注意力機制與該類模型的融合能夠更好地捕獲序列數據的全局和局部特征,提高模型的預測精度。
LSTM模型與局部上下文信息增強注意力機制集合模型ALSTM(attention long short term memory)框架結構如圖4所示。
如圖4所示,輸入的原始序列Xi通過LSTM處理后可獲得序列中的局部上下文依賴關系,再經由局部上下文信息增強注意力機制(Attention)促使LSTM的輸出結果在全局和局部進行整合,得到模型的最終輸出結果。
2.3 融合局部信息增強注意力機制的GRU模型
GRU模型與局部上下文信息增強注意力機制集合的模型AGRU(attention gate recurrent unit)框架結構如圖5所示。
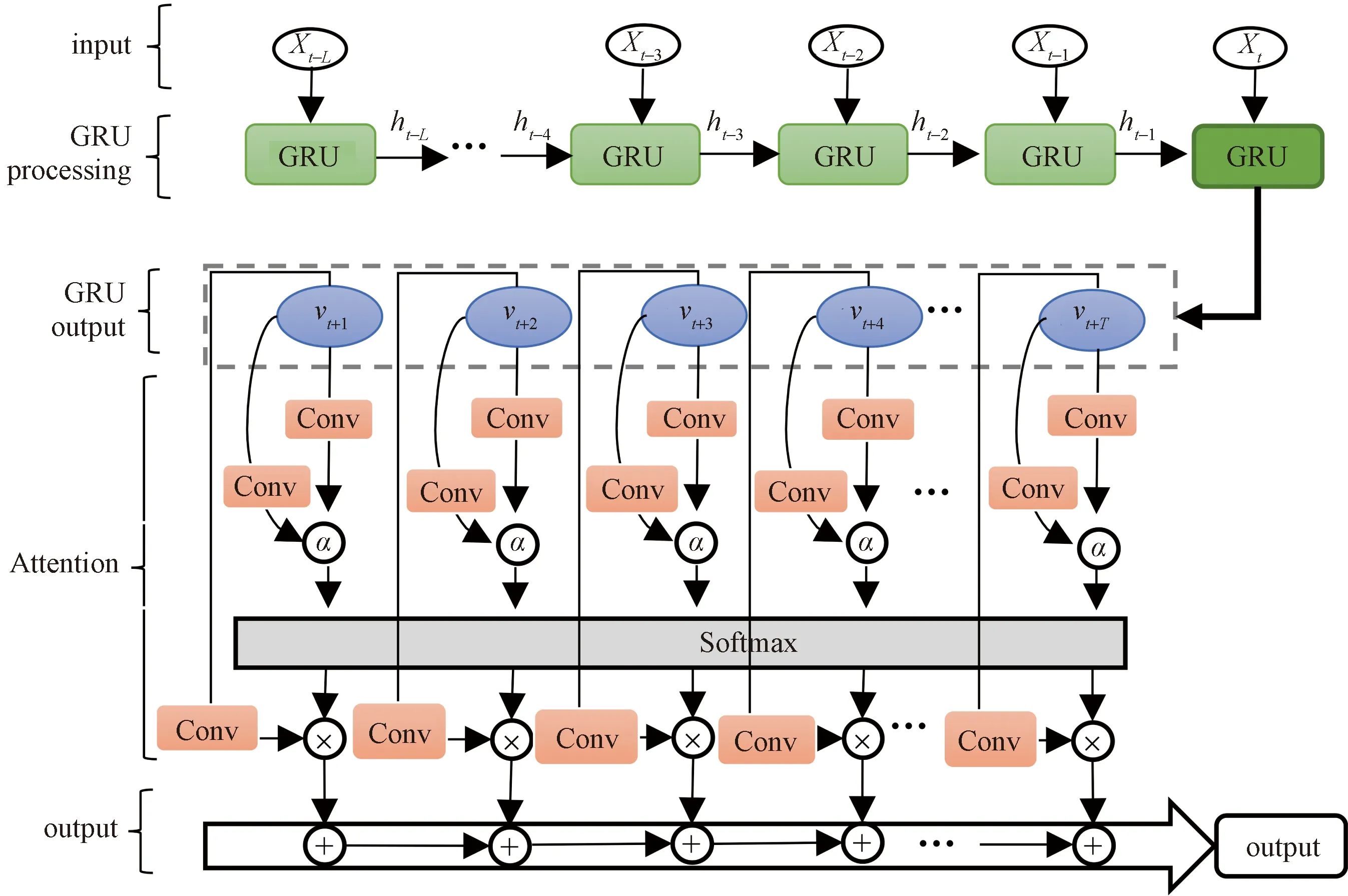
Vi+T為在第T個時刻,第i個位置的序列值V;input為序列輸入;GRU processing為GRU的過程流程;GRU output為經過GRU模型的輸出;Attention為注意力機制模塊;output為輸出
如圖5所示,AGRU模型的工作過程與ALSTM工作過程類似,輸入的原始序列Xi通過GRU處理,可獲得序列中局部的上下文依賴關系,再經由局部上下文信息增強注意力機制(Attention)機制可以使GRU的輸出結果在全局和局部角度進行整合形成AGRU模型。
3 實驗方法
3.1 實驗數據
實驗使用某運營商提供的兩個不同的設備流量數據集Dataset_1和Dataset_2。兩個數據流量數據的具體信息如表1所示。
其中,數據集Dataset_1規模較小但是數據較為完整,基本沒有缺失值和異常值。實驗過程中將數據集Dataset_1中的前4天的數據作為訓練集,第5天的數據作為測試集使用;數據集Dataset_2的數據量較大,但是數據集量具有一定的缺失。并且由于該數據集中存在連續4 d的數據缺失,由于數據缺失量較大,實驗過程中選擇前20 d的數據作為訓練集,最后7 d的數據作為測試集。
從圖6可以發現,數據集Dataset_1的數據質量較好,基本沒有缺失數據。在數據集Dataset_2中除了12月26—30日這4 d的數據整體缺失以外,該數據集在其他時間上還存在少量缺失,在實驗過程中對缺失數據進行了簡單的插補處理。需要注意的是數據集Dataset_2中的數據量較大,在圖6(b)中流量的波動性和周期性展示并不明顯。另外,由于兩個數據集中數據流量的數值量級都比較大,在實驗中對流量數據進行了歸一化處理。流量數據歸一化處理公式如式(7)~式(9)所示。
(7)
(8)
(9)
式中:xi為網絡流量序列中的第i個元素;n為序列中元素個數;μ為該序列的平均值;s為該序列的方差;x_nori為歸一化后序列的第i個元素。
3.2 評價指標
實驗中使用以下4種評價指標評估預測模型在網絡流量預測任務中的性能。
均方根誤差(root mean square error,RMSE)表示的是預測值與其真實值之間的偏差。其值越小說明模型預測效果越好,如式(10)所示。
(10)
平均絕對誤差(mean absolute error,MAE)表示的是預測值與其真實值之間絕對誤差的平均值。其值越小說明模型預測效果越好,如式(11)所示。
(11)
準確率(accuracy,ACC)表示的是預測值與其真實值之間的準確度。其值越小則說明模型預測效果越差,如式(12)所示。
(12)
決定系數R2的取值范圍是[0,1],衡量了模型對因變量變化的解釋程度,即模型能夠解釋因變量的變異性。其值越大說明模型性能越好,公式為

(13)
解釋回歸模型的方差得分Var其值取值范圍是[0,1],越接近于1說明自變量越能解釋因變量的方差變化,值越小說明模型預測效果越差,如式(14)所示。
(14)
3.3 預測結果及分析
實驗采用經典的(history average,HA)、支持向量回歸(support vector regression,SVR)模型以及傳統的時序模型LSTM和GRU[11]作為基本對比模型。通過對同一時間段內不同預測粒度的網絡流量進行預測分析,分別驗證了所提出的AGRU和ALSTM模型的性能。不同模型在數據集Dataset_1和Dataset_2的預測性能如表2和表3所示。

表3 數據集Dataset_2在不同模型上的預測結果
從實驗結果可知,改進后的ALSTM模型和AGRU模型的預測性能比傳統的LSTM模型和GRU模型有顯著的提升,證明了所提出的局部上下文信息增強注意力機制的有效性。主要在于改進后的模型不僅能捕捉時間點對整體序列的依賴關系,同時也增強了模型捕捉序列局部信息以及序列內在聯系的能力。
圖7分別給出了在某一臺具體設備上不同預測模型在測試集上的流量預測結果與該設備真實流量值的可視化結果。
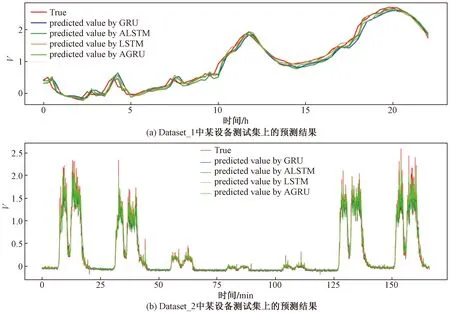
True為正確的結果;predicted value by GRU為GRU模型的預測結果;predicted value by ALSTM為ALSTM模型的預測結果;predicted value by LSTM為LSTM模型的預測結果;predicted value by AGRU為AGRU模型的預測結果
圖8給出了不同預測模型在數據集Dataset_1上所有不同預測粒度的評價指標可視化結果。
圖9給出了不同預測模型在數據集Dataset_2上所有不同預測粒度的評價指標可視化結果。
從上述實驗結果中可以發現,改進后的預測模型ALSTM和AGRU較其他基本對比模型都具有較好的預測性能。需要注意的是,在數據集Dataset_1中所提出的ALSTM模型較AGRU模型具有稍好一些的預測性能,這是因為數據集Dataset_1中的數據量較少導致AGRU模型的訓練并不充分,影響了其預測性能,這也從一個側面說明了ALSTM模型較AGRU模型更適合用于數據量較少的場景。在數據量更充分的數據集Dataset_1中AGRU模型的預測性能顯著高于ALSTM模型,并且所有模型的預測性能都有一定的提升,充分說明了數據量對于模型訓練的重要性,此外在數據較為充分的條件下AGRU模型較ALSTM模型具有更好的性能。
綜上所述,提出的局部上下文信息增強注意力機制能夠有效捕獲時序數據中的局部信息,更好地融合全局和局部特征并區分不同的流量特征值,從而促進預測模型的預測性能。
4 結論
在傳統注意力機制的基礎上設計實現了局部上下文信息增強的注意力機制,提高了網絡流量的預測精度,得到以下結論。
(1)通過在注意力機制中借助卷積計算促使改進后的注意力機制既能夠突出當前時刻對流量序列的整體感知,也能夠捕獲到序列的局部依賴關系。
(2)在傳統GRU和LSTM時序預測模型的基礎上,引入改進后的局部上下文信息增強注意力機制,可以有效提高模型的預測性能。
(3)引入改進注意力機制后的AGRU和ALSTM模型與傳統的GRU模型和LSTM模型相比,具有更小預測誤差和更高的預測準確度。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
文苑(2018年21期)2018-11-09 01:23:06
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
中國衛生(2015年9期)2015-11-10 03:11:12
中外會展(2014年4期)2014-11-27 07:46:46
中國衛生(2014年3期)2014-11-12 13:18:12
中國火炬(2014年4期)2014-07-24 14:22:19
